InnoDB行级锁解析
数据库锁机制的必要性与演进
并发控制的挑战
在多用户并发访问数据库的场景下,数据一致性和事务隔离性成为数据库管理系统必须解决的核心问题。如果没有合适的并发控制机制,会出现以下典型问题:
- 脏读:事务A读取了事务B未提交的数据
- 不可重复读:同一事务内两次读取同一数据,结果不一致
- 幻读:同一事务内两次查询,返回的结果集数量不同
- 丢失更新:两个事务同时修改同一数据,后提交的覆盖了先提交的修改
锁机制的演进历程
数据库锁机制经历了从粗粒度到细粒度的演进过程:
表级锁时代 :
早期数据库系统主要采用表级锁,无论是MyISAM还是早期InnoDB,表锁实现简单、开销小,但并发性能差。一个事务锁定整张表后,其他事务无法访问表中的任何数据,严重限制了系统吞吐量。
页级锁过渡 :
为了平衡锁开销和并发度,一些数据库引入了页级锁(锁定数据页)。页是数据库存储的基本单位,通常为4KB-16KB。页锁的粒度介于表锁和行锁之间,但仍可能造成不必要的锁定冲突。
行级锁时代 :
现代关系型数据库(如InnoDB、Oracle、SQL Server)普遍采用行级锁作为默认锁机制。行锁极大提高了并发性能,但带来了更复杂的锁管理和更高的系统开销。InnoDB作为MySQL最常用的存储引擎,其行级锁实现具有高度的复杂性和精巧性。
InnoDB行级锁的本质与架构
InnoDB行级锁机制
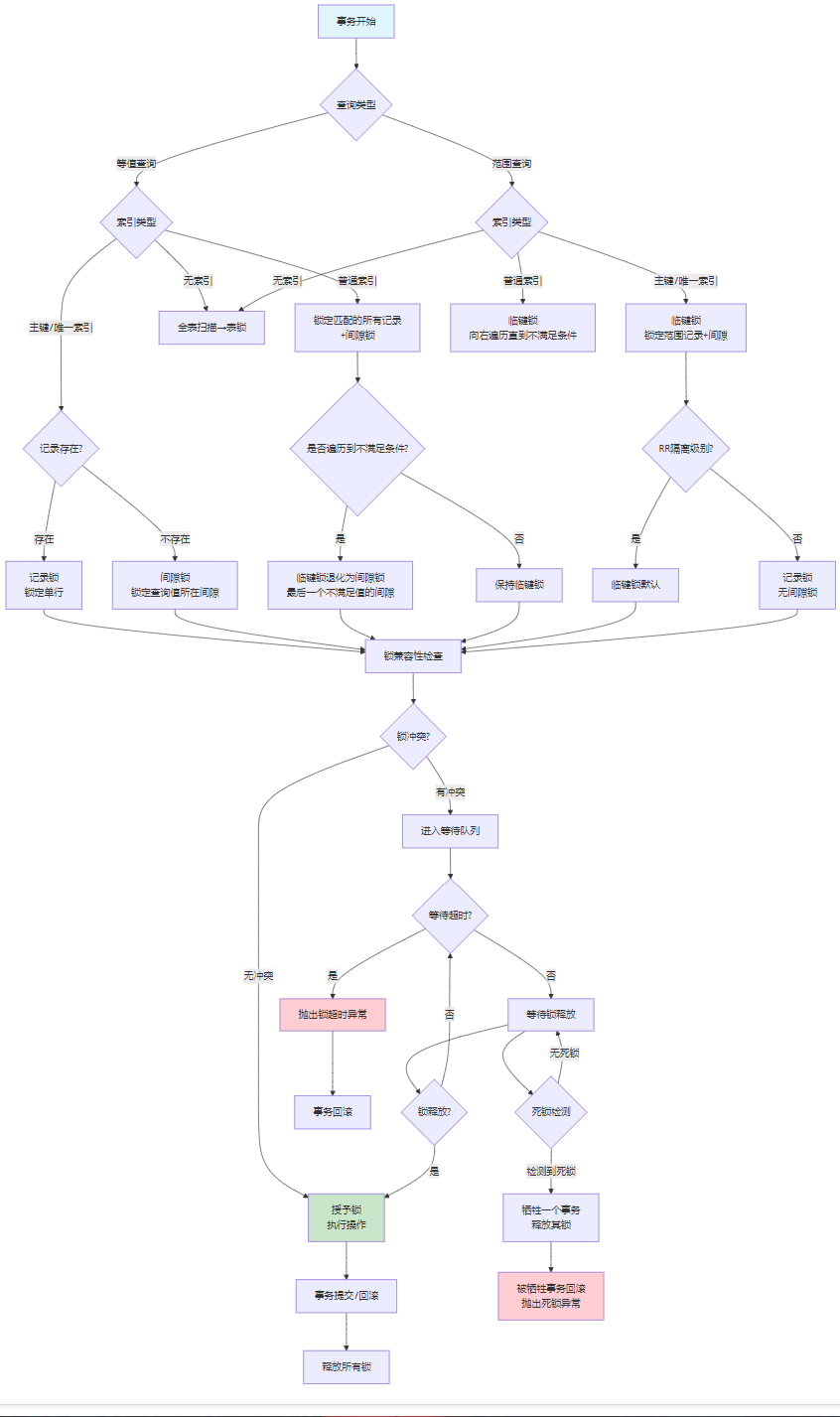
锁类型详细决策
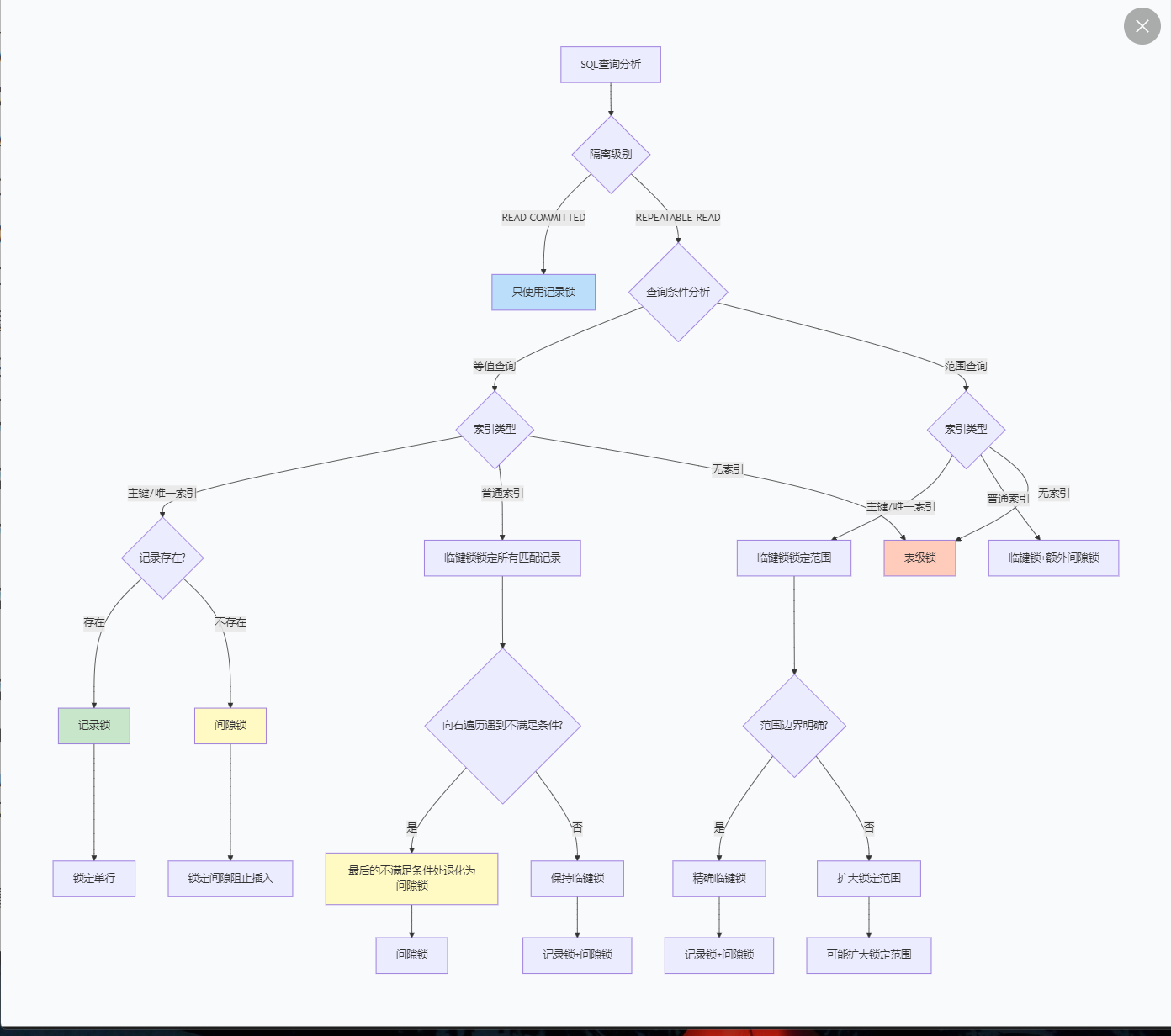
核心命题:为什么锁住的是索引而不是数据行?
这是理解InnoDB行级锁的关键所在。InnoDB存储引擎采用聚集索引(Clustered Index) 的表结构,数据行本身按主键顺序存储在B+树中。这种设计带来了以下影响:
- 数据即索引:在聚集索引中,叶子节点包含完整的数据行,而非行指针
- 锁定路径依赖:要锁定一行数据,必须通过索引路径找到该行
- 锁的物理载体:锁信息存储在索引结构上,而不是单独的数据行上
InnoDB锁系统的架构设计
sql
-- 锁信息查询示例
SELECT
r.trx_id AS '事务ID',
r.trx_state AS '事务状态',
r.trx_started AS '事务开始时间',
TIMESTAMPDIFF(SECOND, r.trx_started, NOW()) AS '事务持续时间(s)',
l.lock_mode AS '锁模式',
l.lock_type AS '锁类型',
l.lock_table AS '锁定的表',
l.lock_index AS '锁定的索引',
l.lock_data AS '锁定的数据'
FROM
information_schema.INNODB_TRX r
JOIN information_schema.INNODB_LOCKS l ON r.trx_id = l.lock_trx_id
WHERE
r.trx_state = 'RUNNING'
ORDER BY
r.trx_started;InnoDB的锁系统包含以下核心组件:
- 锁管理器:全局锁管理结构,负责锁的分配和回收
- 锁对象池:预分配的锁内存结构,避免频繁的内存分配
- 等待队列:处理锁冲突的事务等待机制
- 死锁检测:定期检测和解除死锁的监控机制
锁的内存结构与存储
每个锁在内存中表示为lock_struct结构体,包含以下关键信息:
- 事务ID
- 锁模式(S/X)
- 锁类型(记录锁/间隙锁/临键锁)
- 锁定对象的标识
- 等待标志和等待队列指针
锁信息不持久化到磁盘,而是在内存中维护。服务器重启后,锁信息会丢失,但通过事务日志可以保证数据一致性。
记录锁(Record Locks)深度解析
记录锁的工作原理
记录锁是对索引记录的精确锁定。当对唯一索引或主键进行等值查询时,InnoDB会使用记录锁。
sql
-- 示例:记录锁的产生
START TRANSACTION;
-- 在id=1的记录上加X锁
SELECT * FROM users WHERE id = 1 FOR UPDATE;
-- 在另一个会话中尝试
START TRANSACTION;
-- 这会被阻塞,因为id=1已被X锁锁定
SELECT * FROM users WHERE id = 1 FOR UPDATE;
-- 或
UPDATE users SET name = 'test' WHERE id = 1;共享锁(S Lock)与排他锁(X Lock)的差异
共享锁的特性:
- 多个事务可以同时持有同一数据行的S锁
- S锁之间是兼容的,允许并发读取
- S锁与X锁不兼容,有X锁存在时无法获取S锁
- S锁主要用于保证读一致性
排他锁的特性:
- X锁具有排他性,一个数据行只能有一个X锁
- X锁与任何其他锁都不兼容(包括其他X锁和S锁)
- X锁主要用于数据修改操作
锁兼容性矩阵
| 当前锁模式 | 请求S锁 | 请求X锁 |
|---|---|---|
| 无锁 | 允许 | 允许 |
| S锁 | 允许 | 拒绝 |
| X锁 | 拒绝 | 拒绝 |
记录锁的底层实现机制
记录锁的实现依赖于InnoDB的索引结构。当对一行数据加锁时:
- 索引定位:通过B+树索引定位到目标记录
- 锁位图检查:检查该索引记录对应的锁位图状态
- 锁冲突检测:如果存在不兼容的锁,进入等待队列
- 锁授予:无冲突时,设置锁位图并返回成功
对于聚集索引,锁直接加在数据行上;对于二级索引,锁加在索引记录上,同时还需要对对应的主键记录加锁。
间隙锁(Gap Locks)的深入分析
间隙锁的定义与目的
间隙锁锁定的是索引记录之间的间隙,而不是具体的记录。它的主要目的是防止幻读(Phantom Read)。
sql
-- 示例:间隙锁的产生
-- 假设表users有id: 1, 3, 5, 7, 9
START TRANSACTION;
-- 锁定id在(5, 7)之间的间隙
SELECT * FROM users WHERE id > 5 AND id < 7 FOR UPDATE;
-- 在另一个会话中
START TRANSACTION;
-- 以下插入会被阻塞,因为落入了间隙锁范围
INSERT INTO users (id, name) VALUES (6, 'new_user');间隙锁的工作范围
间隙锁的锁定范围包括:
- 索引记录前的开区间间隙
- 索引记录后的开区间间隙
- 对于唯一索引,特定条件下会退化(后文详述)
间隙锁的特殊性质
-
仅存在于RR隔离级别:在RC隔离级别下,InnoDB不使用间隙锁
-
兼容性规则独特:
- 不同事务可以在同一间隙上加间隙锁
- 间隙锁不阻止其他事务在相同间隙加间隙锁
- 但间隙锁会阻止在间隙中插入新记录
-
索引边界处理:
- 对于最小索引值之前的间隙,使用"负无穷"作为左边界
- 对于最大索引值之后的间隙,使用"正无穷"作为右边界
间隙锁的实际应用场景
sql
-- 场景1:范围查询防止幻读
START TRANSACTION;
-- 这个查询会锁定age在(20, 30)之间的所有间隙
SELECT * FROM employees WHERE age BETWEEN 20 AND 30 FOR UPDATE;
-- 其他事务无法插入age在20-30之间的新记录
-- 但可以插入age=19或age=31的记录
-- 场景2:等值查询不存在的记录
START TRANSACTION;
-- 假设id=6不存在,会锁定(5, 7)的间隙
SELECT * FROM users WHERE id = 6 FOR UPDATE;临键锁(Next-Key Locks)的全面剖析
临键锁的定义与组成
临键锁是InnoDB在RR隔离级别下的默认锁算法,它是记录锁和间隙锁的组合。具体来说,临键锁锁定的是:
- 索引记录本身(记录锁)
- 该记录之前的间隙(间隙锁)
数学表示:临键锁 = 记录锁 ∪ (记录前的间隙锁)
临键锁的锁定规则
sql
-- 示例数据:id为1, 3, 5, 7, 9
START TRANSACTION;
-- 情况1:锁定id=5的记录
SELECT * FROM users WHERE id = 5 FOR UPDATE;
-- 锁定范围: (3, 5] -- 5是记录锁,(3,5)是间隙锁
-- 情况2:范围查询
SELECT * FROM users WHERE id BETWEEN 3 AND 7 FOR UPDATE;
-- 锁定范围: (1, 9] -- 实际测试可能不同,取决于具体实现临键锁的退化机制
在某些特定条件下,临键锁会退化为更简单的锁类型:
唯一索引等值查询且记录存在
sql
-- 假设id是唯一索引,且id=5存在
SELECT * FROM users WHERE id = 5 FOR UPDATE;
-- 退化为记录锁,只锁定id=5这一行唯一索引等值查询且记录不存在
sql
-- 假设id是唯一索引,且id=6不存在
SELECT * FROM users WHERE id = 6 FOR UPDATE;
-- 退化为间隙锁,锁定(5, 7)的间隙普通索引的特殊退化
sql
-- 假设age是普通索引,有值:20, 20, 25, 30
START TRANSACTION;
SELECT * FROM employees WHERE age = 25 FOR UPDATE;
-- 锁定过程:
-- 1. 锁定第一个age=25的记录(临键锁)
-- 2. 继续向右扫描,直到age≠25(age=30)
-- 3. 最后一个不满足条件的记录前的间隙锁会单独加上
-- 最终锁定: (20, 25], (25, 30)的间隙临键锁的算法实现
InnoDB的锁算法通过lock_rec_lock函数实现,其伪代码逻辑如下:
c
// 伪代码,展示临键锁的实现逻辑
LockResult lock_rec_lock(lock_mode, index, record) {
// 1. 检查是否已经持有锁
if (already_locked(record)) {
return LOCK_ALREADY_HELD;
}
// 2. RR隔离级别下使用临键锁
if (isolation_level == RR) {
// 2.1 检查是否满足退化条件
if (is_unique_index && is_equal_query) {
if (record_exists) {
// 退化为记录锁
return add_record_lock(record);
} else {
// 退化为间隙锁
return add_gap_lock(find_gap(record));
}
}
// 2.2 普通情况使用临键锁
return add_next_key_lock(record);
}
// 3. RC隔离级别只使用记录锁
return add_record_lock(record);
}行级锁的索引依赖性与优化
索引对锁定的影响
使用主键/唯一索引
sql
-- 最佳实践:使用主键条件
UPDATE users SET status = 'active' WHERE id = 100;
-- 只锁定id=100这一行,精确锁定使用普通索引
sql
-- 假设在email字段有普通索引
UPDATE users SET status = 'active' WHERE email = 'user@example.com';
-- 锁定过程:
-- 1. 在email索引上锁定所有email='user@example.com'的记录
-- 2. 通过主键回表,锁定对应的主键记录
-- 3. 可能产生多个行锁无索引或索引失效
sql
-- 危险操作:无索引字段条件
UPDATE users SET status = 'active' WHERE name = 'John';
-- 如果name没有索引,会进行全表扫描
-- 可能升级为表锁,或锁定表中所有行锁升级的触发条件
InnoDB的行锁可能升级为表锁,主要发生在以下情况:
- 显式表锁请求 :使用
LOCK TABLES语句 - DDL操作:ALTER TABLE等结构修改操作
- 特殊情况:当锁等待超时或死锁检测成本过高时
- 系统资源不足:锁内存占用超过阈值
索引设计的最佳实践
- 为高频查询条件创建索引:减少锁的扫描范围
- 使用覆盖索引:避免回表带来的额外锁定
- 合理设计组合索引:让索引覆盖更多查询场景
- 避免过度索引:索引本身也会增加锁的开销
高级锁机制与特殊场景
插入意向锁(Insert Intention Locks)
插入意向锁是一种特殊的间隙锁,表示事务准备在某个间隙插入记录。
sql
-- 示例:插入意向锁的使用
-- 事务1
START TRANSACTION;
SELECT * FROM users WHERE id > 10 AND id < 20 FOR UPDATE;
-- 锁定间隙(10, 20)
-- 事务2
START TRANSACTION;
-- 尝试在间隙中插入,会先获取插入意向锁
INSERT INTO users (id, name) VALUES (15, 'new');
-- 插入意向锁与事务1的间隙锁冲突,事务2等待插入意向锁的特性:
- 是一种间隙锁,不是记录锁
- 多个事务可以在同一间隙上获取插入意向锁
- 与已有的间隙锁冲突
- 目的是提高插入操作的并发性
自增锁(AUTO-INC Locks)
自增锁是一种特殊的表级锁,用于处理自增主键的并发插入。
sql
-- 自增锁的行为取决于innodb_autoinc_lock_mode配置
-- 模式0:传统模式,每个插入都需要表锁
-- 模式1:连续模式(默认),简单插入使用轻量级锁
-- 模式2:交错模式,完全并发,但可能不连续
SHOW VARIABLES LIKE 'innodb_autoinc_lock_mode';谓词锁(Predicate Locks)
在RR隔离级别下,InnoDB使用谓词锁来防止幻读。谓词锁不是实际存在的锁类型,而是通过间隙锁和临键锁的组合来实现的。
锁的继承与传播
在二级索引上的锁会传播到主键索引:
sql
-- 假设表结构:id(主键), email(二级索引), name
START TRANSACTION;
-- 在二级索引上加锁
SELECT * FROM users WHERE email = 'test@example.com' FOR UPDATE;
-- InnoDB会同时锁定:
-- 1. email索引上所有email='test@example.com'的记录
-- 2. 对应主键索引上的记录锁的监控、诊断与优化
锁信息查询工具
系统表查询
sql
-- 查看当前锁信息
SELECT
r.trx_id,
r.trx_state,
r.trx_started,
l.lock_id,
l.lock_mode,
l.lock_type,
l.lock_table,
l.lock_index,
l.lock_data,
TIMESTAMPDIFF(SECOND, r.trx_started, NOW()) as duration_sec
FROM
information_schema.INNODB_TRX r
LEFT JOIN information_schema.INNODB_LOCKS l ON r.trx_id = l.lock_trx_id
WHERE
r.trx_state = 'RUNNING'
ORDER BY
r.trx_started;
-- 查看锁等待关系
SELECT
r.blocking_trx_id,
r.blocking_lock_id,
r.requesting_trx_id,
r.requesting_lock_id,
TIMESTAMPDIFF(SECOND, w.wait_started, NOW()) as wait_sec
FROM
information_schema.INNODB_LOCK_WAITS w
JOIN information_schema.INNODB_LOCKS l ON w.requesting_lock_id = l.lock_id;Performance Schema监控
sql
-- 启用锁监控
UPDATE performance_schema.setup_consumers
SET ENABLED = 'YES'
WHERE NAME LIKE 'events_transactions%';
UPDATE performance_schema.setup_instruments
SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE 'wait/synch/mutex/innodb%';死锁检测与分析
死锁产生条件
死锁产生的四个必要条件:
- 互斥条件:资源独占
- 请求与保持:持有资源的同时请求新资源
- 不剥夺条件:资源只能自愿释放
- 循环等待:事务间形成等待环
InnoDB死锁处理
sql
-- 查看最近死锁信息
SHOW ENGINE INNODB STATUS;
-- 在输出中查找"LATEST DETECTED DEADLOCK"部分
-- 死锁相关配置
SHOW VARIABLES LIKE 'innodb_deadlock_detect'; -- 死锁检测开关
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout'; -- 锁等待超时时间避免死锁的策略
- 固定访问顺序:约定事务总是按相同顺序访问表
- 降低事务粒度:小事务减少锁持有时间
- 合理使用索引:减少锁范围
- 使用锁定提示 :如
FOR UPDATE NOWAIT - 设置合理的超时时间
锁性能优化实践
应用层优化
sql
-- 1. 使用悲观锁的替代方案
-- 乐观锁示例
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 100 AND version = 5 AND stock > 0;
-- 2. 分批处理减少锁持有时间
-- 不推荐:长时间持有锁
START TRANSACTION;
UPDATE large_table SET status = 'processed' WHERE condition;
-- 长时间操作
COMMIT;
-- 推荐:分批提交
SET autocommit = 0;
WHILE (存在未处理数据) DO
UPDATE large_table SET status = 'processed'
WHERE condition LIMIT 1000;
COMMIT;
END WHILE;
SET autocommit = 1;数据库层优化
sql
-- 1. 合理设置隔离级别
-- 从RR降低到RC可以减少间隙锁
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 2. 优化索引设计
-- 创建合适的索引减少锁扫描
CREATE INDEX idx_status_created ON orders(status, created_at);
-- 3. 调整锁相关参数
-- 增加锁内存
SET GLOBAL innodb_buffer_pool_size = 8G;
-- 调整锁超时
SET GLOBAL innodb_lock_wait_timeout = 30;架构层优化
- 读写分离:将读操作路由到从库
- 分库分表:减少单表数据量
- 使用缓存:减少数据库访问
- 异步处理:非实时操作采用消息队列
不同场景下的锁策略选择
OLTP场景(高并发事务)
sql
-- 特点:短事务、高并发
-- 策略:行锁为主,尽量减少锁范围
-- 推荐做法:
-- 1. 使用主键/唯一索引操作
UPDATE accounts SET balance = balance - 100 WHERE account_id = 123;
-- 2. 避免长时间持有锁
-- 不推荐:在事务中进行复杂计算
START TRANSACTION;
SELECT balance INTO @bal FROM accounts WHERE account_id = 123;
-- 复杂业务计算...
UPDATE accounts SET balance = @bal - 100 WHERE account_id = 123;
COMMIT;
-- 推荐:快速完成数据操作
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE account_id = 123;
COMMIT;
-- 在事务外处理业务逻辑OLAP场景(分析查询)
sql
-- 特点:大数据量、复杂查询、低并发
-- 策略:避免锁影响,使用快照读
-- 推荐做法:
-- 1. 使用RC隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 2. 使用查询提示
SELECT /*+ MAX_EXECUTION_TIME(10000) */
customer_id, SUM(amount)
FROM orders
GROUP BY customer_id;
-- 3. 考虑使用从库查询
-- 配置读分离,将分析查询路由到专门的分析从库混合工作负载
sql
-- 策略:根据操作类型选择不同锁机制
-- 实时更新使用行锁
START TRANSACTION;
UPDATE inventory SET quantity = quantity - 1
WHERE product_id = 100 AND quantity > 0;
COMMIT;
-- 报表查询使用快照
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT product_id, SUM(quantity)
FROM inventory
GROUP BY product_id;
-- 批量处理使用特殊策略
-- 使用LOCK IN SHARE MODE获取快照,然后批量更新
START TRANSACTION;
SELECT product_id, quantity
FROM inventory
WHERE warehouse_id = 1
LOCK IN SHARE MODE;
-- 基于快照计算,然后批量更新
UPDATE inventory SET status = 'processed'
WHERE warehouse_id = 1;
COMMIT;未来发展与替代方案
MySQL 8.0的锁优化
MySQL 8.0引入了多项锁相关优化:
- 原子DDL:减少DDL操作对锁的影响
- 更好的索引条件下推:减少回表和锁开销
- 增强的Performance Schema:更细粒度的锁监控
乐观并发控制
除了悲观锁,乐观并发控制(OCC)也是一种重要的并发控制策略:
sql
-- 乐观锁实现示例
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100),
stock INT,
version INT DEFAULT 0
);
-- 更新时检查版本
UPDATE products
SET stock = stock - 1, version = version + 1
WHERE id = 100 AND version = 5;
-- 如果受影响行数为0,说明版本冲突,需要重试多版本并发控制(MVCC)
InnoDB的MVCC机制为读操作提供了非锁定的一致性视图:
sql
-- 在RR隔离级别下
START TRANSACTION;
-- 这时获得一致性视图
SELECT * FROM users; -- 看到事务开始时的数据快照
-- 另一个事务修改数据并提交
-- 在另一个会话中
START TRANSACTION;
UPDATE users SET name = 'updated' WHERE id = 1;
COMMIT;
-- 第一个事务仍然看到旧数据
SELECT * FROM users; -- 仍然看到事务开始时的数据
COMMIT;分布式数据库的锁挑战
在分布式数据库中,锁的实现更加复杂:
- 分布式锁服务:如基于ZooKeeper或etcd的锁服务
- 共识算法:Raft、Paxos等保证数据一致性
- 时钟同步:解决分布式事务的时间戳问题
- 冲突检测与解决:更复杂的冲突处理机制
总结
InnoDB的行级锁机制是一个精心设计的并发控制系统,它通过记录锁、间隙锁和临键锁的组合,在保证数据一致性的同时,尽可能提高并发性能。理解这些锁的工作原理对于设计高性能数据库应用至关重要。
关键要点回顾:
- 锁的本质:行级锁锁定的是索引记录,而不是物理数据行
- 锁的演进:根据查询条件和索引类型,InnoDB会选择不同的锁策略
- 隔离级别的影响:RR级别使用临键锁防止幻读,RC级别不使用间隙锁
- 优化方向:合理设计索引、控制事务粒度、监控锁冲突
在实际应用中,需要根据具体的业务场景、数据访问模式和性能要求,选择合适的锁策略和优化方案。随着数据库技术的发展,新的并发控制机制不断涌现,但理解传统锁机制仍然是数据库优化的基础。