数仓整体架构和建模架构
- 阿里巴巴大数据之路目前总共有1和2。其中1的内容主要是针对2010~2020年之间的环境。而2则是在1上做了一些补充,其中既有大模型,也有企业在根据1进行转型的时候,所遇到的问题进行解决。2的解决很多时候,是从企业层面的角度出发,去推动全公司层面的人理解数据,使用数据,推动数据的改革。让数据嵌入公司业务的全流程。
- 我认为对于大部分人来说,只要学习1就可以了。2的话,可以适当了解并吸收。通常情况下,只有在中高层,才需要解决。主要是要建立整个流程的sop,确保数据口径上下一致。同时,搭建整个公司层面的数据门户,让使用的人都能清楚的知道并快速的使用数据。
- 本此总结不涉及数据采集,数据上报的内容。还是重点在数仓建模,针对数仓的数据治理等内容。
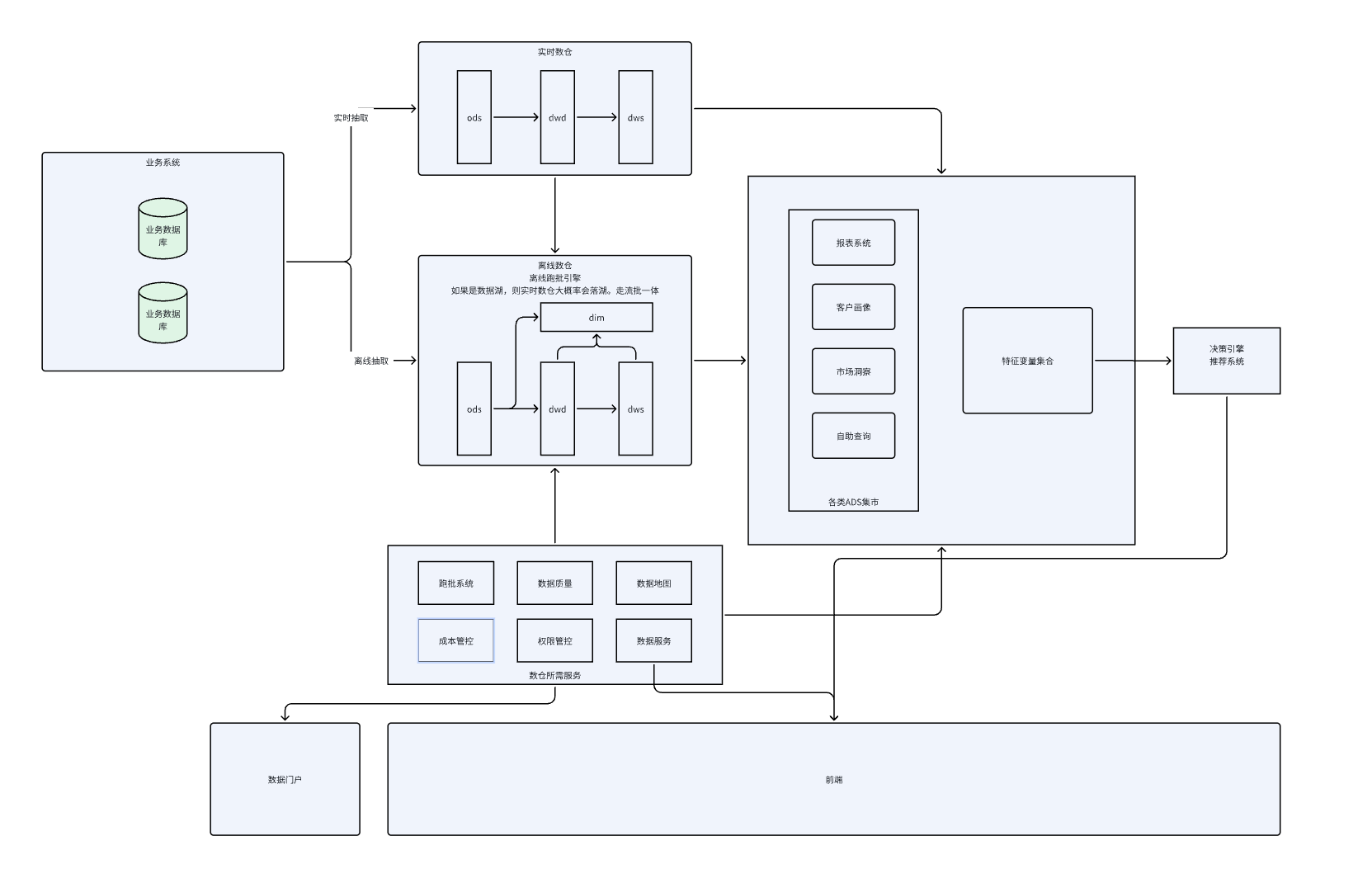
大数据整体的架构图
- 这个架构图是我工作这些年来思考的整体模型,主要是大数据在这其中充当了哪些角色。并且无论是小厂,中厂还是大厂,都会朝着这个架构演进。只是可能需要的内容会有差异。
-
这图画的有点潦草,主要是心得为主。在后续的总结中,可能会对此图进行优化。
-
首先从最开始开始讲:
-
数据抽取:抽取指的是将业务库的数据毫无保留,完整的交给数仓。由数仓统一进行开发和管理。其中分为离线抽取和实时抽取。
-
离线抽取:sqoop
-
实时抽取:flinkcdc
-
-
抽取完了后,就需要对数据进行管理。而管理的方法则是建模,建模,我的理解是根据一定规律将数据进行合理的归纳。降低数据开发的复杂度,而非业务开发的复杂度。常见的建模方式有三范式,er,维度建模,以及基于维度建模的阿里巴巴数据建模。
- 如果基于维度建模,建模分为:ods,dwd,dws,dim。通常很多公司会混合建模,就是将三范式和维度结合起来,进行建模。所以没必要太过于遵守规则,而是基于公司情况进行开展。最终目的是有序,合理的将数据整理,并形成目录,降低数据使用的门槛和提高数据的复用率。
-
数仓主要分为实时数仓和离线数仓。目前流批一体的场景下,部分简单的表可以通过hudi或者paimon实现。降低开发的复杂难度。做到一张表只需要维护一条链路。
-
然后是基于数仓的服务,包括离线任务的调度,实时任务的监控。整体数仓的数据质量管理,数据服务,成本管控中心和权限管控等。这些都是数开日常管理中必须具备的能力。只是说可以针对不同的企业背景和建设程度,做一定的取舍。但是最基本的调度功能和任务监控功能是必须具备的。
- 调度:airflow。其余的可以自行搜索,有很多的开源方案,但是我的理解是如果真的需要做数据治理,那元数据是必备的。而这个最终是需要落地到我们本地库上的。只能通过解析开源方案,并进行一定程度的改造。
-
数仓搭建完毕后,就需要一个或n个平台去使用这些数据。常见的有报表系统,特征变量系统,各部门自己的使用请求。包括针对b端客户或者c端客户的数据产品需求等。
-
这些都完成后,就是通过数据服务统一接口,让前端使用。这里将数据门户单独拎出来是因为这个数据门户是从公司整体的角度,记录登记哪些数据可以使用,数仓也只是其中的一部分,虽然这个一部分非常的多。企业内部非数开人员都会通过数据门户网站链接拜访各类数据产品系统,并获取各类数据产品的使用方法,其中甚至包括部分数据地图的表。
- 可以看到我将特征变量单独拎了出来,是因为现在大模型时代,内容越来越重要。而要做好内容,给用户好的内容,就需要好的特征变量。这些特征变量通常还会有特征变量系统进行全局的管控,确保特征变量的质量。一个好的算法,好的推荐系统,背后一定有好的数据,好的回测作支持。这些都离不开数仓。
-
-
这个架构前端通过数据服务或者直接访问ads层数据进行展示。ads层的各个业务模块可以抽象成不同得数据产品供前端使用。从这个角度看,这个架构就是数据中台架构。但是实际情况不要过度教条,数仓或者ads能解决的是共性的问题。
- 目前很多的业务场景存在数仓整合困难,不懂业务,只懂技术。这种场景会让一部分业务系统的人参与进来,自己拼接明细宽表,供下游使用。
- 还有一类场景则是在前端展示时,因为敏感数据或者业务场景复杂,需要将业务系统本身的数据和数据服务的数据进行整合,从而对外输出。
- 所以我理解最普遍的架构是后端团队会参与进数仓体系,通过数仓已经完善的基建能力,自己整合一部分数据并供到数仓侧,降低数仓数据的开发难度。
- 而数据门户则需要维护好,将来公司的业务开展,前端展示都会通过数据门户进行调研,选择合适的数据产品。
数据建模
ODS层:Operation Data Store(操作型数据层)
- 本质就是原封不动的保留上游业务系统的表结构和对应的数据,并将其存到数仓中。目前各家ods层做法不太相同。这里引用阿里云的介绍:
- 存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。记录基础数据的历史变化。
- 记录数据的历史变化,通常就三种,分别是:
- 增量表:增量表就是根据业务时间字段,增量备份某一时间的数据,并给下游使用。
- 全量表:全量表就是每日零点全量拉取t-1时刻的数据。并做切片备份。
- 拉链表:拉链表是给数据加上表示生命周期的字段:start_date和end_date。这两个字段分别表示该业务的全生命周期,从而记录数据的变更轨道。如果数据变动十分高频,则做拉链表没有必要。通常是一些交易订单表,但是存在近期内有数据变动的情况。和增量表十分相似,只是相比增量表,使用起来更方便。而且相比增量表,可以解决上游业务系统物理删除数据的业务场景。找到这条数据,并进行手动关链。
CDM层:Common Data Model(公共模型层)
- 包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
DIM层:Dimension 公共维度层
-
基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。
-
我这里的理解是在维度建模的世界中,表只有两类,分别是事实表和维度表。事实表只有当前的业务粒度和对应的度量值。这些用来统计指标,而其余的则都可以成为维度。只是在大数据场景下,将事实表的维度剥离出来,做成维表,是收益比很低的一件事,所以很多维表字段不会剥离,相反,还会有很多维表字段进行下沉,多张表中维护同份数据。
-
维度表通常是从统计的角度,哪些可以被统计的对象都可以做成维度表。一般常见的维度对象:用户,地区,日期,商品,车辆等。还有一些没法抽象的,比如业务过程中业务的状态,业务种类这些就没必要做成维度表,而是下沉到dwd层的明细表。
DWD层:Data Warehouse Detail(数仓明细层)
- 以业务过程驱动建模,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。这里通常就是事实表存放的地方。
- 事实表通过一个业务主键和大量相关的度量值和维度信息去描述表达对应的业务过程。事实表中一条记录所表达的业务细节程度被称为粒度。
度量值
- 描述业务过程的度量值分为3种类型,分别是可加性,半可加性和不可加性三种类型。
可加性
- 可加性指的是度量值可以按照任意维度汇总。比如说交易金额,可以按照客户地区,按照支付时间,按照产品类型等任意维度。
半可加性
- 半可加性指的是度量值只能按照特定维度进行汇总,不能对所有维度汇总。比如账户存款可以按照用户类型进行相加,但是如果按照时间维度进行相加没有任何意义。
不可加性
- 不可加性指的是度量值相加没有任何意义。通常比值都是不可加性。比如如实付金额和预付金额相除得到折扣率。这个折扣率相加就没有任何意义,通常的做法是在支付表中将实付和预付拆成两个字段。
事实表
设计原则
原则1:尽可能包含所有与业务过程相关的事实。事实即度量,指的是在加工的过程中,将事实相关的度量值经可能全部加工进来。
原则2:只选择与业务过程相关的事实。这个我认为视具体行业而定,在一些金融行业,通常会在客户实还表上加上借款金额和借款日期这两个放款阶段的字段。这么做的目的是为了后续计算风险指标能更好的进行计算。
原则3:分解不可加性事实为可加的组件。就是将比率字段拆分成两个事实字段进行存储。
原则4:在选择维度和事实之前必须先声明粒度。这个就是表模型设计的时候,确定好对应的业务主键,从而扩展模型。
原则5:在同一个事实表中不能有多种不同粒度的事实。这个意思就是粒度确定了之后,就需要存放与这个粒度一致的事实。而不是一张表中有多个粒度。主要是会给使用的人造成困扰。
原则6:事实的单位要保持一致。就是涉及到事实字段统一用同一个单位。
原则7:对事实的null值要处理。主要是为了解决不同数据库对null的处理不一致问题。通常需要一个默认值。
原则8:使用退化维度提高事实表的易用性。这里的目的是在kimball维度建模中,事实表和维度表是分开存放的,大量的杂项维度必须存放在维度表中。但是这个设计在日常开发中其实会很冗余,可以将大量的维度下沉到事实表中。
设计方法
- 选择业务过程及确定事实表类型
- 声明粒度
- 确定维度
- 确定事实
- 冗余维度
种类
- 事务事实表
- 最简单的一种,就是一条记录就是一个业务过程,不记录这个业务过程的中间状态。日常开发中,用的最多就是事务事实表。通常指的是交易,订单,授信等各类业务场景。都可以用这个表开发。又分为单业务事实表和多业务事实表。
- 单业务事实表
- 一个表中只有一个业务过程。
- 多业务事实表
- 一个表中有多个业务过程。通过某个字段进行区分。
- 单业务事实表
- 最简单的一种,就是一条记录就是一个业务过程,不记录这个业务过程的中间状态。日常开发中,用的最多就是事务事实表。通常指的是交易,订单,授信等各类业务场景。都可以用这个表开发。又分为单业务事实表和多业务事实表。
- 周期快照事实表
- 主要是针对账户,仓储,库存等状态类事实。这些事实每次更新最新的一份并进行计算是毫无意义的,通常伴随着加工时间进行存储,根据时间维度计算状态的一些值并用于展示。
- 相比于事务事实表,周期快照事实表是稠密的。事务事实表则是稀疏的。这里的稠密和稀疏指的是加工过程中涉及的业务过程,事务事实表通常会计算近n日的业务过程并分区存放。而周期快照事实表则是每天存放一个业务快照,无论这个数据有没有变动。
- 累积快照事实表
- 可以看成是事务事实表的一个补充。整个的分析过程涉及多个业务过程,这些业务过程可以互相关联加工计算,但是对于常用的多个业务过程,则可以考虑使用累积快照事实表。
- 累积快照事实表就是将多个业务过程加工在一个粒度上,这些业务过程有递进关系或者关联关系。粒度通常是第一个业务过程的粒度,比如订单粒度。会有下订单,收货,投诉等。这些度量都放在一个订单粒度上。就形成了累积快照事实表。
- 主要是为了解决计算一些横跨多个业务过程的指标。当然,在这个加工过程中,我个人是会将各个业务过程的业务主键也放在累积快照事实表中,希望能尽快关联到对应的业务过程上。
- 无事实的事实表
- 主要是度量值缺失,或者没法描述的业务过程都可以称为无事实的事实表。
- 第一种是日志类事件的。这类日志通常记录的是客户的各种浏览行为,这类行为通常是1,单独计算的可能性较小,通常是配合其他业务过程进行计算。
- 第二种则是记录维度和维度之间关联关系。比如主合同与从合同这两个之间的关系。又比如父子订单之间的关系。
- 聚集型事实表
- 就是在上述事实表的基础上,根据某一维度进行聚集,减少下游使用的计算量,提供现成统一的计算结果。这个表通常放在dws层。
DWS层:Data Warehouse Summary(汇总指标事实表)
- 这里也就是说的聚集型事实表常用的地方。建模原则上得遵循ods->dwd->dws的模式
- 分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求构建公共粒度的汇总指标事实表。公共汇总层的一个表至少会对应一个派生指标。
- 这里关于指标的定义,放到后面指标体系详解。包括主题的构建。我理解dwd层的主题和dws层的主题并非一个概念。甚至还有数据域和主题域的讲法。通常dwd主要讲数据域,dws主要讲主题域。这些都会放到指标体系构建上去讲。