MySQL临时表深度解析:从原理到实践
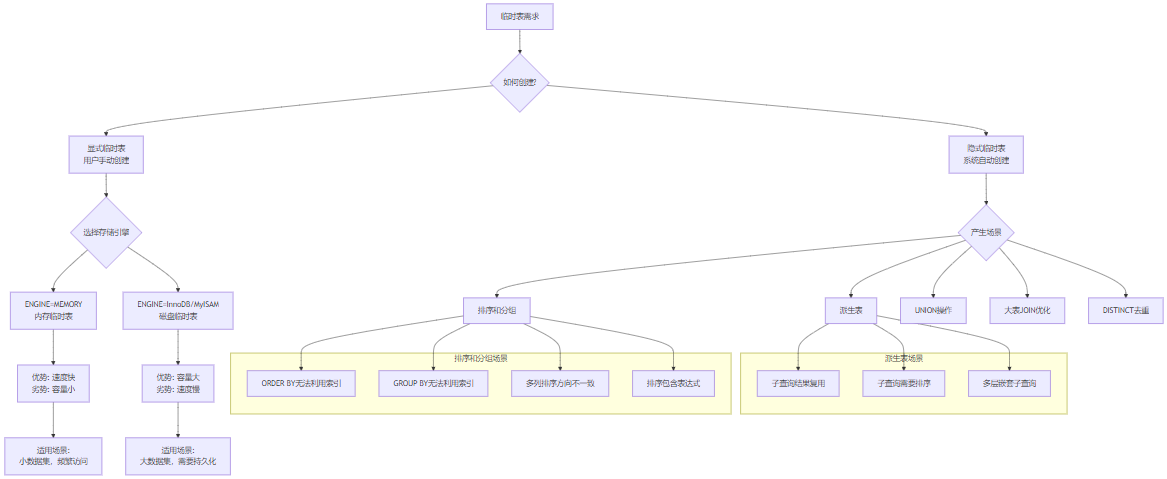
临时表的本质与分类
临时表的定义与特点
**临时表(Temporary Table)**是MySQL中一种特殊类型的表,其生命周期仅限于当前数据库连接(会话)。当会话结束时,临时表会自动被删除,释放所有相关资源。
sql
-- 创建临时表的基本语法
CREATE TEMPORARY TABLE temp_table (
id INT PRIMARY KEY,
name VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 临时表与普通表的关键区别:
-- 1. 仅在当前会话可见
-- 2. 会话结束自动删除
-- 3. 可与普通表同名(优先级更高)临时表的分类体系
MySQL中的临时表根据存储引擎和用途可分为多个类别:
临时表分类体系:
├── 显式临时表(用户手动创建)
│ ├── 内存临时表(ENGINE=MEMORY)
│ └── 磁盘临时表(ENGINE=InnoDB/MyISAM)
│
└── 隐式临时表(系统自动创建)
├── 查询执行临时表
│ ├── DERIVED(派生表)
│ ├── UNION(联合查询)
│ └── SUBQUERY(子查询)
│
└── 排序/分组临时表
├── ORDER BY临时表
└── GROUP BY临时表按存储位置分类
- 内存临时表:使用Memory引擎,数据存储在内存中
- 磁盘临时表:使用InnoDB或MyISAM引擎,数据存储在磁盘上
按创建方式分类
- 显式临时表 :用户使用
CREATE TEMPORARY TABLE语句创建 - 隐式临时表:MySQL优化器在执行查询时自动创建
临时表的产生场景深度分析
排序和分组场景
ORDER BY无法利用索引的场景
sql
-- 场景1:多列排序且排序方向不一致
EXPLAIN SELECT * FROM users
ORDER BY last_name ASC, first_name DESC;
-- 即使有(last_name, first_name)的复合索引,也无法完全利用
-- 场景2:使用非索引列排序
EXPLAIN SELECT * FROM users ORDER BY email;
-- 如果email列没有索引,需要创建临时表
-- 场景3:排序包含表达式或函数
EXPLAIN SELECT * FROM users
ORDER BY SUBSTRING(email, 1, 10) DESC;内部实现机制:
c
// 伪代码:排序操作使用临时表的决策过程
bool need_tmp_table_for_sort(Query *query) {
// 检查排序条件
if (!can_use_index_for_order_by(query)) {
// 检查内存限制
estimated_rows = estimate_row_count(query);
estimated_size = estimated_rows * avg_row_size;
if (estimated_size > sort_buffer_size) {
// 需要外部排序,使用临时表
return true;
}
}
return false;
}
// 排序临时表的创建过程
void create_tmp_table_for_sort(THD *thd, TABLE_LIST *table_list) {
// 1. 估算临时表大小
tmp_table_size = estimate_tmp_table_size(thd);
// 2. 选择存储引擎
if (tmp_table_size < thd->variables.tmp_table_size &&
!contains_blob_or_text(thd)) {
// 使用Memory引擎
create_tmp_table_in_memory(thd, table_list);
} else {
// 使用磁盘临时表(InnoDB)
create_tmp_table_on_disk(thd, table_list);
}
// 3. 执行排序
if (in_memory) {
qsort_in_memory(tmp_table);
} else {
external_sort_on_disk(tmp_table);
}
}GROUP BY无法利用索引的场景
sql
-- 场景1:GROUP BY列没有索引
EXPLAIN SELECT department, COUNT(*)
FROM employees
GROUP BY department;
-- 场景2:GROUP BY包含多列但不符合索引最左前缀
-- 假设有索引(department, position),但查询是:
EXPLAIN SELECT position, COUNT(*)
FROM employees
GROUP BY position;
-- 场景3:GROUP BY与ORDER BY不同
EXPLAIN SELECT department, AVG(salary)
FROM employees
GROUP BY department
ORDER BY AVG(salary) DESC;GROUP BY临时表的工作流程:
c
// 伪代码:GROUP BY使用临时表的实现
execute_group_by_with_tmp_table(THD *thd) {
// 阶段1:创建临时表
tmp_table = create_tmp_table_for_group_by(thd);
// 阶段2:填充临时表
while ((row = get_next_row(thd))) {
// 计算GROUP BY键的哈希值
hash_key = calculate_group_key_hash(row);
// 在临时表中查找或插入
existing_row = find_in_tmp_table(tmp_table, hash_key);
if (existing_row) {
// 聚合函数计算(如SUM、AVG等)
update_aggregate_functions(existing_row, row);
} else {
// 插入新组
insert_new_group(tmp_table, hash_key, row);
}
}
// 阶段3:应用HAVING条件
apply_having_clause(tmp_table);
// 阶段4:排序结果(如果ORDER BY与GROUP BY不同)
if (need_extra_sort) {
sort_tmp_table(tmp_table);
}
// 阶段5:返回结果
return read_from_tmp_table(tmp_table);
}派生表场景
子查询结果需要复用
sql
-- 场景1:子查询在SELECT列表中多次使用
EXPLAIN
SELECT
(SELECT COUNT(*) FROM orders WHERE customer_id = c.id) as order_count,
(SELECT SUM(amount) FROM orders WHERE customer_id = c.id) as total_amount
FROM customers c
WHERE c.country = 'USA';
-- 场景2:子查询需要排序后再使用
EXPLAIN
SELECT * FROM (
SELECT * FROM orders
WHERE order_date > '2023-01-01'
ORDER BY order_date DESC
) AS recent_orders
WHERE amount > 1000;
-- 场景3:多层嵌套子查询
EXPLAIN
SELECT * FROM (
SELECT customer_id, SUM(amount) as total
FROM (
SELECT * FROM orders WHERE status = 'completed'
) AS completed_orders
GROUP BY customer_id
HAVING total > 10000
) AS big_spenders;派生表物化机制
MySQL优化器决定是否将派生表物化为临时表:
sql
-- 查看派生表优化相关参数
SHOW VARIABLES LIKE 'optimizer_switch';
-- derived_merge: 是否尝试合并派生表
-- materialization: 物化优化
-- 强制关闭派生表合并,观察执行计划变化
SET SESSION optimizer_switch = 'derived_merge=off';
EXPLAIN SELECT * FROM (
SELECT * FROM orders WHERE amount > 100
) AS big_orders;物化决策算法:
c
// 伪代码:派生表物化决策
bool should_materialize_derived(Query_block *derived_query) {
// 因素1:派生表复杂度
complexity = calculate_query_complexity(derived_query);
// 因素2:估计行数
estimated_rows = derived_query->get_estimated_row_count();
// 因素3:是否包含聚合、排序、LIMIT等
has_aggregates = derived_query->has_aggregates();
has_order_by = derived_query->has_order_by();
has_limit = derived_query->has_limit();
// 因素4:是否被多次引用
reference_count = derived_query->get_reference_count();
// 决策逻辑
if (has_aggregates || has_order_by || has_limit) {
// 复杂派生表,倾向于物化
return true;
}
if (reference_count > 1) {
// 被多次引用,物化更高效
return true;
}
if (estimated_rows > MATERIALIZATION_THRESHOLD) {
// 行数太多,合并可能更高效
return false;
}
// 默认尝试合并
return false;
}UNION操作场景
UNION与UNION ALL的区别
sql
-- UNION ALL:直接合并,不删除重复
-- 通常不需要临时表(除非需要排序)
EXPLAIN
SELECT id, name FROM employees
UNION ALL
SELECT id, name FROM contractors;
-- UNION:需要去重
-- 通常需要临时表进行去重操作
EXPLAIN
SELECT id, name FROM current_employees
UNION
SELECT id, name FROM former_employees;
-- UNION包含ORDER BY/LIMIT
-- 需要临时表进行整体排序
EXPLAIN
(SELECT id, name FROM employees WHERE department = 'IT')
UNION
(SELECT id, name FROM employees WHERE department = 'HR')
ORDER BY name
LIMIT 10;UNION临时表的工作机制
c
// 伪代码:UNION操作使用临时表的实现
execute_union_with_tmp_table(THD *thd, Query_expression *union_query) {
// 创建结果临时表
tmp_table = create_union_result_table(thd);
// 处理第一个查询
execute_first_select(union_query->first_query_block());
while ((row = get_next_row())) {
insert_into_tmp_table(tmp_table, row);
}
// 处理后续查询
for (query in union_query->rest_query_blocks()) {
execute_select(query);
while ((row = get_next_row())) {
if (union_query->union_distinct) {
// UNION需要检查重复
if (!exists_in_tmp_table(tmp_table, row)) {
insert_into_tmp_table(tmp_table, row);
}
} else {
// UNION ALL直接插入
insert_into_tmp_table(tmp_table, row);
}
}
}
// 应用全局ORDER BY和LIMIT
if (union_query->has_order_by()) {
sort_tmp_table(tmp_table);
}
if (union_query->has_limit()) {
apply_limit_to_tmp_table(tmp_table);
}
// 返回结果
return read_from_tmp_table(tmp_table);
}大表JOIN优化场景
小表驱动大表策略失效
sql
-- 场景1:多表JOIN,无法确定最佳驱动表
EXPLAIN
SELECT *
FROM large_table l
JOIN medium_table m ON l.id = m.large_id
JOIN small_table s ON m.id = s.medium_id
WHERE l.category = 'A' AND m.status = 'active';
-- 场景2:JOIN条件包含复杂表达式
EXPLAIN
SELECT *
FROM users u
JOIN orders o ON SUBSTRING(u.email, 1, 10) = SUBSTRING(o.customer_email, 1, 10);
-- 场景3:JOIN后需要立即排序
EXPLAIN
SELECT u.name, COUNT(o.id) as order_count
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id
ORDER BY order_count DESC;JOIN优化器选择临时表
MySQL优化器可能会选择使用临时表来优化复杂JOIN:
c
// 伪代码:JOIN优化器决策过程
choose_join_strategy(JOIN *join) {
// 评估各种JOIN策略的成本
cost_nested_loops = calculate_nested_loops_cost(join);
cost_hash_join = calculate_hash_join_cost(join);
cost_tmp_table = calculate_tmp_table_cost(join);
// 考虑临时表策略的因素
if (join->need_tmp_table_for_order ||
join->need_tmp_table_for_group) {
// 如果已经需要临时表用于排序/分组,使用临时表可能更优
cost_tmp_table *= 0.8; // 折扣因子
}
// 选择成本最低的策略
return min(cost_nested_loops, cost_hash_join, cost_tmp_table);
}DISTINCT去重场景
DISTINCT工作原理
sql
-- 场景1:单列DISTINCT
EXPLAIN SELECT DISTINCT department FROM employees;
-- 场景2:多列DISTINCT
EXPLAIN SELECT DISTINCT department, job_title FROM employees;
-- 场景3:DISTINCT与聚合函数
EXPLAIN SELECT COUNT(DISTINCT department) FROM employees;
-- 场景4:DISTINCT包含复杂表达式
EXPLAIN SELECT DISTINCT CONCAT(first_name, ' ', last_name)
FROM employees;DISTINCT临时表实现
c
// 伪代码:DISTINCT使用临时表的实现
execute_distinct_with_tmp_table(THD *thd) {
// 检查是否可以使用索引去重
if (can_use_index_for_distinct(thd)) {
// 使用索引优化,避免临时表
return execute_distinct_with_index(thd);
}
// 创建临时表用于去重
tmp_table = create_tmp_table_for_distinct(thd);
// 填充临时表(自动去重)
while ((row = get_next_row(thd))) {
// 临时表的UNIQUE约束自动去重
try_insert_into_tmp_table(tmp_table, row);
// 如果重复,插入会失败,但这是预期的
}
// 从临时表读取去重后的结果
return read_from_tmp_table(tmp_table);
}手动创建临时表场景
显式临时表的应用
sql
-- 场景1:中间结果存储
CREATE TEMPORARY TABLE temp_results AS
SELECT user_id, SUM(amount) as total
FROM transactions
WHERE transaction_date >= CURDATE() - INTERVAL 30 DAY
GROUP BY user_id;
-- 然后在同一会话中使用这个临时表
SELECT u.name, tr.total
FROM users u
JOIN temp_results tr ON u.id = tr.user_id
WHERE tr.total > 1000
ORDER BY tr.total DESC;
-- 场景2:数据分步处理
-- 步骤1:创建临时表存储原始数据
CREATE TEMPORARY TABLE raw_data AS SELECT * FROM log_table WHERE date = CURDATE();
-- 步骤2:数据清洗
DELETE FROM raw_data WHERE column1 IS NULL OR column2 = '';
-- 步骤3:数据转换
UPDATE raw_data SET processed_column = UPPER(original_column);
-- 步骤4:批量插入到目标表
INSERT INTO target_table SELECT * FROM raw_data;
-- 场景3:会话级缓存
CREATE TEMPORARY TABLE session_cache (
cache_key VARCHAR(100) PRIMARY KEY,
cache_value TEXT,
expires_at TIMESTAMP
);
-- 存储会话数据
INSERT INTO session_cache VALUES ('user_preferences', '{"theme":"dark"}', NOW() + INTERVAL 1 HOUR);
-- 读取会话数据
SELECT cache_value FROM session_cache WHERE cache_key = 'user_preferences';临时表的优势深度分析
数据私有性机制
会话隔离的实现
临时表的数据私有性是通过MySQL的会话机制实现的:
c
// 伪代码:临时表的会话隔离实现
struct THD { // 线程描述符(代表一个会话)
// 会话特有的临时表列表
TABLE *temporary_tables;
// 临时表哈希表,用于快速查找
HASH temporary_table_hash;
// 其他会话信息
ulong thread_id;
// ...
};
// 创建临时表时,将其与会话关联
TABLE* create_temporary_table(THD *thd, TABLE_LIST *table_list) {
TABLE *table = create_table_object(table_list);
// 标记为临时表
table->s->tmp_table = true;
// 添加到会话的临时表列表
table->next = thd->temporary_tables;
thd->temporary_tables = table;
// 添加到哈希表
my_hash_insert(&thd->temporary_table_hash, (uchar*)table);
return table;
}
// 查找表时,优先查找临时表
TABLE* open_table(THD *thd, const char *db_name, const char *table_name) {
// 首先在会话的临时表中查找
TABLE *tmp_table = find_in_temporary_tables(thd, db_name, table_name);
if (tmp_table) {
return tmp_table;
}
// 然后在共享表缓存中查找普通表
return open_shared_table(thd, db_name, table_name);
}临时表与普通表的优先级
sql
-- 演示临时表优先级
-- 1. 创建普通表
CREATE TABLE my_table (id INT, name VARCHAR(50));
INSERT INTO my_table VALUES (1, '普通表数据');
-- 2. 在同一会话中创建同名临时表
CREATE TEMPORARY TABLE my_table (id INT, name VARCHAR(50));
INSERT INTO my_table VALUES (2, '临时表数据');
-- 3. 查询会访问临时表
SELECT * FROM my_table; -- 返回临时表数据
-- 4. 其他会话查询同名表
-- 在新会话中:
SELECT * FROM my_table; -- 返回普通表数据
-- 5. 临时表删除后,恢复访问普通表
DROP TEMPORARY TABLE my_table;
SELECT * FROM my_table; -- 返回普通表数据自动清理机制
会话结束时的清理
c
// 伪代码:会话结束时的临时表清理
void close_thread_tables(THD *thd) {
TABLE *table;
// 遍历会话的所有临时表
while ((table = thd->temporary_tables) != NULL) {
// 从列表中移除
thd->temporary_tables = table->next;
// 根据存储引擎进行清理
switch (table->s->db_type()->db_type) {
case DB_TYPE_MEMORY:
// 内存临时表:释放内存
free_memory_table(table);
break;
case DB_TYPE_INNODB:
case DB_TYPE_MYISAM:
// 磁盘临时表:删除文件
remove_disk_table_files(table);
break;
}
// 释放表对象
free_table_object(table);
}
// 清空哈希表
hash_free(&thd->temporary_table_hash);
}异常终止的清理
即使会话异常终止(如连接断开、服务器崩溃),临时表也应该被清理:
c
// 伪代码:服务器启动时的临时表清理
void cleanup_orphaned_temporary_tables() {
// 扫描临时表目录
tmp_dir = get_tmp_table_directory();
for (file in list_files(tmp_dir)) {
// 检查是否为临时表文件
if (is_temporary_table_file(file)) {
// 检查是否有会话正在使用
if (!is_file_in_use(file)) {
// 删除孤儿临时表文件
unlink(file);
}
}
}
}内存加速机制
Memory引擎的优势
Memory引擎(HEAP)是MySQL中专门为临时表设计的存储引擎:
sql
-- Memory引擎表的特性
CREATE TEMPORARY TABLE fast_temp (
id INT PRIMARY KEY,
data VARCHAR(100)
) ENGINE=MEMORY;
-- Memory引擎的优势:
-- 1. 所有数据存储在内存中
-- 2. 使用哈希索引(默认)或B树索引
-- 3. 表级锁(但锁竞争少,因为每个会话私有)
-- 4. 不支持TEXT/BLOB类型
-- 5. 不支持事务内存临时表的性能优化
c
// 伪代码:内存临时表的优化策略
TABLE* create_memory_temp_table(THD *thd, TMP_TABLE_PARAM *param) {
// 根据数据类型选择最优的行格式
if (param->all_binary) {
// 所有列都是定长,使用定长行格式
table = create_fixed_row_memory_table(thd, param);
} else {
// 包含变长列,使用动态行格式
table = create_dynamic_row_memory_table(thd, param);
}
// 根据数据量选择索引类型
estimated_rows = param->estimated_rows;
if (estimated_rows < 1000) {
// 小表使用哈希索引(更快查找)
use_hash_index(table);
} else {
// 大表使用B树索引(支持范围查询)
use_btree_index(table);
}
// 预分配内存
preallocate_memory(table, estimated_rows);
return table;
}临时表的劣势深度分析
隐式转化机制
内存到磁盘的转化条件
MySQL会在以下条件下将内存临时表转化为磁盘临时表:
sql
-- 相关配置参数
SHOW VARIABLES LIKE '%tmp_table%';
-- tmp_table_size: 内存临时表的最大大小(默认16MB)
-- max_heap_table_size: Memory引擎表的最大大小(默认16MB)
SHOW VARIABLES LIKE 'big_tables';
-- big_tables: 如果为ON,所有临时表都使用磁盘转化触发条件:
- 临时表大小超过
tmp_table_size或max_heap_table_size - 临时表包含
BLOB或TEXT列 - 查询中指定了
SQL_BIG_RESULT提示 - 表定义包含
GEOMETRY类型列
转化过程分析
c
// 伪代码:内存临时表到磁盘临时表的转化
bool convert_memory_table_to_disk(TABLE *table) {
// 检查是否需要转化
if (!need_conversion(table)) {
return false;
}
// 创建磁盘临时表
TABLE *disk_table = create_disk_temp_table(table->s->table_name);
// 复制表结构
copy_table_structure(table, disk_table);
// 复制数据
table->file->ha_rnd_init(true);
while ((error = table->file->ha_rnd_next(table->record[0])) == 0) {
// 写入磁盘表
disk_table->file->ha_write_row(table->record[0]);
}
// 关闭原表
table->file->ha_rnd_end();
// 替换表对象
replace_table_in_thd(table->in_use, table, disk_table);
// 释放原内存表
free_memory_table(table);
return true;
}性能影响分析
sql
-- 监控临时表转化
-- 查看状态变量
SHOW STATUS LIKE 'Created_tmp%tables';
/*
Created_tmp_tables: 创建的临时表总数
Created_tmp_disk_tables: 创建的磁盘临时表数
Created_tmp_files: 临时文件数
*/
-- 计算转化率
SELECT
Variable_name,
Variable_value as count,
CASE
WHEN Variable_name = 'Created_tmp_disk_tables' THEN
ROUND(Variable_value /
(SELECT Variable_value
FROM performance_schema.global_status
WHERE Variable_name = 'Created_tmp_tables') * 100, 2)
ELSE 0
END as disk_percentage
FROM performance_schema.global_status
WHERE Variable_name IN ('Created_tmp_tables', 'Created_tmp_disk_tables');
-- 临时表转化率是重要的性能指标
-- 高转化率意味着需要优化查询或调整配置大查询的资源消耗
临时表文件系统影响
磁盘临时表在文件系统中的表现:
bash
# 查看临时表文件位置
mysql> SELECT @@tmpdir;
+-------------------+
| @@tmpdir |
+-------------------+
| /tmp/mysql/ |
+-------------------+
# 临时表文件命名模式
# SQL_XXXX_XX.ibd # InnoDB临时表空间文件
# SQL_XXXX_XX.MYD # MyISAM数据文件
# SQL_XXXX_XX.MYI # MyISAM索引文件
# 监控临时文件使用
lsof | grep mysql | grep /tmp | wc -l
df -h /tmp # 查看临时目录空间使用资源消耗案例分析
sql
-- 危险查询示例:大表分组排序
EXPLAIN ANALYZE
SELECT user_id, COUNT(*) as cnt
FROM huge_log_table
WHERE log_date > '2023-01-01'
GROUP BY user_id
ORDER BY cnt DESC
LIMIT 100;
-- 问题分析:
-- 1. 需要扫描整个大表(IO压力)
-- 2. 无法使用索引进行分组(临时表)
-- 3. 排序需要额外临时表
-- 4. 可能超过内存限制,转化为磁盘临时表
-- 资源消耗:
-- 假设表有10亿行,平均行大小200字节
-- 临时表大小 ≈ 10亿 * (用户ID大小 + 计数大小) ≈ 20GB
-- 如果tmp_table_size=16MB,必然转化为磁盘临时表
-- 磁盘IO压力极大,可能耗尽临时目录空间系统崩溃风险
c
// 伪代码:临时表资源耗尽的风险
void create_tmp_table_file(const char *filename) {
// 尝试创建临时文件
fd = open(filename, O_RDWR | O_CREAT | O_EXCL, 0600);
if (fd < 0) {
if (errno == ENOSPC) {
// 磁盘空间不足
error_message = "磁盘空间不足,无法创建临时表";
log_error(error_message);
// 尝试清理旧的临时文件
cleanup_old_temp_files();
// 重试
fd = open(filename, O_RDWR | O_CREAT | O_EXCL, 0600);
if (fd < 0) {
// 仍然失败,抛出错误
throw_disk_full_error();
}
} else if (errno == EMFILE || errno == ENFILE) {
// 文件描述符耗尽
error_message = "文件描述符耗尽";
log_error(error_message);
// 这可能导致MySQL崩溃
handle_fatal_error();
}
}
return fd;
}复制环境中的危险场景
DROP TEMPORARY TABLE的复制问题
这是MySQL复制中一个极其危险的问题,下面详细分析其机制:
sql
-- 危险操作序列:
-- 主库执行:
CREATE TEMPORARY TABLE temp_data (id INT);
INSERT INTO temp_data VALUES (1), (2), (3);
DROP TEMPORARY TABLE temp_data;
-- 从库复制线程重放这些语句
-- 正常情况下没有问题
-- 但是,如果从库复制线程重启:
-- 1. 重启前:已执行CREATE TEMPORARY TABLE和INSERT
-- 2. 重启后:临时表已不存在(会话级)
-- 3. 继续重放:执行DROP TEMPORARY TABLE temp_data
-- 4. 危险:如果从库存在名为temp_data的普通表,可能会被误删!问题根源分析
这个问题的根源在于MySQL的复制机制和临时表的会话特性:
c
// 伪代码:复制线程处理临时表的逻辑
void handle_temporary_table_in_replication(THD *thd, Log_event *event) {
if (event->get_type_code() == CREATE_TMP_TABLE_EVENT) {
// 创建临时表
execute_create_temporary_table(thd, event);
// 记录到线程的临时表列表
add_to_slave_temp_table_list(thd, event->table_name);
} else if (event->get_type_code() == DROP_TMP_TABLE_EVENT) {
// 检查临时表是否存在
if (is_in_slave_temp_table_list(thd, event->table_name)) {
// 临时表存在,正常删除
execute_drop_temporary_table(thd, event);
// 从列表中移除
remove_from_slave_temp_table_list(thd, event->table_name);
} else {
// 临时表不存在!这是危险情况
// MySQL 5.6之前的行为:尝试删除
// 这可能删除同名的普通表
// MySQL 5.6及之后:安全检查
if (slave_check_temp_table_name(event->table_name)) {
// 如果是明显的临时表名格式,忽略
log_warning("临时表不存在,忽略DROP TEMPORARY TABLE");
} else {
// 可能是普通表,需要特别处理
handle_potential_dangerous_drop(thd, event);
}
}
}
}不同MySQL版本的行为
| MySQL版本 | DROP TEMPORARY TABLE行为 | 风险等级 |
|---|---|---|
| < 5.6.0 | 可能删除同名普通表 | 高 |
| 5.6.0-5.6.10 | 添加安全检查,但仍有漏洞 | 中 |
| 5.6.11+ | 改进的安全检查 | 低 |
| 8.0+ | 更强的保护机制 | 很低 |
复制线程重启的详细场景
c
// 伪代码:复制线程重启过程
void slave_sql_thread_restart() {
// 步骤1:清理原线程状态
cleanup_old_thread_resources();
// 步骤2:临时表丢失!
// 所有会话级临时表都消失了
// 步骤3:重新读取中继日志
start_processing_relay_log();
// 步骤4:遇到DROP TEMPORARY TABLE语句
// 临时表已不存在,但语句仍需执行
// 旧版本MySQL:直接执行,可能删除普通表
// 新版本MySQL:检查表名格式
if (table_name_looks_like_temp_table(event->table_name)) {
// 看起来像临时表,安全忽略
log_warning_and_continue();
} else {
// 看起来像普通表,需要谨慎
// 检查是否真的存在这个普通表
if (check_if_table_exists(event->table_name)) {
// 存在普通表,停止复制并报错
stop_slave_with_error("可能误删普通表");
} else {
// 不存在,安全忽略
log_warning_and_continue();
}
}
}防御措施与最佳实践
sql
-- 1. 升级到MySQL 5.6.11或更高版本
-- 这些版本有更好的临时表复制保护
-- 2. 使用行格式复制(RBR)
-- 行格式复制不记录临时表的创建和删除
SET GLOBAL binlog_format = 'ROW';
-- 3. 避免在复制环境中使用临时表名与普通表名相同
-- 临时表命名规范:添加前缀
CREATE TEMPORARY TABLE tmp_users (...); -- 好
CREATE TEMPORARY TABLE users (...); -- 危险
-- 4. 监控复制错误
SHOW SLAVE STATUS\G
-- 关注:Last_Error, Last_Errno, Slave_SQL_Running
-- 5. 定期检查并清理无用的临时表
-- 在从库上检查是否有孤儿临时表文件
-- 6. 使用复制过滤器避免问题
-- 在从库上过滤掉临时表相关操作
CHANGE REPLICATION FILTER REPLICATE_IGNORE_TABLE = ('test.temp_%');
-- 7. 备份重要表
-- 定期备份可能被误删的表紧急恢复方案
如果发生了误删表的情况:
sql
-- 1. 立即停止复制
STOP SLAVE;
-- 2. 检查误删了哪些表
-- 查看错误日志
SHOW SLAVE STATUS\G
-- 查看Last_Error字段
-- 3. 从备份恢复被误删的表
-- 如果有备份,直接恢复
-- 4. 如果没有备份,尝试从磁盘恢复
-- 使用数据恢复工具,如:
-- - Percona Data Recovery Tool for InnoDB
-- - MySQL Data Recovery Toolkit
-- 5. 跳过错误的复制事件
-- 确定错误事件的position
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1;
START SLAVE;
-- 6. 重新配置复制以避免未来问题
-- 升级MySQL版本
-- 更改为行格式复制
-- 设置复制过滤器临时表的最佳实践
配置优化
sql
-- 1. 合理设置临时表大小
-- 根据系统内存调整
SET GLOBAL tmp_table_size = 64 * 1024 * 1024; -- 64MB
SET GLOBAL max_heap_table_size = 64 * 1024 * 1024; -- 64MB
-- 2. 为临时表使用专用磁盘
-- 在my.cnf中配置
[mysqld]
tmpdir = /mnt/ssd/tmp -- 使用SSD提高IO性能
-- 3. 监控临时表使用
-- 定期检查状态变量
SELECT * FROM sys.session
WHERE tmp_tables > 0 OR tmp_disk_tables > 0;
-- 4. 优化查询以减少临时表
-- 添加合适的索引
-- 改写复杂查询查询优化技巧
sql
-- 1. 避免不必要的临时表
-- 使用索引优化排序和分组
ALTER TABLE orders ADD INDEX idx_user_date (user_id, order_date);
-- 2. 限制结果集大小
-- 尽早使用WHERE条件过滤
SELECT * FROM large_table
WHERE date = CURDATE() -- 先过滤
ORDER BY id;
-- 3. 使用覆盖索引
-- 避免回表操作
EXPLAIN SELECT user_id, COUNT(*)
FROM orders
WHERE status = 'completed'
GROUP BY user_id;
-- 确保有(user_id, status)的复合索引
-- 4. 分阶段处理大数据集
-- 使用分页或分区
SELECT * FROM huge_table
ORDER BY id
LIMIT 10000 OFFSET 0; -- 分批处理
-- 5. 使用物化视图(MySQL 8.0+)
CREATE TABLE order_summary (
user_id INT,
order_count INT,
total_amount DECIMAL(10,2),
PRIMARY KEY (user_id)
);
-- 定期更新汇总表临时表设计模式
sql
-- 1. 临时表命名规范
-- 使用统一前缀
CREATE TEMPORARY TABLE tmp_report_data (...);
CREATE TEMPORARY TABLE tmp_session_cache (...);
-- 2. 显式指定存储引擎
-- 根据数据特性选择
CREATE TEMPORARY TABLE fast_cache (
id INT PRIMARY KEY,
data VARCHAR(100)
) ENGINE=MEMORY; -- 小数据,频繁访问
CREATE TEMPORARY TABLE large_temp (
id BIGINT PRIMARY KEY,
content TEXT,
created_at DATETIME
) ENGINE=InnoDB; -- 大数据,需要事务支持
-- 3. 合理设计表结构
-- 避免不必要的BLOB/TEXT列
-- 使用适当的索引
-- 4. 及时清理临时表
-- 不再使用时立即删除
DROP TEMPORARY TABLE IF EXISTS tmp_report_data;总结
临时表是MySQL中一个强大但危险的工具。正确使用时,它可以显著提高查询性能;使用不当,则可能导致性能问题甚至数据丢失。
关键要点:
- 了解临时表的产生场景:排序、分组、UNION、派生表等操作可能隐式创建临时表
- 监控临时表使用:关注Created_tmp_disk_tables状态变量,优化高转化率的查询
- 配置合理的参数:根据系统资源设置tmp_table_size和max_heap_table_size
- 注意复制环境的风险:DROP TEMPORARY TABLE可能导致从库误删普通表
- 遵循最佳实践:合理命名、及时清理、优化查询设计
临时表是MySQL工具箱中的重要组成部分,理解其工作原理和潜在风险,可以帮助我们更好地利用这一工具,构建高性能、高可靠的数据库应用。