问题一描述:
在hive运行简单查询的时候能够正常执行,但是执行复杂查询的时候,能够完成map和reduce,但是执行到一半失败,返回:Ended Job = job_1769249890116_0001 with exception 'java.io.IOException(java.net.ConnectException: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort)'
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. java.net.ConnectException: Your endpoint configuration is wrong; For more details see: http://wiki.apache.org/hadoop/UnsetHostnameOrPort
如图所示:

方法一:调整map和reduce的内存分配
查询mapred-site.xml(vim ${HADOOP_HOME}/etc/hadoop/mapred-site.xml)发现是我之前给map和reduce的内存分配太少了。
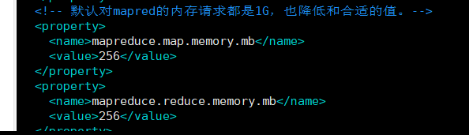
修改配置,将值调整成1024,然后退出保存,再将配置文件更新到其他各个节点上( scp mapred-site.xml node1:`pwd`)

然后重启hadoop集群和hive
方法二:本地模式运行
如果核心需求是执行 SQL 获取结果,而非调试 MapReduce 任务,直接关闭 Hive 对 MapReduce 任务状态的检查,在执行 SQL 前添加以下配置(在hive中运行):
set mapreduce.job.tracker=local;- 强制本地模式(避免集群级别的HistoryServer依赖)然后再执行查询语句即可。
问题二描述:
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTa
sk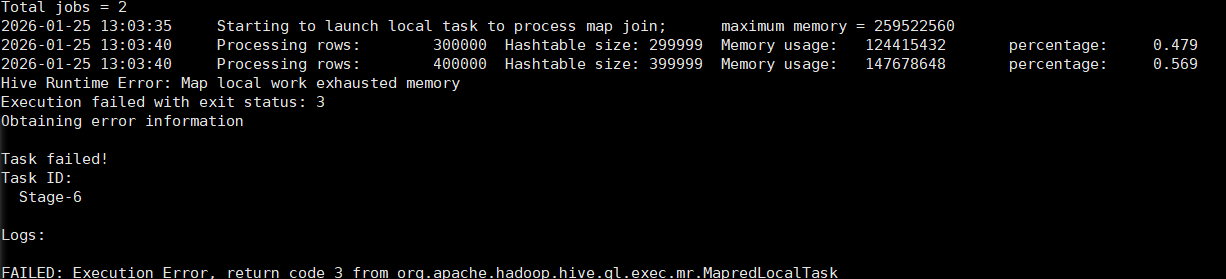
这个错误是Hive 本地 Map Join 时内存耗尽导致的,核心原因是 Hive 在执行小表关联时,将小表加载到内存构建哈希表,但当前内存不足
方法一:关闭本地Map join,改用分布式Map join
set hive.auto.convert.join=false;在hive上执行完上述代码后重新运行查询语句。
方法二:调整yarn配置文件(长期生效)
关闭hive和hadoop集群,修改配置文件yarn-site.xml(vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml)。这是原本的配置:
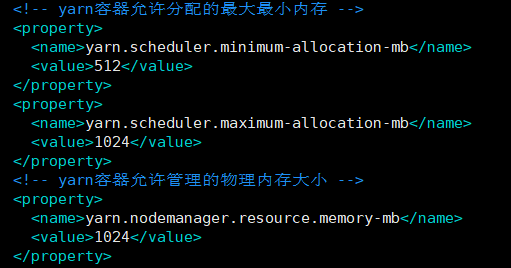
修改允许分配的最大最小内存,以及允许管理的物理内存大小,修改如下:
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocationmb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocationmb</name>
<value>2048</value>
</property>
<!-- yarn容器允许管理的物理内存大小(NN) -->
<property>
<name>yarn.nodemanager.resource.memorymb</name>
<value>2048</value>
</property>改完之后将分发给其他各个节点进行覆盖原本的配置文件( scp yarn-site.xml node1:`pwd`)
修改四个节点的内存,右键节点后选择setting,修改完成虚拟机内存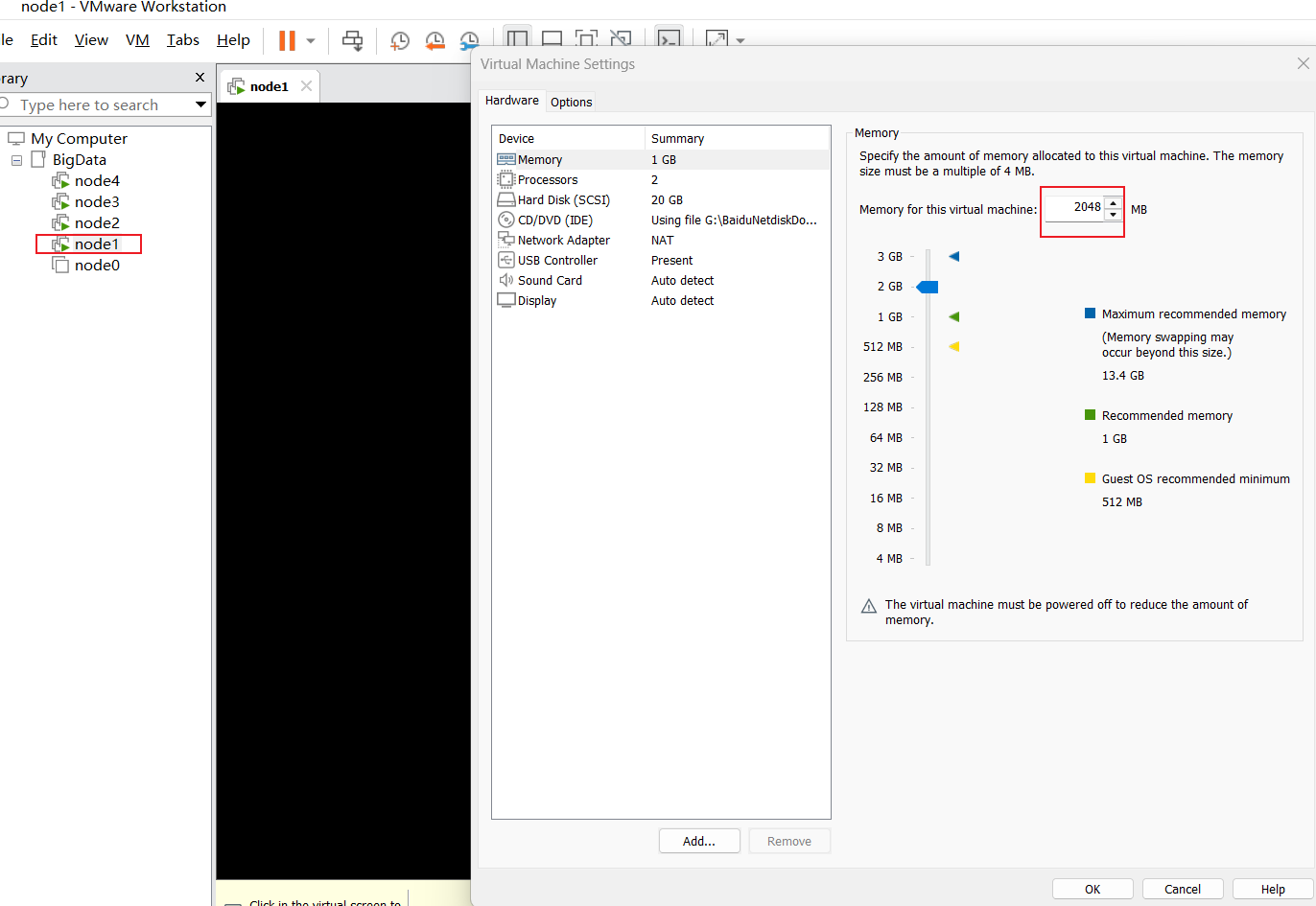
修改完成之后重新启动hadoop集群以及hive