前言
在现代大数据平台中,每天都有可能有数十万甚至上百万的任务在集群中运行。这些任务并非孤立存在,它们之间往往存在着严密的上下游依赖关系,经过数据加工处理,最终产出业务报表。
面对如此庞大的任务量以及错综复杂的依赖网络,如果不加以管理,这些任务就是一盘散沙,当最终的报表产出发生延迟或数据异常时,运维人员将很难快速定位及排查究竟是上游哪一个依赖任务导致了异常,这时就需要引入一个经典的数据结构------DAG(有向无环图)。
什么是DAG?
在数据结构中,图是由顶点(Vertex)和边(Edge)组成的数据结构,用G = (V, E)表示:
- V:顶点集合
- E:边集合
而DAG,即有向无环图则在图的基础上增加了有向 和无环两个关键约束,在大数据中,其三个核心属性,都对应着至关重要的物理意义:
- 图:离散任务的连通性
在大数据场景下,顶点代表一个具体的计算任务 ,边则代表任务之间的逻辑依赖,通过图结构将离散的计算单元连接成一个整体,就能通过遍历算法(如DFS/BFS)感知整个生产链路的全貌了 - 有向:数据流动的不可逆性
在大数据中,数据的处理是有序的,而DAG中的有向边,则代表了数据之间的上下游依赖关系,其方向性赋予了治理系统进行溯源 和推理的能力 - 无环:计算的有限和确定性
无环是DAG最关键的约束------图中不存在任何闭环路径。
离线批处理任务必须在有限的时间内结束,如果有环,任务用于无法完成,资源最终会被耗尽,而DAG的无环特性,保证了我们能够对复杂的任务网络进行线性排序(拓扑排序),从而精确计算每个任务的预期开始时间和结束时间
其主要的代码表现形式有两种:
- 邻接表
java
// Key:顶点
// Value:该顶点指向的所有邻接顶点集合
Map<String, Set<String>> adjacencyList = new HashMap<>();
// 例如:TaskA -> {TaskB, TaskC} 表示TaskA依赖TaskB和TaskC- 邻接矩阵
java
// 用二维数组表示
boolean[][] adjMatrix = new boolean[n][n];
// adjMatrix[i][j] = true 表示顶点i到顶点j有边|-------|--------|-------|
| 特性 | 邻接表 | 邻接矩阵 |
| 空间复杂度 | O(V+E) | O(V2) |
| 添加边 | O(1) | O(1) |
| 删除边 | O(V) | O(1) |
| 查找边 | O(V) | O(1) |
| 遍历所有边 | O(V+E) | O(V2) |
DAG与SLA的联系
在深入应用之前,首先简单了解一下什么是SLA。
在大数据平台中,SLA是服务提供方与使用方之间关于服务性能、可用性、质量等方面达成的量化承诺协议,其明确了平台提供的服务标准,以及未达到标准时的补偿。SLA核心关注的是数据时效性,主要包含三点:
- 承诺时间:业务方要求数据产出的Deadline
- 基线:为保障承诺时间,系统根据任务依赖关系划定的一条红线
- 预警:当预测完成时间超过承诺时间时,就会触发预警
由于大数据平台中报表之间的复杂关系,SLA的数据时效性高度依赖与DAG:
-
支撑复杂的依赖关系
大数据领域中,往往一个报表的执行依赖于其他报表的执行结果,比如,报表D依赖中间表B和C,而B和C又依赖原始表A。这时,就需要通过DAG强行绑定其依赖关系,只有A成功,才会启动B和C,从而建立依赖关系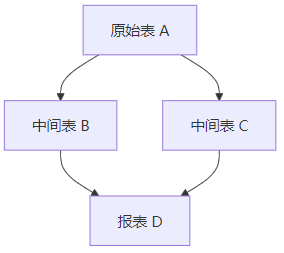
-
关键路径透明化
关键路径,即从开始到结束耗时最长 的链路,这条链路决定着整个工作流调度系统的完成时间,也是SLA承诺时间 的依据,而非关键路径的任务延迟通常不会影响最终SLA。借助任务之间的DAG结构,通过DFS/BFS就能找到关键路径,从而计算SLA的承诺时间
例如:下图是五个任务之间的依赖关系,通过DAG就不难计算出其关键路径是A→C→E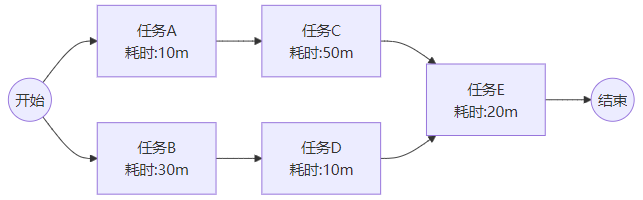
-
故障恢复快速定位
当上游任务A失败了,需要修好后重跑,如果没有DAG,则需要找到所有直接或间接依赖A的下游任务,一个个手动重跑,这在大规模数仓中,几乎是不可能的。而基于DAG构成的报表之间的血缘(Lineage),系统可以自动识别下游任务,一键重跑,从而快速定位故障节点,快速追回SLA时间
DAG在大数据SLA中的应用
DAG在SLA中的应用主要体现在三个阶段:设计期、运行期、复盘期
- SLA的倒推和承诺
这是最经典的DAG应用,业务方只关心最终报表的产出时间,而SLA的承诺时间就是利用DAG的拓扑排序和历史平均运行时长,进行逆向推导的。
假设最终节点SLA=8:00,终点任务平均耗时30分钟,那么其上有必须在7:30之前完成,如此层层递归向上推导,直到根节点,从而计算出根节点开始执行的时间。如果数据源无法在根节点最晚执行时间前就绪,也可以提前告知业务方,这个SLA承诺无法达成,需要优化代码或增加资源。 - 关键路径上的智能调度
资源永远是有限的,当资源紧张时,DAG就决定了谁先跑。
-
- Gantt 图分析: 系统识别出哪条链路是关键路径。
- 优先级调整: 位于关键路径上的任务,其优先级会被自动调高。
- 非关键路径降级 : 比如有一条旁路任务是做"数据质量监控"的,它不阻碍最终报表生成,且有 1 小时的浮动时间。当资源紧张时,调度器会暂缓该任务,把 CPU 让给关键路径任务,以保住最终 SLA。
- 动态SLA预警
传统的监控是任务失败了报警,但SLA级别的监控是:任务虽然在跑,但即使跑完也会导致最终SLA违约,所以报警。
逻辑: 当DAG运行时,会实时计算当前节点的预计完成时间 ,通过结合剩余任务历史平均耗时 以及缓冲系数 计算得出最终 预计完成时间,并与SLA承诺时间 比较,如果预计的最终完成时间超过承诺时间,就会触发SLA破线预警,从而实现动态监测和预警。 - 根因分析与血缘追踪
当SLA违约时,就需要定位分析原因,那么基于DAG,我们就可以生成甘特图 ,对比此次执行DAG 与历史基线DAG ,一眼就可以看出具体是哪个节点(Node)变长了,或者是那两个节点之间的等待时间(Gap)变长了。如果是Node变长,说明是数据量暴涨或代码逻辑问题,如果是Gap变长,说明调度延迟或资源不足
甘特图示例:
