文章目录
-
- Linux线程概念与控制(一):线程本质与虚拟地址空间
- 一、什么是线程
-
- [1.1 线程的定义](#1.1 线程的定义)
- [1.2 从进程到线程的演进](#1.2 从进程到线程的演进)
- 二、虚拟地址空间与分页机制
-
- [2.1 为什么需要虚拟地址空间](#2.1 为什么需要虚拟地址空间)
-
- [2.1.1 没有虚拟内存的困境](#2.1.1 没有虚拟内存的困境)
- [2.1.2 虚拟内存的解决方案](#2.1.2 虚拟内存的解决方案)
- [2.2 物理内存管理](#2.2 物理内存管理)
-
- [2.2.1 页和页框的概念](#2.2.1 页和页框的概念)
- [2.2.2 struct page结构](#2.2.2 struct page结构)
- [2.3 页表机制详解](#2.3 页表机制详解)
-
- [2.3.1 单级页表的问题](#2.3.1 单级页表的问题)
- [2.3.2 两级页表的设计](#2.3.2 两级页表的设计)
- [2.4 地址转换全流程](#2.4 地址转换全流程)
-
- [2.4.1 MMU的工作流程](#2.4.1 MMU的工作流程)
- [2.4.2 TLB快表优化](#2.4.2 TLB快表优化)
- [2.5 缺页异常](#2.5 缺页异常)
-
- [2.5.1 什么是缺页异常](#2.5.1 什么是缺页异常)
- [2.5.2 缺页异常的类型](#2.5.2 缺页异常的类型)
- 三、线程的优缺点
-
- [3.1 线程的优点](#3.1 线程的优点)
- [3.2 线程的缺点](#3.2 线程的缺点)
- [3.3 线程异常](#3.3 线程异常)
- [3.4 线程的用途](#3.4 线程的用途)
- 四、进程vs线程深入对比
-
- [4.1 资源分配与调度](#4.1 资源分配与调度)
- [4.2 线程私有的资源](#4.2 线程私有的资源)
- [4.3 线程共享的进程资源](#4.3 线程共享的进程资源)
- [4.4 理解"单线程进程"](#4.4 理解"单线程进程")
- 五、本篇总结
- 六、承上启下
Linux线程概念与控制(一):线程本质与虚拟地址空间
💬 开篇引入:在前面的进程学习中,我们已经掌握了进程的概念、创建、终止、等待等知识。但实际开发中,我们常常听到"多线程编程"这个词。线程到底是什么?它和进程有什么区别?为什么需要线程?更重要的是,线程究竟在进程的哪里运行?本篇将从最基础的线程概念出发,深入剖析虚拟地址空间与分页机制,为后续理解线程的地址空间布局打下坚实基础!
👍 学习目标:本篇是线程系列的第一篇,我们将理解线程的本质、掌握虚拟地址空间的分页机制、理解页表的工作原理、了解线程与进程的区别与联系。这些都是理解后续线程控制API的理论基础!
🚀 循序渐进:本篇从零开始,不需要线程的前置知识,但需要你掌握基本的进程概念。
一、什么是线程
1.1 线程的定义
在深入学习线程之前,我们先来看一个简单的定义:
bash
线程(thread):在一个程序里的一个执行路线
更准确的定义:线程是"一个进程内部的控制序列"这个定义可能有点抽象,我们用一个生活中的例子来理解:
bash
把进程比作一个工厂:
- 工厂有厂房、设备、原材料(进程的资源)
- 工厂里的工人就是线程(执行流)
一个工厂可以有多个工人同时工作:
- 工人A在车间1生产零件
- 工人B在车间2组装产品
- 工人C在仓库管理物料
这些工人共享工厂的资源(厂房、设备、原材料)
但每个工人有自己的工作台(线程栈)、工具(寄存器)📌 核心理解:
bash
1. 一切进程至少都有一个执行线程(主线程)
- 单线程进程:只有main函数这一个执行流
- 多线程进程:除了main函数,还有其他执行流
2. 线程在进程内部运行,本质是在进程地址空间内运行
- 线程不能脱离进程单独存在
- 线程共享进程的大部分资源
3. 在Linux系统中,线程的实现比较特殊
- CPU眼中看到的PCB都是轻量级进程(LWP)
- Linux不严格区分进程和线程1.2 从进程到线程的演进
让我们回顾一下进程的概念,这样更容易理解线程:
进程的特点:
bash
优点:
1. 进程之间相互独立,互不干扰
2. 进程崩溃不会影响其他进程
3. 资源隔离性好,安全性高
缺点:
1. 创建进程开销大(需要复制父进程的资源)
2. 进程间通信复杂(需要管道、共享内存等)
3. 进程切换开销大(需要切换地址空间)正是因为进程的这些缺点,线程应运而生:
线程的设计目标:
bash
1. 保留进程的并发执行能力
2. 降低创建和切换的开销
3. 简化"进程"间的通信(同一进程内的线程共享资源)二、虚拟地址空间与分页机制
💡 重要提示:要理解线程在哪里运行,必须先深刻理解进程的虚拟地址空间!这一节是整篇文章的核心基础,请务必耐心阅读。
2.1 为什么需要虚拟地址空间
2.1.1 没有虚拟内存的困境
假设没有虚拟内存和分页机制,每个程序在物理内存上的空间必须是连续的:
bash
物理内存(4GB):
┌─────────────────────────────────┐
│ 程序A(100MB) │ 0x00000000 - 0x06400000
├─────────────────────────────────┤
│ 程序B(200MB) │ 0x06400000 - 0x12C00000
├─────────────────────────────────┤
│ 程序C(50MB) │ 0x12C00000 - 0x15E00000
├─────────────────────────────────┤
│ 空闲(3650MB) │ 0x15E00000 - 0xFFFFFFFF
└─────────────────────────────────┘这种方式会带来严重的问题:
bash
问题1: 内存碎片
- 程序B退出后,中间留下200MB的空洞
- 如果新程序需要250MB连续空间,就无法使用这个空洞
- 即使总空闲内存够,但不连续就无法使用
问题2: 地址冲突
- 每个程序编译时不知道自己会被加载到哪里
- 程序A的代码可能写着"跳转到地址0x1000"
- 但0x1000可能已经被其他程序占用
问题3: 没有保护
- 程序A可以直接访问程序B的内存
- 恶意程序可以随意读写其他程序的数据2.1.2 虚拟内存的解决方案
为了解决这些问题,操作系统引入了虚拟内存 和分页机制:
bash
核心思想:
1. 给每个进程提供连续的虚拟地址空间(0 ~ 4GB on 32位)
2. 把物理内存按固定大小(4KB)切分成页框(Page Frame)
3. 把虚拟地址空间也按4KB切分成页(Page)
4. 通过页表建立虚拟页到物理页框的映射
好处:
✓ 每个进程看到的都是连续的地址空间
✓ 物理内存可以是离散的,解决碎片问题
✓ 不同进程的虚拟地址可以映射到不同物理地址,实现隔离示意图:
bash
进程A的虚拟地址空间 物理内存
┌────────────────┐ ┌────────────┐
│ 0x00000000 │ │ 页框0 │
│ 0x00001000 ───┼──────────→│ 页框1 │
│ 0x00002000 ───┼─────┐ │ 页框2 │
│ 0x00003000 │ │ │ 页框3 ←──┼─┐
│ ... │ │ │ 页框4 │ │
│ 0xFFFFFFFF │ │ │ 页框5 ←──┼─┤
└────────────────┘ │ │ ... │ │
│ └────────────┘ │
进程B的虚拟地址空间 │ │
┌────────────────┐ │ │
│ 0x00000000 │ │ │
│ 0x00001000 ───┼─────┤ │
│ 0x00002000 ───┼─────┘ │
│ ... │ │
└────────────────┘
两个进程的虚拟地址0x00001000映射到不同的物理页框
实现了地址空间的隔离!2.2 物理内存管理
2.2.1 页和页框的概念
bash
页框(Page Frame):
- 物理内存按固定长度划分的存储区域
- 在32位系统中,通常是4KB
- 页框是物理内存的最小分配单位
页(Page):
- 虚拟地址空间按固定长度划分的数据块
- 大小等于页框(4KB)
- 页可以存放在任何页框或磁盘中
重要区分:
- 页框是"容器"(物理内存中的位置)
- 页是"内容"(虚拟地址空间的数据)计算页框数量:
bash
假设物理内存有4GB:
页框大小 = 4KB = 4096 Bytes
页框数量 = 4GB / 4KB
= 4 * 1024 * 1024 KB / 4KB
= 1048576 个页框
= 1M 个页框2.2.2 struct page结构
操作系统需要管理这么多页框,Linux内核用struct page结构表示每个物理页:
c
/* 简化版的 struct page */
struct page {
unsigned long flags; // 页的状态标志
atomic_t _mapcount; // 页表映射计数
void *virtual; // 虚拟地址(如果已映射)
// 页可能在不同的链表中
struct list_head lru; // 用于页面回收
struct address_space *mapping;// 页的所有者
pgoff_t index; // 在文件中的偏移
// ... 更多字段
};📌 关键理解:
bash
1. 每个物理页框都有一个struct page结构来描述
2. 这个结构本身也要占用内存
计算开销:
- 假设struct page占40字节
- 1M个页框需要 1048576 * 40 = 40MB
- 相对于4GB内存,只占1%,代价可以接受
3. flags字段记录页的状态:
- PG_locked: 页是否被锁定
- PG_uptodate: 页数据是否有效
- PG_dirty: 页是否被修改过
4. _mapcount记录有多少个页表项指向这个页
- -1表示没有人使用,可以回收
- >= 0表示正在被使用2.3 页表机制详解
2.3.1 单级页表的问题
有了物理页框的管理,接下来需要建立虚拟地址到物理地址的映射,这就是页表的作用。
我们先看最简单的单级页表:
bash
32位系统的虚拟地址空间: 4GB = 2^32 字节
页的大小: 4KB = 2^12 字节
需要的页表项数量: 2^32 / 2^12 = 2^20 = 1048576 项
每个页表项占4字节(存储物理页框号)
页表总大小: 1048576 * 4 = 4MB单级页表结构:
bash
虚拟地址(32位):
┌────────────────────┬────────────────┐
│ 页号(20位) │ 页内偏移(12位) │
└────────────────────┴────────────────┘
页表:
┌────────┬──────────────────┐
│ 索引 │ 物理页框号 │
├────────┼──────────────────┤
│ 0 │ 0x12345 │ ← 虚拟页0映射到物理页框0x12345
│ 1 │ 0xABCDE │
│ 2 │ 0x67890 │
│ ... │ ... │
│1048575 │ 0x11111 │
└────────┴──────────────────┘
地址转换:
1. 取虚拟地址的高20位作为页号
2. 在页表中查找页号对应的物理页框号
3. 物理地址 = 物理页框号 << 12 | 页内偏移在这里插入图片描述
单级页表的问题:
bash
问题1: 需要连续的物理内存
- 4MB的页表需要1024个连续的物理页框
- 这和我们引入分页机制的初衷矛盾!
问题2: 空间浪费
- 大部分程序只使用很小一部分虚拟地址空间
- 例如只用了10MB,实际只需要3个页表项
- 但必须分配完整的4MB页表,浪费严重
问题3: 无法按需分配
- 程序启动时就要分配全部页表
- 不能随着程序运行动态增长2.3.2 两级页表的设计
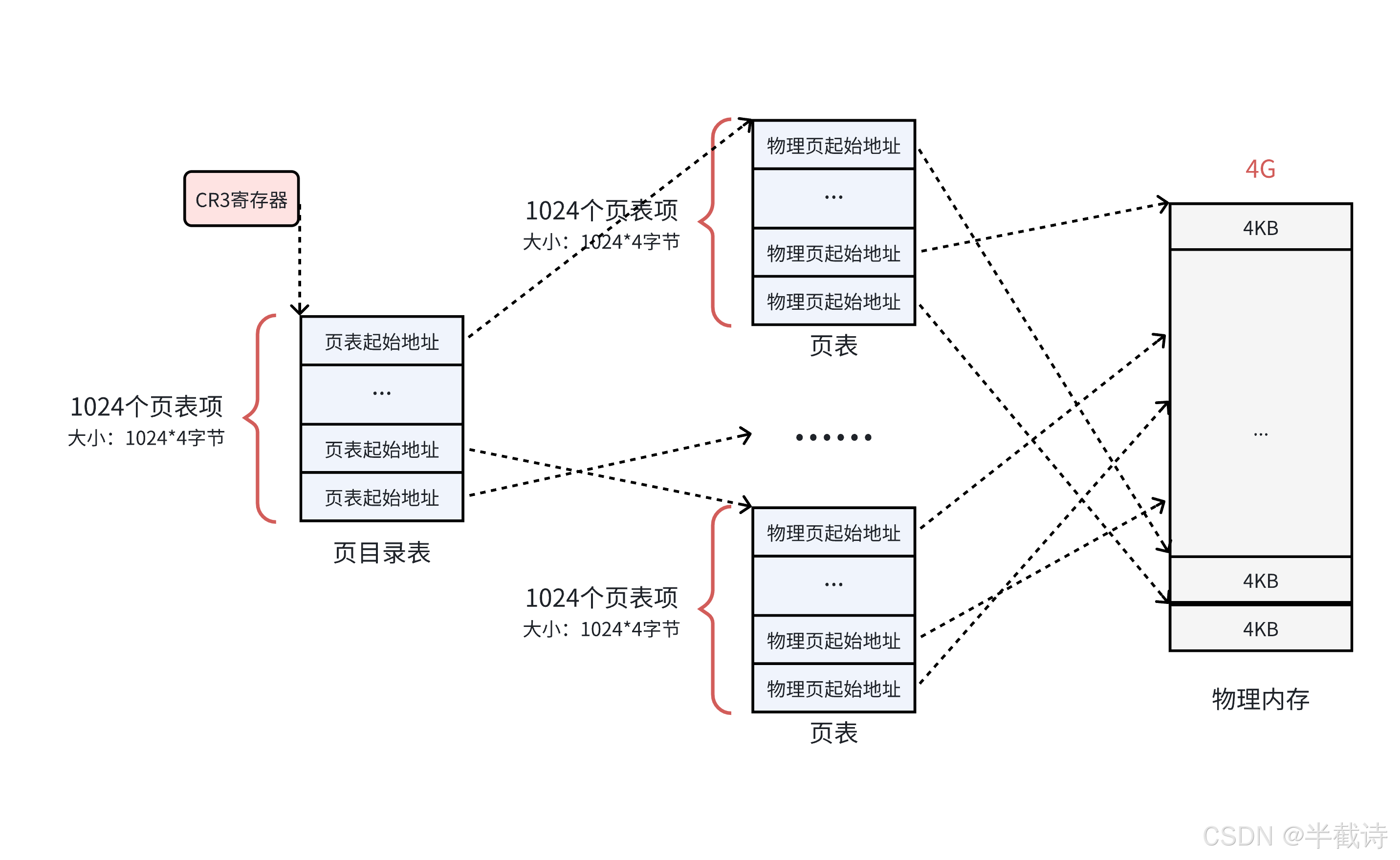
为了解决单级页表的问题,引入两级页表 :
bash
核心思想:
把4MB的大页表拆分成1024个小页表,每个小页表4KB
1024个小页表 * 4KB = 4MB (总容量不变)
但现在可以:
1. 按需分配小页表(程序用多少分配多少)
2. 小页表可以离散存放(每个只需要连续的4KB)
3. 用一个页目录表来管理这1024个小页表两级页表结构
text
页目录表(Page Directory):
┌────────┬──────────────────┐
│ 索引 │ 页表物理地址 │
├────────┼──────────────────┤
│ 0 │ 页表0的地址 │
│ 1 │ 页表1的地址 │
│ 2 │ NULL(未分配) │
│ ... │ ... │
│ 1023 │ NULL(未分配) │
└────────┴──────────────────┘
↑
│
CR3 寄存器指向页目录表虚拟地址结构(32 位,两级页表)
text
┌────────────┬────────────┬─────────────┐
│一级页号(10)│二级页号(10)│页内偏移(12) │
└────────────┴────────────┴─────────────┘
页目录索引 页表索引 字节偏移示例:虚拟地址 0x00401234
1️⃣ 转成二进制(32 位)
bash
00000000 01000000 00010010 00110100按 10-10-12 划分:
bash
0000000001 | 0000000001 | 001000110100
↑ ↑ ↑
一级页号=1 二级页号=1 页内偏移=0x2342️⃣ 地址转换过程
text
一级页号 = 1
→ 查页目录表[1]
→ 得到 页表1 的物理地址
二级页号 = 1
→ 查页表1[1]
→ 得到 物理页框号
页内偏移 = 0x234
物理地址 = (物理页框号 << 12) | 0x234📌 两级页表的优势:
bash
优势1: 按需分配
- 10MB的程序只需要3个页表(12KB)
- 不需要的虚拟地址区域,对应的页表根本不分配
优势2: 离散存储
- 每个页表只需要连续的4KB
- 页目录也只需要4KB
- 容易在物理内存中找到空间
优势3: 节省内存
- 大部分进程使用的虚拟地址空间很小
- 实际分配的页表远小于4MB
计算示例:
程序占用10MB虚拟地址空间
需要的虚拟页数 = 10MB / 4KB = 2560页
需要的二级页表 = 2560 / 1024 ≈ 3个
内存开销 = 3 * 4KB + 4KB(页目录) = 16KB
(相比单级页表的4MB,节省了99.6%!)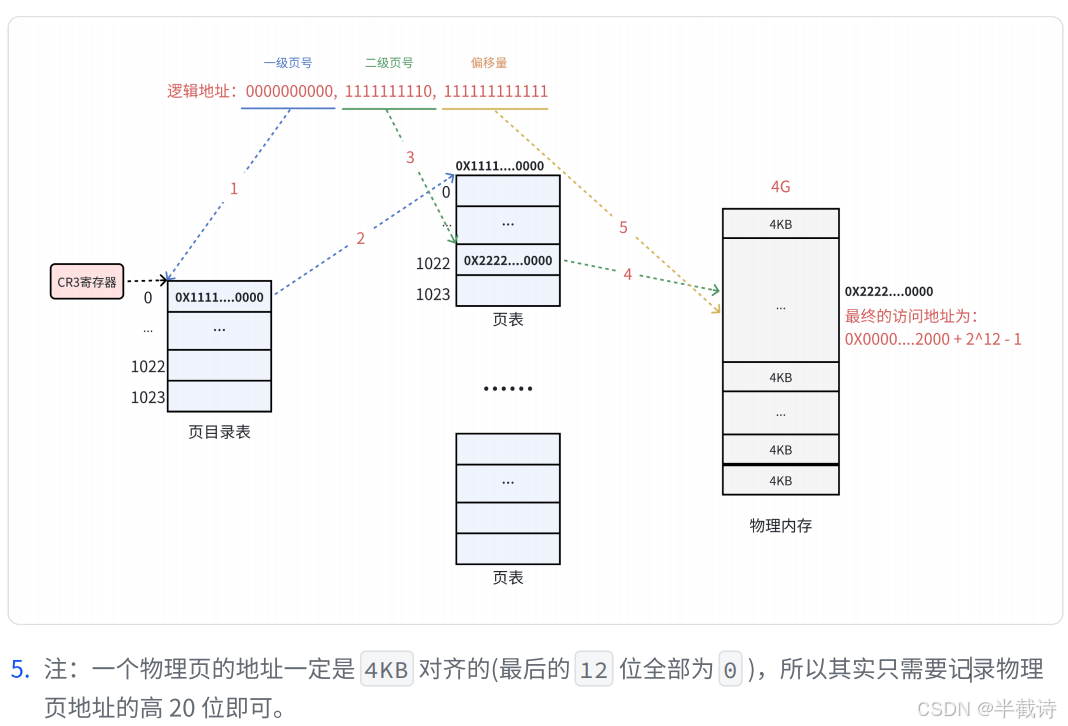
2.4 地址转换全流程
2.4.1 MMU的工作流程
MMU(Memory Management Unit,内存管理单元)是硬件电路,负责地址转换:
bash
虚拟地址 → MMU → 物理地址
步骤1: CPU发出虚拟地址
├─ 从指令中获取,或计算得到
└─ 例如: 0x00401234
步骤2: MMU从CR3寄存器获取页目录基址
├─ CR3存储当前进程的页目录物理地址
└─ 每个进程有独立的页目录
步骤3: 提取一级页号,查页目录
├─ 一级页号 = 虚拟地址[31:22]
├─ 页目录项地址 = CR3 + 一级页号 * 4
└─ 读取得到二级页表的物理地址
步骤4: 提取二级页号,查页表
├─ 二级页号 = 虚拟地址[21:12]
├─ 页表项地址 = 页表基址 + 二级页号 * 4
└─ 读取得到物理页框号
步骤5: 组合物理地址
├─ 页内偏移 = 虚拟地址[11:0]
└─ 物理地址 = (物理页框号 << 12) | 页内偏移
步骤6: 发送到总线,访问物理内存完整示例:
bash
虚拟地址: 0x00401234
二进制: 0000000001 0000000001 001000110100
步骤1: 一级页号 = 0x001 = 1
CR3 = 0x10000(假设)
页目录项地址 = 0x10000 + 1 * 4 = 0x10004
读取 [0x10004] = 0x20000 (二级页表地址)
步骤2: 二级页号 = 0x001 = 1
页表项地址 = 0x20000 + 1 * 4 = 0x20004
读取 [0x20004] = 0x12345 (物理页框号)
步骤3: 页内偏移 = 0x234
物理地址 = 0x12345000 | 0x234 = 0x12345234
步骤4: 访问物理地址0x123452342.4.2 TLB快表优化
你可能注意到,每次地址转换需要访问内存2次(页目录+页表),这会严重影响性能!
TLB(Translation Lookaside Buffer)是MMU内置的缓存,用来加速地址转换:
bash
TLB的工作原理:
┌─────────────────────────────────┐
│ 虚拟页号 │ 物理页框号 │ 权限│
├─────────────────────────────────┤
│ 0x00401 │ 0x12345 │ RW │
│ 0x00402 │ 0xABCDE │ RW │
│ 0x7FFFF │ 0x66666 │ RW │
│ ... │ ... │ ... │
└─────────────────────────────────┘
地址转换流程(带TLB):
1. MMU收到虚拟地址
2. 查TLB(非常快,几个时钟周期)
├─ TLB命中 → 直接得到物理地址,完成!
└─ TLB未命中 → 查页表(慢,几十个时钟周期)
└─ 更新TLB,下次就快了
TLB的特点:
✓ 容量小(几十到几百项)
✓ 速度快(硬件实现)
✓ 基于局部性原理(程序倾向于访问相近的地址)
✓ 命中率高(通常>95%)2.5 缺页异常
2.5.1 什么是缺页异常
当MMU在TLB和页表中都找不到虚拟地址对应的物理页时,就会触发缺页异常(Page Fault):
bash
触发条件:
1. 页表项不存在(虚拟页没有映射到物理页)
2. 页表项存在但权限不足(如写只读页)
3. 页被换出到磁盘(Swap)2.5.2 缺页异常的类型
1. 硬缺页(Hard Page Fault / Major Page Fault):
bash
物理内存中没有对应的页,需要从磁盘读取
处理流程:
1. 暂停当前进程
2. 分配一个空闲的物理页框
3. 从磁盘读取数据到物理页框
4. 更新页表,建立映射
5. 恢复进程执行
特点: 开销大(涉及磁盘I/O,毫秒级)2. 软缺页(Soft Page Fault / Minor Page Fault):
bash
物理内存中已经有这个页,只是当前进程的页表没有建立映射
典型场景:
- 多个进程共享同一个页(如共享库代码段)
- 进程A已经把页读入内存
- 进程B访问时,只需要建立映射即可
处理流程:
1. 找到已存在的物理页
2. 更新页表,建立映射
3. 恢复进程执行
特点: 开销小(只需更新页表,微秒级)3. 无效缺页(Invalid Page Fault):
bash
访问非法地址,如:
- 空指针解引用
- 数组越界
- 栈溢出
处理:
内核发送SIGSEGV信号给进程 → 段错误,进程终止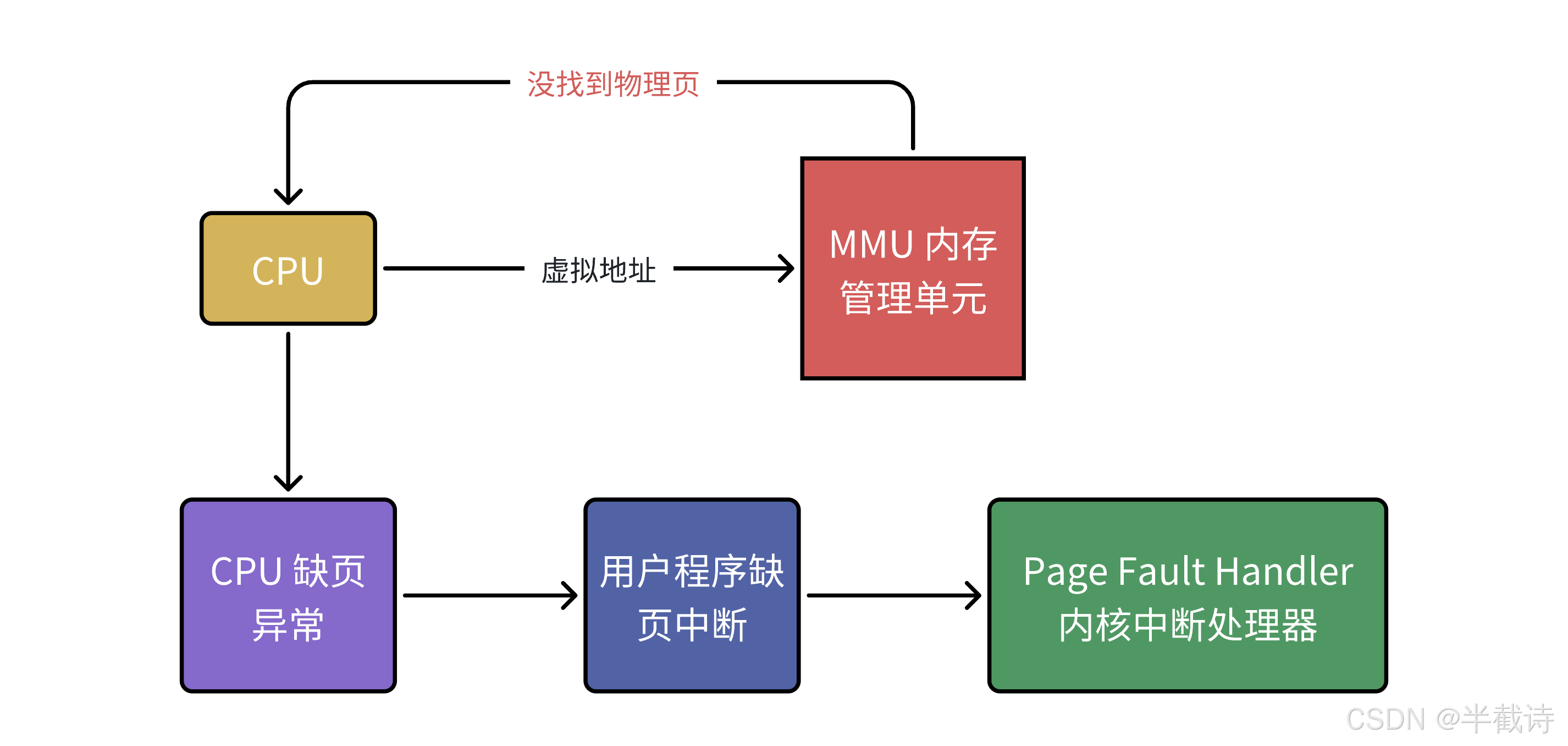
三、线程的优缺点
理解了虚拟地址空间后,我们回到线程本身。线程作为进程的轻量级替代方案,有哪些优缺点呢?
3.1 线程的优点
优点1: 创建开销小
bash
进程创建:
- fork需要复制父进程的资源(代码段、数据段、堆、栈)
- 复制页表
- 分配新的PID
- 开销: 毫秒级
线程创建:
- 只需要分配线程栈和TCB(线程控制块)
- 共享进程的地址空间,无需复制
- 开销: 微秒级
创建速度: 线程 >> 进程优点2: 切换开销小
bash
进程切换:
1. 保存当前进程的寄存器状态
2. 切换页表(CR3寄存器)
3. 刷新TLB(因为地址空间变了)
4. 刷新CPU缓存(Cache失效)
5. 加载新进程的寄存器状态
线程切换:
1. 保存当前线程的寄存器状态
2. 加载新线程的寄存器状态
(无需切换页表和TLB,因为共享地址空间!)
切换速度: 线程切换 > 进程切换优点3: 占用资源少
bash
进程:
- 独立的地址空间(页目录+页表)
- 独立的文件描述符表
- 独立的信号处理表
- ...
线程:
- 共享地址空间
- 共享文件描述符表
- 共享信号处理表
- 只需要私有的栈、寄存器、线程ID
资源占用: 线程 << 进程优点4: 通信简单
bash
进程间通信:
- 需要使用管道、共享内存、消息队列等
- 需要内核介入
- 效率低
线程间通信:
- 直接访问共享的全局变量
- 无需内核介入
- 效率高
通信效率: 线程 >> 进程优点5: 充分利用多核CPU
bash
单进程:
- 只能跑在一个CPU核心上
- 其他核心闲置,浪费
多线程:
- 不同线程可以并行在不同核心上
- 充分利用多核CPU的计算能力
并行能力: 多线程 > 单进程优点6: 提升程序响应性
bash
单线程程序:
- 执行耗时操作(如网络I/O)时,整个程序阻塞
- 用户体验差
多线程程序:
- 一个线程负责I/O,另一个线程处理用户交互
- 即使I/O阻塞,界面仍然响应
响应性: 多线程 > 单线程3.2 线程的缺点
缺点1: 性能损失
bash
场景: 计算密集型任务,线程数 > CPU核心数
问题:
- 多个线程竞争CPU,频繁切换
- 切换带来额外的调度开销
- 可用计算资源不变,开销却增加了
结论: 线程不是越多越好!缺点2: 健壮性降低
bash
进程模型:
- 进程A崩溃,不影响进程B
- 系统整体稳定性高
线程模型:
- 一个线程崩溃(如野指针、除零),整个进程终止
- 所有线程都会受影响
- 需要更谨慎的编程
健壮性: 进程 > 线程缺点3: 缺乏访问控制
bash
进程:
- 每个进程有独立的地址空间
- 一个进程无法直接访问另一个进程的数据
- 安全性高
线程:
- 同一进程内的所有线程共享地址空间
- 任何线程都能访问其他线程的栈(虽然不推荐)
- 线程调用某些系统调用会影响整个进程
访问控制: 进程 > 线程缺点4: 编程难度高
bash
单线程:
- 逻辑简单,顺序执行
- 容易调试
多线程:
- 需要考虑同步问题(竞态条件、死锁)
- 需要考虑数据共享问题
- 调试困难(bug不易重现)
- 时间相关的bug很难定位
开发成本: 多线程 >> 单线程3.3 线程异常
bash
★★★ 重要特性 ★★★
单个线程如果出现异常(除零、野指针等),整个进程都会崩溃!
原因:
1. 线程是进程的执行分支
2. 线程出异常 = 进程出异常
3. 触发信号机制,终止进程
4. 进程终止 → 该进程内的所有线程随即退出
示例:
进程有3个线程:
- 线程A、线程B正常运行
- 线程C访问了空指针 → SIGSEGV信号
- 整个进程收到SIGSEGV → 终止
- 线程A、B、C全部退出3.4 线程的用途
bash
适用场景1: CPU密集型程序
- 科学计算、图像处理、视频编码等
- 利用多核CPU并行计算
- 线程数 ≈ CPU核心数
适用场景2: I/O密集型程序
- Web服务器、数据库、网络爬虫
- 一个线程等待I/O时,其他线程继续执行
- 提升整体吞吐量
适用场景3: 提升用户体验
- GUI程序:界面线程 + 后台任务线程
- 下载工具:下载线程 + 界面线程
- 游戏:渲染线程 + 逻辑线程 + 音频线程四、进程vs线程深入对比
4.1 资源分配与调度
bash
进程:
- 资源分配的基本单位
- 拥有独立的地址空间、文件描述符表等
线程:
- 调度的基本单位
- 共享进程资源,只拥有少量私有资源形象比喻:
bash
把操作系统比作一个公司:
进程 = 部门
- 公司给每个部门分配资源(办公室、设备、预算)
- 部门之间相对独立
线程 = 部门内的员工
- 员工共享部门资源(办公室、设备)
- 员工有自己的工位(线程栈)
- 公司的调度对象是员工(线程),而不是部门(进程)4.2 线程私有的资源
虽然线程共享进程的大部分资源,但线程也有自己的私有数据:
bash
1. 线程ID (tid)
- 在进程内唯一标识线程
- pthread_self()获取
2. 寄存器组
- PC(程序计数器):下一条指令的地址
- SP(栈指针):线程栈的栈顶
- 通用寄存器:eax、ebx等
3. 线程栈
- 每个线程有独立的栈空间
- 存储局部变量、函数调用信息
- 主线程栈在进程栈区
- 其他线程栈在共享区(后续文章详解)
4. errno变量
- 错误码
- 每个线程独立的errno
5. 信号屏蔽字
- 每个线程可以独立屏蔽某些信号
6. 调度优先级
- 可以为每个线程设置不同的优先级4.3 线程共享的进程资源
bash
1. 地址空间
- 代码段(Text Segment):程序指令
- 数据段(Data Segment):全局变量、静态变量
- 堆(Heap):malloc分配的内存
- 共享库(Shared Libraries)
2. 文件描述符表
- 所有线程共享打开的文件
- 一个线程打开文件,其他线程都能访问
3. 信号处理方式
- SIG_IGN(忽略)
- SIG_DFL(默认)
- 自定义信号处理函数
4. 当前工作目录
- 所有线程的cwd相同
- 一个线程chdir,影响所有线程
5. 用户ID和组ID
- uid、gid、euid、egid
6. 进程ID
- 所有线程的pid相同用图示理解:
bash
进程地址空间:
┌─────────────────────────────────┐
│ 内核空间(1GB) │
├─────────────────────────────────┤ ← 0xC0000000
│ │
│ 栈区(主线程栈) │ ← 向下增长
│ ↓ │
│ │
│ ─────────────────────────────── │
│ │
│ 共享区(线程2栈) │ ← 线程栈在这里!
│ 共享区(线程3栈) │
│ 共享库、mmap区域 │
│ │
│ ↑ │
│ 堆区 │ ← 向上增长
│ │
├─────────────────────────────────┤
│ .bss段(未初始化全局变量) │
├─────────────────────────────────┤
│ .data段(已初始化全局变量) │
├─────────────────────────────────┤
│ .rodata段(只读数据) │
├─────────────────────────────────┤
│ .text段(代码段) │
├─────────────────────────────────┤ ← 0x08048000
│ 保留区 │
└─────────────────────────────────┘ ← 0x00000000
线程1(主线程):
- 栈在栈区(高地址)
- 共享.text、.data、堆
线程2、3(子线程):
- 栈在共享区(中间地址)
- 共享.text、.data、堆4.4 理解"单线程进程"
bash
问题: 我们之前学的进程,有线程吗?
答案: 有! 所有进程至少有一个线程
单线程进程:
- 只有main函数这一个执行流
- 这个执行流就是主线程
- 主线程使用进程栈区的栈
多线程进程:
- 有main函数(主线程)
- 还有其他执行流(子线程)
- 子线程使用共享区的栈五、本篇总结
📌 核心知识回顾
线程的本质
- 线程是进程内部的控制序列
- 线程在进程地址空间内运行
- Linux中线程实现为轻量级进程(LWP)
虚拟地址空间
- 解决物理内存碎片、地址冲突、保护问题
- 每个进程有独立的虚拟地址空间(32位系统0~4GB)
- 通过页表建立虚拟地址到物理地址的映射
分页机制
- 物理内存按4KB划分为页框(Page Frame)
- 虚拟地址空间按4KB划分为页(Page)
- struct page描述每个物理页框
两级页表
- 页目录表(1024项) + 二级页表(每个1024项)
- 按需分配,节省内存
- CR3寄存器指向页目录基址
地址转换
- MMU硬件完成虚拟地址到物理地址的转换
- TLB缓存加速地址转换
- 缺页异常:硬缺页(从磁盘加载)、软缺页(建立映射)、无效缺页(段错误)
线程优缺点
- 优点:创建快、切换快、通信简单、占用资源少
- 缺点:健壮性差、编程难度高、一个线程崩溃影响整个进程
进程vs线程
- 进程是资源分配的基本单位
- 线程是调度的基本单位
- 线程共享进程的地址空间、文件、信号处理等
- 线程私有栈、寄存器、线程ID、errno
六、承上启下
本篇我们深入理解了线程的本质和虚拟地址空间的分页机制,为后续学习打下了坚实的理论基础。
下一篇预告:
在第二篇中,我们将学习Linux线程控制的核心API:
bash
✓ pthread_create - 创建线程
✓ pthread_exit - 线程退出
✓ pthread_join - 等待线程
✓ pthread_cancel - 取消线程
✓ pthread_detach - 线程分离
✓ pthread_self - 获取线程ID每个API都会配合完整的代码示例,让你真正掌握多线程编程!
💬 互动环节
学完本篇,你应该能够回答:
- 为什么需要虚拟内存?
- 两级页表相比单级页表有什么优势?
- TLB的作用是什么?
- 线程相比进程有哪些优点?
- 一个线程崩溃会影响其他线程吗?
如果这些问题你都能回答,说明你已经掌握了本篇的核心内容!
👍 如果本文对你有帮助,请点赞、收藏、分享,让更多同学受益!
💭 有疑问欢迎评论区讨论,我会及时回复!