Argo CD 它不只是"自动部署",而是把集群交付这件事管得更像个系统
很多人第一次接触 Argo CD,都会被一句话打动:"Git 一提交,集群自动同步。"
听起来很爽,但真上生产你肯定会追问:它凭什么敢自动?谁在盯着偏差?出了事故怎么回滚?谁有权限动哪个集群?
把这些问题讲清楚,才算真正理解 Argo CD。它的架构其实不复杂,只是分工很明确------有人负责"接待",有人负责"拿清单",有人负责"执行",还有人负责"展示"。
Argo CD 本质在做一件事------让集群永远追上 Git
Argo CD 的核心理念就是 GitOps:
Git 里那份配置是"期望状态",集群里跑的东西是"实际状态"。两者不一致就要纠正。
你可以把它想象成一条橡皮筋:集群跑偏了,就会被拉回到 Git 对应的样子。那这个"拉回去"的动作,到底是谁在做?靠的就是下面这些组件。
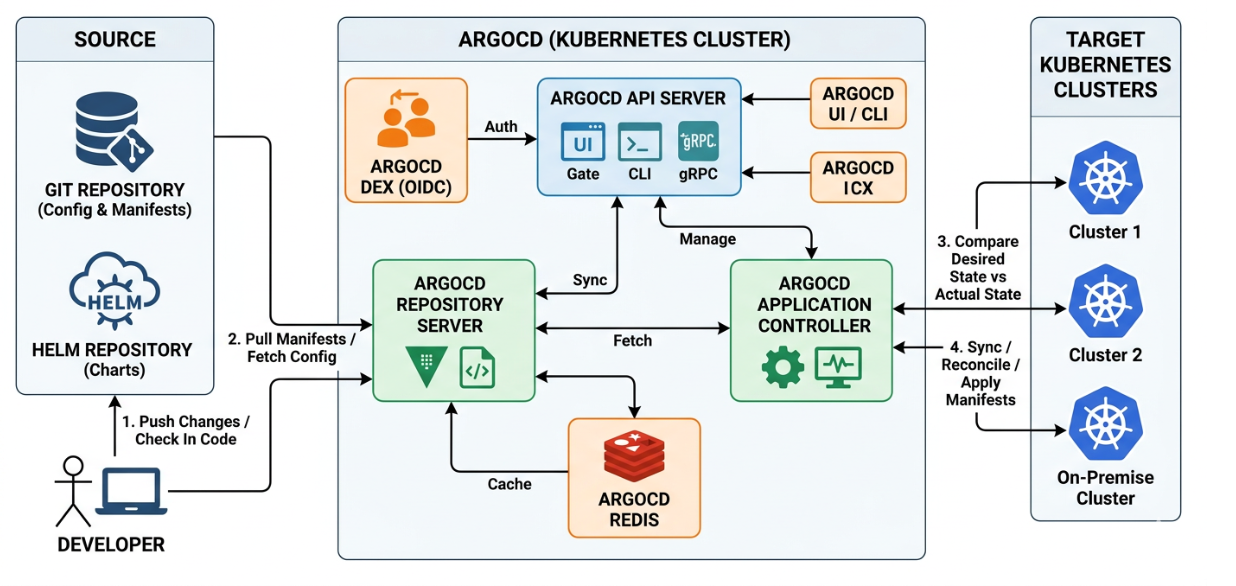
API Server:所有操作的总入口,也是权限的第一道门
不管你是点 Web UI,还是用 argocd CLI,甚至你接入 SSO 登录,本质上都是在跟 API Server 打交道。
它负责的事情很像"前台 + 安保 + 调度中心":
-
谁能登录?(SSO / token / 本地账号)
-
谁能做什么?(RBAC 权限控制)
-
你点了 Sync/回滚/查看 diff,这些请求先到它这里
-
再把指令交给后面的执行者去处理
所以你可以这么理解:
API Server 不直接部署资源,但没有它,你也没法安全地控制 Argo CD。
毕竟谁都能随便一键 Sync,那还得了?
Repo Server:专门负责"拉代码、算清单"的组件
Repo Server 的定位非常明确:它不直接碰集群,它只负责把 Git 里的东西变成最终可下发的 manifests。
它常干的活包括:
-
拉取 Git 仓库(或者 Helm chart 仓库)
-
执行 Helm template、Kustomize build 等渲染
-
处理多源仓库、插件渲染等
-
把"最终要部署的 YAML"交给后面的控制器
很多人会忽略这一点:
Argo CD 并不是把你仓库里的 YAML 原封不动丢进集群。
像 Helm/Kustomize 这种"需要生成清单"的玩法,Repo Server 才是关键角色。
总而言之:Repo Server 负责把 Git 里的"素材"加工成"成品"。
Application Controller:真正的执行者,负责比对差异 + 同步落地
如果说 Repo Server 负责出"成品清单",那 Application Controller 就负责把"成品"真正落到集群里,并且持续盯着状态。
它干的事情就是 Argo CD 的核心价值所在:
-
从 Repo Server 拿到 manifests(期望状态)
-
去集群里读取当前资源(实际状态)
-
做 diff:看哪里不一致、谁多了谁少了、谁被改了
-
执行 Sync:apply/patch/prune,把集群拉回到 Git
-
判断健康状态:Healthy / Degraded / Progressing
-
管理历史版本:支持回滚到某个 revision
所以你可以这样讲清楚它的作用:
Controller 是那个"盯着集群别跑偏"的人,也是那个"亲手把变更推上去"的人。
UI:它不是发动机,但它是驾驶舱
很多人觉得 UI 只是"好看",但在生产环境里,UI 的价值非常实在:
-
一眼看出哪些应用 OutOfSync(偏离 Git)
-
看到 diff(到底差在哪里)
-
看到资源树(哪些 Deployment/Service/ConfigMap 属于这个应用)
-
手动 Sync/回滚/暂停自动同步
-
观察健康状态和事件
如果你在排障时只靠 kubectl,你会发现很容易迷路;而 UI 把"应用视角"拉得很完整。
所以它不是可有可无,而是把可观测性做得更贴近交付流程。
Redis(常见但不是必需):负责缓存,让系统更顺滑
不少生产环境会给 Argo CD 配 Redis。原因很简单:规模大了以后,频繁 diff、频繁查询状态、频繁刷新 UI,会带来不小压力。
Redis 通常用于:
-
缓存应用状态/计算结果
-
提升 API 响应速度
-
减少重复计算与请求压力
你可以把它理解成:
不是核心逻辑的一部分,但能让 Argo CD 跑得更稳、更快。
Application / AppProject:真正决定"谁能部署到哪里"的治理核心
很多人把注意力都放在组件上,但实际用起来最容易出问题的,往往是"边界没划清"。
-
Application:描述"我要把哪个仓库的哪一段配置,部署到哪个集群、哪个 namespace,用什么同步策略"
-
AppProject:描述"一个项目允许用哪些仓库、允许部署到哪些集群/namespace、允许哪些资源类型"
这俩对象的意义是:
把权限从'人'下沉到'项目边界',避免一个应用部署到不该去的地方。
你想想,如果一个开发同学误把测试配置同步到生产集群,真的只是"手滑"吗?更多时候是边界没收好。
把整套架构串起来:一次 Git 变更到底怎么走完闭环?
写博客时,你可以用这种"流水线"描述,让读者一眼懂:
-
Git 仓库变更发生
-
Repo Server 拉代码并渲染出最终 manifests
-
Controller 把 manifests 与集群实际状态做 diff
-
不一致就触发同步(自动或手动),apply/prune 把集群拉回 Git
-
API Server/UI 展示同步结果、diff、健康状态、历史版本
-
出问题就回滚到某个历史 revision,让集群回到那一刻
这就是 Argo CD 的厉害之处:
不仅能部署,还能持续校验、持续纠偏、全程可追溯。
它们各自的定位非常"像团队分工"
-
API Server:入口、认证鉴权、权限控制、调度请求
-
Repo Server:拉仓库、渲染生成 manifests
-
Application Controller:对比差异、执行同步、维护健康状态与历史
-
UI:可视化与操作入口(驾驶舱)
-
Redis(常见):缓存加速
-
Application / AppProject:应用定义与治理边界(决定谁能部署到哪)
核心:
Repo Server 负责"算出应该部署什么",Controller 负责"让集群变成那样",API Server/UI 负责"让人能管得住、看得清"。