基于 CNN 架构的通用分割模型
- [一、FastSAM(Fast Segment Anything Model):快速分割一切](#一、FastSAM(Fast Segment Anything Model):快速分割一切)
-
- [1️⃣ 模型概述](#1️⃣ 模型概述)
- [2️⃣ 核心思想:先全分割,后提示匹配](#2️⃣ 核心思想:先全分割,后提示匹配)
- [3️⃣ 模型架构:基于YOLOv8-seg构建](#3️⃣ 模型架构:基于YOLOv8-seg构建)
- [4️⃣ 可用模型 + 性能对比:FastSAM-s.pt + FastSAM-x.pt](#4️⃣ 可用模型 + 性能对比:FastSAM-s.pt + FastSAM-x.pt)
- [5️⃣ 优缺点:极致的推理速度 + 边缘分割精度不足](#5️⃣ 优缺点:极致的推理速度 + 边缘分割精度不足)
- 二、函数详解
-
- 1、加载模型:FastSAM()
- 2、模型预测:model()
-
- [2.1 基础参数 (通用)](#2.1 基础参数 (通用))
- [2.2 性能参数 (控制分割数量与质量)](#2.2 性能参数 (控制分割数量与质量))
- [2.3 提示参数 (Prompt)](#2.3 提示参数 (Prompt))
- 3、输出结果:results0
- 三、项目实战
Ultralytics YOLO 生态系统,支持目标检测、实例分割、图像分类、姿态估计和目标跟踪等任务。
一、FastSAM(Fast Segment Anything Model):快速分割一切
1️⃣ 模型概述
https://docs.ultralytics.com/zh/models/fast-sam/
FastSAM 是由中国科学院自动化研究所(CASIA-IVA-Lab)于 2023 年提出的一个基于 CNN(卷积神经网络) 架构的通用分割模型。
核心目标:(1)在保留 Meta SAM(Segment Anything Model)强大的零样本(Zero-shot)和提示(Prompt)分割能力的同时;(2)将推理速度提升到
实时(Real-time)水平。
2️⃣ 核心思想:先全分割,后提示匹配
SAM:先输入提示(点/框),模型再根据提示进行推理计算,生成 Mask。
FastSAM:先一次性把图像中所有的物体都分割出来,然后再根据用户的提示(点/框/文字)去检索出对应的 Mask。
- 流程解耦:
先全分割,后提示匹配 (Segment Everything First, Prompt Match Later)
这是 FastSAM 与 Meta SAM 最本质的区别,也是它快的根源。- 任务重构
FastSAM 认为,Meta 提出的Segment Anything(分割一切)任务,本质上并不需要发明全新的架构。
- 思想转化:FastSAM 将零样本分割任务,降维打击为传统的全类别实例分割(Class-agnostic Instance Segmentation)任务。
- 意义:这意味着我们不需要昂贵的 Transformer(ViT),直接利用工业界打磨得最成熟、速度最快的 CNN 检测器(YOLOv8) 就能完成这个任务。
- 数据即泛化
FastSAM 证明了模型的泛化能力(即能认识它是没见过的东西)并非必须源自 Transformer 的注意力机制,而是源自数据。
- 核心观点:只要模型在足够大、足够多样的数据集(SA-1B)上进行训练,即使是传统的 CNN 架构(YOLO),也能涌现出"认识万物"的泛化能力。
训练数据:仅使用 SA-1B 数据集(SAM 的数据集)中的 2%(约 1100 万张图)进行训练,就达到了与 SAM 相当的性能。
3️⃣ 模型架构:基于YOLOv8-seg构建
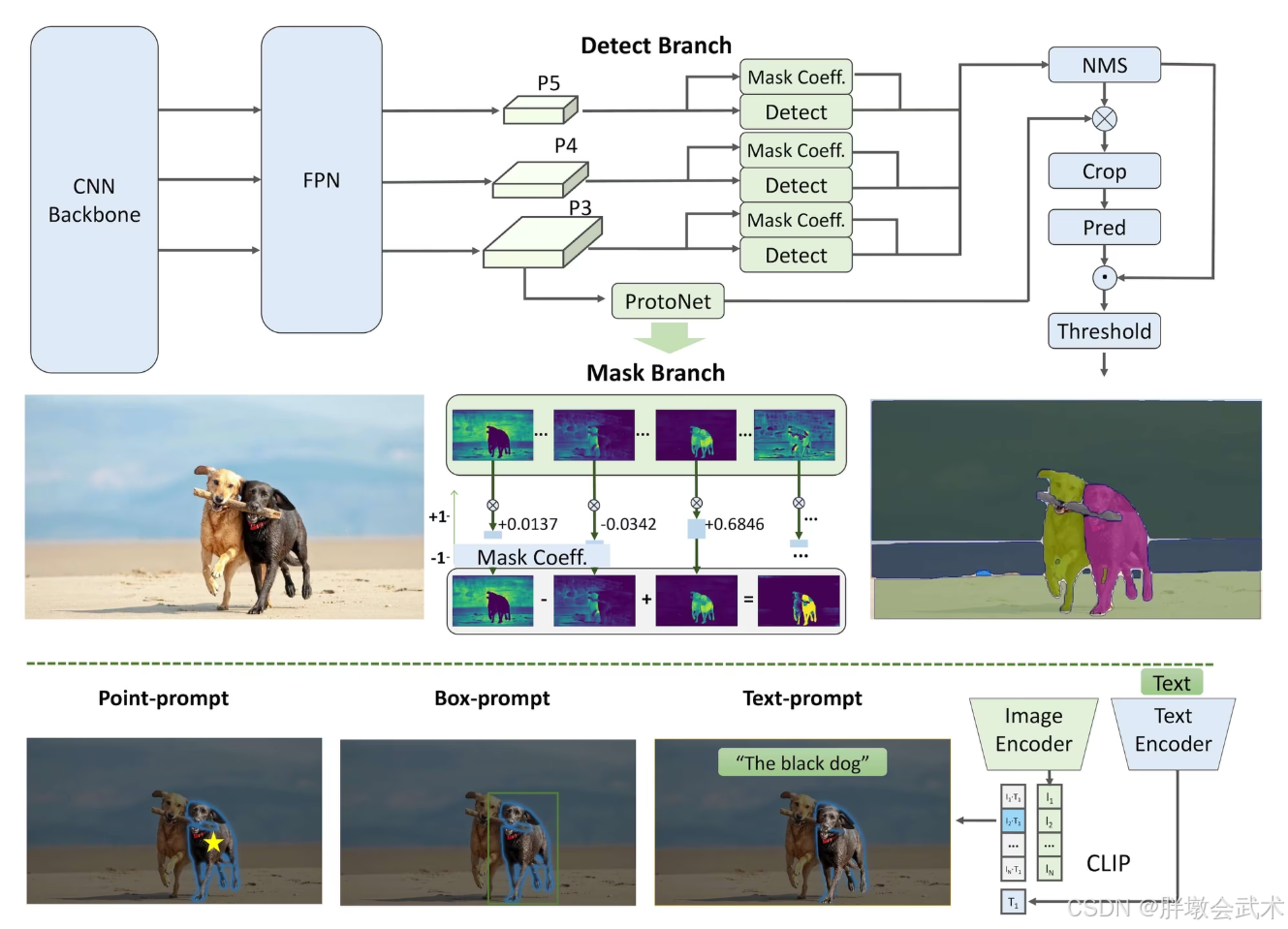
FastSAM 没有使用 Meta SAM 沉重的 Vision Transformer (ViT) 架构,而是基于 YOLOv8-seg 构建:
FastSAM 是一个 CSPDarknet 骨干 + PANet 特征融合 + YOLACT 风格解耦头 的纯 CNN 架构,通过后处理逻辑实现对任意提示的响应。
- 网络主体架构:负责处理图像并输出所有的分割掩码(Masks)
- A.
CNN Backbone (骨干网络)
- 结构 :CSPDarknet53 (配合 C2f 模块)
- 功能:负责从输入图像中提取特征
- 核心改进 :使用 C2f 模块 (Cross Stage Partial bottleneck with 2 convolutions)替代了 YOLOv5 中的 C3 模块。
- 作用:提供了更丰富的梯度流,在保持轻量化的同时增强了特征提取能力。
- B.
Neck (颈部网络)
- 结构:PANet (Path Aggregation Network)
- 功能:多尺度特征融合
- 原理 :结合了
FPN(特征金字塔)的自顶向下路径和 PAN 的自底向上路径。- 作用:将深层的高级语义特征(识别物体是什么)和浅层的空间特征(定位物体边缘)进行融合,确保模型既能分割大物体,也能保留小物体细节。
- C.
Head (检测与分割头)
FastSAM 采用了 Decoupled Head (解耦头) 设计,并结合了 YOLACT 分割思想。它包含两个并行的分支:
- 检测分支 (
Detect Branch)
- 负责输出 Bounding Box (边界框) 和 类别置信度。
- 注意: 在 FastSAM 中,类别通常被视为"前景"通用类别。
- 关键输出 : 同时输出一组
Mask Coefficients (掩码系数),每个Detect检测框对应一组系数(向量)。- 分割分支 (
Mask Branch)
- 功能 :通过
ProtoNet生成 Prototype Masks (原型掩码)。- 原理 :这是一个全卷积分支,输出一组 k k k 个(通常是 32 个)原始的、未裁剪的原型掩码图。这些原型图就像是构建图像的基础"积木"。
- 最终 Mask 生成
- 模型通过线性组合 来生成最终 Mask: M a s k = σ ( ∑ ( P r o t o t y p e × C o e f f i c i e n t s ) ) Mask = \sigma (\sum (Prototype \times Coefficients)) Mask=σ(∑(Prototype×Coefficients))
- 【检测分支输出的"系数"】
加权组合【分割分支输出的"原型"】,最后裁剪到 Bounding Box 区域内,得到最终的物体 Mask。- 提示处理架构:不涉及神经网络的前向传播,而是基于逻辑的后处理算法。
- 输入:第一阶段生成的全图 Mask 集合 + 用户的提示(Point/Box/Text)。
- 点提示 (Point-based)
- 使用逻辑矩阵操作,筛选出包含该点坐标的 Mask。
- 框提示 (Box-based)
- 计算用户画的框与模型预测的所有框(或 Mask 边界框)的 IoU (交并比),选择 IoU 最高的目标。
- 文本提示 (Text-based)
- 引入外部的
CLIP 模型- 将每个 Mask 裁剪下来送入 CLIP
Image Encoder,并通过Text Encoder计算其与用户文本 Embeddings 的相似度,选择最匹配的 Mask。
4️⃣ 可用模型 + 性能对比:FastSAM-s.pt + FastSAM-x.pt
| 对比维度 | FastSAM-s.pt |
FastSAM-x.pt |
|---|---|---|
| 1. 含义与定位 | Small (轻量版/小型模型) 主打极致速度和低算力需求,牺牲了部分精度。 | Extra Large (超大版/超大模型) 主打极致精度,是 FastSAM 系列里的"最强大脑"。 |
| 2. 参数量 (Parameters) | 约 1,200 万 (11.2M) 参数较少,网络结构相对简单。 | 约 6,800 万 (68.2M) 参数量巨大,网络深且宽,特征提取能力强。 |
| 3. 权重文件大小 | 约 22 MB 非常轻巧,便于网络传输和部署。 | 约 138 MB 体积较大,包含更多特征信息。 |
| 4. 推理速度 | 🚀 极快 (可达 100+ FPS) 计算量小,推理飞快,适合高帧率需求。 | 🐢 较慢 (通常 < 30 FPS) 相比 -s 版本,推理耗时可能增加 5-10 倍。 |
| 5. 显存与硬件需求 | 📉 很低 (2GB 显存足够) 普通的消费级显卡(甚至 CPU)都能跑得动。 | 📈 较高 (建议 6GB+ 显存) 需要较好的独立显卡才能跑得顺畅,否则容易 OOM。 |
| 6. 分割精度 | ⭐⭐⭐ (够用) 对于复杂场景、遮挡严重物体或微小细节,效果可能比较粗糙,边缘可能不够贴合。 | ⭐⭐⭐⭐⭐ (精细) 分割的边缘更精细,对物体轮廓的捕捉非常准确,抗干扰能力更强。 |
| 7. 小物体检测能力 | 容易漏检 由于下采样和参数限制,容易忽略极小的目标。 | 效果较好 具有更强的特征保留能力,对小物体(Small Objects)的召回率更高。 |
| 8. 适用场景 | 1. 实时视频处理 :如摄像头监控流。 2. 边缘设备部署 :如树莓派、Jetson Nano、手机端 APP。 3. 简单场景:物体较大且背景干净的任务。 | 1. 医学图像分割 :处理病灶小、对比度低的任务。 2. 离线数据处理 :不追求实时,只追求标注质量。 3. 高分辨率图片:需要保留丰富细节的场景。 |
| 9. 医学分割特别建议 | ⚠️ 一般不推荐 除非你的任务是实时的(如术中导航)且设备算力极差,否则容易漏掉微小病灶(False Negative)。 | ✅ 强烈推荐 医学病灶通常很小且模糊,必须用精度最高的 -x 版本,哪怕它跑得慢一点,也要保证不漏诊。 |
5️⃣ 优缺点:极致的推理速度 + 边缘分割精度不足
| 分类 | 核心维度 | 详细说明 |
|---|---|---|
| ✅ 优点 (Pros) | 1. 极致的推理速度 (Real-time Speed) | • 毫秒级响应 :相比 Meta SAM 秒级的推理时间,FastSAM 可达到毫秒级。 • 高帧率 :在 NVIDIA T4 显卡上可达 50~100 FPS ,完全满足自动驾驶、工业流水线等实时性要求极高的场景。 • 原理:不需要对每个 Prompt 重复运行繁重的 Encoder。 |
| 2. 极低的算力门槛 (Low Hardware Req) | • 架构优势 :基于 CNN (YOLOv8),计算效率远高于基于 Transformer (ViT) 的模型。 • 部署灵活 :不需要 A100 级昂贵显卡,在普通消费级 GPU(如 RTX 3060)、甚至 CPU 和边缘设备(如 Jetson Nano)上都能运行。 | |
| 3. 工业部署友好 (Easy Deployment) | • 生态成熟 :底层是标准的 YOLO 架构,非常容易通过 TensorRT 、ONNX、OpenVINO 等工具进行加速和移植,工程落地难度极低。 | |
| 4. 零样本泛化能力 (Zero-shot) | • 数据驱动:得益于使用 SA-1B(SAM 的数据集)进行训练,继承了"认识万物"的能力,在未见过的物体上表现依然稳健。 | |
| ❌ 缺点 (Cons) | 1. Mask 数量硬性限制 ⚠️ (重点关注) | • 机制缺陷 :采用"先全检测,后筛选"逻辑,必须在推理前预设最大检测数(max_det,默认 300)。 • 严重后果 :如果图中物体极其密集(如细胞、人群)且数量超过预设值,或者在 NMS(非极大值抑制)阶段被过滤,这些物体在第一阶段就会直接消失 。 • 不可挽回:一旦第一阶段漏掉,后续无论用户如何点击提示,模型都无法召回该物体。 |
| 2. 边缘精细度不足 (Lower Edge Precision) | • 原因 :YOLO 架构在特征提取时进行多次卷积下采样(Downsampling),导致空间分辨率损失。 • 表现 :生成的 Mask 边缘通常比较粗糙 ,甚至带有锯齿感,无法像 Meta SAM 那样做到像素级的完美贴合。 | |
| 3. 小物体召回率低 (Small Object Issues) | • 细节丢失 :在面对极小目标(如远处的飞鸟、微小病灶)时,CNN 的感受野机制容易丢失细节,导致漏检。 • 医学场景 :这也是为什么在医学分割中通常建议使用 -x 大模型并调低置信度阈值的原因。 |
|
| 4. 对超参数敏感 (Hyperparameter) | • 调参依赖 :效果高度依赖 conf(置信度)和 iou(交并比)阈值。 • 两难困境 :conf 太高会漏检;conf 太低会产生大量噪点 Mask,不仅拖慢后处理速度,还会挤占宝贵的 max_det 名额。 |
二、函数详解
1、加载模型:FastSAM()
这是类的构造函数,用于实例化 FastSAM 模型对象。
- 功能:加载模型结构,并将预训练权重(Weights)加载到内存或显存中。
- 返回值 :返回一个
FastSAM模型实例对象。
python
from ultralytics import FastSAM
# 🏗️ 实例化模型对象
# 参数:
# model: 权重文件路径 ('FastSAM-x.pt' 或 'FastSAM-s.pt')
model = FastSAM(model='FastSAM-x.pt')2、模型预测:model()
在 Python 中,调用 model(...) 等同于调用 model.predict(...)。它负责图像预处理、前向传播、NMS 后处理以及提示(Prompt)匹配。
- 功能:对输入源进行推理,返回结果列表。
- 返回值 :一个包含
Results对象的列表(List),列表长度等于输入图片的数量。
python
# 🚀 执行推理
results = model(
# --- 基础参数 ---
source='path/to/image.jpg', # 输入源 (图片路径/数组/URL)
device='cuda', # 设备 ('cuda', 'cpu', '0')
imgsz=1024, # 输入尺寸 (建议: 1024 以保留细节)
# --- 阈值控制 ---
conf=0.25, # 置信度阈值 (越低召回越多)
iou=0.7, # NMS 阈值 (越低去重越严格)
max_det=300, # 最大目标数 (建议: 修改为 1000+)
# --- 质量控制 ---
retina_masks=True, # True=高分辨率平滑 Mask; False=低分辨率
# --- 提示参数 (可选,互斥) ---
# points=[[200, 300]], labels=[1], # 点提示
# bboxes=[[10, 10, 200, 200]], # 框提示
# texts=['a dog'], # 文本提示
)2.1 基础参数 (通用)
| 参数名 | 类型 | 默认值 | 详细说明 |
|---|---|---|---|
source |
str / np.array |
必填 | 输入源。可以是图片路径、图片文件夹、URL、视频路径、或者 OpenCV 读取的 Numpy 数组。 |
device |
str |
None |
运行设备。例如 'cuda:0' (GPU), 'cpu', 'mps' (Mac)。如果不填,会自动选择最佳设备。 |
imgsz |
int / tuple |
640 |
输入图像尺寸 。模型会将图片缩放(Padding)到这个尺寸再推理。对于小物体或高精度任务,建议设为 1024。 |
stream |
bool |
False |
是否使用流式加载。处理长视频或大量图片时建议设为 True 以节省内存(返回生成器)。 |
2.2 性能参数 (控制分割数量与质量)
| 参数名 | 类型 | 默认值 | 详细说明 |
|---|---|---|---|
conf |
float |
0.25 |
置信度阈值 (0.0~1.0)。低于此分数的检测框会被丢弃。想要召回更多物体,请降低此值 (如 0.1)。 |
iou |
float |
0.7 |
NMS 交并比阈值 (0.0~1.0)。用于去除重叠框。数值越小,去除重叠越严格;数值越大,允许重叠越多。 |
max_det |
int |
300 |
最大检测数量 。一张图最多保留多少个目标。这是 FastSAM 的数量瓶颈,建议手动改为 1000 或更高。 |
retina_masks |
bool |
False |
高分辨率掩码 。如果为 True,返回原图大小的高清 Mask(边缘更平滑);如果为 False,返回低分辨率 Mask(速度快但边缘有锯齿)。 |
2.3 提示参数 (Prompt)
这些参数用于第二阶段的"筛选",如果不传这些参数,默认执行"全图分割"。
| 参数名 | 类型 | 示例 | 详细说明 |
|---|---|---|---|
points |
list |
[[200, 300]] |
点提示 。坐标列表 [x, y]。 |
labels |
list |
[1] |
点标签 。配合 points 使用。1 表示前景点(选中),0 表示背景点(排除)。 |
bboxes |
list |
[[10, 10, 100, 100]] |
框提示 。格式为 [xmin, ymin, xmax, ymax]。 |
texts |
list |
['a dog'] |
文本提示。使用 CLIP 模型寻找匹配文本描述的 Mask。 |
3、输出结果:results0
因为 model() 支持批量预测(一次传入多张图),所以返回值是一个列表 。results[0] 代表提取列表中的第一个 结果对象(即 ultralytics.engine.results.Results 类)。
- 功能:存储单张图片的所有推理数据(Masks, Boxes, Probs, Original Image)。
- 常用属性与方法:
python
# 📦 处理单张结果
# results 是列表,必须通过索引 [0] 获取单张图的对象
result = results[0]
# --- 常用方法 ---
result.show() # 🖥️ 屏幕弹窗显示结果
result.save(filename='out.jpg') # 💾 保存可视化结果到本地
res_plotted = result.plot() # 🖌️ 返回绘制好的 BGR 图片数组 (供 OpenCV 使用)| 属性名 | 类型 | 详细说明 |
|---|---|---|
result.masks |
Masks 对象 |
最重要的数据 。包含所有的分割掩码数据。详见下表 Masks 结构。 |
result.boxes |
Boxes 对象 |
包含对应的边界框坐标、置信度 (.conf)、类别索引 (.cls)。 |
result.orig_img |
numpy.ndarray |
原始输入的图像数据(未缩放前的),通常是 OpenCV 格式 (H, W, C)。 |
result.names |
dict |
类别名称字典。例如 {0: 'person', 1: 'bicycle'...}。FastSAM 通常只有一个通用类别或 COCO 类别。 |
result.path |
str |
该图片的文件路径。 |
result.plot() |
conf=True |
绘图 。返回一个绘制了 Mask 和 Box 的 numpy 数组(BGR 格式),可直接用 OpenCV 显示。 |
result.show() |
无 | 弹窗显示。直接调用系统窗口显示推理结果(调试用)。 |
result.save() |
filename='res.jpg' |
保存。将绘制好的结果保存到本地磁盘。 |
result.cpu() |
无 | 将结果数据从 GPU 移动到 CPU(方便转 Numpy 处理)。 |
result.numpy() |
无 | 将结果转为 Numpy 格式。 |
当你调用 result.masks 时,你操作的是 ultralytics.engine.results.Masks 对象:
| 子属性/方法 | 类型 | 详细说明 |
|---|---|---|
masks.data |
Tensor |
原始掩码张量 。形状通常是 [N, H, W],其中 N 是检测到的物体数量。这是二进制掩码(0或1)。 |
masks.xy |
list |
返回每个 Mask 的轮廓坐标点(多边形点集),方便做后续几何计算。 |
masks.xyn |
list |
返回归一化(0~1)后的轮廓坐标点。 |
三、项目实战
https://github.com/CASIA-LMC-Lab/FastSAM
1、环境配置
python
# 创建虚拟环境
conda create -n seg_env python=3.10 -y
conda activate seg_env
################################################################################
# 安装PyTorch
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu
################################################################################
# 安装Ultralytics(清华源)
pip install --upgrade ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
# 其他依赖(清华源)
pip install numpy opencv-python matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple2、下载模型
Ultralytics YOLO框架会自动从该存储库下载所需的预训练模型(如果本地未找到)。
自动下载过程特点:
- 无需额外配置;
- 默认从Ultralytics官方Hub下载;
- 权重下载一次后会缓存,后续加载速度快;
- 若指定自定义训练的本地权重路径,则不会触发下载。
模型权重托管在 GitHub 的 ultralytics/assets 仓库。手动下载过程(速度更快):
- 进入:https://github.com/ultralytics/assets/releases,在搜索框输入:
yoloe-11s-seg.pt- 下载该文件后,放到你的工作目录,例如:
D:\yoloe\yoloe-11s-seg.pt- 然后代码中:
model = YOLOE("yoloe-11s-seg.pt")- 即可直接运行。
3、模型预测
python
# Run inference with bboxes and points and texts prompt at the same time
results = model(source, bboxes=[439, 437, 524, 709], points=[[200, 200]], labels=[1], texts="a photo of a dog")
(1)全图分割
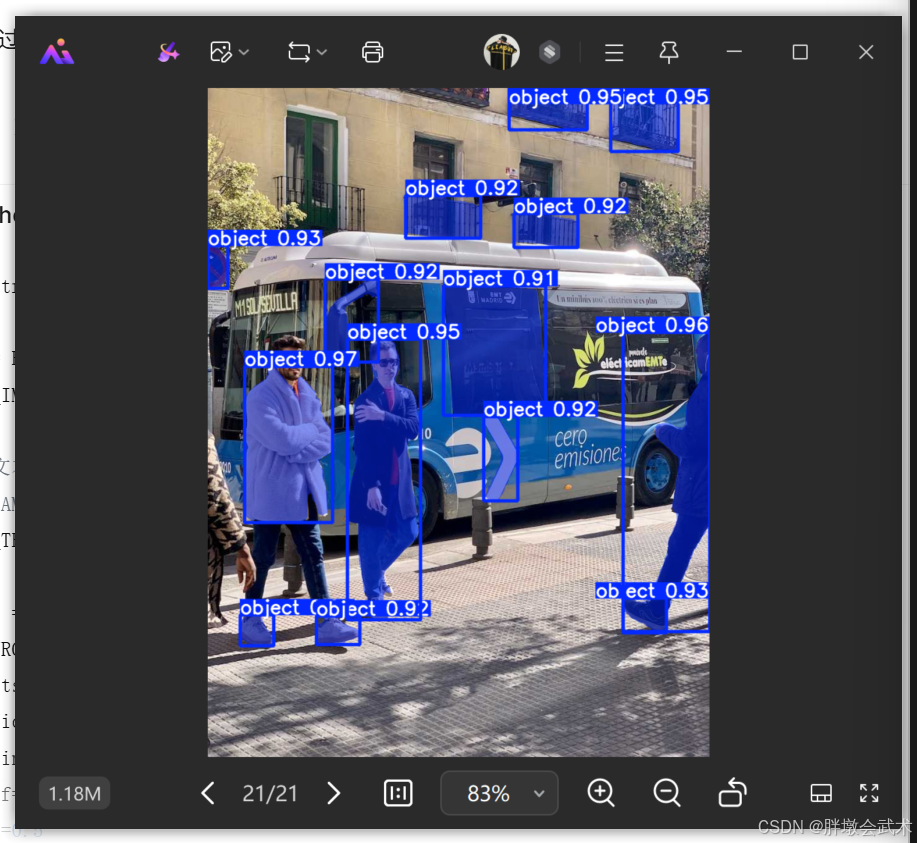
python
from ultralytics import FastSAM
model = FastSAM('FastSAM-x.pt') # 加载模型
SOURCE_IMAGE = 'https://ultralytics.com/images/bus.jpg' # 示例图片 URL
results = model(
SOURCE_IMAGE, # 输入图片
device='cpu', # 使用 CPU 进行推理
retina_masks=True, # 使用高分辨率 Mask,边缘更精细
imgsz=640, # 输入尺寸,表示图片会被缩放到 640x640
conf=0.90, # 置信度阈值,值越高,检测框越少
iou=0.1, # NMS IOU 阈值,值越高,检测框越少
max_det=1000 # 最大检测框数量,默认值为 300
)
result = results[0] # 取第一张图片的结果
result.show() # 显示结果
result.save(filename='result_everything.jpg') # 保存结果在图像上运行推理,(1)获得所有segment results(2)多次运行提示推理,而无需多次运行推理。
python
from ultralytics.models.fastsam import FastSAMPredictor
# Create FastSAMPredictor
overrides = dict(conf=0.25, task="segment", mode="predict", model="FastSAM-s.pt", save=False, imgsz=1024)
predictor = FastSAMPredictor(overrides=overrides)
# Segment everything
everything_results = predictor("ultralytics/assets/bus.jpg")
# Prompt inference
bbox_results = predictor.prompt(everything_results, bboxes=[[200, 200, 300, 300]])
point_results = predictor.prompt(everything_results, points=[200, 200])
text_results = predictor.prompt(everything_results, texts="a photo of a dog")(2)框提示分割(Box Prompt)
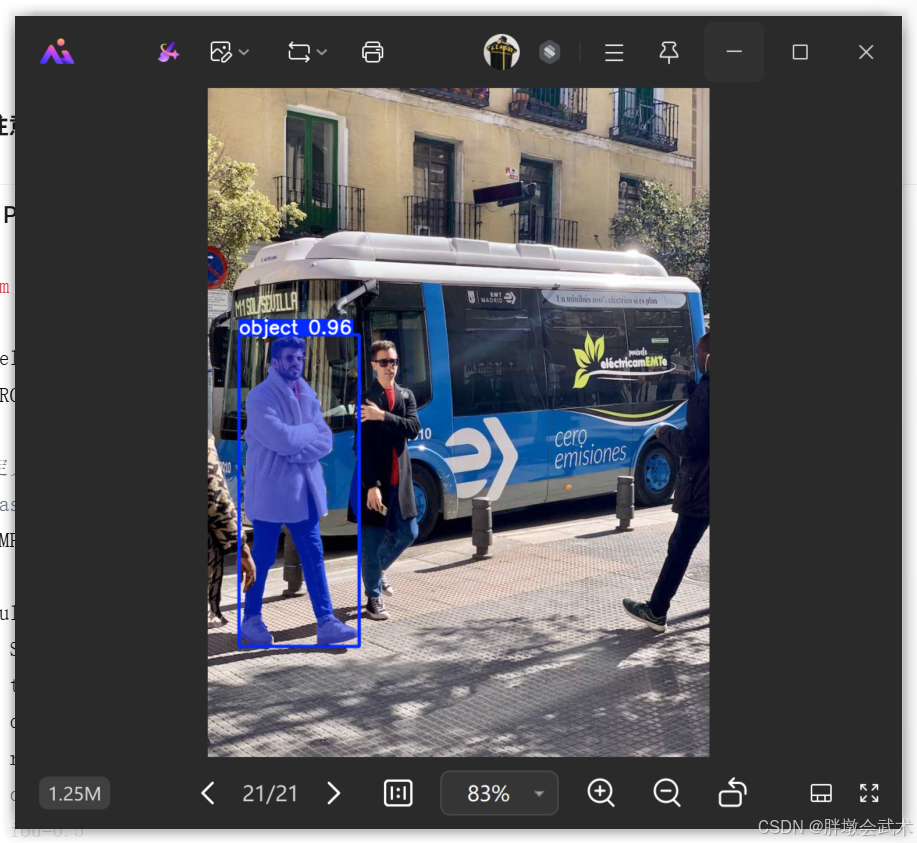
python
from ultralytics import FastSAM
# 加载模型
model = FastSAM('FastSAM-x.pt')
SOURCE_IMG = 'https://ultralytics.com/images/bus.jpg'
# 定义提示框 [x1, y1, x2, y2]
PROMPT_BOX = [25, 400, 450, 900]
# 运行推理
results = model(
SOURCE_IMG,
bboxes=[PROMPT_BOX], # 传入框坐标
device='cpu',
retina_masks=True,
conf=0.4
)
# 显示/保存结果
results[0].show()
results[0].save(filename='result_box.jpg')
print("✅ 框提示分割完成")(3)点提示分割(Point Prompt)
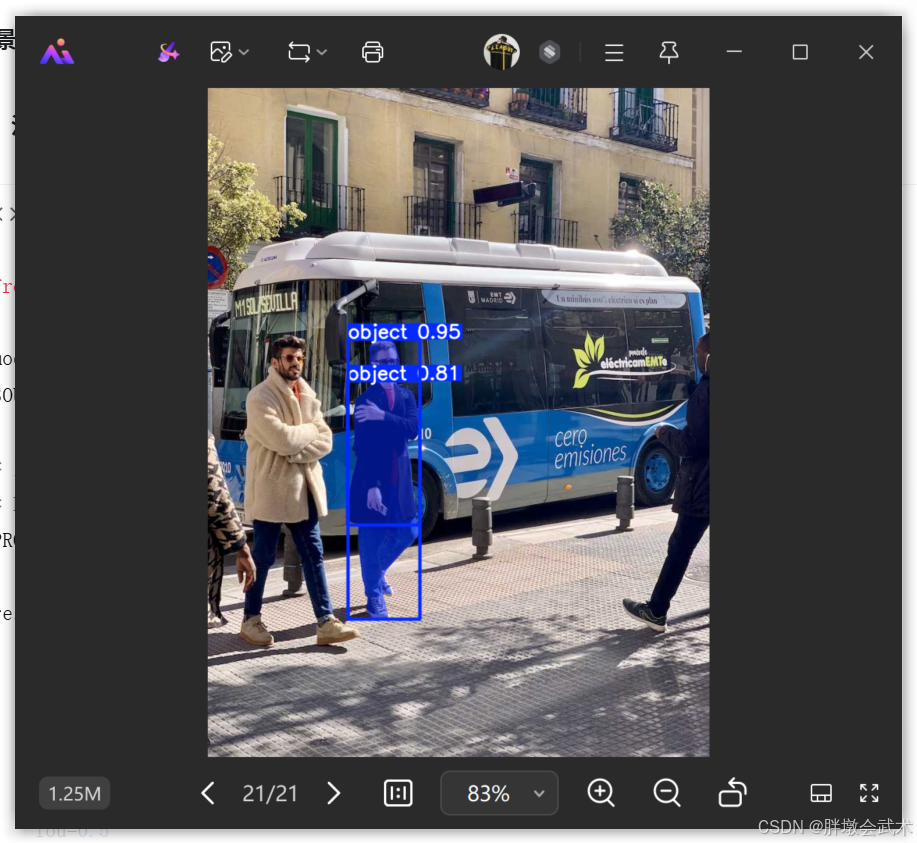
python
from ultralytics import FastSAM
model = FastSAM('FastSAM-x.pt')
SOURCE_IMG = 'https://ultralytics.com/images/bus.jpg'
# 定义提示点 [x, y] 和 标签
# 这里的点大致位于穿西装的人身上
PROMPT_POINT = [[300, 600]]
PROMPT_LABEL = [1] # 1表示这是我想选的目标
results = model(
SOURCE_IMG,
points=PROMPT_POINT,
labels=PROMPT_LABEL,
device='cpu',
retina_masks=True,
conf=0.4
)
results[0].show()
results[0].save(filename='result_point.jpg')
print("✅ 点提示分割完成")(4)文本提示分割(Text Prompt)
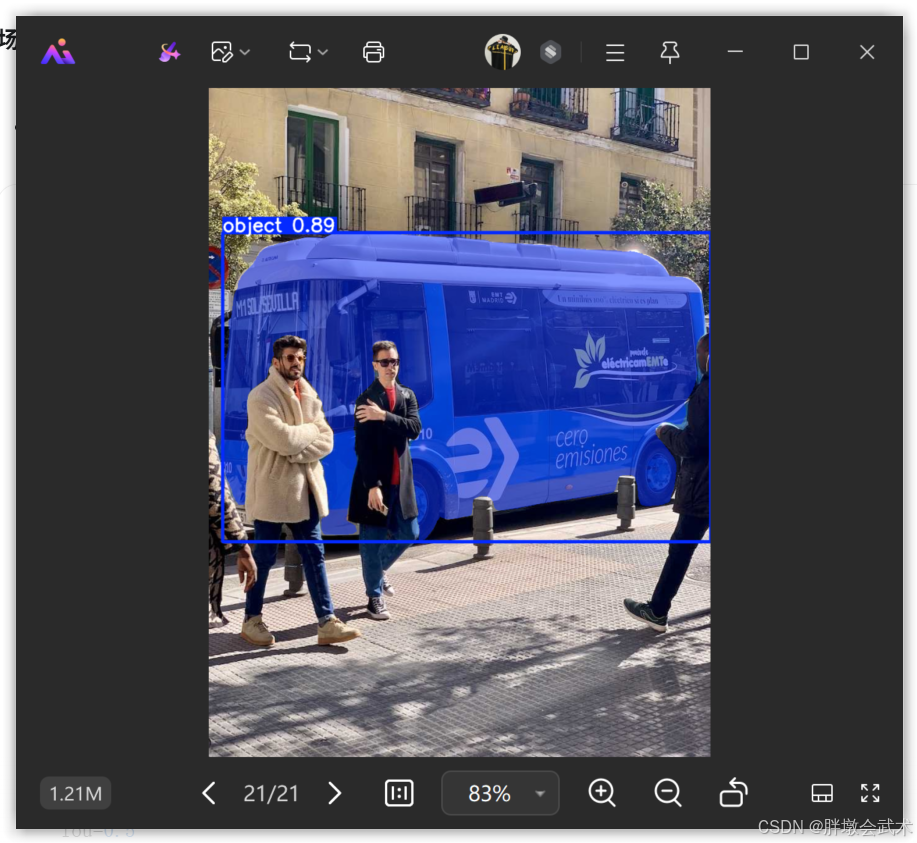
python
from ultralytics import FastSAM
model = FastSAM('FastSAM-x.pt')
SOURCE_IMG = 'https://ultralytics.com/images/bus.jpg'
# 定义文本提示
# FastSAM 会自动计算文本与图像区域的相似度
PROMPT_TEXT = "a red bus" # 尝试分割"一辆红色的巴士"
results = model(
SOURCE_IMG,
texts=[PROMPT_TEXT],
device='cpu',
retina_masks=True,
conf=0.4,
iou=0.5
)
results[0].show()
results[0].save(filename='result_text.jpg')
print(f"✅ 文本提示 '{PROMPT_TEXT}' 分割完成")