目录
[1. 命令各分段底层原理(从左到右拆解)](#1. 命令各分段底层原理(从左到右拆解))
[2. 命令执行流程可视化](#2. 命令执行流程可视化)
[3. 命令输出示例与解读](#3. 命令输出示例与解读)
[1. 场景1:日常巡检(定时执行+日志记录)](#1. 场景1:日常巡检(定时执行+日志记录))
[2. 场景2:故障应急排查(快速定位+根因分析)](#2. 场景2:故障应急排查(快速定位+根因分析))
[3. 场景3:集群变更后验证(升级/配置修改)](#3. 场景3:集群变更后验证(升级/配置修改))
一、背景与痛点:为什么需要这条命令?
在基于 Docker 容器化部署的 K8s 集群(如单节点测试集群、Seed 节点模式集群)中,kube-system 命名空间是集群的"心脏"------包含 kube-apiserver(集群入口)、kube-controller-manager(集群控制中心)、kube-scheduler(调度器)、coredns(DNS解析)、calico/flannel(网络插件)等核心组件。
日常运维中,排查 kube-system 异常 Pod 存在以下痛点:
步骤繁琐 :需先执行 docker ps 找到 K8s 核心容器 → 执行 docker exec -it 容器ID bash 进入容器 → 执行 kubectl get pod -n kube-system 查看 Pod 状态,多步操作易出错;
筛选低效 :kubectl get pod -n kube-system 输出的信息中,90% 是正常的 Pod(READY 列为 1/1、2/2 等),人工逐一排查耗时且易遗漏;
覆盖不全:仅检查 kube-system 可能遗漏其他命名空间的核心组件(如 monitoring 命名空间的监控组件),导致集群隐性故障。
基于以上痛点,我封装了一条"一站式"命令,直接过滤全集群异常 Pod,尤其聚焦 kube-system 核心场景,大幅提升排查效率。
二、核心命令深度解析
最终落地的命令:
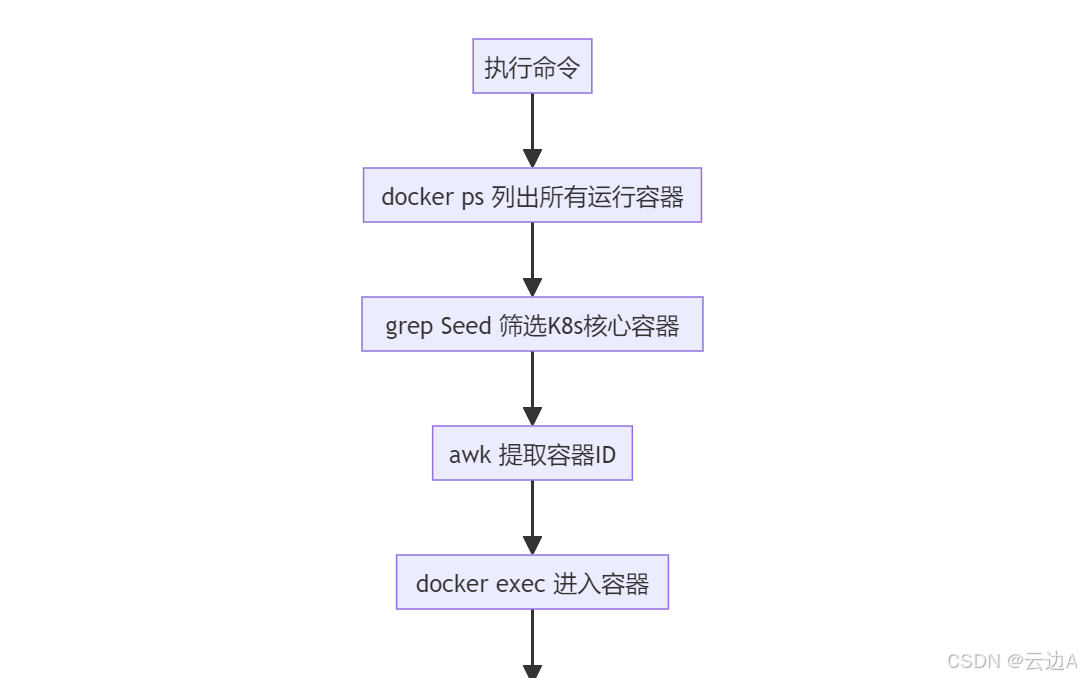
docker exec -it $(docker ps | grep Seed | awk '{print $1}') kubectl get pod -A | grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME'1. 命令各分段底层原理(从左到右拆解)
|--------------------------|-----------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
| 命令分段 | 底层原理 | 补充说明 |
| docker ps | 列出当前运行的 Docker 容器,输出包含:容器ID、镜像名、命令、创建时间、状态、端口、容器名称 | 核心输出字段:CONTAINER ID(第1列)、NAMES(最后1列) |
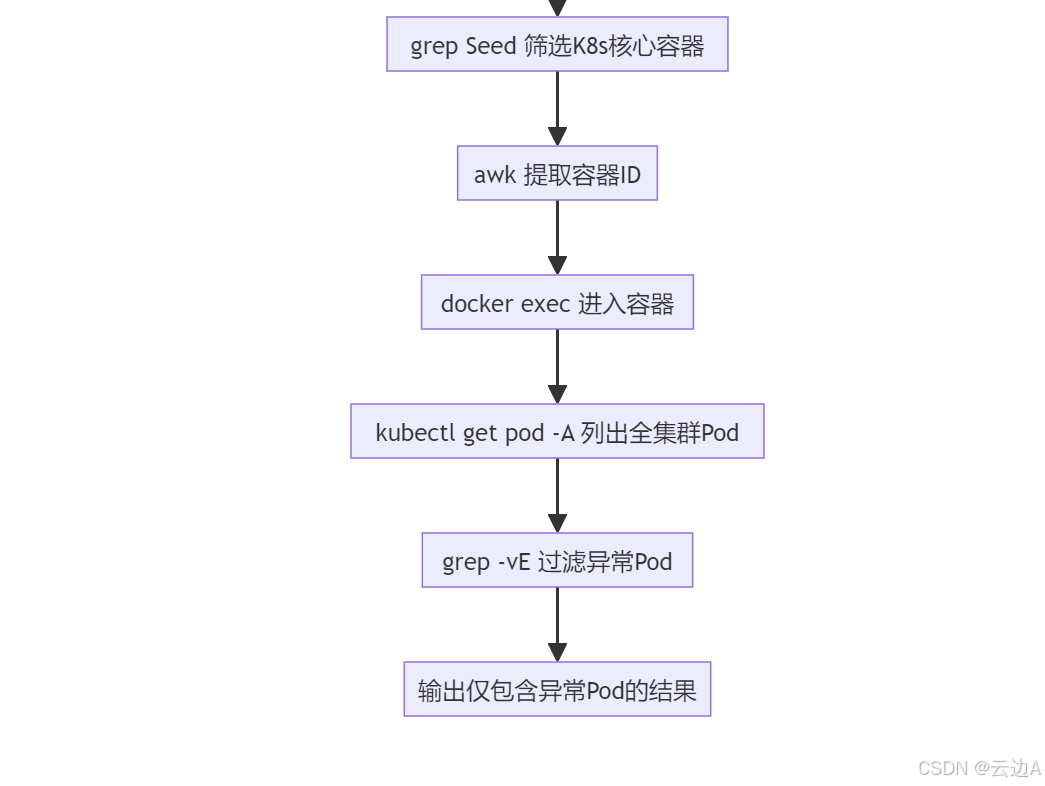
| grep Seed | 过滤容器名称/镜像名中包含"Seed"的行 | 适配场景:你的集群中 K8s 核心容器名称含"Seed"(如 k8s-seed、seed-node);若容器名是"k8s-master""kube-node",需替换为 grep k8s-master |
| awk '{print $1}' | 提取 `docker ps | grep Seed` 输出的第1列(即容器ID) |
| docker exec -it [容器ID] | 在指定 Docker 容器中执行交互式命令: - exec:在运行的容器中执行命令; - -i:保持标准输入打开(交互式); - -t:分配伪终端(模拟终端环境) | 若仅需执行命令无需交互,可去掉 -it,改为 docker exec [容器ID],避免终端占用问题 |
| kubectl get pod -A | kubectl get pod:列出 Pod 信息; -A(等价于 --all-namespaces):列出所有命名空间的 Pod,而非仅 kube-system | 输出字段:NAMESPACE(命名空间)、NAME(Pod名)、READY(就绪数/总容器数)、STATUS(状态)、RESTARTS(重启次数)、AGE(运行时长) |
| grep -vE 'xxx' | grep:文本过滤工具; -v:反向匹配(排除符合条件的行); -E:启用扩展正则表达式; 正则内容:`1/1 | 2/2 |
2. 命令执行流程可视化
3. 命令输出示例与解读
执行命令后,正常/异常输出场景如下:
场景1:无异常Pod(输出为空)
# 执行命令后无任何输出,说明全集群Pod均处于就绪状态(1/1、2/2等)
$ docker exec -it $(docker ps | grep Seed | awk '{print $1}') kubectl get pod -A |grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME'
$ 场景2:存在异常Pod(输出示例)
kube-system coredns-7f6cbbb7b8-2x9zl 0/1 Running 3 1h
kube-system calico-node-8q754 1/2 Error 0 20m
monitoring prometheus-9d876f78c-7k8s2 1/3 Pending 1 30m输出解读:
kube-system coredns-7f6cbbb7b8-2x9zl 0/1 Running:coredns Pod 有1个容器,但0个就绪,状态为 Running(可能是容器启动卡住、健康检查失败);
kube-system calico-node-8q754 1/2 Error:calico-node Pod 有2个容器,仅1个就绪,另1个容器报错(网络插件异常,需优先排查);
monitoring prometheus-9d876f78c-7k8s2 1/3 Pending:监控组件 prometheus Pod 有3个容器,仅1个就绪,状态为 Pending(可能是资源不足、节点调度限制)。
三、实操场景全拆解(附完整脚本)
1. 场景1:日常巡检(定时执行+日志记录)
需求:每日早8点、晚8点执行检查,将结果写入日志,异常时触发告警。
完整脚本(k8s_pod_check.sh)
#!/bin/bash
# 脚本功能:K8s集群异常Pod巡检(重点监控kube-system)
# 脚本作者:xxx
# 脚本版本:v1.0
# 执行权限:需赋予执行权限 chmod +x k8s_pod_check.sh
# 1. 定义基础变量
CHECK_TIME=$(date +%Y-%m-%d\ %H:%M:%S)
LOG_FILE="/var/log/k8s_pod_check.log" # 日志文件路径
CONTAINER_KEYWORD="Seed" # K8s核心容器关键词,根据实际修改
READY_REGEX="1/1|2/2|3/3|4/4|5/5|6/6" # 正常就绪状态,根据集群补充
ALERT_WECHAT_URL="https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx" # 企业微信告警机器人URL
# 2. 函数:执行Pod检查
check_pods() {
# 先检查Docker容器是否存在
CONTAINER_ID=$(docker ps | grep "$CONTAINER_KEYWORD" | awk '{print $1}')
if [ -z "$CONTAINER_ID" ]; then
echo "[$CHECK_TIME] 错误:未找到包含关键词 $CONTAINER_KEYWORD 的Docker容器" >> "$LOG_FILE"
send_alert "【K8s巡检失败】未找到包含关键词 $CONTAINER_KEYWORD 的Docker容器,请检查集群容器状态"
exit 1
fi
# 执行核心检查命令
ERROR_PODS=$(docker exec "$CONTAINER_ID" kubectl get pod -A 2>/dev/null | grep -vE "$READY_REGEX|Comp|NAME")
return 0
}
# 3. 函数:发送企业微信告警
send_alert() {
local ALERT_CONTENT=$1
curl -s -X POST "$ALERT_WECHAT_URL" \
-H "Content-Type: application/json" \
-d '{
"msgtype": "text",
"text": {
"content": "'"$ALERT_CONTENT"'"
}
}' > /dev/null 2>&1
}
# 4. 主逻辑
check_pods
# 记录日志
if [ -n "$ERROR_PODS" ]; then
# 存在异常Pod:记录日志+发送告警
echo "[$CHECK_TIME] 发现异常Pod:" >> "$LOG_FILE"
echo "$ERROR_PODS" >> "$LOG_FILE"
send_alert "【K8s集群异常Pod告警】\n检查时间:$CHECK_TIME\n异常Pod信息:\n$ERROR_PODS"
else
# 无异常Pod:仅记录日志
echo "[$CHECK_TIME] 所有Pod状态正常(含kube-system核心组件)" >> "$LOG_FILE"
fi
exit 0脚本使用步骤:
-
修改脚本中的
CONTAINER_KEYWORD(容器关键词)、LOG_FILE(日志路径)、ALERT_WECHAT_URL(告警URL); -
赋予执行权限:
chmod +x k8s_pod_check.sh; -
添加到crontab定时任务:
编辑crontab
crontab -e
添加以下内容(每日8:00、20:00执行)
0 8,20 * * * /bin/bash /path/to/k8s_pod_check.sh
2. 场景2:故障应急排查(快速定位+根因分析)
当集群出现"服务访问失败""Pod调度失败"等故障时,执行以下步骤:
步骤1:执行核心命令,定位异常Pod
docker exec -it $(docker ps | grep Seed | awk '{print $1}') kubectl get pod -A |grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME'步骤2:针对异常Pod,进一步排查根因(以kube-system的coredns为例)
# 1. 进入K8s核心容器
docker exec -it $(docker ps | grep Seed | awk '{print $1}') bash
# 2. 查看异常Pod的详细信息(重点看Events)
kubectl describe pod coredns-7f6cbbb7b8-2x9zl -n kube-system
# 3. 查看异常Pod的日志
kubectl logs coredns-7f6cbbb7b8-2x9zl -n kube-system
# 4. 检查Pod所在节点状态
kubectl describe node [节点名]常见异常根因与解决方案:
|----------------------------|---------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 异常Pod现象 | 常见根因 | 解决方案 |
| coredns 0/1 Running | 1. CoreDNS配置错误;2. 集群DNS解析异常;3. 网络策略拦截 | 1. 检查CoreDNS配置:kubectl edit configmap coredns -n kube-system;2. 重启CoreDNS Pod:kubectl rollout restart deployment coredns -n kube-system |
| calico-node 1/2 Error | 1. 节点网络冲突;2. Calico配置错误;3. 节点内核参数不兼容 | 1. 查看Calico日志:kubectl logs calico-node-8q754 -n kube-system -c calico-node;2. 检查节点网卡:ip addr;3. 重启Calico DaemonSet:kubectl rollout restart daemonset calico-node -n kube-system |
| kube-apiserver 0/1 Pending | 1. 节点资源不足(CPU/内存);2. 端口被占用;3. 证书过期 | 1. 检查节点资源:free -m、top;2. 检查端口:`netstat -tulpn |
3. 场景3:集群变更后验证(升级/配置修改)
在K8s版本升级、kube-system组件配置修改(如Calico网络策略调整、CoreDNS配置修改)后,执行以下命令验证:
# 执行核心检查命令
docker exec -it $(docker ps | grep Seed | awk '{print $1}') kubectl get pod -A |grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME'
# 额外验证:检查kube-system组件是否全部运行
docker exec -it $(docker ps | grep Seed | awk '{print $1}') kubectl get pod -n kube-system | wc -l
# 对比变更前的Pod数量,确保无Pod缺失四、避坑指南(常见问题与解决方案)
|---------------|-----------------------------------|-------------------------------------------------------------------------------------------------------------|
| 常见问题 | 现象 | 解决方案 |
| 容器ID提取失败 | 执行命令后提示"Error: No such container" | 1. 检查容器关键词是否正确:`docker ps |
| kubectl命令执行失败 | 提示"kubectl: command not found" | 1. 确认容器内安装了kubectl:docker exec 容器ID which kubectl;2. 若未安装,进入容器手动安装:apt update && apt install -y kubectl |
| 过滤结果漏报/误报 | 1. 正常Pod被过滤出来;2. 异常Pod未显示 | 1. 检查正则表达式:补充遗漏的就绪状态(如6/6、7/7);2. 去掉Comp过滤(若集群输出无该字段);3. 先执行kubectl get pod -A查看原始输出,调整正则 |
| 权限不足 | 提示"permission denied" | 1. 以root用户执行命令:sudo docker exec ...;2. 检查容器内kubectl权限:docker exec 容器ID ls -l /usr/bin/kubectl |
五、命令扩展优化(适配不同集群场景)
- 仅检查kube-system命名空间(聚焦核心)
若只需关注kube-system,修改命令:
docker exec -it $(docker ps | grep Seed | awk '{print $1}') kubectl get pod -n kube-system | grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME'-
输出更精简的信息(仅保留命名空间、Pod名、状态)
docker exec -it (docker ps | grep Seed | awk '{print 1}') kubectl get pod -A | grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME' | awk '{print "命名空间:"1, "Pod名:"2, "状态:"$4}'
-
适配非Docker部署的集群(直接执行kubectl)
若集群不是Docker容器化部署(如物理机/虚拟机部署),简化命令:
kubectl get pod -A | grep -vE '1/1|2/2|3/3|4/4|5/5|Comp|NAME'核心命令通过 docker exec 进入K8s容器,结合 grep -vE 反向过滤,可快速定位全集群(重点kube-system)中就绪状态异常的Pod,解决了人工排查效率低、步骤繁琐的问题;
该命令可落地为日常巡检脚本(定时执行+告警)、故障排查工具(快速定位+根因分析)、变更验证手段(升级/修改后验证),适配不同运维场景;
使用时需注意容器关键词匹配、正则表达式补充、权限问题,同时结合 kubectl describe/kubectl logs 等命令完成根因分析,形成完整的排查体系。