1. Redis知识脑图

2. Redis的架构与核心价值
Redis(Remote Dictionary Server)本质上是一个基于内存的、键值对存储系统 。其设计的核心目标是解决传统关系型数据库在高并发、低延迟场景下的性能瓶颈。它的核心价值可以概括为"快 "与"灵"。
- 快:数据完全存储于内存,读写操作时间复杂度通常为O(1),避免了磁盘I/O的延迟,性能可比磁盘数据库高出数个数量级。
- 灵:支持丰富的数据结构(String, Hash, List, Set, Sorted Set, Stream等),并基于这些数据结构提供了原子性操作,使其不仅能做简单缓存,还能直接实现复杂的业务逻辑,如排行榜、消息队列等。
从架构视角看,Redis在系统中常扮演 "加速层" 和 "状态中间件" 的角色。下图勾勒了其核心逻辑架构:
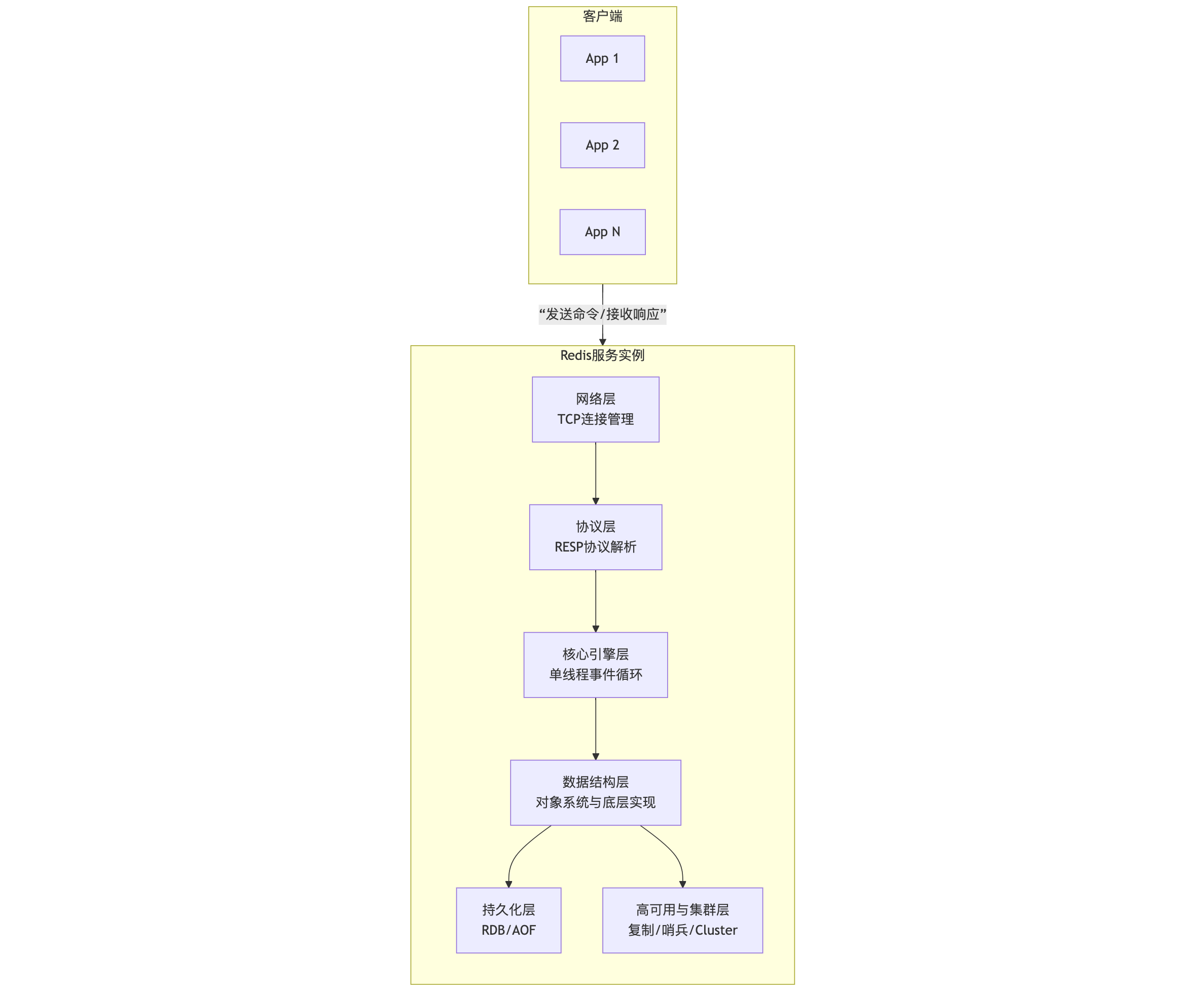
架构解读:
- 自下而上 :请求从网络层进入,经协议层解析为Redis命令,由单线程事件循环引擎 顺序执行。引擎调用数据结构层(对象系统)完成具体操作,并根据配置决定是否触发持久化或集群同步。
- 设计核心 :
- 单线程事件模型:避免了多线程的锁竞争和上下文切换,配合I/O多路复用,在绝大多数场景下实现了极高的吞吐量和低延迟。
- 对象系统 :这是Redis灵活性的根源。所有数据都被封装为
redisObject,通过type和encoding字段实现多态,根据数据大小和类型动态选择最合适的底层数据结构,在性能和内存之间取得平衡。 - 分层解耦:各层职责清晰,使得网络协议、持久化策略、集群方案等可以独立演进(如RESP协议、从RDB/AOF到混合持久化、从哨兵到Cluster)。
3. 实现原理
3.1 高效的数据结构设计
Redis的卓越性能源于其精心设计的底层数据结构。它们并非直接暴露给用户,而是通过对象系统进行封装和调用
3.1.1 对象系统(redisObject)
所有Redis键值对中的"值"都是一个redisObject结构体。
objectivec
typedef struct redisObject {
unsigned type:4; // 数据类型: string, list, hash, set, zset
unsigned encoding:4; // 编码: int, embstr, raw, hashtable, ziplist...
unsigned lru:LRU_BITS; // 最近访问时间,用于内存淘汰
int refcount; // 引用计数,用于内存回收
void *ptr; // 指向实际底层数据结构的指针
} robj;typevsencoding:type是面向用户的(如HSET操作的是Hash类型),而encoding是内部实现(同一个Hash类型,在小数据量时可能用ziplist编码以节省内存,大数据时转为hashtable编码以提升性能)。这种分离是Redis能在不同场景下自动优化的关键。
3.1.2 简单动态字符串(SDS)
Redis没有使用C语言原生的char*字符串,而是自研了SDS。
SDS 结构示例 (sdshdr8):
+---------+---------+---------+-----------------+
| len=5 | alloc=5 | flags=1 | buf[] |
+---------+---------+---------+-----------------+
| |
v v
"H" "e" "l" "l" "o" "\0"- 优势 :
- O(1)获取长度 :通过
len字段直接获得,无需像C字符串那样遍历(O(n))。 - 杜绝缓冲区溢出 :修改前会检查
alloc,自动扩容。 - 减少内存重分配 :采用空间预分配 (扩容时多分配一些)和惰性空间释放(缩容时不立即归还内存)策略。
- 二进制安全 :
buf中可以存储包含\0的数据(如图片),通过len判断结束。
- O(1)获取长度 :通过
3.1.3 字典(Dict)
字典是Redis的基石,用于实现数据库键空间(redisDb)和Hash数据类型。其核心挑战在于扩容时如何避免服务停顿。
初始状态 (ht:
索引: 0 1 2 3
->K1 ->K2
->K5
扩容触发,开始rehash (rehashidx=0):
ht[0] (size=4): ht[1] (size=8):
索引0: ->K1 ->K5 迁移至> 索引0: ->K1
索引1: ->K2 索引1: ->K2
... (K5根据新size重哈希到索引5)
rehashidx++,逐步迁移...- 渐进式Rehash :Redis同时维护两个哈希表
ht[0]和ht[1]。扩容时,将rehashidx从0开始递增,每次对客户端的增删改查操作,除了执行指定操作,还会顺带将ht[0]中rehashidx索引上的所有键值对迁移到ht[1]。迁移完成后,ht[1]替换ht[0]。这巧妙地将庞大的迁移开销分摊到了多次请求中,保证了服务的平滑性。
3.1.4 跳跃表(SkipList)
跳跃表是有序集合(ZSET)的底层实现之一,提供高效的范围查询。
头节点 header
|
L3|--------->[ ]----------------------------->[o3](score=3.0)
|
L2|----->[ ]--------->[o2](score=2.0)------->[ ]
|
L1|->[o1](score=1.0)->[ ]->[ ]->[o3](score=3.0)- 工作原理 :每个节点有随机层高(
level)。查询时从最高层开始,像使用多级索引的尺子,快速跳过大量节点,逐步逼近目标,平均时间复杂度为O(log N)。实现比平衡树更简单,且性能相当。
3.1.5 压缩列表(Ziplist)与快速列表(Quicklist)
- Ziplist :为极致节省内存设计,是一块连续内存,存储多个元素。但插入删除可能引发"连锁更新"问题。在Redis 7.0中,它被更稳健的Listpack所取代。
- Quicklist :List类型的默认实现,是双向链表和Ziplist的结合体。它将长列表分段存储为多个Ziplist节点,在保留链表高效插入删除特性的同时,利用Ziplist减少内存碎片和提高缓存局部性。
3.2 单线程事件驱动模型
Redis 6.0之前,其网络I/O和命令执行是单线程的。这并非劣势,而是精妙的设计选择:
- 避免锁开销:所有数据操作无需加锁,杜绝了竞争条件和死锁。
- 避免上下文切换:单线程模型使得CPU缓存利用率更高。
- 配合I/O多路复用:通过epoll、kqueue等系统调用,单线程可以高效管理成千上万的连接,当某个套接字准备好时,事件循环才进行处理,CPU不会空转。
Redis 6.0引入的多线程仅用于处理网络I/O的读写,即解析请求和打包回复,而核心的命令执行逻辑仍然是单线程的,从而保持了串行化的无锁优势。
3.3 持久化
为解决内存数据易失的痛点,Redis提供了两种持久化策略:
- RDB (快照) :在特定时间点将内存数据全量二进制压缩保存到磁盘(
dump.rdb)。恢复快,但可能丢失最后一次快照后的数据。 - AOF (追加日志) :记录每一个写操作命令,以文本协议格式追加到文件(
appendonly.aof)。数据完整性高,但文件体积大,恢复慢。Redis提供AOF重写机制来压缩文件。
通常采用混合模式:定期执行RDB作为基础备份,期间使用AOF记录增量操作,兼顾恢复速度和数据安全。
3.4 高可用与扩展
- 主从复制 (Replication) :一个主节点(Master)可拥有多个从节点(Slave)。数据从主节点异步同步到从节点,实现了数据备份 和读写分离(读请求可分流至从节点)。
- 哨兵模式 (Sentinel) :在主从复制基础上,引入独立的哨兵进程集群,用于监控 主节点状态,并在主节点故障时,自动进行故障转移,选举新的主节点,实现高可用。
- 集群模式 (Cluster) :Redis的分布式解决方案。采用去中心化架构,将数据分片 到16384个槽位(slot)中,由多个主节点分别负责一部分槽位,每个主节点还可配置从节点。数据访问通过CRC16哈希计算键所属槽位,并直接路由到对应节点,实现了水平扩展和高可用。
4. 典型使用场景与解决的痛点
4.1 缓存 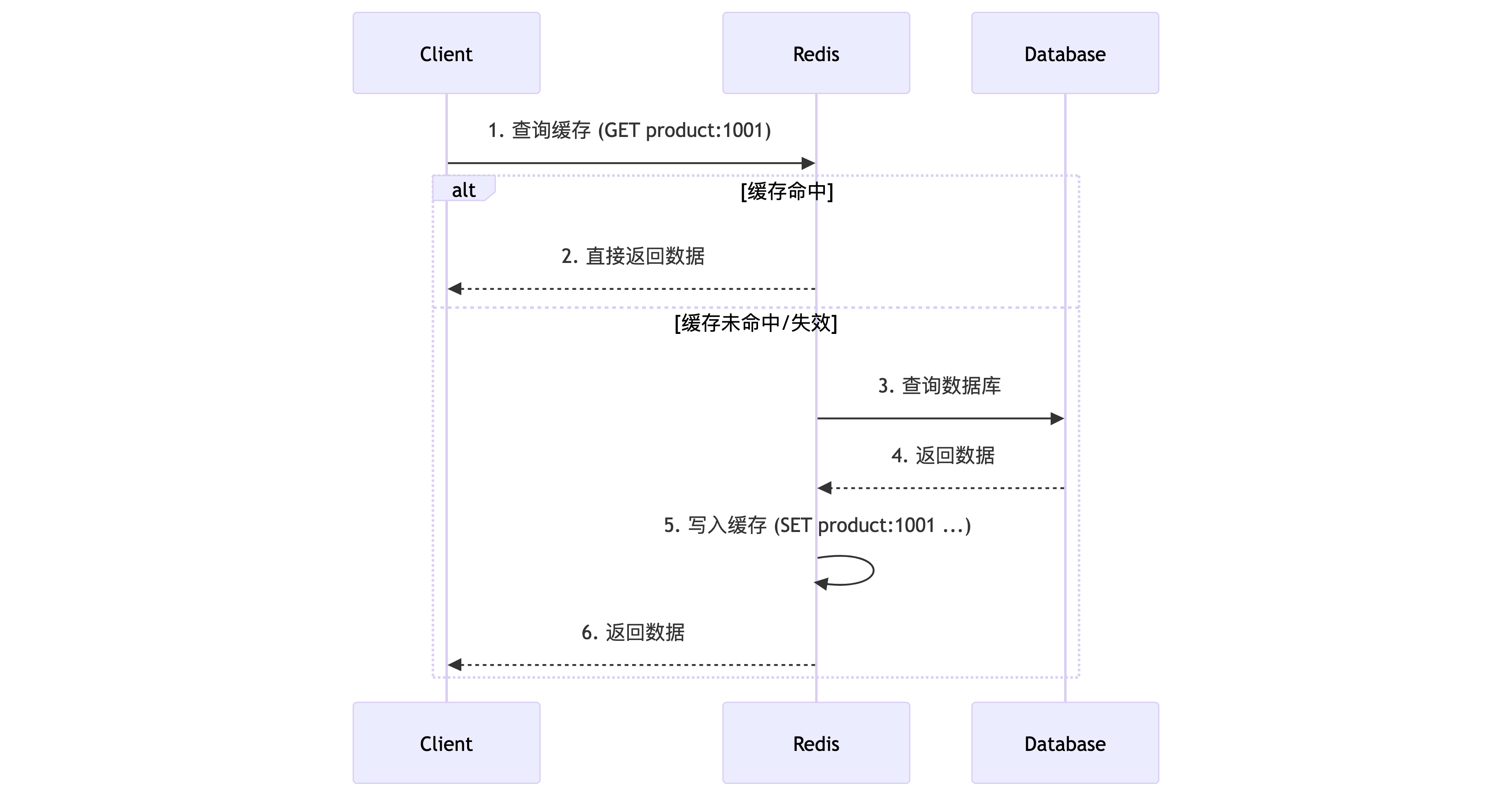
- 痛点:热点数据频繁查询数据库,导致数据库负载过高,响应变慢。
- 解决方案:将查询结果存入Redis,后续请求直接命中缓存。例如,电商首页的热门商品列表、文章详情等。设置合理的过期时间或通过消息队列监听数据库变更来更新缓存,以保证数据最终一致性。
4.2 会话存储 (Session Store)
- 痛点:在Web集群中,用户会话需要共享,无法依赖单机内存。
- 解决方案:将用户Session(如登录信息)集中存储在Redis中,所有应用服务器均可访问,实现无状态服务架构。
4.3 排行榜/计数器
- 痛点:实时更新和查询排名,数据库操作频繁且复杂。
- 解决方案 :使用
Sorted Set,成员即条目,分数即排序依据。ZINCRBY命令可原子性更新分数,ZRANGE命令可高效获取排名,完美契合榜单需求。
4.4 消息队列
- 痛点:需要解耦系统组件,进行异步处理。
- 解决方案 :使用
List的LPUSH/BRPOP命令实现简单的队列。Redis 5.0后提供的Stream数据类型,支持多消费者组、消息持久化和回溯,是更完善的消息队列实现。
4.5 实时数据处理 (Stream Processing)
- 痛点:实时产生的数据流(如用户点击、物联网传感器数据)需要被即时处理和分析。
- 解决方案 :利用
Stream数据结构,生产者XADD消息,消费者通过XREAD或消费组XREADGROUP进行实时处理,可用于实时统计、监控等场景。
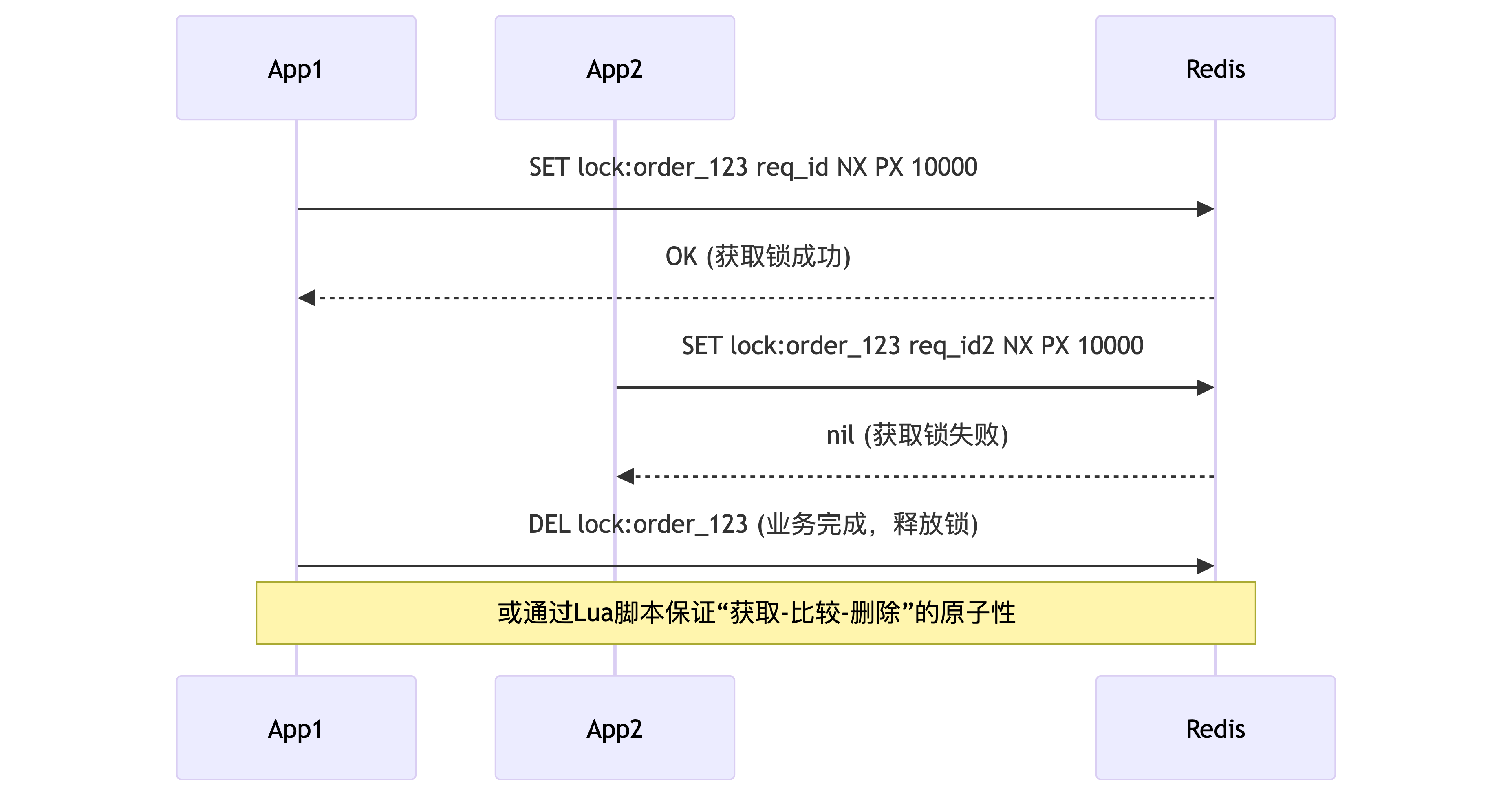
4.6 分布式锁(Distributed Lock)
利用SET命令的NX(不存在才设置)和PX(过期时间)参数实现。
5. 常见问题与解决方案
5.1 缓存经典三问题
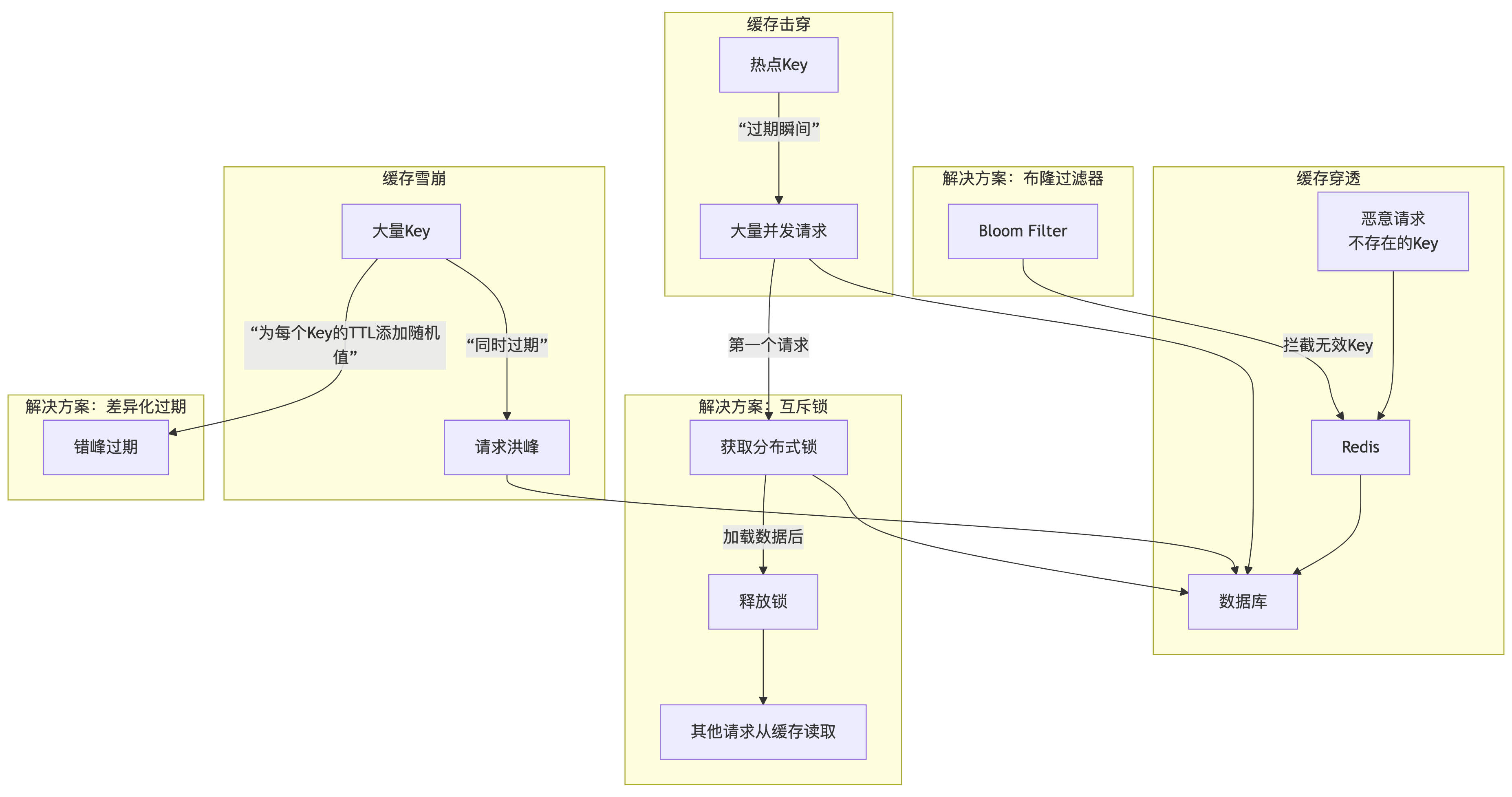
- 缓存穿透 :查询一个根本不存在 的数据,请求穿透缓存,直击数据库。
- 解决方案 :① 布隆过滤器 (Bloom Filter) :将所有可能存在的key哈希到一个位图中,查询前先过滤,拦截绝大部分无效请求。② 缓存空值 :即使数据库没有,也将这个空结果(如
null)进行短时间缓存。
- 解决方案 :① 布隆过滤器 (Bloom Filter) :将所有可能存在的key哈希到一个位图中,查询前先过滤,拦截绝大部分无效请求。② 缓存空值 :即使数据库没有,也将这个空结果(如
- 缓存击穿 :某个热点key过期 的瞬间,大量并发请求同时击穿缓存,直达数据库。
- 解决方案 :互斥锁 (Mutex Lock) 。第一个发现缓存失效的线程,使用
SETNX命令获取分布式锁,然后去数据库加载数据,其他线程等待或重试。加载完成后释放锁,其他线程即可从缓存获取数据。
- 解决方案 :互斥锁 (Mutex Lock) 。第一个发现缓存失效的线程,使用
- 缓存雪崩 :大量key在同一时间 或短时间内集中过期,导致所有请求涌向数据库。
- 解决方案 :① 差异化过期时间 :在基础过期时间上,增加一个随机值(如
基础时间 + random(0, 300秒)),打散过期点。② 数据预热 :在系统低峰期提前加载热点数据。③ 保证高可用:采用Redis集群,即使部分节点不可用,服务仍能维持。
- 解决方案 :① 差异化过期时间 :在基础过期时间上,增加一个随机值(如
5.2 大Key与热Key问题
- 大Key (BigKey) :指单个key存储的value体积过大(如几百KB的String,包含百万成员的Set)。导致操作耗时、网络阻塞、内存不均,甚至引发集群迁移故障。
- 解决方案 :① 拆分 :将大Hash拆分为多个小Hash,通过key命名规则关联。② 压缩 :对value进行序列化压缩。③ 使用合适数据结构 :例如,存储用户粉丝ID列表,用
Set可能很大,改用Bloom Filter表示可能更节省空间。
- 解决方案 :① 拆分 :将大Hash拆分为多个小Hash,通过key命名规则关联。② 压缩 :对value进行序列化压缩。③ 使用合适数据结构 :例如,存储用户粉丝ID列表,用
- 热Key (HotKey) :某个key被极高频率地访问,超过单节点处理能力,可能造成该节点CPU过载。
- 解决方案 :① 本地缓存 :在应用层使用JVM本地缓存(如Caffeine)做二次缓存,但需注意一致性。② Key分片 :将热key拆分为多个子key,如
hotkey:1,hotkey:2,分散到不同节点或实例。
- 解决方案 :① 本地缓存 :在应用层使用JVM本地缓存(如Caffeine)做二次缓存,但需注意一致性。② Key分片 :将热key拆分为多个子key,如
5.3 数据一致性与并发竞争
- 双写一致性 :缓存与数据库的数据同步时机问题。
- 解决方案 :采用 "先更新数据库,再删除缓存" 的策略。删除失败可通过消息队列重试,保证最终一致性。对于强一致性要求极高的场景,缓存可能不适用。
- 并发竞争Key :多个客户端同时写同一个key。
- 解决方案 :使用分布式锁控制写操作的顺序。对于有时序要求的写操作,可在数据中附带时间戳版本,只有版本更新的写操作才被执行。
5.4 运维与性能问题
- 内存溢出 (OOM) :数据量超过
maxmemory限制。- 解决方案 :配置合理的
maxmemory-policy淘汰策略(如allkeys-lru,volatile-ttl),并监控内存使用情况,及时扩容或优化数据。
- 解决方案 :配置合理的
- 持久化阻塞 :RDB fork或AOF重写时,如果内存过大,可能导致主线程短暂阻塞。
- 解决方案:控制单实例内存大小(建议不超过10GB),使用更快的硬盘,或在从节点执行持久化任务。