kubeadm部署 Kubernetes(k8s) 高可用集群 V1.32
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
一、安装要求+环境说明
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
- 7台机器,操作系统为Openeuler22.03 LTS SP4
- 使用 docker-ce
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多,docker 数据卷单独挂载
- 集群中所有机器之间网络互通
- 可以访问外网,需要拉取镜像
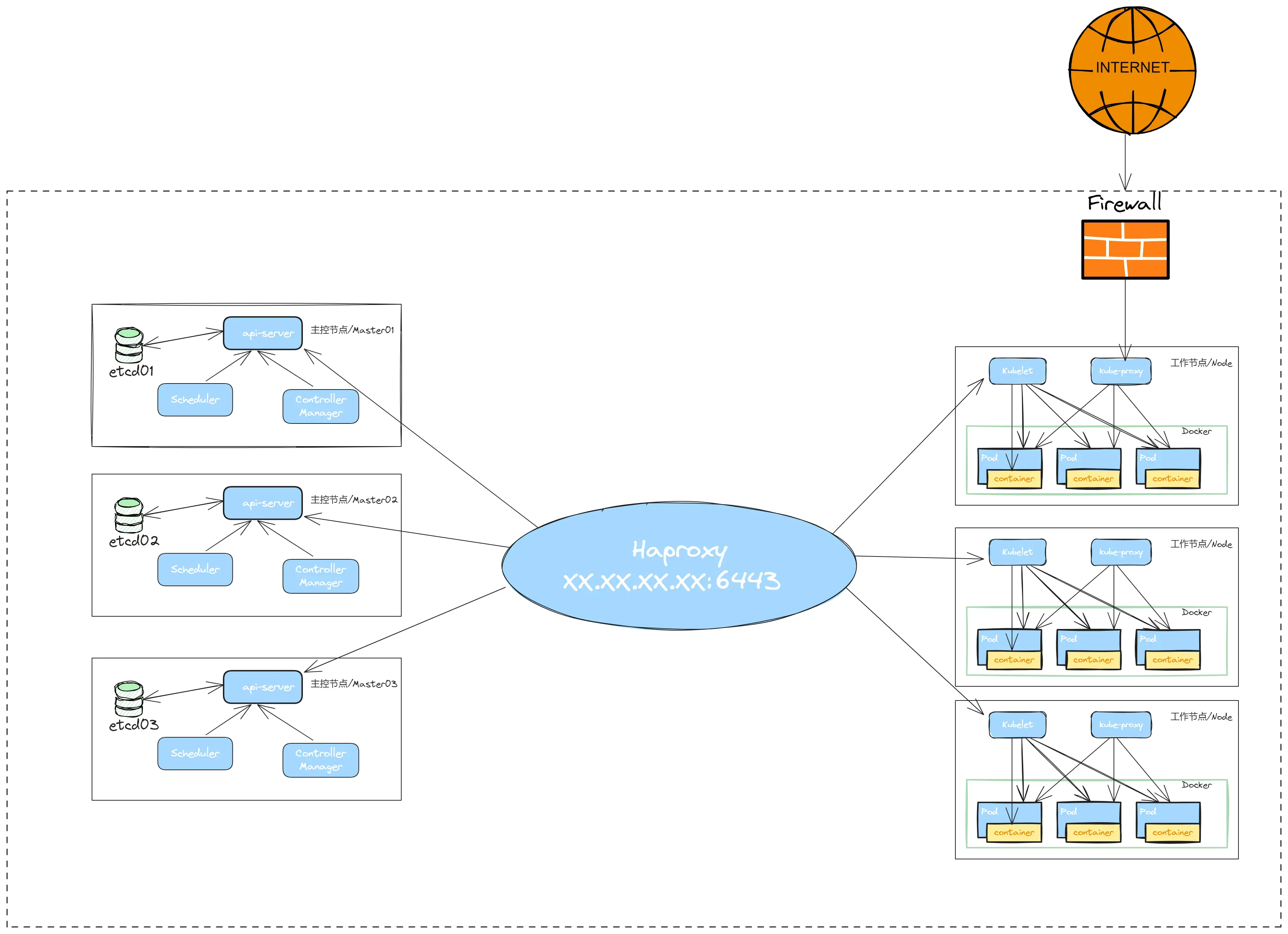
二、机器环境准备
| 角色 | IP | 机器配置 | 组件 | 功能描述 |
|---|---|---|---|---|
| Haproxy | 172.22.33.100 | 16c32g500G | haproxy+nfs | K8S入口,负载均衡,nfs 存储 |
| k8s-master01 | 172.22.33.101 | 8c16g200G | docker,cri-dockerd,kube-apiserver,kube-scheduler,kube-controller-manager,etcd,kubelet,kube-proxy,coredns,calico | k8s master01节点 |
| k8s-master02 | 172.22.33.102 | 8c16g200G | docker,cri-dockerd,kube-apiserver,kube-scheduler,kube-controller-manager,etcd,kubelet,kube-proxy,coredns,calico | k8s master02节点 |
| k8s-master03 | 172.22.33.103 | 8c16g200G | docker,cri-dockerd,kube-apiserver,kube-scheduler,kube-controller-manager,etcd,kubelet,kube-proxy,coredns,calico | k8s master03节点 |
| k8s-node01 | 172.22.33.110 | 16c32g200G | docker,cri-dockerd,kubelet,kube-proxy,coredns,calico | k8s-node01 工作节点 |
| k8s-node02 | 172.22.33.111 | 16c32g200G | docker,cri-dockerd,kubelet,kube-proxy,coredns,calico | k8s-node02 工作节点 |
| k8s-node03 | 172.22.33.112 | 16c32g200G | docker,cri-dockerd,kubelet,kube-proxy,coredns,calico | k8s-node03 工作节点 |
2.1 环境初始化
K8S 集群服务器 都需要配置
bash
关闭防火墙:
$ systemctl stop firewalld
$ systemctl disable firewalld
关闭selinux:
$ sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
$ setenforce 0 # 临时
关闭swap:[临时和永久关闭]
#临时关闭
$ swapoff -a
#永久关闭
$ sed -ri 's/.*swap.*/#&/' /etc/fstab
设置主机名:
$ hostnamectl set-hostname haproxy+nfs
$ hostnamectl set-hostname k8s-master01
$ hostnamectl set-hostname k8s-master02
$ hostnamectl set-hostname k8s-master03
$ hostnamectl set-hostname k8s-node01
$ hostnamectl set-hostname k8s-node02
$ hostnamectl set-hostname k8s-node03
#在K8S上所有节点添加hosts:
$ cat >> /etc/hosts << EOF
172.22.33.101 k8s-master01
172.22.33.102 k8s-master02
172.22.33.103 k8s-master03
172.22.33.110 k8s-node01
172.22.33.111 k8s-node02
172.22.33.112 k8s-node03
EOF
#开启内核路由转发
sed -i 's/net.ipv4.ip_forward=0/net.ipv4.ip_forward=1/g' /etc/sysctl.conf
#将桥接的IPv4,IPV6流量传递到iptables的链:
$ cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
vm.swappiness = 0
EOF
# 生效
$ sysctl --system
#每个节点都需要安装 IPVS 的相关工具和加载ipvs内核模块
$ yum install ipvsadm
#在所有节点执行以下命令
$ cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
$ chmod 755 /etc/sysconfig/modules/ipvs.modules
$ bash /etc/sysconfig/modules/ipvs.modules
#查看IPVS模块加载情况
$ lsmod | grep -e ip_vs -e nf_conntrack_ipv4
#能看到ip_vs ip_vs_rr ip_vs_wrr ip_vs_sh nf_conntrack_ipv4 加载成功
#安装nfs-server(所有节点的操作,后续存储卷需要使用)
$ yum install -y nfs-utils
#配置时间同步定时任务:
$ yum install ntpdate -y
$ ntpdate time1.aliyun.com
#配置定时任务
0 */1 * * * ntpdate -u time1.aliyun.com
#开启系统层面的cgroup v2
#Kubernetes自v1.25以来,Kubernetes中对cgroup v2的支持已经稳定,为原有的cgroup v1支持提供了替代方案。且v1.35版本中弃用和移除了 cgroup v1
#查看是否开启了 cgroup v2
$ stat -fc %T /sys/fs/cgroup/
#如果不是 cgroup v2,运行以下命令并重启
sudo grubby --update-kernel=ALL --args=systemd.unified_cgroup_hierarchy=1
sudo reboot三、部署Docker/cri-dockerd
在所有K8S 集群的节点上,执行
Kubernetes1.24 之后, 在k8s中使用docker,除了安装docker 以外,还需要安装cri-dockerd 组件; 不然就使用Containerd
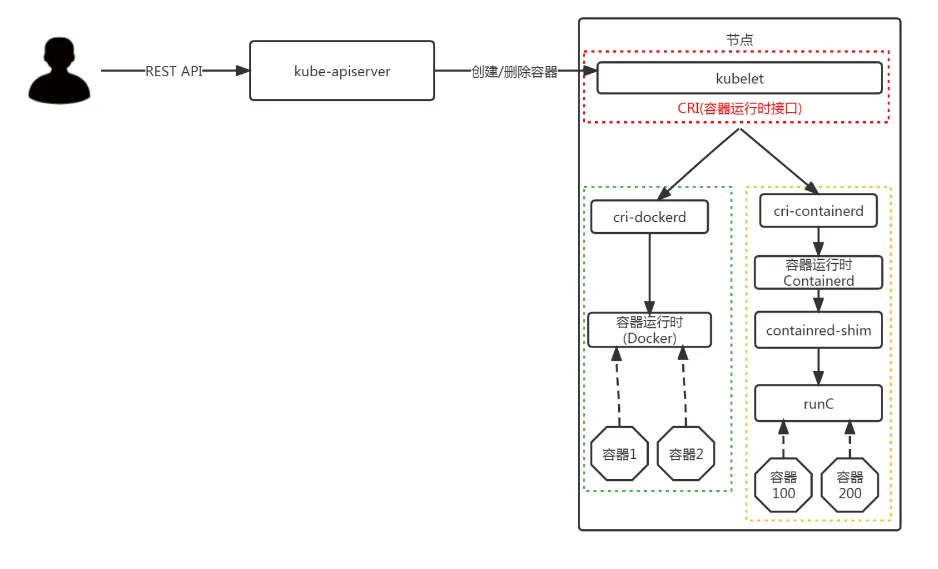
3.1 docker二进制包部署方式
- docker-ce 社区下载地址:
bash
$ wget https://mirrors.nju.edu.cn/docker-ce/linux/static/stable/x86_64/docker-20.10.24.tgz- 解压,拷贝至/usr/bin 下
bash
$ tar -xf docker-20.10.24.tgz
$ cp docker/* /usr/bin
$ which docker- 编写docker.service文件
bash
$ cat > /etc/systemd/system/docker.service <<EOF
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=65535
LimitNPROC=65535
LimitCORE=65535
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF- 挂载docker默认存储路径可选
docker的默认工作路径在/var/lib/docker ,优雅的方式是,不修改默认存储路径,做软链接到文件系统挂载的地方。
bash
#建立工作目录
$ mkdir /home/application/
#格式化磁盘
$ mkfs.xfs /dev/sdb
#磁盘永久挂载
$ vim /etc/fstab
/dev/sdb /home/application xfs defaults 0 0
#使挂载生效
$ mount -a
# 创建docker 工作目录
$ mkdir /home/application/docker
#创建软链接
$ ln -s /home/application/docker /var/lib/- 添加可执行权限
bash
$ chmod +x /etc/systemd/system/docker.service- 启动,配置开机自启动
bash
$ systemctl daemon-reload
$ systemctl start docker.service
$ systemctl enable docker.service- 配置镜像加速器,并制定cgroupdriver=systemd
镜像加速地址可能随时失效,可以都配置几个
bash
$ mkdir -p /etc/docker
$ tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://docker.1ms.run"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
$ systemctl daemon-reload
$ systemctl restart docker3.2 二进制部署cri-dockerd
bash
# 下载cri-dockerd
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.17/cri-dockerd-0.3.17.amd64.tgz
tar -xf cri-dockerd-0.3.17.amd64.tgz
cp cri-dockerd/cri-dockerd /usr/bin/
chmod +x /usr/bin/cri-dockerd
rm -rf cri-dockerd
# 配置启动文件
# pause容器是的 3.10
cat <<"EOF" > /usr/lib/systemd/system/cri-docker.service
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.10
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
# 生成socket 文件
cat <<"EOF" > /usr/lib/systemd/system/cri-docker.socket
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=root
[Install]
WantedBy=sockets.target
EOF
# 启动CRI-DOCKER
systemctl daemon-reload
systemctl start cri-docker
systemctl enable cri-docker
systemctl is-active cri-docker四、部署kubeadm/kubelet/kubectl
在所有K8S 集群的节点上,执行
4.1 添加阿里云YUM软件源
bash
$ cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF4.2 使用 yum安装kubeadm,kubelet和kubectl
bash
# 查看所有的可用版本
$ yum list kubeadm kubelet kubectl --showduplicates | sort -r
#在所有节点安装
$ yum install kubelet kubeadm kubectl --disableexcludes=kubernetes
$ systemctl enable kubelet五、部署Haproxy负载均衡
- 用途:在 Kubernetes 集群外部部署 HAProxy 作为负载均衡器,代理所有 Master 节点的 API Server(默认端口 6443),并确保所有 Node 节点通过该负载均衡器访问集群。
- 环境准备
- Master 节点信息 :获取所有 Master 节点的 IP 地址(
172.22.33.101,172.22.33.102,172.22.33.103)。 - 负载均衡器节点 :选择一台独立服务器部署 HAProxy(
172.22.33.100)
- Master 节点信息 :获取所有 Master 节点的 IP 地址(
5.1 yum安装haproxy
在172.22.33.210 服务器上部署
bash
yum -y install haproxy5.2 修改配置文件
bash
$ cat > /etc/haproxy/haproxy.cfg << EOF
global
log /dev/log local0 warning
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend kube-apiserver
bind *:6443
mode tcp
option tcplog
default_backend kube-apiserver
backend kube-apiserver
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server kube-apiserver-1 172.22.33.101:6443 check
server kube-apiserver-2 172.22.33.102:6443 check
server kube-apiserver-3 172.22.33.103:6443 check
EOF5.3 启动Haproxy
bash
$ systemctl enable haproxy
$ systemctl start haproxy六、部署Kubernetes Master
在所有k8s-master 节点上,执行
6.1 在所有master 节点上创建kubeadm 初始化文件
-
查看该版本的kubeadm-config配置选项
kubeadm config print init-defaults --component-configs KubeletConfiguration
-
查看导出的默认配置,需要根据实际情况修改。
apiVersion: kubeadm.k8s.io/v1beta4
bootstrapTokens:- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages: - signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 1.2.3.4
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
imagePullSerial: true
name: node
taints: null
timeouts:
controlPlaneComponentHealthCheck: 4m0s
discovery: 5m0s
etcdAPICall: 2m0s
kubeletHealthCheck: 4m0s
kubernetesAPICall: 1m0s
tlsBootstrap: 5m0s
upgradeManifests: 5m0s
- system:bootstrappers:kubeadm:default-node-token
apiServer: {}
apiVersion: kubeadm.k8s.io/v1beta4
caCertificateValidityPeriod: 87600h0m0s
certificateValidityPeriod: 8760h0m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
encryptionAlgorithm: RSA-2048
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.k8s.io
kind: ClusterConfiguration
kubernetesVersion: 1.32.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
proxy: {}
scheduler: {}apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:- 10.96.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
crashLoopBackOff: {}
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMaximumGCAge: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
text:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
- groups:
-
导出配置到kubeadm-init.yaml 文件中
#创建初始化目录
mkdir -p /etc/kubernetes/init/#导出yaml文件
kubeadm config print init-defaults --component-configs KubeletConfiguration > /etc/kubernetes/init/kubeadm-init.yaml -
修改后的kubeadm-init.yaml文件【注释版】
在 kubeadm v1beta4 版本中增加了定义证书有效期的字段,我们可以把证书修改为 100 年,这样就再也不用为续期证书烦恼了。
# ========================
# 第一部分:InitConfiguration (节点初始化配置)
# ========================
apiVersion: kubeadm.k8s.io/v1beta4 # 使用的 kubeadm API 版本
bootstrapTokens: # 引导令牌配置(用于节点加入集群)
- groups: # 令牌所属组
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef # 实际的引导令牌值(示例值,实际使用需替换)
ttl: 24h0m0s # 令牌有效期(24小时)
usages: # 令牌用途
- signing # 用于签名
- authentication # 用于认证
kind: InitConfiguration # 资源类型:初始化配置
nodeRegistration: # 节点注册相关配置
criSocket: unix:///var/run/cri-dockerd.sock # CRI 套接字路径(使用 cri-dockerd)
imagePullPolicy: IfNotPresent # 镜像拉取策略(优先使用本地镜像)
imagePullSerial: true # 串行拉取镜像(避免并发问题)
# ========================
# 第二部分:ClusterConfiguration (集群全局配置)
# ========================
---
apiVersion: kubeadm.k8s.io/v1beta4 # 使用的 kubeadm API 版本
caCertificateValidityPeriod: 87600h0m0s # CA 证书有效期(10年)
certificateValidityPeriod: 87600h0m0s # 其他证书有效期(10年)
certificatesDir: /etc/kubernetes/pki # 证书存储目录
clusterName: kubernetes # 集群名称
controllerManager: {} # 控制器管理器配置(空表示使用默认值)
dns: {} # DNS 配置(空表示使用默认值)
etcd: # etcd 数据库配置
local: # 使用本地 etcd 实例
dataDir: /home/application/etcd # etcd 数据存储路径
imageRepository: registry.aliyuncs.com/google_containers # 容器镜像仓库(阿里云镜像源)
kind: ClusterConfiguration # 资源类型:集群配置
controlPlaneEndpoint: 172.22.33.100:6443 # 控制平面端点(负载均衡器/VIP地址)
kubernetesVersion: 1.32.0 # Kubernetes 目标版本
networking: # 网络配置
dnsDomain: cluster.local # DNS 域名后缀
podSubnet: 10.244.0.0/16 # Pod 子网范围(Flannel 默认)
serviceSubnet: 10.96.0.0/12 # Service 子网范围
proxy: {} # kube-proxy 配置(空表示使用默认值)
scheduler: {} # 调度器配置(空表示使用默认值)
# API Server 证书 SAN 扩展列表(允许哪些地址访问 API Server)
apiServer:
certSANs:
- kubernetes # 标准服务名
- kubernetes.default # 默认命名空间下的服务
- kubernetes.default.svc # 完整服务域名
- kubernetes.default.svc.cluster.local # 完整内部域名
- 172.22.33.100 # 负载均衡器/VIP IP
- 172.22.33.101 # Master 节点 IP
- 172.22.33.102 # Master 节点 IP
- 172.22.33.103 # Master 节点 IP
- 127.0.0.1 # 本地回环地址
- 105.3.192.75 # 公网 IP
- "*.srebro.cn" # 通配符域名
- "*.srebro.site" # 通配符域名
# ========================
# 第三部分:KubeProxyConfiguration (kube-proxy 配置)
# ========================
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1 # kube-proxy API 版本
kind: KubeProxyConfiguration # 资源类型:kube-proxy 配置
mode: "ipvs" # 使用 IPVS 模式(性能优于 iptables)
ipvs:
strictARP: true # 启用严格 ARP(解决某些网络环境问题)-
修改后的kubeadm-init.yaml文件【无注释版本】
apiVersion: kubeadm.k8s.io/v1beta4
bootstrapTokens:- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages: - signing
- authentication
kind: InitConfiguration
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
imagePullSerial: true
- system:bootstrappers:kubeadm:default-node-token
apiServer:
certSANs:
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster.local
- 172.22.33.100
- 172.22.33.101
- 172.22.33.102
- 172.22.33.103
- 127.0.0.1
- 105.3.192.75
- ".srebro.cn"
- ".srebro.site"
apiVersion: kubeadm.k8s.io/v1beta4
caCertificateValidityPeriod: 87600h0m0s
certificateValidityPeriod: 87600h0m0s
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /home/application/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
controlPlaneEndpoint: 172.22.33.100:6443
kubernetesVersion: 1.32.0
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
proxy: {}
scheduler: {}apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
ipvs:
strictARP: true - groups:
-
把kubeadm-init.yaml文件同步到各个 master 节点上
ssh k8s-master02 "mkdir -p /etc/kubernetes/init/" && scp -rp /etc/kubernetes/init/kubeadm-init.yaml k8s-master03:/etc/kubernetes/init/
ssh k8s-master03 "mkdir -p /etc/kubernetes/init/" && scp -rp /etc/kubernetes/init/kubeadm-init.yaml k8s-master03:/etc/kubernetes/init/
6.2 在所有master 节点上,优先把镜像pull到本地
在使用 kubeadm 初始化之前,先下载镜像到master 机器上
bash
#k8s-master01 节点上
$ kubeadm config images pull --config /etc/kubernetes/init/kubeadm-init.yaml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.11.3
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.10
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.24-0
#k8s-master02 节点上
$ kubeadm config images pull --config /etc/kubernetes/init/kubeadm-init.yaml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.11.3
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.10
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.24-0
#k8s-master03 节点上
$ kubeadm config images pull --config /etc/kubernetes/init/kubeadm-init.yaml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.32.0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.11.3
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.10
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.24-06.3 在k8s-master01 节点上,完成kubeadm 初始化
⚠️ 在 k8s-master01 节点上,完成初始化即可。
- --upload-certs,将控制平面(Master 节点)的核心证书自动上传到集群的 Secret 中,便于后续添加其他控制平面节点时安全共享证书。当k8s 集群中加入多个 Master 节点时,此参数可避免手动复制证书的复杂操作。
bash
$ kubeadm init --config /etc/kubernetes/init/kubeadm-init.yaml --upload-certs
W0115 22:23:14.748816 9367 validation.go:79] WARNING: certificateValidityPeriod: the value 87600h0m0s is more than the recommended default for certificate expiration: 8760h0m0s
[init] Using Kubernetes version: v1.32.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [*.srebro.cn *.srebro.site k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.22.33.101 172.22.33.100 172.22.33.102 172.22.33.103 127.0.0.1 105.3.192.75]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [172.22.33.101 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [172.22.33.101 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.001612496s
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 14.037303039s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
db81423d497f694e55507f3118d3c518810539cc67d5a9ef9da5306e1f62e138
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes running the following command on each as root:
kubeadm join 172.22.33.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:8f5e3b1c11596b44bd7f764a972886db2832266d9a8e83e9ea3ba41aea41a08f \
--control-plane --certificate-key db81423d497f694e55507f3118d3c518810539cc67d5a9ef9da5306e1f62e138
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.22.33.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:8f5e3b1c11596b44bd7f764a972886db2832266d9a8e83e9ea3ba41aea41a08f- 拷贝kubectl使用的连接k8s认证文件到默认路径
bash
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config6.4 加入 K8s Master 节点
在 K8s-master02 和 k8s-master03 节点上操作
- 使用刚刚 k8s-master01 在kubeadm init输出的kubeadm join命令:
bash
#加入控制平面
$ kubeadm join 172.22.33.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:8f5e3b1c11596b44bd7f764a972886db2832266d9a8e83e9ea3ba41aea41a08f \
--control-plane --certificate-key db81423d497f694e55507f3118d3c518810539cc67d5a9ef9da5306e1f62e138七、加入K8s Node 节点
在K8S 所有node 节点上操作
| k8s-node01 | 172.22.33.110 |
|---|---|
| k8s-node02 | 172.22.33.111 |
| k8s-node03 | 172.22.33.112 |
- 使用刚刚master01 在kubeadm init输出的kubeadm join命令:
bash
$ kubeadm join 172.22.33.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:8f5e3b1c11596b44bd7f764a972886db2832266d9a8e83e9ea3ba41aea41a08f默认token有效期为24小时,当过期之后,该token就不可用了;这时就需要重新创建token,可以直接在master 节点上,使用命令快捷生成:
bash
$ kubeadm token create --print-join-command-
查看 K8s 集群的节点数量及状态
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady control-plane 1h v1.32.11
k8s-master02 NotReady control-plane 1h v1.32.11
k8s-master03 NotReady control-plane 1h v1.32.11
k8s-node01 NotReady1h v1.32.11
k8s-node02 NotReady1h v1.32.11
k8s-node03 NotReady1h v1.32.11
可以看到,所有的节点都已经加入到集群中了,NotReady是需要等待CNI网络插件安装好。
八、部署calico 容器网络 CNI 插件
- Calico 的网络模型基于 "纯三层网络"(L3),核心思想是:Pod 的 IP 地址直接暴露在集群网络中,节点通过路由协议感知 Pod 的位置,而非传统的 Overlay 网络(如 VXLAN 封装)。
- 官方地址: https://docs.tigera.io/calico/latest/about/
- k8s 和 calico 版本对应关系

- 安装方式
找到对应的版本,从github下载calico.yaml文件,修改国内镜像地址后,若无多网卡或网络模式的需求,则无需修改直接apply/create即可
bash
$ https://github.com/projectcalico/calico/blob/v3.27.0/manifests/calico.yaml下载完后还需要修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kubeadm init指定的
--pod-network-cidr=10.244.0.0/16 保持一致; 默认是 192.168.0.0/16
bash
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
bash
$ kubectl apply -f calico.yaml
$ kubectl get pods -n kube-system- 查看所有节点
bash
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane 7d v1.32.11
k8s-master02 Ready control-plane 7d v1.32.11
k8s-master03 Ready control-plane 7d v1.32.11
k8s-node01 Ready <none> 7d v1.32.11
k8s-node02 Ready <none> 7d v1.32.11
k8s-node03 Ready <none> 7d v1.32.11可以看到,所有的节点都是Ready状态。
九. 测试kubernetes集群
- 验证Pod工作
- 验证Pod网络通信
- 验证DNS解析
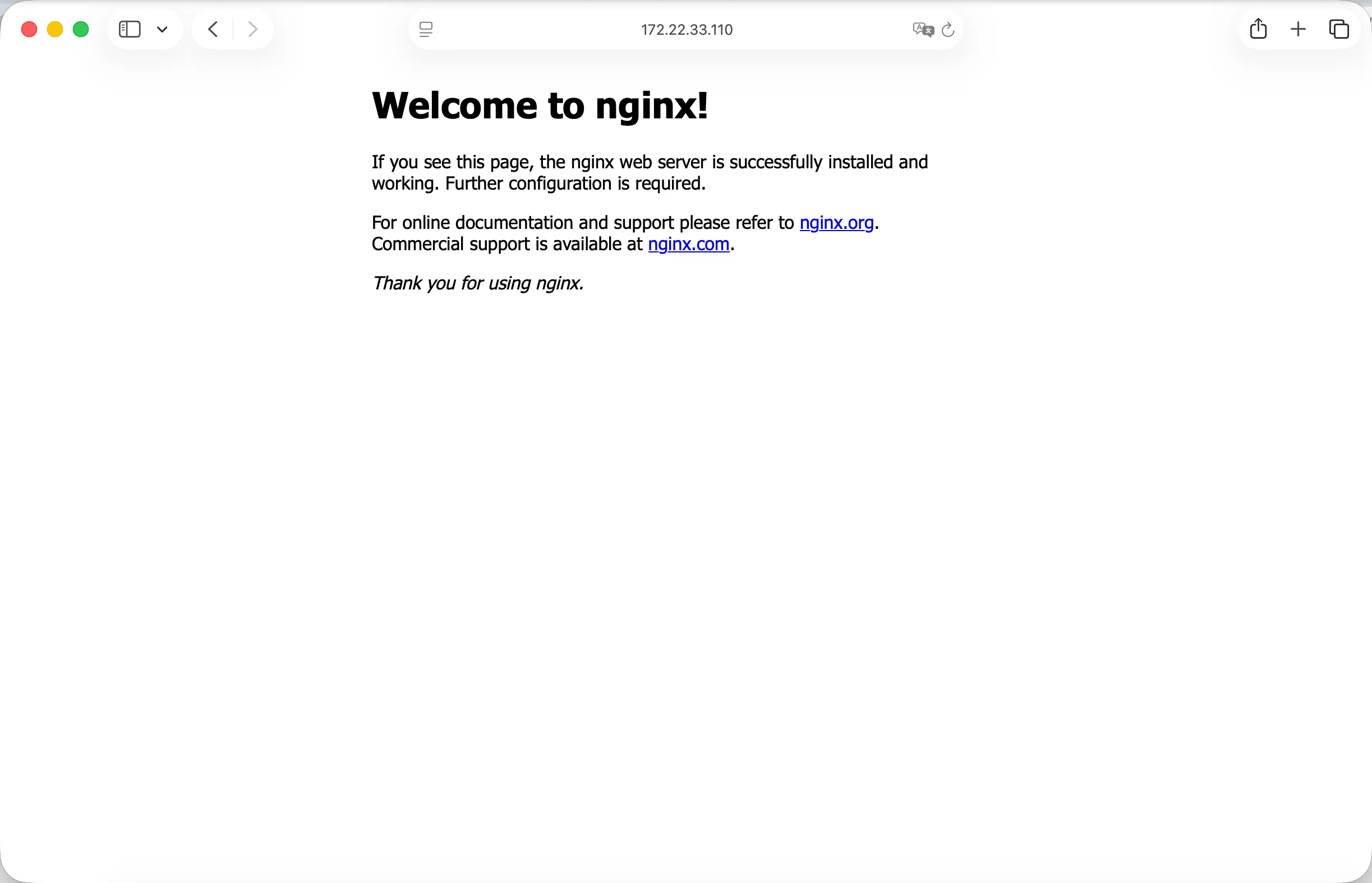
在Kubernetes集群中创建一个pod,验证是否正常运行:
bash
#创建一个 nginx 类型的deployment控制器
$ kubectl create deployment nginx --image=nginx
#
$ kubectl expose deployment nginx --port=80 --type=NodePort
#查看 pod 状态以及 nodeport 端口
$ kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-5869d7778c-4z7kd 1/1 Running 0 15s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7d
service/nginx NodePort 10.111.180.29 <none> 80:31043/TCP 7s访问地址:http://Nodeip:NodePort
十、补充
10.1 kubectl 命令补齐
bash
$ yum install bash-completion -y
$ source /usr/share/bash-completion/bash_completion
$ source <(kubectl completion bash)
$ kubectl completion bash >/etc/bash_completion.d/kubectl