Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
通义千问-VL:一款多功能视觉语言模型,支持理解、定位、文本识别等广泛任务

摘要
在本工作中,我们推出Qwen-VL系列大规模视觉语言模型,该模型可同时感知和理解文本与图像信息。我们以Qwen-LM为基底,通过精心设计的(i)视觉接受器、(ii)输入输出接口、(iii)三阶段训练流程及(iv)多语言多模态清洁语料库赋予模型视觉能力。除常规图像描述与问答功能外,我们还通过对齐图像-描述-边框三元组实现了Qwen-VL的视觉定位与文字识别能力。最终模型(含Qwen-VL与Qwen-VL-Chat)在跨领域视觉基准测试(如图说生成、视觉问答、视觉定位)及不同设置(如零样本、少样本)下刷新了同类通用模型的最优记录。在真实场景对话评测中,经指令微调的Qwen-VL-Chat相较现有视觉语言对话系统亦展现出显著优势。所有模型均已开源以推动后续研究。
1.引言
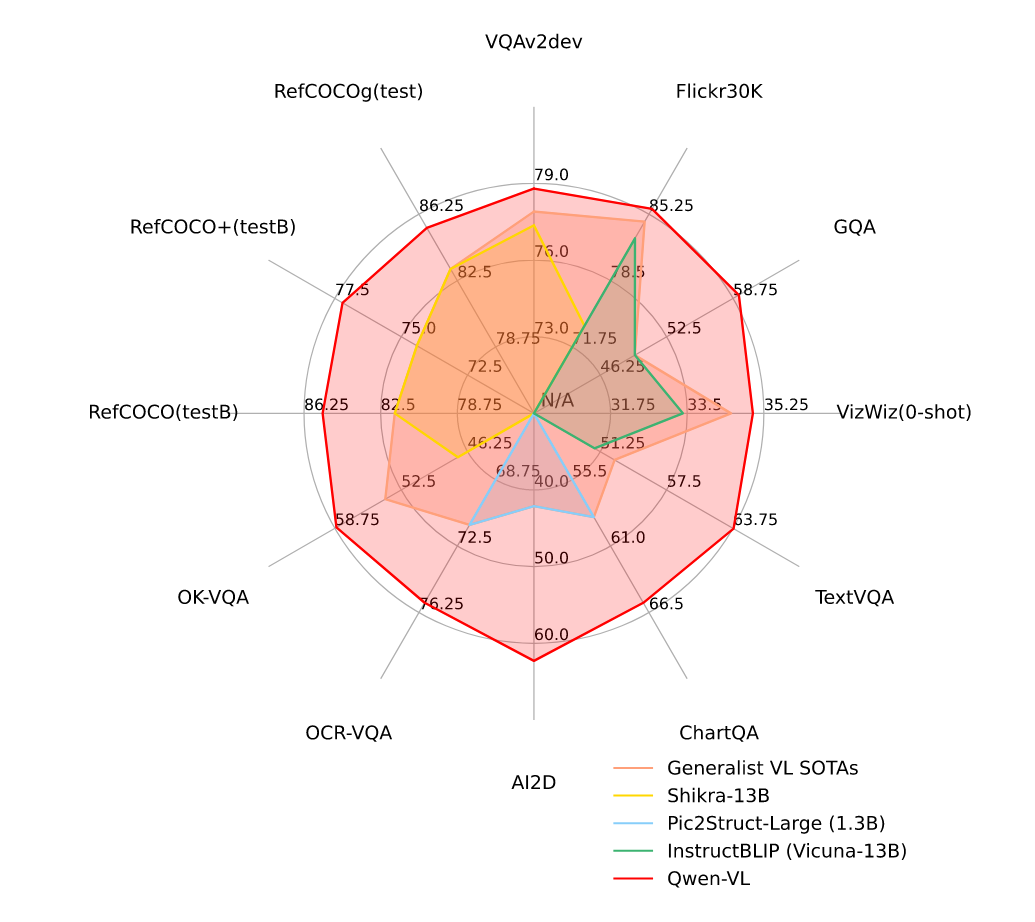
图1:相比其他通用模型,Qwen-VL在广泛任务上实现了最先进的性能。
近期,大型语言模型(LLMs)(Brown等人,2020;OpenAI,2023;Anil等人,2023;Gao等人,2023;Qwen,2023)因其在文本生成与理解方面的强大能力而广受关注。这些模型可通过指令微调进一步对齐用户意图,展现出强大的交互能力以及作为智能助手提升生产力的潜力。然而原生大型语言模型仅存在于纯文本世界,缺乏处理其他常见模态(如图像、语音和视频)的能力,这极大限制了其应用范围。受此驱动,一系列大型视觉语言模型(LVLMs)(Alayrac等人,2022;Chen等人,2022;Li等人,2023c;Dai等人,2023;Huang等人,2023;Peng等人,2023;Zhu等人,2023;Liu等人,2023;Ye等人,2023b,a;Chen等人,2023a;Li等人,2023a;Zhang等人,2023;Sun等人,2023;OpenAI,2023)被开发出来,用以增强大型语言模型对视觉信号的感知与理解能力。这些大规模视觉语言模型在解决现实世界中以视觉为核心的问题方面展现出巨大潜力。
尽管如此,已有大量研究探索了大型视觉语言模型(LVLM)的局限性与潜力,但当前开源LVLM普遍存在训练与优化不足的问题,导致其显著落后于专有模型(Chen et al., 2022, 2023b; OpenAI, 2023),这阻碍了开源社区对LVLM的进一步探索与应用。此外,由于真实视觉场景极为复杂,细粒度视觉理解对LVLM有效精准辅助人类至关重要。然而仅有少数研究尝试该方向(Peng et al., 2023; Chen et al., 2023a),多数开源LVLM仍采用粗粒度图像感知方式,缺乏对象定位或文本阅读等细粒度感知能力。
在本文中,我们探索解决方案并介绍了开源Qwen系列的最新成员:Qwen-VL系列。Qwen-VL是基于Qwen-7B(Qwen,2023)语言模型开发的一系列高性能、多模态视觉语言基础模型。我们通过引入包含语言对齐视觉编码器和位置感知适配器的新型视觉接收器,赋予大语言模型视觉能力。整体模型架构及输入输出接口设计简洁高效,并通过精心设计的三个阶段训练流程,基于海量图文语料库对模型进行全面优化。
我们预训练的检查点"Qwen-VL"能够感知和理解视觉输入,根据给定提示生成所需回应,并完成多种视觉-语言任务,如图像描述、问答、面向文本的问答及视觉定位。基于Qwen-VL进行指令微调的视觉语言聊天机器人"Qwen-VL-Chat"如图2所示,能遵循用户意图实现人机交互与输入图像的感知理解。

图2:我们的Qwen-VL-Chat生成的若干定性示例。Qwen-VL-Chat支持多图片输入、多轮对话、多语言交流、文本阅读、定位能力及细粒度识别与理解功能。
通义千问-VL系列模型的主要特性包括:
• 领先性能:在同规模视觉理解模型中,通义千问-VL在多项核心评测基准上达到顶尖准确率。其卓越表现不仅涵盖传统任务(如图像描述、问答、定位),同时在最新推出的多模态对话评测中同样表现出众。
• 多语言能力:延续通义千问-LM的多语言特性,训练数据包含大量英汉双语及多语言图文对,使通义千问-VL原生支持中英文及多语言指令交互。
• 多图像处理:训练阶段采用任意交错编排的图文数据作为输入,使通义千问-Chat-VL具备多图像对比分析与上下文理解能力。
• 细粒度视觉理解:凭借高分辨率输入与细粒度训练语料,通义千问-VL展现出极具竞争力的细粒度视觉理解能力,在目标定位、文本识别、文字导向问答及细粒度对话等任务中显著优于现有通用视觉语言模型。
2.方法
2.1 模型架构
通义千问视觉语言模型(Qwen-VL)的整体网络架构包含三个组成部分,具体模型参数详见表1:
大规模语言模型:Qwen-VL采用大规模语言模型作为其基础组件,该模型以Qwen-7B(Qwen,2023)的预训练权重进行初始化。
视觉编码器:Qwen-VL的视觉编码器采用Vision Transformer(ViT)架构(Dosovitskiy等人,2021年),并使用Openclip的ViT-bigG预训练权重初始化(Ilharco等人,2021年)。在训练和推理过程中,输入图像被调整至特定分辨率。该视觉编码器通过将图像以14的步长分割成区块,生成一组图像特征。
位置感知视觉语言适配器:为解决长图像特征序列导致的效率问题,Qwen-VL提出了一种压缩图像特征的视觉语言适配器。该适配器由一个随机初始化的单层交叉注意力模块构成,其以一组可训练向量(嵌入向量)作为查询向量,并将视觉编码器提取的图像特征作为键向量进行交叉注意力运算,从而将视觉特征序列压缩至固定长度256。查询向量数量的消融实验详见附录E.2。此外,考虑到位置信息对细粒度图像理解的重要性,该模型在交叉注意力机制的查询-键值对中加入了二维绝对位置编码,以缓解特征压缩过程可能造成的位置信息损失。最终压缩得到的256长图像特征序列将被输入至大语言模型。

2.2 输入与输出
图像输入:图像通过视觉编码器和适配器处理,生成固定长度的图像特征序列。为区分图像特征输入与文本特征输入,两个特殊标记( < i m g > <img> <img>和 < / i m g > </img> </img>)分别添加至图像特征序列的首尾,用于标识图像内容的起始与结束。
边界框输入与输出:为增强模型在细粒度视觉理解与定位方面的能力,Qwen-VL的训练采用了包含区域描述、问题及检测数据的形式。与传统仅涉及图像文本描述或问答的任务不同,该任务要求模型以规范格式准确理解并生成区域描述。针对任意边界框,会进行归一化处理(范围 [ 0 , 1000 ) [0,1000) [0,1000))并转换为特定字符串格式:" ( X t o p l e f t , Y t o p l e f t ) , ( X b o t t o m r i g h t , Y b o t t o m r i g h t ) (X_{topleft},Y_{topleft}),(X_{bottomright},Y_{bottomright}) (Xtopleft,Ytopleft),(Xbottomright,Ybottomright)"。该字符串以文本形式参与分词,无需额外位置词表。为区分检测字符串与常规文本字符串,在边界框字符串首尾分别添加特殊符号 < b o x > <box> <box>和 < / b o x > </box> </box>;同时为了正确关联边界框与其描述的词语或句子,还引入了另一组特殊符号 < r e f > <ref> <ref>和 < / r e f > </ref> </ref>用于标记被该边界框引用的内容。
3.训练
如图3所示,Qwen-VL模型的训练过程包含三个阶段:两阶段预训练和最后的指令微调训练阶段。
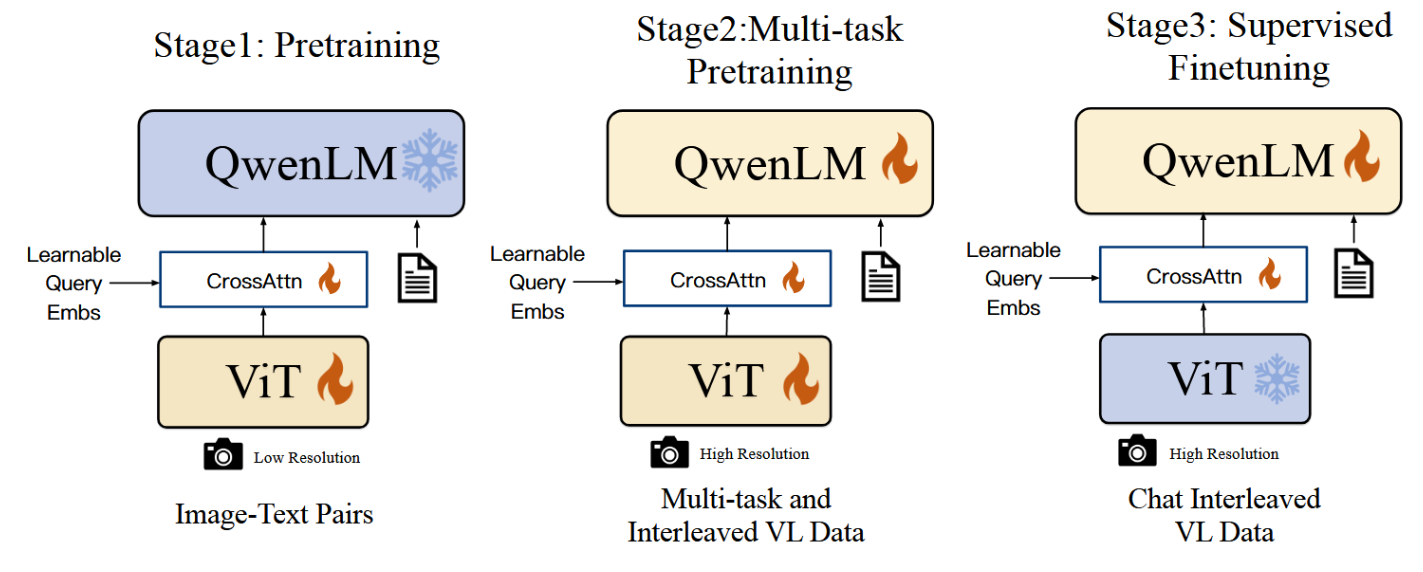
3.1 预训练
在预训练的第一阶段,我们主要使用了大规模、弱标注的网络爬取图像-文本对数据集。我们的预训练数据由多个公开可获取的来源及部分内部数据构成。我们着力清除了数据集中某些特定模式。如表2所示,原始数据集共包含50亿图像-文本对,经过清洗后保留14亿数据,其中英语(文本)数据占比77.3%,中文(文本)数据占比22.7%。
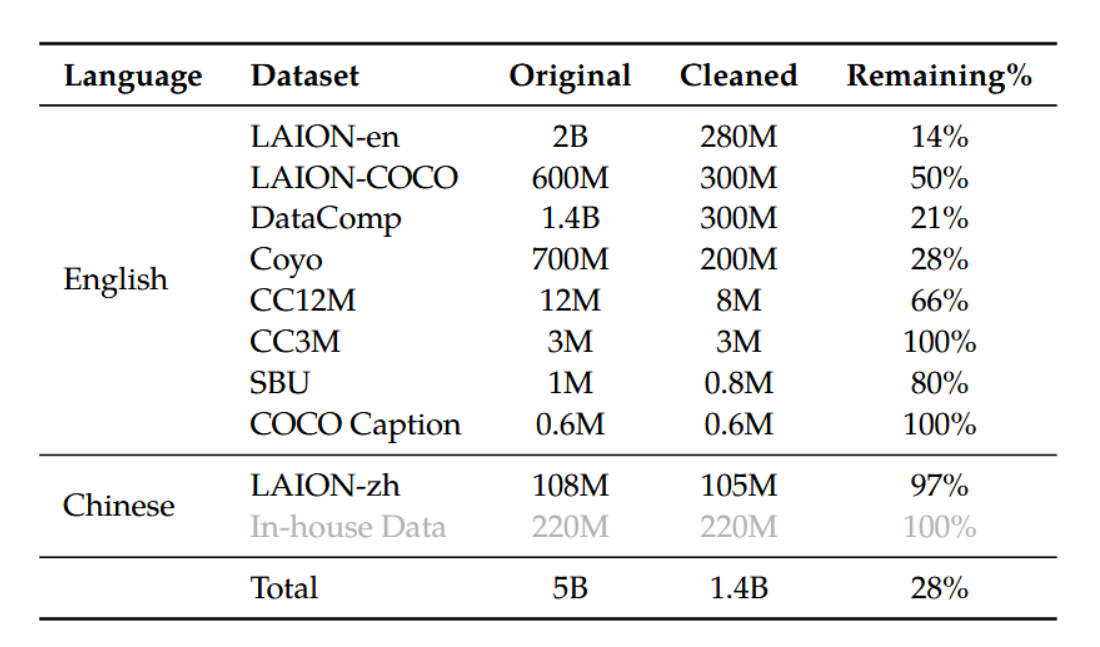
表2:Qwen-VL预训练数据详情。LAION-en与LAION-zh分别是从LAION-5B中提取的英文与中文子集(Schuhmann等,2022a)。LAION-COCO(Schuhmann等,2022b)是通过LAION-en生成的合成数据集。DataComp(Gadre等,2023)和Coyo(Byeon等,2022)是图文配对数据的集合。CC12M(Changpinyo等,2021)、CC3M(Sharma等,2018)、SBU(Ordonez等,2011)及COCO Caption(Chen等,2015)均为学术标注数据集。
在此阶段,我们冻结大型语言模型,仅优化视觉编码器与VL适配器。输入图像统一调整为224×224分辨率,训练目标是最小化文本标记的交叉熵。最大学习率设为2e−4,训练过程中图像-文本对的批次大小为30720。整个预训练第一阶段共进行50,000步,约消耗15亿个图像-文本样本。更多超参数详见附录C,本阶段收敛曲线如图6所示。
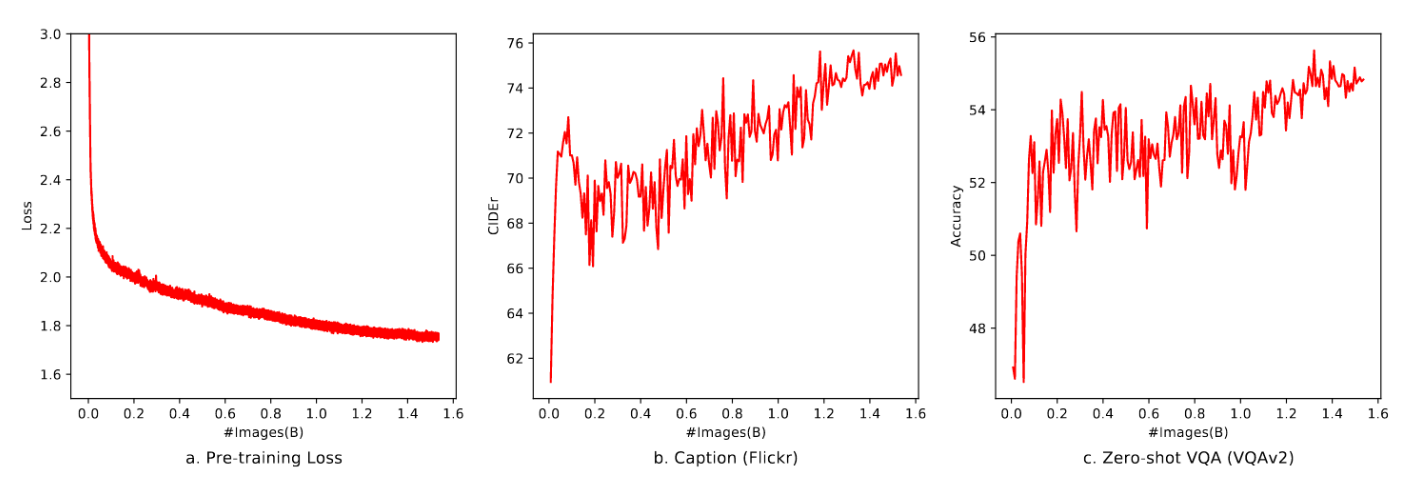
图6:预训练阶段的收敛可视化
3.2 多任务预训练
在多任务预训练的第二阶段,我们引入了更高质量、更细粒度的视觉语言标注数据,采用更大输入分辨率及交错排列的图像-文本数据。如表3所示,Qwen-VL在7个任务上进行了同步训练:文本生成任务使用内部收集的语料以保持大语言模型能力;图像描述数据与表2基本一致(但样本量大幅减少并排除LAION-COCO);视觉问答任务混合使用了公开数据集------包括GQA(Hudson和Manning,2019)、VGQA(Krishna等人,2017)、VQAv2(Goyal等人,2017)、DVQA(Kafle等人,2018)、OCRVQA(Mishra等人,2019)和DocVQA(Mathew等人,2021);基于Kosmos-2框架,我们对GRIT数据集(Peng等人,2023)进行微调后用于指称定位任务;参考定位与定位描述双任务则使用GRIT、Visual Genome(Krishna等人,2017)、RefCOCO(Kazemzadeh等人,2014)、RefCOCO+与RefCOCOg(Mao等人,2016)构建训练样本;为提升文字导向任务性能,我们从Common Crawl收集PDF/HTML格式数据,并参照Kim等人(2022)的方法生成带有自然场景背景的中英文合成OCR数据;最后,通过将同类型任务数据打包成长度为2048的序列,构建出简单的交错图像-文本数据。
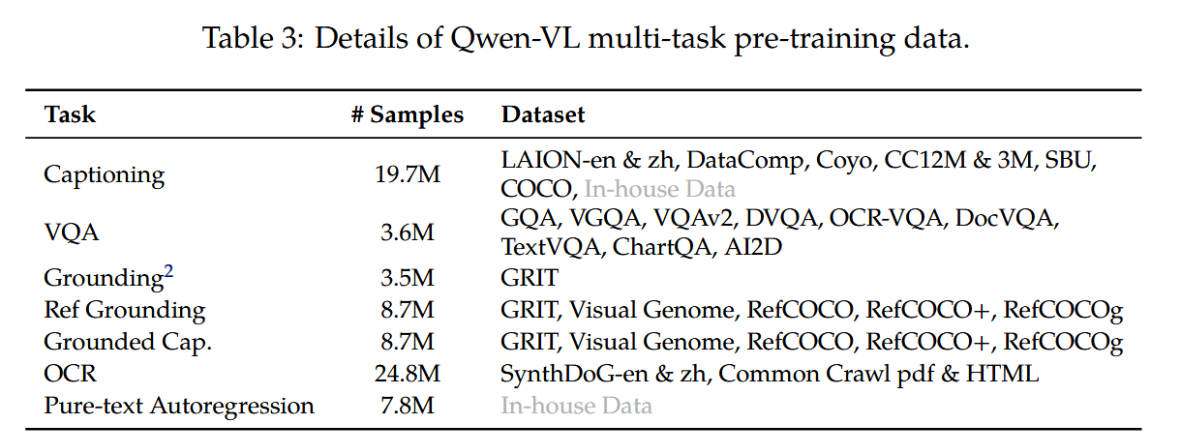
表3:Qwen-VL多任务预训练数据明细。
我们将视觉编码器的输入分辨率从224×224提升至448×448,减少了图像下采样造成的信息损失。此外,针对视觉变换器在高分辨率下的处理能力,我们在附录E.3中进行了窗口注意力与全局注意力的消融实验。我们解锁了大语言模型并对整个模型进行训练,训练目标与预训练阶段保持一致。
3.3 监督式微调
在此阶段,我们通过对Qwen-VL预训练模型进行指令微调以增强其指令遵循与对话能力,最终得到支持交互的Qwen-VL-Chat模型。多模态指令微调数据主要源于图文描述数据或通过大语言模型自指令生成的对话数据,这些数据通常仅解决单图像对话与推理任务,且局限于图像内容理解。我们通过人工标注、模型生成与策略拼接的方式额外构建了一套对话数据,以赋予Qwen-VL模型定位能力与多图像理解能力。经验证,该模型能有效将上述能力迁移至更广泛语言环境及问题类型。同时,我们在训练中混合使用多模态与纯文本对话数据,确保模型对话能力的通用性。指令微调数据总量达35万条。本阶段冻结视觉编码器,仅优化语言模型与适配器模块。该阶段数据格式展示于附录B.2。
4.评估
在本节中,我们对多种多模态任务进行整体评估,以全面衡量模型的视觉理解能力。下文提及的Qwen-VL代表经过多任务训练的模型,而Qwen-VL-Chat指经过监督微调(SFT)阶段后的模型。
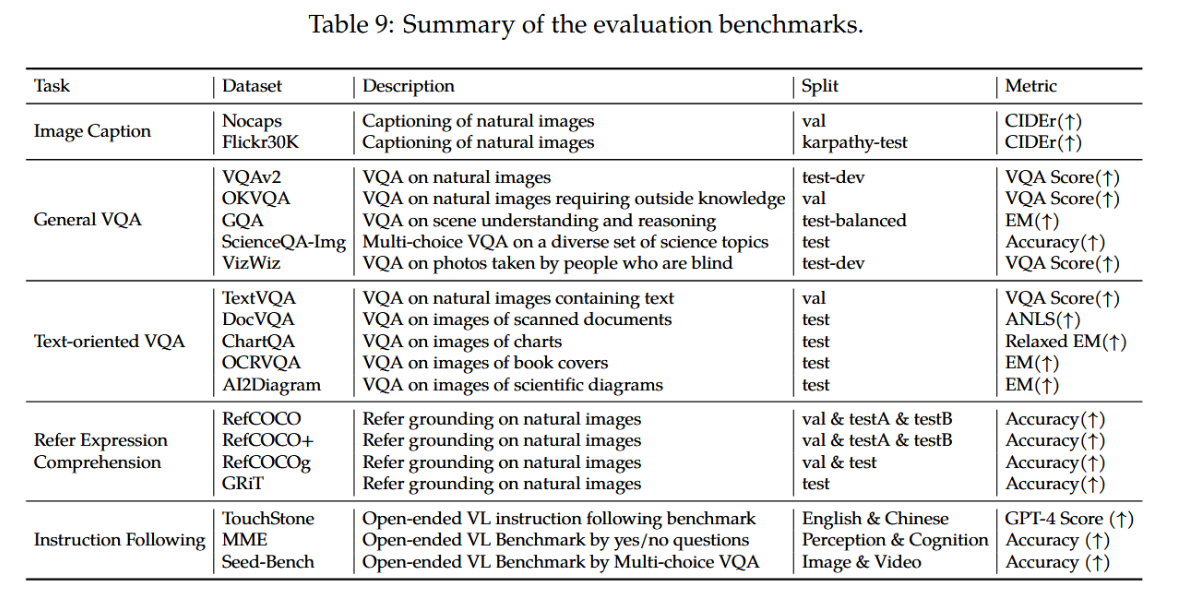
表9详细列出了所用评估基准及相应指标的汇总。
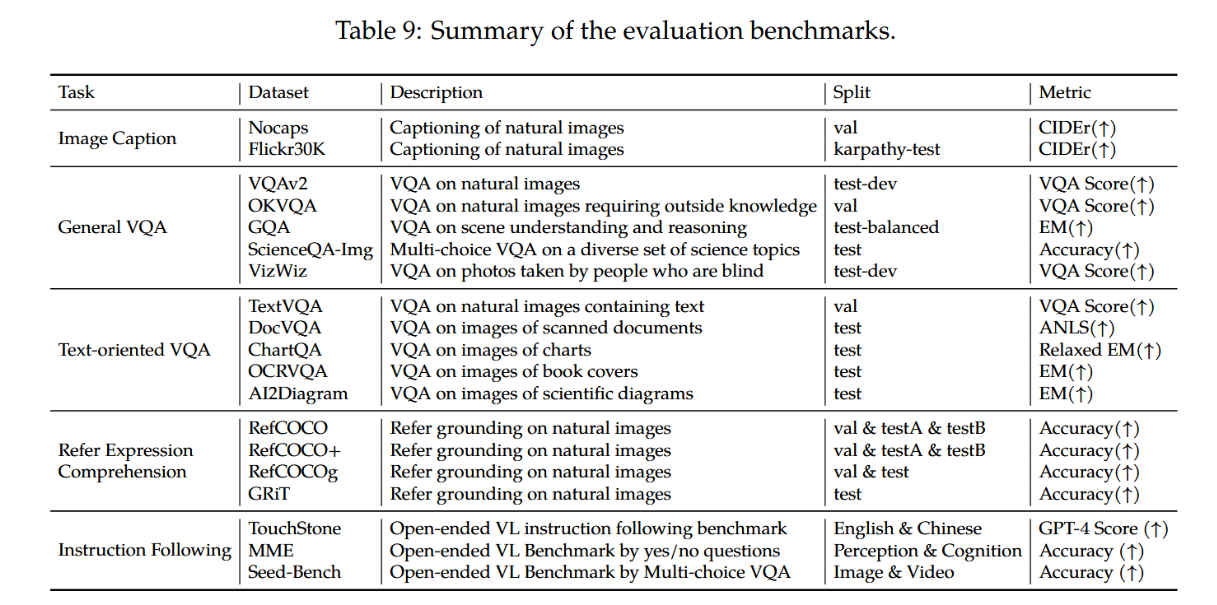
表9:评估基准汇总。
4.1 图像标注与通用视觉问答
图像描述(Image caption)和通用视觉问答(VQA)是视觉语言模型的两个常规任务。具体而言,图像描述要求模型为给定图像生成文字描述,而通用VQA则要求模型根据给定的图像-问题对生成答案。
在图题生成任务中,我们选用Nocaps(Agrawal等人,2019)和Flickr30K(Young等人,2014)作为基准数据集,并以CIDEr分数(Vedantam等人,2015)作为衡量指标。我们采用贪心搜索算法生成描述,输入提示为"用英文描述该图像:"。
在通用视觉问答(VQA)评估中,我们采用五个基准数据集:VQAv2(Goyal等人,2017)、OKVQA(Marino等人,2019)、GQA(Hudson和Manning,2019)、ScienceQA(图像集)(Lu等人,2022b)和VizWiz VQA(Gurari等人,2018)。针对VQAv2、OKVQA、GQA和VizWiz VQA任务,我们采用开放式答案生成策略,通过贪心解码方式处理提示词"{question} Answer:",不限制模型输出空间。而对于ScienceQA任务,我们将模型输出约束至预设选项(非开放式),选取置信度最高选项作为模型预测结果,并以Top-1准确率作为评估指标。
图像描述和通用视觉问答(VQA)任务的整体性能展示在表4中。结果表明,在两项任务上,我们的Qwen-VL和Qwen-VL-Chat模型均显著优于之前的通用模型。具体而言,在Flickr30K karpathy-test数据集的零样本图像描述任务中,Qwen-VL以85.8分的CIDEr得分取得了最先进的性能表现,甚至超越了参数规模更大的通用模型(例如拥有800亿参数的Flamingo-80B)。
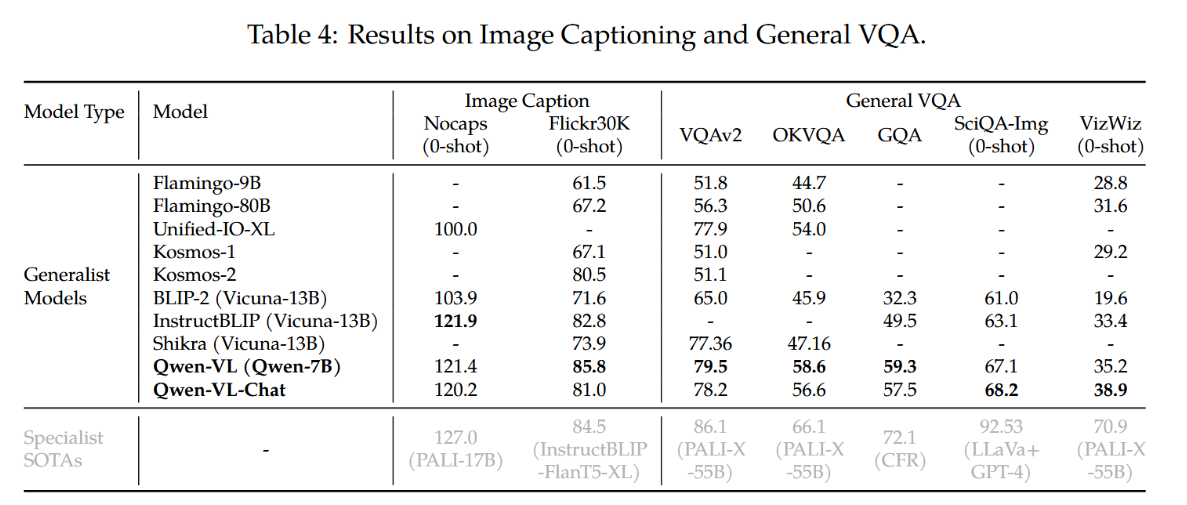
表4:图像描述与通用VQA结果。
在各类通用视觉问答基准测试中,我们的模型亦展现出显著优势。在VQAv2、OKVQA和GQA基准上,Qwen-VL分别取得了79.5%、58.6%和59.3%的准确率,大幅超越近期提出的多模态大模型。值得注意的是,Qwen-VL在ScienceQA和VizWiz数据集上也表现出强大的零样本学习能力。
4.2 面向文本的视觉问答
以文本为导向的视觉理解技术在实际应用场景中具有广阔前景。我们在TextVQA(Sidorov等人,2020)、DocVQA(Mathew等人,2021)、ChartQA(Masry等人,2022)、AI2Diagram(Kembhavi等人,2016)和OCR-VQA(Mishra等人,2019)等多个基准测试上评估了模型在文本导向视觉问答任务上的能力。如表5所示,相比此前通用模型及近期大规模视觉语言模型(LVLM),我们的模型在多数测试集上展现出更优性能,且优势幅度显著。
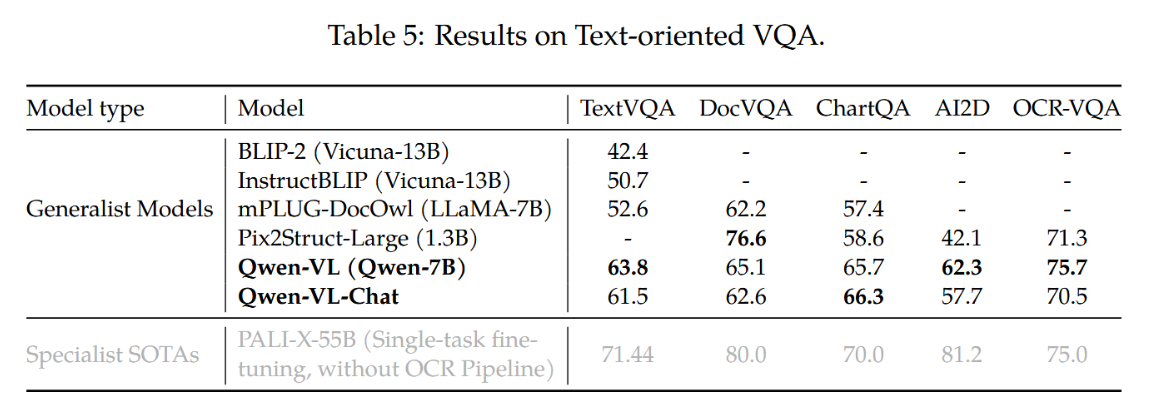
表5:文本导向VQA结果
4.3 指代表达式理解
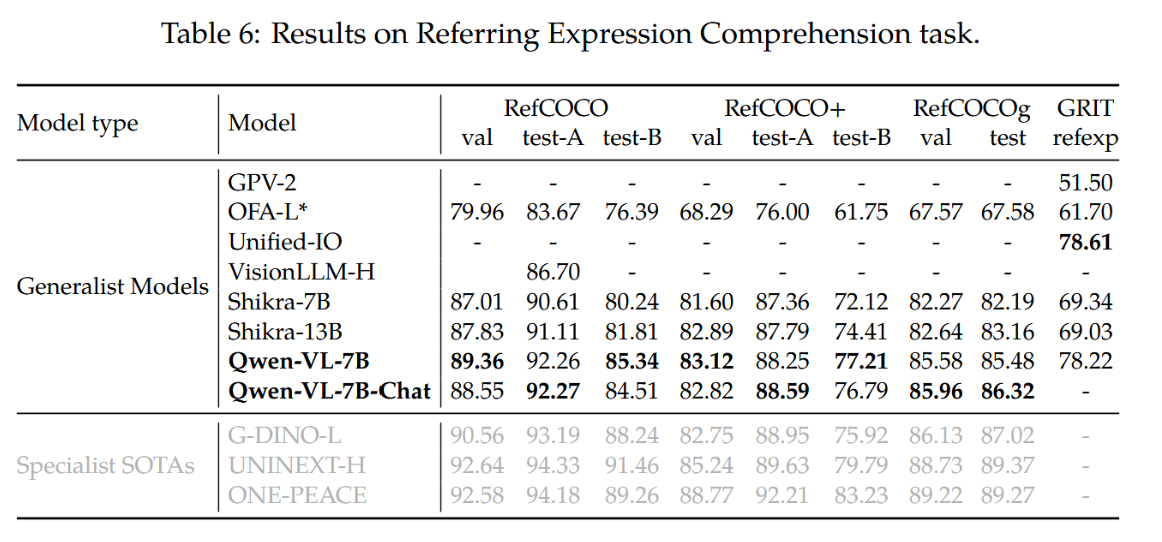
我们通过在RefCOCO(Kazemzadeh等人,2014)、RefCOCOg(Mao等人,2016)、RefCOCO+(Mao等人,2016)和GRIT(Gupta等人,2022)等指代表达理解基准上的评估,展示了模型细粒度的图像理解与定位能力。具体而言,指代表达理解任务要求模型在描述文本的指导下定位目标物体。结果如表6所示。相较于以往的通用模型或近期的大规模视觉语言模型(LVLM),我们的模型在所有基准测试中均取得了最顶尖的成绩。
4.4 视觉语言任务中的小样本学习
我们的模型还展现出令人满意的上下文学习(即小样本学习)能力。如图4所示,在OKVQA(Marino等人,2019)、Vizwiz(Gurari等人,2018)、TextVQA(Sidorov等人,2020)和Flickr30k(Young等人,2014)任务上,千问-VL通过上下文小样本学习取得了优于参数量相近模型(Flamingo-9B(Alayrac等人,2022)、OpenFlamingo-9B(?)和IDEFICS-9B(?))的性能。其表现甚至能匹敌参数量大得多的模型(Flamingo-80B和IDEFICS-80B)。需要说明的是,本研究采用简单随机采样构建小样本示例,未使用更优效的复杂构建方法(如RICES(Yang等人,2022b))。
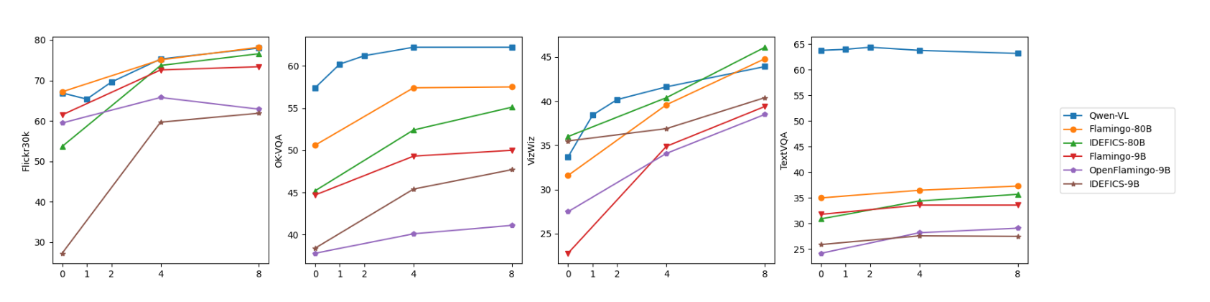
图4:Qwen-VL与其他模型的小样本学习结果对比。
4.5 真实用户行为中的指令遵循
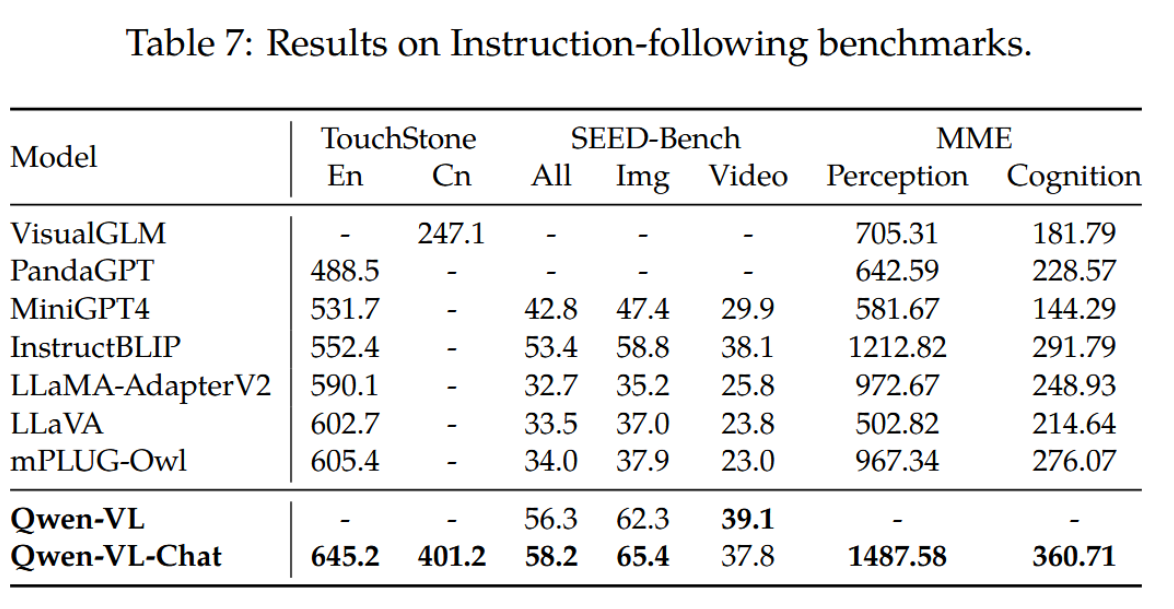
除传统视觉语言测评外,为评估Qwen-VL-Chat模型在真实用户场景中的能力,我们进一步基于TouchStone(Bai等,2023)、SEED-Bench(Li等,2023b)和MME(Fu等,2023)开展测评。TouchStone作为开放式视觉语言指令跟随基准测试,我们在该平台上以中英双语对比了Qwen-VL-Chat与其他指令调优大型视觉语言模型的指令跟随能力。SEED-Bench包含1.9万道经精确人工标注的多选题,用于评估多模态大模型的12项维度(涵盖时空理解)。MME则通过14个子任务同时衡量模型的感知与认知能力。
三个基准测试的结果如表7所示。Qwen-VL-Chat在全部三个数据集上均展现出明显优势,这表明我们的模型在理解并响应用户多样化指令方面表现更优。在SEED-Bench中,我们发现仅通过采样四帧画面即可将模型的视觉能力有效迁移至视频任务。根据TouchStone呈现的综合评分,相较于其他LVLM模型,我们的模型展现出显著优势,尤其在中文理解能力方面。就大类能力而言,该模型在理解与识别领域优势更为突出,特别是文本识别和图表分析等方向。具体明细请参阅TouchStone数据集。
5.相关工作
近年来,研究者们对视觉-语言学习展现出浓厚兴趣(Su等,2019;Chen等,2020;Li等,2020;Zhang等,2021;Li等,2021b;Lin等,2021;Kim等,2021;Dou等,2022;Zeng等,2021;Li等,2021a,2022),尤其在开发多任务通用模型方面(Hu和Singh,2021;Singh等,2022;Zhu等,2022;Yu等,2022;Wang等,2022a;Lu等,2022a;Bai等,2022)。CoCa(Yu等,2022)提出编码器-解码器结构以同步解决图文检索与视觉-语言生成任务;OFA(Wang等,2022a)通过定制化任务指令将特定视觉-语言任务转化为序列到序列任务;Unified I/O(Lu等,2022a)进一步将图像分割和深度估计等任务引入统一框架。另一类研究聚焦构建视觉-语言表征模型(Radford等,2021;Jia等,2021;Zhai等,2022;Yuan等,2021;Yang等,2022a)。CLIP(Radford等,2021)利用对比学习与海量数据在语义空间对齐图像和语言,展现出广泛的跨下游任务泛化能力;BEIT-3(Wang等,2022b)采用混合专家(MOE)结构与统一掩码标记预测目标,在多项视觉-语言任务上取得领先成果。除视觉-语言学习外,ImageBind(Girdhar等,2023)与ONE-PEACE(Wang等,2023)还将语音等多模态数据对齐至统一语义空间,由此构建出更具通用性的表征模型。
尽管已取得显著进展,现有视觉语言模型仍存在若干局限性,例如指令跟随的鲁棒性不足、对未见任务的泛化能力有限以及缺乏情境学习能力。随着大语言模型(LLMs)的快速发展(Brown等人,2020;OpenAI,2023;Anil等人,2023;Gao等人,2023;Qwen,2023),研究者开始基于LLMs构建更强大的视觉语言大模型(LVLMs)(Alayrac等人,2022;Chen等人,2022;Li等人,2023c;Dai等人,2023;Huang等人,2023;Peng等人,2023;Zhu等人,2023;Liu等人,2023;Ye等人,2023b,a;Chen等人,2023a;Li等人,2023a;Zhang等人,2023;Sun等人,2023)。BLIP-2(Li等人,2023c)提出Q-Former以对齐冻结的视觉基础模型与LLMs;LLAVA(Liu等人,2023)和MiniGPT4(Zhu等人,2023)引入视觉指令微调来增强LVLMs的指令跟随能力;mPLUG-DocOwl(Ye等人,2023a)则通过引入数字文档数据赋予LVLMs文档理解能力。Kosmos2(Peng等人,2023)、Shikra(Chen等人,2023a)和BuboGPT(Zhao等人,2023)进一步强化LVLMs的视觉定位能力,实现区域描述与定位。本研究将图像描述、视觉问答、OCR、文档理解和视觉定位能力整合至Qwen-VL,所得模型在这些多样化任务上展现出卓越性能。
6.结论与未来工作
我们推出了Qwen-VL系列,这是一组旨在推动多模态研究的大规模多语言视觉-语言模型。Qwen-VL在多项基准测试中均超越同类模型,支持多语言对话、多图交错对话、中文指代消解以及细粒度识别。未来我们将重点在以下维度持续增强Qwen-VL的能力:
• 融合语音、视频等更多模态;
• 通过扩展模型规模、训练数据和提升分辨率,增强对多模态数据中复杂关联的理解能力;
• 拓展多模态生成能力,特别是生成高保真图像与流畅语音。
7.参考文献
- Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. nocaps: novel object captioning at scale. In ICCV, 2019.
- Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. In NeurIPS, 2022.
- Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv:2305.10403, 2023.
- Jinze Bai, Rui Men, Hao Yang, Xuancheng Ren, Kai Dang, Yichang Zhang, Xiaohuan Zhou, Peng Wang, Sinan Tan, An Yang, et al. Ofasys: A multi-modal multi-task learning system for building generalist models. arXiv:2212.04408, 2022.
- Shuai Bai, Shusheng Yang, Jinze Bai, Peng Wang, Xingxuan Zhang, Junyang Lin, Xinggang Wang, Chang Zhou, and Jingren Zhou. Touchstone: Evaluating vision-language models by language models. arXiv:2308.16890, 2023.
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In NeurIPS, 2020.
- Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset, 2022. URL https://github.com/kakaobrain/coyo-dataset.
- Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR, 2021.
- Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm's referential dialogue magic. arXiv:2306.15195, 2023a.
- Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, et al. Pali: A jointly-scaled multilingual language-image model. arXiv:2209.06794, 2022.
- Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, et al. Pali-x: On scaling up a multilingual vision and language model. arXiv preprint arXiv:2305.18565, 2023b.
- Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv:1504.00325, 2015.
- Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning. In ECCV, 2020.
- Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv:2305.06500, 2023.
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- Zi-Yi* Dou, Aishwarya* Kamath, Zhe* Gan, Pengchuan Zhang, Jianfeng Wang, Linjie Li, Zicheng Liu, Ce Liu, Yann LeCun, Nanyun Peng, Jianfeng Gao, and Lijuan Wang. Coarse-to-fine vision-language pre-training with fusion in the backbone. In NeurIPS, 2022.
- Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv:2306.13394, 2023.
- Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets. arXiv:2304.14108, 2023.
- Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv:2304.15010, 2023.
- Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In CVPR, 2023.
- Google. Puppeteer, 2023. URL https://github.com/puppeteer/puppeteer.
- Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, 2017.
- Tanmay Gupta, Ryan Marten, Aniruddha Kembhavi, and Derek Hoiem. Grit: General robust image task benchmark. arXiv:2204.13653, 2022.
- Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In CVPR, 2018.
- Ronghang Hu and Amanpreet Singh. Unit: Multimodal multitask learning with a unified transformer. In ICCV, 2021.
- Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, et al. Language is not all you need: Aligning perception with language models. arXiv:2302.14045, 2023.
- Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, 2019.
- Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, 2021. URL https://doi.org/10.5281/zenodo.5143773.
- Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. arXiv:2102.05918, 2021.
- Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via question answering. In CVPR, 2018.
- Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In EMNLP, 2014.
- Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In ECCV, 2016.
- Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. In ECCV, 2022.
- Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. In ICML, 2021.
- Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. In IJCV, 2017.
- Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv:2305.03726, 2023a.
- Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv:2307.16125, 2023b.
- Junnan Li, Ramprasaath R Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021a.
- Junnan Li, Dongxu Li, Caiming Xiong, and Steven C. H. Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
- Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv:2301.12597, 2023c.
- Wei Li, Can Gao, Guocheng Niu, Xinyan Xiao, Hao Liu, Jiachen Liu, Hua Wu, and Haifeng Wang. UNIMO: towards unified-modal understanding and generation via cross-modal contrastive learning. In ACL, 2021b.
- Xiujun Li, Xi Yin, Chunyuan Li, Xiaowei Hu, Pengchuan Zhang, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020.
- Junyang Lin, Rui Men, An Yang, Chang Zhou, Ming Ding, Yichang Zhang, Peng Wang, Ang Wang, Le Jiang, Xianyan Jia, et al. M6: A chinese multimodal pretrainer. In KDD, 2021.
- Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv:2304.08485, 2023.
- Jiasen Lu, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, and Aniruddha Kembhavi. Unified-io: A unified model for vision, language, and multi-modal tasks. arXiv:2206.08916, 2022a.
- Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In NeurIPS, 2022b.
- Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In CVPR, 2016.
- Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In CVPR, 2019.
- Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv:2203.10244, 2022.
- Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. In WACV, 2021.
- Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In ICDAR, 2019. Openai. Chatml documents. URL https://github.com/openai/openai-python/blob/main/chatml.md.
- OpenAI. Gpt-4 technical report, 2023.
- Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. In NeurIPS, 2011.
- Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv:2306.14824, 2023.
- Qwen. Introducing qwen-7b: Open foundation and human-aligned models (of the state-of-the-arts), 2023. URL https://github.com/QwenLM/Qwen-7B.
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
- Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. arXiv:2210.08402, 2022a.
- Christoph Schuhmann, Andreas Köpf, Richard Vencu, Theo Coombes, and Romain Beaumont. Laion coco: 600m synthetic captions from laion2b-en. https://laion.ai/blog/laion-coco/, 2022b.
- Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL, 2018.
- Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension. In ECCV, 2020.
- Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. In CVPR, 2022.
- Artifex Software. Pymupdf, 2015. URL https://github.com/pymupdf/PyMuPDF.
- Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. Vl-bert: Pre-training of generic visual-linguistic representations. In ICLR, 2019.
- Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative pretraining in multimodality. arXiv:2307.05222, 2023.
- Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. In CVPR, 2015.
- Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-tosequence learning framework. In ICML, 2022a.
- Peng Wang, Shijie Wang, Junyang Lin, Shuai Bai, Xiaohuan Zhou, Jingren Zhou, Xinggang Wang, and Chang Zhou. One-peace: Exploring one general representation model toward unlimited modalities. arXiv:2305.11172, 2023.
- Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv:2208.10442, 2022b.
- An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, and Chang Zhou. Chinese clip: Contrastive vision-language pretraining in chinese. arXiv:2211.01335, 2022a.
- Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Yumao Lu, Zicheng Liu, and Lijuan Wang. An empirical study of gpt-3 for few-shot knowledge-based vqa. In AAAI, 2022b.
- Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chenliang Li, Junfeng Tian, et al. mplug-docowl: Modularized multimodal large language model for document understanding. arXiv:2307.02499, 2023a.
- Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv:2304.14178, 2023b.
- Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. In ACL, 2014.
- Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. arXiv:2205.01917, 2022.
- Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel C. F. Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, Ce Liu, Mengchen Liu, Zicheng Liu, Yumao Lu, Yu Shi, Lijuan Wang, Jianfeng Wang, Bin Xiao, Zhen Xiao, Jianwei Yang, Michael Zeng, Luowei Zhou, and Pengchuan Zhang. Florence: A new foundation model for computer vision. arXiv:2111.11432, 2021.
- Yan Zeng, Xinsong Zhang, and Hang Li. Multi-grained vision language pre-training: Aligning texts with visual concepts. arXiv:2111.08276, 2021.
- Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In CVPR, 2022.
- Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv:2306.02858, 2023.
- Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. Vinvl: Revisiting visual representations in vision-language models. In CVPR, 2021.
- Yang Zhao, Zhijie Lin, Daquan Zhou, Zilong Huang, Jiashi Feng, and Bingyi Kang. Bubogpt: Enabling visual grounding in multi-modal llms. arXiv:2307.08581, 2023.
- Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing visionlanguage understanding with advanced large language models. arXiv:2304.10592, 2023.
- Xizhou Zhu, Jinguo Zhu, Hao Li, Xiaoshi Wu, Hongsheng Li, Xiaohua Wang, and Jifeng Dai. Uni-perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks. In CVPR, 2022.
附录
A.数据集详情
A.1 图文对
我们使用网络爬取的图文对数据集进行预训练,包括LAION-en(Schuhmann等人,2022a)、LAION-zh(Schuhmann等人,2022a)、LAION-COCO(Schuhmann等人,2022b)、DataComp(Gadre等人,2023)和Coyo(Byeon等人,2022)。我们通过以下步骤清理这些噪声数据:
- 剔除图像宽高比过大的图文对
- 剔除图像尺寸过小的图文对
- 剔除CLIP分数过低(数据集特定阈值)的图文对
- 剔除文本包含非英语或非中文字符的图文对
- 剔除文本包含表情符号字符的图文对
- 剔除文本长度过短或过长的图文对
- 清理文本中的HTML标记部分
- 清理具有特定非规范格式的文本
针对学术标注数据集,我们移除了文本中包含CC12M(Changpinyo et al., 2021)与SBU(Ordonez et al., 2011)中特殊标记的配对。若同一图像对应多个文本,则选取最长的一条。
A.2 视觉问答
对于VQAv2 (Goyal et al., 2017) 数据集,我们依据最高置信度选择答案标注。对于其他VQA数据集,我们未做特殊处理。
A.3 定位
对于GRIT数据集(Peng等人,2023年),我们发现其标注中存在单个描述语句内包含多个递归性指代边界框的情况。为确保每幅图像在避免递归边界框的前提下保留最大数量的标注框,我们采用贪心算法对描述语句进行了清理。对于其他视觉定位数据集,我们直接将名词/短语与其对应的边界框坐标进行拼接。
A.4 OCR光学字符识别
我们采用Synthdog(Kim等人,2022)生成合成OCR数据集。具体而言,我们使用COCO(Lin等人,2014)的train2017和unlabeled2017数据集分割作为自然场景背景,随后选取41种英文字体和11种中文字体生成文本。实验沿用Synthdog的默认超参数设置。我们追踪生成文本在图像中的位置并将其转换为四边形坐标,同时将这些坐标作为训练标签。可视化示例如图5第二行所示。
针对所有收集的PDF数据,我们遵循以下步骤使用PyMuPDF(Software,2015)进行预处理:获取PDF文件中每一页的渲染结果,同时提取所有文本标注及其边界框信息。
- 提取每一页的所有文本及其对应边界框。
- 将每一页渲染并保存为图像文件。
- 移除尺寸过小的图像。
- 移除包含字符过多或过少的图像。
- 移除包含"拉丁字母扩展A区"和"拉丁字母扩展B区"Unicode字符的图像。
- 移除包含"私用区(PUA)"Unicode字符的图像。
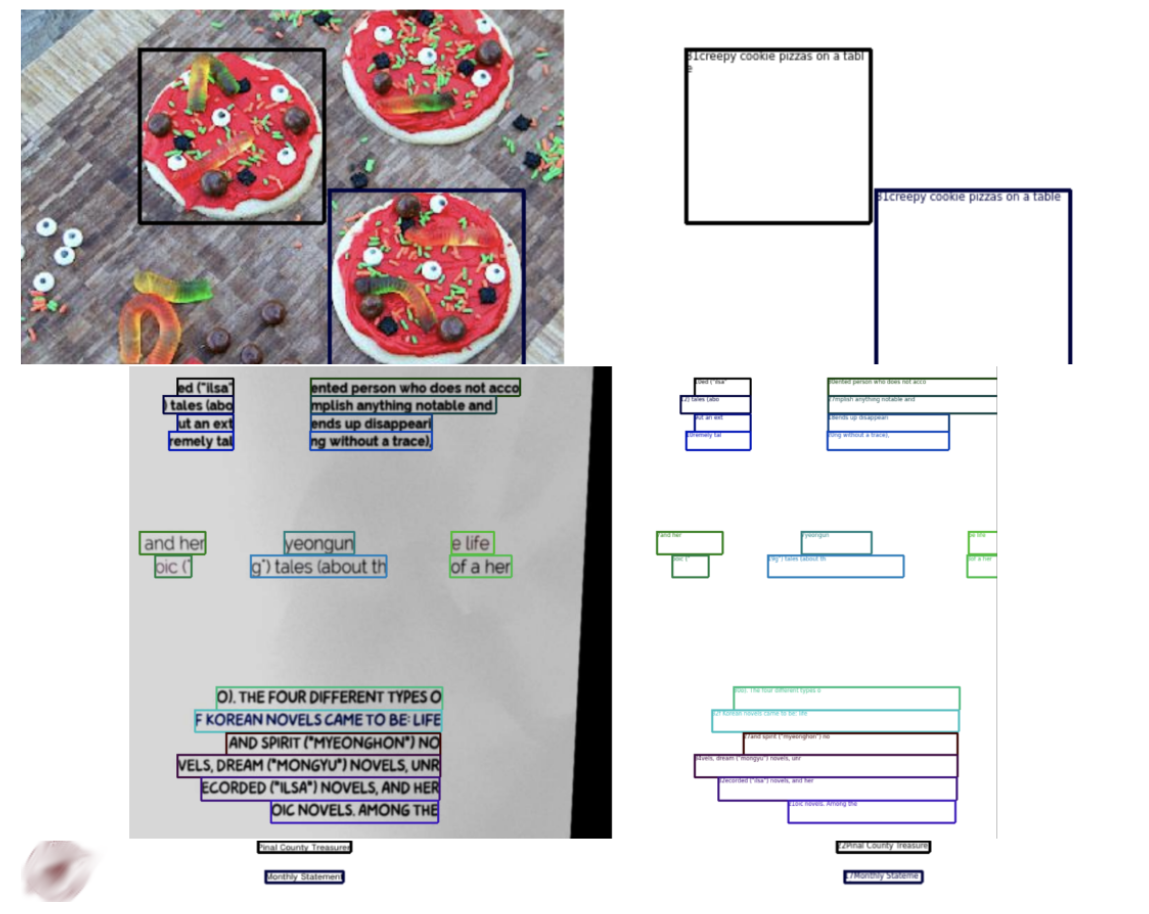
图5:用于训练Qwen-VL的Grounding与OCR数据可视化
对于所有收集到的HTML网页,我们采用与PDF数据相似的处理方法进行预处理,但使用Puppeteer(Google, 2023)替代PyMuPDF来渲染这些HTML页面并获取真实标注数据。我们遵循以下步骤对数据进行预处理。
- 提取每个网页的全部文本。
- 渲染每个页面并将其保存为图像文件。
- 移除尺寸过小的图像。
- 移除包含字符数量过多或过少的图像。
- 移除包含"私人使用区(PUA)"区块中Unicode字符的图像。
B 训练数据格式详情
B.1 多任务预训练数据格式
我们在方框B.1中可视化了多任务预训练的数据格式。该方框包含了全部7项任务,其中黑色文本为无损失计算的前缀序列,蓝色文本为带损失计算的真值标签。
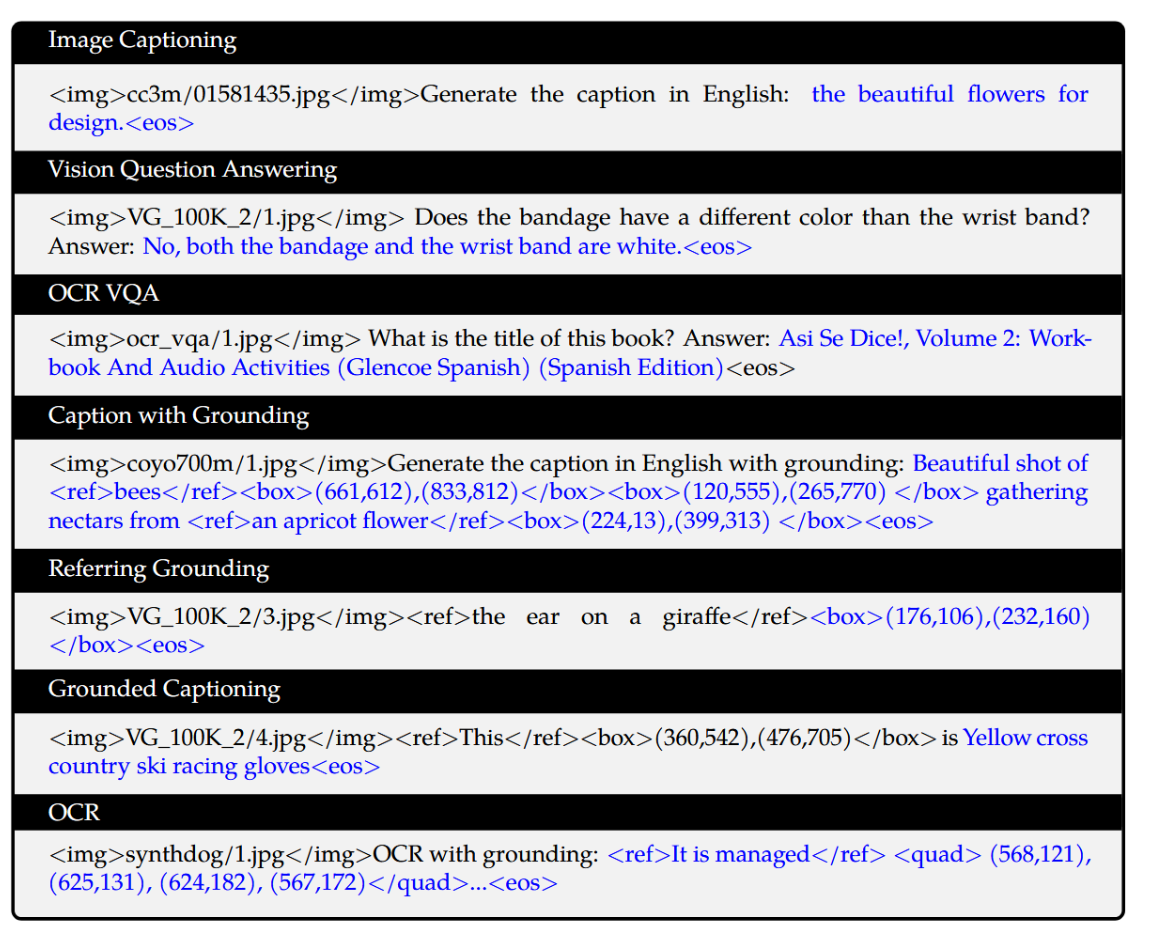
python
图像描述
\<img\>cc3m/01581435.jpg\</img\>生成英文描述:用于设计的美丽鲜花。\<eos\>
视觉问答
\<img\>VG_100K_2/1.jpg\</img\>绷带的颜色和手腕带不同吗?答案:否,绷带和手腕带都是白色的。\<eos\>
OCR视觉问答
\<img\>ocr_vqa/1.jpg\</img\>这本书的标题是什么?答案:Así Se Dice!, 第2卷:练习册与音频活动 (Glencoe西班牙语) (西班牙语版)\<eos\>
带实体定位的描述生成
\<img\>coyo700m/1.jpg\</img\>生成带实体定位的英文描述:<ref>蜜蜂</ref><box>(661,612),(833,812)</box><box>(120,555),(265,770) </box>在<ref>一朵杏花</ref><box>(224,13),(399,313) </box>上采集花蜜的美丽镜头。\<eos\>
指称性实体定位
\<img\>VG_100K_2/3.jpg\</img\>\<ref\>长颈鹿的耳朵\</ref\><box>(176,106),(232,160) </box>\<eos\>
基于定位的描述生成
\<img\>VG_100K_2/4.jpg\</img\>\<ref\>这\</ref\><box>(360,542),(476,705)</box>是黄色越野滑雪竞赛手套\<eos\>
光学字符识别
\<img\>synthdog/1.jpg\</img\>带定位的光学字符识别:<ref>它由</ref>定位 \<quad\> (568,121), (625,131), (624,182), (567,172)\</quad\>...\<eos\>B.2 监督式微调的数据格式
为更好地适应多图像对话与多图像输入场景,我们在不同图像前添加"Picture id:"标识符,其中id对应图像输入对话的次序。在对话格式方面,我们采用ChatML(Openai)格式构建指令微调数据集,每个交互语句均使用两个特殊标记(<im_start>与<im_end>)进行界定,以支持对话终止功能。

python
ChatML数据集格式示例
\<im_start\>user
图片1:<img>vg/VG_100K_2/649.jpg\</img\>图中的标志是什么?\<im_end\>
\<im_start\>assistant
标志是一个橙色菱形的道路封闭标识。\<im_end\>
\<im_start\>user
图中的天气如何?\<im_end\>
\<im_start\>assistant
道路封闭标志的形状是橙色菱形。\<im_end\>在训练过程中,我们仅监督答案和特殊标记(如示例中蓝色部分),不监督角色名称或问题提示,以此确保预测分布与训练分布的一致性。
C 超参数
我们在表8中详细列出了Qwen-VL的训练超参数设置。
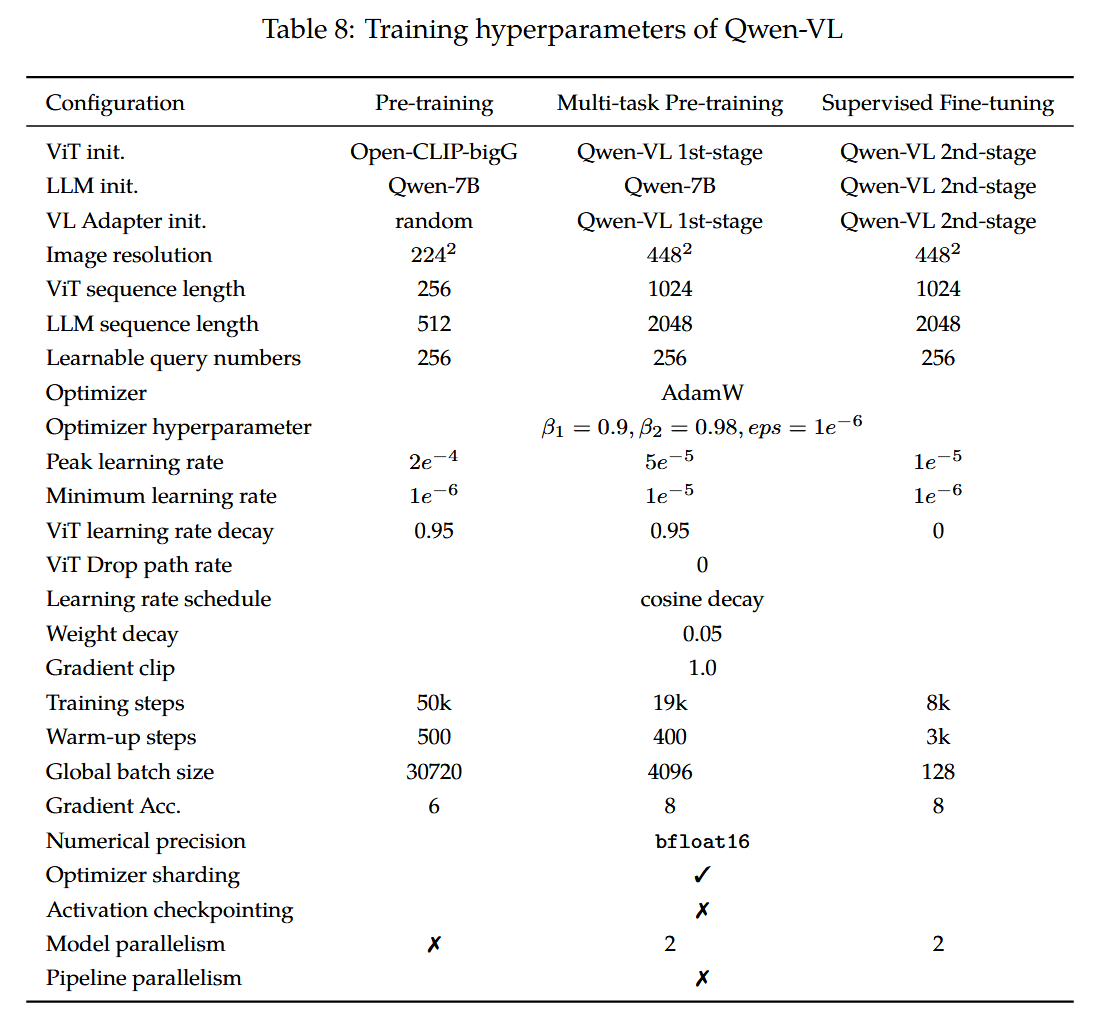
在第一预训练阶段,模型使用AdamW优化器进行训练,参数设置为β1=0.9、β2=0.98、eps=1e−6。我们采用余弦学习率调度策略,最大学习率设为2e−4,最小学习率为1e−6,并进行500步的线性预热。权重衰减设置为5e−2,梯度裁剪阈值设为1.0。对于ViT图像编码器,我们采用分层学习率衰减策略,衰减因子为0.95。训练过程的图像-文本对批次大小为30720,整个第一阶段预训练持续50,000步,消耗约15亿个图像-文本样本和5000亿个图像-文本标记。
在第二阶段的多任务训练中,我们将视觉编码器的输入分辨率从224 × 224提升至448 × 448,以减少因图像下采样造成的信息损失。我们解锁了大语言模型并对整个模型进行训练,其训练目标与预训练阶段保持一致。我们使用AdamW优化器,参数设置为β1 = 0.9,β2 = 0.98,eps = 1e−6。训练共进行19000步,包含400步热身,并采用余弦学习率调度。具体而言,我们对ViT和LLM应用了模型并行技术。
D 评估基准总结
我们在表9中详细汇总了所使用的评估基准及相应指标。
E 附加实验细节
E.1 预训练阶段的收敛性
在图6中,我们展示了预训练阶段(第一阶段)的收敛情况。所有模型均使用BFloat16混合精度进行训练,批次大小为30720,学习率为2e−4。所有图像仅训练一次(一个周期)。随着训练图片数量的增加,训练损失稳步下降。需要注意的是,预训练阶段(第一阶段)未加入任何VQA数据,但零样本VQA分数在波动中呈现上升趋势。
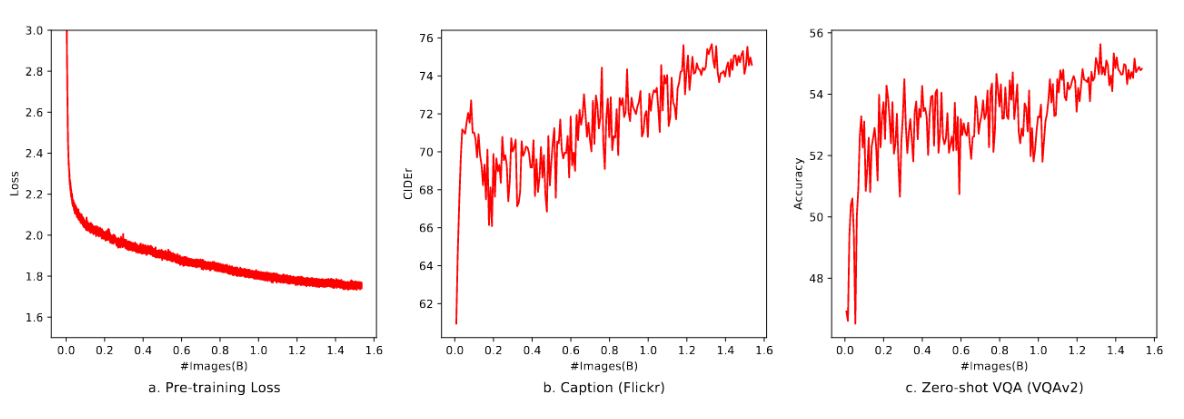
图6:预训练阶段收敛性可视化
E.2 视觉语言适配器中可学习查询的数量
视觉-语言适配器通过交叉注意力机制,使用一组长度固定的学习查询向量对视觉特征序列进行压缩。查询向量过少可能导致部分视觉信息丢失,而查询向量过多则会增加模型收敛难度并提升计算成本。
对视觉语言适配器中可学习查询的数量进行了消融实验。该模型采用ViT-L/14作为视觉编码器,输入图像分辨率为224 × 224,因此ViT输出的序列长度为(224/14)² = 256。如图7左侧所示,训练初始阶段使用的查询数量越少,初始损失值越低。但随着训练收敛,过多或过少的查询都会导致收敛速度减缓,如图7右侧所示。考虑到第二阶段训练(多任务预训练)采用448*448分辨率,此时ViT输出的序列长度为(448/14)² = 1024,过少的查询可能导致更多信息丢失。我们最终在Qwen-VL的视觉语言适配器中选择了256个查询。
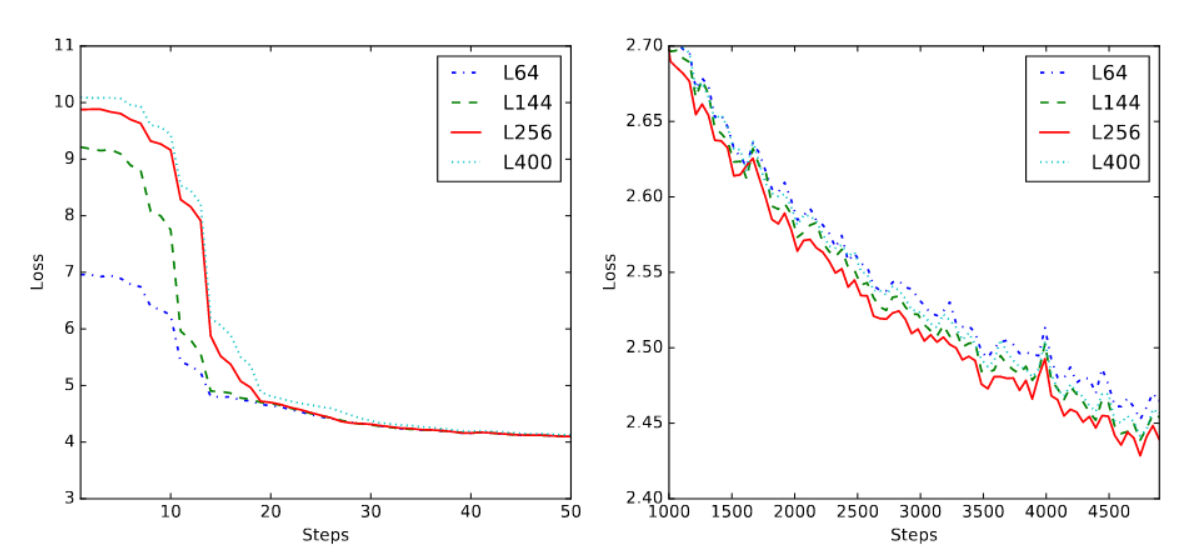
图7:不同视觉语言适配器压缩特征长度下的训练损失可视化。左侧为初始训练损失(50步以内),右侧为收敛阶段的损失(1千至5千步)。图例中,L64表示适配器使用64个查询将视觉特征序列压缩为固定长度64,其余依此类推。损失曲线已进行平滑处理,以避免因波动产生的阴影。
E.3 视觉Transformer中窗口注意力与全局注意力的对比
在模型中使用高分辨率视觉Transformer将显著增加计算成本。一种降低模型计算成本的可行方案是在视觉Transformer中采用窗口注意力机制,即在模型ViT部分的大多数层中仅对224×224的窗口执行注意力计算,仅在ViT部分少数层(例如每4层中的1层)中对完整的448×448或896×896图像执行注意力计算。
为此,我们进行了消融实验,以比较ViT模型在使用全局注意力与窗口注意力时的性能表现。通过对实验结果进行比较,我们分析了计算效率与模型收敛性之间的权衡关系。
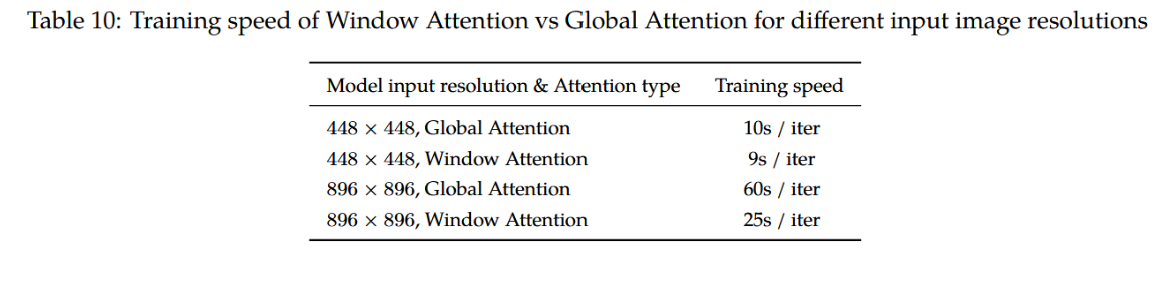
表10:不同输入图像分辨率下窗口注意力与全局注意力的训练速度对比
如图8和表10所示,当使用窗口注意力替代原始注意力时,模型损失显著增高,而两者的训练速度相近。因此,在训练Qwen-VL时,我们决定在视觉变换器中采用原始注意力而非窗口注意力。
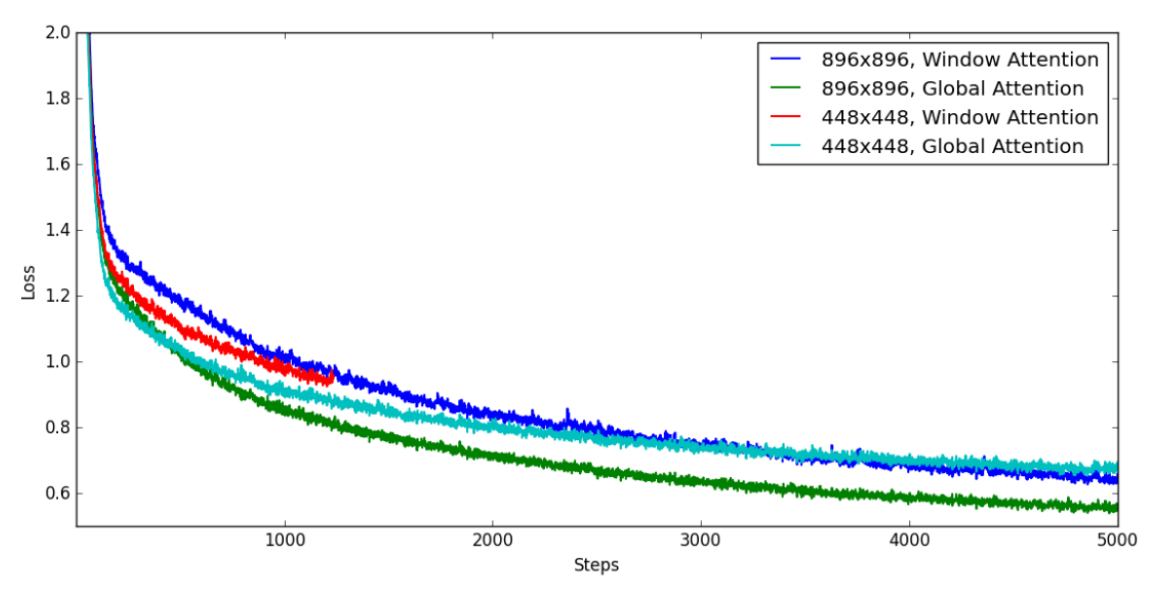
图8:使用窗口注意力与全局注意力时的损失可视化
我们未在896×896分辨率下使用窗口注意力机制的原因是,其训练速度对我们而言过慢。尽管该模型在5000步时达到了与448×448分辨率输入模型相近的损失值,但其训练耗时几乎是后者的2.5倍。
E.4 纯文本任务性能表现
为研究多模态训练对纯文本能力的影响,我们在表11中展示了Qwen-VL在纯文本任务上相较于开源大语言模型的性能。Qwen-VL使用Qwen-7B的一个中间检查点作为大语言模型的初始化。我们未采用Qwen-7B最终发布版检查点的原因在于Qwen-VL与Qwen-7B的开发周期高度重叠。由于Qwen-VL通过Qwen-7B获得了良好的大语言模型初始化,其在纯文本任务上可与许多纯文本大语言模型相媲美。
表11:Qwen-VL在纯文本基准测试中的性能与开源大语言模型对比。由于在多任务训练和指令微调阶段引入了纯文本数据,Qwen-VL的纯文本能力未受任何影响。
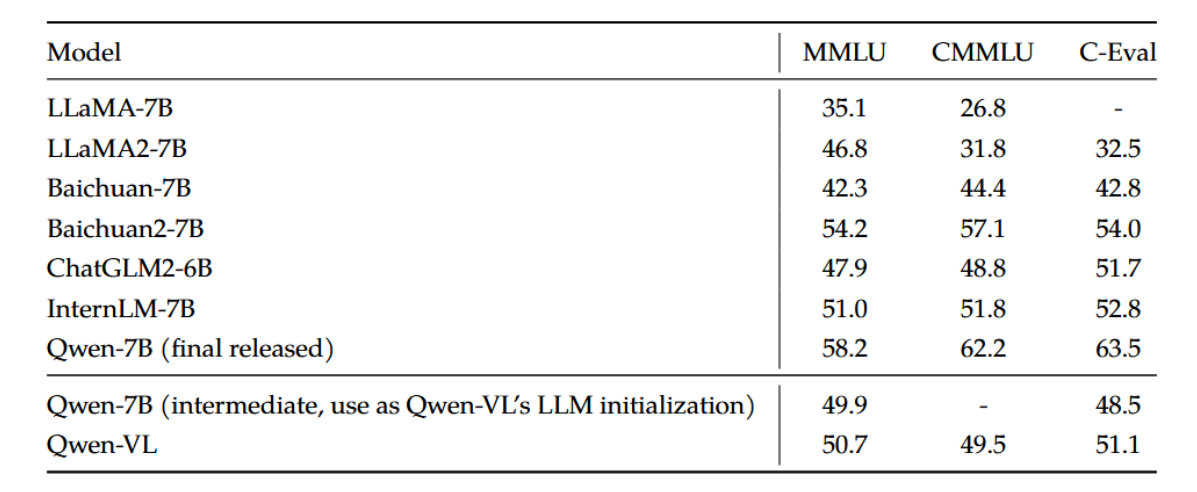
此外,在多任务训练与SFT阶段,Qwen-VL不仅使用了视觉和语言相关的数据,还引入了纯文本数据进行训练。此举旨在借助纯文本数据的信息,防止模型出现文本理解能力的灾难性遗忘。表11的结果表明,Qwen-VL模型在纯文本能力方面不仅未出现下降,甚至在多任务训练后表现有所提升。