文章目录
- 1.前言
- [2. SOME/IP协议规定](#2. SOME/IP协议规定)
-
- [2.1 SOME/IP报头](#2.1 SOME/IP报头)
-
- [2.1.1 Message ID(32 bit)= Service ID + Method ID](#2.1.1 Message ID(32 bit)= Service ID + Method ID)
- [2.1.2 Length(32 bit)](#2.1.2 Length(32 bit))
- [2.1.3 Request ID(32 bit)= Client ID + Session ID](#2.1.3 Request ID(32 bit)= Client ID + Session ID)
- [2.1.4 Protocol Version(8 bit)](#2.1.4 Protocol Version(8 bit))
- [2.1.5 Interface Version(8 bit)](#2.1.5 Interface Version(8 bit))
- [2.1.6 Message Type(8 bit)](#2.1.6 Message Type(8 bit))
- [2.1.7 Return Code(8 bit)](#2.1.7 Return Code(8 bit))
- [2.1.8 wireshark看someip报文](#2.1.8 wireshark看someip报文)
- [2.2 E2E报头位置](#2.2 E2E报头位置)
- [2.3 Payload数据序列化](#2.3 Payload数据序列化)
-
- [2.3.1 结构体序列化](#2.3.1 结构体序列化)
- [2.3.2 TLV(Tag-Length-Value)可扩展结构](#2.3.2 TLV(Tag-Length-Value)可扩展结构)
-
- [2.3.2.1 为什么需要 TLV?](#2.3.2.1 为什么需要 TLV?)
- [2.3.2.2 什么是TLV](#2.3.2.2 什么是TLV)
-
- [2.3.2.2.1 Tag结构](#2.3.2.2.1 Tag结构)
- [2.3.2.3 实际例子](#2.3.2.3 实际例子)
- [2.3.3 数组序列化](#2.3.3 数组序列化)
-
- [2.3.3.1 定长数组](#2.3.3.1 定长数组)
- [2.3.3.2 变长数组](#2.3.3.2 变长数组)
- [2.3.3.3 多维数组(定长)](#2.3.3.3 多维数组(定长))
- [2.3.3.4 多维数组(变长)](#2.3.3.4 多维数组(变长))
- [2.3.4 枚举类型序列化](#2.3.4 枚举类型序列化)
- [2.3.5 定长字符串](#2.3.5 定长字符串)
- [2.3.6 变长字符串](#2.3.6 变长字符串)
- [2.4 传输层绑定](#2.4 传输层绑定)
-
- [2.4.1 魔法数字](#2.4.1 魔法数字)
- [2.5 多服务实例](#2.5 多服务实例)
- [2.6 SOME/IP-TP(大消息分片)](#2.6 SOME/IP-TP(大消息分片))
-
- [2.6.1 分片例子](#2.6.1 分片例子)
- [2.6.2 分片优势对比](#2.6.2 分片优势对比)
- [2.7 methods event fields triggers的someip报文](#2.7 methods event fields triggers的someip报文)
-
- [2.7.1 methods(RR)](#2.7.1 methods(RR))
- [2.7.2 methods(FF)](#2.7.2 methods(FF))
- [2.7.3 events](#2.7.3 events)
- [2.7.4 fields](#2.7.4 fields)
- [2.8 错误处理](#2.8 错误处理)
- [2.9 如何选择传输协议](#2.9 如何选择传输协议)
1.前言
对AUTOSAR_PRS_SOMEIPProtocol文档进行内容解读,这个文档讲的是SOMEIP协议的规范条目,也就是具体要怎么做。
2. SOME/IP协议规定
2.1 SOME/IP报头

对各个字段进行解释
2.1.1 Message ID(32 bit)= Service ID + Method ID
| 子字段 | 位数 | 说明 |
|---|---|---|
| Service ID | 16 bit | 标识哪个服务(最多 65536 个服务) |
| Method ID | 16 bit | 标识服务内的方法或事件 |
Method ID 分配惯例:
- 0x0000 - 0x7FFF:方法(最高位=0)
- 0x8000 - 0x8FFF:事件/通知(最高位=1)
2.1.2 Length(32 bit)
length的含义是:从Request ID 开始到报文结束的字节数
也就是说
Length = 8字节(Request ID + 后4个字段) + Payload长度
2.1.3 Request ID(32 bit)= Client ID + Session ID
| 子字段 | 位数 | 说明 |
|---|---|---|
| Client ID | 16 bit | 标识调用方(ECU内唯一) |
| Session ID | 16 bit | 标识同一Client的不同调用 |
Session ID 规则:
- 不启用会话管理:固定为 0x00
- 启用会话管理:0x0001 - 0xFFFF 循环递增
- 到达 0xFFFF 后回绕到 0x0001(跳过0)
- Response 的 Session ID 必须与 Request 匹配,否则丢弃
2.1.4 Protocol Version(8 bit)
当前固定为 0x01,代表着现在someip协议只有版本1
2.1.5 Interface Version(8 bit)
服务接口的主版本号,用于区分同一服务的不同版本,实现版本兼容性检查。
2.1.6 Message Type(8 bit)
| 值 | 名称 | 描述 |
|---|---|---|
| 0x00 | REQUEST | 请求,期望响应 |
| 0x01 | REQUEST_NO_RETURN | Fire&Forget,无响应 |
| 0x02 | NOTIFICATION | 事件/通知,无响应 |
| 0x80 | RESPONSE | 正常响应 |
| 0x81 | ERROR | 错误响应 |
| 0x20 | TP_REQUEST | 分片请求(SOME/IP-TP) |
| 0x21 | TP_REQUEST_NO_RETURN | 分片 Fire&Forget |
| 0x22 | TP_NOTIFICATION | 分片通知 |
| 0xa0 | TP_RESPONSE | 分片响应 |
| 0xa1 | TP_ERROR | 分片错误响应 |
TP-Flag: 第3高位(0x20)=1 表示这是分片消息。
2.1.7 Return Code(8 bit)
| Message Type | 允许的 Return Code |
|---|---|
| REQUEST | 固定 0x00(E_OK) |
| REQUEST_NO_RETURN | 固定 0x00(E_OK) |
| NOTIFICATION | 固定 0x00(E_OK) |
| RESPONSE | 各种返回码 |
| ERROR | 各种返回码,但不能是 0x00 |
2.1.8 wireshark看someip报文
someip在wireshark里面长这个样子
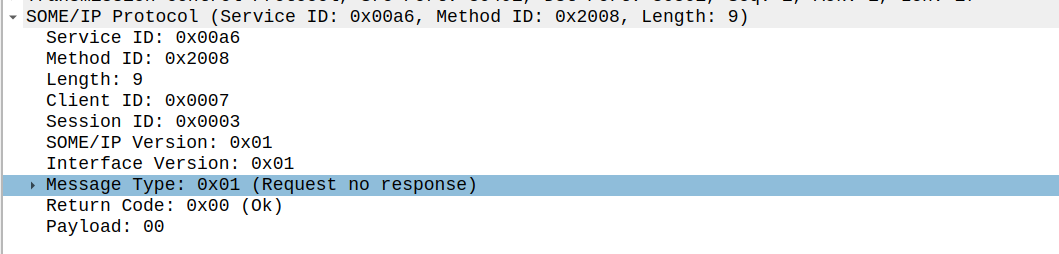
报头所有字段都很清楚的列出来了。
2.2 E2E报头位置
如果启用 E2E(End-to-End)保护,E2E Header 插在 Return Code 和 Payload 之间(默认偏移 64 bit)。
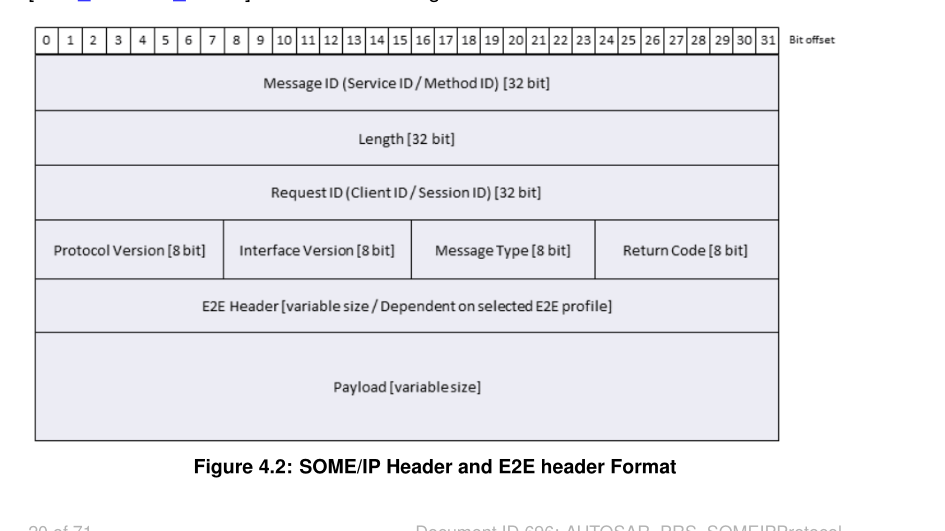
文档中没有细说E2E报头的结构,因为E2E并不专门属于SOME/IP协议,任何协议它都可以加入E2E
2.3 Payload数据序列化
文档对payload里面的数据如何进行序列化的进行了讲解。
报头部分,固定使用大端模式。payload部分,由用户选择大端还是小端。
基础数据类型的序列化不讲了,着重讲特殊类型的序列化。
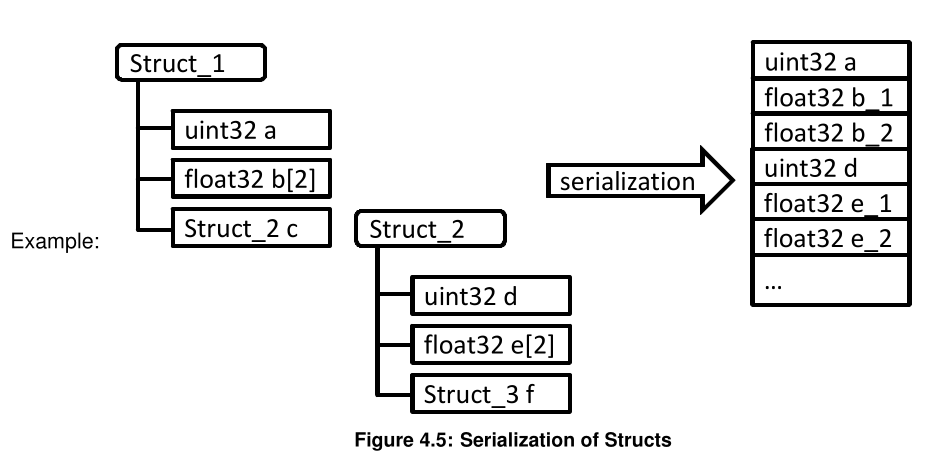
2.3.1 结构体序列化
采用DFS来进行序列化,如图:
2.3.2 TLV(Tag-Length-Value)可扩展结构
文档称,这是 SOME/IP 的高级特性,比起普通的序列化方式兼容性好。
2.3.2.1 为什么需要 TLV?
在车载软件开发中,接口升级是常见需求。比如:
场景: 车辆状态结构体需要新增一个字段
// V1.0 版本
struct VehicleStatus {
uint16 speed;
uint8 gear;
}
// V2.0 版本 - 新增油量字段
struct VehicleStatus {
uint16 speed;
uint8 gear;
uint8 fuelLevel; // 新增
}问题: 如果新旧 ECU 混用会怎样?
| 发送方 | 接收方 | 标准序列化 | TLV 序列化 |
|---|---|---|---|
| V2.0 | V1.0 | 解析错误 | 跳过未知字段 |
| V1.0 | V2.0 | 数据缺失 | 使用默认值 |
结论: TLV 让新旧版本可以共存,实现向前/向后兼容。
2.3.2.2 什么是TLV
TLV = T ag + L ength + Value

- Tag:标识这是哪个字段
- Length:告诉接收方数据有多长(用于跳过未知字段)
- Value:实际的数据内容
图中前两个字节是tag,第三个字节是length,最后一个字节是value。
2.3.2.2.1 Tag结构
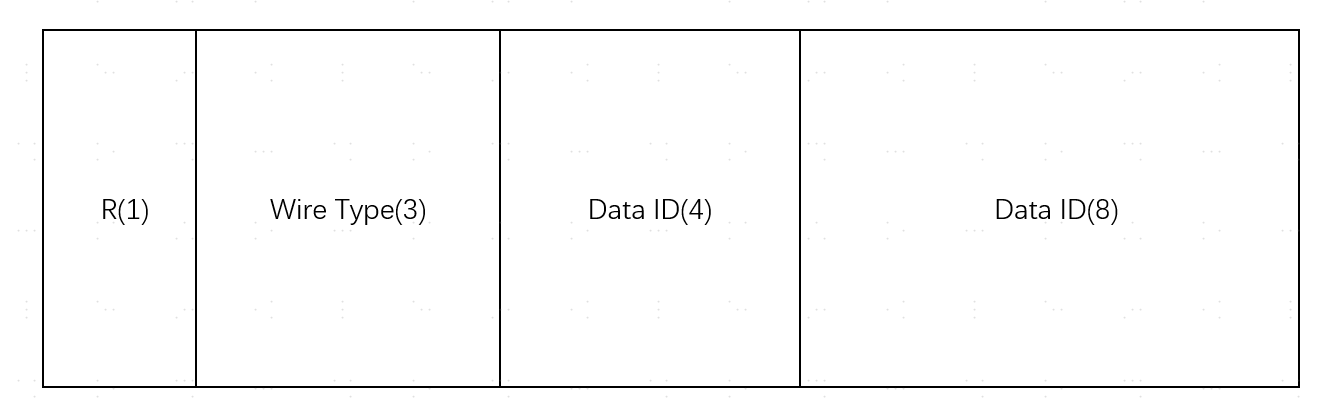
| 部分 | 位置 | 作用 |
|---|---|---|
| Reserved | Byte0 的 Bit7 | 保留位,置0 |
| Wire Type | Byte0 的 Bit6-4 | 指示数据类型 |
| Data ID | Byte0 的 Bit3-0 + Byte1 | 字段的唯一标识(12 bit,范围 0~4095) |
Wire Type 告诉接收方"后面的数据是什么类型":
| Wire Type | 值 | 含义 | 是否需要 Length 字段 |
|---|---|---|---|
| 0 | 0b000 | 8 bit 基本类型 | 不需要 |
| 1 | 0b001 | 16 bit 基本类型 | 不需要 |
| 2 | 0b010 | 32 bit 基本类型 | 不需要 |
| 3 | 0b011 | 64 bit 基本类型 | 不需要 |
| 4 | 0b100 | 复杂类型(长度由配置决定) | 需要 |
| 5 | 0b101 | 复杂类型(1字节长度) | 需要 |
| 6 | 0b110 | 复杂类型(2字节长度) | 需要 |
| 7 | 0b111 | 复杂类型(4字节长度) | 需要 |
基本类型不需要长度的原因是,基本类型的数据长度是固定的。
2.3.2.3 实际例子
struct Person {
uint8 age; /* Data ID = 0 */
uint32 salary; /* Data ID = 1 */
struct Address {
uint8 city;
uint8 street;
} addr; /* Data ID = 2 */
}数据: age=25, salary=50000, city=1, street=20
序列化过程:
| 字段 | Tag 计算 | Tag | Length | Data |
|---|---|---|---|---|
| age | Wire=0, ID=0 | 0x0000 | - | 0x19 |
| salary | Wire=2, ID=1 | 0x2001 | - | 0x0000C350 |
| addr | Wire=4, ID=2 | 0x4002 | 0x02 | 0x01 0x14 |
最终字节流如下:
00 00 19 20 01 00 00 C3 50 40 02 02 01 142.3.3 数组序列化
2.3.3.1 定长数组
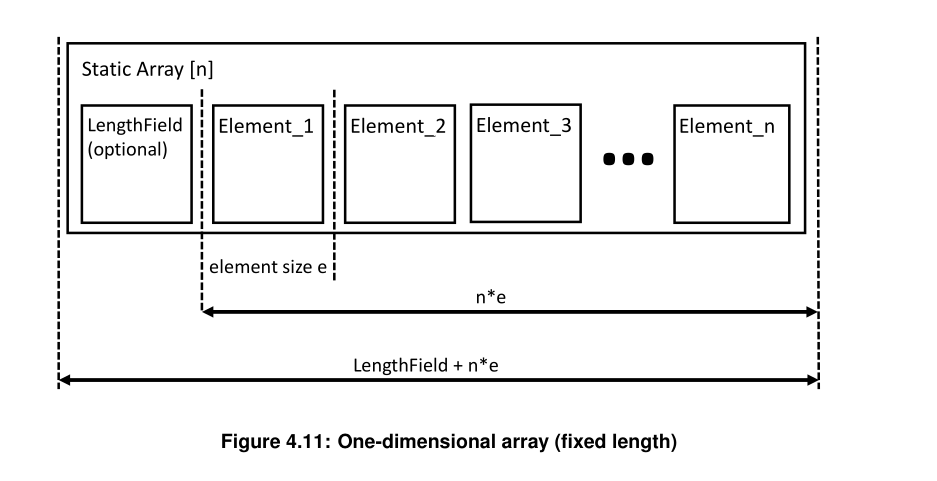
规则:
- Length 字段是可选的
- 元素数量由数据类型定义决定
2.3.3.2 变长数组
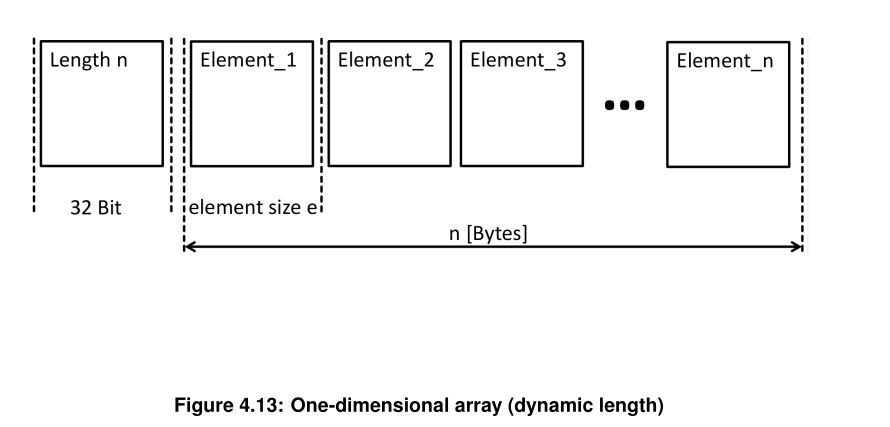
关键规则:
- Length 字段大小:0 / 8 / 16 / 32 bit(可配置,默认 32 bit)
- Length 值 = 所有元素占用的字节数
- Length 不包含自身大小
计算元素个数:
- 定长元素:元素数 = Length / 元素大小
- 变长元素:无法直接计算,必须逐个解析
2.3.3.3 多维数组(定长)
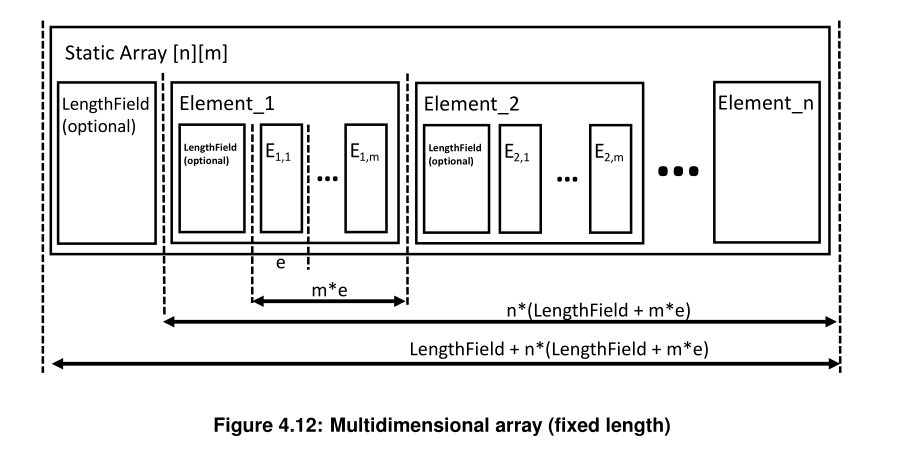
特点:
- 遵循 C/C++ 的行优先内存布局
- 每一维都可以有自己的 Length 字段 (可选)
- 总大小 = LengthField + n × (LengthField + m × e)
2.3.3.4 多维数组(变长)
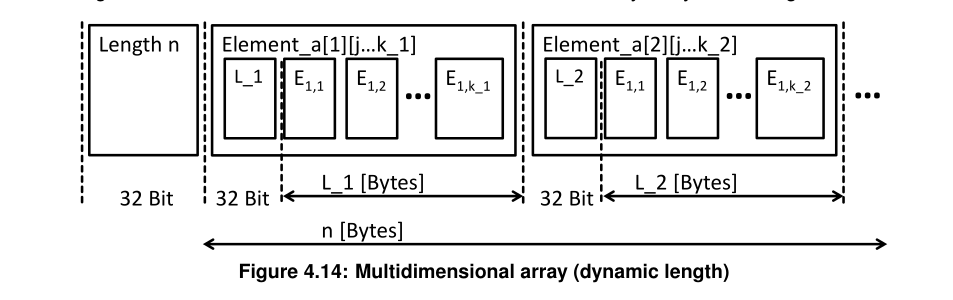
关键特性:
- 每个子数组可以有不同长度(k_1 ≠ k_2)
- 每个子数组都有自己的 Length 字段
- 外层 Length 包含所有内层数据
- 支持"锯齿数组"(Jagged Array),就是每一行长度不一样
2.3.4 枚举类型序列化
枚举 = 无符号整数,SOME/IP 不关心枚举的语义,只传输数值。序列化时当作 uint8/uint16/uint32 传输
2.3.5 定长字符串
需要在字符串最前面加上BOM,结尾加上结束标志/0。
BOM是字节序标记
| 编码 | BOM | 说明 |
|---|---|---|
| UTF-8 | 0xEF 0xBB 0xBF | 3 字节 |
| UTF-16BE | 0xFE 0xFF | 2 字节 |
| UTF-16LE | 0xFF 0xFE | 2 字节 |
2.3.6 变长字符串
变长字符串需要在最开头加上长度,然后再加上BOM,结尾加上结束标志/0
2.4 传输层绑定
SOMEIP可以通过TCP或者UDP来传输。并且一个UDP/TCP报文里面可以包含多个SOME/IP报文
2.4.1 魔法数字
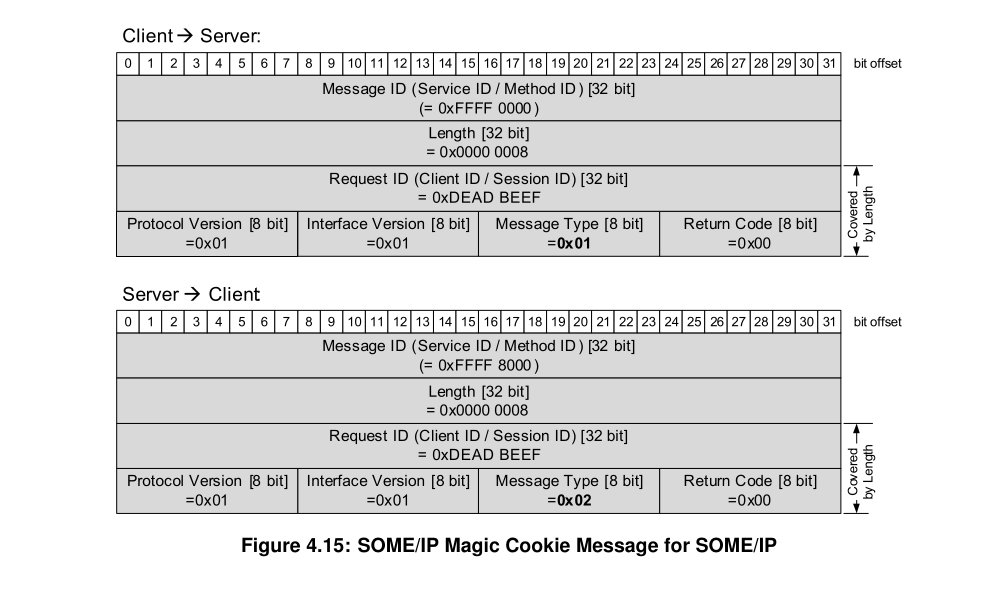
TCP 是流式协议,测试工具 如何找到 SOME/IP 消息边界? 定期插入 Magic Cookie 消息作为同步点。目的是为了调试工具中间接入的时候,知道流式数据的边界在哪里。正常通信可以不使用
魔法数据的Request ID都是0xDEAD BEEF
2.5 多服务实例
问题:同一个服务有多个实例,怎么区分?比如一辆车有 4 个车门,每个车门都提供"车门控制服务",怎么区分是哪个门?
答案:用端口号区分。同一个服务的不同服务实例不允许使用同一个端口。
文档说了一句话:为什么不使用service instance id作为区分呢?因为instanceid只会出现在someip sd报文,不会出现在someip报文里面。
2.6 SOME/IP-TP(大消息分片)
TCP有分片机制,但是TCP的分片机制慢,并且使用UDP的时候就没的用了。所以SOME/IP层也可以做分片。
SOME/IP-TP 的工作原理和TCP一样,把payload分片。
SOME/IP-TP header是在正常的SOME/IP协议报头后面加多了4 byte,前28bit是偏移值,还有三位保留值,置0,最后一位表示是否是最后一个分片(more fragment),如图:
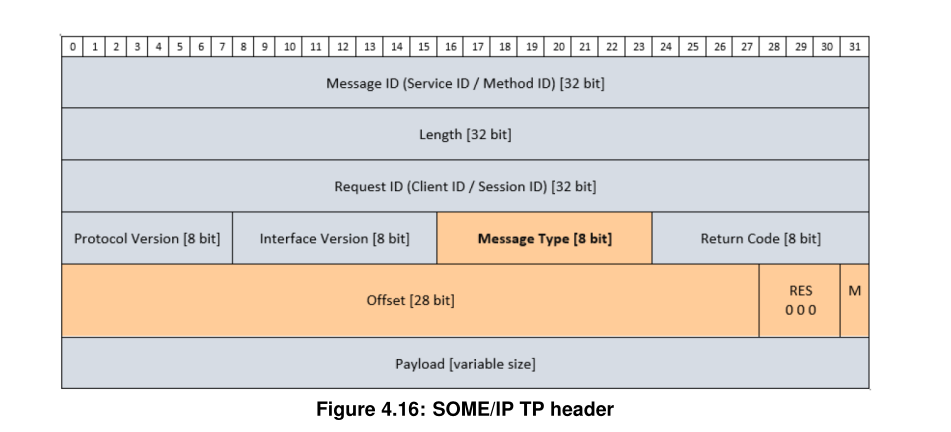
| 字段 | 大小 | 说明 |
|---|---|---|
| Offset | 28 bit | 这个分片在原消息中的偏移量(单位:16字节) |
| Reserved | 3 bit | 保留,置0 |
| More Segments (M) | 1 bit | 1=后面还有分片,0=这是最后一片 |
2.6.1 分片例子
文档 PRS_SOMEIP_00730 原文:
"UDP-based SOME/IP messages are limited to 1400 bytes payload. Due to this, the maximum length of a segment that is correctly aligned is 1392 bytes."
文档明确说明someip的payload最大不能超过1392字节。
这个1392是计算出来的,UDP说明
假设现在有一个这样的SOME/IP报文,payload大小是5880Byte,超过了文档说的1392字节,所以要分片。

分片流程如下,Length是整个报文除了Message ID+Length本身的长度。
解释一下什么是8+4+1392
- 8是Request I + protocol Version,Interface Version,Message Type,Return Code。总共8 Bytes
- 4是TP Header,占4个字节
- 1392是Payload的大小
| 分片 | Length | Offset值 | 实际偏移 | Payload | M Flag |
|---|---|---|---|---|---|
| #1 | 8+4+1392=1404 | 0 | 0 字节 | 1392 B | 1 |
| #2 | 1404 | 87 | 1392 字节 | 1392 B | 1 |
| #3 | 1404 | 174 | 2784 字节 | 1392 B | 1 |
| #4 | 1404 | 261 | 4176 字节 | 1392 B | 1 |
| #5 | 8+4+312=324 | 348 | 5568 字节 | 312 B | 0 |
所以总共分为5片。
2.6.2 分片优势对比
三种分片
TCP,IP,SOME/IP都可以做分片,他们不同的优势是什么?
| 分片方式 | 谁做的 | 特点 |
|---|---|---|
| IP 分片 | IP 层 | 自动丢一个全丢,不推荐 |
| TCP 分段 | TCP | 自动可靠传输,有重传 |
| SOME/IP-TP | SOME/IP 层 | 应用层分片,每片独立 |
SOME/IP-TP 是典型的 "UDP + 应用层增强" 模式:保留 UDP 的速度优势,只补上必要的分片能力,其他不可靠性由应用层按需处理。
2.7 methods event fields triggers的someip报文
介绍一下四种通信方式的someip报文长什么样
2.7.1 methods(RR)
Request 消息构造
| 字段 | 设置 |
|---|---|
| Message ID | 要调用的方法 ID |
| Length | 8 + Payload 长度 |
| Request | ID可选,用于匹配响应 |
| Message Type | 0x00 (REQUEST) |
| Return Code | 0x00 |
| Payload | 输入参数(按顺序序列化) |
Response 消息构造
| 字段 | 设置 |
|---|---|
| Message ID | 从 Request 复制 |
| Length | 8 + 新 Payload 长度 |
| Request | ID从 Request 复制 |
| Message Type | 0x80 (RESPONSE) 或 0x81 (ERROR) |
| Return Code | 执行结果码 |
| Payload | 输出参数(按顺序序列化) |
2.7.2 methods(FF)
Request 消息构造
| 字段 | 设置 |
|---|---|
| Message ID | 要调用的方法 ID |
| Length | 8 + Payload 长度 |
| Request | ID可选,用于匹配响应 |
| Message Type | 0x01 (REQUEST NO RETURN) |
| Return Code | 0x00 |
| Payload | 输入参数(按顺序序列化) |
没有Response
2.7.3 events
不需要client发出,没有request
| 字段 | 设置 |
|---|---|
| Message Type | 0x02 (NOTIFICATION) |
| Client ID | 0x00(不针对特定 Client) |
| Session ID | 每次发送递增(如启用) |
| Return Code | 0x00 |
2.7.4 fields
fields可能出现的报文形式就是methods+events加起来。
2.8 错误处理
SOME/IP有两种错误,一种是应用层的错误,一种是在传输的时候就报错。
| 机制 | Message Type | 适用场景 |
|---|---|---|
| Return Code | 0x80 (RESPONSE) | 应用层错误,但仍是正常响应 |
| Error Message | 0x81 (ERROR) | 严重错误,无法正常响应 |
区别:
- Return Code ≠ 0x00 但 Message Type = 0x80 . 应用层报错,但协议层正常
- Message Type = 0x81 .协议层认为是错误
这是Return code的所有值:

2.9 如何选择传输协议
文档中建议,如果要求传送速度的话,建议都选择UDP。如果要求稳定性的话,使用TCP。
特别强调了,站在数据量的角度上,如果数据量大,超过1400字节,如果要求速度,就是用someip-tp+udp。如果要求稳定,使用tcp+someip(分片由tcp来做)。
如果数据量超大,不要使用someip