当你开始认真考虑"混合检索",说明你已经走过理想主义阶段
在技术讨论里,"混合检索"经常被描述成一种听起来不太高级的方案。
它很容易被误解成:
- 两边都没做好
- 不够自信
- 各退一步
但如果你把视角从"技术炫酷"切换到"工程长期运行",你会发现一个非常一致的事实:
所有真正跑过规模、跑过事故、跑过长期维护的检索系统,最后几乎都会走向混合。
不是因为团队保守,
而是因为现实问题不纯粹。
一个必须先澄清的误区:混合检索不是"关键词 + 向量一起查"
很多人脑子里的混合检索,停留在一个非常粗糙的想象阶段:
- 同时跑关键词检索
- 同时跑向量检索
- 把结果拼在一起
这当然是一种"混合",
但它不是工程上真正有价值的那种。
工程理性里的混合检索,本质上是:
为不同类型的问题,选择不同的确定性来源。
它关心的不是"用了几种技术",
而是"每一步是否可解释、可控制、可演进"。
纯向量检索失败的原因,决定了混合检索必然出现
如果你回顾前面的文章,会发现纯向量检索的问题高度集中:
- 相似但不可用
- TopK 越调越大
- 重要性被相似度淹没
- 行为难以复现
- 系统解释成本极高
这些问题并不是"调得不够好",
而是向量检索作为工具的天然特性。
向量检索擅长的是:
- 模糊
- 近似
- 召回
但真实业务系统需要的,还包括:
- 确定性
- 层级
- 规则
- 可解释
混合检索出现,不是因为向量检索不行,
而是因为它不可能单独承担所有职责。
向量检索能力边界示意图
同样,纯关键词检索也不是"万金油"
说混合检索是工程理性,并不意味着关键词检索就能独立解决一切。
关键词检索的天然短板也非常明确:
- 无法处理表达多样性
- 对用户输入依赖极高
- 对新问题泛化能力差
在下面这些场景里,关键词检索天然吃亏:
- 用户不知道该用什么词
- 问题描述高度口语化
- 文档语义接近但词不同
这也是为什么在系统早期,
很多团队会被向量检索"震撼到"。
混合检索的真正前提:先承认"问题不是同一类"
很多检索系统之所以混乱,本质原因只有一个:
把所有用户问题,当成同一类问题来处理。
而工程理性的第一步,恰恰是反过来:
- 承认问题是分层的
- 承认有些问题追求"准"
- 有些问题追求"稳"
- 有些问题追求"尽量别出错"
混合检索,就是把这个现实,明确写进系统架构。
一个典型、但非常成熟的混合检索分工
在很多长期运行的系统里,混合检索最终会长成类似这样:
- 强规则、高频问题 → 关键词 / 规则
- 半结构、业务文档 → 关键词 + 权重
- 低频、探索性问题 → 向量检索
- 风险问题 → 限制向量介入深度
这不是技术折中,而是:
把确定性交给确定性工具,把不确定性交给不确定性工具。
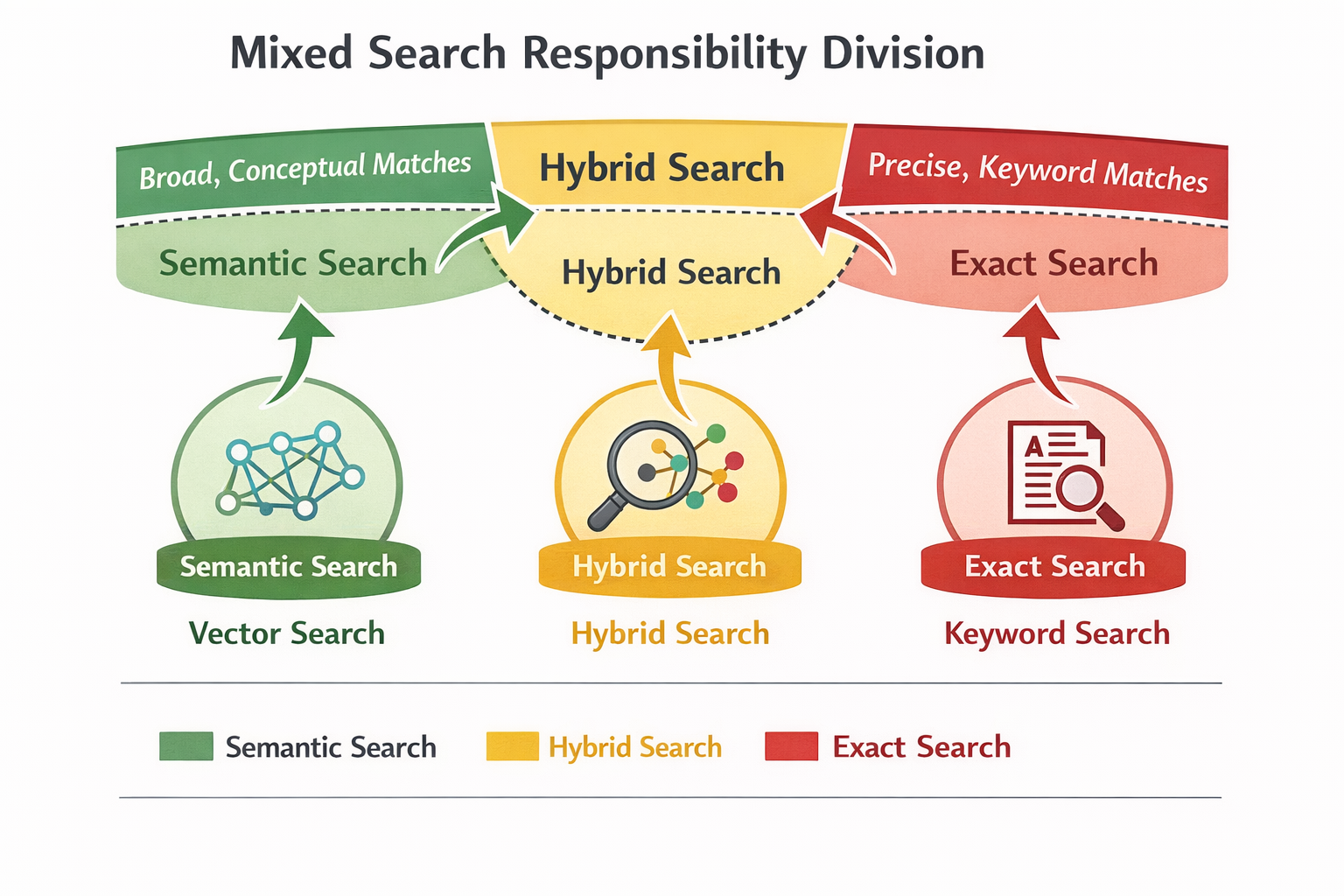
混合检索职责分工图
为什么"先关键词,后向量"通常比反过来更稳
一个非常常见、但很少被系统总结的工程经验是:
在混合检索中,让关键词先兜底,往往比让向量先兜底更稳。
原因并不复杂。
关键词检索的失败是"显性的":
- 没命中
- 命中不全
而向量检索的失败往往是"隐性的":
- 命中但不可用
- 相似但误导
在关键路径上,工程师更怕后者。
一个简化但非常真实的混合检索流程示意
text
用户问题
↓
是否命中强规则 / 明确关键词?
↓ 是
关键词检索 → 结果
↓ 否
向量检索 → TopK → rerank → 模型这条链路看起来朴素,但它的工程意义非常大:
- 把风险前置
- 把不确定性后移
- 把"猜测"留给更合适的阶段
为什么混合检索"更复杂",却"更好维护"
这是很多人一开始想不通的地方。
混合检索在代码层面,确实更复杂:
- 多套检索逻辑
- 多套评估方式
- 多套兜底路径
但在长期维护上,它反而更简单。
原因只有一个:
每一部分的失败,都更容易被隔离和解释。
- 关键词失效 → 词典/规则问题
- 向量失效 → 召回/切分问题
- rerank 失效 → 排序模型问题
系统不再是一个"整体黑盒"。
一个成熟团队的心理变化过程
几乎所有走到混合检索的团队,都会经历下面这个心理曲线:
- 初期:希望"一种技术解决所有问题"
- 中期:不断 patch、补丁、兜底
- 后期:开始主动拆分问题类型
当你不再执着于"统一方案",
而开始追求"可解释、可维护",
混合检索几乎是必然选择。
一个非常现实的判断题(你可以直接拿去用)
如果你正在犹豫是否该上混合检索,可以直接问自己:
如果我现在关掉向量检索,系统会更稳定还是更混乱?
如果我现在关掉关键词检索,系统会更稳定还是更混乱?
如果两个答案都是否定的,
那你现在的架构,很可能已经不健康了。
混合检索真正的风险,不在技术,而在"职责不清"
需要强调的是:
混合检索不是没有风险。
它最大的风险在于:
- 职责边界模糊
- 一会儿靠关键词
- 一会儿靠向量
- 出问题没人说得清是谁的锅
所以混合检索真正的难点,不是实现,而是:
明确每一种检索方式"负责什么,不负责什么"。
在做混合检索方案验证时,最容易踩的坑是:在单一路径上不断加逻辑,却缺乏横向对照。用LLaMA-Factory online这类工具快速搭建"关键词 / 向量 / 混合"三种方案的对照实验,在同一批真实问题集上比较稳定性和可解释性,往往能更快帮助团队确认:混合检索是不是工程理性,而不是心理安慰。
总结:混合检索不是妥协,而是你终于开始尊重现实
如果要用一句话总结这篇文章,我会写成:
当你不再执着于"哪种技术更先进",
而开始关心"系统长期会不会失控",
混合检索就不再是折中,而是理性选择。
纯向量,是理想主义;
纯关键词,是确定性崇拜;
而混合检索,是工程现实。
当你的系统走到这一步,
说明它已经开始从"技术展示",走向"长期运行"。