目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-Transformer架构1-整体介绍和Transformer架构2-自注意力,欲渐进,请循序
- 本文重点介绍Transformer架构中的嵌入和位置编码,它们在编码器堆栈和解码器堆栈中都有用到
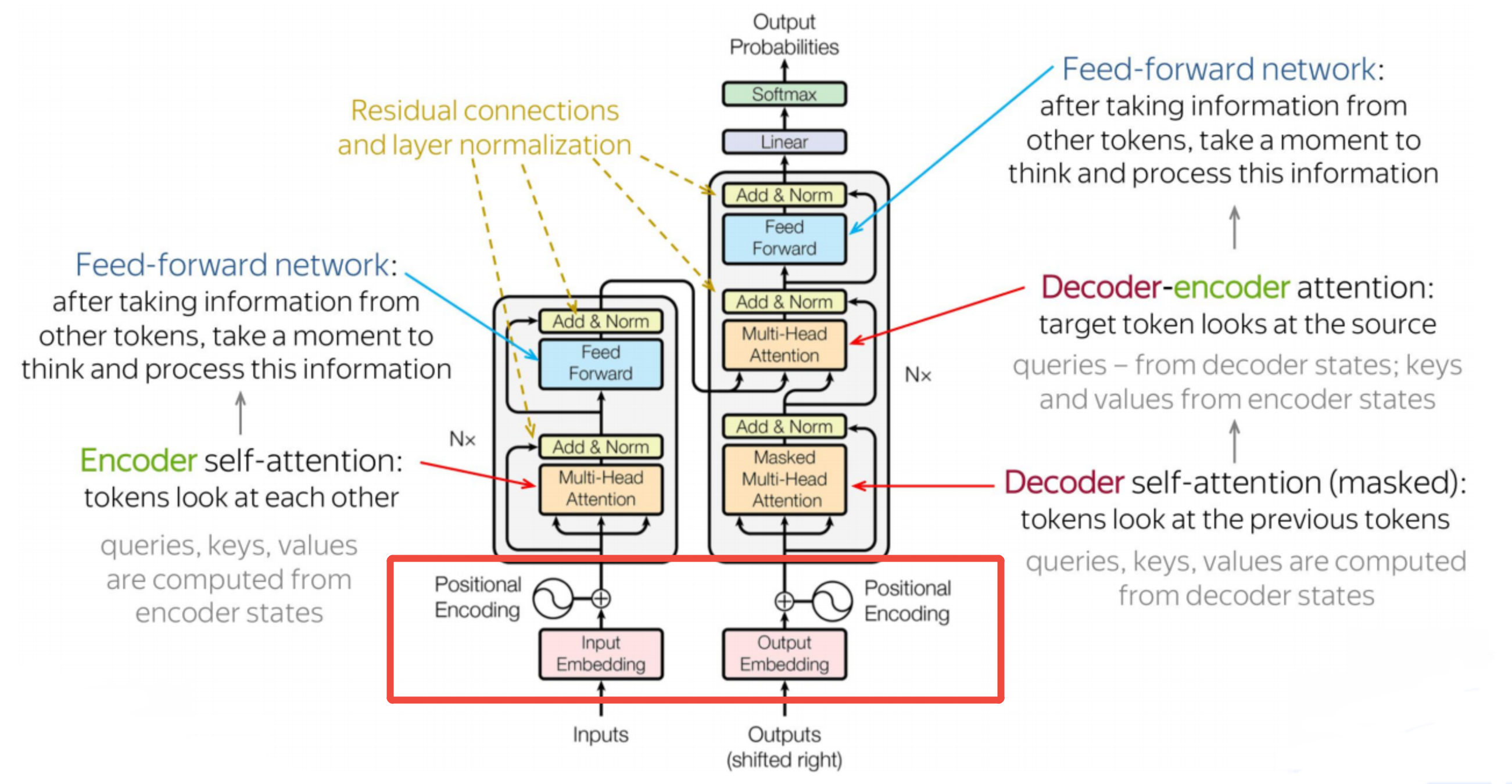
一、嵌入-Embedding
与Transformer架构1-整体介绍中讲的一样,这里的Embedding,实际上是三个动作:
- 分词Tokenize:将"我爱中国的山川湖海"拆分成"我","爱","中国","的","山","川","湖","海"
- 编码Encoding:将分词后的每个词,对照词表(类似机器能理解的新华字典),一个个翻译成机器能处理的数字编码,如1代表中文的"我",71代表中文的"爱",编码后形成1,71,102,99,210,211,212,213这样的序列
- 嵌入Embedding:嵌入是为了将数据向量化。向量化本质是通过嵌入模型,用高维向量(如1024维)充分表征每个词的语义(如"我"的多重含义、"我"的词性是名词、"我"一般用作主语或宾语等),且语义相似的两个向量余弦距离也更近。编码后的序列经向量化后是一个二维矩阵(矩阵1024列,代表嵌入模型的维度;矩阵8行,代表token的个数)
为什么嵌入后的向量,能充分表征原始token,能理解深层语义?
数据科学家负责给出理论解释,工程师则从实践结果验证猜想,这里不深究
不同类型的嵌入比较
| 嵌入类型 | 特点 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|---|
| 词嵌入 | 为每个词学习固定向量 | 简单高效,捕获词汇语义 | 无法处理一词多义,OOV问题(超出词表范围) | Word2Vec, GloVe, 文本分类 |
| 子词嵌入 | 基于子词(BPE/WordPiece)单位 | 解决OOV,捕获形态学,共享表示 | 序列变长,需分词器 | BERT, GPT系列,机器翻译 |
| 字符嵌入 | 基于字符级别的最小单位 | 完全无OOV,完美形态学处理 | 序列很长,训练困难,语义稀疏 | Char-CNN, ByT5, 形态丰富语言 |
| 段落嵌入 | 为文档/段落学习整体表示 | 文档级语义理解,信息聚合 | 丢失细节信息,粒度较粗 | Doc2Vec, 文档检索,段落分类 |
| 实体嵌入 | 为知识图谱实体学习表示 | 融合结构化知识,关系编码 | 需要外部知识库,数据依赖 | 知识图谱补全,推荐系统 |
| 多模态嵌入 | 跨模态统一表示空间 | 模态对齐,跨模态检索/生成 | 对齐难度大,数据要求高 | CLIP, DALL-E, 视觉问答 |
| 上下文嵌入 | 动态生成,依赖上下文环境 | 处理一词多义,深度语境理解 | 计算量大,需完整前向传播 | BERT, ELMo, 所有预训练模型 |
| 稀疏嵌入 | 高维稀疏表示(如哈希嵌入) | 内存效率高,快速检索 | 精度较低,哈希冲突问题 | 大规模推荐系统,广告召回 |
| 图嵌入 | 为图节点学习向量表示 | 捕获结构信息,关系感知 | 依赖于图质量,动态图难处理 | Node2Vec, GNN, 社交网络分析 |
注 :现代大模型主要采用上下文嵌入 (如Transformer架构)和子词嵌入(BPE/WordPiece),因其在语义表示和泛化能力上的综合优势。
二、位置编码-Position Encoding
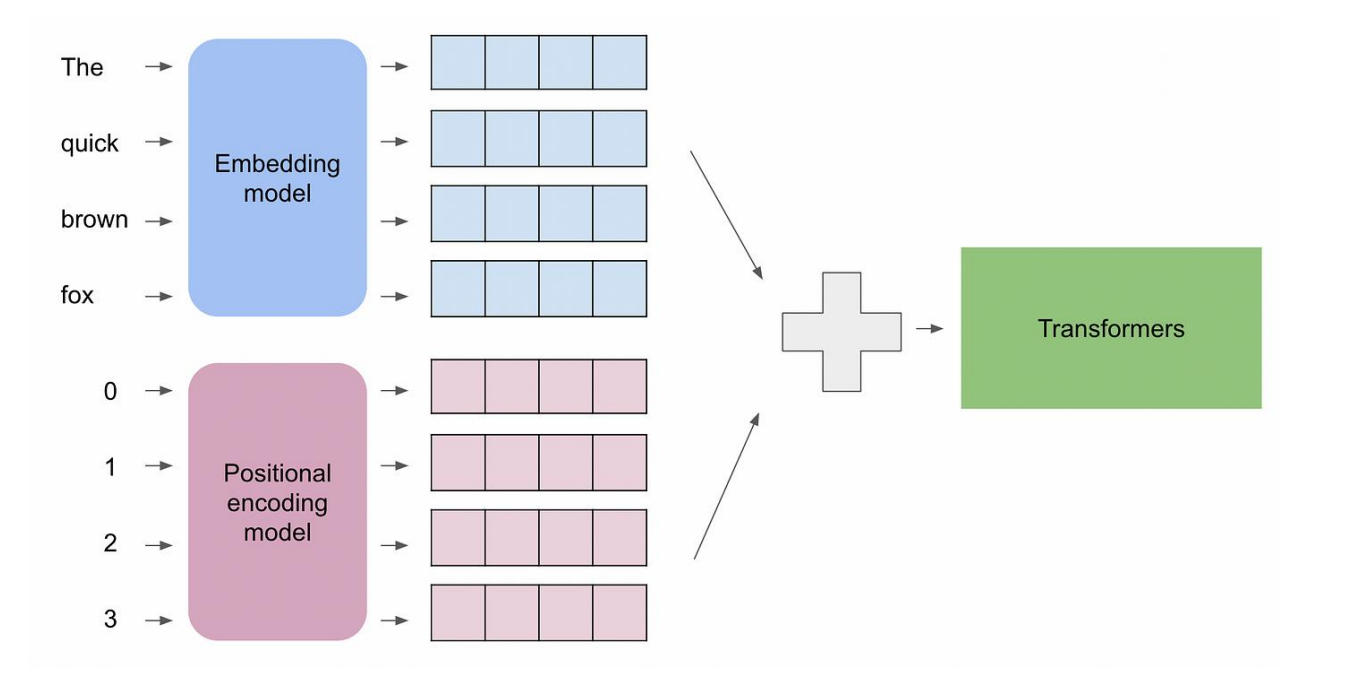
为什么需要位置编码
- 嵌入后的每个向量,只有单个词的信息。而语言的信息,不仅存在于每个词中,还存在每个词出现的顺序/位置中。
- 后续的自注意力本身是排列等变的:输入序列重排时,输出也相应重排,缺乏位置信息。
- 因此位置编码用来填补这个空白,它为嵌入后的数据注入位置信息,使Transformer能够处理自然语言中的顺序依赖关系
什么是位置编码
对比理解:
嵌入是一种编码手段,它将人类理解的语句转换成浮点数矩阵(一组向量),该矩阵包含了原始语句的每个词的语义信息;
位置编码也是类似的编码手段,它将人类理解的语句的位置信息转换成相同大小 的浮点数矩阵,该矩阵包含了原始语句中,每个词的顺序信息。
因此嵌入后的矩阵+位置编码后的矩阵=包含原始语句完整语义的矩阵
不同类型的位置编码比较
| 编码类型 | 特点 | 优点 | 缺点 | 典型应用 |
|---|---|---|---|---|
| 正弦余弦 | 预定义三角函数,无需训练 | 无限外推能力,参数效率高,相对位置编码 | 灵活性差,无法自适应数据 | 原始Transformer,ViT |
| 可学习嵌入 | 每个位置学习一个向量 | 自适应数据,灵活性高 | 长度固定,无外推能力,增加参数量 | BERT,RoBERTa,GPT-2 |
| 相对位置 | 编码相对距离而非绝对位置 | 更好的泛化,适合长序列 | 实现复杂,需要训练偏置参数 | T5,DeBERTa,Transformer-XL |
| 旋转编码 | 通过旋转操作融入位置信息 | 保持相对位置特性,优秀外推 | 数学复杂,计算量稍大 | LLaMA,PaLM,ChatGLM |
| 线性偏置 | 在注意力分数加线性衰减偏置 | 极简设计,强大外推能力 | 表达能力受限,过于简单 | BLOOM,ALiBi系列 |
| 层次编码 | 多粒度位置编码 | 适合文档级任务,层次感知 | 实现复杂,多组参数 | Longformer,BigBird |
注 :现代大模型多采用相对位置 或旋转位置编码,因其在长序列处理和外推能力上的优势。
为什么位置编码和嵌入后的矩阵相加后,transformer能同时理解到位置和语义信息?
这可以分解为两个问题:1、为什么矩阵合并后信息没有丢失?2、为什么用加法?
1、为什么矩阵合并后信息没有丢失?**
矩阵合并后,原始语义信息和位置信息都溶解 在合并后的矩阵里,无法反向提取出来,好像反而会导致信息的丢失,其实不然。
以位置信息为例,Transformer能理解位置信息,不是因为能从加法和中"反向取出"位置编码,而是因为:
-
位置信息已"溶解"在所有后续计算中,特别是注意力机制中,位置的影响会自然显现
-
位置编码的特定设计使其在注意力计算中产生可识别的模式
-
模型通过训练学会了识别这些模式,而不是反向提取
2、为什么用加法?
加法被选择,不是因为它是理论上最优的,而是因为它是实践中最佳的平衡点:
-
计算效率:O(d)复杂度,最简单快速
-
梯度友好:不会导致梯度消失/爆炸
-
信息保存:基本保持语义信息的完整性
-
足够表达:结合注意力机制,能学习复杂模式
-
实验验证:在各种任务上表现优异