目录
摘要:本文深入浅出地介绍了循环神经网络(RNN)的核心原理、它在处理序列数据时遇到的"长期依赖"问题,并详细阐述了长短时记忆网络(LSTM)如何通过精巧的门控机制来解决这一局限。文章结构清晰,适合初学者理解RNN与LSTM的基础知识。
一、为什么需要RNN?传统神经网络的痛点
在处理文本、语音等序列数据时,传统神经网络(如全连接网络)存在两个主要缺陷:
-
无法捕捉顺序依赖:它将输入视为独立的点,忽略了词语间的上下文逻辑(例如,无法根据"编程"和"Python"预测下一个词是"写")。
-
输入输出长度固定:其网络结构要求输入和输出的维度是固定的,无法灵活处理不同长度的句子或文本。
为了解决这些问题,RNN应运而生。其核心思想是引入"隐状态",让网络在处理每个新输入时,都能"记住"并利用之前的信息。
二、RNN核心原理:带"记忆"的网络结构
1. RNN的基本结构与计算逻辑 RNN的关键在于其循环连接。它在每个时间步使用相同的网络参数,并将上一步的"记忆"(隐状态 hh)传递到当前步的计算中。
-
初始状态 :隐状态 h0h0 通常初始化为零向量。
-
当前步计算 :当前输入 xtx**t 与上一步的隐状态 ht−1h**t −1 结合,计算出当前的隐状态 hth**t。
-
公式:ht=tanh(Uxt+Wht−1+b)h**t =tanh(Uxt +Wht −1+b)
-
其中,U, W, b 是所有时间步共享的参数,这大大减少了模型参数量,并使模型能处理任意长度的序列。
-
2. RNN的输入与输出形式 RNN的一个常见变体是"多对多"结构,即输入一个序列 x1,x2,...,xn,输出一个等长的序列 y1,y2,...,yn。每个输出 yty**t 由当前的隐状态 hth**t 通过一个输出层计算得到,常用于需要对每个时间步进行预测的任务(如词性标注)。
三、RNN的致命局限:长期依赖问题
尽管RNN理论上是"长短期记忆"的,但在实践中,当序列过长时,它很难学习到距离较远的信息之间的关联。
-
问题根源:在反向传播训练过程中,梯度需要通过时间步逐层传播。当序列很长时,梯度会倾向于消失(变得极小)或爆炸(变得极大)。
-
后果 :梯度消失是最常见的问题,它导致网络早期的参数几乎无法更新,从而使模型失去了"长期记忆"的能力,只能记住邻近的信息。
四、突破局限:LSTM(长短时记忆网络)
LSTM是RNN的一种变体,专门设计用来解决长期依赖问题。它通过引入"门控机制"来控制信息的流动,让网络可以自主选择记住重要的信息、遗忘无关的信息。
1. LSTM的核心:3种门控结构 LSTM在每个时间步中,除了传递隐状态 hth**t 外,还引入了一个新的"细胞状态" CtC**t,作为信息的"高速公路"。三个门协同工作,对细胞状态进行保护和更新:
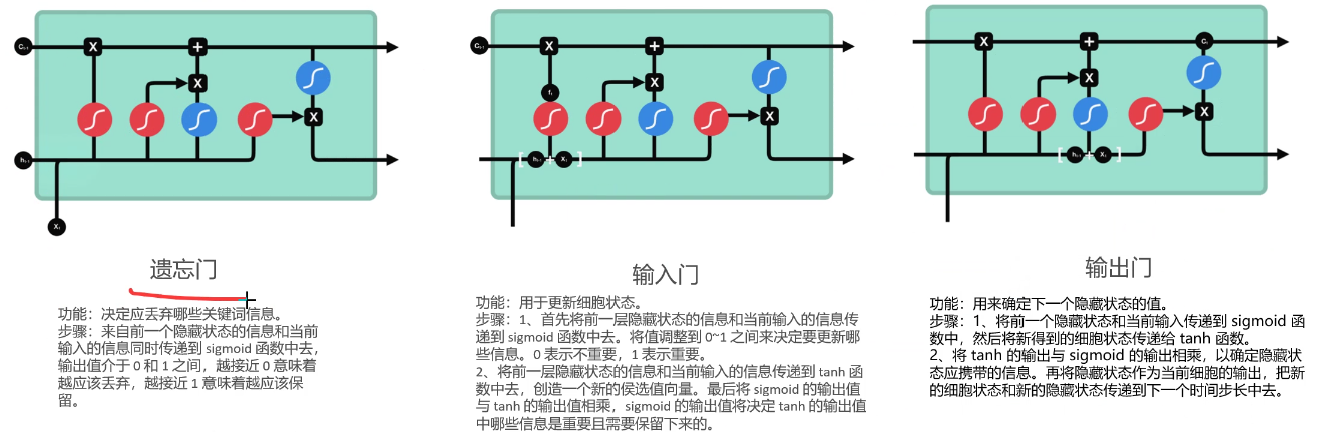
-
遗忘门 :决定要从上一个细胞状态 Ct−1C**t −1 中丢弃哪些信息。它通过查看当前输入 xtx**t 和上一个隐状态 ht−1h**t −1,为 Ct−1C**t−1 中的每个元素输出一个0到1之间的数(1表示"完全保留",0表示"完全遗忘")。
-
输入门 :决定要将哪些新信息存入当前的细胞状态 CtC**t。它包含两部分:
-
一个sigmoid层决定要更新哪些值。
-
一个tanh层生成新的候选值向量 C~tC ~t。然后将这两部分相乘,得到要添加的新信息。
-
-
细胞状态更新 :将旧的细胞状态 Ct−1C**t −1 乘以遗忘门的输出,再加上输入门生成的新信息,就得到了新的细胞状态 CtC**t。这种"加法"式的更新,是梯度能更顺畅传播、解决梯度消失的关键。
-
输出门 :决定最终要输出什么作为当前的隐状态 hth**t 。这个输出基于当前的细胞状态 CtC**t,但会经过一个tanh(将值缩放到-1到1之间)和一个sigmoid门的过滤。
2. LSTM的优势 通过这种精巧的门控机制,LSTM能够:
-
长期保留关键信息:遗忘门可以为重要信息(如句子的主题词)分配接近1的权重,使其在细胞状态中长久传递。
-
有效缓解梯度消失:细胞状态的更新主要通过加法进行,使得梯度在反向传播时能够保持稳定,从而让网络学习到长距离的依赖关系。
五、RNN与LSTM的应用场景
在实践中,RNN和LSTM的应用场景高度重叠,但选择上有所侧重:
-
短序列任务(如短文本情感分类):简单的RNN可能足够,计算成本更低。
-
长序列任务 (如机器翻译、文本摘要、语音识别):优先选择LSTM,因为它能更好地捕捉长距离依赖,性能更优。
六、总结
-
RNN 通过引入"隐状态"实现了对序列数据的处理,但受限于梯度消失问题,难以学习长期依赖。
-
LSTM 通过"遗忘门"、"输入门"和"输出门"三个门控机制,有效地解决了RNN的痛点,能够灵活地管理和利用长序列中的信息,成为处理复杂序列任务的主流模型。