目录
[方案 C:100% 效率数据拼接器 (Gearbox)](#方案 C:100% 效率数据拼接器 (Gearbox))
[方案 D:通道分离存储(Channel Striping)](#方案 D:通道分离存储(Channel Striping))
[2.1. 原始数据量计算](#2.1. 原始数据量计算)
[2.2. 存储空间需求 (以字节为单位)](#2.2. 存储空间需求 (以字节为单位))
[2.3. 不同方案的占用对比](#2.3. 不同方案的占用对比)
[2.4. 硬件设计建议](#2.4. 硬件设计建议)
[3.1. 设计约束与目标](#3.1. 设计约束与目标)
[3.2. 数学推导过程](#3.2. 数学推导过程)
[3.3. 最优值选取](#3.3. 最优值选取)
[3.4. 结论](#3.4. 结论)
[4.1 原始的1000Byte](#4.1 原始的1000Byte)
[4.2 忽略了DDR突发读写的1440 Byte](#4.2 忽略了DDR突发读写的1440 Byte)
[4.2.1. 核心约束:寻找"完美包长"](#4.2.1. 核心约束:寻找“完美包长”)
[4.2.2. 方案对比与最终推荐](#4.2.2. 方案对比与最终推荐)
[4.2.3. 1440 字节方案的优缺点](#4.2.3. 1440 字节方案的优缺点)
5.拓展------DDR的突发读写长度(程序死机的原因))
[5.1. 什么是 Burst Length (突发长度)?](#5.1. 什么是 Burst Length (突发长度)?)
[5.2. 突发长度 8 与你的 DATA_NUM = 128 的关系](#5.2. 突发长度 8 与你的 DATA_NUM = 128 的关系)
[5.3. 为什么这会导致状态机卡死在 0x10?](#5.3. 为什么这会导致状态机卡死在 0x10?)
前言
问题:模数转换器AD芯片的采样率为4M,位宽是24bit,。DDR3的位宽是64bit,突发读写的长度是8。上位机软件可能会采集单通道、双通道、三通道的数据,需要设计一种打包方式完成数据打包上传。该笔记主要是记录思考的过程。
1.方案对比
一开始思维被限定住了,以为DDR3的位宽是64bit,所以数据只能按64位打包,然后想着单通道采集和双通道采集时,每24bit填充成32位,这样子就可以按64bit打包了。三通道的时候舍弃第三位,填充1位合并成64位。但是这个方案会影响采集的精度,也不能充分发挥24位AD芯片。所以考虑还是以32位数据打包,32位数据打包有两种方案。对比一下这两种方案的"消耗":
方案A和方案B:
| 维度 | 方案 A (96位填入128位) | 方案 B (每个24位补齐到32位,分次存入) |
|---|---|---|
| DDR3 空间浪费 | 较大 。每存一组数据浪费 |
较小 。每存一个通道浪费 |
| DDR3 带宽效率 | 效率约 56% (72/128)。 | 效率约 75% (72/96)。 |
| FIFO 资源占用 | 较高。128 bit 位宽非常消耗 BRAM 资源。 | 较低。32 bit 位宽更省资源。 |
| 逻辑实现难度 | 最简单(直接拼接)。 | 略高(需要一个简单的状态机或计数器)。 |
| Vivado IP 支持 | 支持 (128:64 是 2:1 比例)。 | 支持 (32:64 是 1:2 比例)。 |
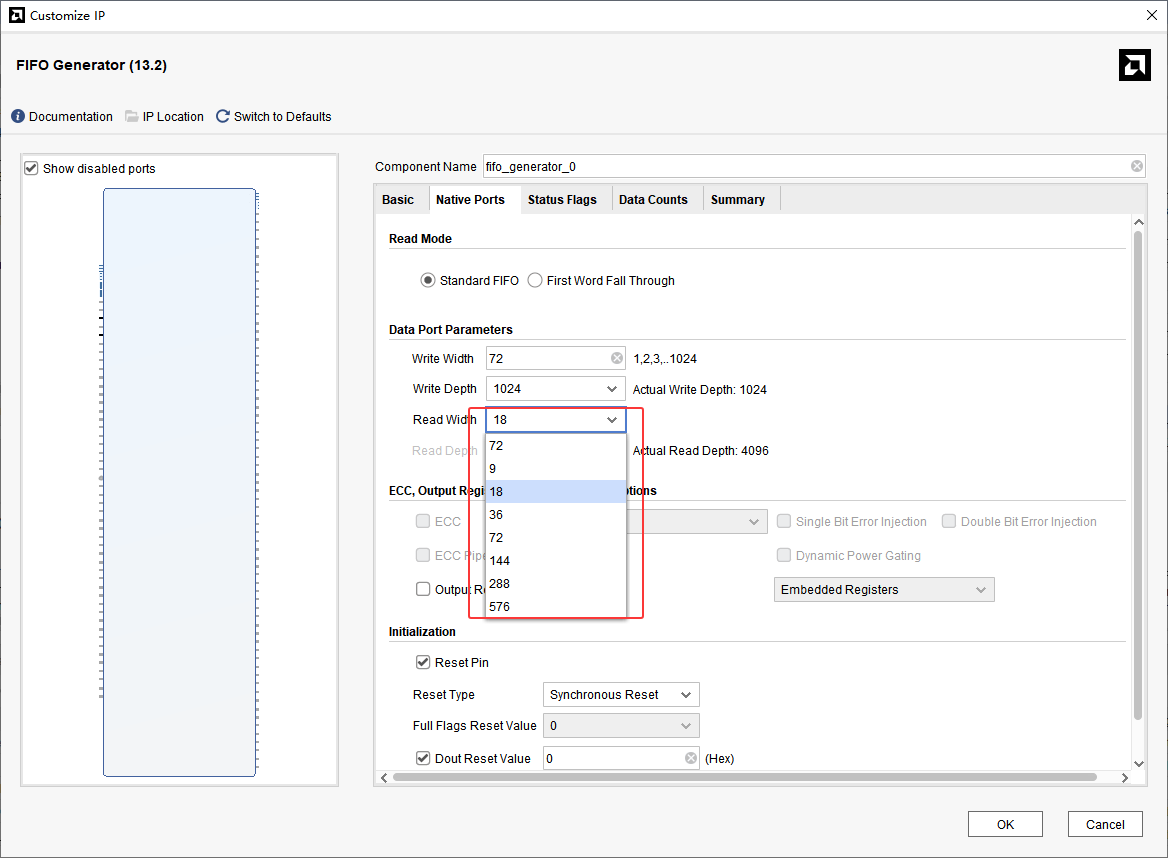
以上这两种方案都会浪费空间,增加存储的数据量。因此还需要更好的方案。考虑过将FIFO设计为72位写入,64位读出,但是vivado的FIFO IP核只能是2的倍数关系,如下图所示:
因此需要自己设计一个72bit转64bit的拼接器,方案如下:
方案 C:100% 效率数据拼接器 (Gearbox)
这个方案的核心逻辑是:利用"最小公倍数"原理。
这意味着:你每输入 8 个 采样包(每个 72bit),逻辑上正好可以产出 9 个 DDR3 数据字(每个 64bit)。
逻辑实现思路
位移缓存:建立一个约 128bit 的移位寄存器。
积攒输出 :每次输入 72bit,缓存器里的有效位数就会增加。只要有效位数
,就输出一个 64bit 数据,并将剩下的位左移待用。
零浪费:DDR3 的每一位都填满了 ADC 数据。
具体实现可以了解这篇笔记:FPGA设计技巧:基于动态掩码的Verilog数据位宽转换实现(72bit转64bit)-CSDN优缺ding
优缺ding点:
| 优点 (Better) | 缺点 (Trade-offs) |
| 存储空间 100% 利用:不浪费 1GB 里的任何 1bit。 | 软件解析复杂:一个 24bit 的采样值可能被劈成两半。例如:前 8bit 存在第 N 个地址,后 16bit 存在第 N+1 个地址。 |
节省 DDR 带宽:同样的采样率下,对 DDR3 的带宽压力减小 25%。 时序压力:移位寄存器和状态机在高速时钟下(如 200MHz+)可能需要打拍优化以满足时序。
其实还有一种方案,这是更常见的一种方案------通道分离存储。
方案 D:通道分离存储(Channel Striping)
-
做法:不将CH1/CH2/CH3 拼在一起存。给每个通道开辟独立的 DDR3 区域。
-
每个通道是 24bit。你可以把 CH1 的 8 个采样(
-
评价:对软件最友好。软件做 FFT 时通常只需要某一个通道的数据,这种存法让软件读取速度起飞。
但是这种做法会使存储空间受限,因此没有采用。
方案C和方案D方法对比:
-
如果是为了省空间 (比如要存很久的数据):用 Gearbox 方案。
-
如果是为了方便后面写算法 (如 FFT/滤波):用方案 E(通道分离)。
2.数据量对比
4MHz 采样率、3 片 AD 芯片同时采集(每片 24bit),结合方案C设计的 100% 效率 Gearbox 逻辑,详细计算一下 DDR3 的存储空间占用情况。
2.1. 原始数据量计算
单通道位宽:24 bit
通道数量:3 通道
单次采样总位宽 :
采样频率 :
总数据速率 (Data Rate):
2.2. 存储空间需求 (以字节为单位)
方案C的Gearbox 逻辑,没有任何补零浪费,存储效率为 100%:
每秒写入量 :
每分钟写入量 :
每小时写入量 :
2.3. 不同方案的占用对比
为了直观展示 方案C的Gearbox 逻辑的优势,对比一下之前讨论过的补齐方案:
存储策略 位宽效率 每秒占用 (MB/s) 每小时占用 (GB) 结论 方案C:Gearbox (100% 效率) 100% 36 MB/s 126.6 GB 最省空间 方案B:补齐为 32bit (96bit/采样) 75% 48 MB/s 168.8 GB 多消耗约 42 GB/小时 方案A:补齐为 128bit (128bit/采样) 56% 64 MB/s 225.0 GB 多消耗约 98 GB/小时 2.4. 硬件设计建议
4*512MB的存储时间:512MB*4/36=56 s。
3.数据打包的长度
数据打包的长度需要考虑两点:一个是24bit的采样数据在一包内不分割;另一个是,一帧数据包的长度要是DDR的突发读写长度8的倍数。因此有以下计算:
数据帧长度与对齐参数 n的推导流程
3.1. 设计约束与目标
在系统数据封装过程中,需兼容 64-bit 总线与 72-bit 数据块的对齐要求。设 n 为数据块的组合系数,需满足以下约束条件:
对齐约束:总比特数(数据载荷 + 辅助信息)必须是 64-bit 字长的 8 倍整数倍(即 512-bit 对齐,以适配高速总线突发传输)。
长度约束:总字节数需小于以太网标准 MTU(1500 Byte)。
3.2. 数学推导过程
已知 64 与 72 的最小公倍数(LCM)为 576。根据对齐要求,建立如下同余方程:
符号含义
(3是同步码+时间码+状态码)
提取公因子 64,简化方程:
即要求 (9n + 3)$是 8 的倍数:
利用模运算性质拆解:
解得 n的取值序列为:
3.3. 最优值选取
进一步考虑存储深度与传输效率,对比不同 n 值下的载荷长度(以 Byte 为单位):
当 n = 21 时:
此结果超过了标准以太网帧或内部缓冲区的长度限制。
当 n = 13 时:
该长度在 1500 Byte 限制内,且具备较好的传输效率与对齐特性。
3.4. 结论
综上所述,取 n = 13 ,则DATA_NUM=13*9+3=120 作为系统最优封装系数,此时对应的数据载荷长度为 936 Byte 。其对应三通道的采样时间是26 微秒 。
计算每次采样产生的数据量(数据帧大小)
每次采样时,3个通道同时采集数据。
单通道位宽: 24 bit = 3 Byte
通道数: 3 通道
单次采样总字节数:
计算一个数据包包含的采样点数
用数据包的总长度除以单次采样的字节数。
数据包长度: 936 Byte
采样点数:936 / 9=104 个采样点
计算时长
根据采样率计算这 104 个点需要多长时间。
采样率: 4 MHz(即每秒采集 4,000,000 次)
单个采样点周期:
总时长:
总结:
每个 936 字节的数据包包含了 104 次 采样的数据,对应的时间长度为 26 us。
同理,对应两通道的时间为 26us*3/2 = 39us ;单通道: 26us * 3 = 78us
4.正向寻找数据长度的过程
这种办法并不好找,但当时用过,想记录一下。
4.1 原始的1000Byte
这是一个非常经典的带宽对齐问题。要让 1 秒的数据在最后一包正好对齐,我们需要从原始数据速率 出发,推导出 64-bit 字数 ,再找到能被整除的包长。
第一步:计算 1s 的总数据量
采样率:4 MSPS = 4,000,000 次采样/秒
总样本数:4,000,000 * 3 通道 = 12,000,000 个样本/秒
原始位宽:每个样本 24 bit
总比特数 (bps):12,000,000 * 24 = 288,000,000 bit/s
转换到 64-bit 流:
288,000,000 / 64 = 4,500,000个 (64-bit 字)/秒
我们要找的每一帧的数据长度(DATAs) ,必须能整除 4,500,000。
第二步:推荐的打包长度方案
根据通信协议,采样数据长度是
1000Byte。以此为条件来验证并优化:方案 A:采用您标注的 1000 字节(最推荐)
每个 64-bit 字 = 8 字节。
每包 64-bit 字数:1000 字节 / 8 = 125 个。
验证整除性:4,500,000 / 125 = 36,000 包/秒。
结论 :完美对齐。每秒发送 36,000 包,最后一包结束时正好是第1秒的最后一比特。
**2026-01-27-lhw:**这个如果按秒来看是可以的,但是按帧来看最后一个数据点125*64=8000,72*111=7992,所以每一帧的最后8位,是下一帧的一个数据提供的,如果采的帧数不是9的倍数的话会有不完整的帧。所以原来的1000Byte不再适用。
4.2 忽略了DDR突发读写的1440 Byte
为了配合 方案 C:100% 效率 Gearbox (72bit -> 64bit) ,我们必须在原本的"时间对齐"基础上,增加一个核心约束:包长度必须是 Gearbox 处理单元的整数倍。这样可以确保每一包的结尾正好是一个采样点的结束,而不会出现"半个采样点在第一包,半个在第二包"的极其复杂的解包逻辑。
4.2.1. 核心约束:寻找"完美包长"
根据 Gearbox 原理,最小的完整转换单元是:
输入: 8个采样包 * 72 bits = 576 bits
输出: 9 个存储字 * 64 bits = 576 bits
字节数: 576 bits / 8 = 72 Bytes
因此,你的 DATAs(数据载荷) 长度必须能同时满足以下两个条件:
Gearbox 对齐: 必须是 72 字节 的整数倍。
1s 对齐: 必须能整除一秒内的总字节数 36,000,000 Bytes。
4.2.2. 方案对比与最终推荐
我们来筛选符合上述两个条件的长度(单位:字节):
候选长度 (Byte) 是否是 72 的倍数 (Gearbox) 1s 是否对齐 (36,000,000) 评价 1000 ❌ (13.88倍) ✅ 放弃。会导致每包结束时有残余位。 1152 ✅ (16倍) ✅ (31,250 包/秒) 推荐。数据长度适中。 1440 ✅ (20倍) ✅ (25,000 包/秒) 最推荐。接近以太网 MTU (1500),效率最高。 720 ✅ (10倍) ✅ (50,000 包/秒) 可选。但包头比例略高。 4.2.3. 1440 字节方案的优缺点
选择 1440的优点:
Gearbox 逻辑简单: 每发送完一个数据包,Gearbox 内部的
bit_cnt刚好归零。你不需要处理跨包的"残余位移"。以太网效率高: 加包头后约 1480 字节,正好处于标准以太网帧(1500 字节)的边缘,不分片,带宽利用率最高。
选择 1440的缺点:
- 不满足DDR3的突发读写长度 : 1440 字节等于 180 个 64-bit 字。180 / 8 = 22.5。DDR3 突发(Burst 8)不对齐。
5.拓展------DDR的突发读写长度(程序死机的原因)
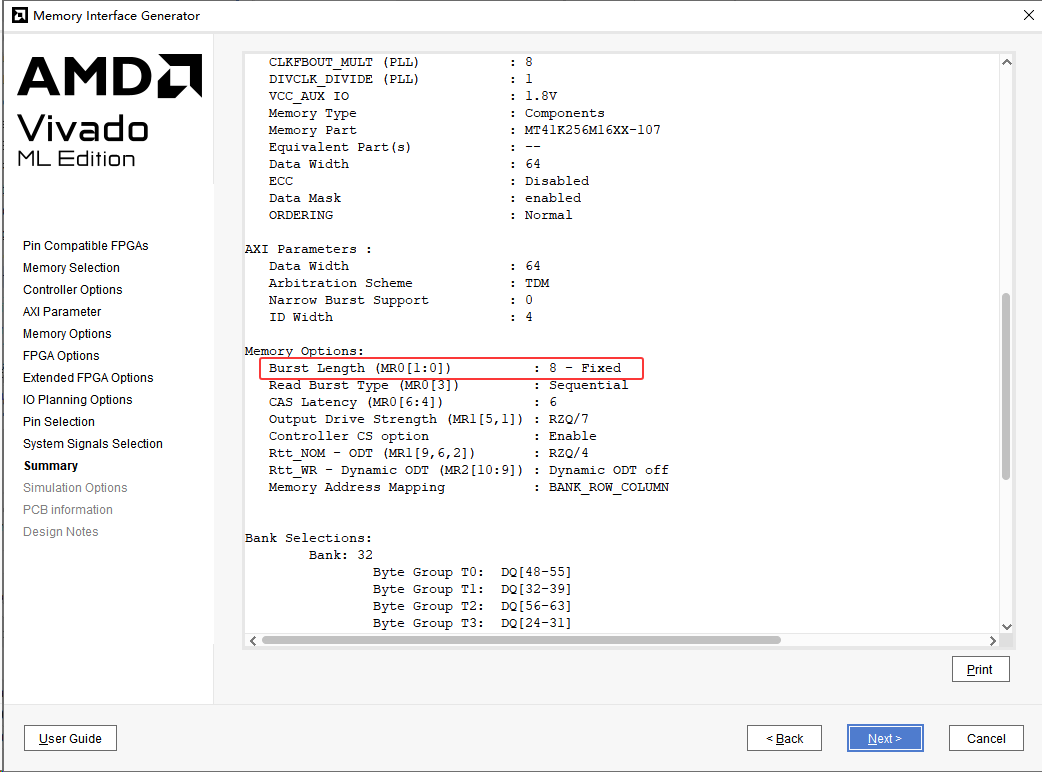
图中显现的是 Memory Interface Generator (MIG) 的配置摘要。红框中的 "Burst Length (MR01:0) : 8 - Fixed" 是 DDR3 物理层的一个核心参数。:
5.1. 什么是 Burst Length (突发长度)?
-
物理层属性:在 DDR3 存储器中,突发长度是指每发送一个读/写命令,存储器连续传输的数据个数。
-
为什么是 8 :对于 DDR3 来说,8 是标准突发长度(BL8)。这意味着 DDR3 芯片内部每次物理操作最少处理 8 个数据位宽。由于你的数据位宽是 64-bit,每 1 次物理突发会处理
-
"Fixed" (固定):意味着该控制器被固定设置为 BL8 模式,不支持切换到 BC4(突发中断 4)模式。
5.2. 突发长度 8 与你的 DATA_NUM = 128 的关系
这是一个非常容易混淆的地方:
-
AXI 层面的突发 (
DATA_NUM):这是你在 Verilog 代码中设置的 AXI 总线事务长度。你设置的是 128,意味着一次 AXI 事务包含 128 个 64-bit 数据。 -
物理层面的突发 (
Burst Length):这是 MIG 控制器操作 DDR3 芯片的物理方式。 -
自动转换 :MIG 内部的 AXI 接口会自动将你那 128 个数据的长事务,拆分成
5.3. 为什么这会导致状态机卡死在 0x10?
之前的 AXI4_ctrl.v 卡在 S_WR_RESP (0x10),即等待 BVALID 信号。这通常与物理层的配置有以下冲突:
-
对齐要求 :因为物理突发长度是 8,所以 AXI 总线的地址和长度必须是 8 的倍数。
-
你的
DATA_NUM = 128是 8 的倍数,这通常是安全的。 -
风险点 :如果你在代码中临时修改
DATA_NUM为一个非 8 的倍数(比如 147,如你注释中提到的),MIG 可能会因为地址/长度不对齐 而拒绝处理,从而不返回BVALID,导致死锁。
-
-
WLAST 信号 :MIG 必须接收到 128 个数据,并且第 128 个数据伴随
s_axi_wlast高电平,才会认为写操作结束并返回BVALID。
以上就是本次笔记的内容。