此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第五课的第三周内容,与 CV 相对应的,这一课所有内容的中心只有一个:自然语言处理(Natural Language Processing,NLP) 。
应用在深度学习里,它是专门用来进行文本与序列信息建模 的模型和技术,本质上是在全连接网络与统计语言模型基础上的一次"结构化特化",也是人工智能中最贴近人类思维表达方式 的重要研究方向之一。
这一整节课同样涉及大量需要反复消化的内容,横跨机器学习、概率统计、线性代数以及语言学直觉。
语言不像图像那样"直观可见",更多是抽象符号与上下文关系的组合,因此理解门槛反而更高 。
因此,我同样会尽量补足必要的背景知识,尽可能用比喻和实例降低理解难度。
本周的内容关于序列模型和注意力机制 ,这里的序列模型其实是指多对多非等长模型,这类模型往往更加复杂,其应用领域也更加贴近工业和实际,自然也会衍生相关的模型和技术。而注意力机制则让模型在长序列中学会主动分配信息权重,而不是被动地一路传递。二者结合,为 Transformer 等现代架构奠定了基础。
本篇的内容关于seq2seq 模型,是对多对多非等长模型的展开介绍。
1.seq2seq 模型(Sequence to Sequence Model)
2014 年被普遍认为是seq2seq模型真正成型的关键年份。
首先,起源论文 Sequence to Sequence Learning with Neural Networks被发表,其中首次系统性地验证了基于 RNN 的 Encoder--Decoder 架构 可以直接建模"输入序列 → 输出序列"的生成过程,并成功应用于机器翻译任务。这项工作明确确立了 seq2seq 作为一种通用序列生成范式,也奠定了后续神经机器翻译模型的基本结构。
几乎在同一时期,另一篇论文Learning Phrase Representations using RNN Encoder--Decoder for Statistical Machine Translation从表示学习的角度提出了 RNN Encoder--Decoder 这一结构性思想,并引入了带门控机制的循环单元(后来发展为 GRU)。这项工作强调编码器学习语义表示、解码器建模条件生成分布,为随后注意力机制的提出提供了直接的理论与结构基础。
这两篇论文从工程实现与结构抽象两个互补视角,共同奠定了 seq2seq 模型与编码--解码范式在自然语言处理中的核心地位。
同样简单介绍一下历史,看起来很高深,但其实许多内容在我们之前就已经知道了,只是现在我们为其正式命名引入了,下面就来分点展开:
1.1 seq2seq 模型:编码-解码结构
seq2seq 模型的全称是 Sequence to Sequence 模型,顾名思义,是指 "序列到序列" 的模型。
在我们之前介绍的RNN 结构类型中,seq2seq 模型专指输入为序列,输出同样为序列的多对多非等长模型。
这里很容易产生一个问题:为什么多对多等长模型,就像我们之前演示的命名实体识别,不也是输入序列,输出序列吗?它为什么不被归纳在 seq2seq 模型中呢?
实际上,二者的差异存在于它们的模型结构和传播逻辑上,我们简单展开如下:
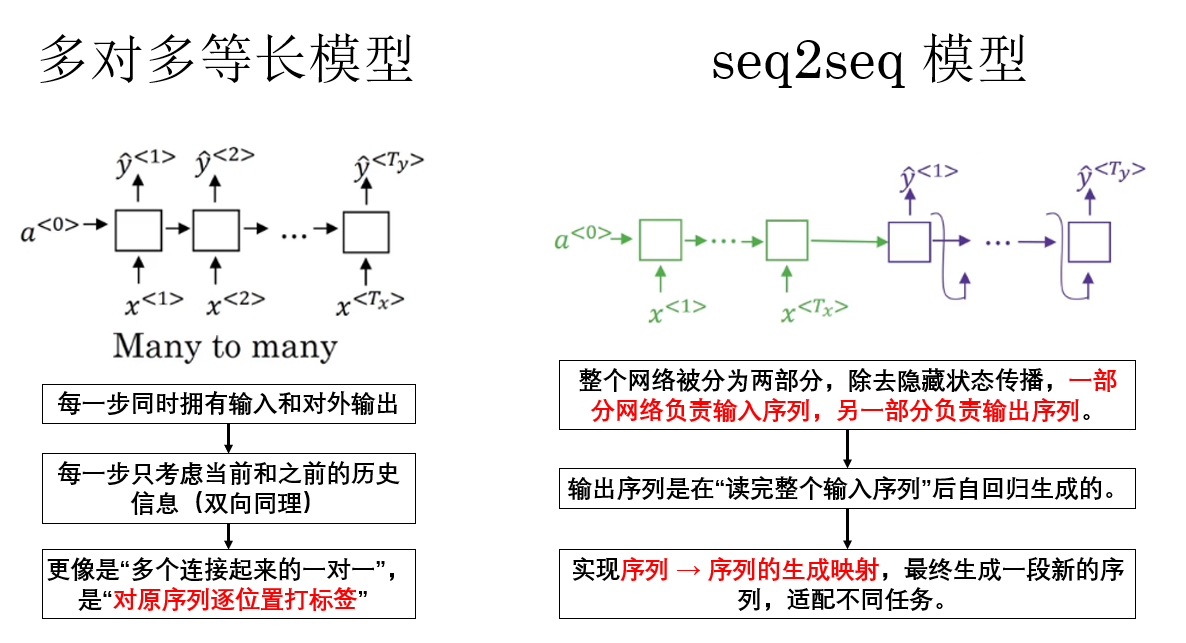
总结来说,seq2seq 面向的是"生成另一段序列"的问题,而命名实体识别等对多等长模型面向的是"对原序列逐位置打标签"的问题。
前者是非等长的序列生成,后者是等长的序列标注,因此后者不被归入 seq2seq 模型范畴。
在明确了概念后,接下来就可以具体来看 seq2seq 模型内部最核心的结构设计------编码--解码(Encoder--Decoder)框架。
在刚刚的图中我们已经看到了,在经典的 seq2seq 模型中,整体网络通常由两个相互独立但逻辑上强耦合的子网络组成:
- 编码器(Encoder):将输入序列压缩为语义表示。
- 解码器(Decoder):基于语义表示生成输出序列。
展开如下:
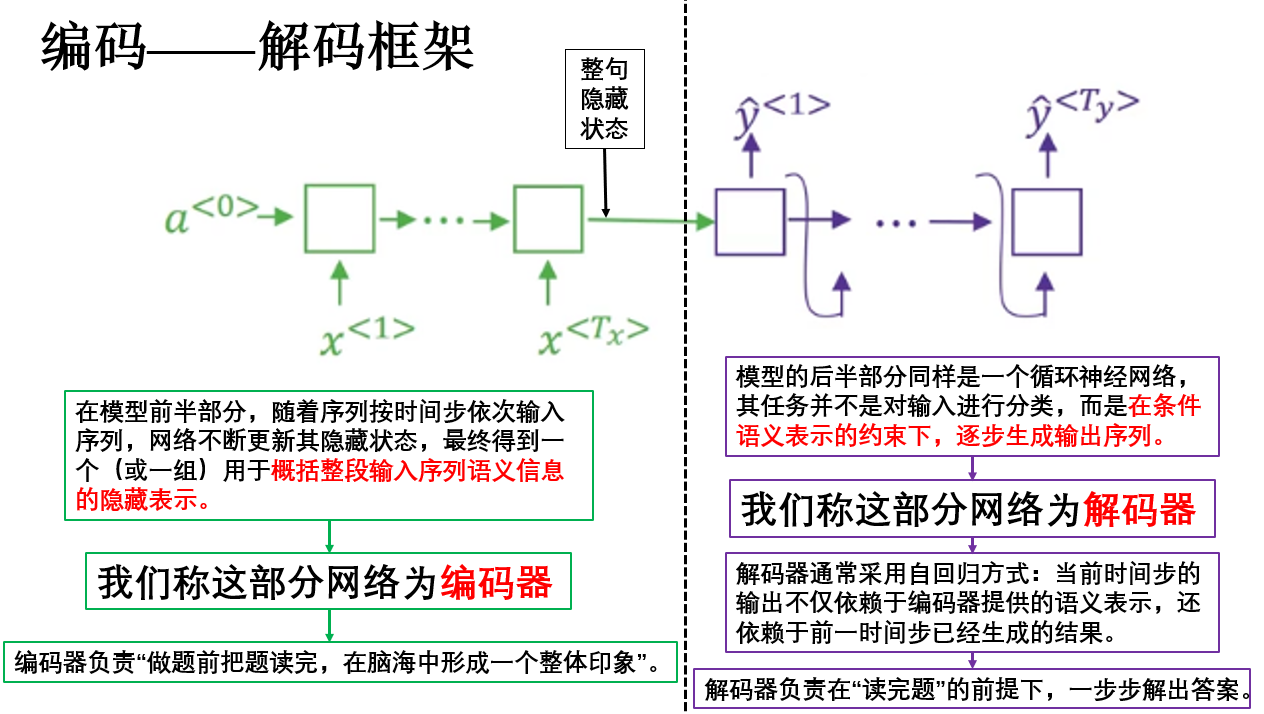
从整体结构上看,seq2seq 的编码--解码框架有几个特点:
- 输入序列与输出序列在时间维度上不要求对齐,既非等长。
- 编码阶段与解码阶段在结构上明确分离。
- 输出是一个生成过程 ,而非逐位置的判别结果,其传播类似我们之前介绍的新序列采样。
正是这些特征,让其拥有广泛的应用领域和极高的延展性,下面就来看看seq2seq 的一些具体应用。
1.2 seq2seq 模型的应用领域
可以看到,seq2seq 模型的核心能力在于:在不要求输入输出对齐的前提下,将一段序列映射为另一段序列,并通过生成过程逐步给出结果。
这一特性决定了 seq2seq 并不适用于"逐位置判别"的任务,而是天然适合语义层面的序列转换问题 。
听起来有些抽象,展开来说:seq2seq 模型的应用并不依赖具体任务形式,而依赖于一个条件:
任务是否可以被表述为"在理解一段序列后,生成另一段序列"。
正是这一能力,使得 seq2seq 在多个领域中展现出极强的通用性,简单列举如下:
| 应用领域 | 输入序列 | 输出序列 |
|---|---|---|
| 机器翻译 | 源语言句子 | 目标语言句子 |
| 文本摘要 | 长文本序列 | 短摘要序列 |
| 对话系统 / 文本生成 | 用户输入文本 | 系统回复文本 |
| 语音识别 | 声学特征序列 | 文本序列 |
这些都并不难理解,无非是数据不同,编码解码的模型结构都是相通的,就不再展开了。
值得一提的是,吴恩达老师在课程里举了一个特别的例子:图像描述生成(Image Captioning)。
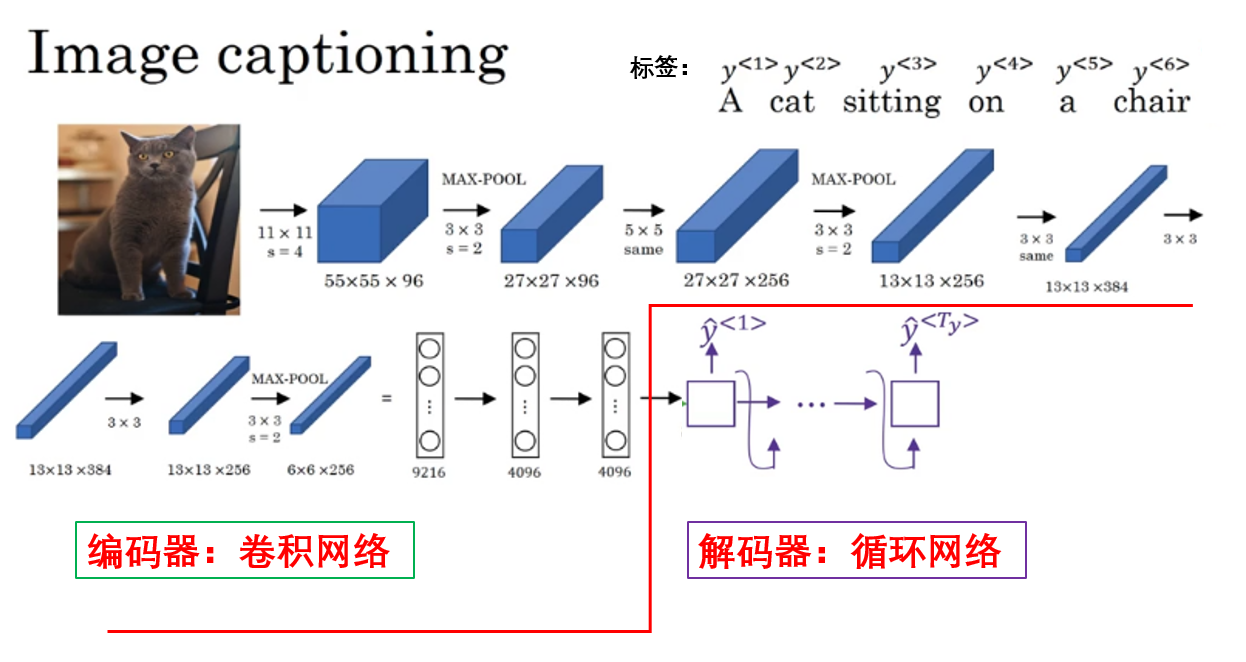
如图,在这一任务中,模型的输入不再是文本序列,而是一张图像,输出则是一段自然语言描述。 但它依然可以被纳入 seq2seq 的框架之中。
其核心思想在于: 只要能够将输入数据编码为一种序列化或向量化的语义表示,后续的解码过程就仍然可以按照"序列生成"的方式进行。
在图像描述生成任务中,图像通常首先由卷积神经网络提取为高层语义特征,作为编码器的输出,解码器则在这一语义表示的条件约束下,逐词生成对应的文本描述。
像这种"非文本输入 → 文本输出"的建模方式,让模型不再局限于单一模态的数据,我们便称这类建模方式为多模态学习。
我们最常见的 AI 就是一种多模态模型,你不仅可以和 AI 进行文字交流,还可以上传图片或文件并让其输出不同内容。
从这一视角来看,seq2seq 并不仅是一类 NLP 模型结构,而是一种可以跨模态复用的序列建模范式。
对 seq2seq 的基础内容就介绍到这里,下面我们展开介绍一下 seq2seq 模型特有的评估指标:BLEU 得分。
2. BLEU 得分(Bilingual Evaluation Understudy)
seq2seq 模型出现后,一个紧随而来的问题就是:如何非手工地判断模型生成的这一整段序列,究竟好不好?
对于分类或序列标注任务,我们可以逐位置对比预测结果与真实标签,直接计算准确率或 F1。
但在机器翻译、文本摘要等 seq2seq 任务中,输出往往是不固定长度的一整句话甚至一整段文本,且"正确答案"并不唯一。 这就使得传统指标几乎失效。
以机器翻译为例,假设参考译文为:I like machine learning.
而模型输出为: I enjoy machine learning.
从语义上看,这两个句子几乎完全一致。但如果我们采用"逐词是否相同"的方式进行评估,模型反而会被判定为错误。
也就是说: seq2seq 任务的评价目标是"语义相似度",而不是"形式一致性"。
于是,在 2002 年的论文: BLEU: a Method for Automatic Evaluation of Machine Translation中,首次提出了 BLEU 指标,用于在不依赖人工逐句评审的前提下,对机器翻译结果进行自动化评估。
其基本思想可以概括为一句话: 如果模型生成的结果,在局部片段层面上与人工参考结果高度重合,那么整体质量往往也是可信的。
下面就来展开介绍其评估过程:
2.1 n-gram 精确率(Modified n-gram Precision)
计算 BLEU 得分的第一步,是 计算n-gram 精确率 。
所谓 n-gram,就是把候选序列划分为长度为 \(n\) 的连续词片段,例如:
- unigram(\(n=1\)):单个词就是一个 unigram
- bigram(\(n=2\)):相邻两个词组合起来是一个 bigram
- trigram(\(n=3\)):相邻三个词组合起来是一个 trigram
BLEU 的关键并不在于"词有没有出现",而在于模型生成的局部结构,是否与人工译文存在重合。
我们仍然使用前面的例子,并假设已经完成分词:
- 参考标签:
[I, like, machine, learning],长度 \(r = 4\)。 - 候选输出:
[I, enjoy, machine, learning],长度 \(c = 4\)。
下面,就是用这一公式来计算对应的 n-gram 精确率:
\p_n = \\frac{\\sum_{\\text{ngram}} \\min(\\text{Count}_{\\text{cand}}, \\text{Count}_{\\text{ref}})}{\\sum_{\\text{ngram}} \\text{Count}_{\\text{cand}}} \\
我们用文字来展开这个计算过程:
- 枚举候选序列中的每一个 n-gram :将模型输出序列切分成长度为 \(n\) 的连续片段。
- 统计候选 n-gram 与参考 n-gram 的匹配次数:
- \(\text{Count}_{\text{cand}}\) 表示候选序列中该 n-gram 出现的次数。
- \(\text{Count}_{\text{ref}}\) 表示参考序列中该 n-gram 出现的次数。
- 取最小值 \(\min(\text{Count}{\text{cand}}, \text{Count}{\text{ref}})\) 计算合理匹配次数。
- 除以候选序列中所有 n-gram 的总数 :这相当于计算了候选序列中有多少比例的 n-gram 与参考序列匹配,即"精确率"。
下面就来具体演示一下:
首先,我们计算 Unigram,即 \(n=1\):
| Unigram | Candidate 出现次数 | Reference 出现次数 | \(\min(\text{Count}{\text{cand}}, \text{Count}{\text{ref}})\) |
|---|---|---|---|
| I | 1 | 1 | 1 |
| enjoy | 1 | 0 | 0 |
| machine | 1 | 1 | 1 |
| learning | 1 | 1 | 1 |
因此:
\p_1 = \\frac{1+0+1+1}{4} = \\frac{3}{4} = 0.75 \\
继续,我们在试试 Bigram,即 \(n=2\):
| Bigram | Candidate 出现次数 | Reference 出现次数 | \(\min(\text{Count}{\text{cand}}, \text{Count}{\text{ref}})\) |
|---|---|---|---|
| (I, enjoy) | 1 | 0 | 0 |
| (enjoy, machine) | 1 | 0 | 0 |
| (machine, learning) | 1 | 1 | 1 |
因此 Bigram 精确率为:
\p_2 = \\frac{0 + 0 + 1}{3} = \\frac{1}{3} \\approx 0.333 \\
以此类推,继续计算:
- trigram:完全无匹配,\(p_3 = 0\)
- 4-gram:完全无匹配,\(p_4 = 0\)
最终,你会发现,这一步,其实是在不同尺度上计算候选序列和参考序列的匹配度。
2.2 长度惩罚 BP(Brevity Penalty)
在最终计算之前,BLEU 专门设置了一个参数 BP 用来解决这样一个问题:
如果只看 n-gram 精确率,模型可以"作弊"------生成很短的序列,只输出部分正确词,就可能获得很高分。
其公式如下:
\\\text{BP} = \\begin{cases} 1, \& c \> r \\\\ \\exp\\left(1 - \\frac{r}{c}\\right), \& c \\le r \\end{cases} \\
其中, \(c\) 是模型生成序列的长度、\(r\) 是参考序列的长度。
计算得到的 BP 会作为最终评估的系数,因此,它的语义是这样的:
- 如果生成序列长度 >= 参考长度,BP = 1,不额外惩罚。
- 如果生成序列太短,BP < 1,会对总分进行指数级扣分。
举个例子:
设参考序列长度 \(r = 4\) 、模型生成序列长度 \(c = 2\) ,计算 BP 为:
\\\text{BP} = \\exp(1 - \\frac{4}{2}) = \\exp(-1) \\approx 0.368 \\
这样,即使 unigram/bigram 匹配较好,最终 BLEU 分数也会因为序列太短而大幅下降。
BP 的引入确保 BLEU 得分不仅考虑 局部 n-gram 匹配 ,还考虑 生成序列长度合理性 。
简单来说:短序列不能通过"少输出"来刷分。
2.3 多阶 n-gram 的几何平均
你会发现:低级 n-gram 到高阶 n-gram 实际上是对语序的逐步注重。
而如果只使用 unigram,模型可能生成一堆"正确的词",但语序混乱;如果只使用高阶 n-gram,又会对细微差异过于苛刻。
因此,BLEU 的做法是:同时计算多个 \(p_n\),并取它们的几何平均。
其中,最常见的就是 BLEU-4,即和我们刚刚一样计算前四阶 n-gram 进行最终评估,公式如下:
\\\text{BLEU} = \\text{BP} \\cdot \\exp\\left( \\sum_{n=1}\^{4} w_n \\log p_n \\right) \\
其中,参数 \(w_n\) 就是第 \(n\) 阶 n-gram 在最终得分中所占的权重 ,通常取均等权重 \(w_n = \frac{1}{4}\)。
而对数和再指数的方式,可以把几何平均转化为加权 log 和的形式,计算更稳定,同时也避免了直接乘法下的数值下溢(数值太小了超出存储位数,导致计算机无法精确表示)。
在我们的例子中:
\p_1 = 0.75,\\quad p_2 \\approx 0.333,\\quad p_3 = 0,\\quad p_4 = 0 \\
\\\exp\\left( \\sum_{n=1}\^{4} w_n \\log p_n \\right) = \\prod_{n=1}\^4 p_n\^{w_n} = 0.75\^{0.25} \\cdot 0.333\^{0.25} \\cdot 0\^ {0.25} \\cdot 0\^ {0.25} = 0 \\
此时可以看出一个问题:只要某一阶 \(p_n = 0\),整体 BLEU 就会变为 0。
这并不是缺陷,而是 BLEU 的一个重要使用前提: BLEU 是为"语料级评估"设计的,而不是单句评估指标。
在真实使用中,BLEU 会在整个测试集上累加 n-gram 统计后再计算,此时 \(p_n\) 几乎不会为 0。
由此,我们就完成了 BLEU 指标的计算。
BLEU 是首个自动化、可复现的序列生成评价指标,为神经机器翻译和 seq2seq 研究奠定了基础,它主要依赖 n-gram 匹配,极大加速了模型调试与对比,但也有其局限性:对语义和多样性敏感性不足。
因此,后续也发展出更多了指标,如 BERTScore、ROUGE、CIDEr 等,它们在语义理解、多样性和跨模态任务上进行了改进与拓展,我们遇到再展开。
3.总结
| 概念 | 原理 | 比喻 / 直观理解 |
|---|---|---|
| seq2seq 模型 | 输入序列映射到输出序列,允许非等长,基于编码--解码结构 | 将一句话"翻译"成另一句话,就像把中文句子转换成英文句子 |
| 编码器 (Encoder) | 将输入序列压缩为固定维度的语义表示 | 像把整篇文章压缩成大脑里的核心理解 |
| 解码器 (Decoder) | 根据编码器提供的语义表示逐步生成输出序列 | 像根据脑中理解逐字复述或生成一句话 |
| 应用领域 | 机器翻译、文本摘要、对话系统、语音识别、图像描述生成 | 将不同模态的输入(文本、语音、图像)转化为另一段序列输出 |
| BLEU 指标 | 基于 n-gram 精确率和长度惩罚 BP 计算序列生成质量 | 检查生成句子中局部片段有多少和参考句子重合,顺序和长度也考虑在内 |
| n-gram 精确率 | 统计候选序列与参考序列 n-gram 的匹配比例 | 像对比两段文字中每个词或词组出现情况 |
| Brevity Penalty (BP) | 对生成过短的序列进行惩罚,防止"少说就高分" | 就像考试中答题太短,即使答案对也会扣分 |
| 几何平均 (多阶 n-gram) | 对不同阶 n-gram 精确率取几何平均并加权 | 平衡单词准确性和语序准确性,既考虑词对又考虑短语对 |
| BLEU 局限 | 单句容易为 0,主要用于语料级评估,对语义和多样性敏感性不足 | 就像只看字面重合,可能忽略同义表达 |