相对优势估计存在偏差------揭示群体相对强化学习中的系统性偏差问题
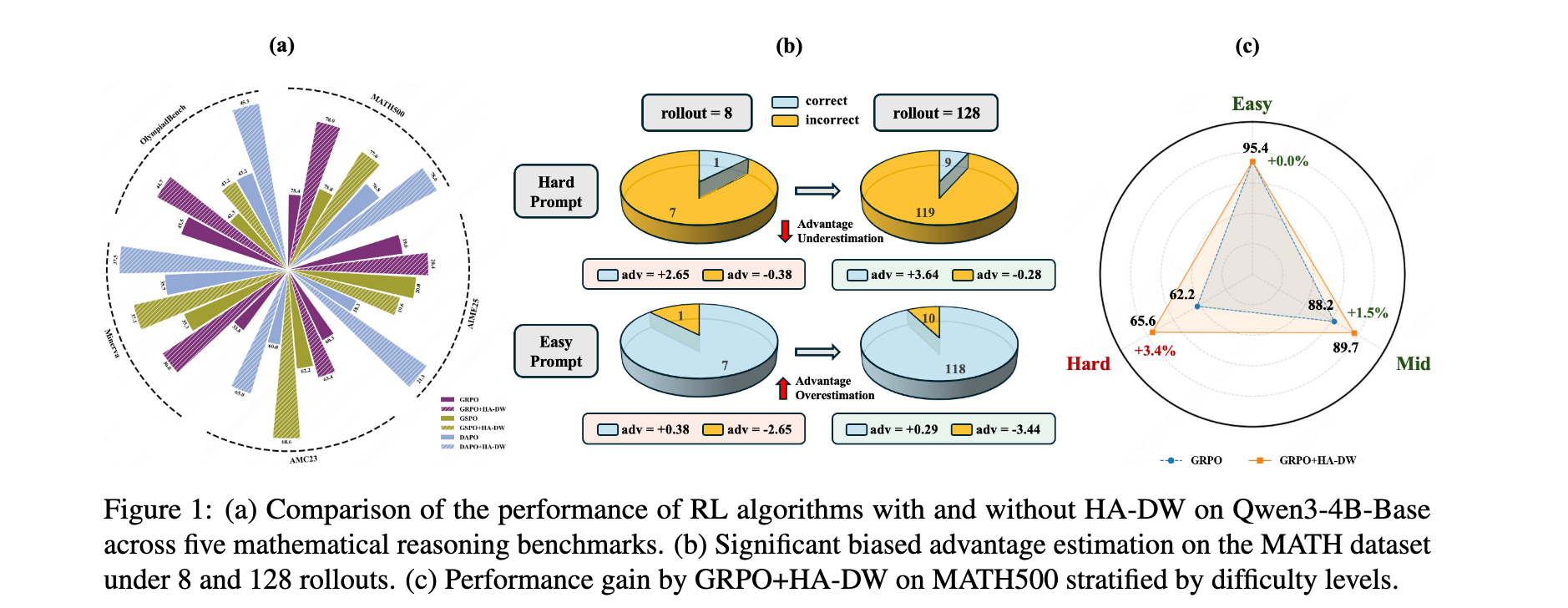
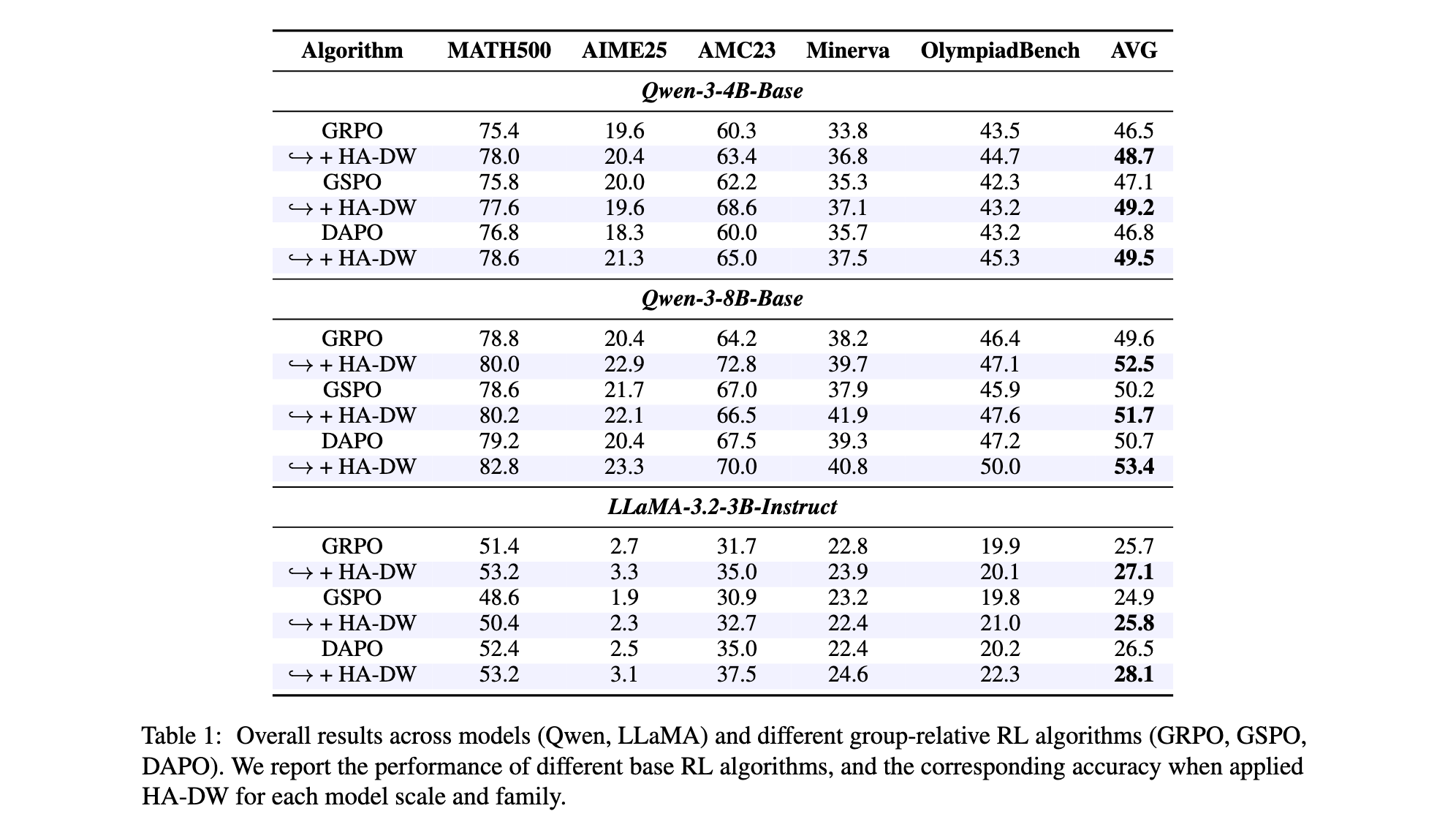
在大型语言模型的后训练时代,强化学习从验证者奖励(RLVR)已成为提升模型推理能力的核心范式。以GRPO为代表的群体相对算法因其无需训练评判网络的简洁设计而备受青睐。然而,本文揭示了这一方法中一个被长期忽视的根本性问题:群体相对优势估计存在系统性偏差。本文不仅提供了首个理论分析,证明该估计器对困难问题会系统性低估优势、对简单问题会过度估计优势,还提出了基于历史感知的自适应难度加权(HA-DW)方案来纠正这一偏差。实验表明,该方法在多个数学推理基准上持续提升性能,为RLVR训练提供了新的理论见解和实践指导。
论文标题: Your Group-Relative Advantage Is Biased
来源: arXiv:2601.08521 | https://arxiv.org/abs/2601.08521
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
随着DeepSeek-R1的成功,强化学习从验证者奖励(RLVR)迅速崛起为训练推理导向LLM的简单而强大的范式。GRPO(Group Relative Policy Optimization)因其无需额外价值网络的群体相对优势估计机制而获得了广泛关注,随后涌现了GSPO、DAPO、Dr.GRPO、GMPO等多种变体以提升算法稳定性和性能。这些方法的核心思想是:对于每个采样的提示词,生成少量响应,使用组内平均奖励作为基线计算优势,从而避免了训练独立的评判模型。这种设计在实践中得到了广泛应用,但其理论性质一直缺乏深入理解。现有的研究虽然关注算法的稳定性和采样效率,却忽视了群体相对优势估计本身可能存在的统计学偏差问题。
研究问题
- 优势估计偏差:群体相对优势估计器相对于真实(期望)优势是否存在系统性偏差?如果有,这种偏差的具体表现是什么?
- 偏差的影响机制:这种偏差如何影响模型的探索与利用平衡?它对困难问题和简单问题分别会产生什么不同的影响?
- 计算约束下的局限性:在实际RLVR训练中,受限于计算资源,每个提示词通常只采样少量响应(如8个)。在这种小群体规模下,优势估计偏差的程度有多严重?
主要贡献
- 理论发现 (核心贡献):首次提供理论分析,揭示了RLVR中基于群体的优势估计存在固有偏差。具体而言,对于困难提示词( p t < 0.5 p_t \lt 0.5 pt<0.5),该估计器会系统性低估期望优势;对于简单提示词( p t > 0.5 p_t \gt 0.5 pt>0.5),则会系统性地高估优势。此外,当提示词难度达到极端情况时( p t < 1 / G p_t \lt 1/G pt<1/G或 p t > ( G − 1 ) / G p_t \gt (G-1)/G pt>(G−1)/G),这种偏差将成为确定性的:估计器必然低估极端困难问题的真实优势,必然高估极端简单问题的真实优势。
- 算法创新:基于这一根本发现,提出了History-Aware Adaptive Difficulty Weighting(HA-DW)算法。该方法通过一个演化的难度锚点整合长期奖励趋势和历史训练信息,动态调整优势权重。HA-DW补偿了群体相对优势估计引入的偏差,实现了RL训练中探索与利用之间更加原则性的平衡。
- 实验验证:在五个数学推理基准上进行了广泛的实验验证,证明了将HA-DW集成到GRPO及其变体中能够在不同模型规模下持续提升性能。值得注意的是,即使与使用更多rollouts的GRPO相比,该方法仍能取得更优结果,展现了其高效性。
方法论精要
问题建模与理论基础
在训练步骤 t t t,我们从数据分布 D D D中采样一个提示词 x t x_t xt。给定 x t x_t xt,群体相对RL算法从当前策略 π θ t ( ⋅ ∣ x t ) \pi_{\theta_t}(\cdot|x_t) πθt(⋅∣xt)中独立采样 G G G个响应 { y t , i } i = 1 G \{y_{t,i}\}{i=1}^G {yt,i}i=1G。每个响应 y t , i y{t,i} yt,i接收一个标量奖励 r t , i ∈ { 0 , 1 } r_{t,i} \in \{0,1\} rt,i∈{0,1},形成奖励集合 { r t , i } i = 1 G \{r_{t,i}\}_{i=1}^G {rt,i}i=1G,其中 r ( ⋅ ) r(\cdot) r(⋅)是奖励函数。
群体相对策略优化(Group-PO)目标定义为:
J group ( θ ) = 1 G ∑ i = 1 G ψ ( π θ ( y t , i ∣ x t ) π θ old ( y t , i ∣ x t ) ) ϕ ( A ^ t , i ) J_{\text{group}}(\theta) = \frac{1}{G}\sum_{i=1}^G \psi\left(\frac{\pi_\theta(y_{t,i}|x_t)}{\pi_{\theta_{\text{old}}}(y_{t,i}|x_t)}\right)\phi(\hat{A}_{t,i}) Jgroup(θ)=G1∑i=1Gψ(πθold(yt,i∣xt)πθ(yt,i∣xt))ϕ(A^t,i)
其中 π θ old \pi_{\theta_{\text{old}}} πθold是参考(行为)策略。群体相对优势 A ^ t , i \hat{A}_{t,i} A^t,i计算为:
A ^ t , i = r t , i − p ^ t , p ^ t = 1 G ∑ i = 1 G r t , i \hat{A}{t,i} = r{t,i} - \hat{p}t, \quad \hat{p}t = \frac{1}{G}\sum{i=1}^G r{t,i} A^t,i=rt,i−p^t,p^t=G1∑i=1Grt,i
这里 p ^ t \hat{p}_t p^t是组基线。
在RLVR设置中,期望奖励定义为:
p t = E y t ∼ π θ t ( ⋅ ∣ x t ) r ( y t ) = P ( r ( y t ) = 1 ∣ x t , π θ t ) p_t = \mathbb{E}{y_t \sim \pi{\theta_t}(\cdot|x_t)}r(y_t) = P(r(y_t)=1|x_t,\pi_{\theta_t}) pt=Eyt∼πθt(⋅∣xt)r(yt)=P(r(yt)=1∣xt,πθt)
期望优势定义为:
A t , i = r t , i − p t A_{t,i} = r_{t,i} - p_t At,i=rt,i−pt
偏差的数学本质
本文的核心发现是:在奖励为二元(0或1)的RLVR设置中,每个响应的奖励可以建模为伯努利随机变量:
r t , i ∼ Bernoulli ( p t ) , ∀ i ∈ G r_{t,i} \sim \text{Bernoulli}(p_t), \quad \forall i \in G rt,i∼Bernoulli(pt),∀i∈G
让 R = ∑ i = 1 G r t , i R = \sum_{i=1}^G r_{t,i} R=∑i=1Grt,i表示组内总奖励。经验组基线为 p ^ t = R / G \hat{p}_t = R/G p^t=R/G。
在基于群体的策略优化中,当 R = 0 R=0 R=0或 R = G R=G R=G时,群体相对优势估计器 A ^ t , i \hat{A}{t,i} A^t,i对所有 i ∈ G i \in G i∈G都满足 A ^ t , i = 0 \hat{A}{t,i}=0 A^t,i=0,导致零梯度从而没有参数更新。在实践中,这种退化组要么被显式丢弃,要么被GRPO风格的算法隐式忽略。
因此,分析聚焦于有效更新机制,即至少有一个响应接受非零优势的组。这对应于非退化事件:
S : = { 1 ≤ R ≤ G − 1 } S := \{1 \leq R \leq G-1\} S:={1≤R≤G−1}
基于此,本文得到了主要理论结果:定理1 表明,给定提示词 x t ∼ D x_t \sim D xt∼D,令 y t , i ∼ π θ t ( ⋅ ∣ x t ) y_{t,i} \sim \pi_{\theta_t}(\cdot|x_t) yt,i∼πθt(⋅∣xt)为采样响应且奖励为 r t , i r_{t,i} rt,i。假设 G ≥ 2 G \geq 2 G≥2,且对事件 S = { 1 ≤ R ≤ G − 1 } S = \{1 \leq R \leq G-1\} S={1≤R≤G−1}进行条件化,则对于任意 i ∈ G i \in G i∈G:
- 当 p t < 0.5 p_t \lt 0.5 pt<0.5时, E A \^ t , i ∣ S < A t , i \mathbb{E}\\hat{A}_{t,i}\|S \lt A_{t,i} EA\^t,i∣S<At,i
- 当 p t > 0.5 p_t \gt 0.5 pt>0.5时, E A \^ t , i ∣ S > A t , i \mathbb{E}\\hat{A}_{t,i}\|S \gt A_{t,i} EA\^t,i∣S>At,i
- 当且仅当 p t = 0.5 p_t = 0.5 pt=0.5时, E A \^ t , i ∣ S = A t , i \mathbb{E}\\hat{A}_{t,i}\|S = A_{t,i} EA\^t,i∣S=At,i
定理1清晰地展示了群体相对优势估计器的期望偏差方向:对于困难问题( p t < 0.5 p_t \lt 0.5 pt<0.5),该估计器的期望低于真实优势;对于简单问题( p t > 0.5 p_t \gt 0.5 pt>0.5),则高于真实优势。该估计器仅在 p t = 0.5 p_t = 0.5 pt=0.5时是无偏的。随着 p t p_t pt偏离 0.5 0.5 0.5且 G G G越小,这种偏差会放大,如图2所示。
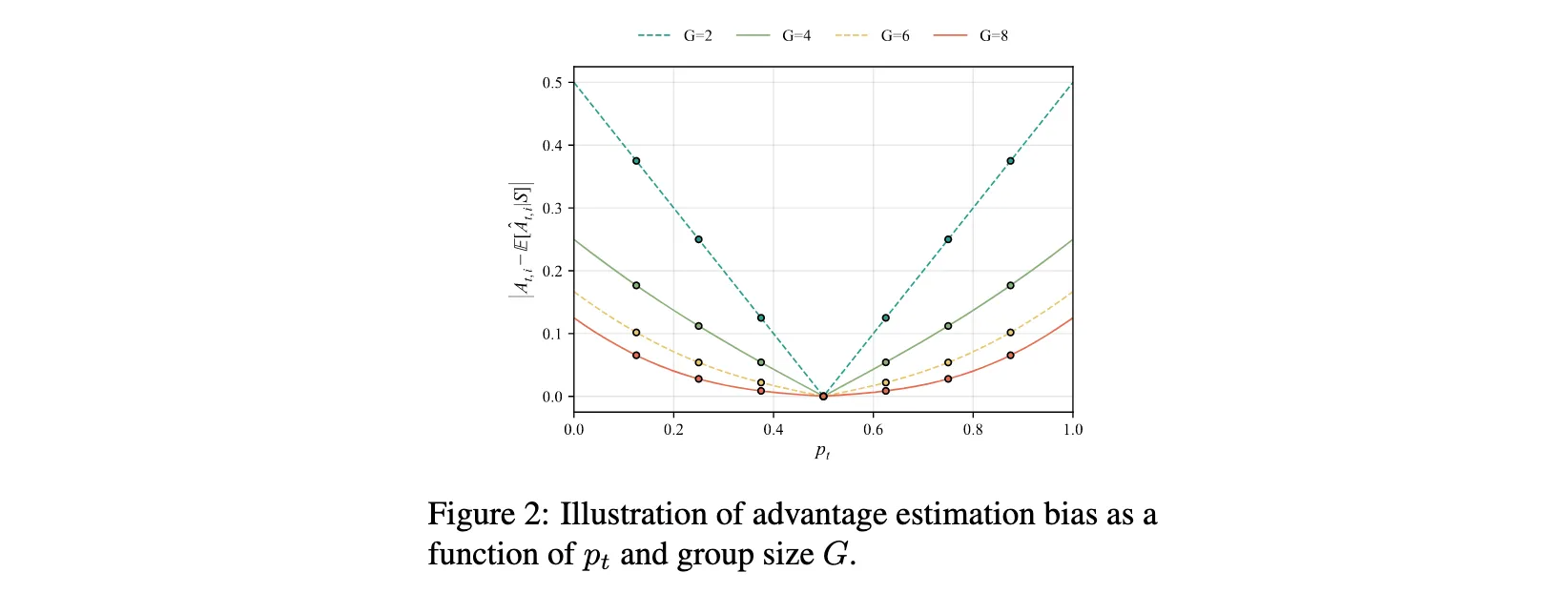
进一步地,定理2在分布层面表征了优势估计的概率性质,提供了大估计误差的精确概率质量。推论1和推论2则在实践中常用的小组规模设置下( 2 ≤ G ≤ 8 2 \leq G \leq 8 2≤G≤8)给出了具体的偏差概率下界。例如,当 p t < 0.25 p_t \lt 0.25 pt<0.25时,优势被低估的概率超过78%;当 p t > 0.75 p_t \gt 0.75 pt>0.75时,优势被高估的概率同样超过78%。推论3更是揭示了一个确定性结果:对于极端困难提示词( p t < 1 / G p_t \lt 1/G pt<1/G),估计器必然低估真实优势;对于极端简单提示词( p t > ( G − 1 ) / G p_t \gt (G-1)/G pt>(G−1)/G),估计器必然高估真实优势。
HA-DW算法设计
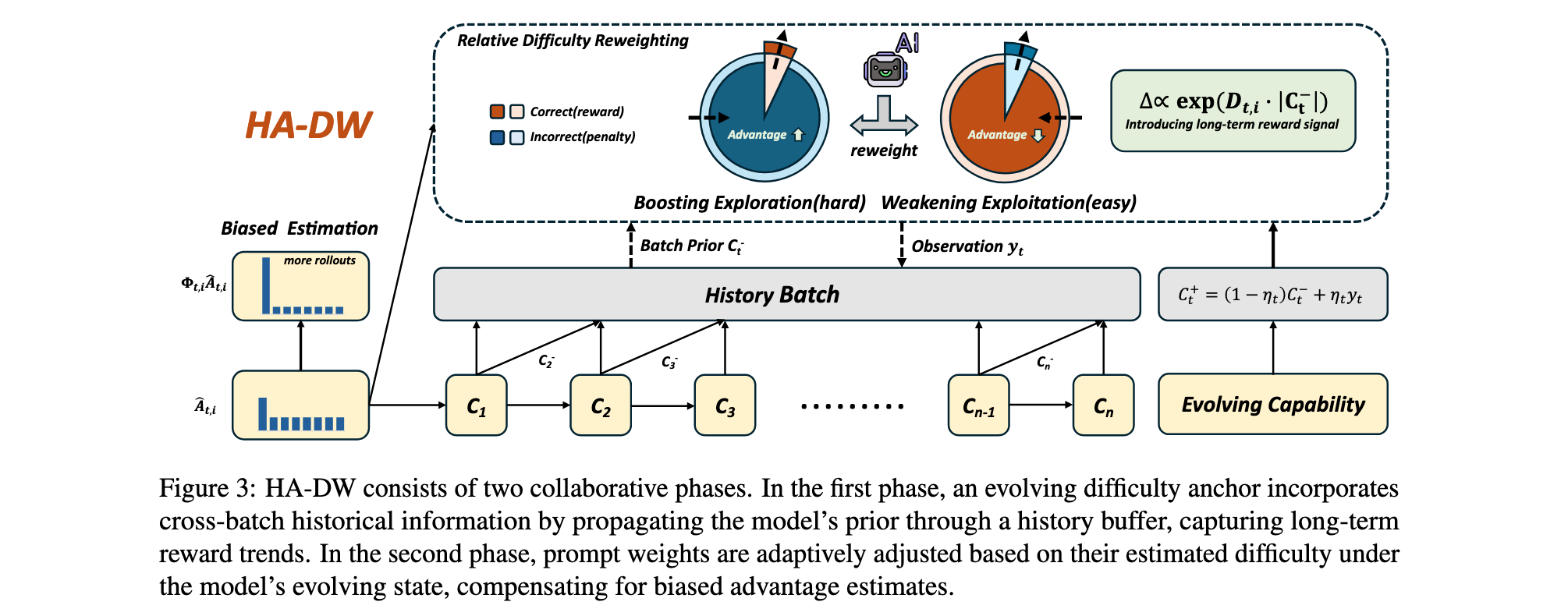
为了纠正群体相对优势估计的固有偏差,本文提出了HA-DW算法,包含两个关键组成部分。
1. 演化难度锚点(Evolving Difficulty Anchor)
为了跨批次跟踪演化的模型状态,本文提出了跨批次难度锚点框架,整合长期奖励趋势和历史信息。令 B t B_t Bt表示批次 t t t中的响应总数。模型更新由当前批次的提示词准确率 y t y_t yt与历史信息共同指导,定义为:
y t = K t B t , K t = ∑ i = 1 B t r t , i y_t = \frac{K_t}{B_t}, \quad K_t = \sum_{i=1}^{B_t} r_{t,i} yt=BtKt,Kt=∑i=1Btrt,i
将模型的求解能力 C t C_t Ct视为潜在信念状态。在训练步骤 t t t,使用观测值 y t y_t yt通过类卡尔曼更新将先验信念 C t − C_t^- Ct−更新为后验信念 C t + C_t^+ Ct+:
C t + = ( 1 − η t ) C t − + η t y t , η t ∈ 0 , 1 C_t^+ = (1 - \eta_t)C_t^- + \eta_t y_t, \quad \eta_t \in 0,1 Ct+=(1−ηt)Ct−+ηtyt,ηt∈0,1
遗忘因子 η t \eta_t ηt控制历史信息的影响,并通过模型稳定性动态调制。具体地,计算前 m m m个批次的平均信念:
C ˉ t = 1 m ∑ j = 1 m C t − j \bar{C}t = \frac{1}{m}\sum{j=1}^m C_{t-j} Cˉt=m1∑j=1mCt−j
定义相应的标准差:
σ t = 1 m ∑ j = 1 m ( C t − j − C ˉ t ) 2 \sigma_t = \sqrt{\frac{1}{m}\sum_{j=1}^m (C_{t-j} - \bar{C}_t)^2} σt=m1∑j=1m(Ct−j−Cˉt)2
自适应遗忘因子为:
η t = η ⋅ σ t \eta_t = \eta \cdot \sigma_t ηt=η⋅σt
其中 η \eta η是任务相关的超参数。直观上,训练早期使用较大的 η t \eta_t ηt以捕获快速的能力变化,后期使用较小的 η t \eta_t ηt以保留历史信息并减少噪声。在连续步骤之间,后验信念 C t + C_t^+ Ct+作为下一批次的先验信念: C t + → C t + 1 − C_t^+ \rightarrow C_{t+1}^- Ct+→Ct+1−。整体上, C t C_t Ct通过信念更新聚合跨历史批次的信息,并基于此演化信念调节训练策略。这个演化信念作为后续难度自适应重加权的感知锚点。
2. 历史感知自适应难度加权(History-Aware Adaptive Difficulty Weighting)
为了纠正群体相对优势估计中的固有偏差,引入HA-DW,基于模型演化状态动态调整优势权重,同时整合长期奖励信号。结合演化难度锚点,定义基于历史的提示词难度为:
diff his t = p ^ t − C t − \text{diff}_{\text{his}}^t = \hat{p}_t - C_t^- diffhist=p^t−Ct−
其中 diff his t \text{diff}_{\text{his}}^t diffhist捕捉了提示词难度相对于当前模型信念的幅度和方向。
确定调整方向时,使用演化难度锚点作为参考,定义:
D t , i = − sgn ( A ^ t , i ) ⋅ sgn ( diff his t ) D_{t,i} = -\text{sgn}(\hat{A}{t,i}) \cdot \text{sgn}(\text{diff}{\text{his}}^t) Dt,i=−sgn(A^t,i)⋅sgn(diffhist)
其中 sgn ( ⋅ ) \text{sgn}(\cdot) sgn(⋅)表示符号函数。
量化调整幅度时,使用绝对历史难度:
M t = ∣ diff his t ∣ M_t = |\text{diff}_{\text{his}}^t| Mt=∣diffhist∣
这里 M t M_t Mt衡量提示词偏离模型当前能力的程度。
定义历史感知重加权因子:
Φ t , i = λ scale ⋅ exp ( D t , i ⋅ M t ) \Phi_{t,i} = \lambda_{\text{scale}} \cdot \exp(D_{t,i} \cdot M_t) Φt,i=λscale⋅exp(Dt,i⋅Mt)
其中 λ scale \lambda_{\text{scale}} λscale是缩放常数,指数形式确保优势权重的平滑和乘法调整。
得到的HA-DW目标为:
L HA-DW ( θ ) = 1 G ∑ i = 1 G ψ ( π θ ( y t , i ∣ x t ) π θ old ( y t , i ∣ x t ) ) ⋅ ϕ ( A ^ t , i ) ⋅ Φ t , i L_{\text{HA-DW}}(\theta) = \frac{1}{G}\sum_{i=1}^G \psi\left(\frac{\pi_\theta(y_{t,i}|x_t)}{\pi_{\theta_{\text{old}}}(y_{t,i}|x_t)}\right) \cdot \phi(\hat{A}{t,i}) \cdot \Phi{t,i} LHA-DW(θ)=G1∑i=1Gψ(πθold(yt,i∣xt)πθ(yt,i∣xt))⋅ϕ(A^t,i)⋅Φt,i
其中 ψ ( ⋅ ) \psi(\cdot) ψ(⋅)和 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)遵循群体相对RL算法中的具体定义。
直观上, Φ t , i \Phi_{t,i} Φt,i对困难提示词的估计优势进行放大------此时基于群体的估计较为保守------而对简单提示词的估计优势进行抑制------此时过度估计普遍存在------从而纠正了分析中识别的系统性偏差。HA-DW可以作为即插即用的模块无缝集成到GRPO及其变体中,在固定rollouts下提升推理性能,同时有效缓解偏差优势估计。
3. 理论保证
本文提供了理论分析以证明所提出的调整策略的有效性。引理1表明,通过适当的重加权因子 c c c,可以减少估计偏差。定理3证明了,在适当的缩放参数 λ scale \lambda_{\text{scale}} λscale选择下,HA-DW调整产生的优势估计在期望上更接近真实优势 A t , i A_{t,i} At,i。这个理论结果为实践中选择 λ scale \lambda_{\text{scale}} λscale提供了原则性指导。
实验洞察
实验设置
在Qwen3-4B-Base、Qwen3-8B-Base和LLaMA-3.2-3B-Instruct上进行了实验,评估不同算法在五个常用RLVR基准上的数学推理性能。将提出的HA-DW方法应用于几种代表性的群体相对强化学习算法:GRPO、GSPO和DAPO。比较应用HA-DW的群体相对算法与原始方法的性能,验证了方法的有效性和可扩展性。在VeRL框架内,使用单个节点的8块NVIDIA A100 GPU进行RL训练。
主要结果
表1展示了主要结果。值得注意的是,配备HA-DW的基于群体的RL算法(GRPO、GSPO和DAPO)在五个基准上均优于原始方法。在不同规模和系列的不同模型上,在基准上观察到清晰且一致的改进。总体而言,结果强调了HA-DW通过动态重加权重来补偿优势估计偏差,充分利用那些被掩盖的关键提示词,从而释放RL中的潜在性能增益。
为了验证方法在扩展模型能力方面的有效性,将MATH500数据集分为三个难度级别:简单(Level 1)、中等(Levels 2-3)和困难(Levels 4-5)。评估了使用GRPO和GRPO+HA-DW训练的Qwen3-4B-Base,如图1©所示。两种方法在简单和中等级别上的表现相当,但GRPO+HA-DW在困难提示词上比GRPO高出3.4%。这种改进归功于基于历史的动态重加权策略,它增强了对困难提示词的探索,同时减少了对简单提示词的不必要利用。同时,它间接证实了偏差估计的存在。
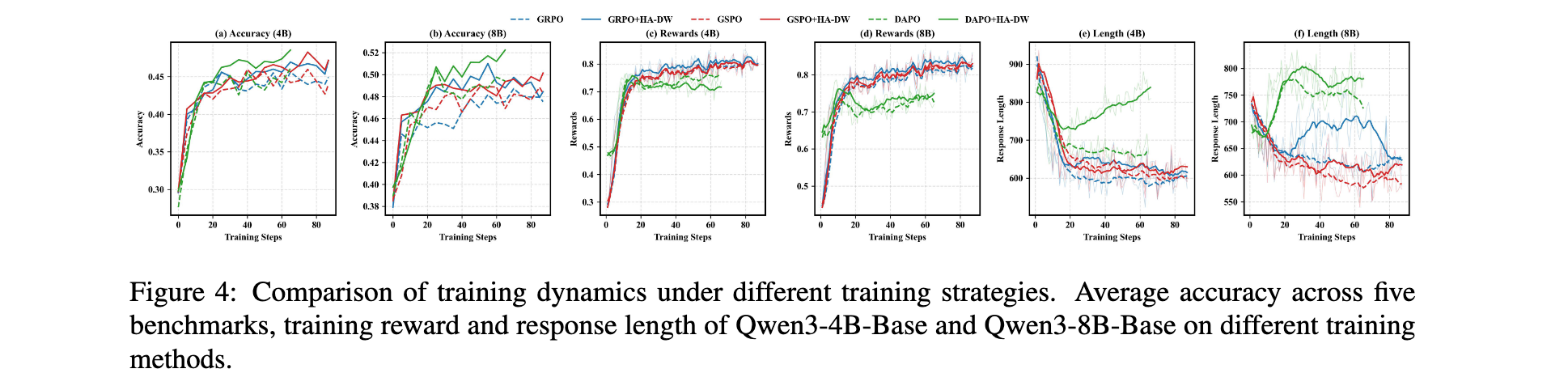
训练动态
图4展示了Qwen3-4B-Base和Qwen3-8B-Base在整个训练过程中五个基准的平均准确率、训练奖励和响应长度的时间动态。应用HA-DW的RL算法在准确率上收敛到更高的性能平台,并获得比原始RL算法更高的奖励,表明HA-DW的应用通过缓解偏差优势估计提升了对困难提示词的探索并减弱了对简单提示词的利用。此外,该方法鼓励更长的推理,大大提高了推理能力。HA-DW能够激励模型产生更复杂的推理思维链来应对更具挑战性的任务。
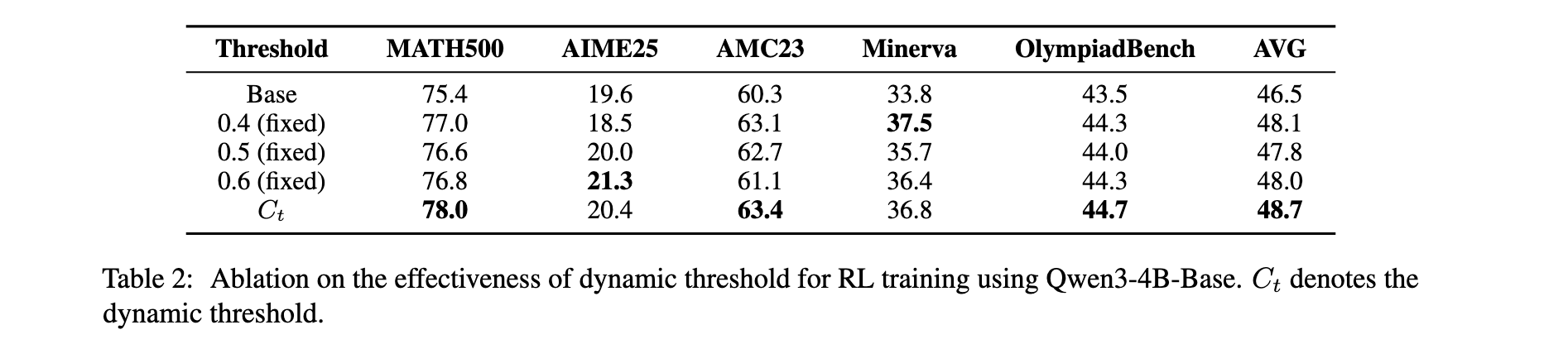
消融实验
对动态阈值 C t C_t Ct的有效性进行了评估,通过在五个基准上将其与固定阈值进行比较,如表2所示。在Qwen3-4B-Base上使用基于GRPO的训练的实验表明,动态调整实现了最佳性能。移除 C t C_t Ct会降低性能,而固定阈值仍然通过部分缓解偏差估计而优于基线。通过整合跨批次信息, C t C_t Ct捕获长期奖励信号并进一步增强RL性能。
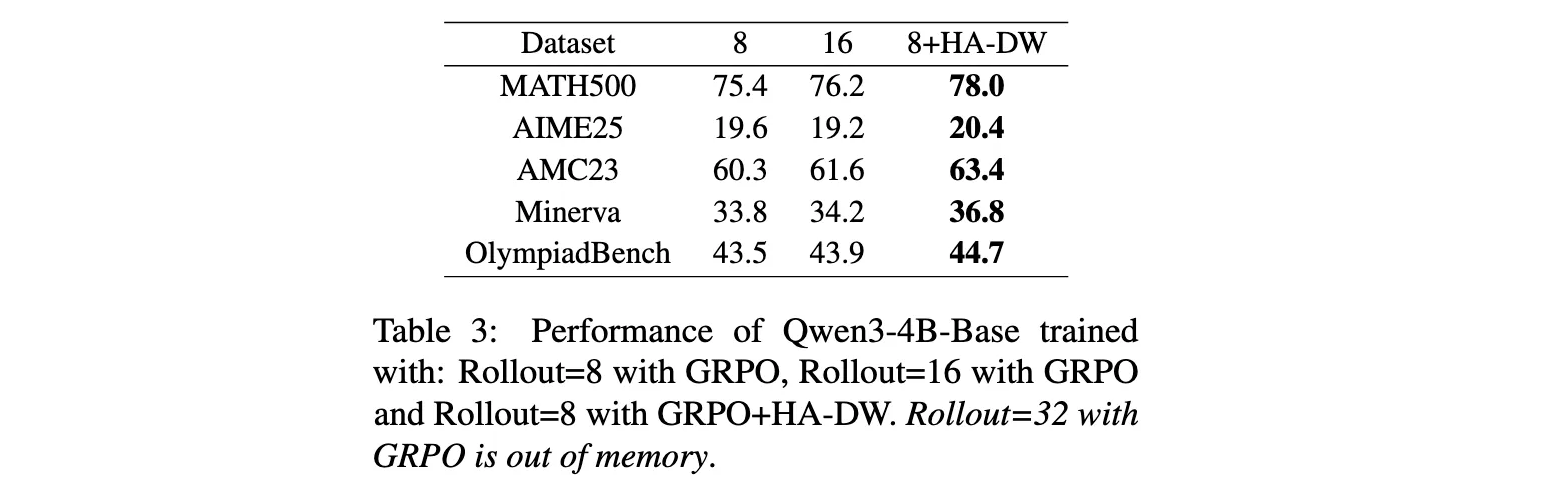
小样本效率
表3比较了使用8个rollouts的GRPO、16个rollouts的GRPO以及8个rollouts加HA-DW的GRPO的性能。结果显示,使用HA-DW的8个rollouts方法在所有基准上都优于16个rollouts的纯GRPO,甚至在某些指标上接近或超过32个rollouts的水平(后者因内存不足无法运行)。这证明了HA-DW在计算资源受限场景下的高效性。
总结与展望
本文揭示了群体相对RL算法的一个基本限制:偏差优势估计。为了解决这个问题,提出了HA-DW,它基于模型演化状态动态调整优势权重。广泛的实验表明,HA-DW通过缓解偏差优势估计有效地提升了推理性能。
这一工作的意义在于,它不仅发现了一个被长期忽视的理论问题,还提供了一个简单而有效的解决方案。HA-DW可以作为即插即用的模块集成到现有的群体相对RL算法中,无需大幅修改现有训练流程,就能获得稳定的性能提升。这对于在实际应用中部署RLVR具有重要的实用价值。
未来的研究方向包括:将该方法扩展到更广泛的有偏估计场景;探索其他类型的跨批次信息整合策略;在非数学推理任务上验证该方法的有效性;以及深入研究不同奖励函数设置下偏差的本质和纠正策略。
总之,本文为RLVR领域的理论研究和实践应用提供了新的见解,推动了对群体相对算法局限性的深入理解,并为构建更鲁棒、更高效的强化学习训练系统指明了方向。