做遥感影像最烦的就是数据标签,大部分遥感影像数据基本在公开数据集都找不到(除了DOTA的),就算有也是只有图片没有标签文件,所以意思就是遥感数据集obb旋转框标签必须我们手动自己打,这里讲一下怎么加快效率
一、数据集获取
【去公开数据集网站】
关于【ground track field田径场 + soccer ball field足球场】、【harbor港口】、【bridge桥梁】这些图片都有公开数据集获取https://opendatalab.com/OpenDataLab/ADVANCE/explore/main?dir=%2Fraw%2FADVANCE_vision.zip%2Fvision%2Fsports%20land&ds=1782&pageNo=1&pageSize=30&row=4&showAnnotation=truehttps://opendatalab.com/OpenDataLab/ADVANCE/explore/main?dir=%2Fraw%2FADVANCE_vision.zip%2Fvision%2Fsports%20land&ds=1782&pageNo=1&pageSize=30&row=4&showAnnotation=true
https://aistudio.baidu.com/datasetdetail/117006https://aistudio.baidu.com/datasetdetail/117006
等等,可以自己去查
【自己爬虫】
关于个别目标比如【roundabout环岛】的数据集几乎是没有,怎么都找不到,所以只能我自己去百度图库爬虫了
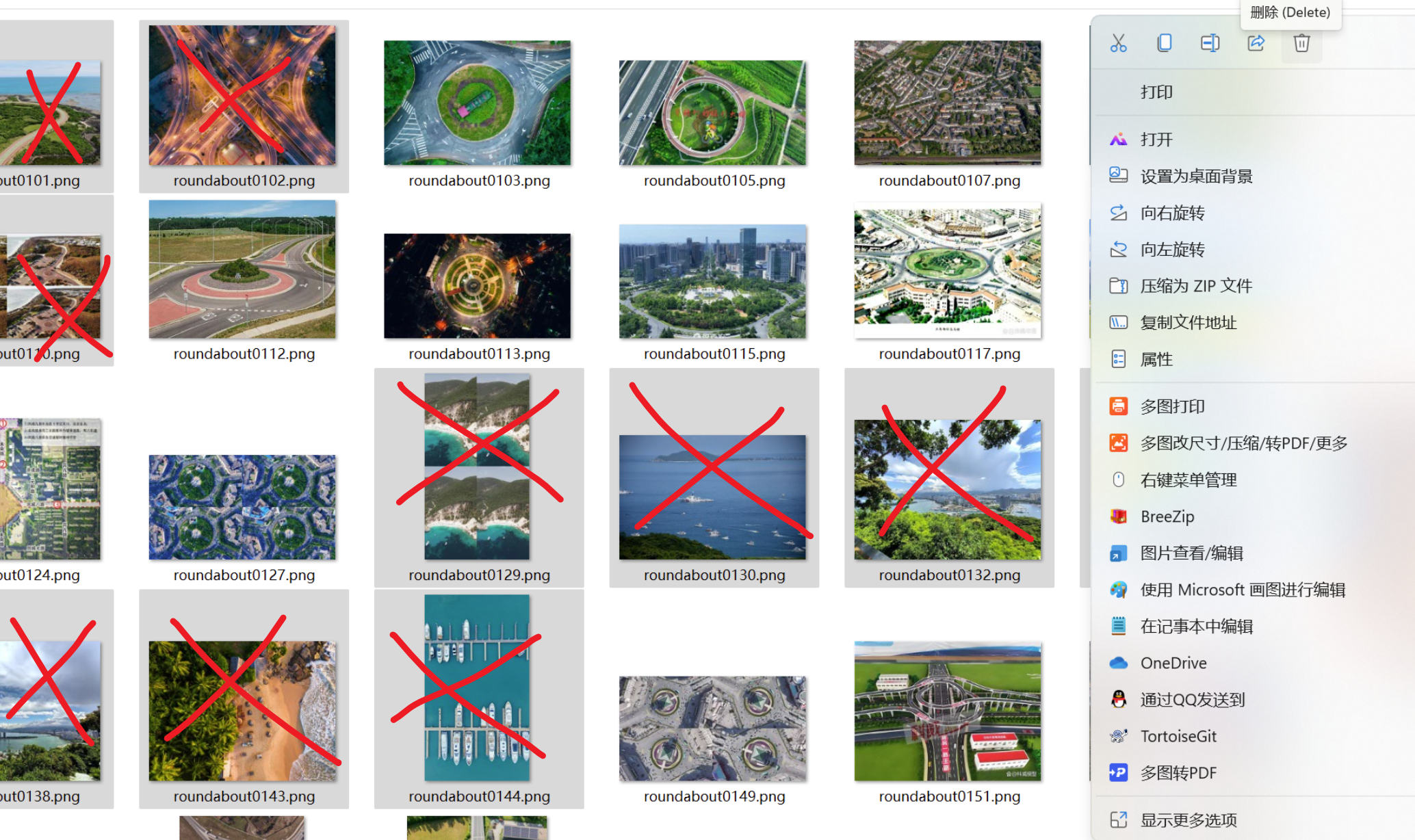
pythonimport os import requests import re import time import random # 这里save_dir切换你自己要保存到的文件夹地址 def download_images(keyword, target_count=300, save_dir=r"F:\我自己的毕设\YOLO_study\DOTA\Datasets\DOTA_split\all_images\my_new_data"): # 创建保存文件夹 if not os.path.exists(save_dir): os.makedirs(save_dir) print(f"📁 文件夹已创建: {save_dir}") # 伪装 Header headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36', 'Referer': 'https://image.baidu.com/' } url = 'https://image.baidu.com/search/acjson' count = 0 page = 0 print(f"🚀 开始爬取关键词: 【{keyword}】,目标: {target_count} 张") while count < target_count: # 构造参数 params = { 'tn': 'resultjson_com', 'logid': '1122334455', 'ipn': 'rj', 'ct': '201326592', 'is': '', 'fp': 'result', 'queryWord': keyword, 'cl': '2', 'lm': '-1', 'ie': 'utf-8', 'oe': 'utf-8', 'adpicid': '', 'st': '', 'z': '', 'ic': '', 'hd': '', 'latest': '', 'copyright': '', 'word': keyword, 's': '', 'se': '', 'tab': '', 'width': '', 'height': '', 'face': '', 'istype': '', 'qc': '', 'nc': '1', 'fr': '', 'expermode': '', 'force': '', 'cg': '', 'pn': page * 30, # 翻页 'rn': '30', # 每页数量 'gsm': hex(page * 30)[2:], } try: # 请求 JSON 数据 res = requests.get(url, headers=headers, params=params, timeout=10) res.encoding = 'utf-8' try: json_data = res.json() except: print("⚠️ 解析 JSON 失败,跳过此页") page += 1 continue data_list = json_data.get('data', []) if not data_list: print("❌ 没有更多数据了,结束爬取。") break for item in data_list: if count >= target_count: break if 'thumbURL' not in item: continue # 优先尝试获取高清原图链接 (replaceUrl 通常包含未加密的原图链接) img_url = item.get('thumbURL') # 默认用缩略图保底 # 尝试找高清图 if item.get('replaceUrl') and len(item['replaceUrl']) > 0: obj_candidate = item['replaceUrl'][0].get('objurl') if obj_candidate: img_url = obj_candidate # 下载图片 try: # 获取图片内容 img_res = requests.get(img_url, headers=headers, timeout=10) if img_res.status_code == 200: file_ext = os.path.splitext(img_url)[1] if not file_ext or len(file_ext) > 5: file_ext = ".jpg" # 默认后缀 # 命名格式: keyword_00001.jpg file_name = f"{save_dir}/{count:05d}{file_ext}" with open(file_name, 'wb') as f: f.write(img_res.content) print(f"✅ [{count + 1}/{target_count}] 下载成功: {file_name}") count += 1 else: print(f"⚠️ 下载失败 (状态码 {img_res.status_code}): {img_url}") except Exception as e: print(f"⚠️ 下载出错: {e}") page += 1 # 随机休眠一下,防止被封 IP time.sleep(random.uniform(0.5, 1.5)) except Exception as e: print(f"❌ 网络请求错误: {e}") break print(f"\n任务完成!共下载 {count} 张图片,保存在 '{save_dir}' 文件夹下。") print("❗请务必人工筛选一遍,删除无关图片或带水印严重的图片!") # 运行爬虫 if __name__ == "__main__": download_images("城市道路环岛俯视图", target_count=300)记得人工删除一些无关紧要的图片
【整理文件名】
记得去这个网站把刚刚收集的一大堆乱七八糟的图片文件统一一下文件名
https://rename.jgrass.xyz/https://rename.jgrass.xyz/
二、数据打标签
1、工具配合思路
那么新增的图片我算了一下大概有1400多张,如果一点一点标注我真的会去死的,所以我发现了两种工具结合的快速方法:
我们现在需要了解这两个工具:【label-studio】和【X-AnyLabeling】
【X-AnyLabeling】是一个自动化标注工具,它是基于YOLO等各个AI模型来实现自动化打标签的工具,但是他傻逼的点在于,它的模型本身就是基础的YOLO模型,比如yolo11-obb模型,它本身就只认得少数目标物体,我给他检测一些新的目标物体就一点用也没有
解决办法就是,必须给每一个目标种类的图片我们手动打个30图片,然后在本地用yolo代码先训练一个模型,这个模型认识这些你的目标之后,我们再部署到X-AnyLabeling里,他就可以把数据集里剩下几百几千张图片自动化标注了(当然也并非100%准确),简单说就是:你去酒店想吃一道 "剁椒鱼头",但是酒店的厨师都不知这是啥?然后你需要先自己做出一道"剁椒鱼头",并教会酒店的厨师,然后他们才能帮你做出几百几千道"剁椒鱼头"。
;
;
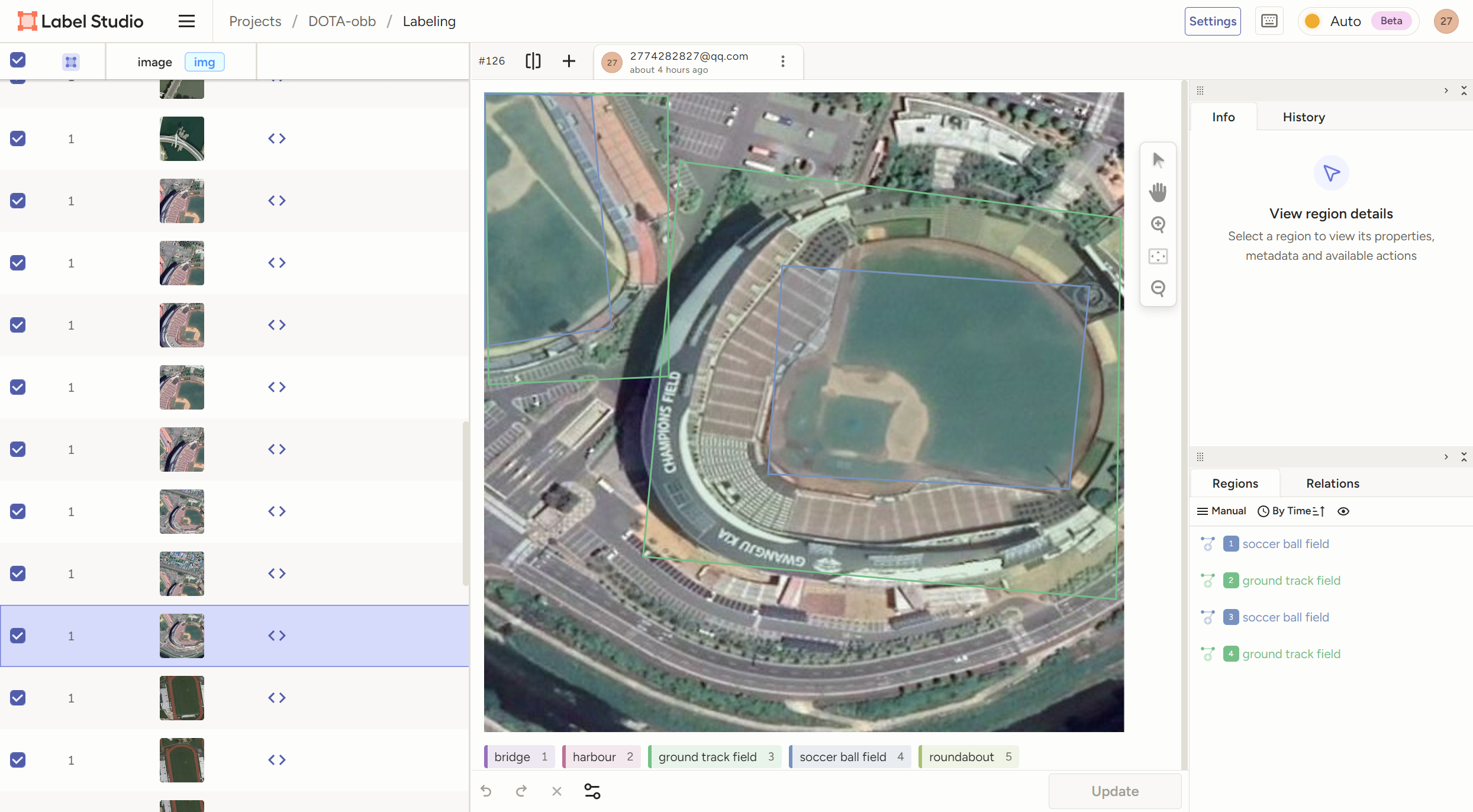
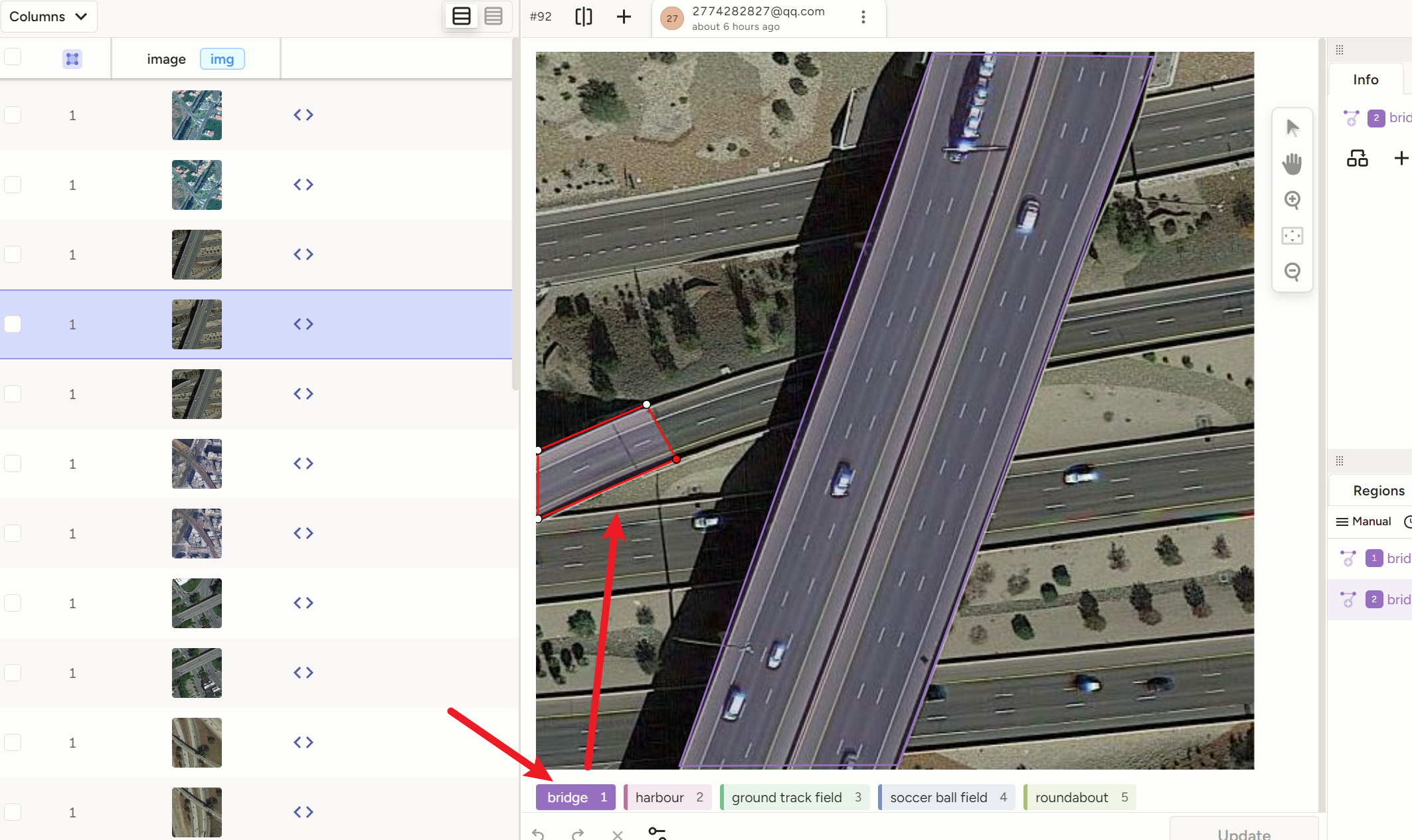
那么又关【label-studio】什么事?你去用【X-AnyLabeling】标注OBB旋转框实操一下就知道,你需要先拉一个垂直的矩形框,然后点他,然后用键盘Z、V来控制往左往右旋转,然后还只能是矩形框,拉一个框至少10秒。但是我们要知道YOLO-obb旋转框的原理就是要找一个物体的【四个点坐标:(x1,y1) (x2,y2)(x4,y4) (x3,y3)】,所以我们其实不用完全是矩形框,硬性条件只是有四个点!!那么【label-studio】的"动作检测"的拉框,就只用鼠标点四个点就能拉一个旋转框了

2、【label-studio】先标注一部分
1)安装配置
先执行这个代码来全局下载,别漏了 --user
pip install --user label-studio -i https://pypi.tuna.tsinghua.edu.cn/simple有这些黄色红色的警告报错都不用管,正常的一个提醒而已,现在以及安装完毕
;
然后再执行这个命令,找到你的label-studio是安装在哪了:
echo %USERPROFILE%\AppData\Roaming\Python\Python312\Scripts可以去这个路径检查一下有没有label-studio.exe,有的话就对了,把这个文件夹路径复制下来,注意是当前文件夹而不是包括这个label-studio.exe
添加到path环境变量,搞定

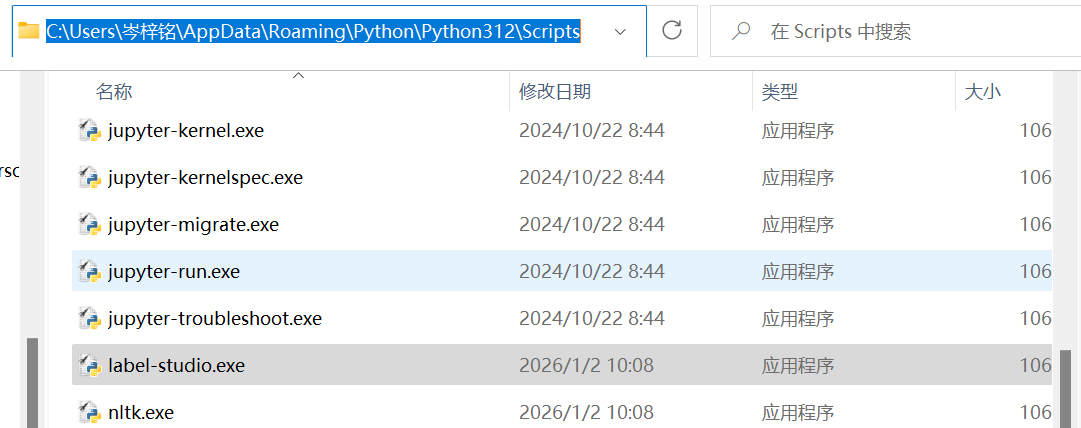
以后用的时候只用敲【label-studio】就可以启动
首次启动还要注册登陆一下
然后要创建一个自己的项目
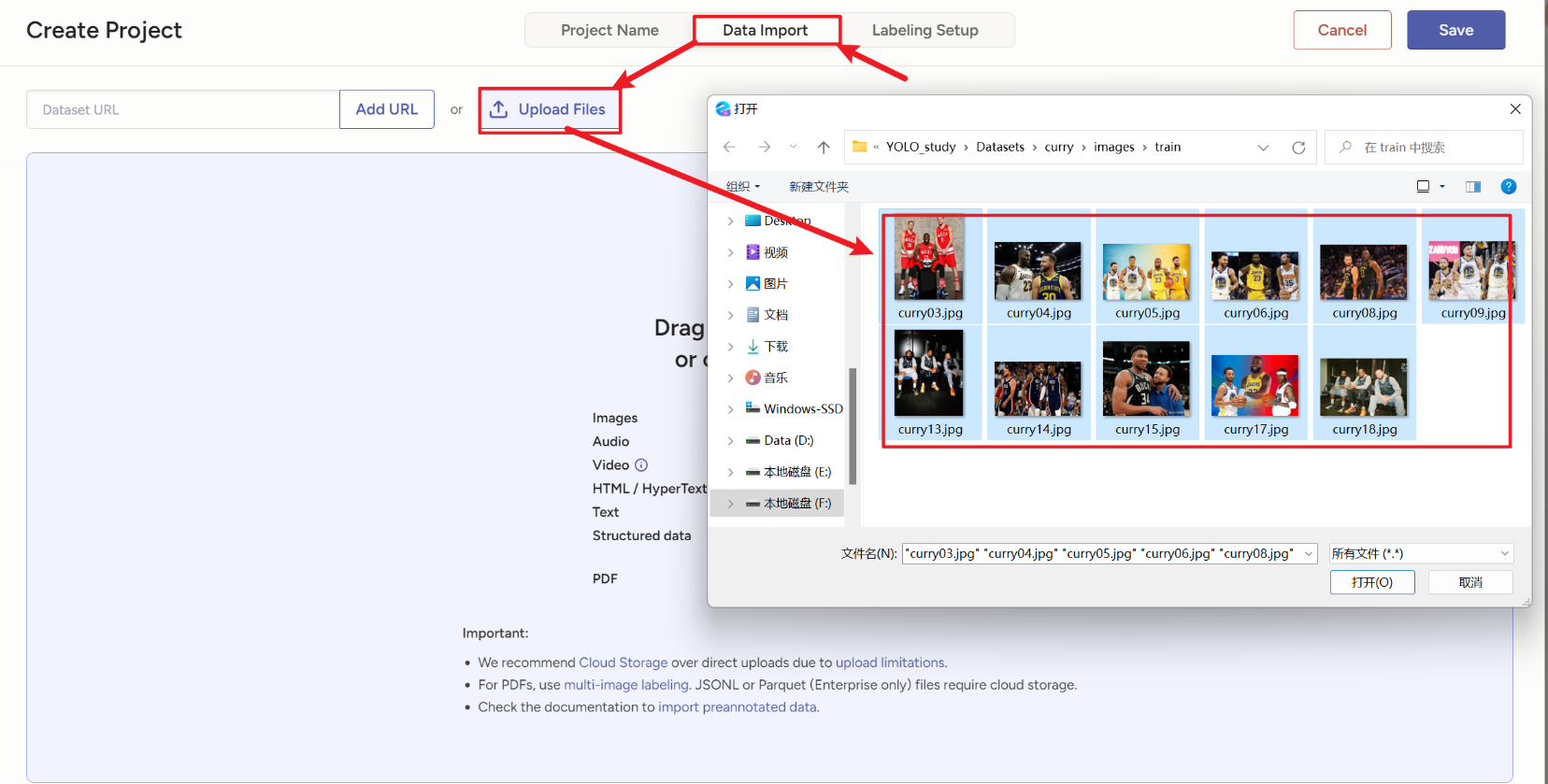
先别点save,然后下一步上传图片
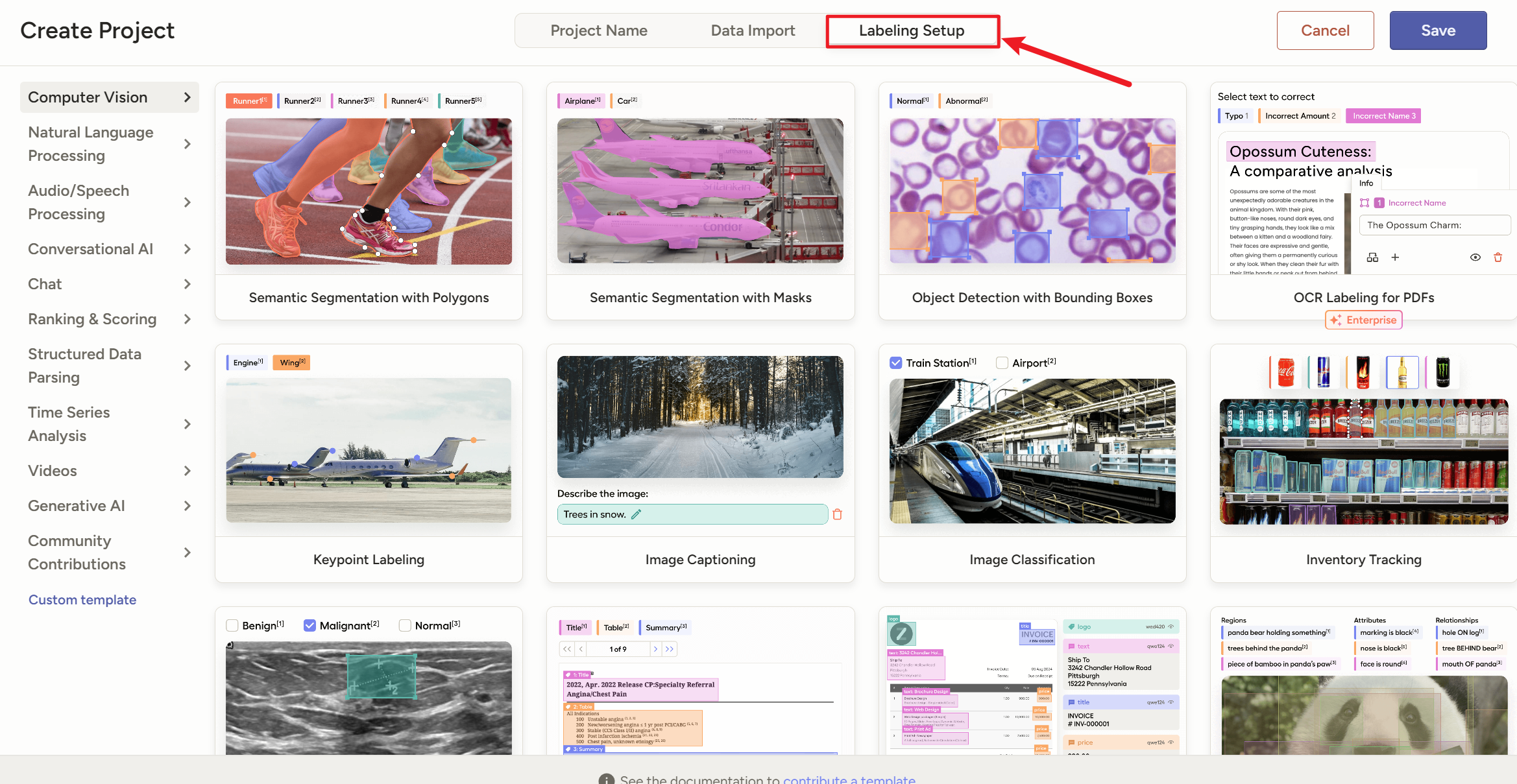
然后点右边选择一个模板,这个网站提供了很多模板
如果是普通的目标检测的垂直水平矩形框,就用这个【
Object Detection with Bounding Boxes】就是【目标检测(用矩形框标注特定对象)】
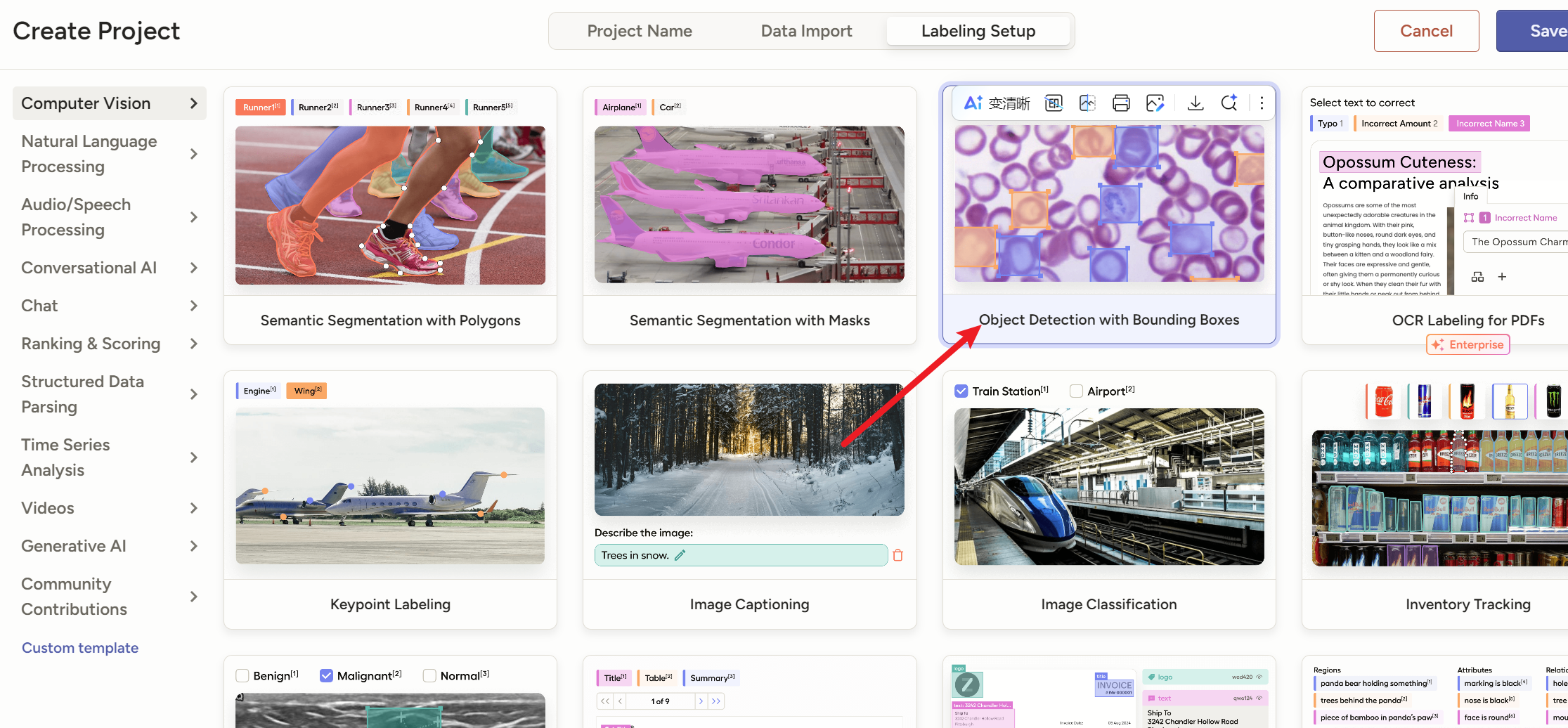
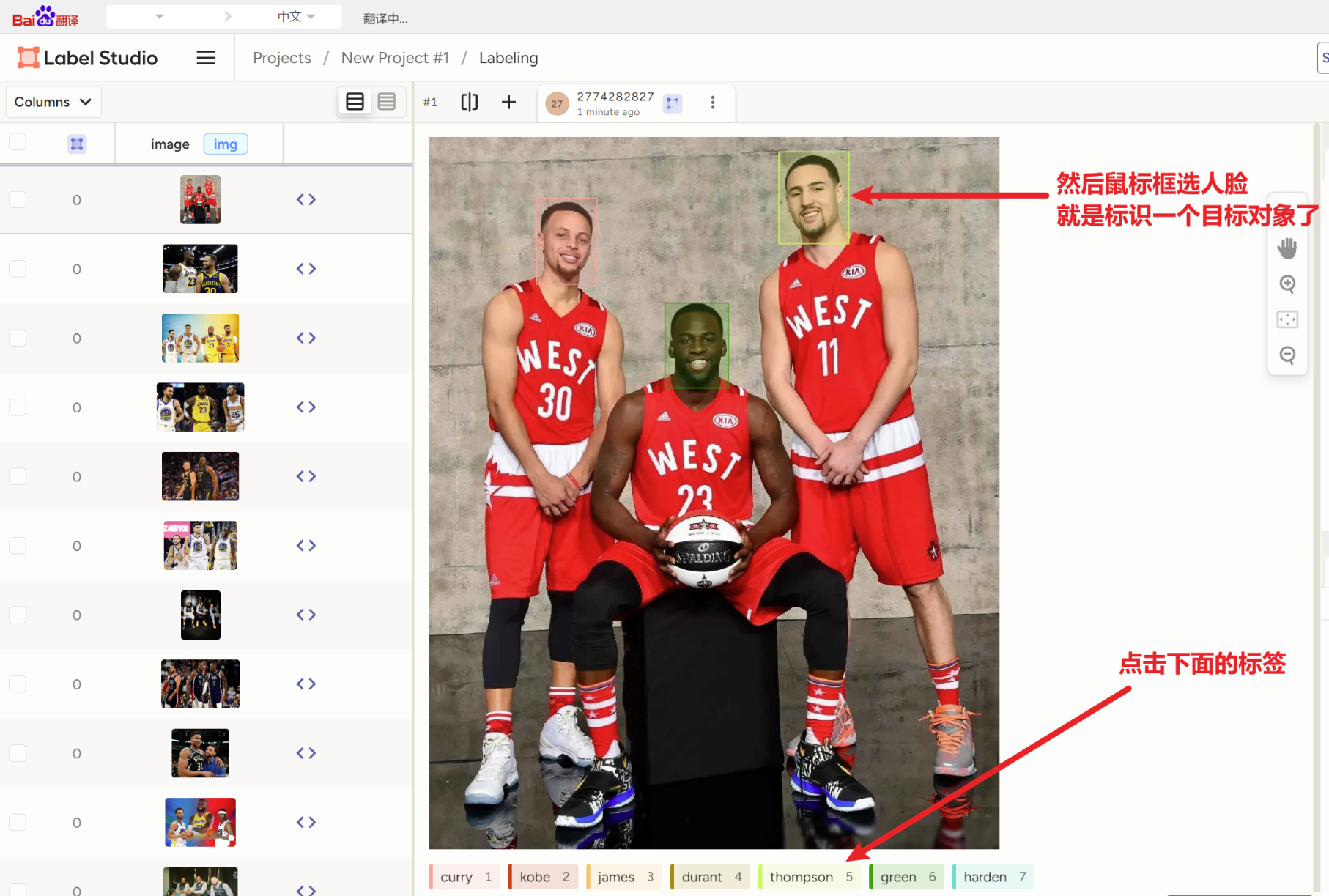
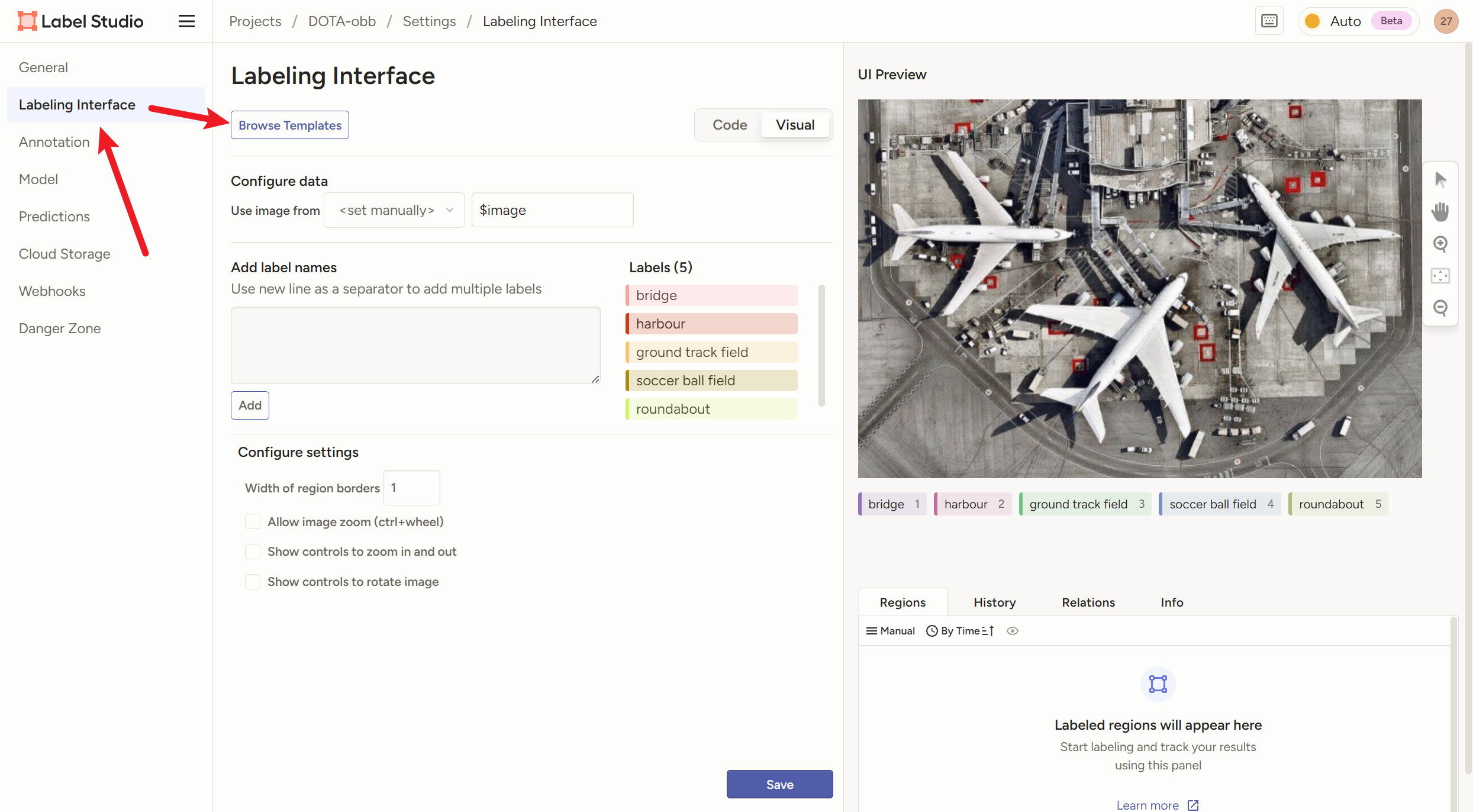
2)怎么给【旋转框obb】打标签
label-studio没有提供旋转框obb的模板,那么我们需要自定义一个标签模式,创建一个项目后按下图操作
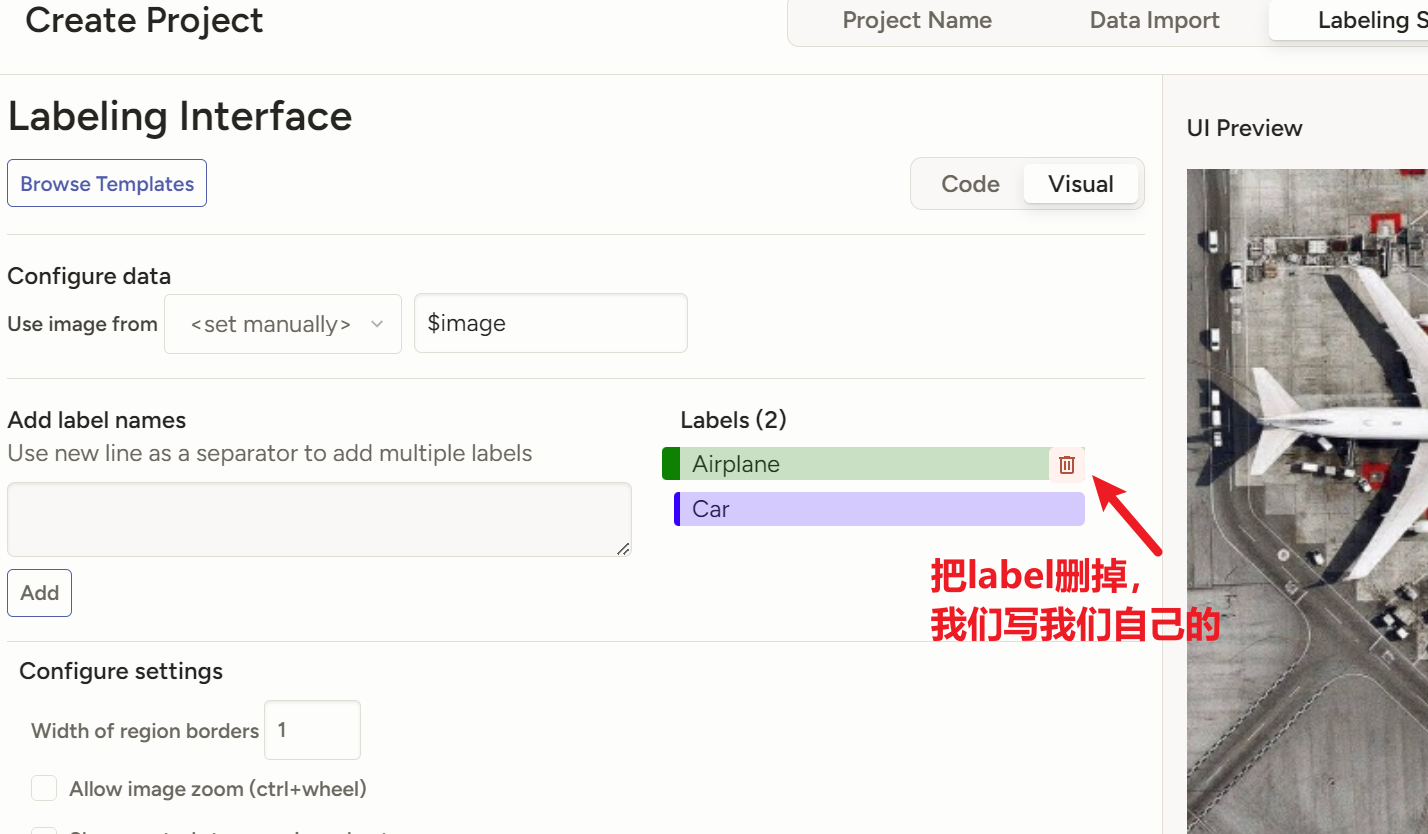
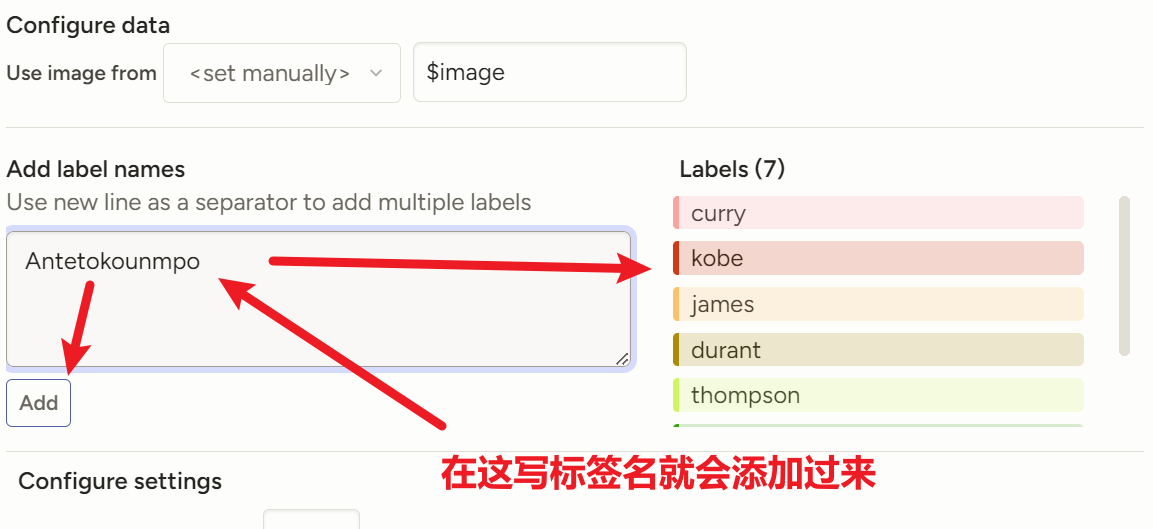
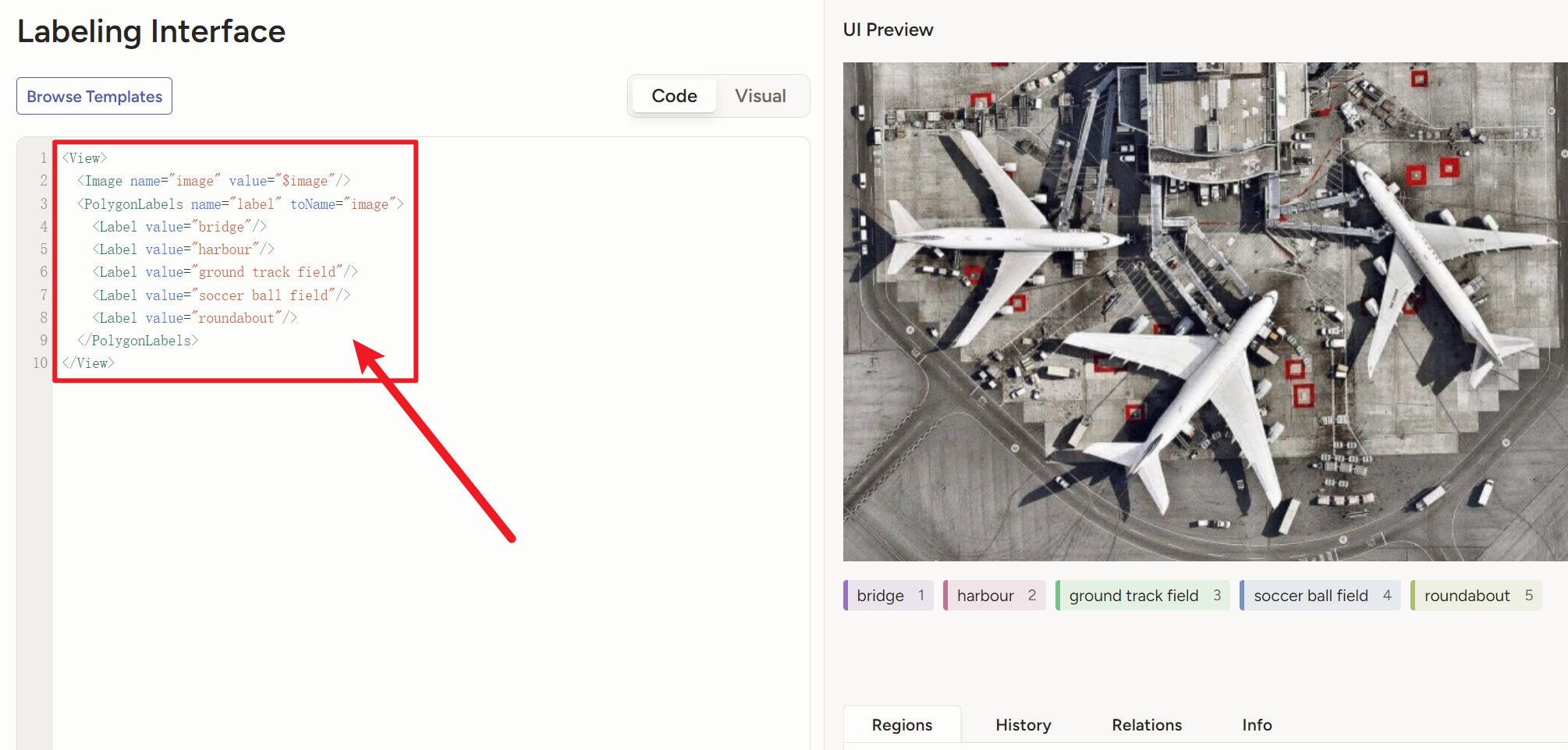
把我的代码复制进去,标签处改成自己需要的标签
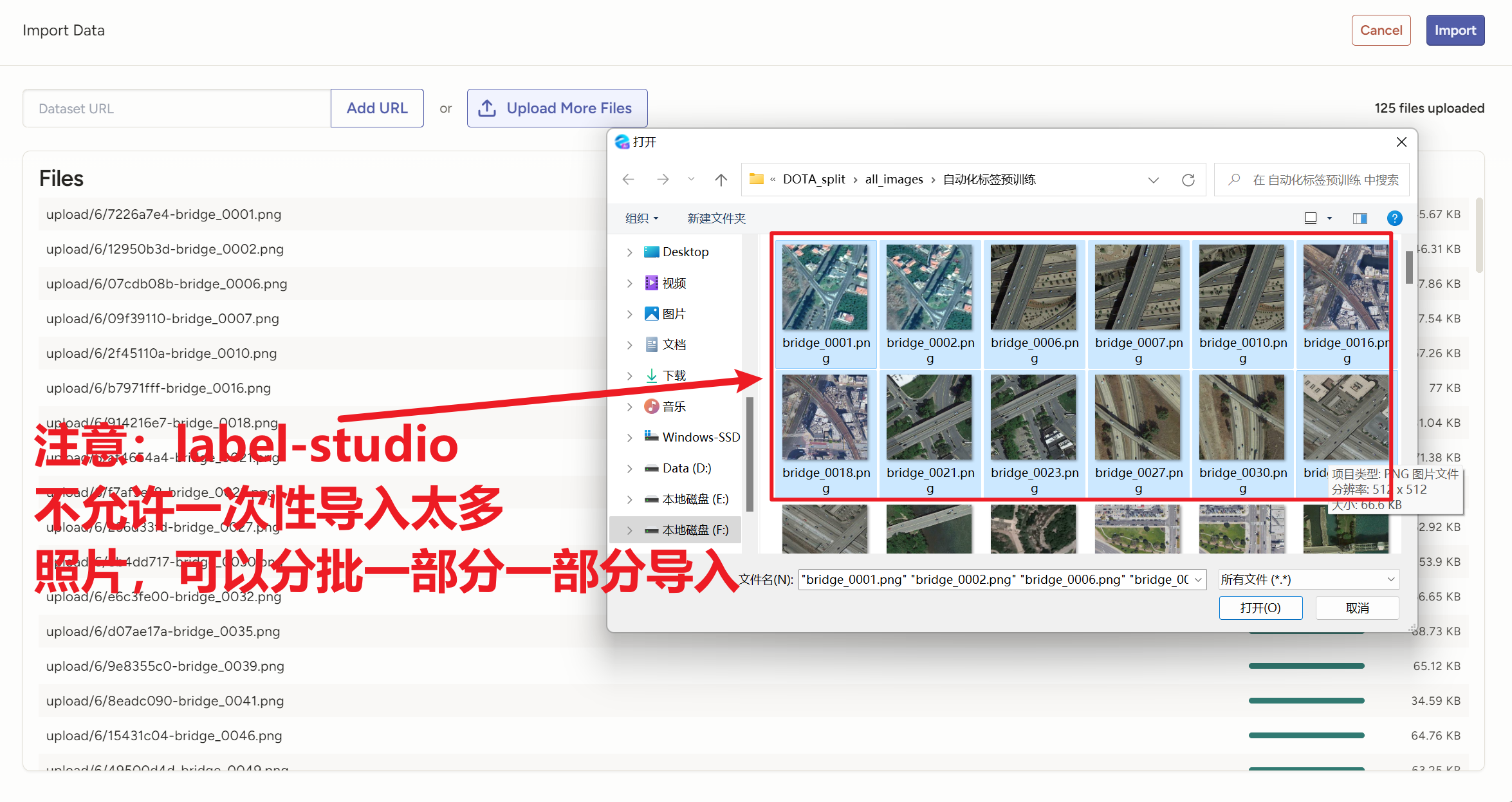
<View> <Image name="image" value="$image"/> <PolygonLabels name="label" toName="image"> <Label value="添加你的标签1"/> <Label value="添加你的标签2"/> <Label value="添加你的标签3"/> <Label value="添加你的标签4"/> ...... </PolygonLabels> </View>然后导入图片,注意平台有个保护机制,一次性不让导入太多图片,我们只能分批一部分一部分地导入
然后还是一样地操作,点标签,然后一次点四个点,就自动成了一个框
记住!!!只能点四个点!!!少了不行,多了也不行,不然坐标格式就跟yolo-obb不一样了!!!!!!!框直不直、是不是矩形无所谓,只要有四个点的坐标!!!
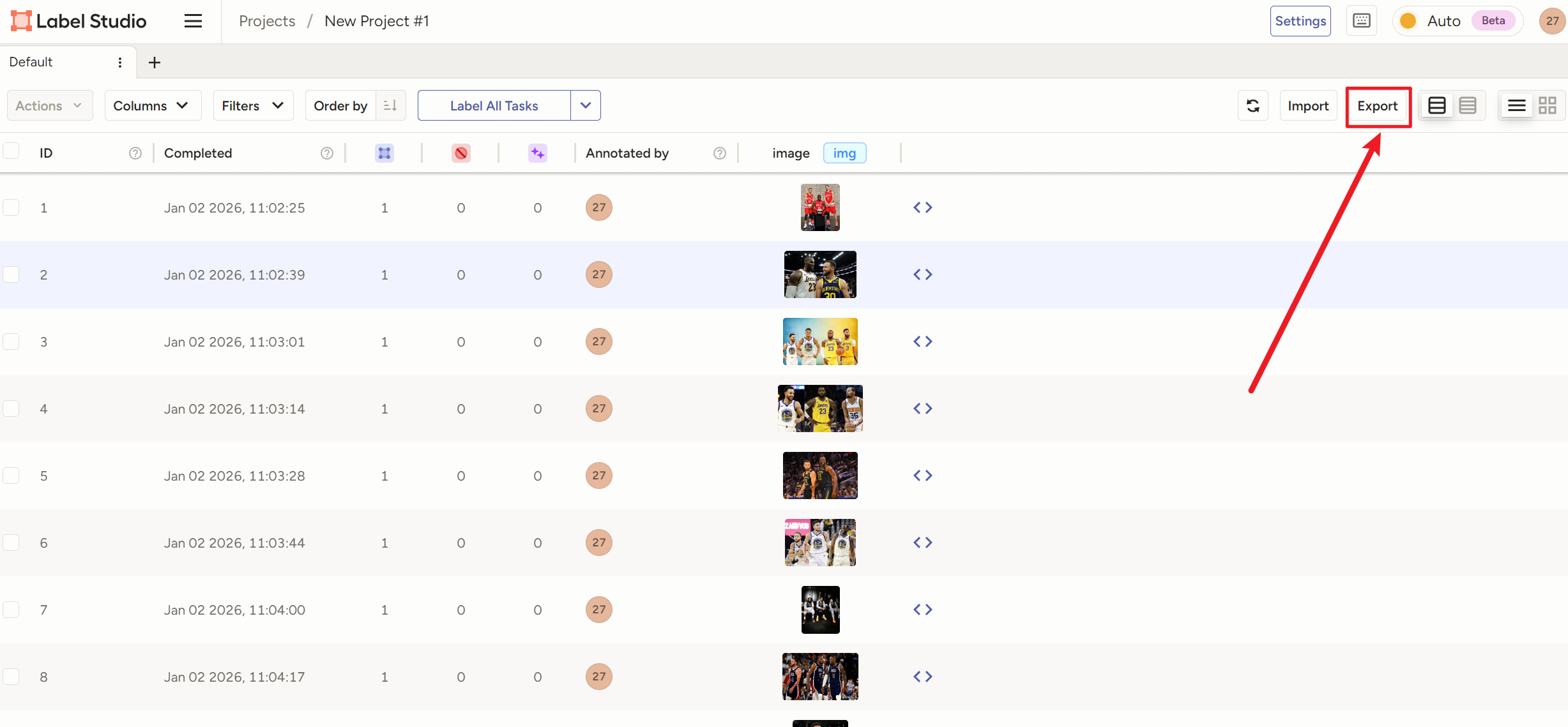
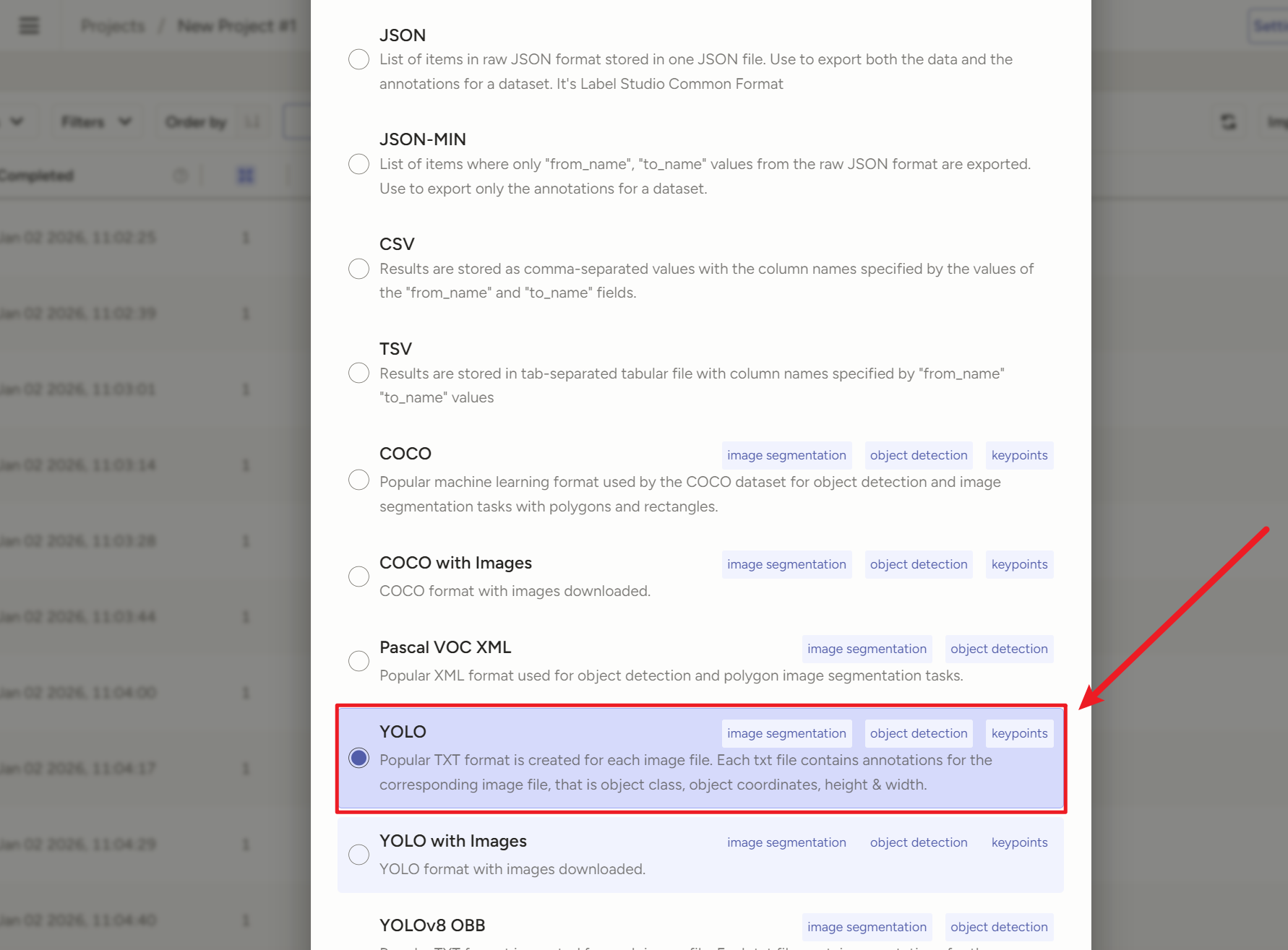
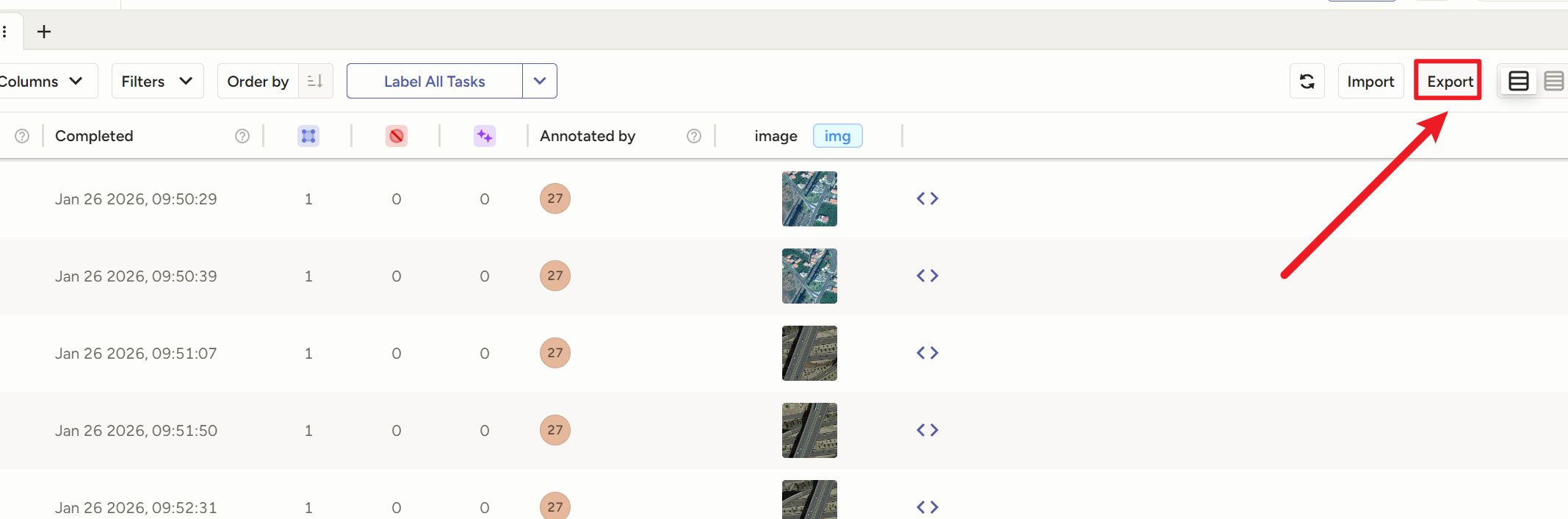
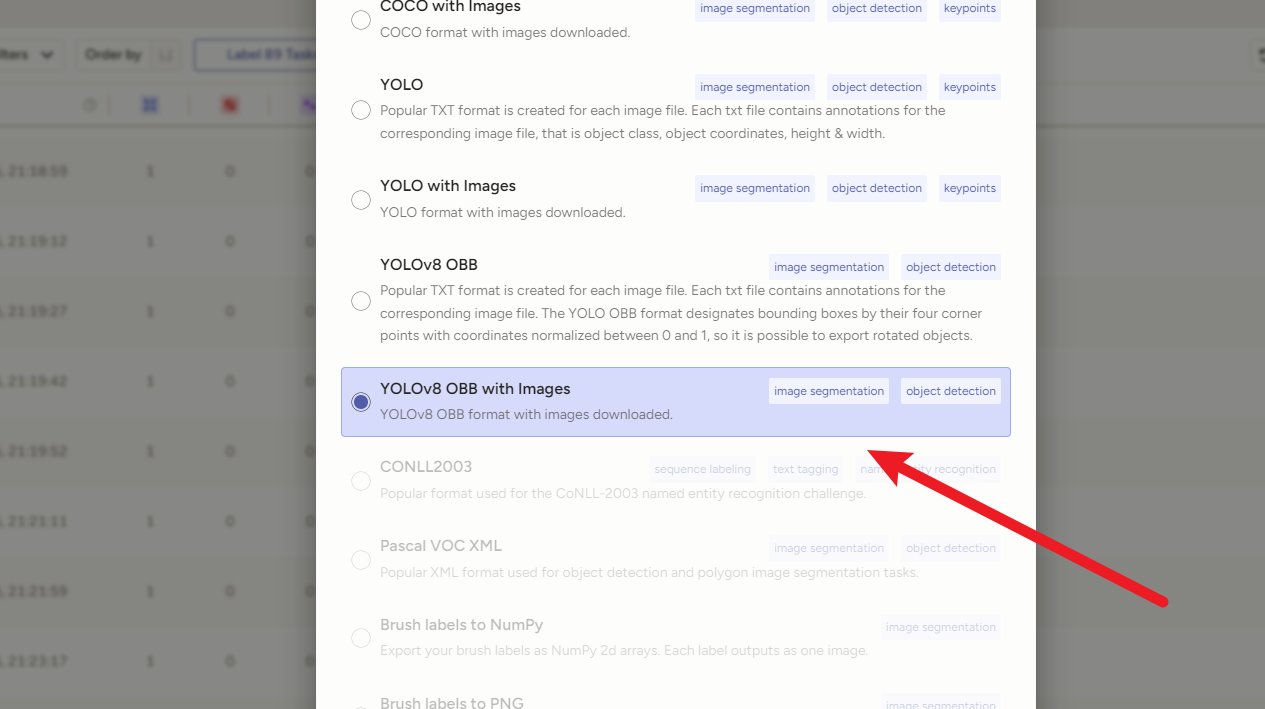
导出时选YOLv8 OBB
切记一定要用【 YOLOv8 OBB**++with Images++】!!!!!!!!!!!**
切记一定要用【 YOLOv8 OBB**++with Images++】!!!!!!!!!!!**
切记一定要用【 YOLOv8 OBB**++with Images++】!!!!!!!!!!!**
切记一定要用【 YOLOv8 OBB**++with Images++】!!!!!!!!!!!**
切记一定要用【 YOLOv8 OBB**++with Images++】!!!!!!!!!!!**
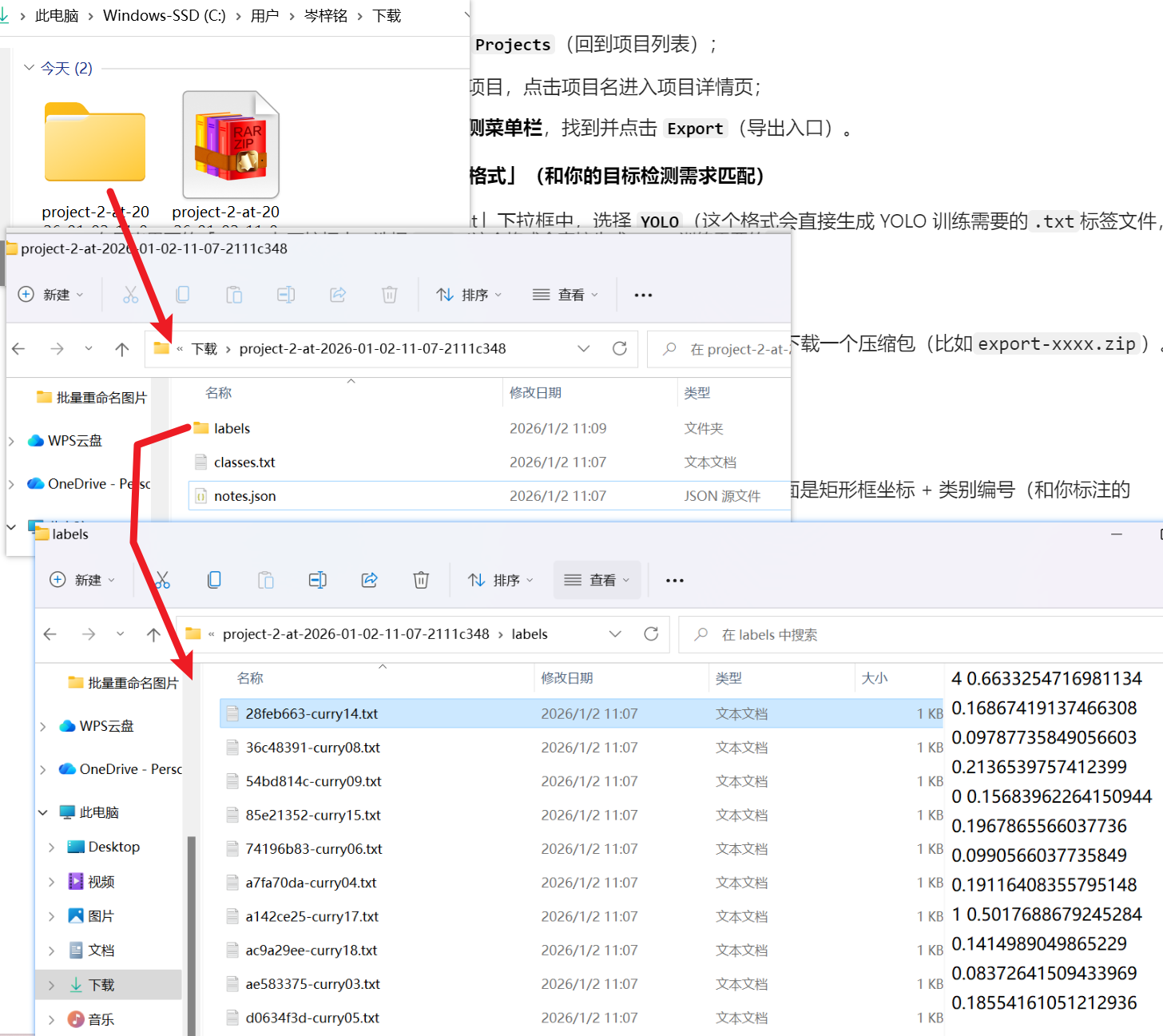
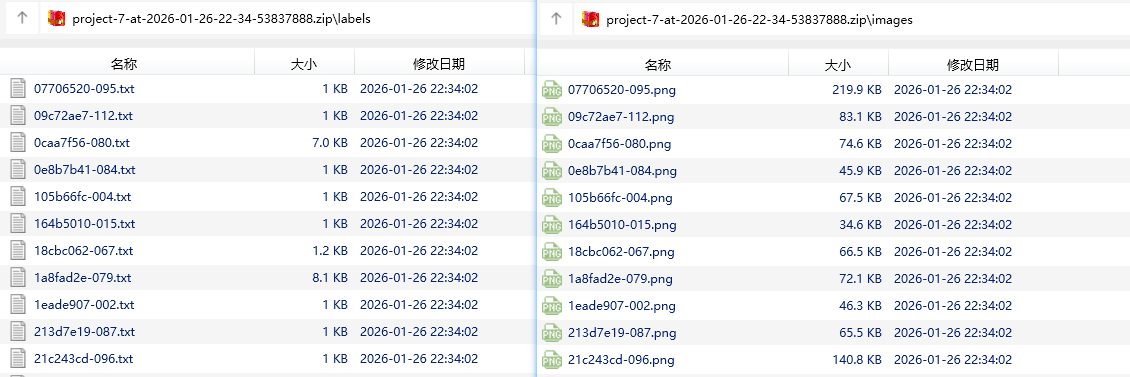
因为打完的标签全是乱的,只有带上图片一起导出,图片文件名才和标签文件名一致
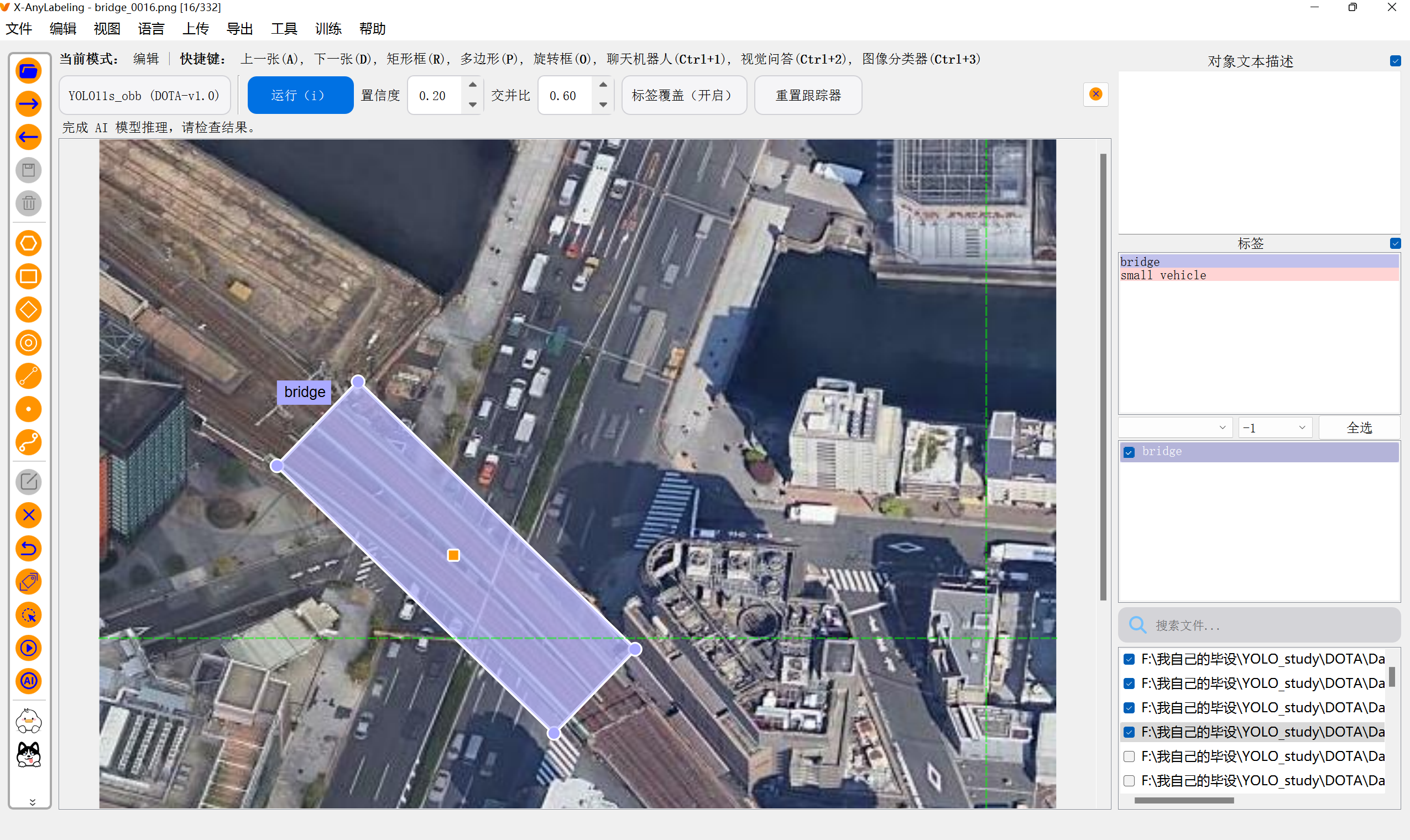
3、【X-AnyLabeling】自动化标注
1)安装配置
自动化标注工具安装链接:【X-AnyLabeling】点击这个链接
下载好后,解压到我们跑模型的python环境下(因为这个工具依赖ultralytics、pytorch,我们跑模型的python环境有这些依赖,就不用重新下载了)
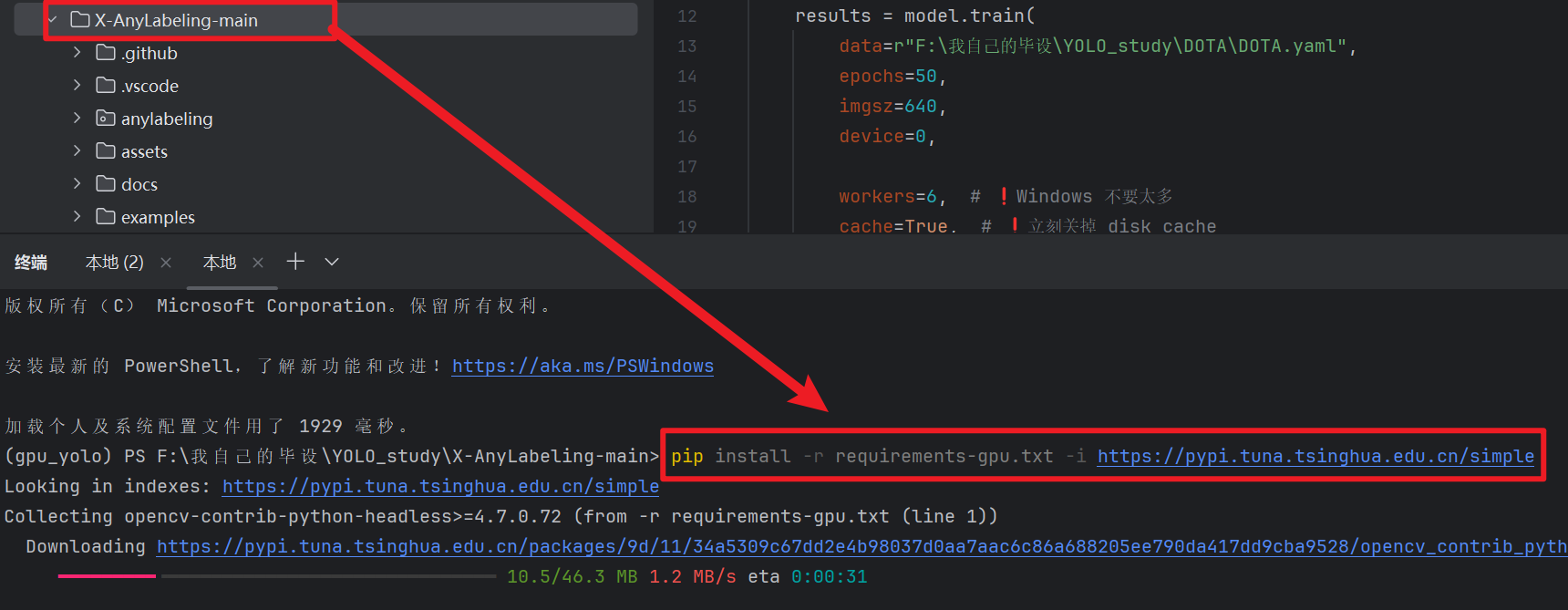
打开这个工具的目录终端,输入下面命令安装 "GPU版依赖"(没GPU的自己搜一下CPU版,再说没GPU你就别跑这么大的遥感数据集了)
pythonpip install -r requirements-gpu.txt -i https://pypi.tuna.tsinghua.edu.cn/simple;
然后以后就执行【python anylabeling/app.py】这个命令来打开这个软件
;
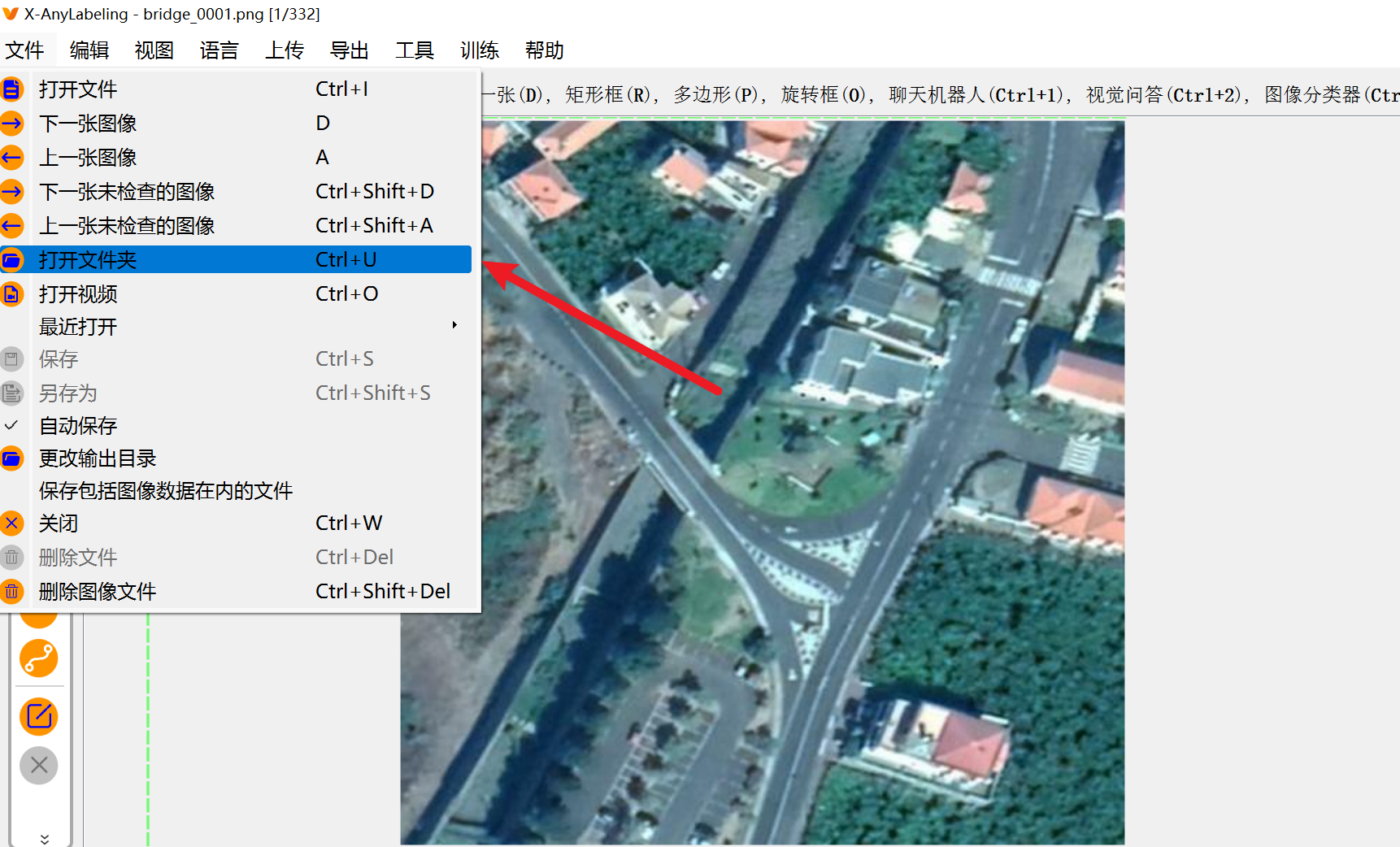
然后先导入文件夹
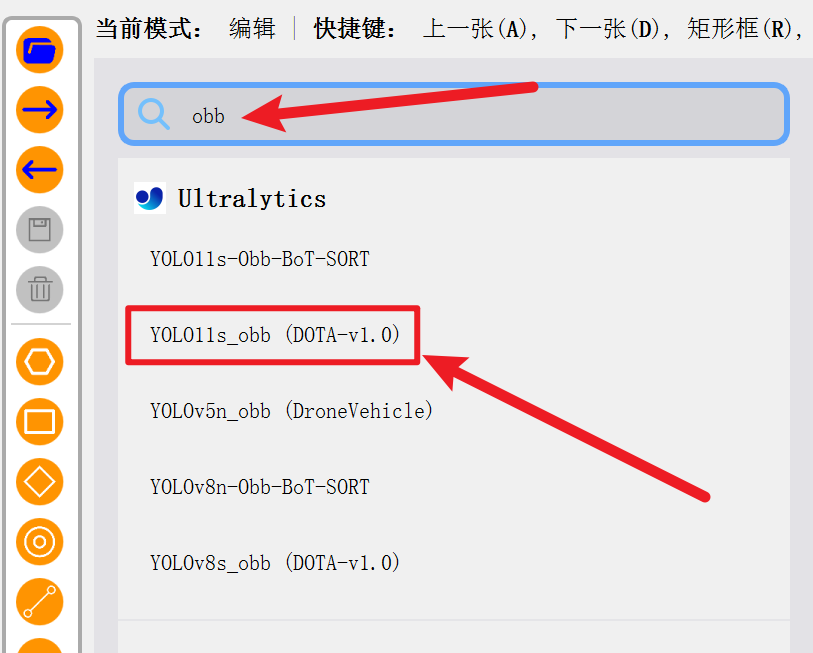
摁【Ctrl+A】启动AI模型,点击它进去选择我们要的OBB旋转框模型
然后我们要什么模型,就输入关键词搜一下,比如我们要旋转框obb格式的AI模型就这样
点击一下,首次使用时工具就会在后台先把这个模型下载到本地,等下载好了就可以用了
这里注意:一定一定一定一定一定一定要 "开魔法",不然这些模型都没办法下载到本地,这个工具就一点卵用也没有
即使开了也可能下载失败,多点几次或者换一下别的模型就行了
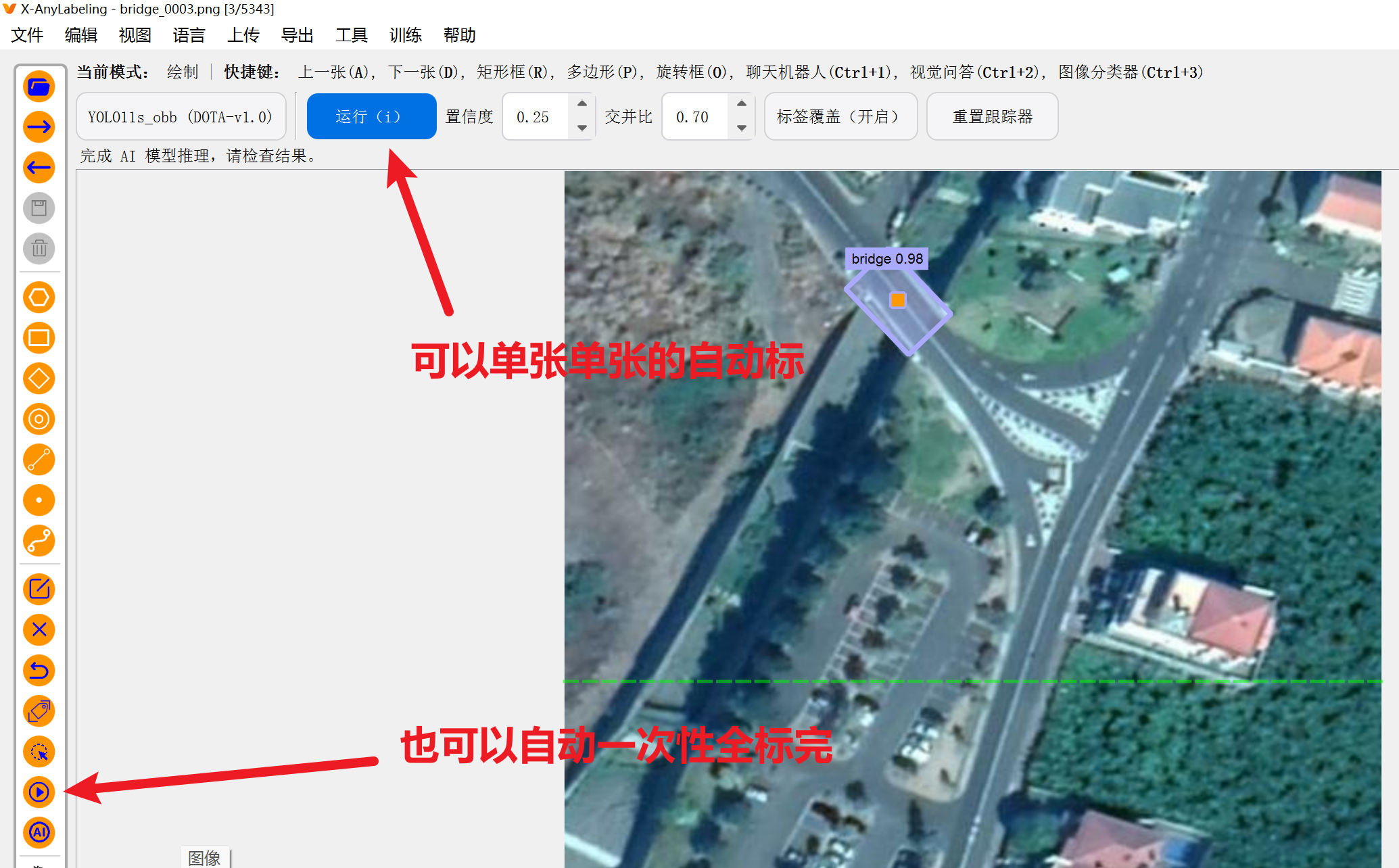
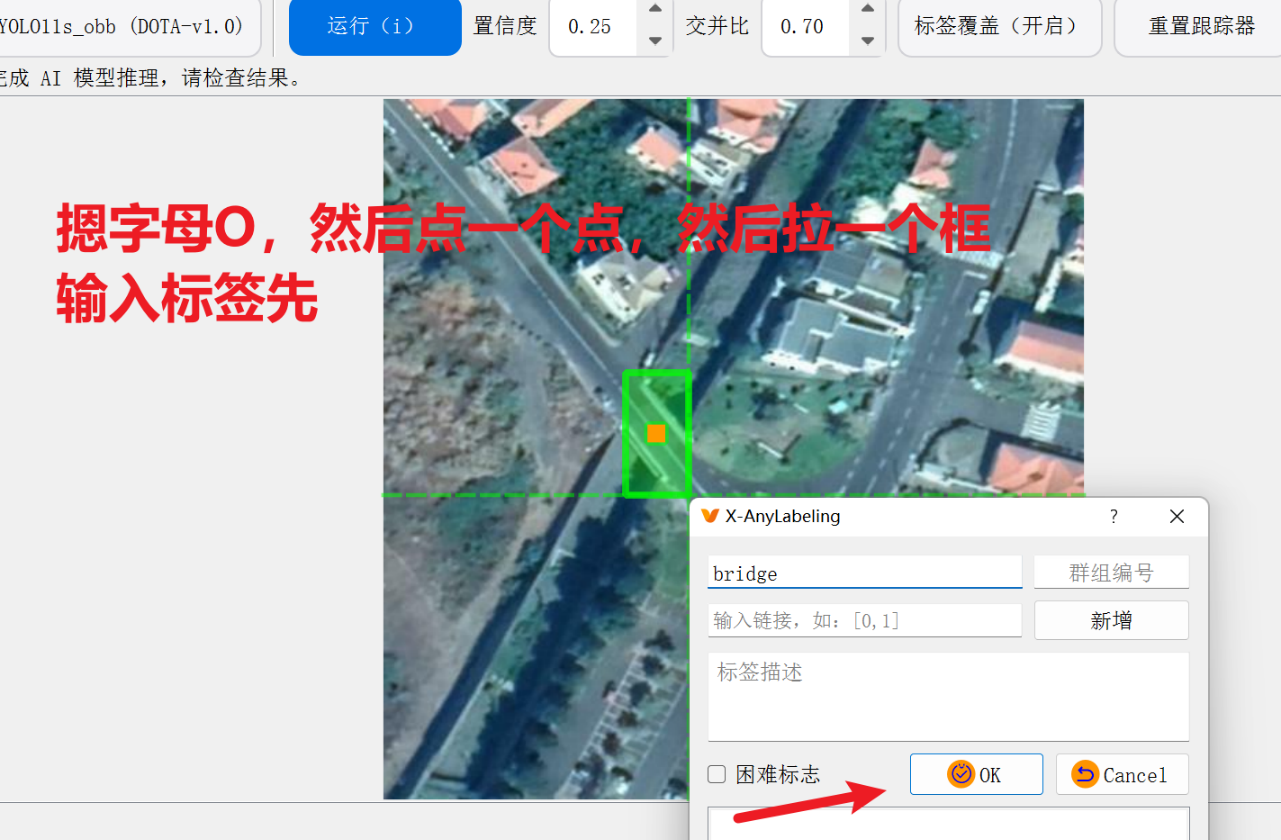
这里不推荐用它来拉 obb旋转框,因为很麻烦,这里只是演示一下它是怎么拉旋转框的
(还是推荐手动拉框用label-studio,这个工具知识和AI自动化拉框)



2)自动化给【旋转框obb】打标签
那么如果前面我们已经手动用【label-studio】标注了一堆图片了,现在我们就要用这一小部分数据集先训练一个模型先
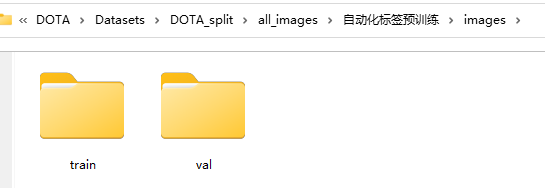
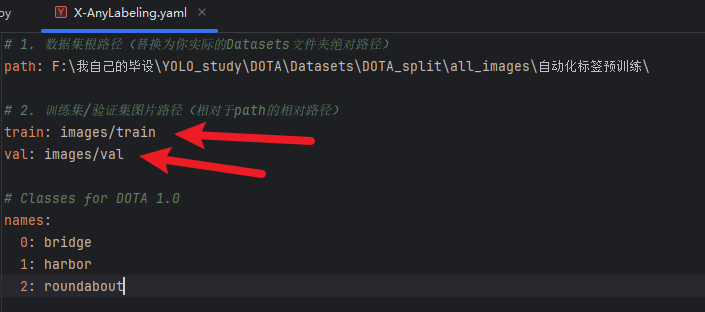
还得注意,把文件images和labels里的文件分成【train】和【val】好应对yolo训练的文件个格式:
3)然后就是训练我们手动标注的小预训练模型
pythonimport torch from ultralytics import YOLO if __name__ == '__main__': # 这是为了Windows下开启workers>0 的硬性条件,workers>0就加快速度 torch.multiprocessing.freeze_support() # 解决多进程报错问题 # 直接加载官方YOLO11n预训练模型 # model = YOLO(r"F:\我自己的毕设\YOLO_study\DOTA\my_yaml\11\my_yolo11-obb.yaml").load("yolo11n-obb.pt") model = YOLO("yolo11n-obb.pt") results = model.train( data=r"F:\我自己的毕设\YOLO_study\DOTA\Datasets\DOTA_split\all_images\自动化标签预训练\X-AnyLabeling.yaml", epochs=100, # 训练100轮 patience=60, # 防过拟合,60轮验证集mAP还不提升就停止 imgsz=1280, # 遥感图像目标还是太小,调大尺寸 # 加快速度 device=0, workers=3, # ❗Windows 不要太多 #cache=True, # ❗立刻关掉 disk cache batch=-1, #val=False, # ❗打开验证(反而更稳定) #plots=False, # ❗关闭训练曲线 # 小目标增强 augment=True, # 开启增强 hsv_h=0.015, # 色相、对比度 hsv_s=0.7, # 饱和度 hsv_v=0.4, # 亮度 degrees=8.0, # 旋转角度 mosaic=0.5, # 取50%图片开始mosaic增强 close_mosaic=50, # 最后50轮不做mosaic增强,专注于原始图像学习 copy_paste=0.8, # 复制粘贴增强 mixup=0.0, # 小目标很多很乱,别整混合了 perspective=0.0, # 透视变换关了吧,本来就是俯瞰视图没什么角度倾斜 # 防止过拟合的优化器 lr0=0.01, # 学习率 lrf=0.1, # 学习率衰减 )
4)最后最重要的步骤!!千万别搞错!!!
要导入我们的自定义,我们需要官方要求的两个文件
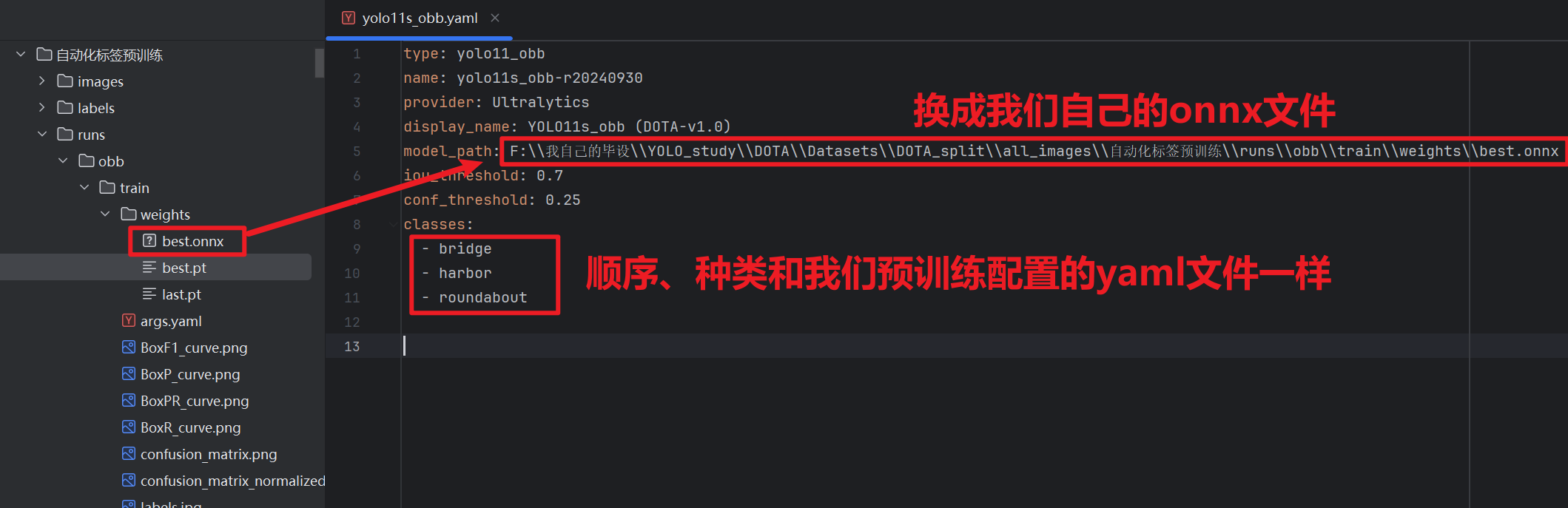
- 第一个是【yaml】配置文件
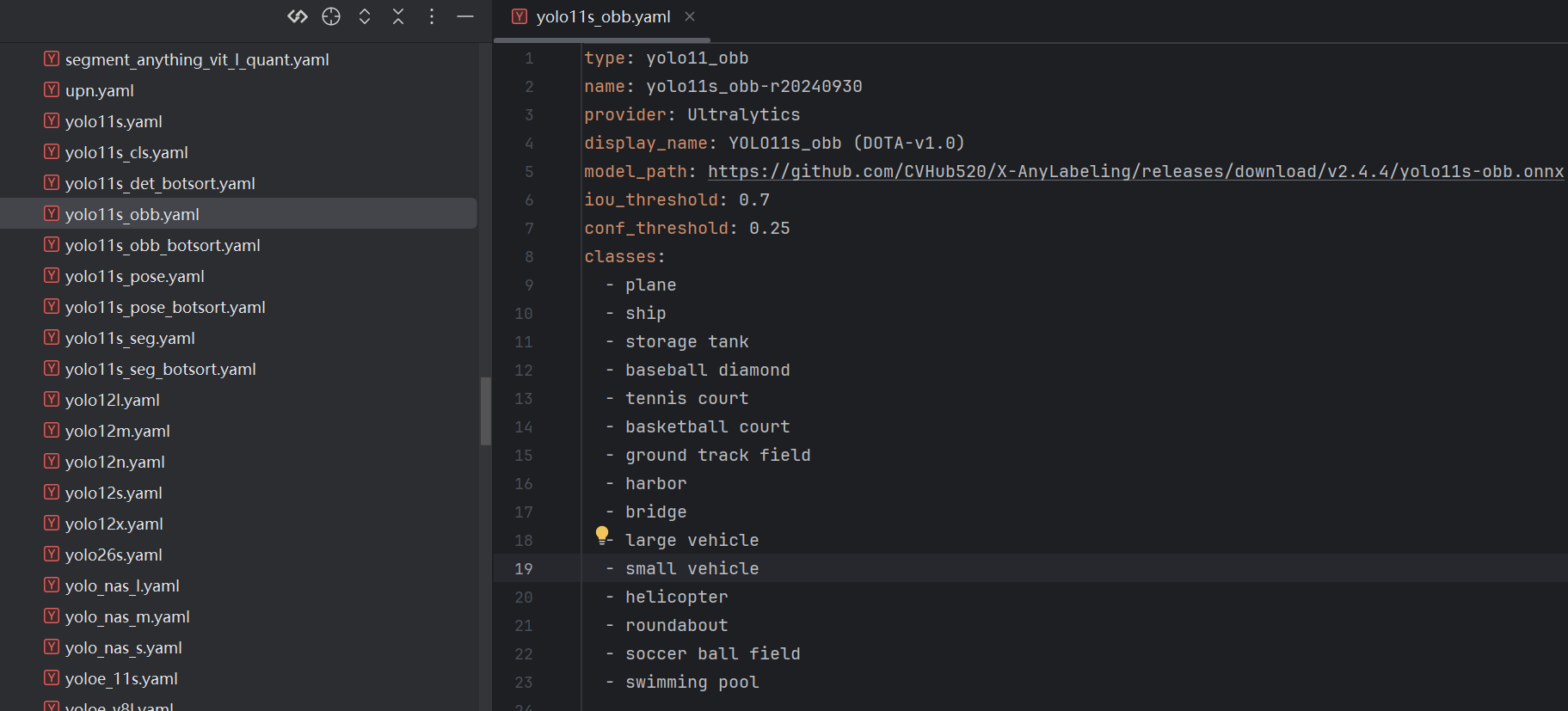
- 跟我们训练的那个yaml文件不一样,这个是告知X-Anylabeling我们的模型在哪?我们要标注的几个标签是啥?
- 我们要到X-Anylabeling安装路径下图的位置找到自己需要的yaml文件,比如我yolo-obb的就选obb的yaml文件
- 然后复制到我们自己的目录,后需要改一下里面的内容
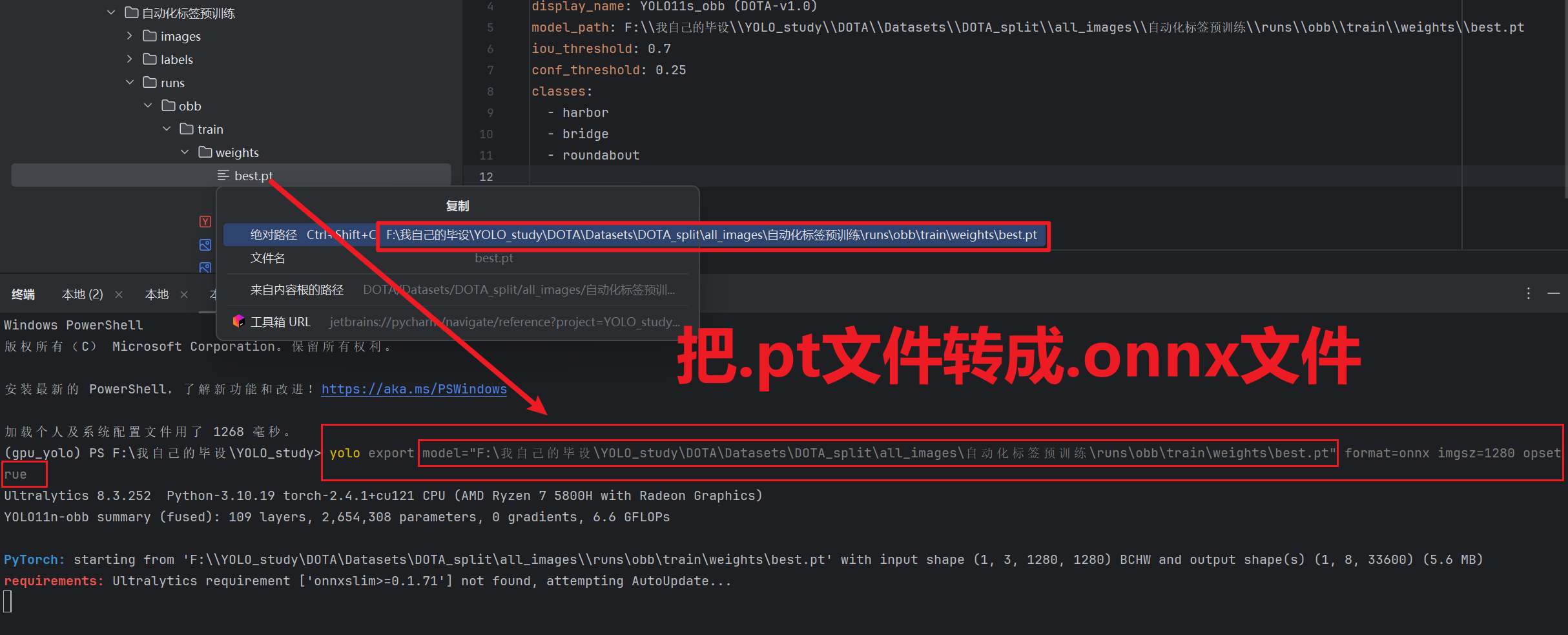
- 第二个文件就是【.onnx】文件
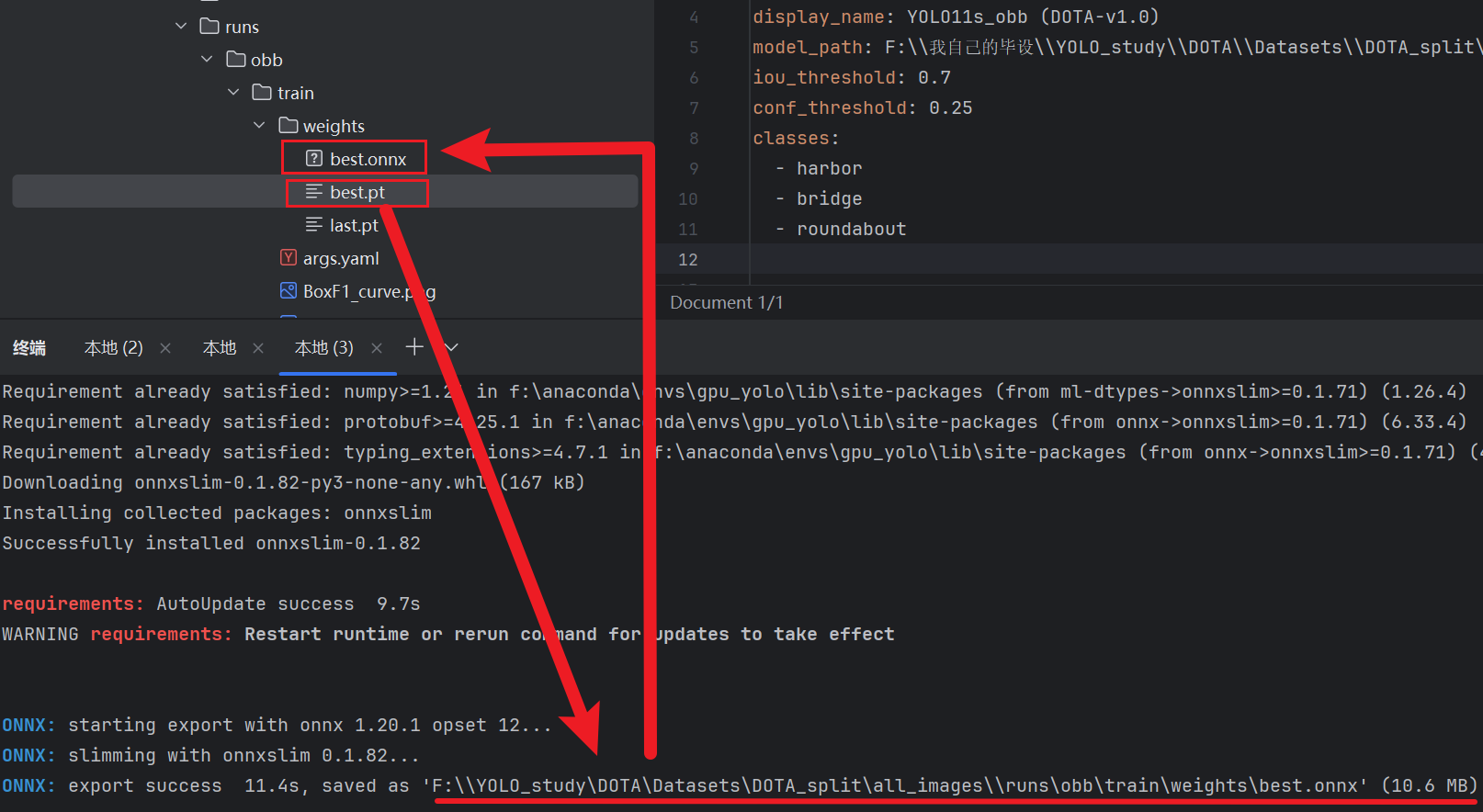
这个死人软件不支持【.pt】文件模型,所以我们必须先把【.pt】模型转成【.onnx】格式,到终端输入下面指令
pythonyolo export model="我们刚刚预训练的模型.pt文件路径" format=onnx imgsz=和训练的时候的尺寸一致 opsetrue
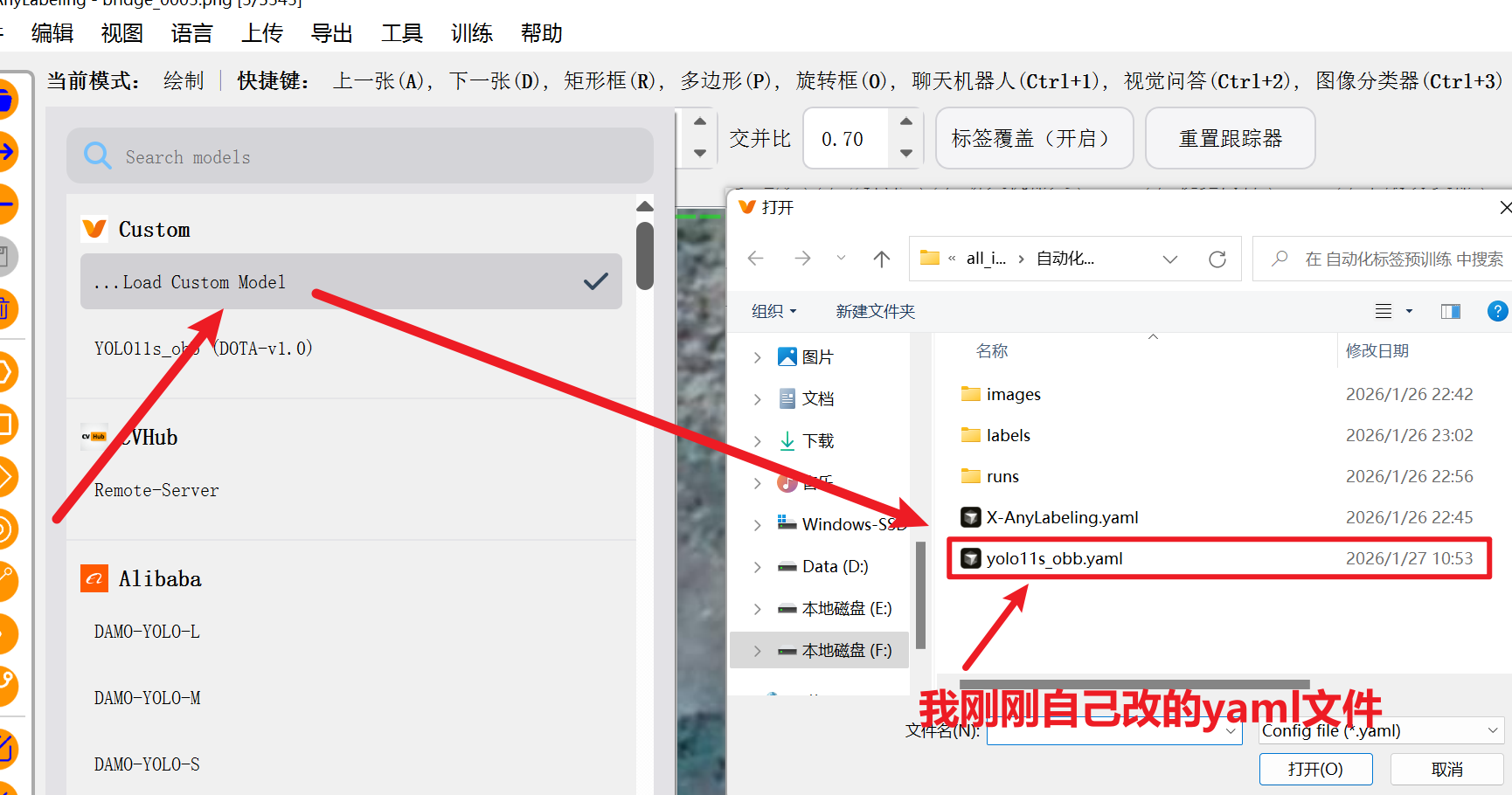
现在就可以修改刚刚的yaml文件了
然后大功告成,回到工具导入模型