联邦学习入门指南 --- Part 2:核心挑战与安全机制
🛡️ 从"可用"到"可靠":构建鲁棒的联邦系统
🎯 目标 :深入理解联邦学习在实际部署中面临的统计挑战、通信瓶颈以及隐私防御技术
💡 核心:如何在数据非独立同分布 (Non-IID) 和潜在攻击下保持模型的收敛与安全
📋 目录
- 1. 最大的统计挑战:Non-IID 数据
- 2. 通信瓶颈与效率优化
- 3. 隐私泄露风险:梯度真的安全吗?
- 4. 三大防御技术体系 (DP, HE, MPC)
- 5. 系统异构性与掉队者问题
- 6. 实战代码演示:添加差分隐私噪声
1. 最大的统计挑战:Non-IID 数据
在传统机器学习中,我们假设数据是 IID (独立同分布) 的。但在联邦学习中,数据是由不同用户在不同设备上生成的,天生具有异构性。这是联邦学习面临的首要数学挑战。
1.1 什么是 Non-IID (非独立同分布)?
- 特征分布倾斜:不同用户对同一事物的描述方式不同(如手写字体的笔画粗细、角度)。
- 标签分布倾斜:不同用户拥有的数据类别完全不同。
- User A 的相册里只有"猫"和"狗"。
- User B 的相册里只有"汽车"和"风景"。
1.2 Non-IID 带来的后果
如果直接对 Non-IID 数据使用标准的 FedAvg 算法,会导致模型权重发散 (Weight Divergence)。
- 现象:客户端 A 的梯度指向"左",客户端 B 的梯度指向"右"。
- 结果 :服务器聚合后的模型不仅没有优化,反而震荡,导致精度大幅下降甚至无法收敛。
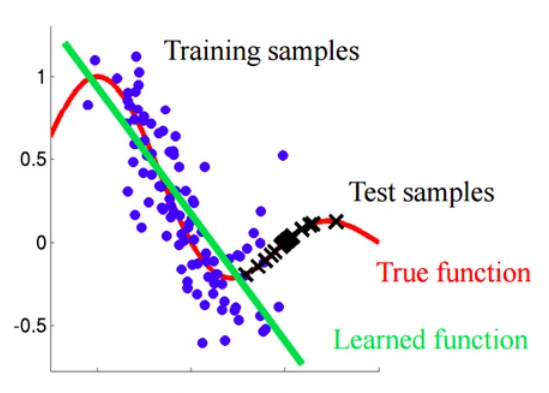
1.3 解决方案逻辑
- FedProx:在损失函数中增加正则项,限制本地模型偏离全局模型太远。
- 数据共享:服务器下发一小部分公开的 IID 数据集给客户端进行混合训练(需权衡隐私)。
2. 通信瓶颈与效率优化
联邦学习需要在成千上万个设备与服务器之间传输模型参数。现代深度神经网络(如 Transformer)参数量动辄数亿,带宽消耗巨大。
2.1 为什么是瓶颈?
- 上行带宽受限:边缘设备(手机、IoT)的上传速度通常远低于下载速度。
- 高频交互:模型可能需要数千轮迭代才能收敛。
2.2 压缩技术
为了减少传输的数据量,通常采用以下策略:
- 梯度量化 (Quantization) :
将 32位浮点数 (float32) 压缩为 8位整数 (int8) 甚至二值化 (1-bit),精度损失微小但体积缩小 4-32 倍。 - 稀疏化 (Sparsification) :
仅上传数值较大的梯度(主要信息),抛弃接近于 0 的微小更新。
3. 隐私泄露风险:梯度真的安全吗?
误区 :"我不上传原始数据,只上传梯度,所以绝对安全。"
现实 :梯度包含了原始数据的分布信息,攻击者可以通过反向工程恢复出原始图像或文本。
3.1 梯度泄露攻击 (Gradient Leakage)
深度学习模型的梯度计算公式为 。如果攻击者(即便是恶意的中心服务器)掌握了模型结构和客户端上传的梯度 ,可以通过优化算法反解出输入数据 。
- 深度泄露 (Deep Leakage from Gradients):通过不断调整虚拟输入数据,使其产生的梯度与真实梯度一致,从而还原出用户的私密照片。
3.2 成员推理攻击 (Membership Inference)
攻击者可以判断某条特定的数据记录(如某人的病历)是否被用于训练该模型。
4. 三大防御技术体系 (DP, HE, MPC)
为了防御上述攻击,联邦学习引入了密码学和统计学手段构建"隐私护盾"。
4.1 差分隐私 (Differential Privacy, DP)
-
原理 :在客户端上传梯度前,人为加入符合特定分布(如高斯分布、拉普拉斯分布)的随机噪声。
-
逻辑:噪声掩盖了单条数据的贡献,使得攻击者无法反推具体数据,但统计规律依然保留。
-
代价:模型精度会有所下降(隐私与精度的权衡)。
4.2 同态加密 (Homomorphic Encryption, HE)
- 原理 :允许服务器直接在密文上进行聚合运算(加法/乘法),运算结果解密后与明文运算结果一致。
- 特点:服务器全程看不见梯度的真值,计算安全性极高。
- 代价:计算复杂度极高,会显著增加训练时间。
4.3 安全多方计算 (Secure Multi-Party Computation, MPC)
- 原理:将梯度拆分成多个碎片 (Secret Sharing),分发给不同的服务器。任何单一服务器都无法还原完整信息,只有多方协作才能计算出聚合结果。
5. 系统异构性与掉队者问题
在现实部署中,参与方设备的硬件能力千差万别。
- 掉队者 (Stragglers):某些设备计算能力弱或网络差,导致无法按时完成训练。
- 同步阻塞 :在标准的同步联邦学习中,服务器必须等待所有被选中的客户端完成上传才能进行聚合。一个"掉队者"会拖慢整个系统。
解决方案:
- 异步联邦学习 (Asynchronous FL):服务器一旦收到更新就立即聚合,无需等待所有节点(但可能引入模型过时问题)。
- 客户端选择 (Client Selection):优先选择计算能力强、网络稳定且电量充足的设备参与训练。
6. 实战代码演示:添加差分隐私噪声
基于 Part 1 的代码,我们在客户端上传环节增加高斯噪声,演示最基础的 DP 保护逻辑。
python
import torch
class SecureClient:
def __init__(self, local_data, privacy_sigma=0.01):
self.local_data = local_data
self.model = init_model()
self.sigma = privacy_sigma # 噪声强度
def train_and_protect(self, global_weights):
# 1. 加载全局参数
self.model.load_state_dict(global_weights)
# 2. 本地常规训练
optimizer = torch.optim.SGD(self.model.parameters(), lr=0.01)
for x, y in self.local_data:
loss = calculate_loss(self.model(x), y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 3. 获取真实梯度/参数更新
true_update = self.model.state_dict()
# 4. 关键步骤:添加差分隐私噪声 (Differential Privacy)
protected_update = {}
for name, param in true_update.items():
# 生成与参数形状相同的高斯噪声
noise = torch.normal(mean=0.0, std=self.sigma, size=param.size())
# 将噪声注入参数
protected_update[name] = param + noise
# 5. 上传加噪后的参数
return protected_update
# --- 运行逻辑 ---
# 即使服务器截获了 protected_update,也难以通过微小的梯度变化反推原始数据 x
# 因为噪声掩盖了那部分细微的特征贡献🎉祝你天天开心,我将更新更多有意思的内容,欢迎关注!
最后更新:2026年1月
作者:Echo