YOLOv26原理分析及训练实战代码
一、YOLOv26性能比较
1.1简介
YOLOv26,也称YOLO26,是由ultralytics团队在2025年9月发布,而在2026年1月公开源码。也许是出于版本号冲突的考虑,ultralytics团队发布的这一版YOLO版本号并没有延续之前的v11、v12、v13系列,而是以年份26命名。
Github源码地址为:https://github.com/ultralytics/ultralytics
与ultralytics团队提出的上一个YOLO版本YOLOv11不同,此次的YOLOv26有相应的论文介绍,论文地址为:https://arxiv.org/abs/2509.25164
1.2MSCOCO数据集表现
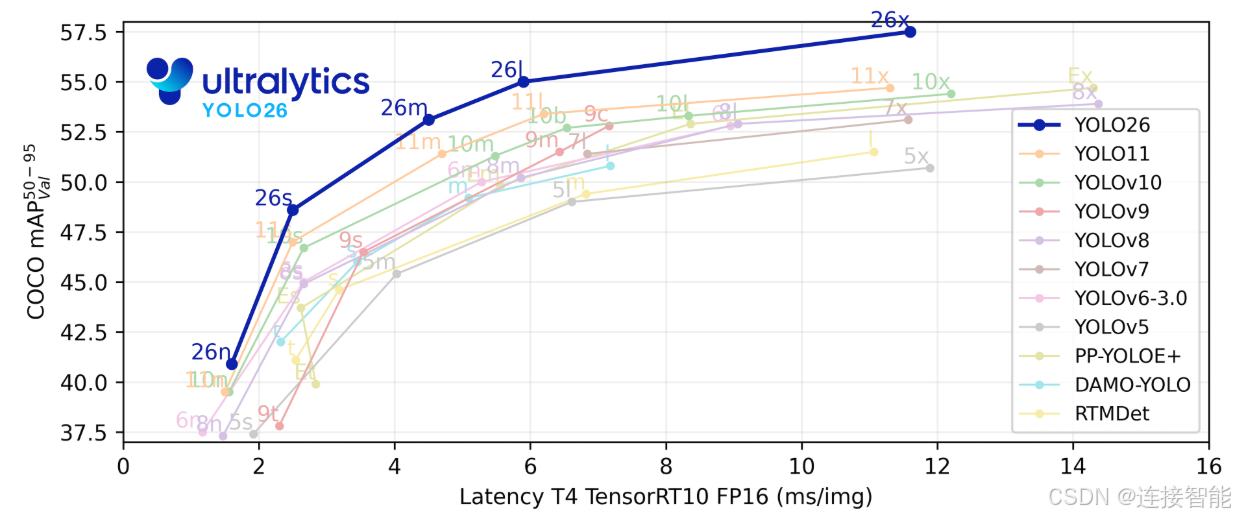
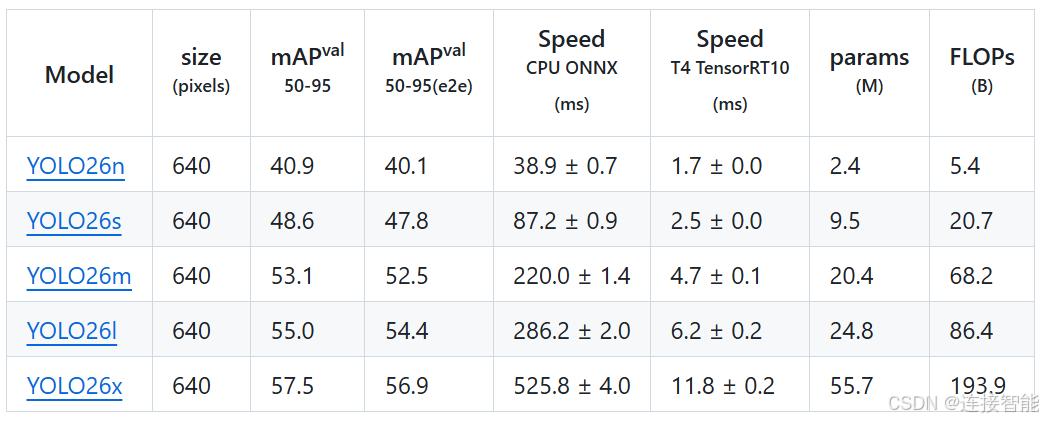
YOLOv26同样有n/s/m/l/x五种规模的模型,参数量以及在MSCOCO数据集上的表现如下:
1.3对比YOLOv11、v12、v13
1.3.1mAP50-95
在MSCOCO数据集上的mAP50-95,对比如下表:
| 模型规模 | YOLOv11 | YOLOv12 | YOLOv13 | YOLOv26 | YOLOv26(e2e) |
|---|---|---|---|---|---|
| n | 39.5 | 40.4 | 41.6 | 40.9 | 40.1 |
| s | 47.0 | 47.6 | 48.0 | 48.6 | 47.8 |
| m | 51.5 | 52.5 | ------ | 53.1 | 52.5 |
| l | 53.4 | 53.8 | 53.4 | 55.0 | 54.4 |
| x | 54.7 | 55.4 | 54.8 | 57.5 | 56.9 |
可以看到,在不使用e2e模式即不移除NMS的情况下,除了n规模下v26性能低于v13,其余4种规模相对于v11、v12、v13都有了一个比较大的提升幅度。
而在使用e2e模式即移除NMS的情况下,v26在5种规模下都优于v11。在n、s、m三种规模下接近或低于v12与v13,而在l、x规模下,对比v12、v13精度有明显的提升。
1.3.2参数量与计算浮点数
参数量(M)对比如下表:
| 模型规模 | YOLOv11 | YOLOv12 | YOLOv13 | YOLOv26 |
|---|---|---|---|---|
| n | 2.6 | 2.5 | 2.5 | 2.4 |
| s | 9.4 | 9.1 | 9.0 | 9.5 |
| m | 20.1 | 19.6 | ------ | 20.4 |
| l | 25.3 | 26.5 | 27.6 | 24.8 |
| x | 56.9 | 59.3 | 64.0 | 55.7 |
计算浮点数(GFLOPs)对比如下表:
| 模型规模 | YOLOv11 | YOLOv12 | YOLOv13 | YOLOv26 |
|---|---|---|---|---|
| n | 6.5 | 6.0 | 6.4 | 5.4 |
| s | 21.5 | 19.4 | 20.8 | 20.7 |
| m | 68.0 | 59.8 | ------ | 68.2 |
| l | 86.9 | 82.4 | 88.4 | 86.4 |
| x | 194.9 | 184.6 | 199.2 | 193.9 |
从表中可看出,n、s、m规模下v26参数量接近或略高于v11~v13,而l和x规模的v26参数量略低于v11,明显低于v12 ~ v13。
计算浮点数,v26整体略低于v11,介于v12与v13之间。
二、YOLOv26训练与评估
2.1模型安装
根据Github页面说明,v26要求python≥3.8,pytorch≥1.8,要求与v11一致,没有其他特殊的依赖包要求。
推荐使用如下命令,将源码下载到本地,然后执行训练代码,根据提示缺少哪些依赖包,然后进行安装:
bash
git clone https://github.com/ultralytics/ultralytics.git2.2模型训练
2.2.1训练代码
训练示例代码如下,读者可进行安装环境测试,也可以对coco.yaml修改,添加自己的数据集进行训练:
python
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolo26n.yaml')
# Train the model
results = model.train(
data='coco.yaml',
epochs=50,
batch=32,
imgsz=256,
optimizer='SGD',
scale=0.5,
mosaic=1.0,
mixup=0.0,
copy_paste=0.1,
device="0",
)上述代码指定:使用sgd优化器,批次大小32,图像统一调整到256×256,训练50个迭代。
scale、mosaic、mixup、copy_paste参数是数据增强的一些设置,device指定使用的显卡id,如只有一块显卡,则为0。
2.2.2训练参数
coco.yaml设置了使用数据集的路径,文件位于ultralytics\ultralytics\cfg\datasets\coco.yaml,如果使用其他数据集,要进行修改。
需要注意的是上述代码中模型配置文件yolo26n.yaml文件其实是yolo26.yaml文件,n是指定使用的模型规模,文件位于ultralytics\ultralytics\cfg\models\26,内容如下:
yaml
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO26 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo26
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
end2end: True # whether to use end-to-end mode
reg_max: 1 # DFL bins
scales: # model compound scaling constants, i.e. 'model=yolo26n.yaml' will call yolo26.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 260 layers, 2,572,280 parameters, 2,572,280 gradients, 6.1 GFLOPs
s: [0.50, 0.50, 1024] # summary: 260 layers, 10,009,784 parameters, 10,009,784 gradients, 22.8 GFLOPs
m: [0.50, 1.00, 512] # summary: 280 layers, 21,896,248 parameters, 21,896,248 gradients, 75.4 GFLOPs
l: [1.00, 1.00, 512] # summary: 392 layers, 26,299,704 parameters, 26,299,704 gradients, 93.8 GFLOPs
x: [1.00, 1.50, 512] # summary: 392 layers, 58,993,368 parameters, 58,993,368 gradients, 209.5 GFLOPs
# YOLO26n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5, 3, True]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO26n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, True]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, True]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, True]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 1, C3k2, [1024, True, 0.5, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)模型配置文件中相较以往yolo模型多出了两个参数,分别为end2end和reg_max。
end2end可设置为True和False,设置为True时不使用NMS进行后处理,即端到端模式,此时会明显提高模型预测速度,但会造成精度下降,具体影响程度读者可进行测试。
reg_max设置为1时,表示禁用 DFL。
2.2.3预训练文件与Arial字体文件
首次训练,yolov26会尝试下载预训练文件与Arial字体文件,如果网络存在问题,建议手动下载,然后复制到对应文件夹。
例如yolo26n.pt,应复制到代码同目录下。
而Arial.ttf字体文件,windows系统中应复制到%APPDATA%\Ultralytics,Linux系统中应复制到/root/.config/Ultralytics
2.3模型评估
模型评估示例代码如下:
python
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("best.pt")
metrics = model.val(
data="custom.yaml",
#imgsz=640,
batch=128,
iou=0.45,
plots=True
)评估代码中几个重要参数如下:
- data参数指定评估的数据集配置文件,一般与训练时使用的数据集配置文件相同;
- imgsz指定评估的图片尺寸,当不设置该参数时,模型会使用训练时输入的图片尺寸进行评估;
- iou指定预测框重叠的iou阈值,一般该值越小模型性能会更优,而训练时默认iou值为0.7,当评估时设置iou低于0.7时会发现模型性能较训练时有所提升,这是在使用NMS的情况下。
三、YOLOv26原理与结构分析
3.1概述
YOLOv26与之前的YOLO系列有所不同,它将模型改进的方向从模块的改进转向了检测流程、损失函数及优化器的改进,并且将改进的重心放在了推理预测速率的提高上,针对边缘低功耗低算力设备,简化部署和提高推理速度。
具体来说YOLOv26有四大改进:
- 去除DFL(Distribution Focal Loss);
- 取消NMS(非极大值抑制),直接输出最终结果;
- 使用ProgLoss (Progressive Loss Balancing)和STAL(Small-Target-Aware Label Assignment),使训练更稳定,提高小目标检测能力;
- 提出MuSGD优化器,融合了SGD与Muon两个优化器的优势,能够达到更快更稳定的收敛。
3.2去除DFL
DFL模块,是使用离散概率分布表示边界框坐标,首先预测坐标位于16个区间的概率,然后对16个概率值进行归一化处理,最后计算期望值作为预测的坐标。
DFL的引入提高了目标框的预测精度,但也带来了计算成本和模型导出困难。
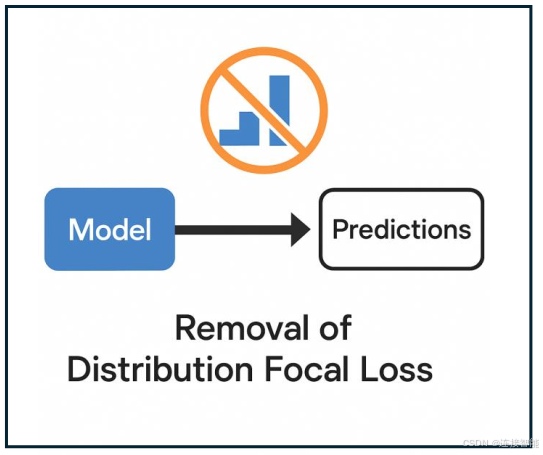
YOLOv26去除了DFL模块,采用直接回归的方式,从而提高了推理速度,降低了模型部署的难度。
而根据对比结果,YOLOv26实现了相近甚至更优的正确率。
3.3端到端推理取消NMS
以往的YOLO系列模型,模型预测输出要经过NMS进行后处理,才能得到最终输出,后处理约占据总预测时间的1/3到2/3,而且需要调整超参数如IoU阈值才能获得理想的结果。
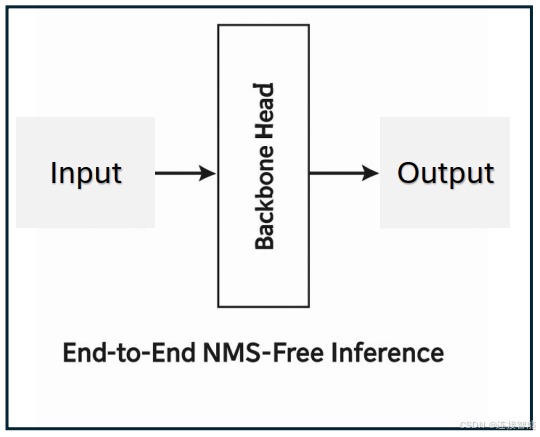
YOLOv26重新设计了预测head,使模型直接输出无冗余的预测框,从而也就不需要NMS进行预测框过滤,减少了预测时间,当然也带来了些许的精度损失。
3.4ProgLoss+STAL
ProgLoss (Progressive Loss Balancing),渐进式损失平衡策略,能够动态调整不同损失分量的权重,确保模型不会过拟合于训练样本数量多的目标类别,也不会忽视样本数量少的目标类别。
这种渐近式损失平衡策略,能够提高模型泛化性和预防训练后期的不稳定性。
STAL(Small-Target-Aware Label Assignment),小目标感知标签分配策略,能够优先小目标的标签分配,避免小目标因有限像素表征和被遮挡导致检测困难。
ProgLoss+STAL,使得YOLOv26在包含小目标或被遮挡的目标的数据集上,正确率有明显的提高。
3.5MuSGD优化器
MuSGD优化器是SGD与Muon优化器结合而来。
SGD(Stochastic Gradient Descent)优化器,核心思想是随机梯度下降算法,在以往的YOLO系列以及计算机视觉领域中较为常见。
而Muon(Momentum Orthogonalized by Newton-Schulz)优化器,核心思想是利用牛顿--舒尔茨迭代对梯度动量进行正交化处理,是用在LLM(large language model)训练中,即自然语言处理领域。
Muon优化器专门针对神经网络隐藏层的二维权重参数设计,在每次参数更新前,对梯度更新矩阵进行近似正交化处理,从而改善优化动力学,加速训练收敛。
据论文中所说,两者结合使得YOLOv26在更少的训练迭代获得了具有竞争力的正确率,从而减少了训练时间和计算成本。