问题
现在需要从Amazon Glue Data Catalog定时T+1聚合查询结果保存到MySQL中。
准备可以读写的数据库连接
首先登录mysql,创建拥有读写的数据库用户:
sql
create database 用户名 default character set utf8mb4 collate utf8mb4_unicode_ci;
create user '用户名'@'%' identified by '密码';
grant all privileges on 数据库名.* to '用户名'@'%';
flush privileges;准备好数据库之后,然后,我们在 AWS Glue中创建数据库连接。可以参考这篇文章:AWS中国云中的ETL之从aurora搬数据到s3(Glue版)
准备一个mysql测试表
sql
# glue写入数据调试空表
CREATE TABLE debug_table_01 (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增主键,用于追踪数据行',
job_run_id VARCHAR(100) COMMENT 'Glue作业的Run ID,用于区分每次运行',
source_column_1 VARCHAR(255) COMMENT '示例字段1,模拟字符串数据',
source_column_2 INT COMMENT '示例字段2,模拟整数数据',
source_column_3 DECIMAL(10, 2) COMMENT '示例字段3,模拟金额或浮点数据',
processed_at DATETIME DEFAULT (CONVERT_TZ(NOW(), '+00:00', '+08:00')) COMMENT '数据写入时间,自动记录'
) COMMENT='用于接收AWS Glue或Athena写入结果的调试表';创建AWS Glue任务
开始创建Glue 任务
这个纯代码的ETL任务,就是pyspark实现。
设置ETL数据库连接
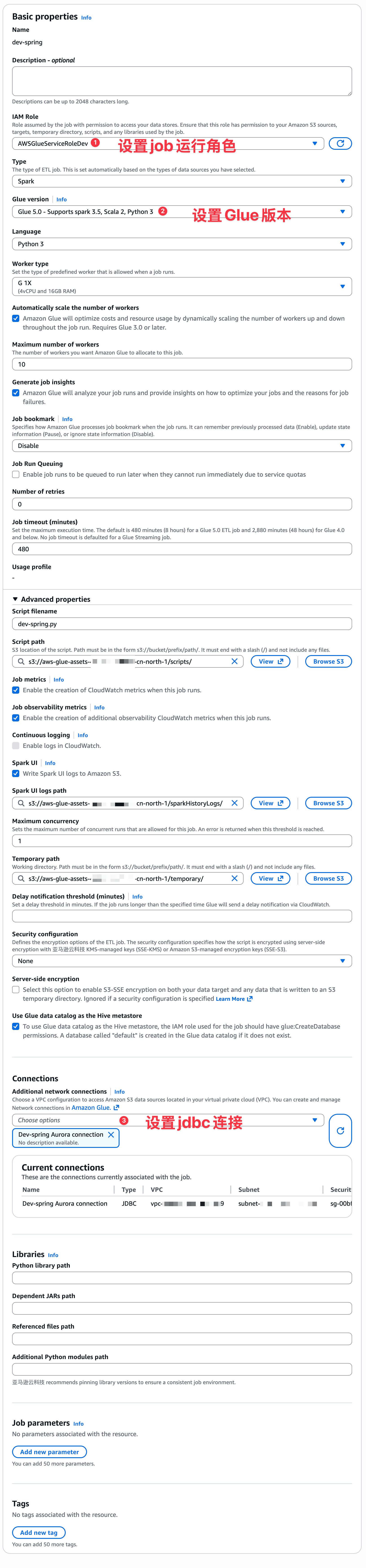
这里主要是设置数据库连接和运行job角色。
pyspark实现
python
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import DynamicFrame
def sparkSqlQuery(glueContext, query, mapping, transformation_ctx) -> DynamicFrame:
for alias, frame in mapping.items():
frame.toDF().createOrReplaceTempView(alias)
result = spark.sql(query)
return DynamicFrame.fromDF(result, glueContext, transformation_ctx)
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Script generated for node dev-Amazon Glue Data Catalog
devAmazonGlueDataCatalog_node1769417028575 = glueContext.create_dynamic_frame.from_catalog(database="dev_hf_gc", table_name="my_table_name", transformation_ctx="devAmazonGlueDataCatalog_node1769417028575")
# Script generated for node SQL Query
SqlQuery0 = '''
SELECT
-- id 字段是自增主键,由MySQL自动生成,这里不插入
'glue-job-run-001' as job_run_id, -- 模拟一个作业ID
'test_string' as source_column_1, -- 模拟字符串数据
100 as source_column_2, -- 模拟整数数据
999.99 as source_column_3 -- 模拟金额数据
-- processed_at 字段有默认值,由MySQL自动生成,这里不插入
FROM myData
LIMIT 5 -- 先只插入5条测试数据,避免意外写入大量数据
'''
SQLQuery_node1769417077264 = sparkSqlQuery(glueContext, query = SqlQuery0, mapping = {"myData":devAmazonGlueDataCatalog_node1769417028575}, transformation_ctx = "SQLQuery_node1769417077264")
glueContext.write_dynamic_frame_from_options(
frame=SQLQuery_node1769417077264,
connection_type="mysql",
connection_options = {
"useConnectionProperties": "true",
"dbtable": "debug_table_01",
"connectionName": "Dev-spring Aurora connection"
}
)
job.commit()这里就是模拟从AWS Glue Data Catalog中读取到数据后,然后,通过jdbc连接写入数据到mysql数据库中。