训练大语言模型(LLM)主要分为三个核心阶段:
- 预训练:从海量数据集中学习,形成基础模型。
- 监督微调(SFT):通过精心挑选的示例优化模型,使其更实用。
- 强化学习(Reinforcement Learning,RL):与监督微调(SFT)不同,SFT依赖人类专家提供的标签数据,而RL则允许模型从自身的学习中进步。让模型在那些导致更好结果的token序列上进行训练,允许模型从自身的经验中学习。模型不再仅仅依赖显式标签,而是通过探索不同的token序列,并根据哪些输出最有用来获得反馈(奖励信号)。随着时间的推移,模型学会了更好地与人类意图对齐。
大模型对齐基础
大模型对齐是指让大型语言模型的行为、输出与人类的意图、价值观和道德规范保持一致的过程,以确保AI系统安全、可靠且符合人类期望。
为什么要做对齐?
1.安全性和责任性:
避免有害输出: 防止模型生成仇恨言论、歧视性内容、骚扰、暴力、自残等指导信息、极端观点或虚假信息。
防止滥用:防止模型被用于进行欺诈、制造垃圾邮件、传播恶意软件、进行社会攻击等。
增强鲁棒性:让模型不容易被恶意提示诱导去做坏事。
2.提高可用性和可靠性:
遵循指令: 让模型能准确理解并执行用户的具体要求(如"以简洁的摘要风格写")
保持真实性: 减少模型"胡说八道",尽量基于事实推理(虽然完全杜绝幻觉很难)
符合用户期望:让模型的输出方(如语气、风格、详细程度)符合人类用户的合理预期。
道德判断:在涉及道德两难问题时(虽然模型可能不具备真正的道德观),能输出符合社会普遍伦理的答案或拒绝回答,而不是给出危险建议。
3.增强可信度和实用性:
一个行为符合预期、安全可靠、能够遵循指令的模型才真正有用,才能被用户信任并应用于各种严肃场景。
对齐的主要维度
- 安全对齐:确保模型行为符合人类安全标准,防止生成有害、误导或危险内容。
- 人类对齐:使模型理解并尊重人类价值观的复杂性,具体包括:
- 功能对齐:模型能准确理解并执行人类指令。
- 价值观对齐:模型行为反映人类道德和伦理标准。
- 意图对齐:模型能推断并遵循人类真实意图,而非仅字面指令。
对齐的常见技术
- 人类反馈强化学习(RLHF):通过人类反馈作为奖励信号,指导模型训练以增强对齐。
- 红队测试:模拟攻击者寻找模型漏洞,以提升安全性。
- 安全微调:使用专门设计的数据集增强模型安全性。
- 内容过滤与监控:实时检测并过滤不当输出。
大语言模型对齐的四种方法
参考链接:https://cloud.tencent.com/developer/article/2416650
语言模型的对齐在20年就有相关工作,22年谷歌提出基于指令微调的Flan,Openai则提出InstructGPT,ChatGPT,大模型的对齐工作受到广泛的关注。
目前,大模型的对齐工作中,RLHF算法是能够达到最优的结果,RLHF通过人类反馈和PPO算法,能够有效的将模型和人类偏好进行对齐。但是RLHF也存在难以训练,训练显存占用较大的缺点。基于此,相关研究工作(RRHF, DPO)等也逐渐被提出,希望能够在较小的显存占用的情况下,实现对齐的工作。
RLHF
RLHF是InstructGPT和ChatGPT的训练方法,关于RLHF的介绍,主要参考InstructGPT和huggingface的博客。
在RLHF出现之前,LLM存在着各种依赖输入提示prompt生成多样化文本,但是对于生成结果的难以进行评估。比如模型生成故事,文本,或者代码片段,这些生成结果难以通过现有的基于规则的文本生成指标(BLEU和ROUGE指标)来进行衡量。除了上述的评估指标,现在的模型通常通过预测下一个token的形式和简单的损失函数比如交叉熵损失函数来进行建模,没有显示的引入人的偏好和主观意见。
因此OpenAI提出使用生成文本的人工反馈作为性能衡量指标,或者进一步用该损失来优化模型,也即RLHF的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。
RLHF的三个阶段
• 预训练一个语言模型LM
• 根据问答数据训练一个奖励模型RM
• 使用强化学习RL的方式微调LM
1.预训练语言模型
使用经典的预测下一个token的自回归方式预训练一个语言模型。OpenAI选择InstructGPT。基于预训练得到的LM,生成训练奖励模型(RM,也叫偏好模型)的数据。
2.训练奖励模型
RM模型接受一系列文本并返回一个标量奖励,数值上对应人的偏好。可以直接使用端到端的方式进行建模(直接让RM输出分数),也可以进行模块化的建模(对输出进行排名,再将排名转化为奖励)。
对于RM模型的选择方面,RM可以是另一个经过微调的LM,也可是根据偏好数据从头开始训练的LM。比如Anthropic提出的偏好模型预训练(Preference Model Pretraining, PMP)来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。
对于训练文本方面,RM的提示-生成对 文本是从预定义的数据集中采样生成的,并用初始的LM对这些提示生成文本。OpenAI采用用户提交给GPT API的prompt。
对于训练奖励数值方面,这里需要人工对LM生成的回答进行排名。对文本直接标注分数会很容易受到主观因素的影响,通过排名可以比较多个模型的输出并构建更好的规范数据集。
对于具体的排名方式,使用Elo系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
RM模型和生成模型的规模不一定一样,比如OpenAI就采用了6B的RM和175B的LM。不过一种广泛认可的直觉就是,偏好模型和生成模型需要具有类似的能力来理解提供给他们的文本。
3.用强化学习微调
之前由于工程和算法原因,人们认为使用强化学习训练LM是不可能的。而目前的可行方案是使用策略梯度强化学习(Policy Gradient RL)算法,近端策略梯度优化(Proximal Policy Optimization, PPO)微调初始的LM的部分或者全部参数。
将微调任务表述为RL问题。该策略(policy)是一个接受提示并返回一系列文本或者文本的概率分布的LM。策略的行动空间(action space)是LM的词表对应的所有词元(一般在50k的数量级),观察空间(observation space)是可能的输入词元序列(词汇量^输入token的数量),奖励函数是偏好模型哦那个i和策略转变约束(Policy shift constraint)的结合。
PPO算法的奖励函数计算如下:将提示x输入到初始LM和当前微调的LM,分别得到输出文本y1和y2。将来自当前策略的文本传递给RM得到一个标量的奖励 rθ。将两个模型的生成文本进行比较计算差异的惩罚项(输出词分布序列之间的KL散度的缩放), r=rθ−λrKL 。这一项被用于惩罚RL策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一个惩罚项可能导致模型在优化中生成乱码文本来愚弄模型提供高奖励值。
RRHF
RLHF需要三阶段的训练:SFT,RM,PPO。但PPO对超参数比较敏感,并且RLHF在训练阶段需要四个模型,因此RLHF的方法难以训练。因此本文作者提出RRHF,通过对来自不同来源的响应(自身的模型响应,其他大型语言模型响应和人类专家响应)进行打分,并通过排序损失函数使得这些概率和人类偏好保持一致。RRHF只需要1-2个模型,并且不需要复杂的调优,可以看作是SFT和RM模型训练的一个扩展。RRHF在helpful和harmless数据集上进行测试,表明和PPO一致的性能。
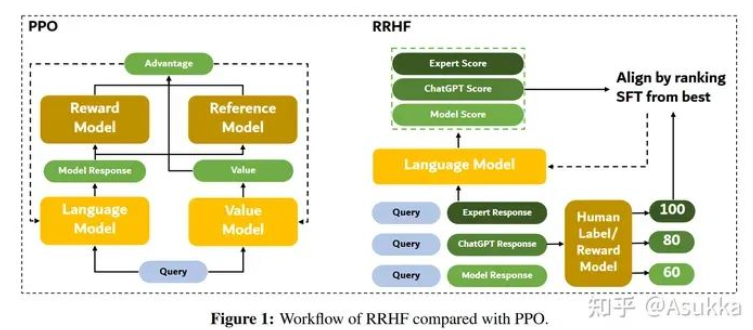
FLAN
这篇论文是ChatGPT之前做的比较好的对齐工作,其核心思想就是探究增加数据集的规模,增加模型的大小,增加COT的数据对于模型的性能和泛化能力的影响。
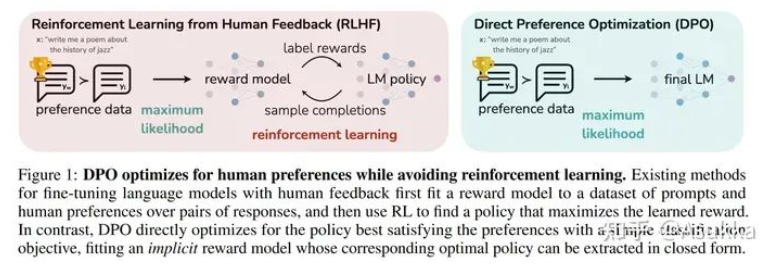
DPO
参考链接:https://zhuanlan.zhihu.com/p/634705904
与RRHF中所提到的一样,RLHF需要超参数以及四个模型,本文提出新的范式,支持以封闭的形式提取响应的最优策略,只需要简单的分类损失就可以解决标准的RLHF问题。DPO的流程如下所示,左边的是RLHF的流程,通过显式的构建RM来让模型学习到人类偏好,而DPO则是隐式的拟合RM模型。
大模型对齐与强化学习的区别
大模型对齐(如RLHF)与强化学习是紧密相关但处于不同层面的概念。简单来说,强化学习是一种通用的机器学习范式,而大模型对齐(特别是RLHF)是强化学习在大语言模型领域的一项具体应用技术。
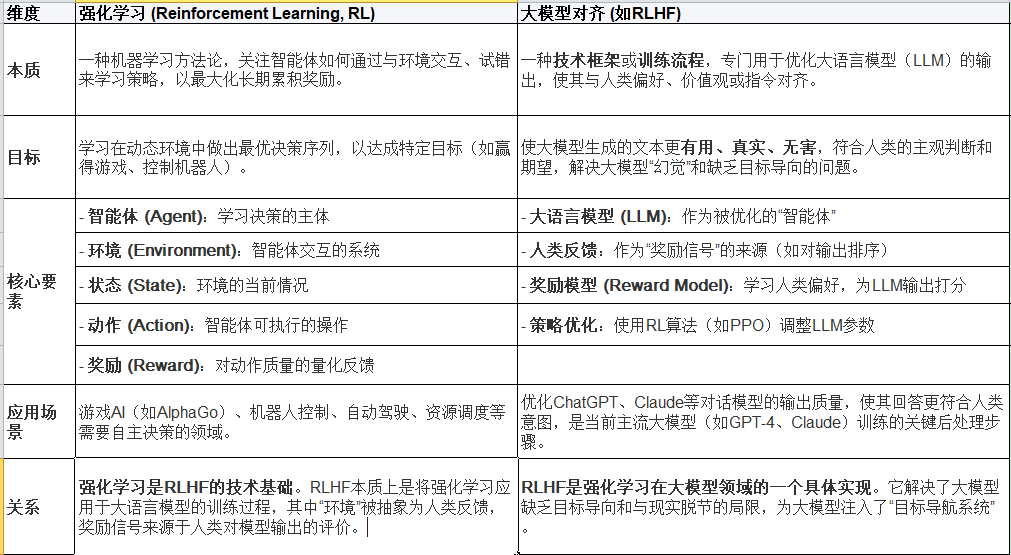
可以将二者的关系理解为"工具与应用":强化学习是那个强大的"工具"(杠杆),而大模型对齐(RLHF) 是用这个工具去解决的一个关键"问题"(撬动大模型的潜力)。没有强化学习,就无法实现像RLHF这样高效、目标导向的对齐方法;而没有大模型对齐这一需求,强化学习在自然语言处理领域的这一具体应用就不会如此突出。
强化学习基础
参考链接:https://cloud.tencent.com/developer/article/2506010
强化学习并不是某一种特定的算法,而是一类算法的统称。
如果用来做对比的话,他跟监督学习,无监督学习 是类似的,是一种统称的学习方式。
强化学习,英文名为reinforcement learning,简称RL,其想要解决的问题是智能体(agent)如何在复杂环境(environment)下最大化其能获得的奖励。
一般来说,强化学习分成两个主要部分:智能体和环境,在整个强化学习过程中,智能体会与环境交互。当智能体从环境获得某个状态后,其会利用该状态输出一个动作(action),这个动作将会在环境中被执行,而环境则会根据智能体采取的动作输出下一个状态以及对当前的动作进行评分。
强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种「绩效奖励」非常类似。我们平时也常常用这样的策略来提高自己的游戏水平。
你会发现,强化学习和监督学习、无监督学习 最大的不同就是不需要大量的"数据喂养"。而是通过自己不停的尝试来学会某些技能。
RL的目的是什么?
人类和LLM处理信息的方式存在显著差异。例如,对于人类来说,基本的算术是直观的,而LLM则将文本视为一串token序列,这对它们来说并不直观。然而,LLM能够在复杂主题上生成专家级回答,仅仅因为它们在训练过程中见过足够多的示例。
这种认知差异使得人类注释者难以提供一组"完美"的标签来持续引导LLM找到正确答案。RL弥补了这一差距,它允许模型从自身的经验中学习。模型不再仅仅依赖显式标签,而是通过探索不同的token序列,并根据哪些输出最有用来获得反馈(奖励信号)。随着时间的推移,模型学会了更好地与人类意图对齐。
RL背后的直觉
LLM本质上是随机的------即使是相同的提示,输出也可能不同,因为它是从概率分布中采样的。我们可以利用这种随机性,通过并行生成成千上万甚至数百万个可能的响应。这可以看作是模型在探索不同的路径------有些是好的,有些是差的。我们的目标是鼓励模型更多地选择较好的路径。
为了实现这一点,我们让模型在那些导致更好结果的token序列上进行训练。与监督微调(SFT)不同,SFT依赖人类专家提供的标签数据,而RL则允许模型从自身的学习中进步。模型通过发现哪些响应最有效,并在每个训练步骤后更新其参数。随着时间的推移,这使得模型在未来收到相似提示时,更有可能生成高质量的答案。
强化学习(RL)代表了人工智能领域的一个令人兴奋的前沿。通过将模型训练在一个多样化且充满挑战的问题池中,RL使模型能够探索超越人类想象的策略,从而优化其思维和决策能力。
1.RL基础
典型RL设置的关键组成部分:
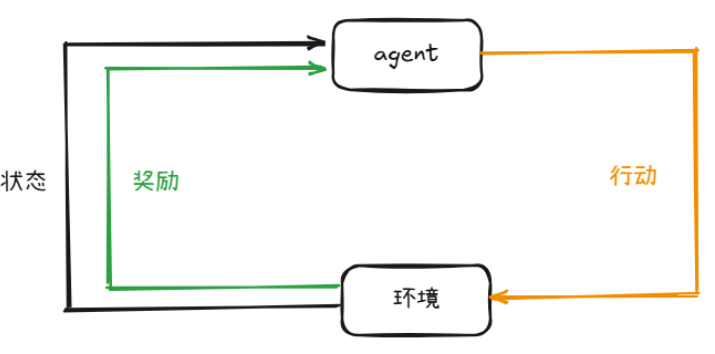
- Agent(智能体) 这是学习的主体,负责在环境中采取行动。
- Environment(环境)智能体与之交互的外部世界,它会根据智能体的行动给出反馈。
- State(状态)环境在某一时刻的具体情况,智能体根据状态决定行动。
在每个时间点,智能体(Agent)会在环境(Environment)中执行一个动作(Action),这个动作会将环境从当前状态(State)转移到新的状态。同时,智能体会收到一个奖励(Reward),这是一个数值形式的反馈,用于评估动作的好坏。正奖励鼓励智能体重复该行为,而负奖励则起到抑制作用。
通过不断从不同状态和动作中收集反馈,智能体逐渐学习出最佳策略(Policy),以在长期内最大化累积奖励。这种学习过程使智能体能够在复杂环境中做出更优的决策。
策略
策略(Policy)是智能体的决策规则。如果智能体遵循一个好的策略,它将在每个状态下做出正确的决策,从而在多个步骤中累积更高的奖励。用数学术语来说,策略是一个函数(πθ(a|s)),它定义了在给定状态下选择不同动作的概率。
价值函数
价值函数(Value Function)用于评估某个状态的好坏,考虑的是长期期望奖励。对于LLM(大语言模型)而言,奖励可能来自人类反馈或奖励模型。
Actor-Critic架构
Actor-Critic是一种流行的强化学习框架,结合了两个关键组件:
- Actor(演员)负责学习和更新策略(πθ),决定在每个状态下应该采取哪个动作。
- Critic(评论者)评估价值函数(V(s)),为Actor提供反馈,告知其选择的动作是否带来了好的结果。
工作原理:
- Actor基于当前策略选择一个动作。
- Critic评估结果(奖励 + 下一个状态)并更新其价值估计。
Critic的反馈帮助Actor优化策略,使未来的动作能够获得更高的奖励。
将其与LLM结合
在LLM的上下文中:
- 状态可以是当前的文本(提示或对话)。
- 动作是生成的下一个token(词或子词)。
- 奖励模型(例如人类反馈)告诉模型生成的文本是好是坏。
- 策略是模型选择下一个token的规则。
- 价值函数评估当前文本上下文对最终生成高质量响应的贡献程度。
2.RL算法
2.1 RL算法:GRPO
GRPO(Group Relative Policy Optimisation,群组相关策略优化)是一种改变游戏规则的RL算法,它是PPO(Proximal Policy Optimisation,近端策略优化)的变种,于2024年2月在《DeepSeekMath》论文中被提出。
为什么选择GRPO而不是PPO?
PPO在推理任务中表现较差的原因包括:
- 依赖评论者模型(Critic Model):PPO需要一个单独的评论者模型,这会增加内存和计算开销。
- 训练复杂性:评论者模型在处理细致或主观任务时可能变得复杂。
- 高计算成本:RL流水线需要大量资源来评估和优化响应。
- 绝对奖励评估:PPO依赖于单一标准判断答案的好坏,难以捕捉开放性任务的细微差别。
GRPO通过相对评估消除了对评论者模型的依赖。响应在一个组内进行比较,而不是通过固定标准判断。可以将其类比为学生之间互相比较答案,而不是由老师单独评分。随着时间的推移,模型的表现会趋向于更高质量。
2.2 RL算法:CoT(Chain of Thought,思维链)
传统的LLM训练流程是:预训练 → SFT → RL。然而,DeepSeek-R1-Zero跳过了SFT,允许模型直接探索思维链(CoT)推理。
CoT使模型能够像人类一样,将复杂问题分解为中间步骤,从而增强推理能力。OpenAI的o1模型也利用了这一点,其2024年9月的报告指出:o1的表现随着更多RL训练和推理时间的增加而提升。
DeepSeek-R1-Zero的特点
DeepSeek-R1-Zero表现出反思性倾向,能够自我精炼推理过程。论文中的关键图表显示,随着训练的进行,模型的思考深度增加,生成了更长(更多token)、更详细且更优的响应。
2.3 RL算法:RLHF(Reinforcement learning with Human Feedback,带有人工反馈的强化学习)
对于具有明确可验证输出的任务(例如数学问题或事实问答),AI的回答可以轻松评估。然而,对于像总结或创意写作这样没有单一"正确"答案的领域,如何评估模型的表现呢?
这就是人工反馈的作用所在。通过引入人类评估,模型能够学习生成更符合人类偏好和意图的响应。然而,传统的强化学习方法在这种场景下并不可扩展,因为完全依赖人工反馈会导致高昂的成本和效率低下。
RLHF通过结合人类反馈和强化学习,使模型能够在复杂任务中学习更优的策略,同时保持可扩展性和实用性。这种方法为模型在开放性和主观性任务中的表现提供了重要支持。
在需要评估开放性任务(如创意写作、诗歌或总结)时,完全依赖人工评估是不现实的。假设需要十亿次人工评估,这种方法不仅成本高昂,而且效率低下,难以扩展。因此,更智能的解决方案是训练一个AI奖励模型,让它学习人类的偏好,从而大幅减少人工工作量。
为什么使用排名而非绝对评分?
对响应进行排名比直接评分更容易且更直观。人类更容易判断哪个回答更好,而不是为每个回答分配一个具体的分数。
RLHF的优点:
- 广泛适用性:RLHF可以应用于任何领域,包括创意写作、诗歌、总结等开放性任务。
- 简化评估:对输出进行排名比生成人工标签或创意输出更容易。
RLHF的缺点: - 奖励模型的局限性:奖励模型是近似的,可能无法完美反映人类的偏好。
- RL模型可能会利用奖励模型的漏洞,生成荒谬的输出但仍获得高分,尤其是在训练时间过长的情况下。
RLHF与传统RL的区别 - 传统RL:适用于可验证的领域(如数学、编程),模型可以无限运行并发现新的策略。
- RLHF:更像是一个微调步骤,用于将模型与人类的偏好对齐,而不是发现全新的策略。
通过RLHF,模型能够在开放性任务中生成更符合人类期望的响应,同时减少对人工评估的依赖。然而,奖励模型的局限性仍需谨慎处理,以避免模型生成低质量或不合逻辑的输出。