参考文:Cao B, Xia Y, Ding Y, et al. Predictive Dynamic FusionJ. arXiv preprint arXiv:2406.04802, 2024.2406.04802 Predictive Dynamic Fusion
一、理论
今天就先看看论文中的各个指标含义和多模态训练代码的参数吧
文章中一个比较重要的概念就是置信度的概念了,在论文前段,对置信度的扩展比较多同时没有什么具体说明,不知道概念的话读着还是很混乱的;
置信度
在机器学习中,置信度表示模型对其预测结果"有多确定"。
它刻画的是:模型认为自己预测是正确的程度
例如,在分类任务中:"这是正类的概率是 0.92",那么 0.92 就可以视为模型对该预测的置信度
在监督学习中,给定输入样本 xxx,模型预测类别为 y^\hat{y}y^,则置信度通常定义为:
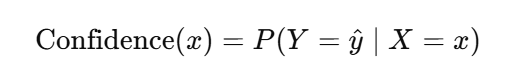
即:模型对预测类别的后验概率估计
置信度 和 不确定性(补充)
文中用熵来衡量整体不确定性,算是置信度的一种扩展:
关于熵的概念,之前在b站看到的一位up主讲的很生动:https://www.bilibili.com/video/BV15V411W7VB/
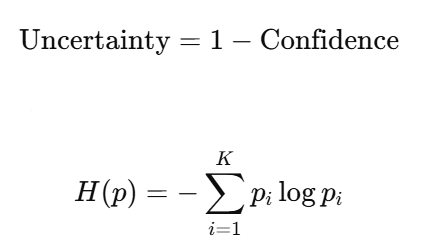
置信度高 <=> 熵低
分类评价指标对比
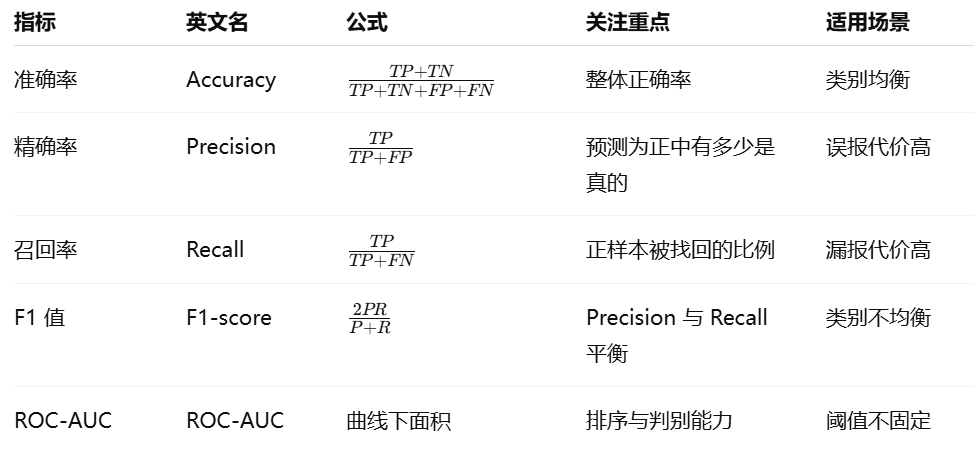
指标含义对照
| 指标 | 一句话解释 |
|---|---|
| Accuracy | 模型整体准不准 |
| Precision | 模型说"是"的时候靠谱吗 |
| Recall | 真正"是"的有没有被找全 |
| F1 | Precision 和 Recall 的折中 |
| ROC-AUC | 正样本排在负样本前面的能力 |
The Mono-Confidences and Holo-Confidences
该文的目的之一是为了解决模态权重融合的权重问题;也就是,多个模态分别从多个维度评价目标的状态,给出不一样的结果,怎么融合这几个结果的问题。
目前可以确定的是:融合权重 ω 应当与损失 l 呈负相关,并且与其他模态的损失呈正相关。也就是:当前模态越可靠 → 权重越大;其他模态越不可靠 → 当前模态权重越大
对单个模态的模型,权重 ω 是要求的权重,损失loss是:
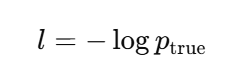
所以,就有人两个信度指标:
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
| The Mono-Confidences | Holo-Confidences |
| 当前模态本身有多可靠 | 相对其他模态我有多可靠 |
| 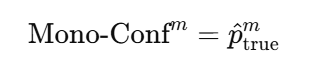 |
| 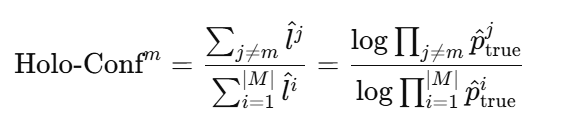 |
|
将他们统合:
Co-Belief(协同信度)
Mono-Confidence:只看自己;Holo-Confidence:只看别人;但多模态融合需要:既考虑自身可靠性,又考虑整体模态状态。
故有:

再由协同信度确定该模态的权重。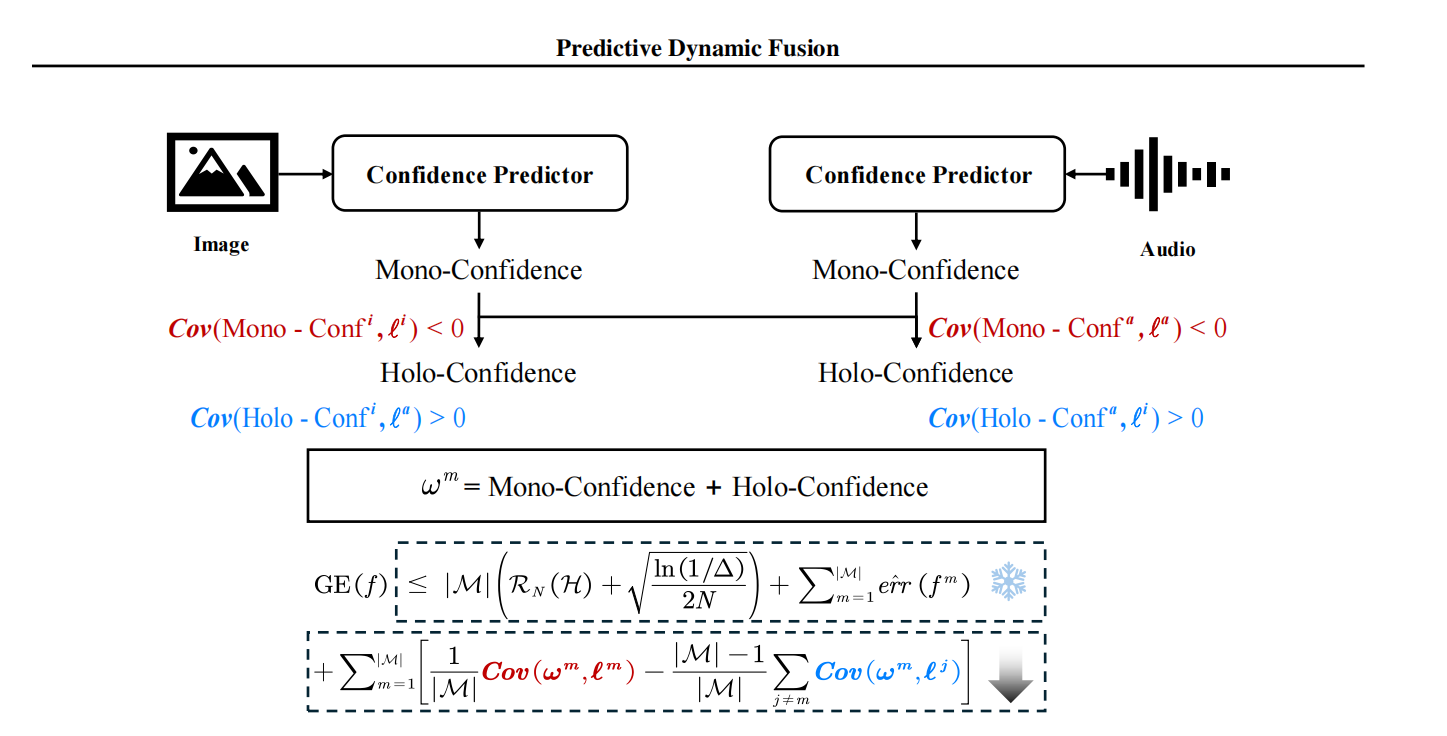
理论先到这里,其他的后面再看;
二、代码
1、运行环境
代码训练环境没有明确说明,但根据结构可以看得出来用的是autodl里的云服务器,Ubuntu20.04+python3.11的版本,卡随便租一个都一样。
论文附带代码只有2mb,明显缺失了很多预训练结构与数据集文件;
2、数据集文件
这里选用了代码中可选的第二个训练集MVSA_Single,需要自己到网站下好转到autodl服务器上:MVSA_Single
训练集之类的划分源代码已有了,自己按要求放到同一目录下即可。
3、词向量文件
源代码缺失了预训练好的词向量文件glove.840B.300d,需要自己使用指令下载到指定目录
wget https://nlp.stanford.edu/data/glove.840B.300d.zip
4、源代码逻辑错误
训练代码中的forward函数存在运行逻辑错误,文本和图像的loss(txt_clf_loss和img_clf_loss)定义在了if之外,会运行不成功;估计是作者没有仔细整理,代码算法逻辑倒没什么问题;
原代码150行左右:
def model_forward(i_epoch, model, args, criterion,optimizer, batch,mode='eval'):
txt, segment, mask, img, tgt,idx = batch
freeze_img = i_epoch < args.freeze_img
freeze_txt = i_epoch < args.freeze_txt
if args.model == "bow":
txt = txt.cuda()
out = model(txt)
elif args.model == "img":
img = img.cuda()
out = model(img)
elif args.model == "concatbow":
txt, img = txt.cuda(), img.cuda()
out = model(txt, img)
elif args.model == "bert":
txt, mask, segment = txt.cuda(), mask.cuda(), segment.cuda()
out = model(txt, mask, segment)
elif args.model == "concatbert":
txt, img = txt.cuda(), img.cuda()
mask, segment = mask.cuda(), segment.cuda()
out = model(txt, mask, segment, img)
elif args.model == "latefusion_pdf":
txt, img = txt.cuda(), img.cuda()
mask, segment = mask.cuda(), segment.cuda()
tgt = tgt.cuda()
maeloss = nn.L1Loss(reduction='mean')
out, txt_logits, img_logits, txt_tcp_pred, img_tcp_pred = model(txt, mask,segment,img,'pdf_train')
label = F.one_hot(tgt, num_classes=args.n_classes) # [b,c]
if args.task_type == "multilabel":
txt_pred = torch.sigmoid(txt_logits)
img_pred = torch.sigmoid(img_logits)
else:
txt_pred = torch.nn.functional.softmax(txt_logits, dim=1)
img_pred = torch.nn.functional.softmax(img_logits, dim=1)
txt_tcp, _ = torch.max(txt_pred * label, dim=1,keepdim=True)
img_tcp, _ = torch.max(img_pred * label, dim=1,keepdim=True)
tcp_pred_loss = maeloss(txt_tcp_pred, txt_tcp.detach()) + maeloss(img_tcp_pred, img_tcp.detach())
else:
assert args.model == "mmbt"
for param in model.enc.img_encoder.parameters():
param.requires_grad = not freeze_img
for param in model.enc.encoder.parameters():
param.requires_grad = not freeze_txt
txt, img = txt.cuda(), img.cuda()
mask, segment = mask.cuda(), segment.cuda()
out = model(txt, mask, segment, img)
tgt = tgt.cuda()
txt_clf_loss = nn.CrossEntropyLoss()(txt_logits, tgt)
img_clf_loss = nn.CrossEntropyLoss()(img_logits, tgt)
clf_loss=txt_clf_loss+img_clf_loss+nn.CrossEntropyLoss()(out,tgt)
if mode=='train':
loss = torch.mean(clf_loss)+torch.mean(tcp_pred_loss)
return loss,out,tgt
else:
loss= torch.mean(clf_loss)+torch.mean(tcp_pred_loss)
return loss,out,tgt修改后:
def model_forward(i_epoch, model, args, criterion, optimizer, batch, mode='eval'):
txt, segment, mask, img, tgt, idx = batch
tgt = tgt.cuda()
clf_loss = 0.0
tcp_pred_loss = 0.0 # ⭐ 先初始化,避免炸
# ---------- 普通单 / 早期融合模型 ----------
if args.model == "bow":
txt = txt.cuda()
out = model(txt)
clf_loss = criterion(out, tgt)
elif args.model == "img":
img = img.cuda()
out = model(img)
clf_loss = criterion(out, tgt)
elif args.model == "concatbow":
txt, img = txt.cuda(), img.cuda()
out = model(txt, img)
clf_loss = criterion(out, tgt)
elif args.model == "bert":
txt, mask, segment = txt.cuda(), mask.cuda(), segment.cuda()
out = model(txt, mask, segment)
clf_loss = criterion(out, tgt)
elif args.model == "concatbert":
txt, img = txt.cuda(), img.cuda()
mask, segment = mask.cuda(), segment.cuda()
out = model(txt, mask, segment, img)
clf_loss = criterion(out, tgt)
# ---------- late fusion(特例) ----------
elif args.model == "latefusion_pdf":
txt, img = txt.cuda(), img.cuda()
mask, segment = mask.cuda(), segment.cuda()
out, txt_logits, img_logits, txt_tcp_pred, img_tcp_pred = \
model(txt, mask, segment, img, 'pdf_train')
# 分类 loss
txt_loss = criterion(txt_logits, tgt)
img_loss = criterion(img_logits, tgt)
clf_loss = txt_loss + img_loss
# TCP loss
maeloss = nn.L1Loss(reduction='mean')
label = F.one_hot(tgt, num_classes=args.n_classes)
if args.task_type == "multilabel":
txt_pred = torch.sigmoid(txt_logits)
img_pred = torch.sigmoid(img_logits)
else:
txt_pred = F.softmax(txt_logits, dim=1)
img_pred = F.softmax(img_logits, dim=1)
txt_tcp, _ = torch.max(txt_pred * label, dim=1, keepdim=True)
img_tcp, _ = torch.max(img_pred * label, dim=1, keepdim=True)
tcp_pred_loss = (
maeloss(txt_tcp_pred, txt_tcp.detach()) +
maeloss(img_tcp_pred, img_tcp.detach())
)
# ---------- mmbt ----------
else:
assert args.model == "mmbt"
txt, img = txt.cuda(), img.cuda()
mask, segment = mask.cuda(), segment.cuda()
out = model(txt, mask, segment, img)
clf_loss = criterion(out, tgt)
# ---------- 总 loss ----------
loss = clf_loss + tcp_pred_loss
return loss, out, tgt四、各训练参数
主要是get_args里面的参数解释:
训练与优化相关参数
| 参数名 | 默认值 | 含义说明 | 影响阶段 | 备注 / 建议 |
|---|---|---|---|---|
batch_sz |
128 | 每个 batch 的样本数量 | 训练 | 大 batch 更稳定,但占显存 |
gradient_accumulation_steps |
24 | 梯度累积步数 | 训练 | 等效 batch = batch_sz × steps |
lr |
1e-4 | 初始学习率 | 训练 | BERT 微调常用 1e-5~5e-5 |
weight_decay |
0.0 | 权重衰减系数(L2 正则) | 训练 | 防止过拟合 |
dropout |
0.1 | Dropout 概率 | 模型 | Transformer 常用 0.1 |
max_epochs |
100 | 最大训练轮数 | 训练 | 搭配 early stopping |
patience |
10 | Early stopping 容忍轮数 | 训练 | 验证集无提升时停止 |
warmup |
0.1 | 学习率 warmup 比例 | 训练 | 防止初期梯度震荡 |
lr_factor |
0.5 | 学习率衰减倍率 | 训练 | ReduceLROnPlateau |
lr_patience |
2 | 学习率衰减等待轮数 | 训练 | 验证集不提升则降 lr |
seed |
123 | 随机种子 | 全局 | 保证实验可复现 |
n_workers |
12 | DataLoader 线程数 | 数据加载 | 与 CPU 核数相关 |
文本模态:
| 参数名 | 默认值 | 含义说明 | 影响阶段 | 备注 |
|---|---|---|---|---|
bert_model |
./bert-base-uncased |
BERT 预训练模型路径 | 模型 | 可换成 large |
freeze_txt |
0 | 是否冻结文本编码器 | 训练 | 1 表示不更新 BERT |
max_seq_len |
512 | 文本最大 token 长度 | 数据 | BERT 上限 |
embed_sz |
300 | 词向量维度 | 模型 | 对应 GloVe |
glove_path |
glove.840B.300d.txt | GloVe 文件路径 | 数据 | 300 维 |
hidden_sz |
768 | 文本隐藏层维度 | 模型 | BERT-base 默认 |
图像模态(Image)相关参数
| 参数名 | 默认值 | 含义说明 | 影响阶段 | 备注 |
|---|---|---|---|---|
img_hidden_sz |
2048 | 图像特征维度 | 模型 | ResNet 输出 |
num_image_embeds |
1 | 图像 token 数 | 模型 | MMBT 中常见 |
img_embed_pool_type |
avg | 图像特征池化方式 | 模型 | avg / max |
freeze_img |
0 | 是否冻结图像编码器 | 训练 | 1 表示冻结 |
drop_img_percent |
0.0 | 随机丢弃图像比例 | 数据增强 | 模态缺失模拟 |
融合参数:
| 参数名 | 默认值 | 含义说明 | 影响阶段 | 备注 |
|---|---|---|---|---|
model |
latefusion_pdf | 使用的模型结构 | 模型 | PDF = Predictive Dynamic Fusion |
hidden |
\[\] | 额外隐藏层结构 | 模型 | 如 512,256 |
include_bn |
True | 是否使用 BatchNorm | 模型 | 提高训练稳定性 |
df |
True | 是否启用动态融合 | 模型 | PDF 核心开关 |
baseline |
None | 对比方法名称 | 实验 | 仅用于记录 |
任务与数据相关参数:
| 参数名 | 默认值 | 含义说明 | 影响阶段 | 备注 |
|---|---|---|---|---|
task |
MVSA_Single | 使用的数据集 | 数据 | 多模态情绪识别 |
task_type |
classification | 任务类型 | 训练 | 单标签 / 多标签 |
weight_classes |
1 | 是否类别加权 | loss | 类别不平衡时用 |
noise |
0.0 | 标签噪声比例 | 数据 | 鲁棒性实验 |
data_path |
/path/to/data_dir/ | 数据集路径 | 数据 | 必须配置 |
savedir |
/path/to/save_dir/ | 模型保存路径 | 输出 | checkpoint |
其中,很多任务数据相关参数都需要调整