递归语言模型 (Recursive Language Models): 将上下文作为环境的推理范式
论文标题: Recursive Language Models
作者: Alex L. Zhang 1 {^1} 1, Tim Kraska 1 {^1} 1, Omar Khattab 1 {^1} 1 (MIT CSAIL)
代码: https://github.com/alexzhang13/rlm
5. 总结
核心结论 :本文提出了一种名为递归语言模型 (RLMs) 的推理时扩展 (inference-time scaling) 范式。RLM 不试图扩展 Transformer 的上下文窗口,而是从根本上改变了模型处理长文本的方式:将长 Prompt 视为外部环境中的一个变量,而非输入层的张量。
关键成果:
- 无限上下文潜力:在 10M+ token 级别的任务上,RLM 展示了极强的处理能力,成功处理了超出 GPT-5 上下文窗口两个数量级的输入。
- 抗"上下文腐烂" (Context Rot):在信息密集型任务(如 OOLONG-Pairs,复杂度随长度呈二次方增长)中,原生 GPT-5 性能急剧下降,而 RLM 保持了极高的 F1 分数 (GPT-5: <0.1% vs RLM: 58.0%)。
- 小模型的大潜力:通过在一个小的无关数据集上微调,8B 参数模型 (RLM-Qwen3-8B) 的性能提升了 28.3%,并在长文本任务上接近了原生 GPT-5 的表现。
1. 思想
当前的大型语言模型 (LLM) 面临一个根本性的物理和算法瓶颈。
-
大问题 (The Context Bottleneck):
- 上下文窗口限制 :尽管 RoPE 等技术在扩展,但 Attention 机制的计算复杂度( O ( N 2 ) O(N^2) O(N2) 或 O ( N ) O(N) O(N))使得处理无限长文本在物理上不可行。
- 上下文腐烂 (Context Rot):即使在窗口内,随着输入长度增加,模型在复杂推理任务上的性能也会显著下降。模型难以在数十万 token 中保持注意力聚焦。
- 现有方案的局限 :
- RAG (检索增强):只能获取片段,无法进行全局性的、需要综合全篇信息的推理。
- 摘要 (Summarization):有损压缩,丢失了推理所需的细节。
-
核心思想 (Paradigm Shift):
- 将 Prompt 视为外部环境 (Environment):与其将整本书塞进大脑(Context Window),不如将书放在桌上(REPL Environment),大脑只负责决定"读哪里"和"记笔记"。
- 递归与符号化交互 :RLM 不直接读取 P P P (Prompt),而是初始化一个编程环境 E \mathcal{E} E,其中 P P P 是一个变量。LLM 编写代码来检查、切分、并在切片上递归调用自身。
- 这种方法将神经处理 (Neural Processing) 转化为符号化程序执行 (Symbolic Program Execution),通过递归将大问题分解为适合 LLM 窗口的小问题。
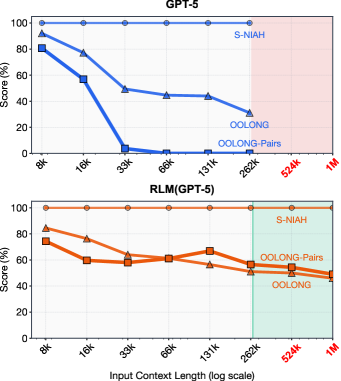
Figure 1: RLM 与 GPT-5 在不同复杂度长文本任务上的对比。随着输入长度(横轴)增加,GPT-5 在复杂任务(橙色/蓝色实线)上性能崩溃,而 RLM(虚线)保持稳定。红色区域外代表超出了 GPT-5 的物理上下文窗口。
2. 方法
RLM 的本质是一个基于 LLM 的元控制器 (Meta-Controller),运行在一个持久化的 REPL (Read-Eval-Print Loop) 环境中。
2.1 形式化定义
给定一个基础模型 M \mathcal{M} M (如 GPT-5) 和一个超长输入 P P P。
传统方法是计算 Y = M ( P ) Y = \mathcal{M}(P) Y=M(P),这受限于 M \mathcal{M} M 的最大窗口 K K K。
RLM 将 P P P 存储在外部环境 E \mathcal{E} E 中。在时间步 t t t,RLM 接收历史状态 H t H_t Ht(包含代码、元数据、简短观察,但不包含完整的 P P P ),生成代码 C t C_t Ct:
C t ← M ( H t ) C_t \leftarrow \mathcal{M}(H_t) Ct←M(Ht)
然后,代码在环境 E \mathcal{E} E 中执行,更新环境状态 S t + 1 S_{t+1} St+1 并产生输出 O t O_t Ot:
( S t + 1 , O t ) ← REPL ( S t , C t ) (S_{t+1}, O_t) \leftarrow \text{REPL}(S_t, C_t) (St+1,Ot)←REPL(St,Ct)
关键在于,下一时刻的输入 H t + 1 H_{t+1} Ht+1 仅包含 O t O_t Ot 的元数据或截断值 ,从而保持 H H H 始终在 K K K 限制内。
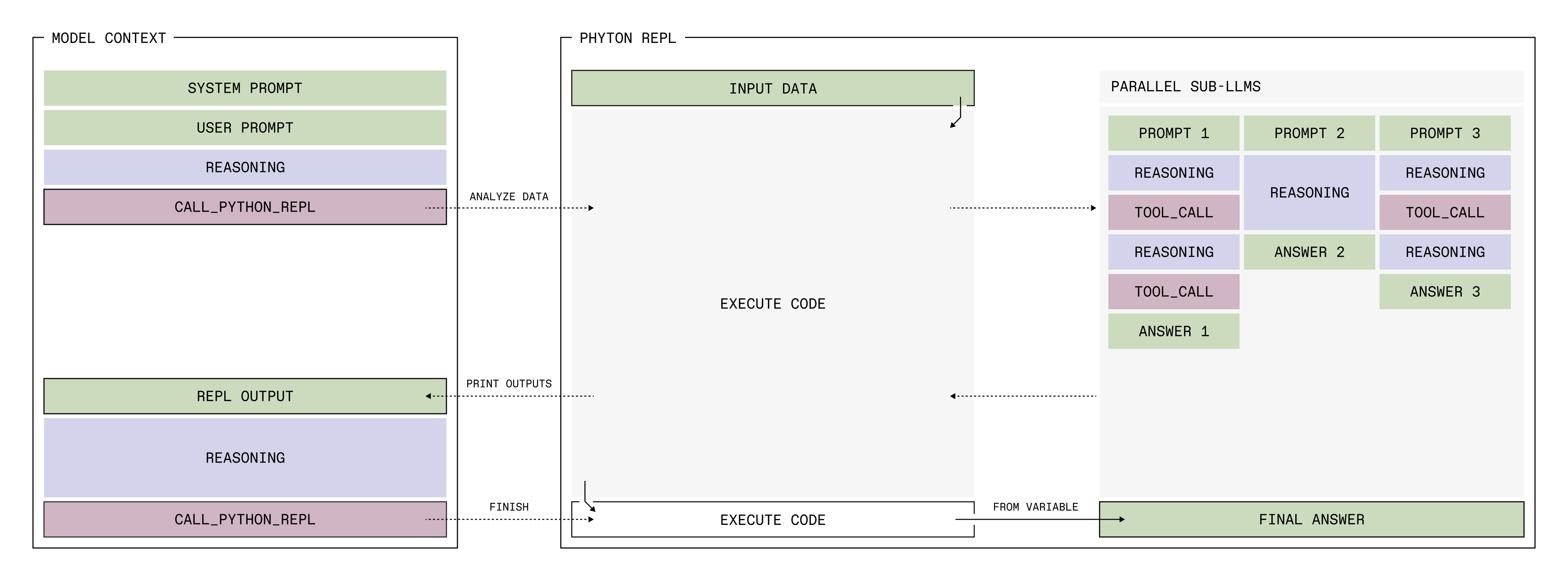
RLM 架构。(来自Blog)
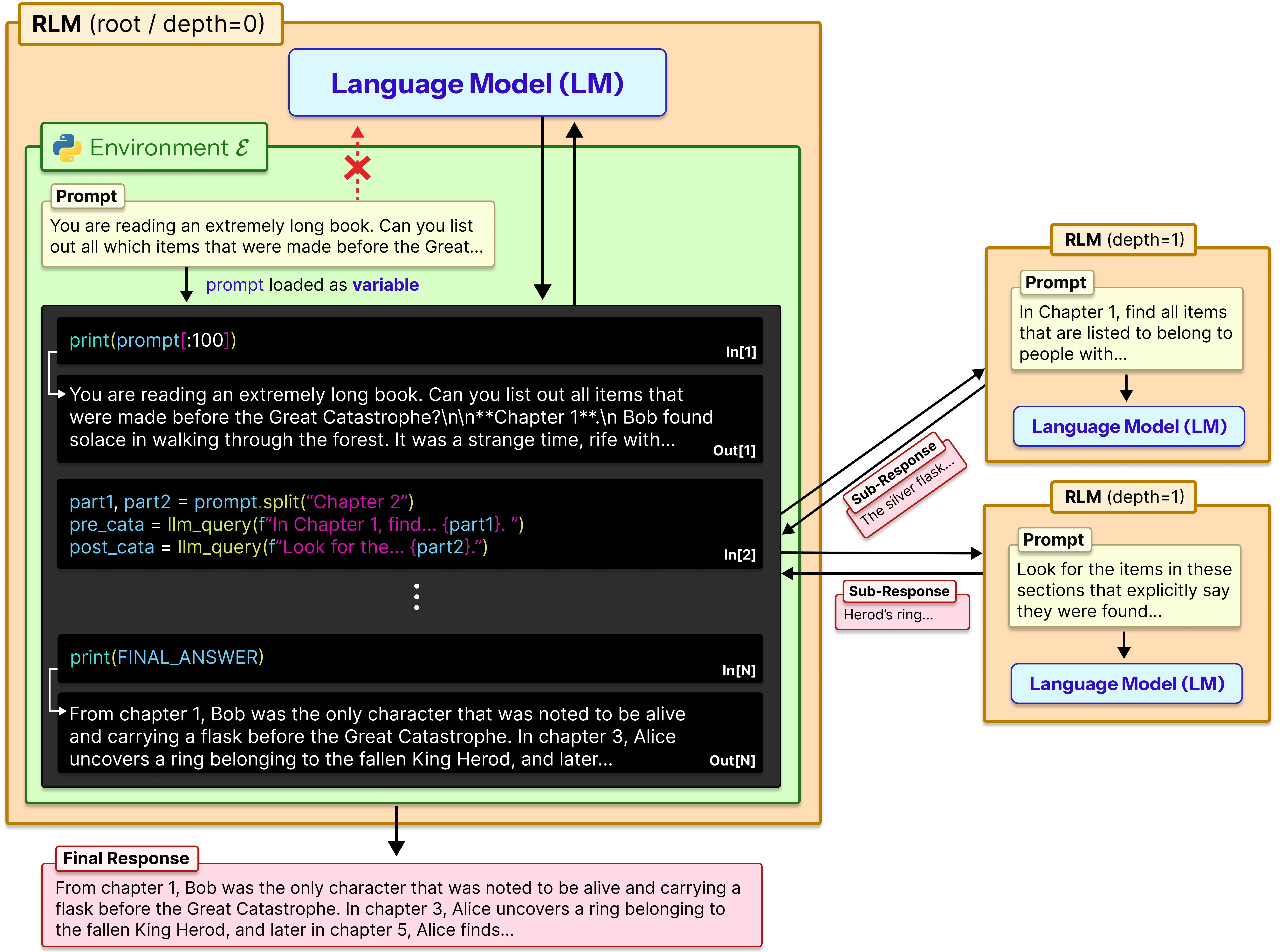
Figure 2: RLM 架构。用户 Prompt 被加载为环境中的变量。Root LLM 编写 Python 代码来切片 Prompt,并调用 llm_query (Sub-LM) 处理这些切片。Sub-LM 的结果被存回变量或聚合,最终输出结果。
2.2 关键算法逻辑 (Algorithm 1)
RLM 的执行流程与传统 Agent (如 ReAct 或 CodeAct) 有本质区别:
- 符号化句柄 (Symbolic Handle) : LLM 无法直接看到 P P P 的文本,它看到的是变量名
prompt和它的元数据(如长度len(prompt))。 - 程序化递归 (Programmatic Recursion) :
- LLM 编写代码将 P P P 切分为 p 1 , p 2 , ... p_1, p_2, \dots p1,p2,...。
- 调用
sub_LLM(p_i)处理子块。 - 精华步骤 : 子调用的结果可以被赋值给新变量,而不是直接打印到上下文中 。例如
summary_1 = sub_llm(chunk_1)。这使得 RLM 可以管理远超其自身显存的信息流。
- 终止条件 : 当 LLM 决定有了最终答案,它将结果写入特定的
Final变量。
2.3 策略模式 (Strategies)
RLM 自发涌现出了多种处理长文本的策略(见 Figure 4):
- Chunk-and-Conquer: 线性切分,分别汇总。
- Regex Filtering: 使用正则表达式先过滤出相关片段,再进行 LLM 阅读(大幅降低成本)。
- Deep Recursion : 多层级调用(虽然实验主要限制在 1 层递归,但理论上支持 N N N 层)。

Figure 4: RLM 的涌现行为。(a) 使用 Regex 过滤内容。(b) 递归子调用分解任务。© 拼接子任务输出形成长回复。
3. 优势
与现有的长文本处理方案相比,RLM 具有独特的结构性优势:
- 相比 Context Compression (摘要/压缩) : RLM 是无损的。它可以在必要时通过代码访问原始 Prompt 的每一个字符,而不是依赖模糊的压缩表示。
- 相比 Retrieval (RAG) : RLM 支持全覆盖推理。RAG 假设答案在 Top-K 文档中,而 RLM 可以遍历所有文档(例如"统计所有文档中提到 X 的次数")。
- 相比 Standard Agents (CodeAct) : 标准 Agent 通常将工具输出直接回填到 Context 中,导致 Context 迅速爆炸。RLM 强制使用变量引用,实现了显存解耦。
4. 实验
4.1 实验设置
- 基座模型: GPT-5 (Closed), Qwen3-Coder-480B (Open).
- 任务 :
- S-NIAH: 大海捞针 (Simple)。
- BrowseComp+ (1K docs): 多文档问答,需要跨文档推理。
- OOLONG: 线性复杂度的语义转换与聚合(每一行都重要)。
- OOLONG-Pairs : 二次复杂度 O ( N 2 ) O(N^2) O(N2) 的成对关系聚合(极高难度)。
- 对比基线: Base Model, CodeAct (+BM25), Summary Agent (迭代摘要).
4.2 核心结果
- 极高难度的突破 :
在 OOLONG-Pairs (32K tokens, 二次复杂度) 任务上:- GPT-5 Base: 0.1 分 (完全失败,因上下文腐烂)。
- Summary Agent: 0.1 分 (摘要丢失了成对匹配所需的细节)。
- RLM (GPT-5) : 58.0 分 。
这证明了对于需要全局细粒度信息的任务,递归+代码是唯一解。
- 扩展性 (Scaling) :
在 10M+ token 规模下,RLM 依然保持高性能,而所有基线方法均无法运行或性能归零。 - 微调效果 (Distillation) :
作者收集了 Qwen3-Coder-480B 的 RLM 轨迹(约 1000 条),微调了一个 Qwen3-8B 模型。- 结果 : RLM-Qwen3-8B 在各项任务上平均优于 Base Qwen3-8B 28.3%。
- 这表明"如何使用 REPL 进行递归思考"是一种可学习的通用能力,不依赖于模型本身的巨量知识。
- 成本分析 :
- 虽然 RLM 可能进行多次调用,但在许多任务(如 BrowseComp+)上,RLM 实际上比 Summary Agent 更便宜 。因为 RLM 可以通过代码(如 Regex 或关键词)有选择地读取数据,而不是被迫摘要全文。
- 对于高复杂度任务,成本随复杂度线性或二次增长,这是物理规律的必然,但 RLM 提供了"即便昂贵也能做出来"的能力。
其他博文解读
Bolg: Recursive Language Models: the paradigm of 2026
一篇有价值的工程实践报告,来自 Prime Intellect(一家专注于去中心化 AI 计算和 Agent 研究的机构)。
如果说上一篇 Paper 是 RLM 的理论原型 ,那么这篇 Blog 就是 RLM 的工程落地实战手册 。它不仅验证了 Paper 的结论,还提出了具体的架构改进(特别是"Context Folding"的概念),并诚实地展示了 RLM 在哪些地方还没做好。
以下是深度解读:
1. 概念升级:Context Folding (上下文折叠)
Prime Intellect 将 RLM 归类为 "Context Folding" 的一种终极形式。
- 问题:Context Rot(上下文腐烂)。随着 context 变长,模型变笨,且成本线性增长。
- 传统解法:基于文件的摘要(File-system based scaffolding),如 Claude Code。
- Context Folding :主动管理上下文,将其保持在短且高效的状态。
- 其他流派:分支(Branching)后只返回摘要;分层总结(Agentic Context Engineering)。
- RLM 流派(本文推崇) :完全不依赖摘要(因为摘要是有损的),而是依赖代码和变量引用(无损的句柄)。
2. 工程实现的三个关键改进 (vs 原论文)
Prime Intellect 在复现 RLM 时,为了适应复杂的 Agent 任务,做了三个强架构约束:
A. 工具使用的层级隔离 (Tool Isolation)
- 设计 :只有 Sub-LLM 可以使用外部工具(如 Google Search, Browser 等)。Main RLM 只有 Python REPL。
- 原理:工具的输出(如网页 HTML、搜索结果 JSON)通常包含海量 Token。如果让 Main RLM 直接用工具,它的上下文瞬间就会爆炸。
- 效果 :Main RLM 被迫成为纯粹的 "Manager / Scheduler" ,它只看代码和变量名;Sub-LLM 成为 "Worker",在并在"脏乱差"的数据泥潭里打滚,只把清洗后的结果传回给 Manager。
B. 强制变量输出 (Answer via Variable)
- 设计 :Main RLM 不能直接生成答案文本,必须将答案写入一个特定的 Python 变量
answer["content"],并设置answer["ready"] = True。 - 原理 :这强制模型进行 "显存解耦"。模型无法通过"生成"来作答,只能通过"编程"来构建答案。这也允许答案在多个推理步中被反复修改、拼接(类似在内存中编辑字符串),而不是像传统 LLM 那样一锤子买卖(生成即不可改)。
C. 并行化 (Parallelism)
- 设计 :引入
llm_batch()函数。 - 原理:这是 RLM 相比线性 Chain-of-Thought 的最大优势。对于 Map-Reduce 类任务(如 Oolong),可以将耗时操作并行分发给多个 Sub-LLM,这也是"时间换空间"策略中,优化时间维度的关键。
3. 实验与发现 (Ablation Study)
Prime Intellect 在四个截然不同的环境中进行了测试,结果非常诚实:
| 环境 (Environment) | 任务类型 | RLM 表现 | 关键发现 |
|---|---|---|---|
| DeepDive | 深度搜索 (Deep Research) | 提升 (需配合 Tips) | Sub-LLM 是关键。通过并行分发搜索任务,Main RLM 保持了极短的上下文,而 Sub-LLM 处理了海量网页内容。 |
| math-python | 数学推理 + Python | 下降 (Hurt) | 过度工程化。数学题通常需要的是深度思考 (Chain of Thought),而不是分治。强制使用 Sub-LLM 反而打断了推理链条,且引入了额外的通信开销。 |
| Oolong | 长文本聚合 (Map-Reduce) | 显著提升 (真实数据) | 验证了 Paper 结论。对于真实世界的复杂长文本(Real dataset),RLM 完胜。只有在非常短的文本上,Base LLM 才有优势。 |
| Verbatim-copy | 精确复制/编辑 | 提升 | 利用了"变量编辑"能力。RLM 可以先写一个草稿到变量里,然后写代码去 fix typo,最后提交。这是传统 LLM 做不到的(生成的 token 无法收回)。 |
4. 为什么 RLM 在 Math 上失败了? (First Principles Analysis)
这是一个非常好的反直觉案例。根据第一性原理:
- RLM 的优势 :处理 Information-Intense (信息密集型) 任务。因为信息太多,塞不进脑子,所以需要切分处理。
- Math 的本质 :Compute-Intense (计算密集型) 任务。信息量(题目)通常很短,但需要极高的逻辑深度。
- 结论 :对于短 Context 但高推理深度的任务,RLM 的"分治策略"是无效的,甚至是有害的(破坏了注意力的连贯性)。RLM 是为了解决 Context Bottleneck ,而不是 Reasoning Bottleneck。
5. "The Bitter Lesson" 与未来:RL Training
文章最后提到了 Rich Sutton 的名篇 《The Bitter Lesson》:
"通用方法(利用计算力的扩展,如搜索和学习)最终总是胜过利用人类先验知识的方法。"
- 当前状态 :目前的 RLM 还是靠 Prompt Engineering (文中提到的
Environment Tips) 来告诉模型"你应该这样用 Sub-LLM"。这是一种人工植入的 Heuristics。 - 未来方向 :端到端的强化学习 (End-to-End RL) 。
- 不告诉模型怎么切分,让它自己在环境中试错。
- 如果在 Math 任务中,模型发现调用 Sub-LLM 没用,它应该学会退化回一个普通的 LLM。
- 如果在 Oolong 任务中,模型发现并行度不够,它应该学会写更激进的并行代码。
总结思考
Recursive Language Models这篇论文的思路与我的 Python DSL 思路有部分重合, 基本上属于 Python DSL 处理超长上下文时的一个技巧.
- 原理
双层LLM, 主LLM不直接阅读信息, 而是持有一个REPL工具, 主LLM知道自己应该通过调用写代码调用REPL的方式理解信息.
最关键的是, 代码中允许调用sub LLM, 一个允许主LLM写Prompt进行分配任务的LLM, 会代理执行主LLM的子任务, 子任务各自独立, 所以使用的是而是 Map-Reduce ------ 对全量信息进行程序化的遍历、转换与聚合 . 最终结果通过代码聚合得到信息的某个侧写.
- 第一性原理
因为对于几乎所有任务, 并不需要同时了解所有信息, 仅需要了解信息全集中的子集. 从全集中提取任务需要的信息子集的过程可以简化为search, RLM的核心思想就是使用sub LLM 完成search. 对比其他search工具: RAG使用向量相似度, 正则使用预设规则.
- 优势:
- 更智能 (使用了LLM),
- 可并行(子任务独立)