大家好,我是土哥~
关注我的老粉应该都知道,我从最开始写文章时,分享的都是 Flink 相关的技术文章,也发表了多篇爆款文章。今年呢,从技术规划上,我将做以下几大规划,主要分为四大方向:
1. 公司爆料内推篇
2. 成长职业规划篇
3. 粉丝求职面试篇
4. 数仓优化实战篇
希望从公司简介内推、个人职业规划、粉丝求职面试、技术沉淀等方面形成一个闭环,全方位帮助我的粉丝得到进一步的成长~
今天给大家带来实时数仓实战篇一:长周期去重指标相关的文章
1 前言
做实时数仓的同学,有没有遇到过这种崩溃场景?
你的产品提了一个需求:想看最近 30 天卷入 UV 实时看板 ,要求分钟级更新。
于是你用 Flink 实现长周期任务, 通过 state 存全量用户 ID ,但任务跑了 3 天就 OOM(内存溢出);
于是又换成离线批处理,但 T+1 时效又被业务 diss 太慢,在实时时效和精确统计中,一直无法做到鱼和熊掌兼得。。。
今天,土哥就用一套实时增量+历史存量+湖仓一体的方案 ,从业务痛点到技术选型,从核心步骤到踩坑经验,帮你搞定长周期去重的所有问题,同时把周 UV 做到分钟级更新 ,误差控制在0.8%以内,且任务运行资源可以下降30%。
2 背景
长周期去重指标含义
长周期去重指标 = 时间窗口 + 唯一标识去重
简单说,就是在一个较长时间窗口内(比如 7 天、30天),对用户 ID、设备 ID 等唯一标识做去重计数。常见的有:
-
电商:店铺 7 天 UV、商品 30 天点击设备数;
-
直播:直播间 24 小时观看用户数;
-
广告:广告投放 15 天触达独立用户数。
这类指标的核心矛盾是:窗口越长,数据量越大,实时计算和精确统计的冲突越明显。
2.2 传统方案的死穴
我们先盘点下常见方案的痛点,看看为啥它们解决不了问题:
| 方案类型 | 实现逻辑 | 痛点 |
|---|---|---|
| 纯离线批处理 | Hive/Spark每天算一次 | 时效差(滞后 12-24 小时),无法支撑实时决策 |
| 纯实时Flink | 开长窗口+状态去重 | 状态爆炸(30 天窗口存上亿用户 ID)、OOM 频繁 |
比如纯实时方案算 30 天卷入 UV,假设每天 1000 万用户,30 天就是 3 亿 ID ------ Flink 状态要存这么多数据,不仅内存扛不住,同时 checkpoint 时间能长达 10 分钟,当出现 failover 时,任务重启一次就得等半小时。
3 技术方案
3.1 技术架构
本方案设计核心是实时增量算精准近期数据,离线批量补全历史数据,最后通过中间存储合并。整体架构方案如下:
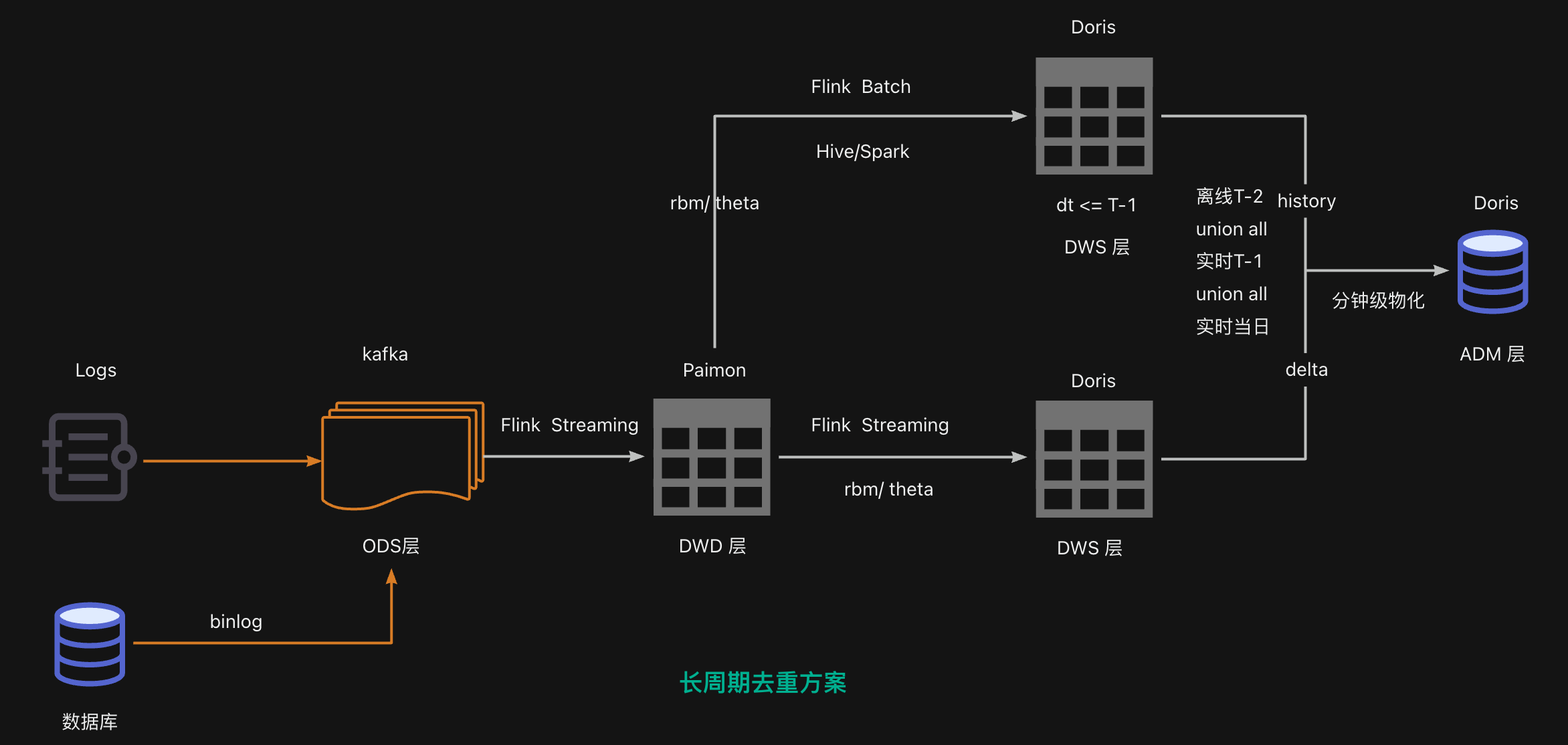
链路1(ODS层):ODS 层使用 kafka 存储,作为消息中间件,上游来自前端埋点或服务端埋点或 OB 库。
链路2(DWD层):DWD 层使用 Paimon 进行离线、实时存储,可以做到流批一体。
链路3(DWS离线) :DWS离线侧,负责算<=T-1 的历史数据,保证最终精确,可以使用 Doris 进行存储,用户 OLAP 数据分析;
链路4(DWS实时) :DWS实时侧:负责实时计算当日数据,可以通过dt、hh 进行分区,使用 Doris 进行存储,用户 OLAP 数据分析,可以做到秒级;
3.2 关键技术选型
很多同学会问:为啥用 Paimon 不用 Hudi ?为啥选 Theta/RBM 不直接存原始 ID ?为啥 ADM 层要用 Doris 呢?
这里直接给结论:
(1)Paimon:中间存储的最优解
我们需要一个支持实时写入、离线批量读取、增量合并 的存储------Paimon(原 Flink Table Store)刚好满足:
-
实时写入:Flink 能 1 分钟内(checkpoint间隔时间)把数据写入 Paimon 分区,且数据可以进行验数分析;
-
离线读取:Flink Batch/Spark能直接读 Paimon 的历史分区,不用转格式;
-
增量合并:支持 CDC 变更和分区覆盖,实时和离线数据能无缝合并。
对比 Hudi,Paimon 的小文件合并更轻量,适合分钟级的小批量写入;
对比 Iceberg,Paimon 的 Flink 集成更原生,不用写复杂的 UDF。
(2)Theta vs RBM:
这两个都是去重计数的算法,如何选取,主要取决于业务需求,我们把它们存在 Doris/Paimon 里做中间结果:
-
Theta Sketch :近似估算算法(HyperLogLog,简称 HLL),用哈希值+位图存去重结果,占用空间小(1000 万用户 ID 仅需10 KB),计算快,但有误差(默认误差 2% 以内);
-
RBM(Roaring Bitmap) :精确统计算法,本质是存去重后的原始 ID,但用了压缩和索引优化,比直接存 ID 省 50% 空间,适合误差必须为 0 的场景(比如电商的支付 UV)。
我们的方案里,实时增量用RBM(准),离线批量用RBM(准),最后合并时取 RBM 的精确结果。
(3)Doris
DWS、ADM 层用 Doris,主要是两个原因:
-
物化视图自动合并:Doris 能把 Theta/RBM 结果自动聚合,生成按分钟、小时、天调度一次的物化视图,查询时直接读视图,速度比查原始数据快 10 倍;
-
高并发低延迟:支持每秒 1000+ 查询,响应时间在 100ms 以内,刚好满足运营看板、API 接口的需求。
4.实战
4.1 DWD 层
Flink 实时写入 Paimon
业务日志(用户访问日志)先发到 Kafka,Flink 流读作业按分钟写入 Paimon DWD 层,这里的关键参数:
-
Paimon的
partition.fields设为dt,hh(日、时)即可; -
Flink的
checkpoint.interval设为1分钟,确保数据 1 分钟内落地Paimon。
代码片段(Flink SQL):
CREATE TABLE dwd_paimon_log_ri (
`create_log` VARCHAR COMMENT '时间戳',
`user_id` VARCHAR COMMENT 'userid',
`dt` VARCHAR COMMENT '',
`hh` VARCHAR COMMENT ''
)
PARTITIONED BY (`dt`,`hh`)
WITH (
'ant.version'='10'
,'partition.time-interval'='1d'
,'partition.timestamp-formatter'='yyyyMMdd HH'
,'partition.idle-time-to-done'='5min'
,'snapshot.time-retained'='48h'
,'partition.timestamp-pattern'='$$dt $hh'
,'bucket'='-1'
,'connector'='paimon'
,'snapshot.expire.execution-mode'='async'
,'partition.expiration-time'='63d'
,'target-file-size'='256MB'
);
INSERT INTO dwd_paimon_log_ri
SELECT create_log
,user_id
,REPLACE(SUBSTR(create_log, 1, 10), '-', '') AS dt
,SUBSTR(create_log, 12, 2) AS hh
FROM ods_kafka_log_ri t1 DWD 层主要职责为 Flink 流式写入 Paimon,通过 dt、hh 进行分区,这样下游可以离线、实时分别读取。
4.2 DWS 层
4.1.1 DWS实时侧
DWS 层实时侧通过 Flink 流读 Paimon 写入 Doris。
这里的关键是用 rbm 代替原始 ID 存储:
- 本质是存去重后的原始 ID,但用了压缩和索引优化,比直接存 ID 省 50% 空间,适合误差必须为 0 的场景(比如电商的支付 UV)
代码片段:
CREATE VIEW log AS
SELECT create_log
,DATE_FORMAT(create_log, 'yyyyMMdd') AS day
,DATE_FORMAT(create_log, 'HH') AS hour
,DATE_TRUNC(SUBSTRING(create_log, 1, 19), 'HH') AS b_time
,user_id
FROM dwd_paimon_log_ri
WHERE is_date(create_log)
AND UNIX_TIMESTAMP(create_log, 'yyyy-MM-dd HH:mm:ss') >= (
UNIX_TIMESTAMP() - 86400 * 2
)
AND UNIX_TIMESTAMP(create_log, 'yyyy-MM-dd HH:mm:ss') < (
UNIX_TIMESTAMP() + 60
);
INSERT INTO ads_doris_log_rs
SELECT day AS dt
,hour
,b_time
,UNIX_TIMESTAMP() * 1000000 AS version
,'v1' AS reset_version
,'EVENT' AS event_code
,CAST(rbm_acc_udaf(user_id) AS BINARY) AS uv_rbm_bytes
,COUNT(1) AS pv
FROM log
GROUP BY
,day
,hour
,b_time4.1.2 DWS 离线侧
通过 rbm 精准计算历史 T-1 的全量数据。
INSERT INTO adm_doris_log_dd PARTITION (dt = '${bizdate}')
SELECT '${bizdate}' AS dt
,UNIX_TIMESTAMP() * 1000000 AS version
,'v1' AS reset_version
,'EVENT' AS event_code
,CAST(rbm_acc_udaf(user_id) AS BINARY) AS uv_rbm_bytes
,COUNT(1) AS pv
FROM dwd_paimon_log_ri
WHERE dt <= '${bizdate}'
GROUP BY dt4.3 ADM 层
合并历史与增量
这里采用离线 T-2 的数据 UNION ALL 实时 T-1 的数据 UNION ALL 实时增量数据。
为什么要这样做呢?防止离线 T-1 在当天未产出,造成数据合并错误。
部分代码:
SELECT
rbm_distinct(base64_decode(uv_rbm_bytes)) as uv,
SUM(pv) pv
FROM (
-- 实时
SELECT
,uv_rbm_bytes
,pv
FROM ads_doris_log_rs
WHERE dt = TO_CHAR (
DATE_SUB (TIMESTAMP '${current_hh}', INTERVAL '0' HOUR),
'yyyyMMdd'
)
and hour <= SUBSTR (
TO_CHAR (
DATE_SUB (TIMESTAMP '${current_hh}', INTERVAL '0' HOUR),
'yyyy-MM-dd HH:mm:ss'
),
12,
2
)
-- T-1 实时
UNION ALL
SELECT
,uv_rbm_bytes
,pv
FROM ads_doris_log_rs
WHERE
dt = TO_CHAR (
DATE_SUB (TIMESTAMP '${current_hh}', INTERVAL '1' DAY),
'yyyyMMdd'
)
-- T-2 离线
UNION ALL
SELECT
,uv_rbm_bytes
,pv
FROM ads_doris_log_dd
WHERE
dt = TO_CHAR (
DATE_SUB (TIMESTAMP '${current_hh}', INTERVAL '2' DAY),
'yyyyMMdd'
)
)四、总结
4.1. 平衡快和准
上述方案的最大价值是在成本可控的前提下,做到了分钟级时效和最终精确。
若对时效性要求很高,同时 UV 数据误差可以接受在2%以内,推荐:
-
实时增量用 Theta,资源消耗只有纯实时的1/10;
-
离线批量用 RBM,保证历史数据 100% 精确;
2. 场景复用
这套方案适用于所有长周期去重+实时需求的场景:
-
电商:店铺7天UV、商品30天点击设备数;
-
广告:广告投放 15 天触达独立用户数。
如果你的场景不需要 100% 精确,可以全用 Theta(省资源)。
如果需要 100% 精确,可以把实时增量也换成RBM(但资源消耗会增加)。
长周期去重是实时数仓的必考题, 你在做长周期去重时,遇到过哪些问题?是误差太大?还是资源不够?欢迎在评论区留言,我们一起交流!
增值服务:简历修改|面试辅导|Flink资料|模拟面试
你好,我是土哥,计算机硕士毕业,现某大厂资深大数据开发工程师。出生在一个 18 线开外的小村庄,通过自己努力毕业一年在新一线城市买房,在社招、校招斩获 28 家中大厂 offer。
2026年,很多公司岗位流动性非常大,已经到了一年中最佳的求职高峰期。如果你想跳槽,但苦于一个人孤军奋战、无人指导、复习无从下手,或者不擅长写简历,手上只有拿不出手的毫无难点亮点的项目经历...
那么我的建议是多和身边的大佬沟通,哪怕是付费咨询,只要你能从他身上学到经验,那就是值得的。如果身边没有这样的人,那么我就毛遂自荐一下吧,毕竟,茫茫网络你能看到这篇文章何尝不是一种命运安排。
土哥社招参加 28 场面试,100% 通过率,拿到全部 offer!