
✨道路是曲折的,前途是光明的!
📝 专注C/C++、Linux编程与人工智能领域,分享学习笔记!
🌟 感谢各位小伙伴的长期陪伴与支持,欢迎文末添加好友一起交流!

- 前言
- 一、宏观认识
- [二、Block Group内部构成](#二、Block Group内部构成)
- [三、inode 与 数据块的关联逻辑](#三、inode 与 数据块的关联逻辑)
-
- [3.1 基础关联](#3.1 基础关联)
- [3.2 索引机制](#3.2 索引机制)
- [3.3 跨分区问题](#3.3 跨分区问题)
- [3.4 虚拟文件系统到物理地址的访问](#3.4 虚拟文件系统到物理地址的访问)
- [3.5 思考](#3.5 思考)
- 四、从文件系统底层理解Linux文件的增删查改
-
- [4.1 新建文件](#4.1 新建文件)
- [4.2 删除文件](#4.2 删除文件)
- [4.3 查找文件](#4.3 查找文件)
- [4.4 修改文件](#4.4 修改文件)
- [4.5 核心补充](#4.5 核心补充)
-
- [4.5.1 目录的本质](#4.5.1 目录的本质)
- [4.5.2 Linux的文件寻址逻辑](#4.5.2 Linux的文件寻址逻辑)
- [4.5.3 思考](#4.5.3 思考)
- [4.6 总结](#4.6 总结)
前言
在上一节中,我们留下了两个未解之谜:
- 问题一:块是如何在分区上排布的?我们该如何高效地找到目标块?
- 问题二:inode又存放在分区的什么位置?
其实,这两个问题的答案都指向同一个核心概念------文件系统。
还记得我们在 inode 结构定义中看到的 ext2_inode 吗?这个 ext2 就是我们要介绍的第一个真正意义上的 Linux 文件系统------Ext2(Second Extended File System)。
Ext2 的历史地位:
- 1993年由Rémy Card设计开发
- 是Linux历史上第一个高性能的文件系统
- 虽然现在已被Ext3/Ext4取代,但其核心设计思想影响深远
一、宏观认识
为了方便理解,前文将 LBA 地址直接对应到扇区进行讲解。但在虚拟文件系统(VFS)的视角下,磁盘的最小管理单位并非扇区,而是块(Block)。通常一个块大小为 4KB,由多个连续扇区组成(8个)。以块为单位访问磁盘,不仅能一次性读写更多数据,还能利用数据的局部性原理提前缓存相关数据,从而显著提高内存缓存命中率和操作系统的整体效率。
例如我们面对 800GB 这样庞大的磁盘空间,直接管理非常困难,因此我们采用分层抽象与间接管理的策略,这与行政区域的划分逻辑类似:
- 磁盘抽象与分区(Partition):
首先,我们将物理上由多个盘面组成的磁盘抽象为一个线性的 LBA 地址空间。接着,借鉴"国家分省"的思路,将 800GB 空间逻辑划分为若干分区(例如一个 200GB 的分区)。- 实现方式: 使用
partition结构体记录每个分区的起始和结束 LBA 地址(整数),并通过part结构体集合来管理所有分区。
- 实现方式: 使用
plain
struct partion{
int begin;
int end;
}
struct partion part[]注意: 分区仅是逻辑划分,不改变物理盘面结构,底层仍通过 LBA 转换为 CHS 地址访问物理扇区。
- 块组划分(Block Group):
即便 200GB 的分区,直接管理依然复杂。我们继续沿用"分治"思想,将其细分为更小的单元(例如 20 个 10GB 的组)。只要掌握了管理一个 10GB 组的方法,就能复制该逻辑管理其余 19 个组,进而管理整个分区,最终实现对 800GB 磁盘的全盘管理。 - 文件系统介入:
当空间被细化到 10GB 的块组级别后,如何具体管理这些块组内的文件、目录和空闲空间?这就需要引入具体的文件系统实现,在 Linux 中,这正是 ext2 文件系统 发挥作用的地方。
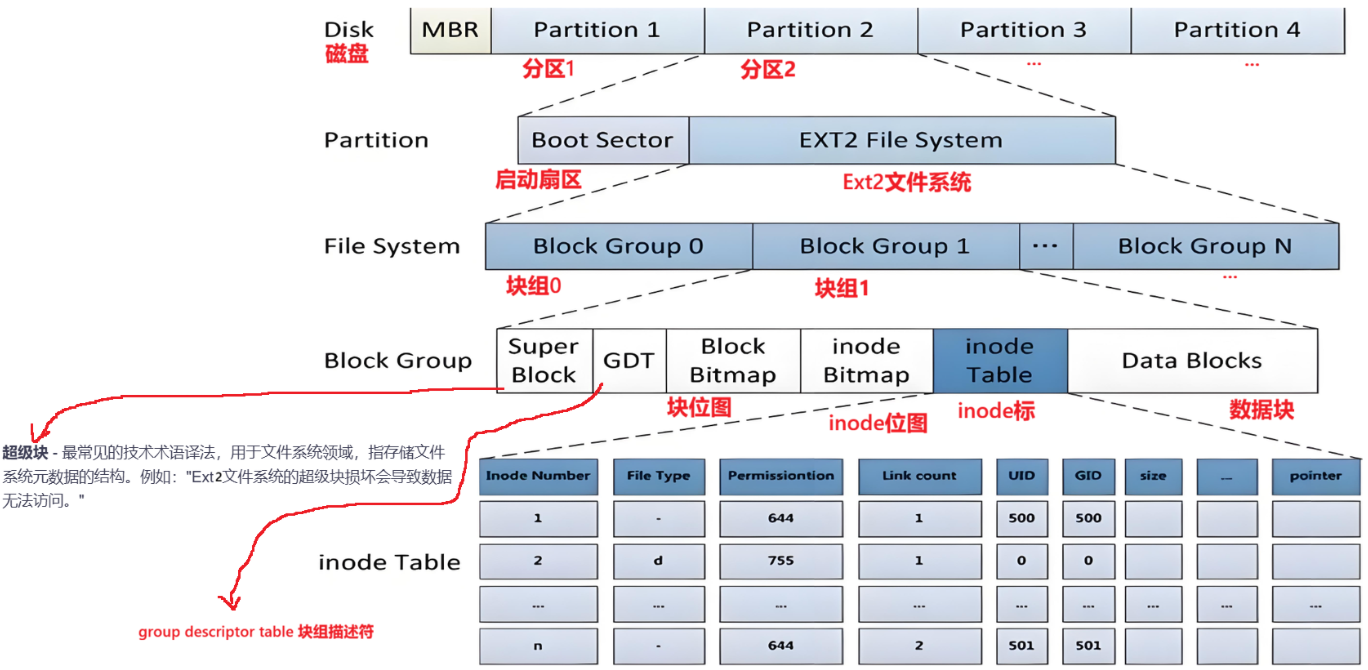
- 在硬盘上存储文件前,必须先将其格式化为某种文件系统,以便系统组织和管理文件。
- 在 Linux 系统中,最常见的是 ext2 系列文件系统,包括早期的 ext2 以及后来的 ext3 和 ext4。
- 尽管 ext3 和 ext4 在功能上有所增强,但它们的核心设计仍基于 ext2,因此我们以 ext2 为例进行说明。
- ext2 文件系统将整个分区划分为若干大小相同的块组(Block Group)。只要掌握了单个块组的管理方式,就可以管理整个分区,从而实现对磁盘上所有文件的统一管理。
注意 :上图中的启动块(Boot Block/Sector)的大小是确定的为1KB。由PC标准规定,用来储存磁盘分区信息和启动信息,任何文件系统都不能修改启动块,启动块之后才是Ext2文件系统的开始。
二、Block Group内部构成
我们上面说到Ext2文件系统会根据分区的大小划分为数个Block Group,且每个块组内的结构组成相同,所以我们管理好了一个块组就能管理好其他块组。那我们就来看看他的内部结构究竟是如何组成的?
- 超级块(Super Block)
- 超级块(Super Block)是文件系统的核心元数据区域,主要存储整个分区级别的文件系统结构信息,包括:分区总容量、空闲块(block)和空闲索引节点(inode)的数量、文件系统最近一次写入数据的时间、最近一次磁盘检测的时间等关键信息。一旦超级块损坏,整个文件系统的结构会被破坏,无法正常工作。
为了提高容错性,超级块会在每个块组的起始位置保留一份完整拷贝(第一个块组的超级块为核心副本)。这一设计能应对磁盘部分扇区出现物理故障的情况 ------ 即便核心超级块所在区域损坏,系统仍可读取其他块组中备份的超级块信息,保证文件系统正常访问。因此,文件系统需要始终维护所有块组中超级块区域的数据一致性,避免因副本数据不一致导致的管理异常。
- GDT(Group Descriptor Table)
- 块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。
- 每个块组描述符存储⼀个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。
- 块组描述符在每个块组的开头都有⼀份拷贝。
- 块位图(Block Bitmap)
Block Bitmap(块位图)是文件系统中管理数据块(Data Block)分配 / 释放的核心元数据结构,本质是一串二进制位(bit),通过每 1 个 bit 映射 1 个 Data Block的方式,用极简的空间记录所有数据块的占用状态(是否被占用),是文件系统实现高效块管理的基础方案。
- inode位图(Inode Bitmap)
每个bit表示一个inode是否空闲可用
- i节点表(Inode Table)
- 存放文件属性,如文件大小,所有者,最近修改时间等
- 当前分组所有Inode属性的集合
- inode编号以分区为单位,整体划分,不可跨分区
- Data Block
数据区:存放文件内容,也就是一个一个的Block。根据不同的文件类型有以下几种情况:
- 对于普通文件,文件的数据存储在数据块中。
- 对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls -l命令看到的其它信息保存在该文件的inode中。
- Block 号按照分区内的编号规则进行统一分配,编号从0开始依次递增,每个Block对应唯一的编号,且该编号仅在所属分区内有效,不可跨分区。
三、inode 与 数据块的关联逻辑
Linux系统中,文件在磁盘上采用属性与数据分离存储的设计;但二者并非独立存在,必然需要建立专属的关联机制------这正是inode与数据块之间核心关联逻辑的设计初衷,接下来我们就来拆解这份关联的实现原理。
3.1 基础关联
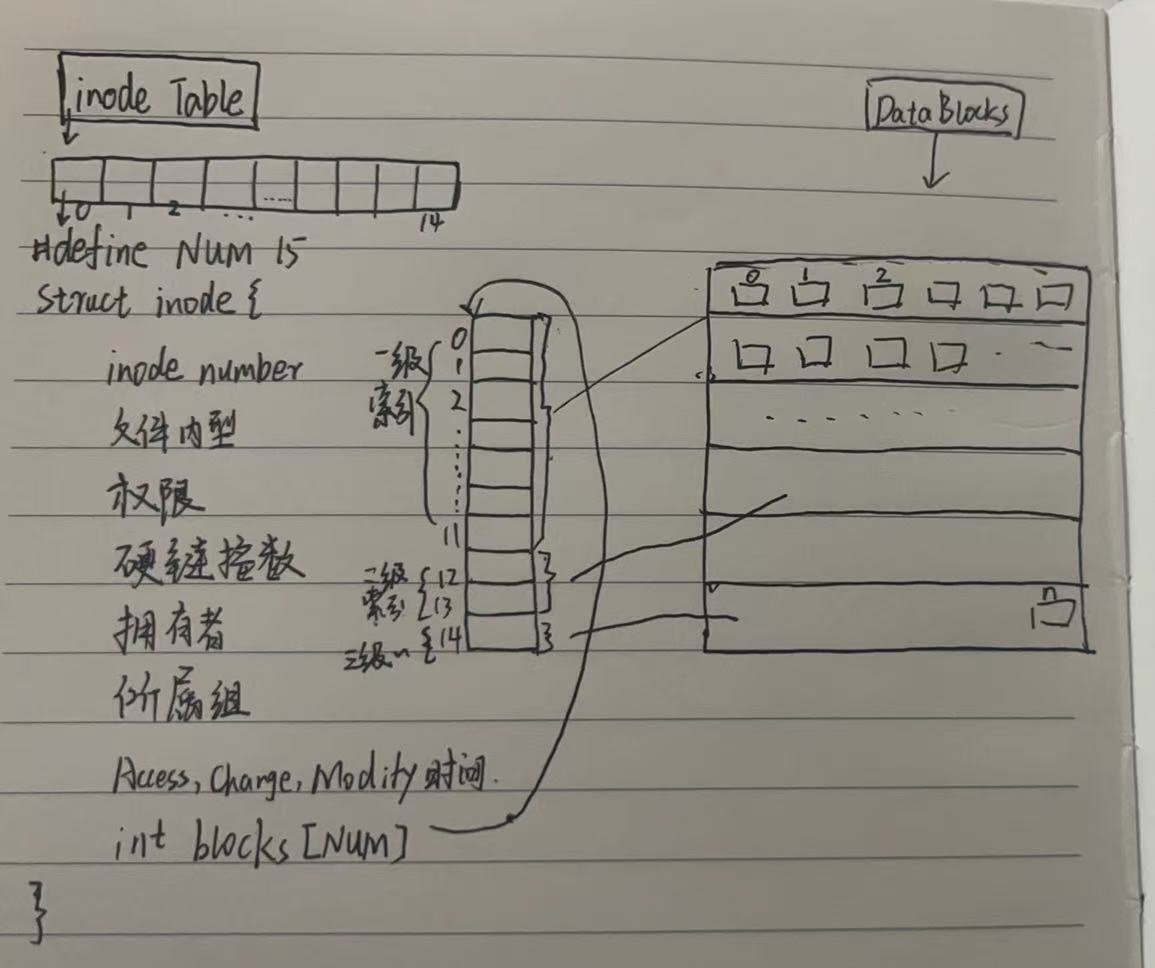
- 数据块的全局统一编号 :一个磁盘分区内,所有块组的 Data Block 会进行整体连续编号,从 0 开始到 n 结束,0 对应第一个块组的第一个数据块,n 对应最后一个块组的最后一个数据块。每个数据块大小固定(通常为 4KB),且只有唯一编号,本身无任何 "自主属性",仅作为纯数据存储载体,等待 inode 的索引调度。
- inode 的核心桥梁作用 :inode 表中存储着一个个 inode 结构体(固定 128 字节),每个 inode 对应一个文件,包含文件的所有属性 (大小、所有者、修改时间等)和唯一 inode 编号 (分区内唯一,跨分区可重复)。而 inode 结构体中最关键的,是一个包含 15 个元素的数据块编号数组------ 这是 inode 与数据块建立关联的直接入口,文件的所有数据块编号,都通过这个数组被索引和管理。
3.2 索引机制
inode 中的数据块编号数组共 15 个下标(0-14),被划分为直接索引 、二级索引 、三级索引三个部分,逐级解决大文件的存储问题,每一级索引的设计,都是为了突破上一级的存储容量限制,我们以 4KB 数据块、4 字节数据块编号(整数型)为基础,拆解每一级的索引逻辑和存储能力。
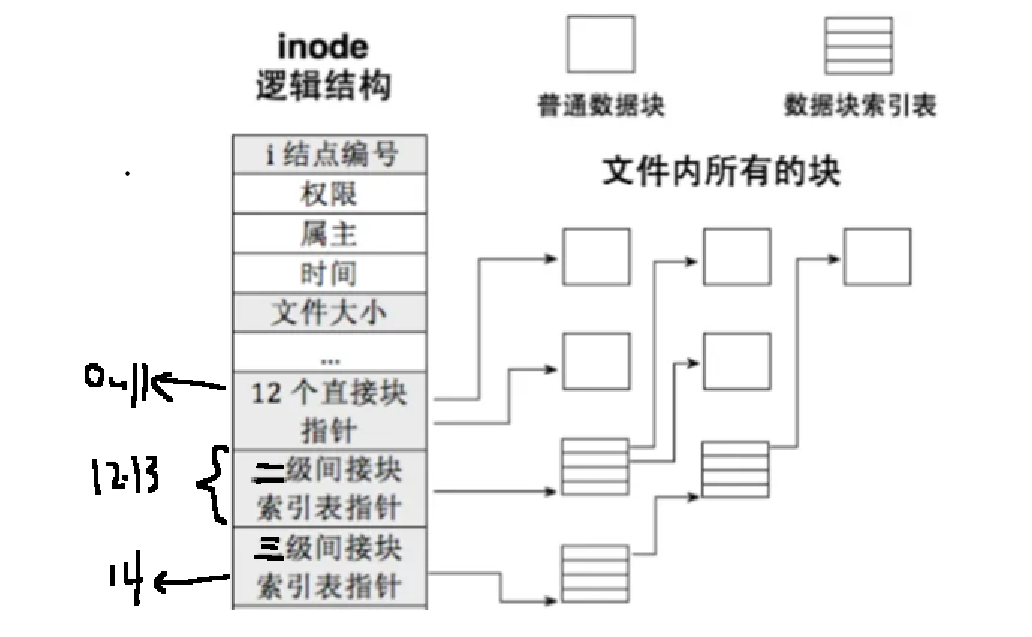
- 直接索引:下标 0-11,小文件的快速访问
数组下标 0 到 11,共 12 个位置为直接索引,这是最基础、最高效的索引方式:
- 直接索引的数组位置中,直接存储文件实际数据块的编号,无需中间层转发;
- 访问时,通过 inode 直接拿到数据块编号,一步定位到存储文件内容的 Data Block,耗时最短。
- 存储容量:12 个数据块 × 4KB / 块 = 48KB,满足绝大多数小文件的存储需求。
- 二级索引:下标 12-13,突破小文件容量限制
当文件大小超过 48KB,直接索引的 12 个数据块存满时,二级索引开始发挥作用,对应数组下标 12、13 两个位置:
- 二级索引的数组位置中,不直接存储文件数据块编号 ,而是存储 "存储了数据块编号的中间数据块编号"------ 简单说,就是用一个数据块当 "索引块",专门存实际数据块的编号,再将这个索引块的编号存在 inode 的二级索引位置。
- 存储能力计算:单个 4KB 的索引块,可存储的数块编号数为 4KB/4 字节 = 1024 个;一个二级索引位置对应 1 个索引块,可管理 1024×4KB=4MB 的文件空间;两个二级索引位置则可管理 2×4MB=8MB 的文件空间。

二级索引通过 "一次中转",将文件存储能力从 48KB 提升到了 8MB+48KB,满足中等大小文件的存储需求。
- 三级索引:下标 14,索引之王,支撑超大文件存储
当文件大小超过 8MB+48KB,二级索引也无法满足时,三级索引作为最终解决方案登场,仅对应数组下标 14 这一个位置:
- 三级索引是 "二次中转" 的索引方式,其数组位置中存储的,是 "存储了二级索引块编号的中间索引块编号"------ 即三级索引的索引块存二级索引块的编号,二级索引块再存实际数据块的编号,层层递进找到文件数据。
- 存储能力计算:单个 4KB 的三级索引块,可存储 1024 个二级索引块的编号;而一个二级索引块可管理 4MB 文件空间,因此单个三级索引可管理 1024×4MB=4GB 的文件空间。
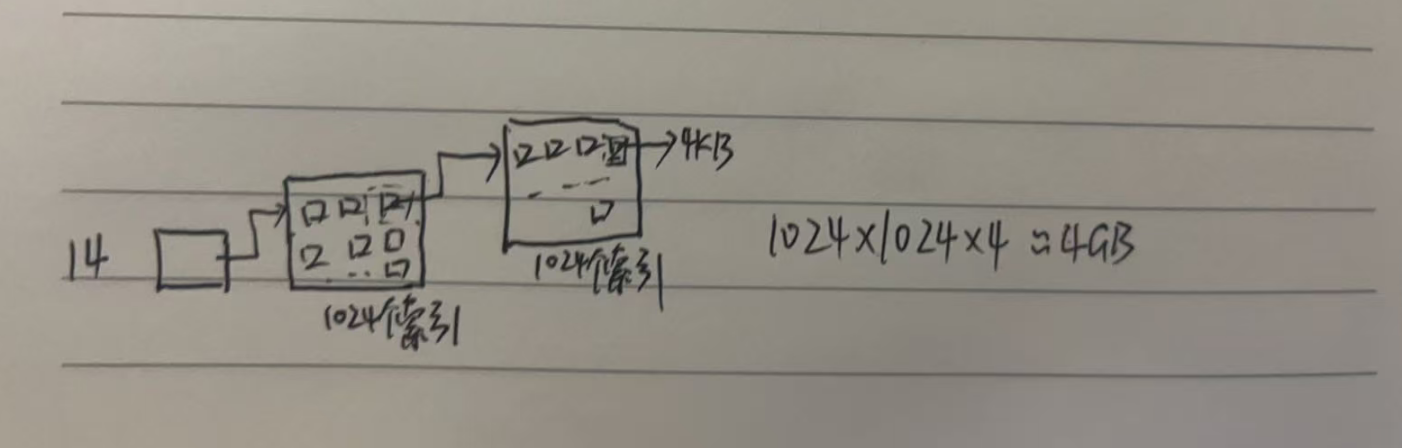
4GB 的存储容量,足以覆盖绝大多数超大文件的存储需求,这也是为什么 Linux 文件系统中,单个文件的存储能力能达到数 GB 的核心原因。
综上,一个 inode 通过三级索引机制,最大可管理的文件空间为:48KB(直接)+8MB(二级)+4GB(三级),完全满足日常各类文件的存储需求。
3.3 跨分区问题
我们知道,inode 编号以分区为单位划分 ,仅在所属分区内唯一,不同分区的 inode 编号大概率会出现重复,那 Linux 是如何区分不同分区中相同编号的 inode 呢?
答案很简单:通过文件路径区分。
- 这和 Windows 的磁盘分区逻辑类似 ------Windows 将磁盘划分为 C、D、E 盘,本质是对物理磁盘的分区划分,不同分区通过盘符路径区分;Linux 没有盘符的概念,而是通过虚拟文件系统的挂载路径实现分区区分,将不同的磁盘分区挂载到虚拟文件系统的不同目录下,形成统一的文件路径体系。
- 无论哪个分区的文件,最终都会有一个唯一的绝对路径,Linux 通过这个路径先定位到文件所属的分区,再在该分区内通过 inode 编号找到对应的 inode 结构体,后续再通过 inode 的索引机制访问数据块。路径成为了跨分区识别 inode 的 "唯一标识",从根本上解决了 inode 编号重复的问题。
3.4 虚拟文件系统到物理地址的访问
以上我们讲的 inode、数据块、索引机制,都是Linux 虚拟文件系统(VFS) 层面的抽象结构,而文件的实际属性(inode 内容)和实际内容(数据块内容),最终都要存储在物理磁盘(SSD / 机械硬盘)上,这中间的桥梁,就是LBA 地址 和CHS 地址的转换:
- LBA 地址的统一映射 :物理磁盘会被划分为一个个固定大小的块(与文件系统的 4KB 数据块对应也就是8个扇区),每个块都有唯一的LBA(逻辑块地址),VFS 层面的 inode 和数据块,都会被映射到磁盘的某个 LBA 地址范围内,即 inode 表和数据区都有对应的 LBA 地址。
- LBA 转 CHS:物理地址寻址 :LBA 是磁盘的逻辑地址,而磁盘的物理访问需要CHS 地址(盘面 - 磁道 - 扇区)。当 Linux 通过 VFS 拿到 inode 和数据块的 LBA 地址后,会将该地址交给磁盘的地址寄存器,由磁盘控制器通过专属算法,将 LBA 地址转换为对应的 CHS 物理地址,最终定位到磁盘的指定盘面、磁道、扇区,读取或写入实际数据。
简单来说,VFS 层面的 inode 和数据块是 "逻辑抽象",LBA 地址是 "逻辑与物理的桥梁",CHS 地址是 "物理访问的最终入口",三者结合,实现了从文件路径到磁盘物理数据的完整访问链路。
3.5 思考
- 面对数量众多的数据块,如何判断其占用状态?
答案就是Block Bitmap(数据块位图)------位图中比特位的位置与数据块编号一一对应,比特位的值则直接标识对应数据块是否被占用。
同理 ,inode编号的数量同样庞大,要判断某个inode是否有效可用,只需依靠inode Bitmap(inode位图):位图的比特位位置与inode编号精准映射,通过比特位的值就能确定对应inode是否有效,若有效则可直接到inode表中找到该inode进行访问。
- 那删除文件时,是否需要将inode的文件属性重置、把数据块的内容清空?
其实完全没必要。因为文件属性和数据的写入均采用覆盖写 机制,后续新数据会直接覆盖原有内容,无需额外做清空操作。而标识文件被删除的核心方法,只需从管理层面入手:由于位图中
1代表占用/有效、0代表空闲/无效,只需将该文件对应的inode位图比特位、以及所有数据块对应的Block Bitmap比特位统一置0,即可完成文件的删除操作。
注意: 我们初次使用磁盘时,磁盘上无任何文件,自然也没有对应的文件属性和数据,此时虚拟文件系统中的inode位图和Block Bitmap会全部置0,同时超级块、块组描述符表的相关信息也需要完成初始化配置。因此,任何分区在投入使用前,都必须完成格式化初始化:通过LBA地址映射为CHS物理地址,将文件系统的这些基础元数据,提前写入磁盘对应的盘面、磁道和扇区中,为后续分区的块组分隔、正常使用做好准备。
四、从文件系统底层理解Linux文件的增删查改
在Linux文件系统中,文件的增、删、查、改 本质上不是对"文件"本身的直接操作,而是围绕inode、位图(inode Bitmap/Block Bitmap)、数据块三大核心的状态更新与关联操作;用户层面看到的文件名,最终也会被操作系统转化为inode编号,再基于inode完成所有底层动作。以下从底层逻辑拆解文件增删查改时,系统的具体执行流程,同时补充编号分配规则与文件名的底层映射逻辑。
4.1 新建文件
新建文件的核心是为文件分配专属inode和数据块(有内容时),并通过位图标记资源占用、建立inode与数据块的关联,具体步骤:
- 分配并激活inode :系统从inode位图中找到最小的空闲inode编号(位图对应位为0),为文件分配该inode,用于记录文件的所有属性(大小、所有者、创建时间等);同时将inode位图中该编号对应的比特位置为1,标记此inode已被占用。
- 分配数据块(文件有内容时) :根据文件内容的实际大小,从Block Bitmap中找到对应数量的最小空闲数据块编号,将文件内容写入这些数据块;并将Block Bitmap中这些数据块编号对应的比特位置为1,标记数据块已被占用。
- 建立inode与数据块的关联 :将已分配的数据块编号,依次填入该文件inode结构体中的数据块编号数组,让inode能精准找到存储文件内容的所有数据块。
- 无内容文件:若新建的是空文件,仅执行第一步(分配并激活inode)即可,无需分配数据块,inode的数据块编号数组也无有效内容。
4.2 删除文件
Linux删除文件的核心是释放inode和数据块资源,而非清空inode属性或数据块内容,具体步骤:
- 标记资源空闲 :找到待删除文件的inode编号,将inode位图 中该编号对应的比特位置为0,标记此inode变为空闲;同时找到该文件占用的所有数据块编号,将Block Bitmap中这些编号对应的比特位全部置为0,标记数据块变为空闲。
- 无需清空数据 :由于Linux对文件属性和内容的写入均采用覆盖写机制,后续新建文件时,新的inode属性和数据会直接覆盖原有内容,因此无需额外清空inode和数据块中的旧数据,大幅提升删除效率。
- 资源可复用:被标记为空闲的inode和数据块,会进入系统的空闲资源池,后续新建文件时,系统可重新分配这些编号的inode和数据块。
4.3 查找文件
查找文件的核心是通过inode编号验证资源有效性,并基于inode获取文件属性和内容 ,由于inode结构体中不存储文件名,因此系统底层从不通过文件名查找文件,具体步骤:
- 获取inode编号 :操作系统先将用户输入的文件名转化为对应的inode编号(底层通过目录实现,后文详解)。
- 验证inode有效性:根据inode编号,查看inode位图中对应位的状态:若为0,说明该inode未被占用,文件不存在,查找流程终止;若为1,说明文件存在,继续下一步。
- 获取文件属性:根据inode编号,在对应块组的inode表中找到该inode结构体,直接读取其中记录的所有文件属性。
- 读取文件内容 :遍历该inode结构体中的数据块编号数组,根据数组中的数据块编号,找到对应的所有数据块,依次读取数据块中的内容,拼接后即为文件的完整内容。
4.4 修改文件
修改文件的前提是确认文件存在 ,核心是按需更新inode属性或数据块内容,若内容扩容,还需额外分配数据块,具体步骤:
- 验证文件存在:执行与"查找文件"完全相同的流程,通过inode编号验证文件有效性,仅当文件存在时,才能进行后续修改操作。
- 修改文件属性:若仅修改文件属性(如修改所有者、修改文件权限),直接在对应的inode结构体中,更新相关属性字段即可,无需操作数据块。
- 修改文件内容 :
- 内容覆盖(大小不变):根据inode的数据块编号数组,找到存储文件内容的所有数据块,直接覆盖写入新内容即可,无需分配新数据块。
- 内容扩容(大小增加):从Block Bitmap中找到最小的空闲数据块,将新增内容写入新数据块,标记数据块为占用,并将新数据块编号填入inode的数据块编号数组;若直接索引满,则自动启用二级/三级索引。
- 内容缩容(大小减少):将不再使用的冗余数据块编号从inode的数据块编号数组中移除,并将Block Bitmap中这些数据块对应的比特位置为0,释放空闲数据块。
4.5 核心补充
在Linux"一切皆文件"的设计理念下,目录并非独立于文件的特殊存在,而是一种存储"文件名-inode编号映射关系"的特殊文件。它和普通文件一样遵循「文件=属性+内容」的核心结构,却承担着整个文件系统的"导航定位"作用------Linux所有文件的寻址、访问,本质都是通过目录的映射关系层层实现的,同时目录的读、写、执行权限,也直接决定了对其下文件的操作能力。下面从目录本质、寻址逻辑、经典问题解析三个维度,彻底讲透目录的核心原理。
4.5.1 目录的本质
既然目录是文件,那它就拥有普通文件的所有基础特征,同时又有专属的内容存储规则,核心特征可总结为两点:
- 和普通文件一致:有属性,有数据块
用ls -l -i查看目录时,能看到其专属的inode编号,这说明目录有自己的inode结构体,存储着所有者、权限、修改时间等文件属性;作为有内容的文件,目录也会分配专属的数据块,用于存储自身的"文件内容"。

- 专属内容规则:存储"文件名-inode编号"的映射关系
目录的数据块中,不会存储普通文件的实际内容,而是专门存放当前目录下所有文件/子目录的"文件名"与"对应inode编号"的键值对 。这是目录的核心价值,也是Linux通过文件名找到文件实际存储位置的关键------文件名对系统底层无实际意义,仅作为inode编号的"用户层别名",而目录就是这份别名与实际标识的"映射表"。
简单来说,目录的核心作用就是提供文件名到inode编号的转换能力,没有目录的映射,用户无法通过易记的文件名访问文件,只能直接使用晦涩的inode编号。
4.5.2 Linux的文件寻址逻辑
当我们想要访问某个文件(如/home/test/file.txt)时,系统需要通过目录的映射关系找到目标文件的inode编号,这个过程看似是"向下遍历目录",实则是从当前路径向上递归到根目录,再从根目录向下递归找到目标 的过程,整个逻辑依托Linux文件系统的多叉树结构实现,核心步骤与设计细节如下:
- 寻址的核心前提:根目录是所有递归的起点
Linux虚拟文件系统的所有文件/目录,都以/ 根目录为根节点形成多叉树,根目录是整个文件系统的"起点",没有上级目录,因此无需向上递归。为了固化这一起点,大多数Linux文件系统会将 根目录的inode编号固定为2,用
stat /即可验证,这一固定设计是整个寻址逻辑的基础。
- 完整寻址流程:先向上递归找根,再向下递归找目标
以"访问当前目录下的test.txt文件"为例,系统的完整寻址过程如下:
① 向上递归到根目录 :要找到当前目录下test.txt的映射关系,需先拿到当前目录的inode编号;而当前目录的inode编号,需要到其上级目录 的映射关系中查找;上级目录的inode编号,又需要到上上级目录 中查找......以此类推,直到递归到根目录(inode=2),向上递归终止。
② 从根目录向下递归 :拿到根目录的inode编号后,到对应块组的inode表中找到根目录的inode结构体,遍历其中的数据块编号数组,访问根目录的数据块(即根目录的映射表),找到根目录下下一级目录的"文件名-inode编号"映射,拿到对应inode编号;再通过该inode编号访问下一级目录的映射表,依次向下遍历,直到找到当前目录 的inode编号。
③ 访问目标文件的映射关系:拿到当前目录的inode编号后,访问其数据块中的映射表,根据目标文件名test.txt,匹配到对应的inode编号;最终通过该inode编号,即可访问目标文件的属性和实际内容。
- 性能优化:缓存常用的路径映射关系
上述"先向上、再向下"的递归过程,需要多次与磁盘进行IO交互,而磁盘作为外设,访问效率远低于内存。为了提升文件寻址效率,Linux系统会做路径缓存优化 :将用户经常访问的文件/目录路径上的"文件名-inode编号"映射关系,提前缓存到内存中。
这样一来,第一次访问某路径时,仍需执行完整的磁盘递归寻址;但后续再次访问该路径时,系统可直接从内存缓存中读取映射关系,无需再与磁盘交互,大幅提升访存和存取效率。
4.5.3 思考
理解了目录的"特殊文件本质"和"映射表核心作用",再来看Linux中关于目录的经典权限、规则问题,就会变得通俗易懂,核心逻辑均围绕目录的映射表访问、写入 ,以及权限对操作的限制展开:
- 为什么同一个目录下,不能有同名文件?
- 核心原因:目录的数据块是"文件名-inode编号"的键值对映射表 ,遵循一个key对应一个value的基本规则。
- 如果同一个目录下出现两个同名文件,就会出现一个文件名(key)对应多个inode编号(value) 的情况,系统无法通过文件名准确匹配到唯一的inode编号,也就无法正常寻址和访问文件。
- 【例外】硬链接是特殊情况:多个不同的文件名,可映射到同一个inode编号,这是硬链接的核心设计,与"同名文件冲突"并不矛盾。(之后会讲解)
- 当前目录没有w(写)权限,为什么无法创建文件?
- 创建文件的核心步骤之一:将新文件的"文件名-inode编号"映射关系,写入当前目录的数据块(映射表)中。
- 如果当前目录没有w写权限,系统就无法对其数据块执行写入操作,新文件的映射关系无法被存储;而没有映射关系,用户就无法通过文件名找到新文件的inode编号,相当于新文件无法被"注册"到文件系统中,因此自然无法创建。
- 当前目录没有r(读)权限,为什么无法查看目录下的文件?
- 查看目录下的文件,本质是读取目录数据块中的"文件名-inode编号"映射表,再将文件名展示给用户。
- 如果当前目录没有r读权限,系统就无法读取其inode结构体中的数据块编号数组,也无法遍历数据块访问映射表;无法获取映射表中的文件名,自然也就无法查看目录下的文件列表。
- 前目录没有x(可执行)权限,为什么无法cd进入该目录?
- 目录的x可执行权限,并非表示"执行目录"(目录无法被执行),而是 "进入目录并访问其下文件/子目录映射关系" 的权限,更底层的逻辑是:
- 没有x权限,系统将无法修改环境变量PWD中的当前工作路径 ,也无法通过该目录的inode编号,访问其数据块中的映射表;路径无法切换,且无法获取目录内的映射关系,因此
cd进入目录的操作会被禁止。
4.6 总结
- inode是文件的"唯一标识" :Linux中一个文件对应一个唯一的inode,inode编号以分区为单位分配,跨分区可重复,操作系统通过inode编号区分不同文件,而非文件名。
- 位图是资源的"状态管家":inode Bitmap和Block Bitmap仅通过0/1标记资源的空闲/占用状态,是系统快速分配、释放资源的基础,保证了资源操作的高效性。
- 数据块是内容的"存储载体":仅用于存储文件的实际内容,无任何自主属性,完全由inode通过数据块编号数组调度。
- 文件名是"用户层别名":对操作系统底层无实际意义,仅为方便用户使用,最终会被转化为inode编号,再完成所有操作。
简单来说,Linux文件系统的所有操作,最终都可以归结为**"通过文件名找inode,通过inode找数据块,通过位图管理资源"**,理解这一逻辑,就理解了Linux文件操作的底层本质。
✍️ 坚持用 清晰易懂的图解 + 可落地的代码,让每个知识点都 简单直观!
💡 座右铭 :"道路是曲折的,前途是光明的!"
