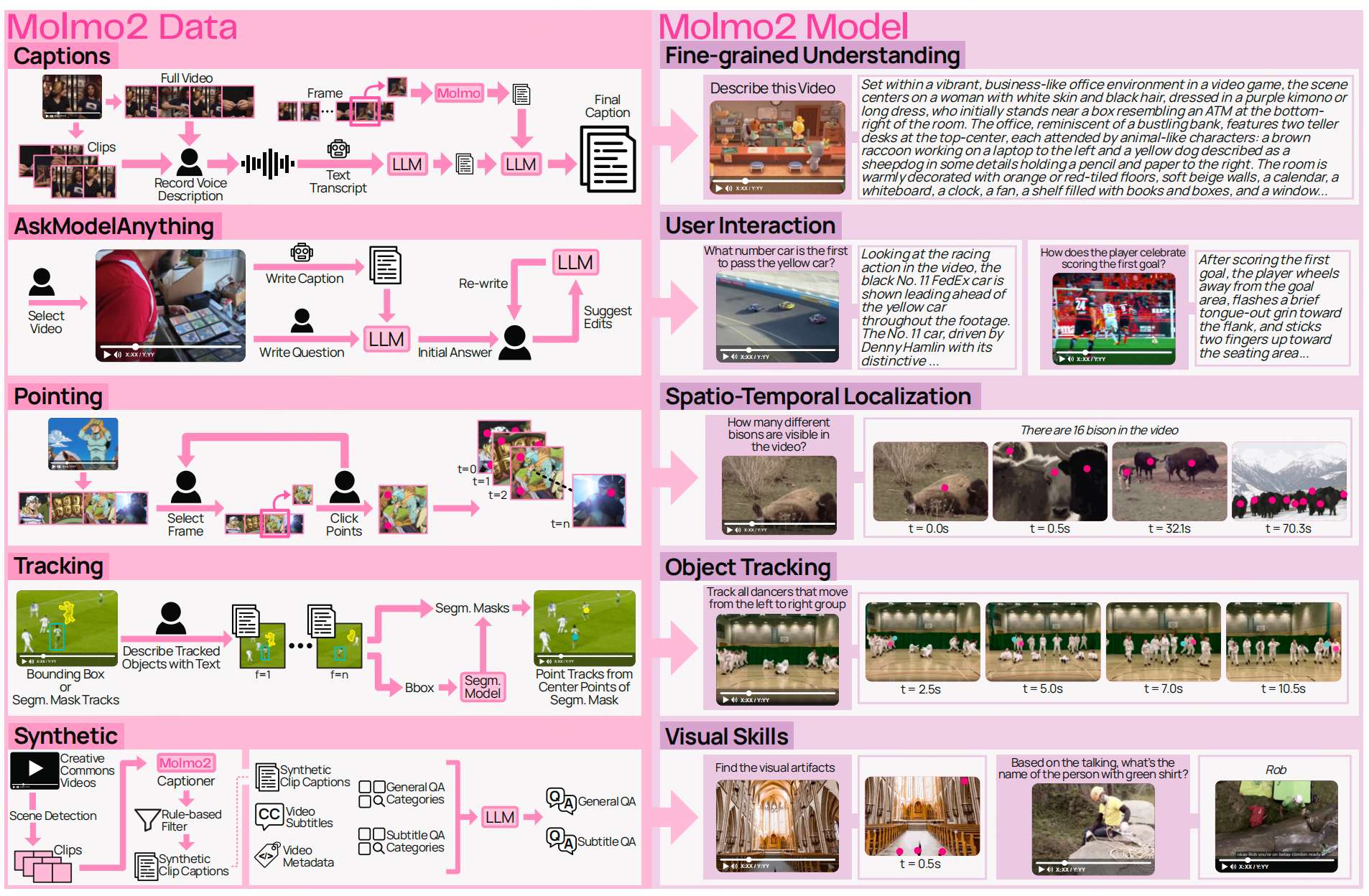
如果想打造自己的VLM模型,不妨看看Molmo2,训练数据、训练配方均开源。
训练数据
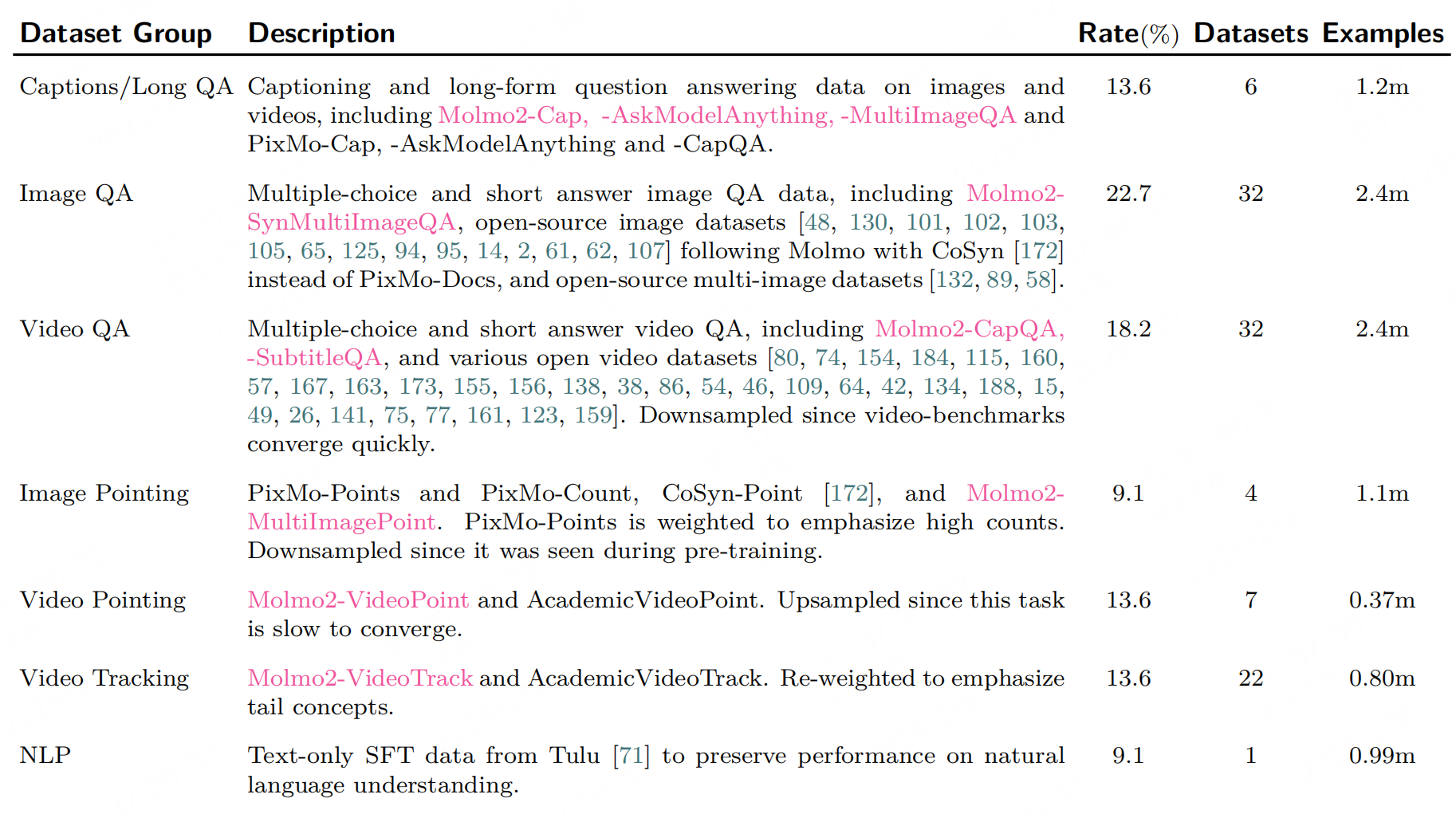
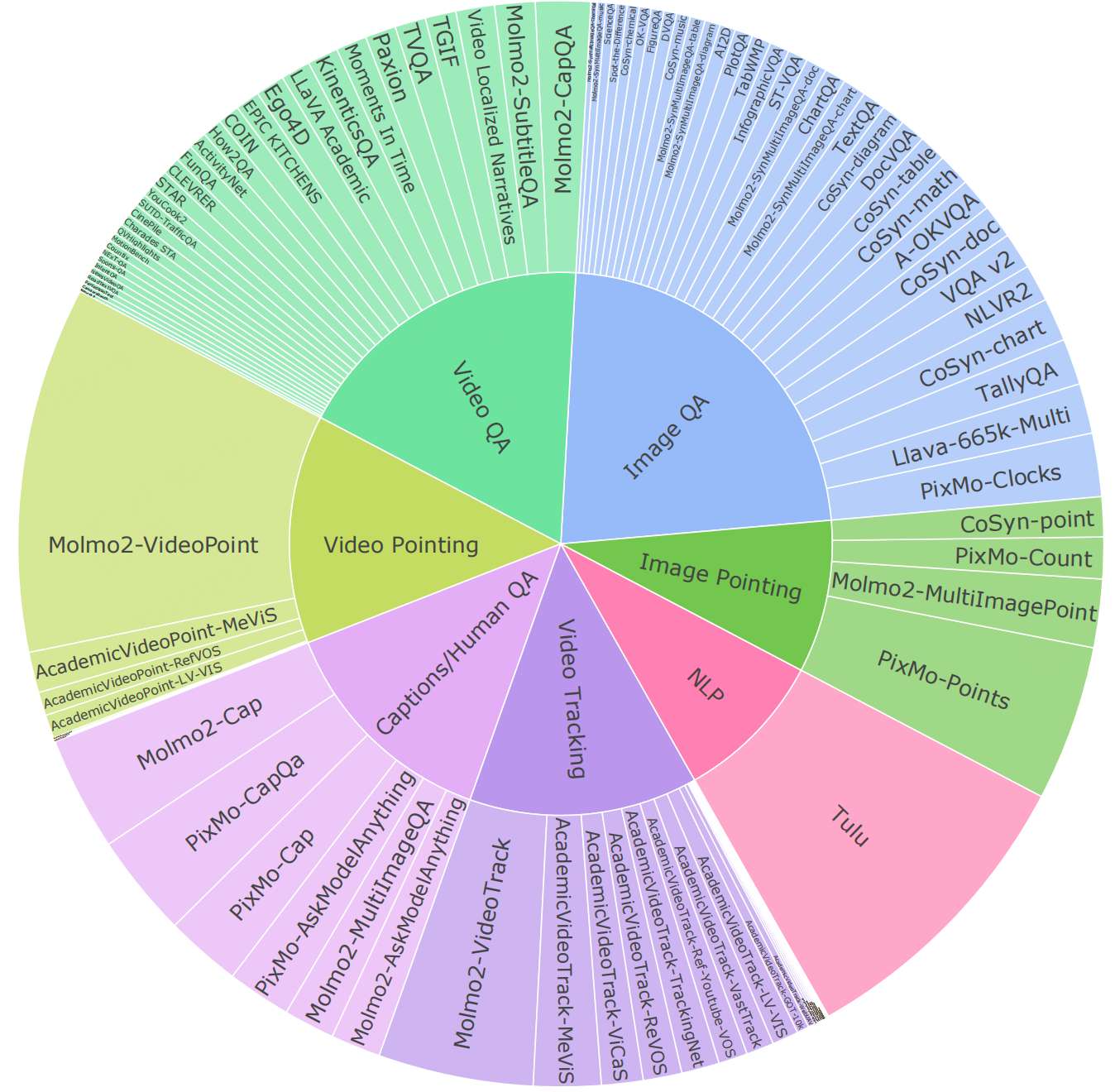
最核心的还是这份开源数据。
模型架构
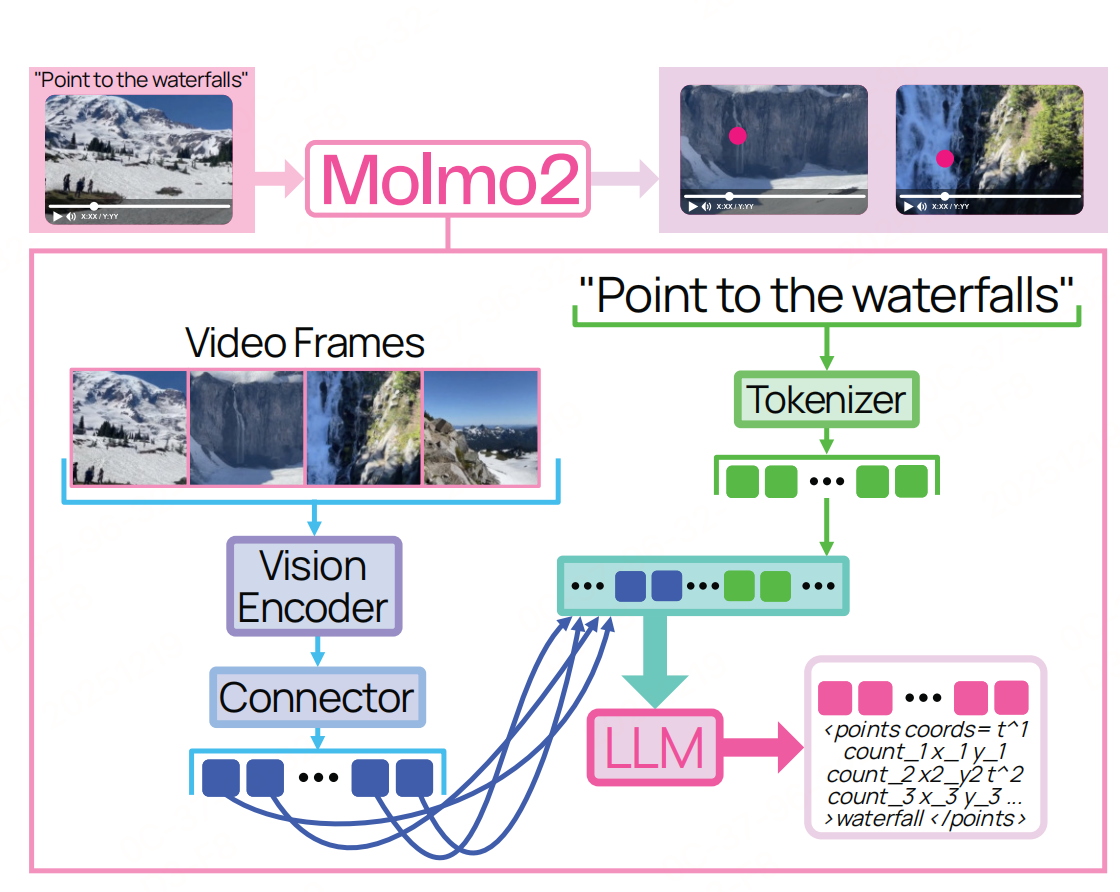
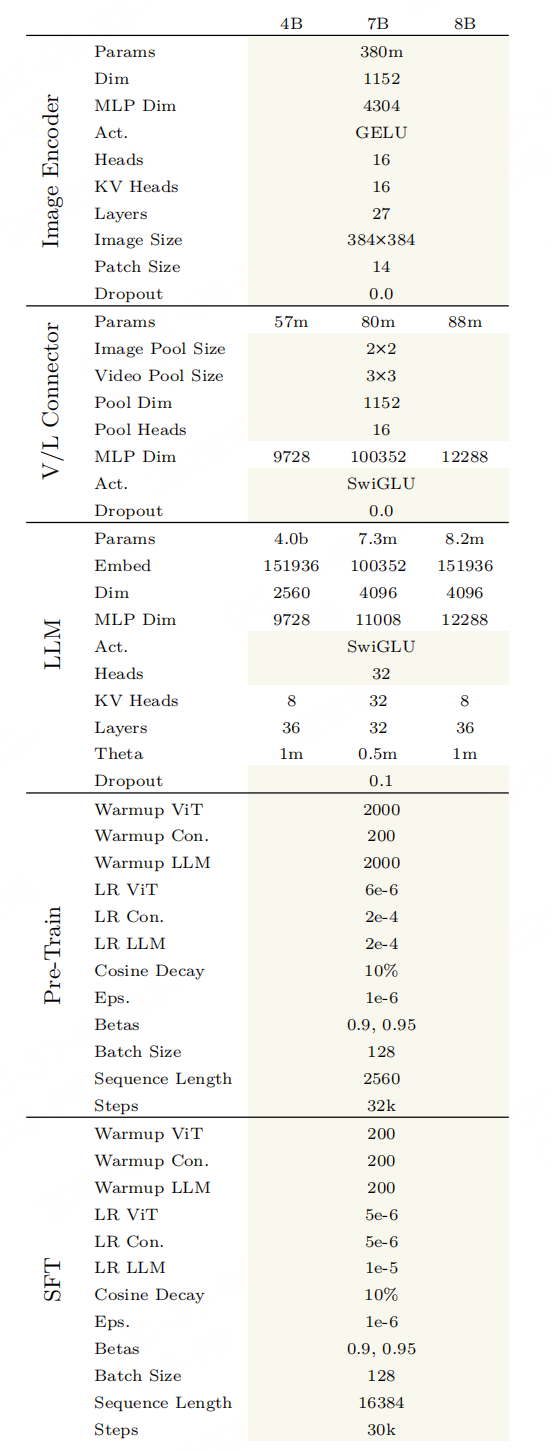
遵循经典的VLM架构:vit+connector(连接器并非使用 ViT 最后一层输出,而是选择ViT 倒数第三层(9th-from-last)和倒数第九层(3rd-from-last)特征(继承自前代 Molmo)+llm,但针对 "视频理解与像素级接地(Grounding)" 核心需求做了优化。目标是高效处理单图像、多图像及视频输入,同时实现时空定位与跨模态语义对齐。
视觉输入的核心挑战是高分辨率细节保留 与长视频计算成本控制。Molmo2 针对图像和视频设计了不同的裁剪方案。
1. 图像裁剪:多重叠裁剪实现高分辨率覆盖
为解决单裁剪丢失细节的问题,采用"单裁剪 + 多重叠裁剪"的组合策略:
- 基础裁剪:将图像下采样后生成 1 个"基础裁剪块"(默认尺寸与 ViT 输入匹配,如 384×384);
- 重叠裁剪 :额外生成最多 K K K 个重叠裁剪块平铺图像(训练时 K = 8 K=8 K=8,推理时 K = 24 K=24 K=24),覆盖图像边缘与细节区域;
- 适配逻辑 :若图像尺寸无法被 K K K 个裁剪块整除,则先下采样至可平铺尺寸,避免黑边填充导致的特征噪声。
多裁剪策略让模型能捕捉图像局部细粒度特征(如小物体、文本),为"图像指向(Pointing)""计数"等定位任务提供像素级支撑。
2. 视频裁剪:低帧率采样 + 帧筛选控制token成本
视频处理的核心是平衡"时间覆盖范围"与"计算量":
- 帧率采样 :以 S = 2 S=2 S=2 FPS(帧/秒)采样视频帧,单帧按图像裁剪逻辑处理(仅用单裁剪,避免多裁剪导致的 Token 爆炸);
- 帧数量限制 :设置最大帧数 F F F(常规训练 F = 128 F=128 F=128,长上下文训练 F = 384 F=384 F=384):
- 若视频时长 > F / S F/S F/S(如 128 帧 / 2 FPS = 64 秒),则均匀采样 F F F 帧,确保覆盖视频全时段;
- 强制保留"最后一帧":因多数视频播放器结束后会停留在最后一帧,该帧对用户交互(如"视频结尾的物体是什么")具有特殊意义。
- 时间戳对齐:采样帧的时间戳基于视频实际时长计算(而非帧索引),确保动态视频的时间维度准确性(如"0.5s 时物体位置")。
注意力掩码
确保模型在高效打包训练(多个短示例合并为一个长序列)时,仍能精准学习单任务的语义关联。
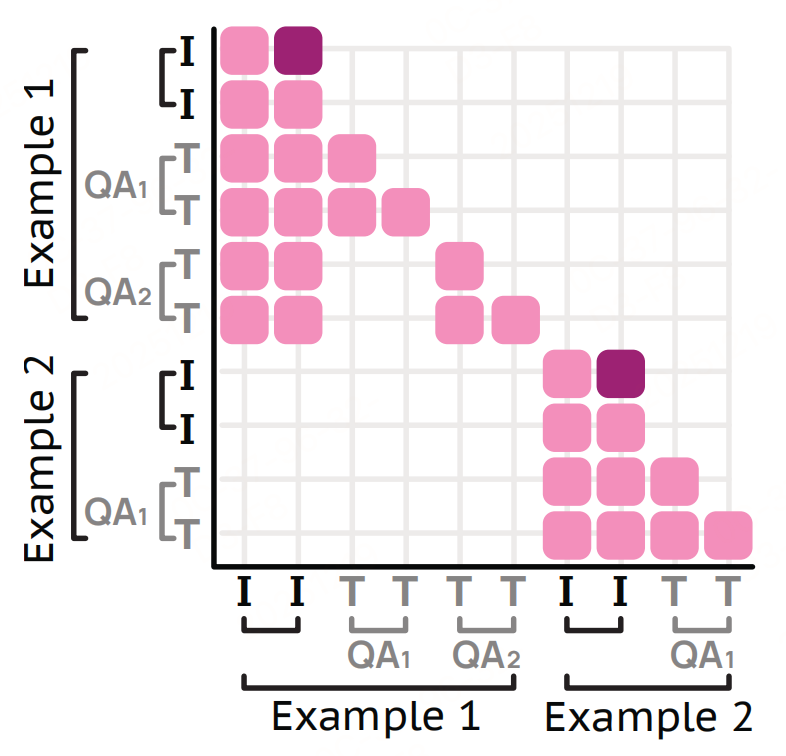
上图:一个包含两个样本的 packed 序列的注意力掩码。第一个样本包含一张图像的两对问答。帧标记(深粉色)具有前向注意力,而掩码块则屏蔽了不同样本之间的交叉注意力(左下角空白块)以及同一样本内不同问答对之间的交叉注意力(上方空白块)。
- 跨示例掩码:不同训练示例的视觉 Token/文本之间不允许注意力交互,避免无关信息干扰;
- 跨任务掩码:同一示例的不同标注任务(如同一视频的" caption 生成"与"指向")之间不互相关注,防止任务间梯度冲突;
训练配方
训练采用三阶段递进式 pipeline(预训练→监督微调→长上下文微调),核心目标是从"图像基础能力"逐步扩展到"视频-图像联合理解"与"长上下文Grounding"。
1. 阶段1:轻量级图像预训练
- 图像字幕数据:PixMo-Cap( dense 图像字幕),占比 60%,用于学习视觉 - 文本语义关联;
- 图像指向数据:PixMo-Points(图像指向)、PixMo-Count(图像计数)、CoSyn-Point(文本 - rich 图像指向),占比 30%,提前让模型掌握 "像素级定位" 格式与逻辑;
- NLP 数据:Tulu的监督微调数据(过滤非英文与代码),占比 10%,避免视觉训练导致语言能力退化。
2. 阶段2:SFT
整合图像、视频、多图像数据,让模型掌握"视频理解""跨模态 QA""视频指向/跟踪"等核心任务,是能力扩展的核心阶段。
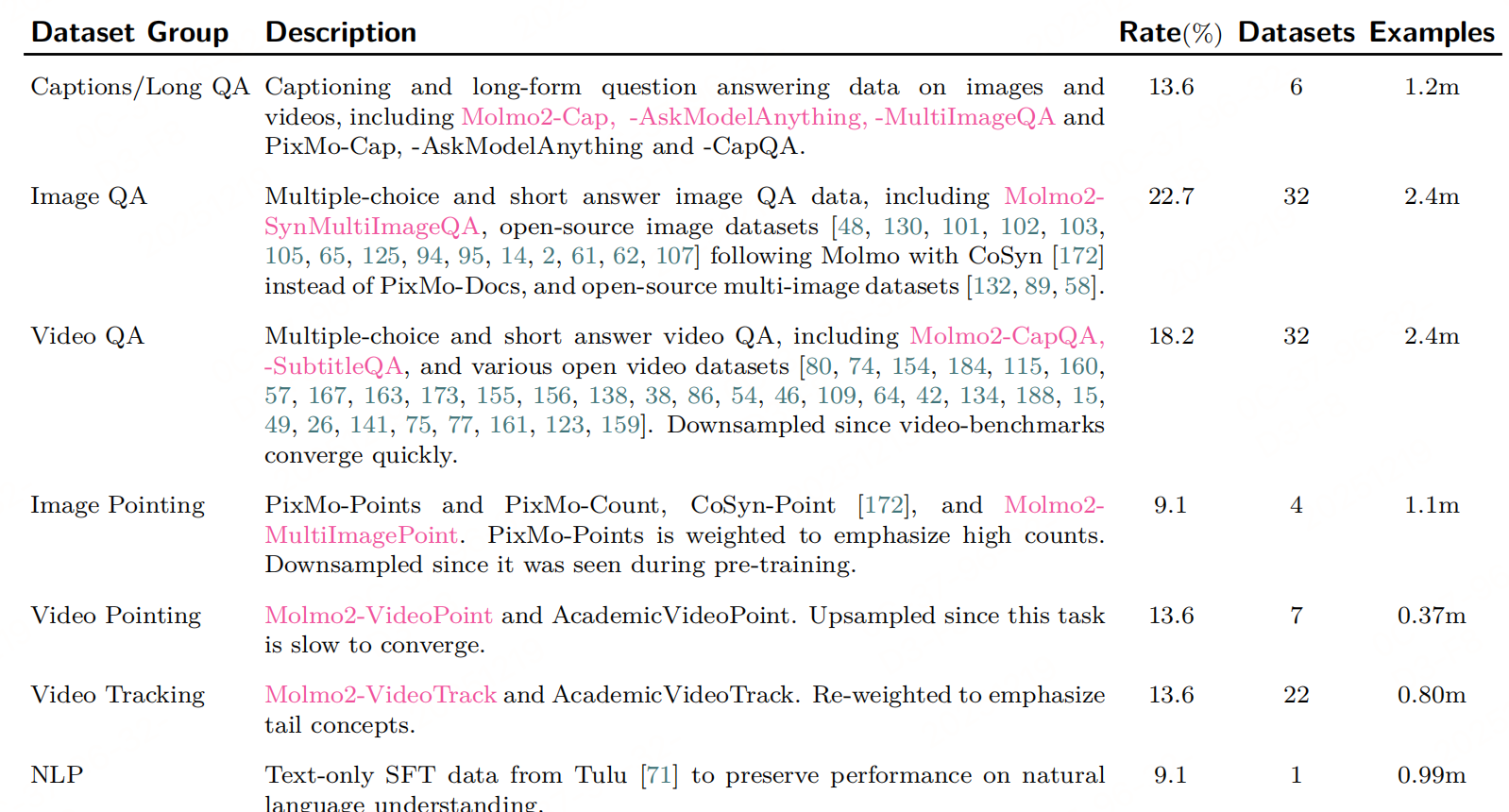
3. 阶段3:长上下文微调
解决"长视频(>64 秒)理解"短板,支持更多帧输入与更长文本上下文,适配实际场景中长时序视频分析需求。序列长度从 16k 提升至 36,864,视频最大帧数从 128 增至 384(仍按 2 FPS 采样,覆盖最长 192 秒视频)
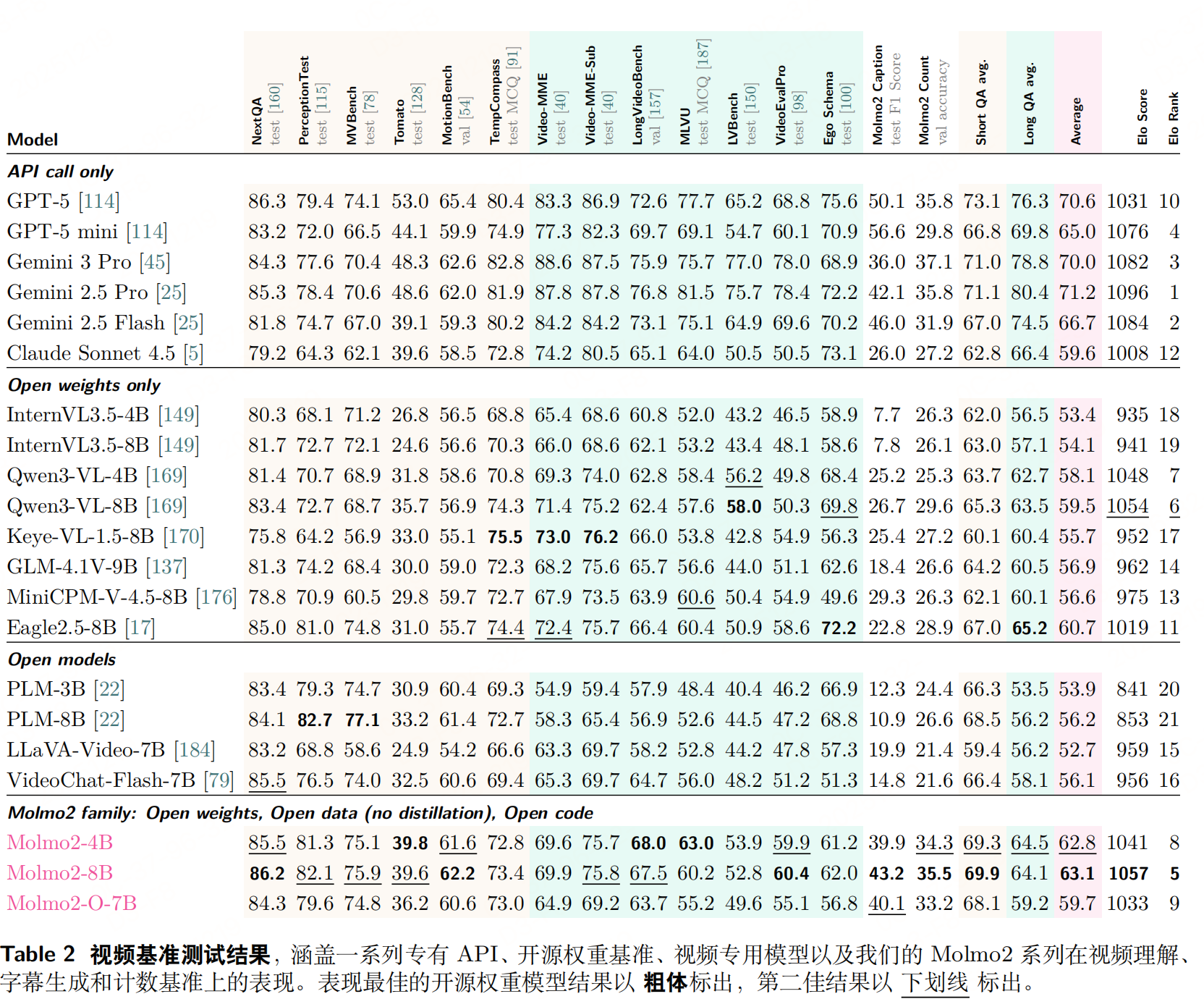
实验
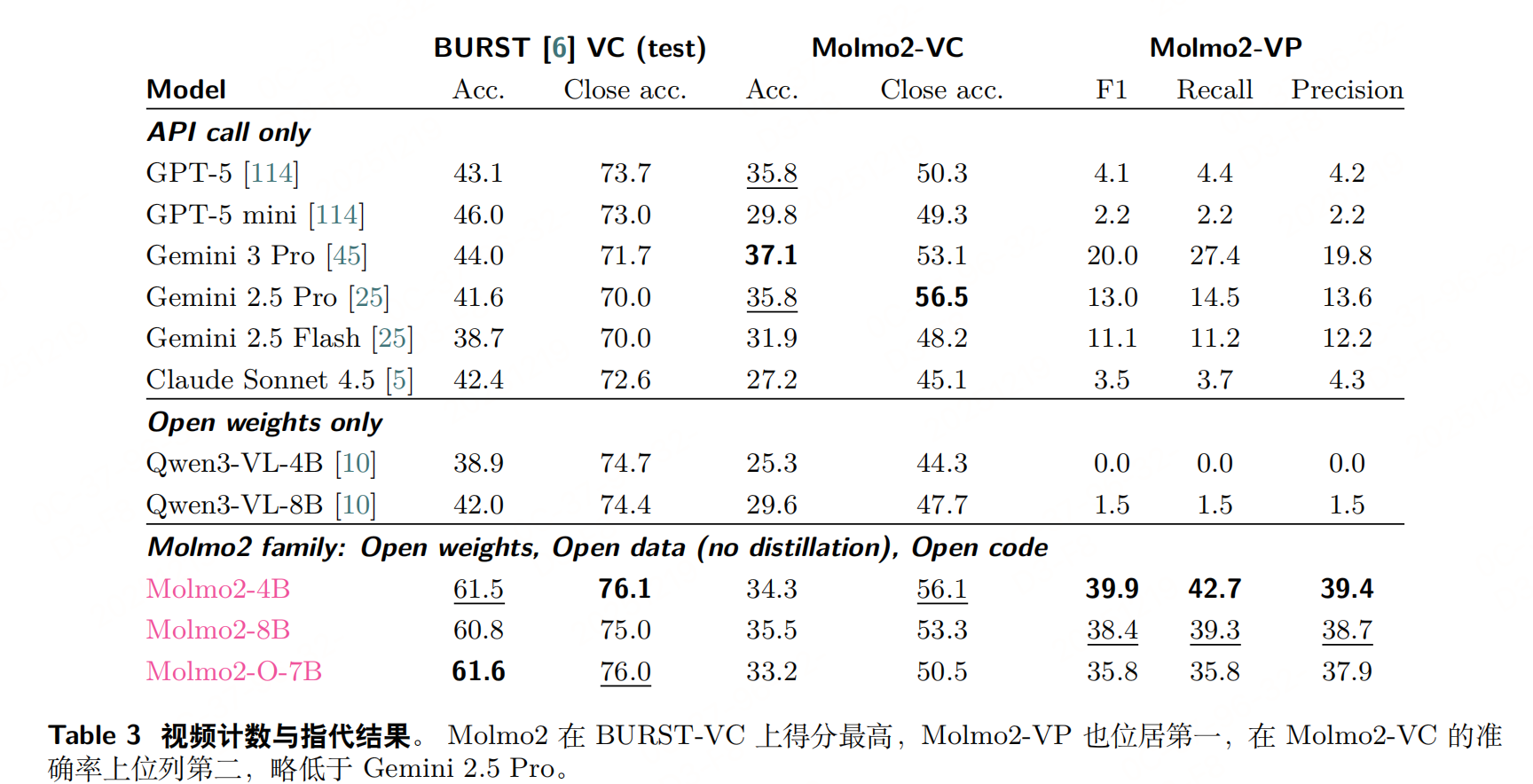
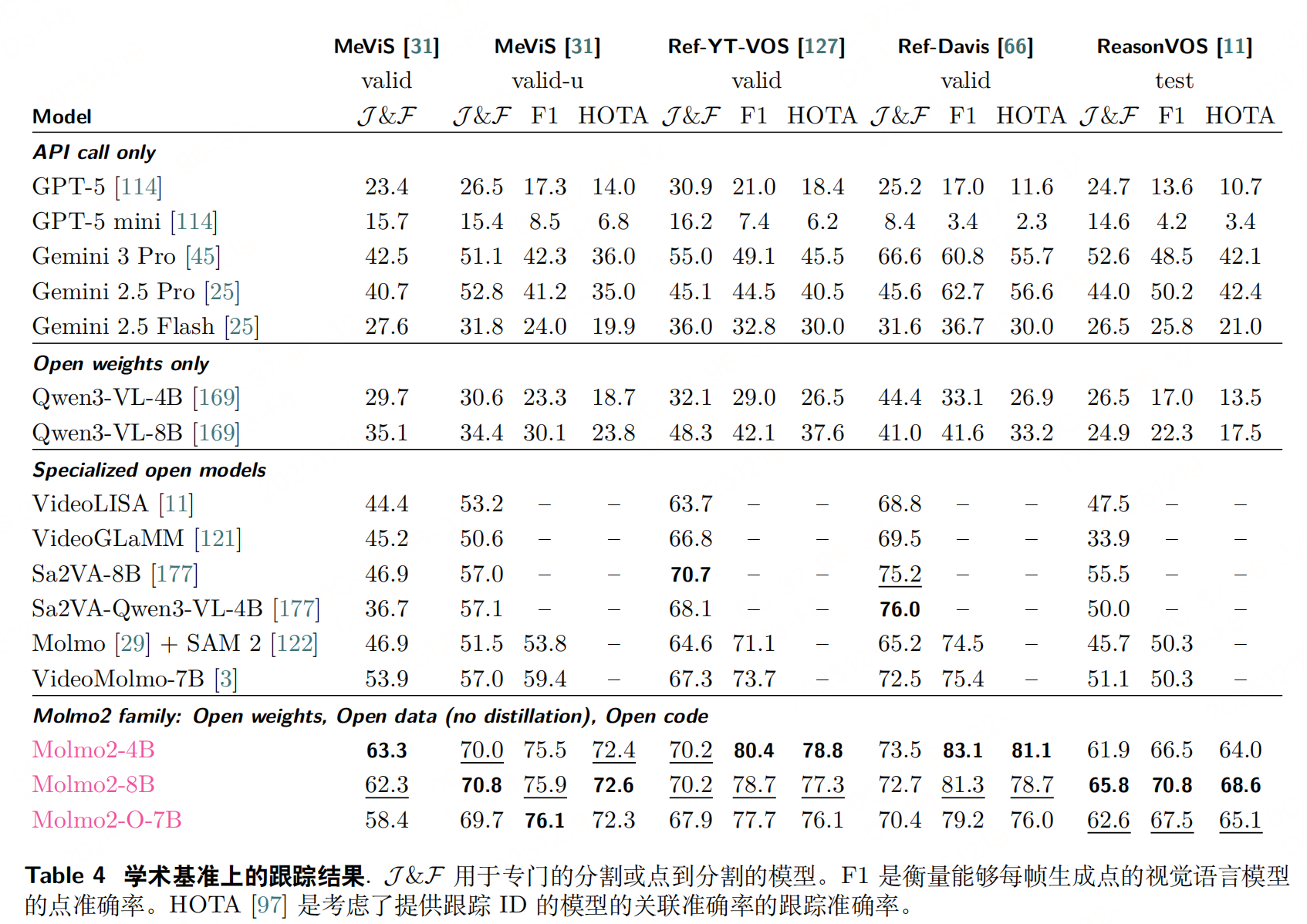
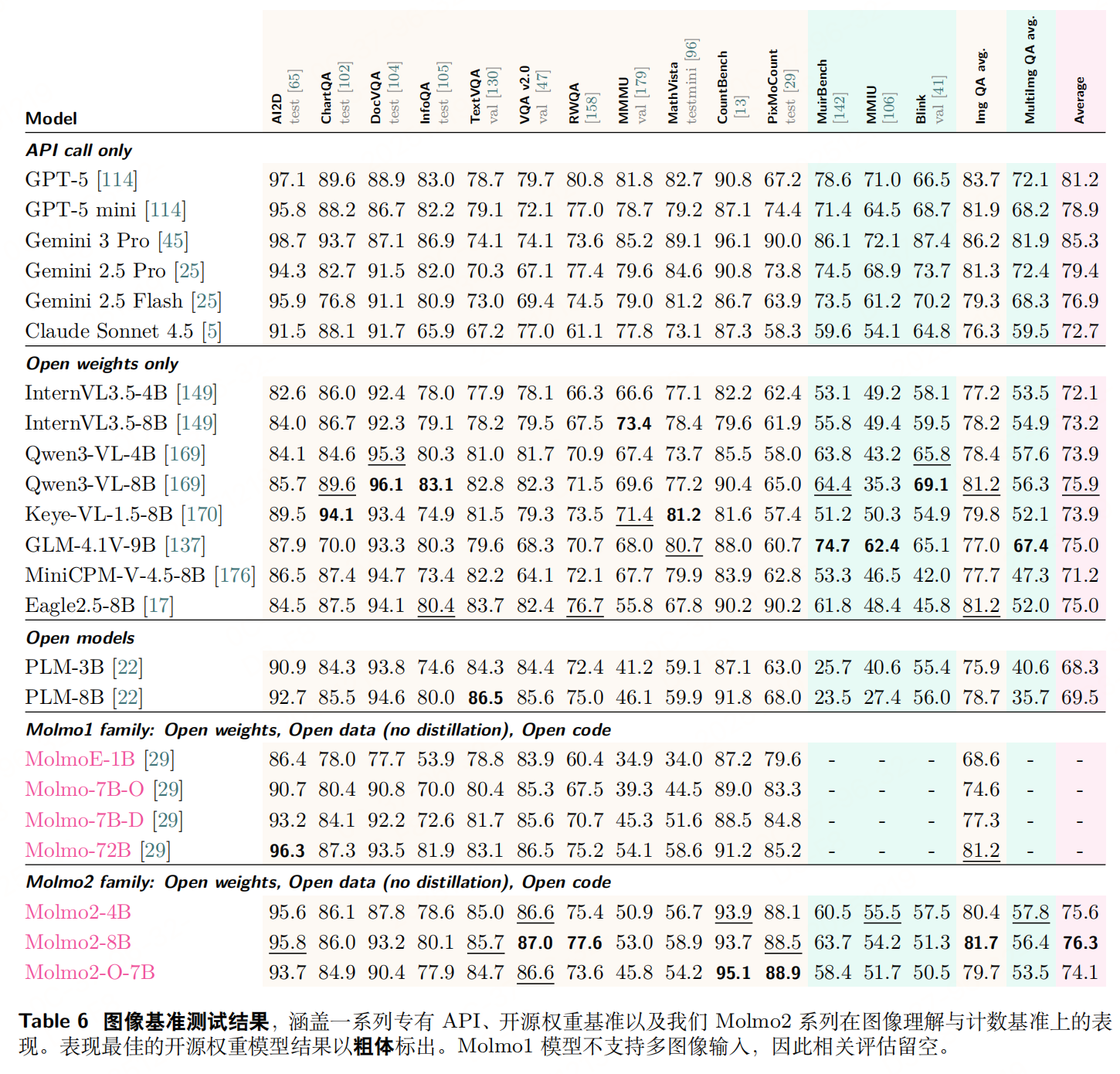
总结
Molmo2 的训练设计围绕"从专到博、效率优先"原则:先通过图像预训练夯实基础,再用多源混合数据扩展多模态能力,最后通过长上下文微调补全短板;同时以 Token 加权、Packing、消息树等技巧解决多模态训练的核心痛点,最终实现"开源模型中视频接地性能领先"(如视频指向 F1 38.4 超越 Gemini 3 Pro 的 20.0)。
参考文献
- Molmo2:Open Weights and Data for Vision-Language Models with Video Understanding and Grounding,https://arxiv.org/pdf/2601.10611