快速了解部分
基础信息(英文):
- 题目: ActiveVLA: Injecting Active Perception into Vision-Language-Action Models for Precise 3D Robotic Manipulation
- 时间: 2026.01
- 机构: Fudan University, Shanghai Innovation Institute, Nanyang Technological University
- 3个英文关键词: Vision-Language-Action (VLA), Active Perception, 3D Robotic Manipulation
1句话通俗总结本文干了什么事情
本文提出了一种名为 ActiveVLA 的新框架,让机器人不再被动地"看"世界,而是能像人一样主动调整视角和焦距,从而在杂乱或有遮挡的环境中精准完成复杂的操作任务。
研究痛点:现有研究不足 / 要解决的具体问题
现有的 VLA(视觉-语言-动作)模型大多依赖固定的、腕部摄像机提供的 2D 视角,无法在执行任务时根据需要动态调整观察角度或分辨率。这种被动感知导致机器人在面对长程任务、精细操作或严重遮挡(Occlusion)时,因无法获取关键细节而失败。
核心方法:关键技术、模型或研究设计(简要)
该研究设计了一个"由粗到精"的主动感知框架:首先通过多视角投影定位关键 3D 区域,然后利用主动视角选择(避开遮挡)和主动 3D 变焦(放大细节)来优化视觉输入,最后结合 VLM(视觉语言模型)预测精确的动作。
深入了解部分
相比前人创新在哪里
前人工作主要集中在被动感知(固定摄像头)或 2D 图像处理。本文的创新在于引入了**主动感知(Active Perception)**机制,赋予机器人动态调整"视线"的能力(即选择最佳观测点和变焦),将 3D 场景理解与 VLM 结合,解决了遮挡和细节丢失问题。
解决方法/算法的通俗解释
想象一个新手厨师在杂乱的厨房里找东西。传统机器人就像被蒙住一只眼且头不能动的人,只能凭有限的视野乱摸。ActiveVLA 则像是一个聪明的学徒,它会先扫视全局(粗阶段),然后主动把头凑近橱柜里看清楚(主动视角选择),甚至眯着眼睛放大看那个被挡住一半的苹果柄(主动 3D 变焦),确认抓哪里最稳,最后才伸手去拿。
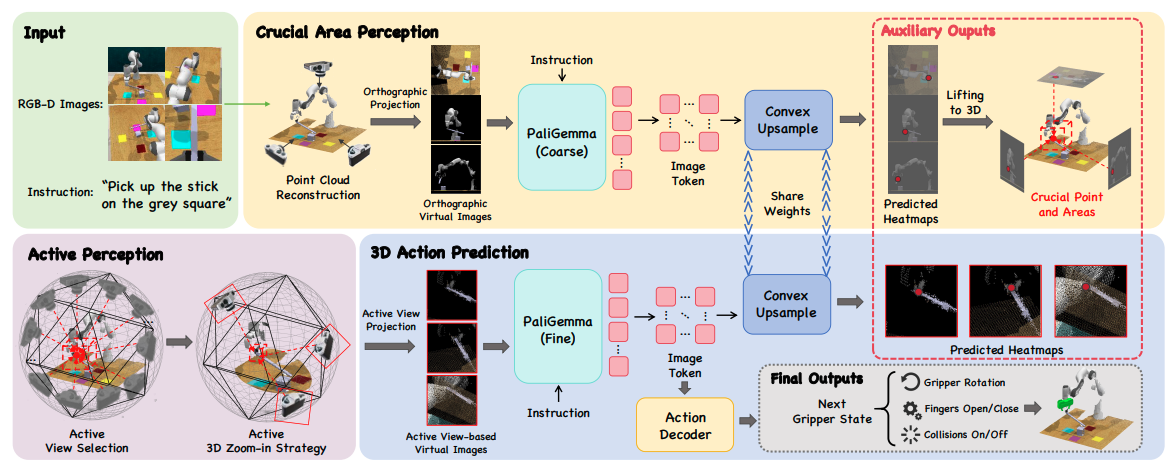
解决方法的具体做法
- 3D 关键区域感知(粗阶段):利用 RGB-D 图像重建点云,通过正交投影生成多视角 2D 图像,输入 VLM 预测关键区域热力图,反投影回 3D 空间定位目标。
- 主动视角选择:围绕目标区域生成候选相机位姿,通过评分函数(考虑可见性、距离、多样性)筛选出能避开遮挡、视野最好的几个视角。
- 主动 3D 变焦:对选定的关键区域进行虚拟"光学变焦"(缩小视场角),在不损失分辨率的情况下放大局部细节,辅助精细操作。
- 3D 动作预测:将优化后的视图输入 VLM 生成热力图,结合全局与局部特征预测机器人的 6D 位姿和夹爪动作。
基于前人的哪些方法
该研究基于预训练的 PaliGemma (作为 VLM Backbone)和 SigLIP (视觉编码器),并借鉴了 BridgeVLA 的架构思想(如输入输出对齐),在此基础上增加了 3D 主动感知模块。
实验设置、数据、评估方式、结论
- 设置与数据:在 RLBench、COLOSSEUM 和 GemBench 三个模拟基准及真实机器人(Franka Panda)上进行评估。
- 评估方式:任务成功率(Success Rate, SR)、平均排名(Avg. Rank)。
- 结论:ActiveVLA 在 RLBench 上达到 91.8% 的平均成功率(优于 SOTA),在 COLOSSEUM 和 GemBench 上也表现最佳。真实场景实验显示,面对严重遮挡(如从层层叠叠的抽屉中取毛巾、从杂乱水果中拿香蕉),其成功率显著高于基线模型(如 RVT-2 和 BridgeVLA)。
提到的同类工作
- BridgeVLA:基于 PaliGemma 的 VLA 模型,本文的基础对齐方法来源。
- RVT / RVT-2:基于粗到精 Transformer 的 3D 操控策略,本文的主要对比基线之一。
- PerAct:基于点云的粗到精抓取方法,本文的对比基线之一。
- Act3D:利用 3D 特征场进行动作选择的模型,本文的对比基线之一。
和本文相关性最高的3个文献
- BridgeVLA:本文直接采用了其预训练权重和部分架构设计,是本文方法的基础。
- RVT-2:代表了当前基于粗到精 3D 视觉的 SOTA 水平,是本文主要超越的对比对象。
- PaliGemma:本文使用的 VLM 主干网络,其强大的视觉语言能力是实现复杂指令操控的前提。
我的
- 热力图 GT label是自动标注的,而非人标。在Simulator里可以得到Object的点云,对应投影后就是label。