很多模型"胡说"的问题,根本不是 hallucination
如果你在真实业务里跑过一段时间 RAG,你大概率会遇到这样一种场景:
- 模型给出的回答
- 每一句话都能在上下文中找到出处
- 甚至引用得"头头是道"
但结论是错的,
而且错得非常自信。
这时候,很多人第一反应是:
"是不是模型 hallucination 了?"
但如果你真的把上下文翻出来看,往往会发现一个令人不安的事实:
模型并不是在编造不存在的东西,
而是在一堆互相矛盾的证据里,选了一个"讲得通的版本"。
这篇文章要讨论的,不是"模型会不会胡说",
而是一个更工程、更残酷的问题:
在 RAG 系统里,
证据不足和证据冲突,
哪一种对模型更致命?
一个先给出来的结论(你可以先记住)
我会很明确地先给出结论,再慢慢解释:
证据不足,往往导致模型不确定;
证据冲突,往往逼模型胡说。
而在真实工程里,
后者比前者危险得多。
为什么"证据不足"反而常常是一个"可控问题"
我们先从"证据不足"说起。
在很多工程师眼里,"证据不足"是一个必须立刻修复的问题:
- TopK 太小
- 文档没召回
- 切分不完整
但如果你从模型行为的角度看,会发现一个非常重要的现象:
当证据不足时,模型更容易表现出"犹豫"。
这种犹豫可能表现为:
- 回答简短
- 使用模糊措辞
- 直接说"不确定""文档中未提及"
从系统风险角度看,这其实是一个相对健康的状态。
模型在"证据不足"时,反而更容易守住边界
这是一个很多人没有意识到的事实。
当上下文里:
- 没有明确结论
- 没有支持性描述
模型的概率空间,其实是被压缩的。
它缺少"可以展开叙事"的素材,
于是更容易:
- 保守
- 简短
- 偏向拒答
这就是为什么在很多系统里:
- TopK 很小
- 上下文很干净
模型反而显得"老实"。
工程上,"证据不足"是可以被明确识别和处理的
从工程视角看,"证据不足"还有一个非常重要的优点:
它是可诊断的。
你可以很清楚地看到:
- 检索没命中
- chunk 不包含结论
- 文档缺失
你可以选择:
- 提示用户
- 返回兜底
- 升级人工
- 或明确标注"不确定"
这些都是显式策略。
再看"证据冲突":真正的灾难从这里开始
现在我们来看"证据冲突"。
证据冲突的典型特征是:
- 多个 chunk 看起来都相关
- 但结论不一致
- 或适用条件不同
而这些 chunk,同时被送进了模型的上下文。
在这种情况下,模型面对的不是"能不能回答",
而是:
在有限时间内,必须选一个说法。
这是生成模型最危险的处境。
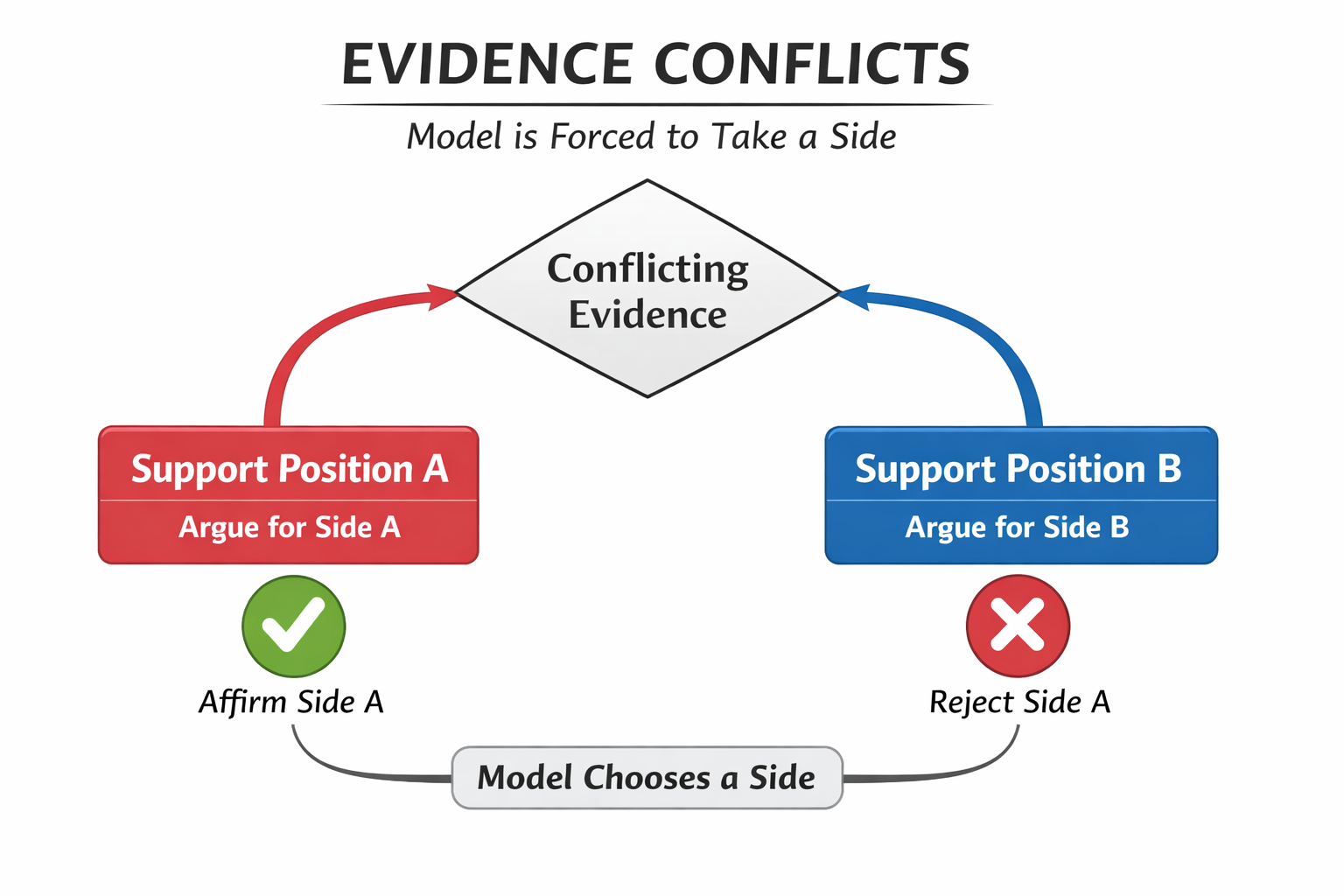
证据冲突 → 模型被迫选边示意图
模型不是裁判,它不会"暂停比赛"
一个非常重要、但经常被误解的事实是:
模型不会因为证据冲突而自动停下来。
它不会说:
- "你们先统一一下再来问我"
相反,它会:
- 尝试综合
- 尝试折中
- 或直接偏向某一方
而这种"选择",并不是基于真实性,
而是基于:
- 哪个表述更完整
- 哪个语气更确定
- 哪个在上下文中出现得更频繁
这也是为什么:
证据冲突时,模型往往"越自信,越危险"。
一个非常真实的例子:规则 + 例外 + 旧版本
这是 RAG 里最常见、也最致命的一种冲突组合。
假设上下文里同时出现:
- chunk A:当前主规则
- chunk B:特殊例外
- chunk C:历史版本说明
对人来说,这三个信息是有层级的。
但对模型来说,它们只是:
- 三段同等权重的文本
于是模型可能会:
- 把例外当成通用规则
- 把旧版本当成当前标准
- 或尝试"综合三者"给出一个不存在的规则
这不是 hallucination,
这是冲突驱动的生成。
规则 / 例外 / 版本冲突示意图
为什么证据冲突,比证据不足更难被发现
这是工程上最痛的一点。
证据不足,通常表现为:
- "没答出来"
- "答得很空"
而证据冲突,表现为:
- "答得很完整"
- "逻辑很顺"
- "引用看起来也对"
如果你不做对照评估,很难第一时间发现问题。
这也是为什么很多系统:
- demo 看起来不错
- 线上却频繁"悄悄答错"
TopK 和证据冲突,是一对天然的放大器
你前面的文章已经铺垫了这一点,这里我们把它说透。
证据冲突本身,并不罕见。
真正的问题在于:
TopK 把本该被过滤掉的冲突证据,一起送进了上下文。
当 TopK 变大:
- 冲突概率指数级上升
- 模型被迫做更多"解释性选择"
于是你看到的就是:
- 回答越来越长
- 但不确定性越来越高
一个很残酷但很真实的结论
我会把这句话写得非常直白:
模型最容易胡说的时候,
不是它不知道答案,
而是它"知道太多不同版本的答案"。
证据不足,模型可能沉默;
证据冲突,模型一定会说点什么。
而工程上,
后者更危险。
为什么 rerank 很难从根本上解决证据冲突
很多团队会寄希望于 rerank。
但这里有一个必须讲清楚的事实:
rerank 解决的是"排序问题",而不是"冲突问题"。
如果:
- 冲突证据本身都排在前列
- 或只是顺序不同
rerank 并不能决定:
- 哪个才是"该信的"
它最多只是:
- 先让模型看到哪一个
但其他冲突信息依然存在。
一个非常实用的工程判断标准
你可以用下面这个问题,判断当前系统更像是"证据不足",还是"证据冲突"。
如果我删掉一半上下文,答案会不会反而更稳定?
- 如果会 → 你很可能在处理证据冲突
- 如果不会 → 你可能真的是证据不足
这个判断,在真实项目里非常好用。
一个简化但极具说明性的对照实验
python
# 原始 TopK
context_full = retrieve(query, top_k=10)
# 精简 TopK
context_small = retrieve(query, top_k=3)
answer_full = llm(context_full, query)
answer_small = llm(context_small, query)
compare(answer_full, answer_small)如果你发现:
- context_small 的回答更短
- 但更稳定、更保守
那问题很可能不在"信息不够",
而在"信息打架"。
工程上,如何"偏向证据不足,而不是证据冲突"
这是一个非常重要的设计取向。
成熟系统,往往会**主动选择"证据不足"**这条路:
- 限制 TopK
- 严控切分质量
- 对冲突内容做预处理
- 宁可拒答,也不乱答
因为在风险管理上:
不确定 ≪ 错得很自信
在判断当前 RAG 问题是"证据不足"还是"证据冲突"时,最大的难点在于:团队很难快速对比不同上下文规模下模型行为的变化。用LLaMA-Factory online并行跑"精简上下文 / 扩展上下文"的对照实验,直接观察回答长度、确定性和一致性,往往能非常直观地看出:模型到底是缺证据,还是被证据冲突逼着胡说。
总结:宁可让模型不知道,也别逼它编一个答案
如果要用一句话作为这篇文章的最终总结,我会写成:
在 RAG 系统里,
证据不足是一个可以管理的问题,
而证据冲突,是一个会失控的问题。
当你意识到这一点,你的设计目标就会发生变化:
- 不再追求"尽量多给"
- 而是追求"尽量干净"
让模型少看一点,
不是保守,
而是对系统长期稳定性的尊重。