本文档为伪分布式大数据环境(1台虚拟机:hadoop)中Spark组件的功能测试教程,涵盖Spark依赖服务启停、WebUI访问验证及Python交互模式验证等核心测试场景。严格遵循视频操作流程,详细说明每个步骤的操作要点、执行命令及预期结果,助力高效完成Spark组件可用性及基础交互功能验证。
一、前期准备:环境基础信息
测试前需确认环境配置符合要求,避免因基础环境问题导致测试流程中断:
- 虚拟机配置:1台虚拟机(命名为hadoop),已完成伪分布式的Hadoop部署
- 系统账号:优先使用hertz账号(密码:hertz);特殊操作需使用root账号(密码:1)
- 工具准备:Mobaxterm远程连接工具(已安装并可正常使用)、本地浏览器(如Chrome、Edge)
二、Spark测试详细步骤
步骤1:确认虚拟机启动状态
操作说明:启动虚拟机,等待系统加载完成,直至出现登录页面。
预期结果:虚拟机正常启动,显示系统登录界面,无启动报错。
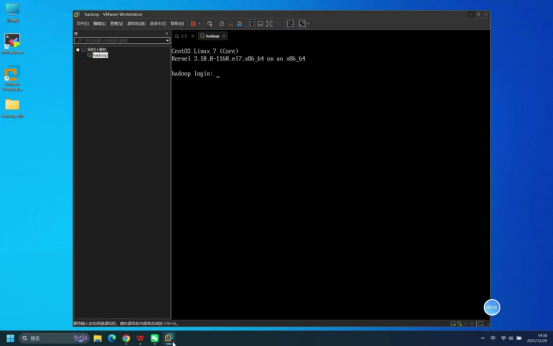
步骤2:使用Mobaxterm连接虚拟机
操作说明:打开本地Mobaxterm工具,按照伪分布式部署教程中的详细步骤建立与虚拟机的远程连接。
核心操作要点:
- 新建远程连接,选择SSH连接方式
- 输入虚拟机IP地址(需提前确认正确)
- 选择登录账号类型(默认为普通用户)
预期结果:Mobaxterm连接成功,进入连接等待登录状态。
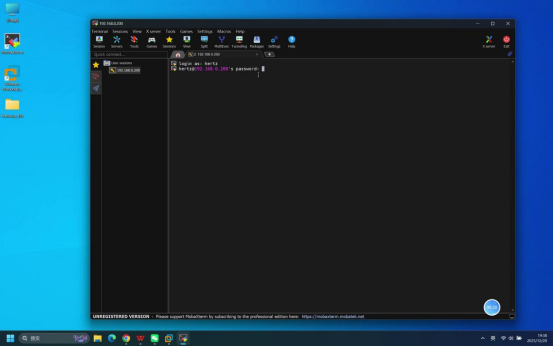
步骤3:输入账号密码完成登录
操作说明:在Mobaxterm连接成功后的登录界面,依次完成账号和密码输入。
具体操作:
- 当终端显示账号输入提示时,输入:hertz
- 回车后,终端显示密码输入提示,输入:hertz(密码输入时默认不显示明文)
- 再次回车确认
预期结果:登录成功,终端界面显示当前登录用户及主机信息(如hertz@hadoop \~$)。
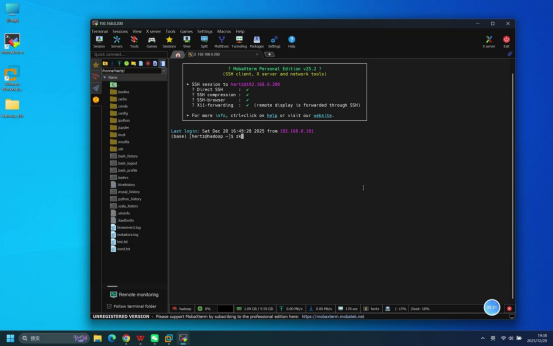
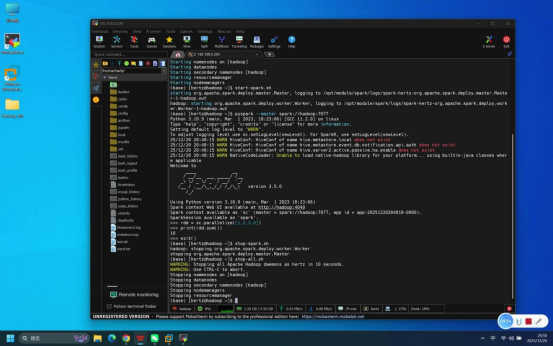
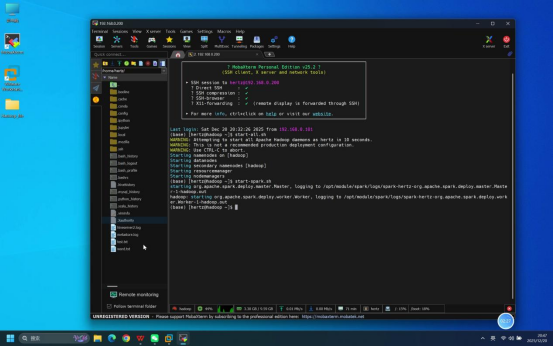
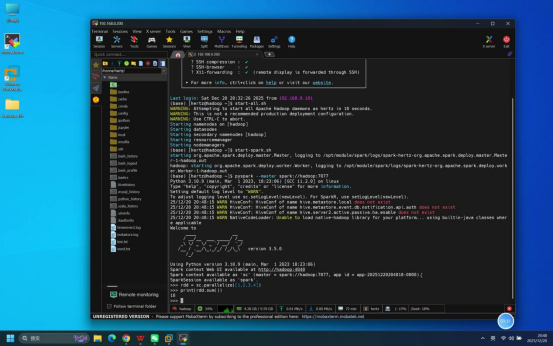
步骤4:启动Spark相关服务
操作说明:在登录成功的Mobaxterm终端中,按依赖顺序启动相关服务(先启动基础依赖服务,再启动Spark服务)。
具体命令:
- 启动Hadoop服务:start-all.sh
- 启动Spark服务:start-all.sh(Spark伪分布式环境一键启动命令,含Spark Master和Worker服务)
说明:启动过程中若出现权限提示,直接回车确认即可;需等待前一个服务启动完成(无报错)后,再执行下一个启动命令。
预期结果:所有服务启动无报错,终端依次显示各服务(QuorumPeerMain、NameNode、DataNode、ResourceManager、NodeManager、Master、Worker等)的启动日志信息。
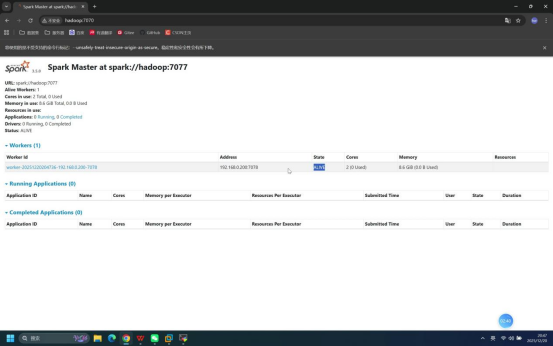
步骤5:浏览器访问Spark WebUI
操作说明:打开本地浏览器,输入Spark WebUI访问地址,验证Spark Master服务状态。
具体操作:
- 打开浏览器(如Chrome)
- 地址栏输入:hadoop:7070
预期结果:浏览器成功加载Spark WebUI页面,显示Spark Master节点信息、Worker节点状态(伪分布式下为1个Worker)、集群资源使用情况等,无服务异常提示。
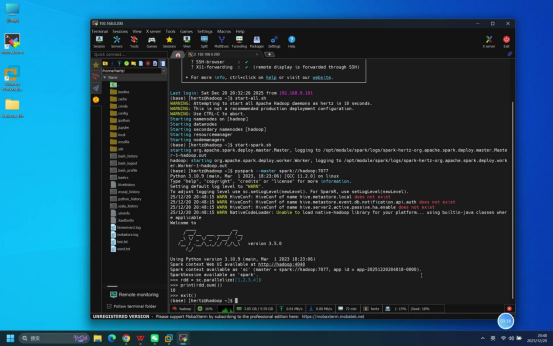
步骤6:Python交互模式验证
操作说明:回到Mobaxterm终端,启动Spark Python交互模式,执行简单命令验证交互功能可用性。
具体操作:
- 启动Python交互模式:在终端输入命令:pyspark --master spark://hadoop:7077
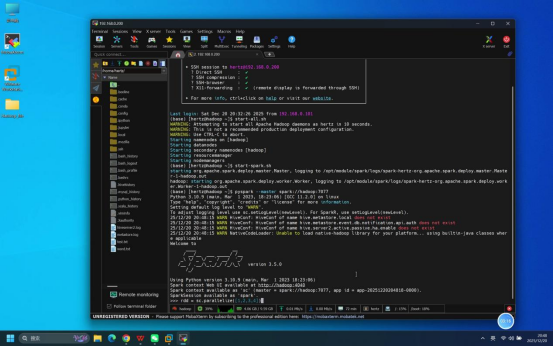
- 简单功能验证:交互模式启动成功后,输入测试命令:rdd = sc.parallelize(1,2,3,4) 和 print(rdd.sum())
- 退出交互模式:验证完成后,输入命令:exit() 退出Python交互模式
步骤7:关闭Spark相关服务
操作说明:测试完成后,在终端中按与启动相反的顺序关闭所有相关服务,避免资源占用或数据损坏。
具体命令:
- 关闭Spark服务:stop-all.sh(Spark伪分布式环境一键关闭命令)
- 关闭Hadoop服务:stop-all.sh
预期结果:所有服务均正常关闭,无报错提示。