文章目录
- 本篇摘要
- [一.ES 介绍及简单使用](#一.ES 介绍及简单使用)
-
- 1·介绍
- 2.安装过程
- 3.ES核心知识概念
-
-
- [**1. 索引(Index-->库)**](#1. 索引(Index-->库))
- [**2. 文档(Document)**](#2. 文档(Document))
- [**3. 字段(Field)**](#3. 字段(Field))
- [**4. 类型(Type-->类似表)**(7.x后已废弃)](#4. 类型(Type-->类似表)(7.x后已废弃))
- [**5. 映射(Mapping)**](#5. 映射(Mapping))
-
- 4.kibana介绍
-
- [**Kibana 是什么?**](#Kibana 是什么?)
- [**Kibana 和 Elasticsearch 的关系**](#Kibana 和 Elasticsearch 的关系)
- 5.安装Kibana过程
- 6.kibana-es使用
- 7.es-client使用及封装使用接口
- 二.本篇小结

本篇摘要
本文从 Elasticsearch(ES)简介、安装到核心概念,结合 Kibana 可视化工具,全面讲解其分布式搜索能力。重点演示 C++ 客户端 API 封装,涵盖索引管理、CRUD 操作,并通过代码示例实现数据增删查改,来为后面项目操作做铺垫。
一.ES 介绍及简单使用
1·介绍
Elasticsearch 简称 ES,是开源分布式搜索引擎。
特点:
- 分布式相关:具备分布式特性,支持自动发现、索引自动分片与索引副本机制。
- 易用性与接口:采用 restful 风格接口,零配置,能让用户以简单方式操作。
- 多数据源与扩展性:可对接多数据源,本身扩展性好,能扩展到上百台服务器,处理 PB 级别数据。
- 存储检索及时性:近乎实时地存储、检索数据。
- 技术底层与封装:由 Java 开发,以 Lucene 为核心实现索引和搜索功能,但通过简单 RESTful API 隐藏 Lucene 复杂度,降低全文搜索门槛。
数据操作面向与方式:
- 面向对象:面向文档(document oriented),可存储整个对象或文档。
- 数据处理 :不
只是存储,还会对每个文档内容建立索引以实现可搜索;支持对文档(而非行式/列式数据)进行索引、搜索、排序、过滤等操作。
2.安装过程
| 步骤 | 命令/操作 |
|---|---|
| 1. 导入 GPG 密钥 | `wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch |
| 2. 添加 APT 源 | `echo "deb [signed-by=...] https://artifacts.elastic.co/packages/8.x/apt stable main" |
| 3. 更新 & 安装 | sudo apt update && sudo apt install elasticsearch |
| 4. 启动 & 自启 | sudo systemctl start elasticsearch && sudo systemctl enable elasticsearch |
| 5. 检查状态 | sudo systemctl status elasticsearch |
| 6. 测试访问 | curl http://localhost:9200/ |
| 7. (可选)远程访问 | 修改 network.host: 0.0.0.0 并重启 |
| 8. (可选)设置密码 | sudo /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic |
检测是否安转成功
1· 启动es:在Shell中执行命令sudo systemctl start elasticsearch。
2·查看es服务的状态:在Shell中执行命令sudo systemctl status elasticsearch.service。
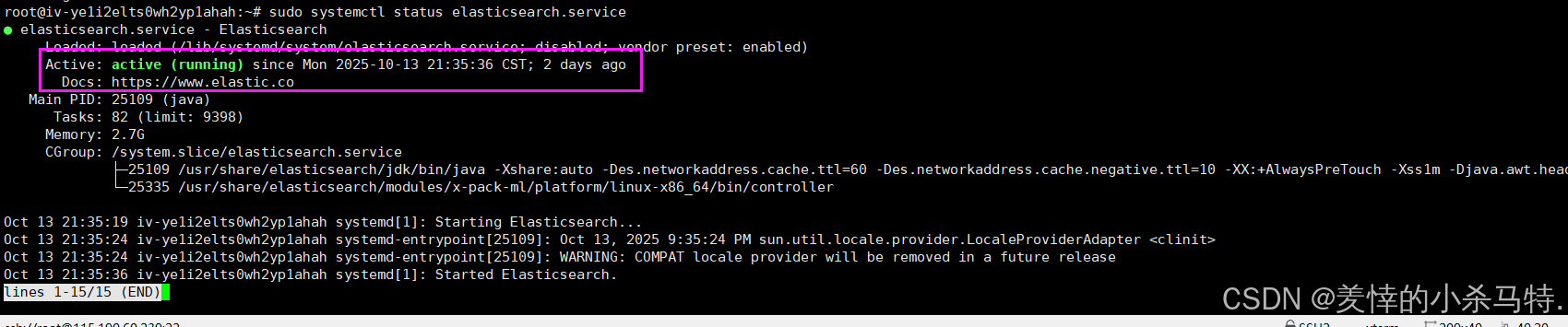

- 可以看到,ES服务成功运行并部署在服务器的9200端口上。
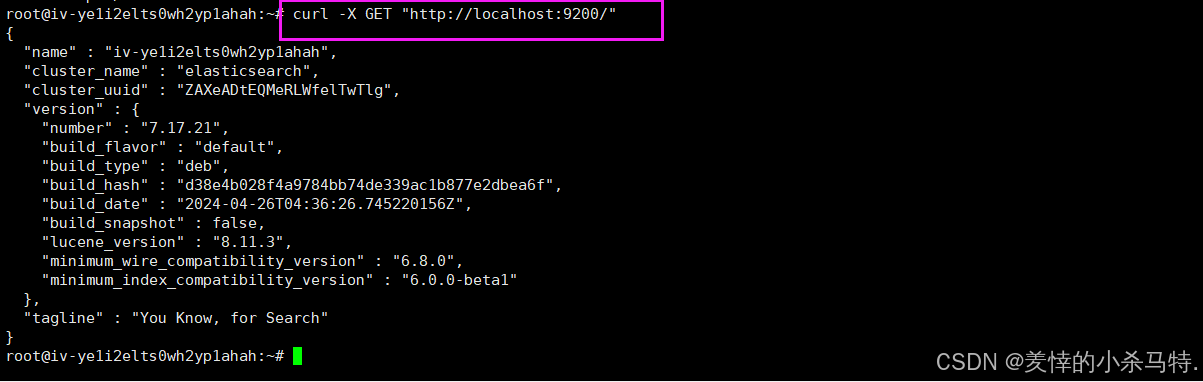
- es服务成功能进行访问。
对应配置文件修改
默认仅本机可访问;使用Vim编辑/etc/elasticsearch/elasticsearch.yml文件。
新增配置:
network.host: 0.0.0.0http.port: 9200cluster.initial_master_nodes: ["node-1"]
3.ES核心知识概念
1. 索引(Index-->库)
- 是什么:数据的逻辑容器(类似数据库)
- 例子 :
logs-2024(存储2024年的日志数据)products(存储商品信息)users(存储用户数据)
2. 文档(Document)
-
是什么:索引中的一条具体数据(JSON格式)
-
例子 :
json// 在users索引中的一条文档 { "name": "张三", "age": 25, "email": "zhangsan@example.com", "join_date": "2024-01-15" }
3. 字段(Field)
- 是什么:文档中的单个数据项
- 例子 (来自上面的文档):
name字段(值:"张三")age字段(值:25)email字段(值:"zhangsan@example.com")
4. 类型(Type-->类似表)(7.x后已废弃)
- 旧版例子 (6.x及之前):
- 在
content索引中可能有:article类型(存储文章)comment类型(存储评论)
- 在
- 新版(7.x+) :
- 一个索引只能有一种类型(默认
_doc) - 例子:
users索引中所有文档都是_doc类型
- 一个索引只能有一种类型(默认
5. 映射(Mapping)
-
是什么:定义字段的数据类型
-
例子:
json// 手动定义的映射示例 { "mappings": { "properties": { "name": { "type": "text" }, // 文本类型 "age": { "type": "integer" }, // 整数类型 "email": { "type": "keyword" }, // 关键词类型(精确匹配) "join_date": { "type": "date" } // 日期类型 } } }自动推断的例子:
-
如果你插入
{"price": 99.99},ES会自动推断price为float类型 -
如果你插入
{"status": "active"},ES会自动推断status为text类型
提示 :在ES 7.x及以上版本,创建索引时通常不需要指定类型(使用默认的
_doc类型即可),但是专注于索引和字段映射的设计更重要。
4.kibana介绍
Kibana 是什么?
Kibana 是 Elasticsearch 的可视化工具 ,用 网页界面 展示和分析 ES 里的数据(比如日志、图表、仪表盘)。
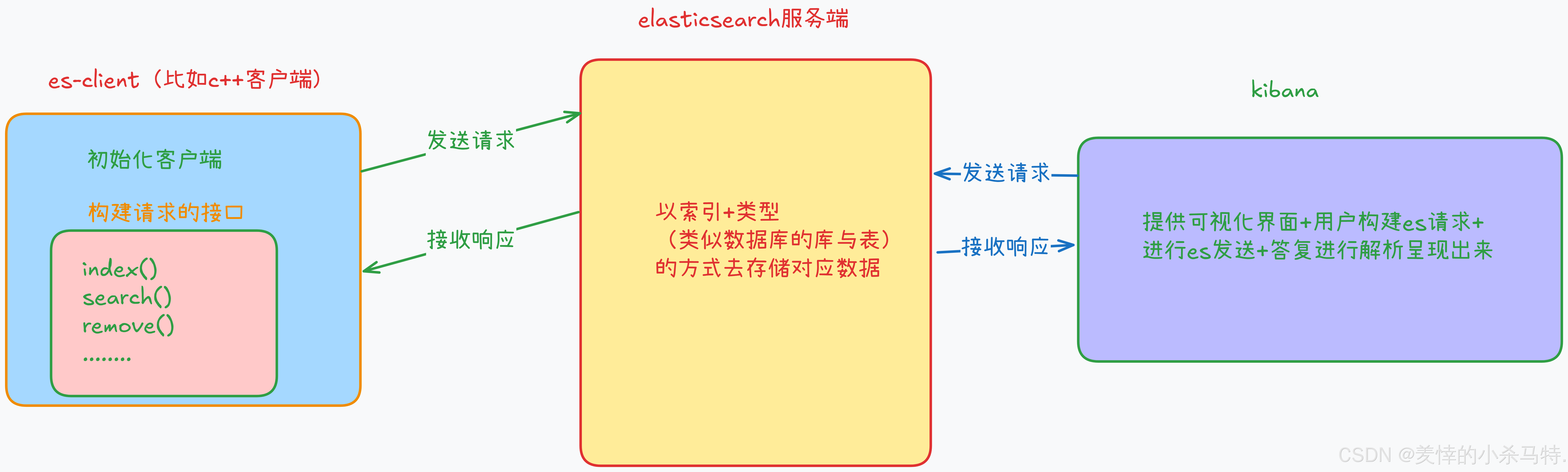
Kibana 和 Elasticsearch 的关系
- Kibana 必须连接 Elasticsearch 才能用(就像手机需要网络才能上网)。
- Elasticsearch 负责 存数据、搜索数据(像数据库)。
- Kibana 负责 把 ES 里的数据变成图表、仪表盘(让人更容易看懂)。
简单比喻:
- Elasticsearch = 仓库(存东西)
- Kibana = 展示柜(把仓库里的数据摆出来给人看)
常见用途:
- 看 日志(比如网站报错)
- 做 数据图表(比如访问量统计)
- 监控 服务器状态(比如 CPU 使用率)
访问方式 :浏览器打开 http://你的服务器IP:5601 即可使用(这是它的默认端口,可以根据配置文件进行修改)。
关系图形象如下:
5.安装Kibana过程
-
安装Kibana:
使用
apt命令安装Kibana:bashsudo apt install kibana -
配置Kibana(可选):
根据需要配置Kibana。配置文件通常位于
/etc/kibana/kibana.yml。可能需要设置如服务器地址、端口、Elasticsearch URL等:bashsudo vim /etc/kibana/kibana.yml例如,你可能需要设置Elasticsearch服务的URL,大概在32行左右:
yamlelasticsearch.host: "http://localhost:9200" -
启动Kibana服务:
安装完成后,启动Kibana服务:
bashsudo systemctl start kibana -
设置开机自启(可选):
如果你希望Kibana在系统启动时自动启动,可以使用以下命令来启用自启动:
bashsudo systemctl enable kibana -
验证安装:
使用以下命令检查Kibana服务的状态:
bashsudo systemctl status kibana
下面演示下:
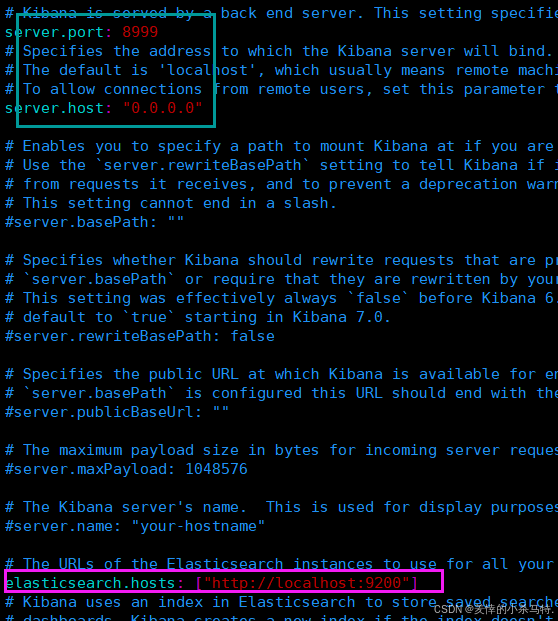
- 这里对对应的kibana的配置文件进行编辑:默认监听所有ip并部署在本地的8999端口 ,然后
它收到的数据发送到localhost的9200端口(也就是es服务器),接收到的答复再呈现可视化出来方便用户观看。
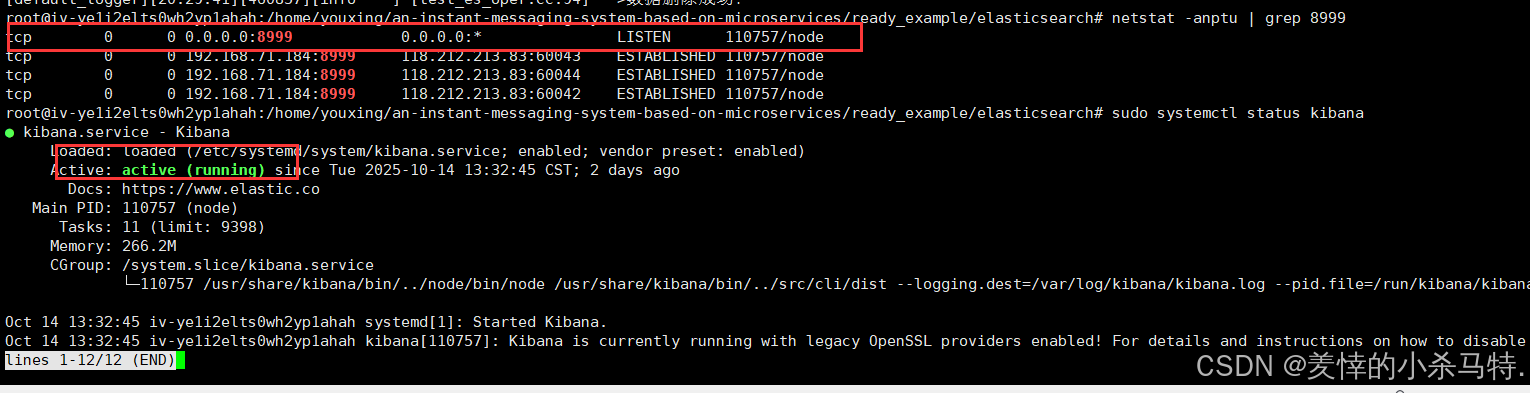
- 监听端口正监听,服务正常运行。
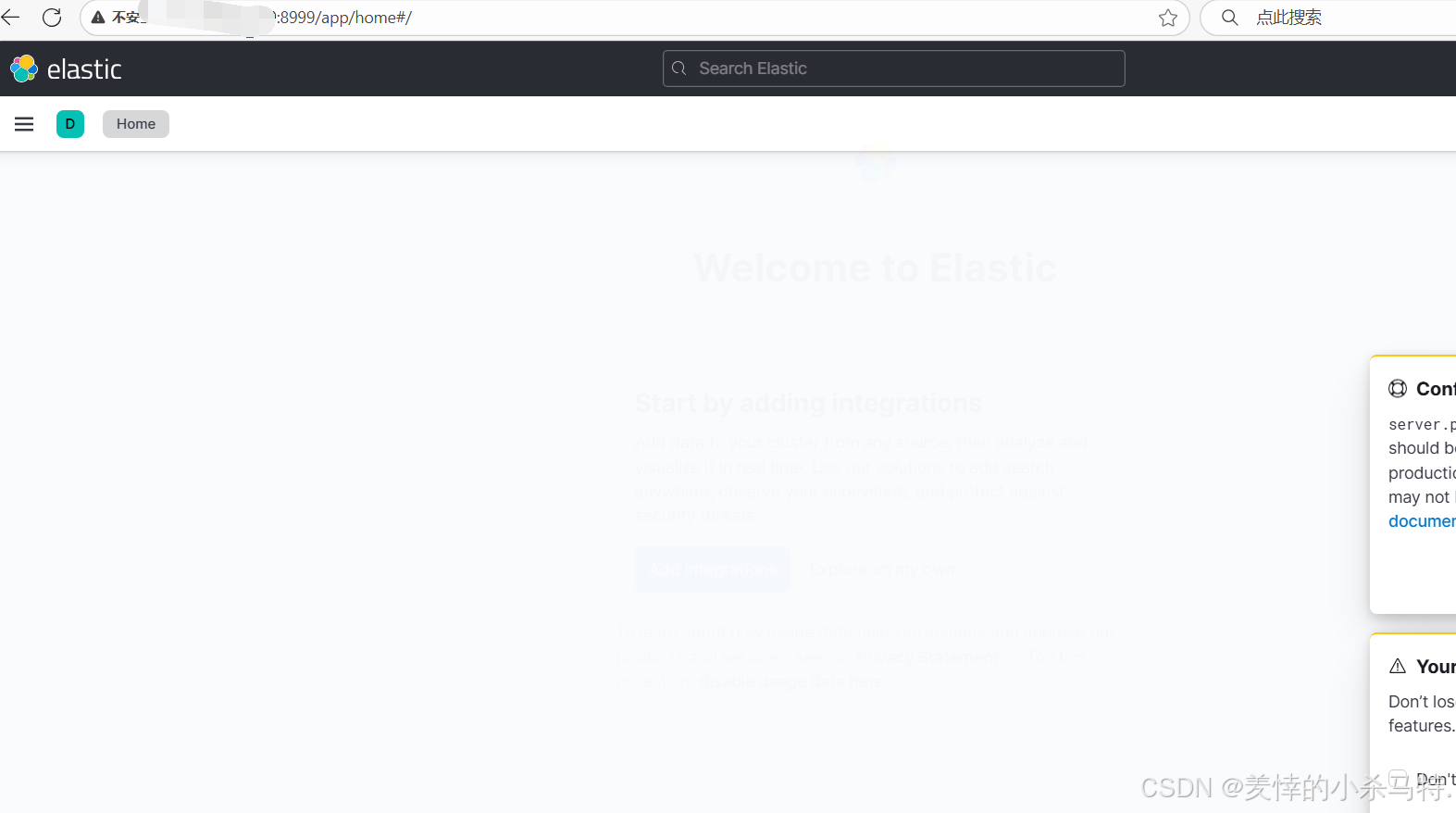
- 下面访问对应的ip+port可以看到kibana服务。
6.kibana-es使用
下面操作下:
- 找到对应kibana能与es服务交互请求与答复的界面。
下面进行创建索引,增删查一下:
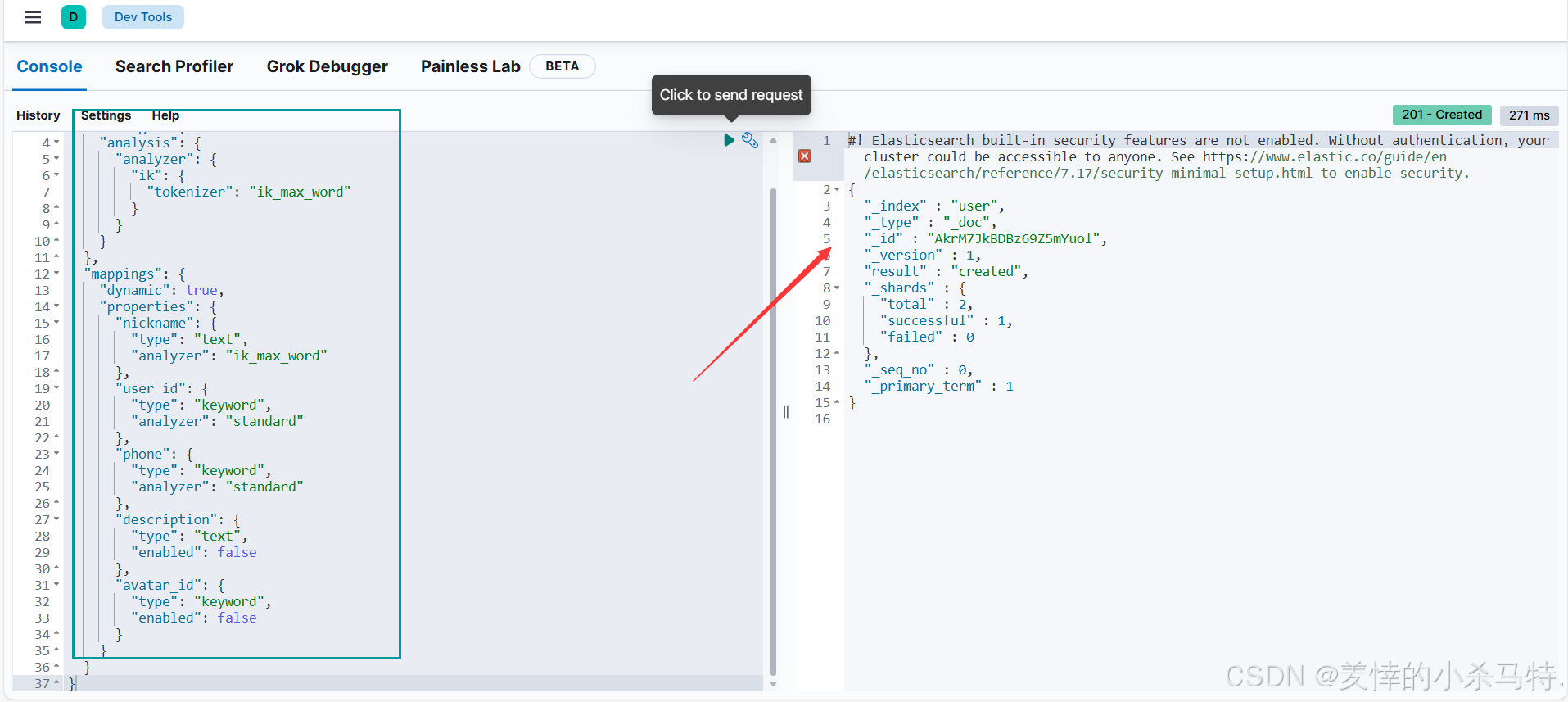
- 构建对应的信息索引类型与映射(可以理解成类似mysql表里的字段但是一个索引只能有一个类型也就是表)。
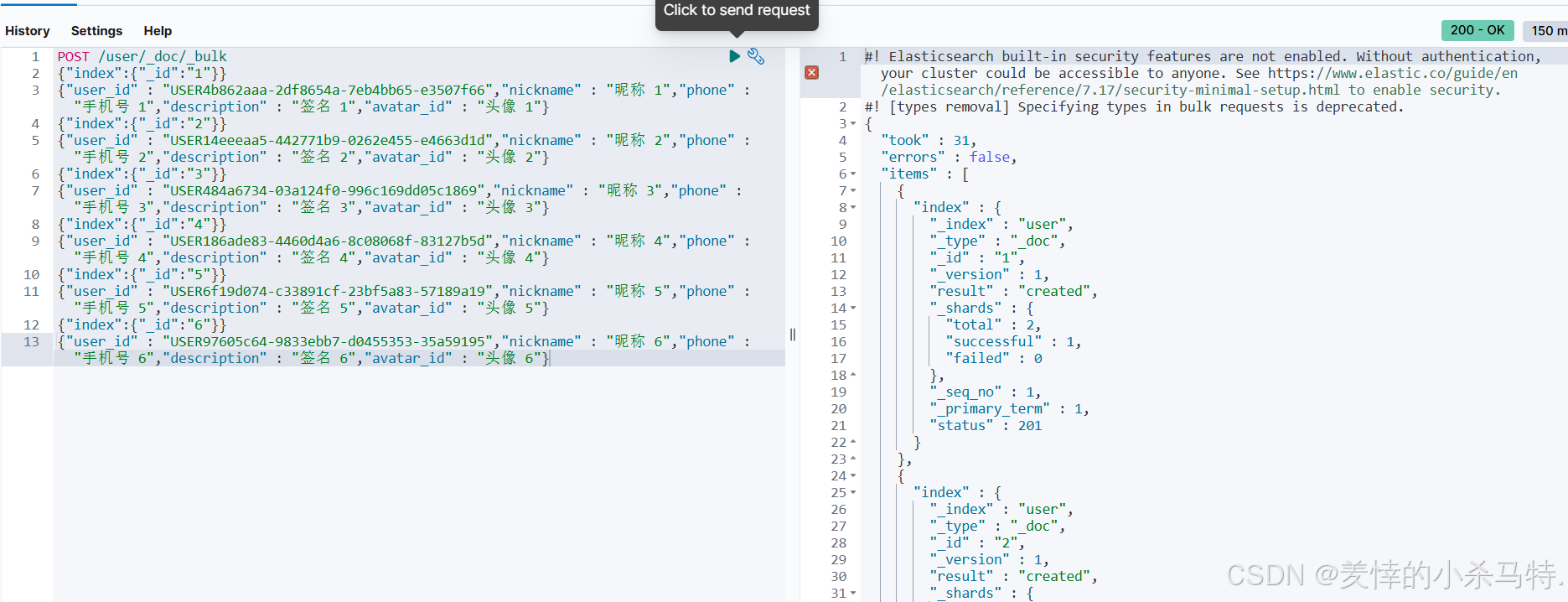
- 成功插入对应数据。
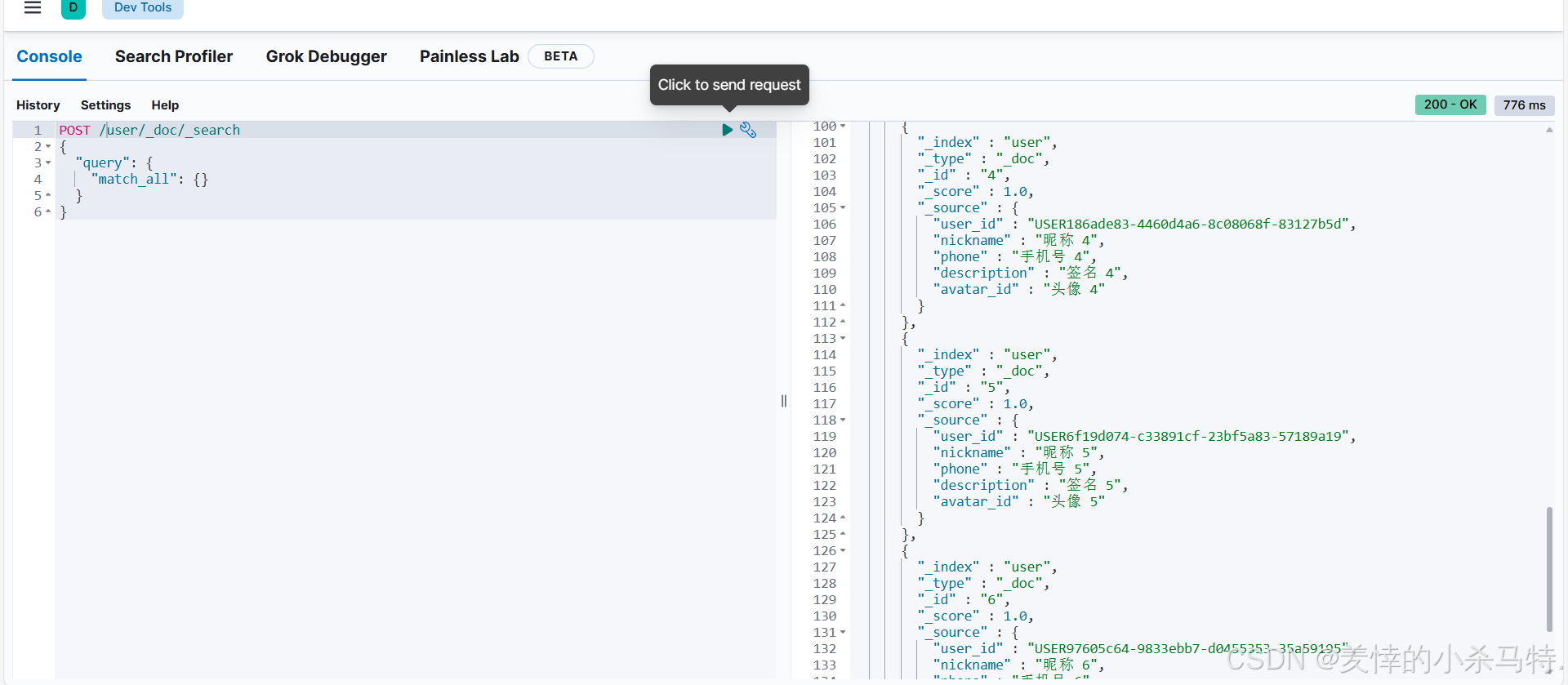
- 进行全量查询。
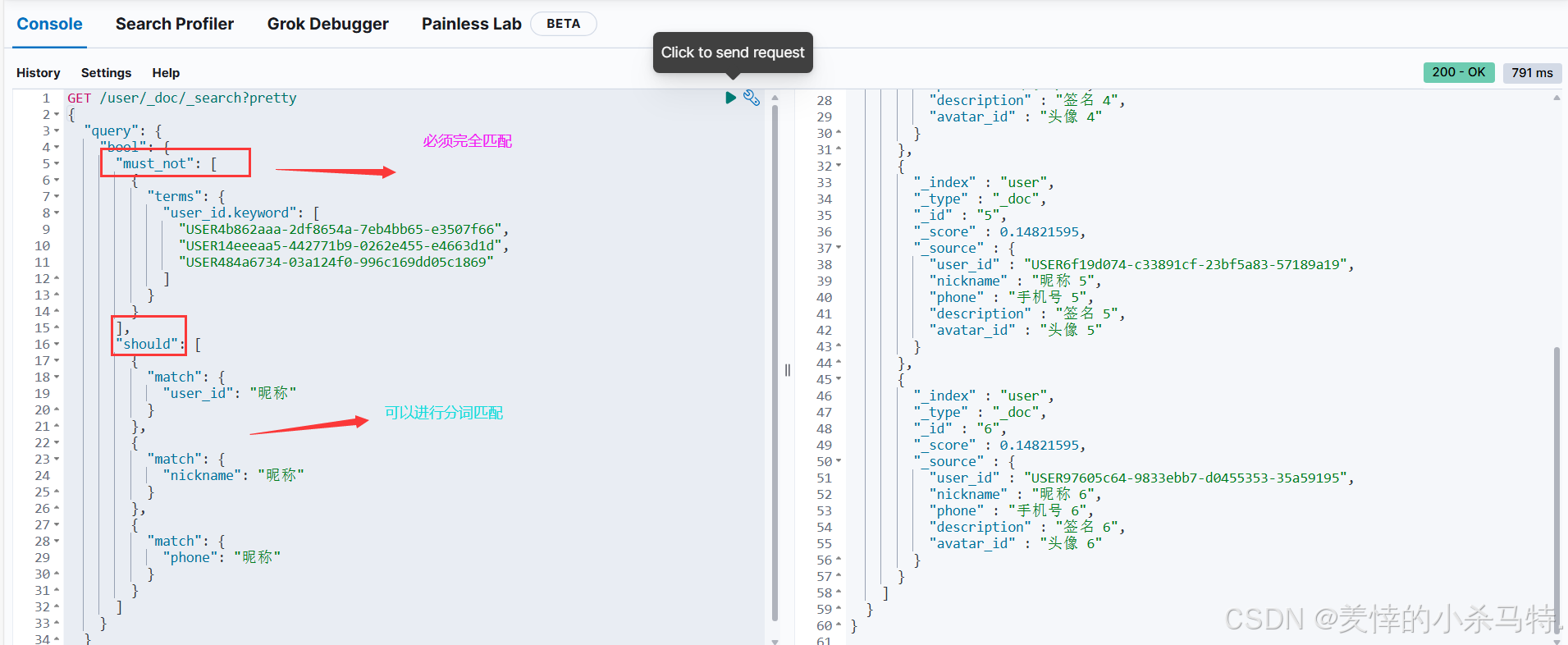
- 按需查询。
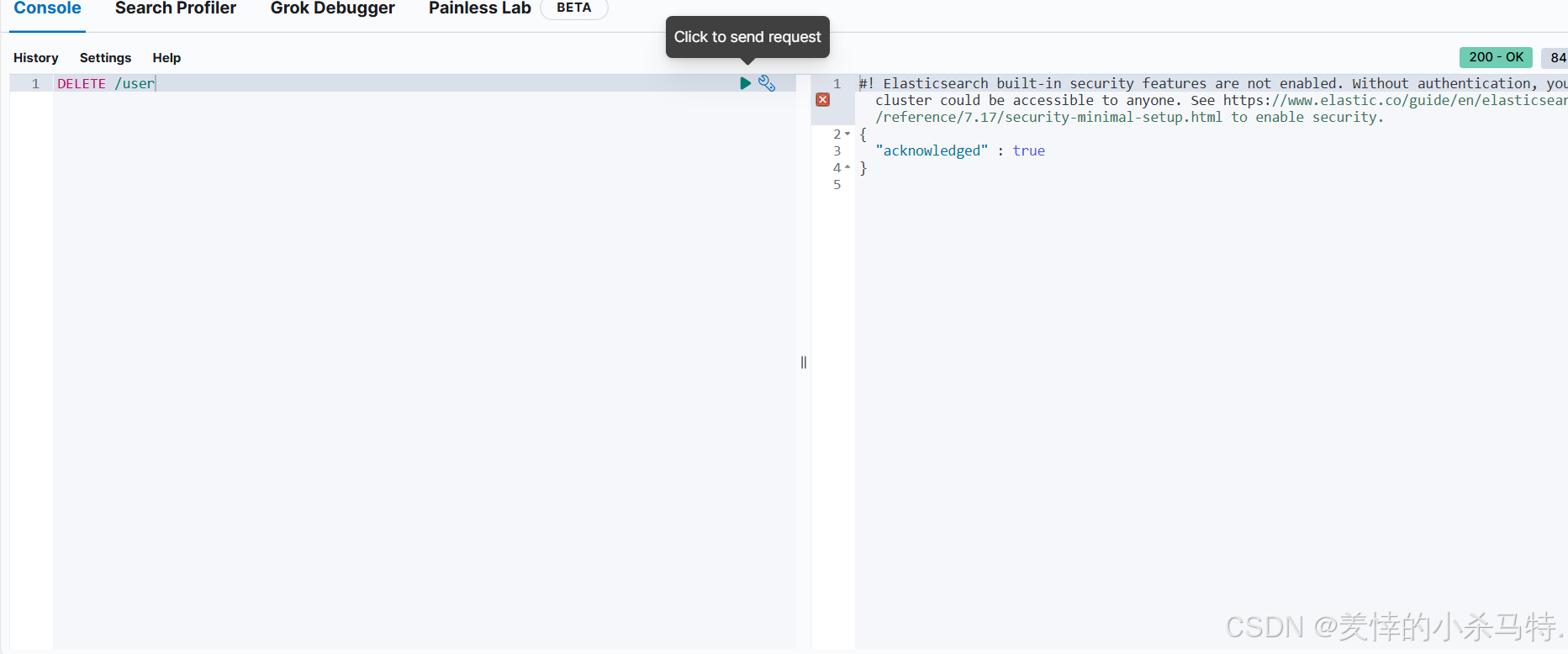
- 成功删除整个索引(这里也可以选择对应插入数据时候的id进行单个删除)。
7.es-client使用及封装使用接口
es接口
1. search - 搜索文档
cpp
cpr::Response search(
const std::string &indexName, // 索引名(如 "users")
const std::string &docType, // 类型(ES 7.x+ 可忽略,传空字符串"")
const std::string &body, // 查询DSL的JSON字符串(如 {"query": {"match_all": {}}})
const std::string &routing // 路由键(可选,默认空)
);作用 :在指定索引中执行搜索查询(类似 SQL 的 SELECT)。
例子:
cpp
// 搜索 users 索引中所有文档
auto response = search("users", "", R"({"query": {"match_all": {}}})");2. get - 获取单个文档
cpp
cpr::Response get(
const std::string &indexName, // 索引名(如 "products")
const std::string &docType, // 类型(ES 7.x+ 可忽略)
const std::string &id, // 文档ID(如 "1")
const std::string &routing // 路由键(可选)
);作用 :根据 ID 获取索引中的特定文档(类似 SQL 的 SELECT * FROM table WHERE id=1)。
例子:
cpp
// 获取 products 索引中 ID 为 "100" 的文档
auto response = get("products", "", "100");3. index - 创建/更新文档
cpp
cpr::Response index(
const std::string &indexName, // 索引名(如 "orders")
const std::string &docType, // 类型(ES 7.x+ 可忽略)
const std::string &id, // 文档ID(如 "2";若为空则ES自动生成)
const std::string &body, // 文档内容的JSON字符串(如 {"name": "Book"})
const std::string &routing // 路由键(可选)
);作用 :向索引中写入或更新一个文档(ID 存在则更新,不存在则创建)。
例子:
cpp
// 插入/更新 orders 索引中 ID 为 "5" 的文档
auto response = index("orders", "", "5", R"({"item": "Laptop", "price": 999})");4. remove - 删除文档
cpp
cpr::Response remove(
const std::string &indexName, // 索引名(如 "logs")
const std::string &docType, // 类型(ES 7.x+ 可忽略)
const std::string &id, // 要删除的文档ID(如 "3")
const std::string &routing // 路由键(可选)
);作用 :根据 ID 删除索引中的文档(类似 SQL 的 DELETE FROM table WHERE id=3)。
例子:
cpp
// 删除 logs 索引中 ID 为 "20240101" 的文档
auto response = remove("logs", "", "20240101");类比 SQL 操作
| ES 接口 | 对应 SQL 操作 | 核心功能 |
|---|---|---|
search |
SELECT ... WHERE ... |
搜索/查询数据 |
get |
SELECT * FROM ... WHERE id=? |
按 ID 精确获取数据 |
index |
INSERT/UPDATE |
写入或更新数据 |
remove |
DELETE |
删除数据 |
这些接口是 Elasticsearch REST API 的 C++ 封装(通过 HTTP 请求库 cpr 实现,也就是说用到的除了elasticsearch库还有cpr库(c++仿照python 的requests库实现的))。
ES 客户端 API 二次封装
封装思想
- 为什么需要封装?
- 方便直接把对应固有的属性特征直接创建好,构建好对应json格式,为用户搞好对应单一添加接口方便操作(比如可以根据用户需要创建对应属性,根据用户需要插入对应数据集合,根据用户选择何种模式进行search完成json序列化与发送及获取应答等。)
封装了四种主要操作:索引创建、数据新增、数据查询、数据删除。
其实就是按照之前kibana演示的发送的格式进行json对象构建,然后用户来调用添加最后进行统一序列化发送+应答接收等。
- 这里每次给这几个类传入的是client对象(构建好的);而不是初始化的时候构建这样为了利用资源充分减少消耗。
- 创建索引发送请求+构建输入进行插入发送请求+分两种情况(分片与不分片)进行匹配查询发送请求+删除指定id的数据进行发送请求的四个类。
封装源码
对应封装的代码:
1·封装功能接口可结合注释看详解:
2封装接口格式依据对应文本请求:
测试效果
测试效果:
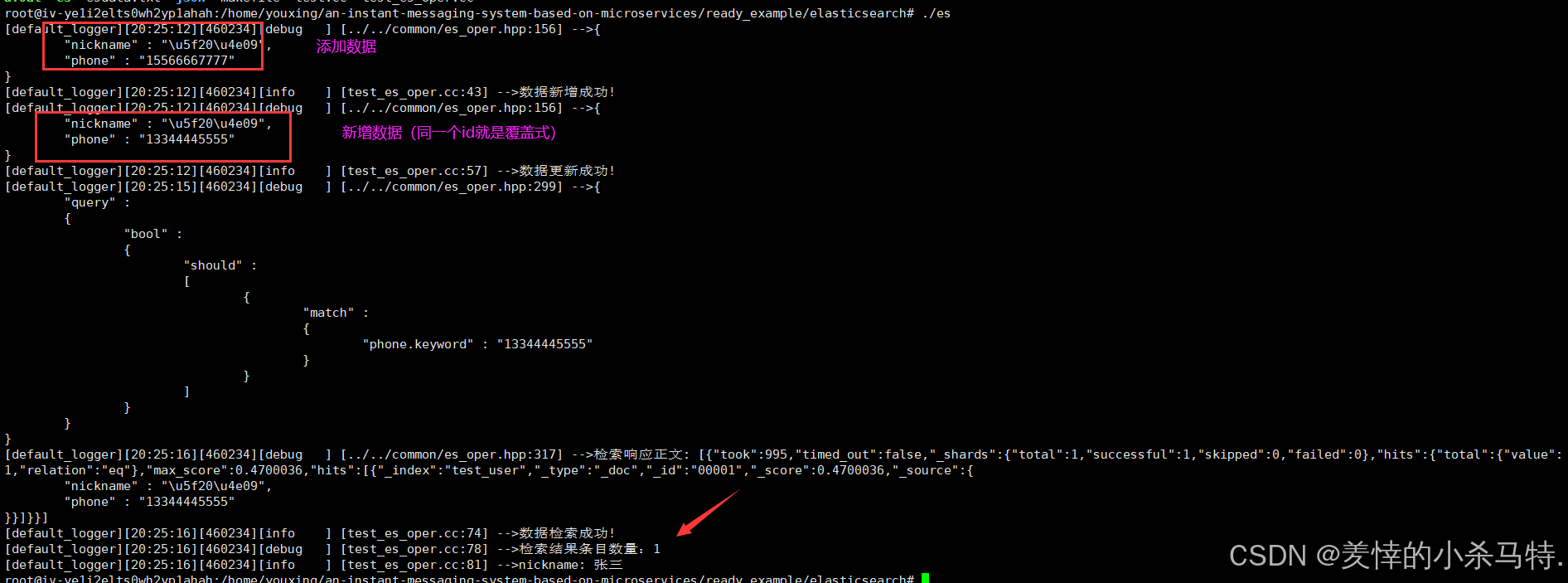

- 这里可以发现对应创建索引/增加数据/修改数据/按需查询数据/删除数据都是正常的(删除的话根据插入的数据id进行删除即可)。
注意:
这里可能会先清空然后再进行新添加对应数据,也就是再新覆盖的时候如果进行查询可能会查到空也就是并发接收请求故可以等它更新完再进行查(采取休眠几秒等待更新完成再次查询)。
测试源码
测试代码:
cpp
#include "../../common/es_oper.hpp"
#include <gflags/gflags.h>
DEFINE_bool(run_mode, false, "程序的运行模式,false-调试; true-发布;");
DEFINE_string(log_file, "", "发布模式下,用于指定日志的输出文件");
DEFINE_int32(log_level, 0, "发布模式下,用于指定日志输出等级");
int main(int argc, char *argv[])
{
google::ParseCommandLineFlags(&argc, &argv, true);
init_logger(FLAGS_run_mode, FLAGS_log_file, FLAGS_log_level);
// 进行客户端够建:
std::vector<std::string> host{"http://127.0.0.1:9200/"};
auto client = std::make_shared<elasticlient::Client>(host);
/////////这里不需要持久对象直接匿名对象向es服务端发送构建完成即可:
// 索引创建
// bool ret = EsIndex(client, "test_user").append("nickname").append("phone", "keyword", "standard", true).create();
// if (ret == false)
// {
// LOG_INFO("索引创建失败!");
// return -1;
// }
// else
// {
// LOG_INFO("索引创建成功!");
// }
// // 数据的新增
bool ret = EsInsertData(client, "test_user")
.append("nickname", "张三")
.append("phone", "15566667777")
.insert("00001");
if (ret == false)
{
LOG_ERROR("数据插入失败!");
return -1;
}
else
{
LOG_INFO("数据新增成功!");
}
// // 数据的修改
ret = EsInsertData(client, "test_user")
.append("nickname", "张三")
.append("phone", "13344445555")
.insert("00001");
if (ret == false)
{
LOG_ERROR("数据更新失败!");
return -1;
}
else
{
LOG_INFO("数据更新成功!");
}
// std::this_thread::sleep_for(std::chrono::seconds(3)); //这里可能会先清空然后再进行新添加对应数据,也就是再新覆盖的时候如果进行查询可能会查到空
//也就是并发接收请求故可以等它更新完再进行查
//////条件数据查询:
Json::Value user = EsSearch(client, "test_user")
.append_should_match("phone.keyword", "13344445555")
// .append_must_not_terms("nickname.keyword", {"张三"})
.search();
if (user.empty() || user.isArray() == false)
{
LOG_ERROR("结果为空,或者结果不是数组类型");
return -1;
}
else
{
LOG_INFO("数据检索成功!");
}
int sz = user.size();
LOG_DEBUG("检索结果条目数量:{}", sz);
for (int i = 0; i < sz; i++)
{
LOG_INFO("nickname: {}", user[i]["_source"]["nickname"].asString());
}
// //进行数据移除操作(id)
// ret = EsRemoveData(client, "test_user").remove("00001");
// if (ret == false)
// {
// LOG_ERROR("删除数据失败");
// return -1;
// }
// else
// {
// LOG_INFO("数据删除成功!");
// }
return 0;
}二.本篇小结
本文以实操为导向,从 ES/Kibana 部署起步,解析其核心组件(索引、文档、映射等),并通过 C++ 封装示例,展示如何通过二次开发简化 ES 操作来为后续项目简化操作。