1 回忆Transformer
在开始学习BERT之前,我们来简要回顾一下Transformer模型。
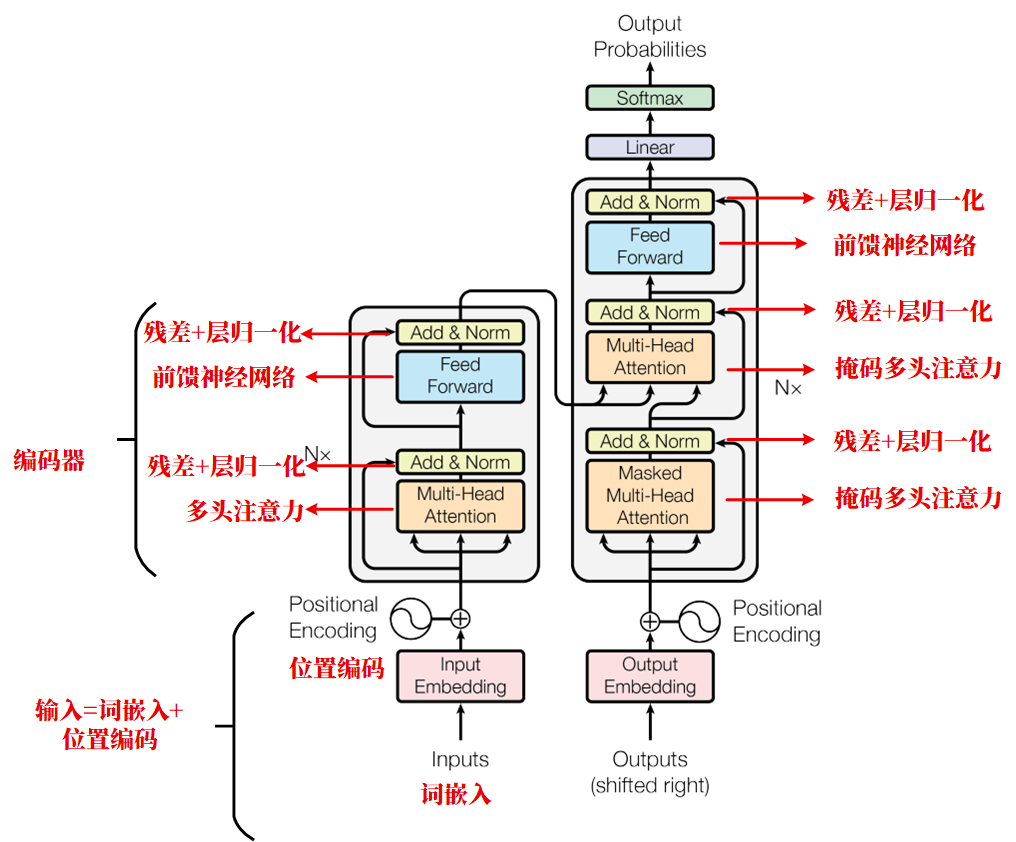
1.1 Transformer的输入
我们需要将输入转化为模型可以理解的数学形式。具体过程为: 首先将单词或者句子转换为一个固定维度的向量,得到词嵌入,这个过程采用的方法有比如Word2Ved、Glove等。
由于Transformer已经摈弃了RNN和LSTM的顺序输入,因此输入的位置信息需要采用位置编码引入。位置编码包含了序列的绝对或者相对信息。
最终的输入由词嵌入+位置编码,最终输入至模型中进行训练。
1.2 Transformer模型结构
Transformer模型的组成主要包括两部分:
编码器(Encoder)和解码器(Decoder)。Transformer模型本质上是多个相同的编码器和解码器的堆叠。
编码器主要包含多头注意机制、残差连接、层归一化以及前馈神经网络。
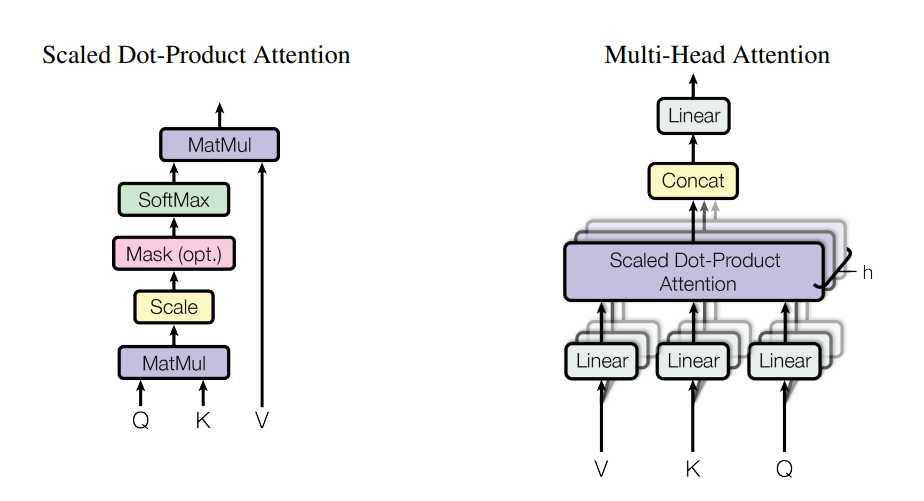
1、多头注意力机制用来对输入序列自身进行注意力计算,以获取到输入序列中不同单词的相关性。
2、残差连接将注意力层的输出和原始输出数据进行相加,避免网络过深梯度消失的问题。
3、层归一化对单个样本的特征进行标准化,使其均值为0,方差为1,使得数据训练更加稳定。
4、再经过以上三个步骤后,输入来到第二个前馈神经网络层,这层网络其实就是最简单的人工神经网络,计算单元是由多个神经元组成的,这些神经元依据权重和偏置进行连接。
每个神经元接收来自上一层神经元的输入,然后通过激活函数进行处理,最后将结果传递给下一层神经元。
5、在经过前馈神经网络后,再次进行残差连接和层归一化,完成一个编码器的步骤。
解码器与编码器不同的地方在于注意力为掩码多头注意力。掩码多头注意力与全局自注意力的不同之处在于在对序列中位置的处理上(掩码操作)。
其余的比如残差连接、层归一化以及前馈神经网络与编码器是类似的,只不过解码器的连接方式和输入与编码器略有不同。
在经过编码器和解码器的计算之后,经由全连接层和softmax得到模型的预测。
2 BERT模型架构
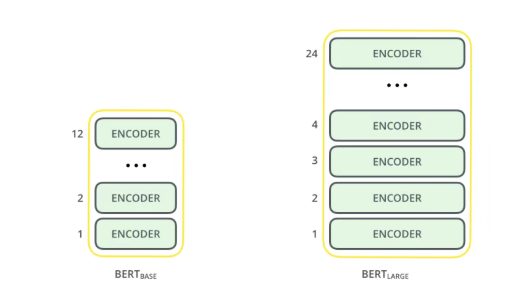
BERT架构源于Transformer,但是在Transformer模型的基础上进行了关键改造。BERT完全舍弃了Transformer中Decoder的设计,只保留了Encoder,并且BERT拥有两个版本:
-
BERT-Base:12层Transformer编码器,12个注意力头,隐藏层维度768,约1.1亿参数。
-
BERT-Large:24层Transformer编码器,16个注意力头,隐藏层维度1024,约3.4亿参数。

以上两种BERT模型的规模是不同的,但是均有大量的Encoder层,Base版本有12层 Encoder,Large 版本有 20 层 Encoder。
除此之外,BERT模型与Transformer相比,前馈神经网络的复杂度更高,Base版本有768个隐藏层单元,Large版本有1024个隐藏层单元。
并且拥有更多的注意力头数(分别有12个和16个),超过了Transformer的默认配置参数(论文中有 6个Encoder, 512个隐藏层单元和8个注意力头)。
它们的训练数据来源于BooksCorpus(包含上千本未出版的儿童图书)和英文维基百科,分别包含8亿个和25亿个单词,总共包含33亿个单词。
3 BERT的输入
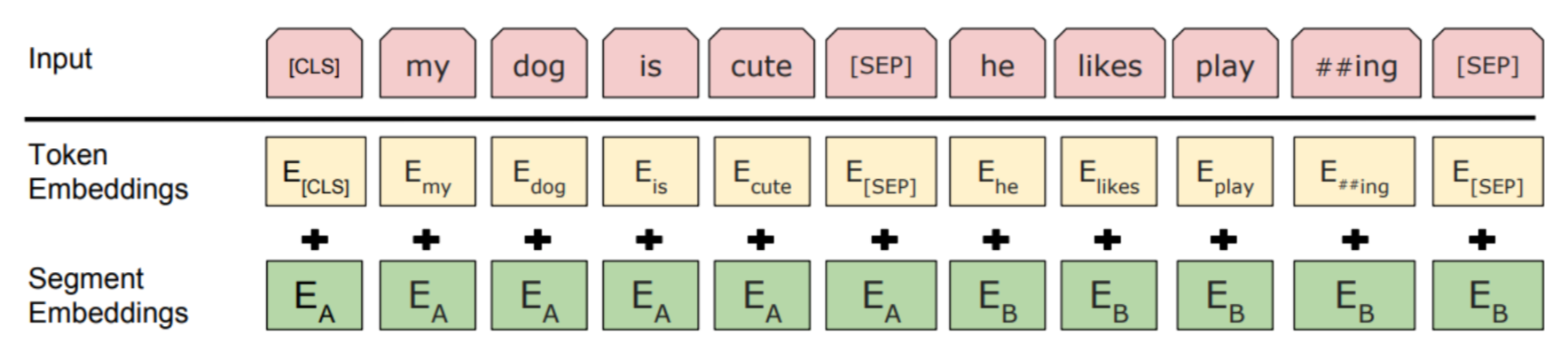
我们首先来理解一下一句完整的句子是怎么进行分词的。 比如有一句话:"my dog is cute,he likes playing.",当我们采用WordPiece分词器来进行分词时,会得到如下结果:
Tokens =\[CLS my dog is cute SEP he likes play ##ing SEP]。
这个结果是怎么得到的呢?
BERT的词汇表中共有30000个标记,我们首先检查每个单词在词汇表中是否存在,如果存在,我们则标记这个单词,如果不存在,我们便拆分为字词,然后检查字词是否存在于词汇表中。
比如playing被拆分为##play和##ing,得到结果:
Tokens =my dog is cute he likes play ##ing。
在Tokens =my dog is cute he likes play ##ing的基础上,我们增加CLS和SEP到句子的结尾,得到最终的输入:
Tokens =\[CLS my dog is cute SEP he likes play ##ing SEP]。

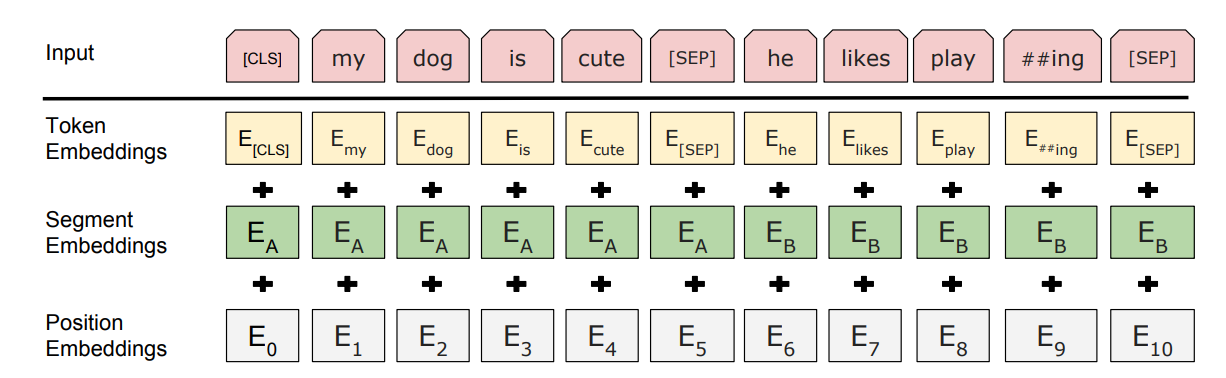
在把数据输入至BERT模型之前,针对输入,我们还要通过3个嵌入层将其转化为嵌入向量,这3个嵌入层分别是:
- 标记嵌入(Token embedding)
我们在对语句进行分词拆解后,并且增加了CLS和SEP标记,此时我们采用标记嵌入的嵌入层将以上数据转化为嵌入向量,重点在于这些嵌入向量的值是在训练过程中不断学习的,比如我们的输入:
Tokens =\[CLS my dog is cute SEP he likes play ##ing SEP]; 它的标记嵌入为:

- 片段嵌入(Segment embedding)
片段嵌入从字面理解就是用来表征片段信息的,比如my dog is cute,he likes playing.这句话其实是由两个分句组成的包括my dog is cute和he likes playing。
片段嵌入便只返回两种嵌入EA或者EB,如果标记属于A就标记到EA,反之标记到EB,如下图所示:
- 位置嵌入(Position embedding)
由于Transformer摈弃了RNN以及LSTM的结构,在Transformer的输入是加入了位置编码的。因此在BERT中成为了位置嵌入。
我们将\[CLS my dog is cute SEP he likes play ##ing SEP]分别标记为E0、E1、E2......E10。
至此我们从输入得到了标记嵌入、片段嵌入以及位置嵌入,将对应的嵌入相加,就得到了BERT的输入表示:
4 BERT的预训练和微调
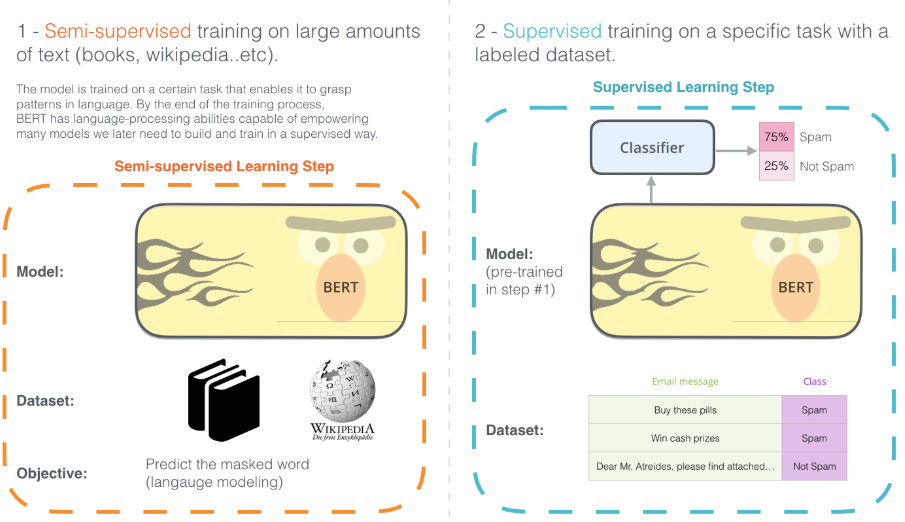
4.1 BERT预训练
BERT预训练主要分为两点:
- 屏蔽语言建模
- 下一句预测
我们说的简单一些,所谓的屏蔽语言建模其实就是将模型的输入序列随机选择一些单词,将其替换为特殊标记MASK,而模型需要预测出这些被掩盖的单词。
所以也有一种说法是BERT其实是完形填空,这种做法有利于增强模型的理解能力。
那么下一句预测是什么呢?
在某一个任务中,我们有两个句子A和B,模型需要预测B是否是A的直接后续。这种操作增强了模型理解句子之间关系的能力,比如在问答系统中十分重要。
4.2 BERT微调
微调就是Fine-tuning,在迁移学习中尤为常见。BERT的微调训练主要分为两步:
-
构建语言大模型,采用大量的训练数据A无监督来进行训练;
-
在预训练好的语言模型基础上,采用下游任务的训练数据B来进行有监督的训练。一般会在模型的后面加一层全连接层或者直接加上softmax来进行分类。也有其他的做法,比如在大语言模型之后加上TextCNN或者DPCNN等。本质上是利用了预训练语言模型提取出的高级特征。
4.3 BERT下游任务
依据下游任务输入和输出的形式,微调支持的下游任务主要分为四类:
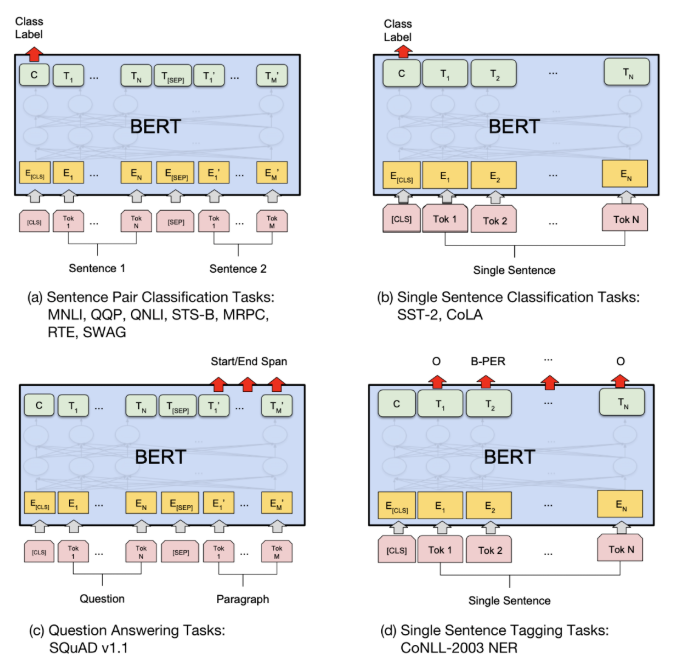
句对分类
给定两个句子,判断它们的关系。这其实是在做文本匹配,例如判断两个句子是否相似、判断后者是否为前者的答案。
单句分类:
给定一个句子,判断该句子的类别。常见的任务有情感识别、判断语句是否连贯等。
文本问答
给定一个问句和一个蕴包含答案的句子,找出答案在后句的位置。例如给定一个问题(句子 A),在给定的段落(句子 B)中标注答案的起始位置和终止位置。
单句标注
给定一个句子,标注每个词的标签。例如给定一个句子,标注句子中的人名、地名和机构名。其实就是命名体识别。
5 小结
我们通过回忆Transformer的结构,了解了BERT的结构。然后讨论了BERT的输入,如何通过标记嵌入、片段嵌入和位置嵌入,最终相加,得到最终模型的输入。然后简要介绍了BERT的预训练和微调。
事实上,BERT的预训练非常复杂,远不止只言片语可以说清楚,其中预言建模类型就有好几种,比如自回归语言建模和自编码语言建模。而自回归语言建模又分为前向预测和反向预测。
通过各种机制的结合,BERT可以同时学习到词语层面的上下文理解能力以及句子间层面的关系理解能力,结合预训练和微调,BERT能够灵活适应各种下游任务,在NLP中拥有重要的地位。
欢迎大家关注我的gzh:阿龙AI日记。