一、 Agent与LangChain结合机制
LangChain 1.0通过将Agent的决策与LangGraph的图式执行相结合,提供了生产级的Agent运行时。其结合机制体现在以下几个方面:
1 核心结合点:create_agent + LangGraph
create_agent作为上层统一入口,其内部实现依赖于LangGraph。当调用create_agent时,LangChain会自动构建一个基于ReAct(推理+行动)范式的图结构。这个图包含了Agent决策、工具调用、状态更新等核心节点,并通过边来控制逻辑流转。这种设计将Agent的"思考"过程映射为图的遍历,使得整个执行流程变得透明、可控。
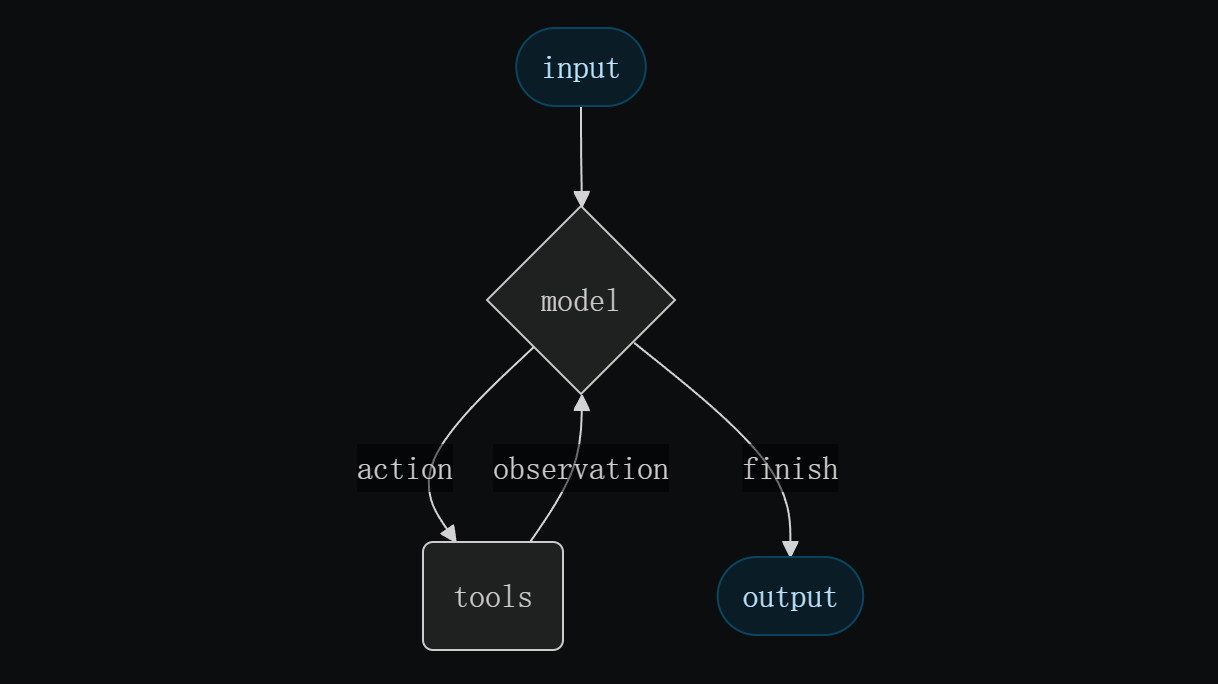 * LangChain 1.0 的 create_agent 凭借 9 个核心参数,实现了从快速原型验证到生产级部署的全场景覆盖,开发者可根据实际业务场景灵活组合配置,大幅降低 Agent 开发的门槛与复杂度。
* LangChain 1.0 的 create_agent 凭借 9 个核心参数,实现了从快速原型验证到生产级部署的全场景覆盖,开发者可根据实际业务场景灵活组合配置,大幅降低 Agent 开发的门槛与复杂度。
-
create_agent 的核心价值,在于通过「三要素 + 三扩展」的极简抽象范式,彻底重构了 Agent 的开发逻辑。其中,「三要素」------ 模型(Model)、工具(Tools)、提示词(System Prompt)是 Agent 的核心骨架:模型决定其思考能力,工具定义其可执行的操作范围,提示词划定其行为边界,三者共同构成 Agent 的核心能力底座。而「三扩展」------ 中间件(Middleware)、内存管理(Memory)、状态管理(State)则是 Agent 的生产级保障:它们为 Agent 赋予了生产环境所需的可靠性、可观测性与可维护性,如同为 Agent 搭建了稳定的「神经系统」。
-
这一设计将开发者从底层细节中彻底解放:无需手写繁琐的 ReAct 循环、手动处理工具调用异常、编写上下文压缩逻辑等,转而采用声明式编程模式 ------ 只需描述「Agent 应该实现什么目标」,框架便会自动将其编译为高效、可靠且安全的执行计划。本质上,create_agent 是 LangGraph 的编译器前端,能够将开发者的高层业务意图,转化为优化后的图结构,并自动集成持久化、流式输出、断点恢复等核心运行时能力。
这种架构带来了三重革命性价值:其一,开发效率提升 10 倍,仅需 10 行代码即可构建出可直接投产的智能客服、数据分析等 Agent 应用;其二,运维成本降低 60%,中间件机制可将 PII 检测、人工审批、自动重试等横切关注点与业务代码解耦,无需侵入核心逻辑即可实现;其三,可扩展性实现质的突破,通过 TypedDict 扩展 State 结构,能够无缝集成用户画像、多模态输入、性能监控等复杂业务场景需求。
| 参数 | 类型 | 必填 | 默认值 | 核心作用 | 最佳实践 |
|---|---|---|---|---|---|
model |
str/实例 | ✅ | - | 推理引擎 | 生产环境实例化配置 |
tools |
list | ✅ | \[\] | 执行能力 | 描述清晰,按需添加 |
system_prompt |
str | ❌ | None | 行为准则 | 明确角色和约束 |
middleware |
list | ❌ | \[\] | 功能扩展 | 组合日志、安全、摘要 |
checkpointer |
Saver | ❌ | None | 短期记忆 | 生产用 PostgresSaver |
store |
Store | ❌ | None | 长期记忆 | 跨会话用 PostgresStore |
state_schema |
TypedDict | ❌ | AgentState | 扩展状态 | 用 TypedDict 非 Pydantic |
context_schema |
TypedDict | ❌ | None | 动态上下文 | 配合 middleware 使用 |
response_format |
BaseModel | ❌ | None | 结构化输出 | API 对接场景启用 |
python
from langchain.agents import create_agent
agent = create_agent(
model=model, # 模型
tools=[order_query_tool], # 工具
system_prompt="你是一个订单查询助手,能够查询订单状态和明细。" , # 系统提示
middlewares=[order_query_middleware], # 中间件
checkpointer=checkpointer, # 检查点短期记忆
store=store, # 状态存储长期记忆
state_schema=OrderQueryState, # 扩展状态(如需要)
context_schema=AgentContext, # 上下文状态(如需要)
response_format=ResponseModel # 结构化输出(如需要)
)
# ============ 限制最大 3 次循环 ============
config = {
"configurable": {"thread_id": "limit_demo"}, # 限制thread_id 线程ID
"recursion_limit": 3 # 最多 3 次迭代,或使用中间件进行精确跟踪和终止循环
}
result = agent.invoke(
{"messages": [{"role": "user", "content": "LangChain 1.0 发布日期"}]},
config=config
)二、 工具(Tools)的集成与调用
工具是Agent与外部世界交互的桥梁。在LangChain中,工具的name、description和args_schema至关重要,它们共同决定了模型是否以及如何选择和调用工具。一个设计良好的工具描述是提示工程的关键部分。
- 工具注册 :通过
@tool装饰器或继承BaseTool类来定义工具。 - 工具调用:Agent在决策时,会根据工具描述选择最合适的工具。执行引擎负责调用该工具并处理其返回结果或异常。
- 安全与治理:在生产环境中,应对工具的调用进行严格的风险控制,如速率限制、权限隔离、输入校验等,这些可以通过中间件或在工具实现中直接加入。
- LangChain的tool介绍:https://docs.langchain.com/oss/python/langchain/tools 和 https://reference.langchain.com/python/langchain/tools/
- LangChain内置工具列表:https://python.langchain.com/docs/integrations/tools/
| 工具名 | Python 类 | 作用 |
|---|---|---|
| python_repl | PythonREPLTool |
执行 Python |
| shell | ShellTool |
执行命令行 |
| human | HumanTool |
人工输入 |
| requests_get | RequestsGetTool |
GET 请求 |
| requests_post | RequestsPostTool |
POST 请求 |
| bing_search | BingSearchRun |
Bing 搜索 |
| serper | GoogleSerperRun |
Google 搜索 |
| tavily_search | TavilySearchResults |
Tavily 搜索 |
| web_loader | WebBaseLoader |
网页加载 |
| apify | ApifyActorTool |
网页爬虫 |
| gmail | Gmail 工具 | 邮件管理 |
| google_calendar | GoogleCalendar 工具 | 日程管理 |
| python_ast | PythonAstREPLTool | 数据分析安全执行器 |
| read_file | ReadFileTool | 读取文件 |
| write_file | WriteFileTool | 写入文件 |
| sql_db_query | QuerySQLDatabaseTool | SQL 查询 |
| retriever | VectorStoreTool | RAG 检索 |
python
# 环境依赖版本
pip list | grep langchainlangchain 1.2.7
langchain-classic 1.0.1
langchain-community 0.4.1
langchain-core 1.2.7
langchain-deepseek 1.0.1
langchain-openai 1.1.7
langchain-tavily 0.2.17
langchain-text-splitters 1.1.0
langgraph 1.0.7
langgraph-checkpoint 4.0.0
langgraph-prebuilt 1.0.7
langgraph-sdk 0.3.3
langsmith 0.6.4
python
#python 版本
!python --versionPython 3.12.121.使用网络搜索工具
python
# pip install langchain-tavily优先使用支持 Function Calling 的模型(如 GPT-4o、Qwen)
python
# 定义带速率限制的load_chat_model函数
from langchain.chat_models import init_chat_model
from langchain_core.rate_limiters import InMemoryRateLimiter
from langchain.agents import create_agent
from langchain_tavily import TavilySearch
limiter=InMemoryRateLimiter(
requests_per_second=5, # 每秒最多5个请求
check_every_n_seconds=1.0 # 每1秒检查一次是否超过速率限制
)
# 2.导入模型和工具
#tavily介绍: https://docs.langchain.com/oss/python/integrations/tools/tavily_search
web_search = TavilySearch(max_results=2,
tavily_api_key='tvly-dev-xxxxxx')
def load_chat_model():
return init_chat_model(
model='deepseek-chat', # 模型名称
model_provider='deepseek', # 模型供应商
temperature=0.5, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=512, # 最大生成token数
base_url='https://api.deepseek.com',
api_key='sk-xxx',
rate_limiter=limiter # 自动限速
)
if __name__ == '__main__':
agent=create_agent(
model=load_chat_model(),
tools=[web_search],
system_prompt="你是一个智能助手,可以调用工具帮助用户解决问题。"
)
question="帮我查询2026年1月份关于ai的最新新闻"
result=agent.invoke({
"messages":[
{"role":"user",
"content":question
}
]
})
print(result)
print(result['messages'][-1].content)2.自定义tool工具使用
2.1 使用@tool装饰器来定义工具
@tool装饰器是LangChain中最简单、最直观的工具创建方式。它通过装饰器语法将普通Python函数转换为Agent可调用的工具,适合快速原型开发和简单工具实现。
技术概述:
-
自动参数推断:基于函数签名自动生成工具的参数schema
-
简化配置:只需提供工具名称和描述即可快速创建
-
同步执行:默认支持同步函数调用,异步需要单独定义
-
快速验证:适合概念验证和快速迭代开发
核心优势:
-
代码简洁,一行装饰器即可完成工具注册
-
无需复杂的类继承和配置
-
与Python函数无缝集成,开发效率高
适用场景:
-
快速原型验证
-
简单工具实现
-
开发测试阶段
python
from langchain_core.tools import tool
from langchain.agents import create_agent
# 1. 定义一个简单的 Tool (Runnable)
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
# 2.导入模型
model = load_chat_model(
model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
provider="openai", # 指定模型提供商为openai
)
# 3.创建Agent
agent = create_agent(model=model,tools=[multiply])
# 4. 调用Agent
response = agent.invoke({
"messages": [{
"role": "user",
"content": "帮我计算12乘以6等于多少?"
}]
})
response["messages"]
response["messages"][-1].content- 使用LangGraph Studio 查看Agent结构
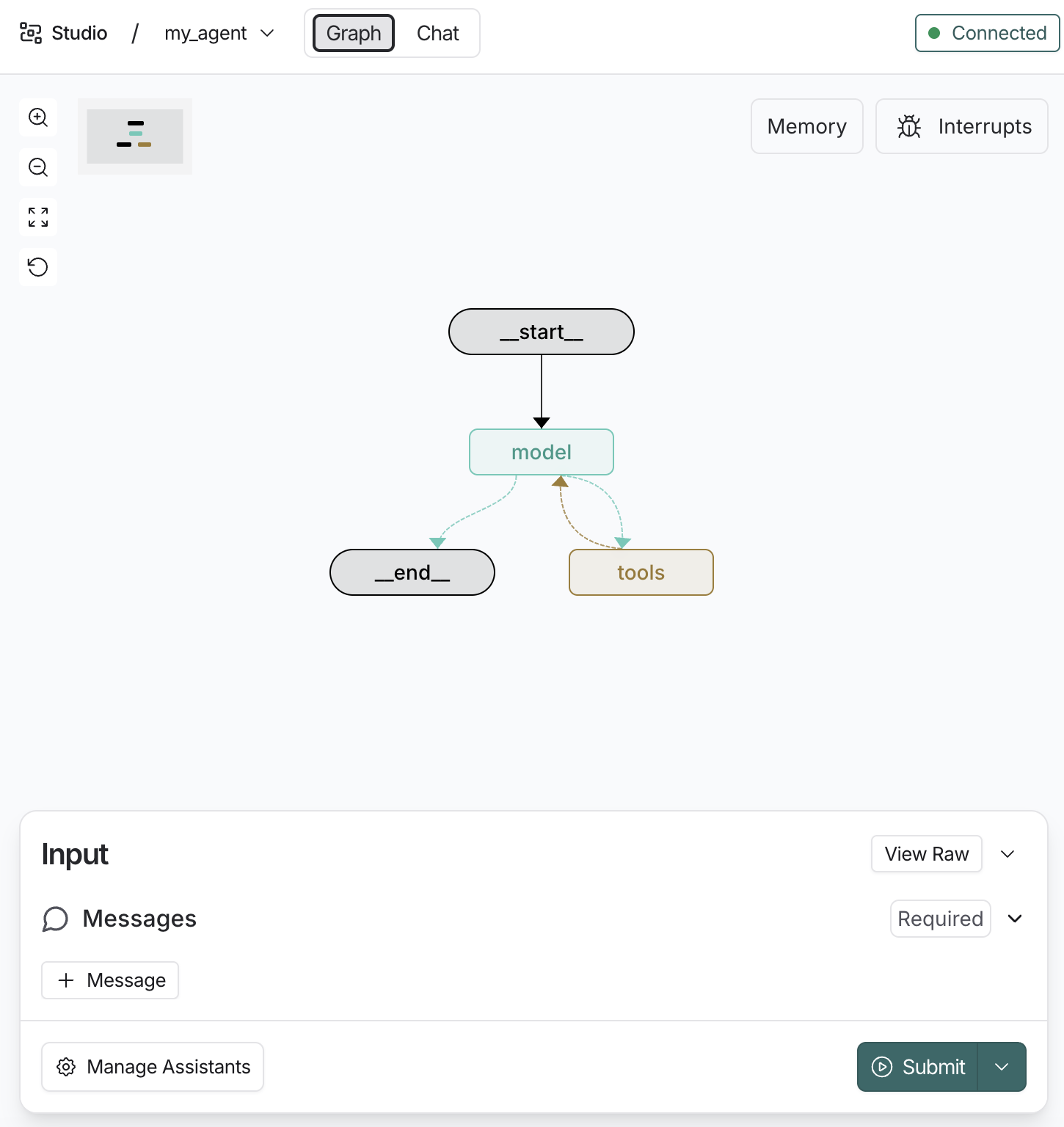
2.2 StructuredTool.from_function()
- 这是最常用的方式,通过函数直接创建结构化工具,支持同步和异步双重实现。
StructuredTool.from_function()方法提供了更强大的工具创建能力,支持完整的参数校验和异步执行,适合生产环境使用。
技术概述:
-
强类型校验:支持Pydantic模型进行参数验证
-
异步支持 :通过
coroutine参数支持异步函数 -
完整元数据:支持name、description、return_direct等完整配置
-
生产就绪:内置错误处理和参数校验机制
核心特性:
-
参数schema完全可控,支持复杂数据结构
-
异步执行支持,适合I/O密集型操作
-
完整的工具元数据配置
-
生产环境级别的错误处理
适用场景:
-
生产环境工具开发
-
需要严格参数校验的场景
-
异步操作需求
-
企业级应用
python
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
"""
1. 通过 Pydantic BaseModel 定义参数,提供:
- 参数描述(description)
- 必填/可选约束
- 更清晰的 Schema 文档
"""
class DivideInput(BaseModel):
"""除法工具输入参数"""
dividend: float = Field(description="被除数")
divisor: float = Field(description="除数,不能为零")
def divide(dividend: float, divisor: float) -> float:
"""执行除法运算,支持浮点数"""
if divisor == 0:
raise ValueError("除数不能为零")
return dividend / divisor
# 2. 创建带参数校验的工具
division_tool = StructuredTool.from_function(
func=divide,
name="DivisionTool",
description="安全执行除法运算,自动处理除零错误",
args_schema=DivideInput, # 显式指定参数模式
return_direct=False, # 是否直接返回工具结果(不经过 LLM 再次处理)
)
# 3. 测试参数校验(触发 Pydantic 验证)
try:
division_tool.invoke({"a": 10, "b": 2}) # 错误:参数名不匹配
except Exception as e:
print(f"参数校验失败:{e}")
# 4. 正确调用
result = division_tool.invoke({"dividend": 10, "divisor": 2})
print(f"除法结果:{result}")参数校验失败:2 validation errors for DivideInput
dividend
Field required [type=missing, input_value={'a': 10, 'b': 2}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
divisor
Field required [type=missing, input_value={'a': 10, 'b': 2}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
除法结果:5.02.3 继承StructuredTool
通过继承StructuredTool类创建工具提供了最大的灵活性和控制力,适合复杂业务逻辑和状态管理需求。
技术概述:
-
完全自定义:可以完全控制工具的所有行为
-
状态管理:支持工具内部状态维护
-
复杂逻辑:适合实现复杂的业务逻辑
-
企业级特性:支持完整的生命周期管理
核心能力:
-
完整的Pydantic集成和类型系统
-
自定义错误处理和重试机制
-
工具内部状态管理
-
复杂的业务逻辑封装
适用场景:
-
企业级复杂工具开发
-
需要状态管理的工具
-
复杂的业务逻辑封装
-
高性能要求的场景
python
import os
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
from typing import Type
# 1. 定义包含业务逻辑的工具
class OrderQueryInput(BaseModel):
"""订单查询参数"""
order_id: str = Field(description="订单编号,格式:ORD-2024-XXXX")
include_details: bool = Field(default=False, description="是否包含商品明细")
class OrderQueryTool(StructuredTool):
"""订单查询工具"""
name: str = "query_order"
description: str = "查询电商平台订单状态和物流信息"
args_schema: Type[BaseModel] = OrderQueryInput
return_direct: bool = False
def _run(self, order_id: str, include_details: bool = False) -> dict:
# 模拟数据库查询
order_db = {
"ORD-2024-1234": {"status": "已发货", "express": "顺丰", "amount": 299},
"ORD-2024-5678": {"status": "待付款", "express": "", "amount": 149},
}
# 处理查询逻辑
if order_id not in order_db:
return {"error": f"订单 {order_id} 不存在"}
result = order_db[order_id]
# 处理包含明细的情况
if include_details:
result["items"] = ["商品A × 2", "商品B × 1"]
return result
# 2. 初始化模型
model = init_chat_model(
model="openai:gpt-4o-mini",
temperature=0,
api_key=os.getenv("OPENAI_API_KEY")
)
# 3. 创建 ReAct Agent(自动处理工具调用)
agent = create_agent(
model=model,
tools=[OrderQueryTool()], # 直接传入 StructuredTool 实例
system_prompt="你是一个电商客服助手,使用工具查询订单信息,回答要友好且准确",
checkpointer=InMemorySaver()
)
# 4. 执行并观察 ReAct 过程
async def run_agent():
config = {"configurable": {"thread_id": "customer_001"},"recursion_limit": 15}# 最大 15 次迭代
query = "请帮我查订单 ORD-2024-1234 的详细状态,包括商品明细"
async for step in agent.astream(
{"messages": [{"role": "user", "content": query}]},
config=config,
stream_mode="values" # 流式输出模式,返回每一步的完整状态
):
message = step["messages"][-1]
message.pretty_print()
print("-" * 50)
# 运行
await run_agent()核心要点总结
-
参数校验:始终使用 args_schema 定义 Pydantic 模型,确保输入合法
-
异步优先:为网络 I/O 操作提供 _arun 实现,提升 Agent 并发性能
-
文档清晰:description 字段是 LLM 选择工具的唯一依据,必须详细描述功能和参数
-
返回值控制:return_direct=True 适合无需 LLM 润色的确定性格式数据
-
调试友好:使用 tool.invoke() 单独测试工具,确保逻辑正确后再集成到 Agent
三种方法对比与选择
| 特性 | @tool装饰器 | StructuredTool.from_function() | 继承StructuredTool |
|---|---|---|---|
| 代码简洁度 | ⭐⭐⭐⭐⭐(极简) | ⭐⭐⭐⭐(简洁) | ⭐⭐(较繁琐) |
| 参数控制 | 灵活,支持args_schema,强校验 |
支持args_schema,强校验 |
完全自定义 Schema |
| 异步支持 | ❌(需单独定义 async 函数) | ✅(通过coroutine参数) |
✅(实现_arun方法) |
| 元数据定制 | 中等(name, description) | 中等(name, description, return_direct) | 完全定制(所有属性) |
| 适用场景 | 快速原型、简单工具 | 生产环境、需要参数校验的场景 | 复杂业务逻辑、状态管理 |
| 类型提示 | 依赖函数签名 | 结合 Pydantic 强类型 | 完整的 Pydantic 集成 |
3.多工具使用
python
from langchain.agents import create_agent
from langchain_core.tools import tool
# 定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 定义数学计算工具
@tool
def calculate(expression: str) -> str:
"""计算一个数学表达式的结果。"""
try:
result = eval(expression)
return f"计算结果是:{result}"
except Exception as e:
return f"计算出错:{str(e)}"
# 1. 初始化LLM
llm = load_chat_model(model="gpt-4o-mini",provider="openai")
# 2. 创建Agent
agent = create_agent(
model=llm,
tools=[get_weather, calculate],
system_prompt="你是一个多功能的助手,可以查询天气和进行数学计算。"
)
# 3. 测试多工具调用
user_queries = [
"北京和上海的天气怎么样?",
"如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?"
]
# 4. 执行测试
for query in user_queries:
print(f"用户: {query}")
response = agent.invoke({
"messages": [{"role": "user", "content": query}]
})
print(f"Agent: {response['messages'][-1].content}")
print("-" * 50)用户: 北京和上海的天气怎么样?
Agent: 当前天气情况如下:
- 北京:晴朗,气温25°C
- 上海:多云,气温28°C
--------------------------------------------------
用户: 如果北京气温是25度,上海是28度,那么北京的温度比上海低多少度?
Agent: 北京的温度比上海低3度。
--------------------------------------------------查看运行流程
python
import getpass
import operator
from typing import Annotated, List, Union
import os
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage, ToolMessage
from langchain.agents import create_agent
# 引入 UI 库
from rich.console import Console
from rich.panel import Panel
from rich.text import Text
from rich.markdown import Markdown
# 初始化控制台
console = Console()
# --- 第一步:定义工具 (和以前一样,这是 Core 标准) ---
# 定义天气查询工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息。"""
weather_data = {
"北京": "晴朗,气温25°C",
"上海": "多云,气温28°C",
"广州": "小雨,气温30°C"
}
return f"{city}的天气是:{weather_data.get(city, '未知')}"
# 定义数学计算工具
@tool
def add(a: float, b: float) -> float:
"""计算两个数的和"""
return a + b
tools = [get_weather, add]
# --- 第二步:初始化模型 (必须绑定工具) ---
model = ChatOpenAI(model="gpt-4o", temperature=0)
# --- 第三步:构建图 (使用 prebuilt 的 ReAct Agent) ---
# 在 LangChain 1.0+ 中,这是 AgentExecutor 的官方替代品
# 它自动构建了:State -> Model Node -> Tool Node -> Loop 逻辑
graph = create_agent(model, tools=tools)
# --- 第四步:编写"教学专用"的可视化流式运行器 ---
def run_demo_with_visualization(user_input: str):
print("\n" + "="*50)
console.print(f"[bold yellow]开始任务:[/bold yellow] {user_input}")
messages = [HumanMessage(content=user_input)]
# graph.stream 是 LangGraph 的核心
# 它可以让我们看到状态流转的每一步 (step-by-step)
step_count = 1
# values 模式会返回当前的 message 列表状态
for event in graph.stream({"messages": messages}, stream_mode="values"):
# 获取最新的一条消息
current_message = event["messages"][-1]
# 1. 如果是人类的消息 (初始状态)
if isinstance(current_message, HumanMessage):
continue # 跳过,这是输入
# 2. 如果是 AI 的消息 (思考与决策)
if isinstance(current_message, AIMessage):
# 检查是否有工具调用
if current_message.tool_calls:
# 提取工具调用的细节
for tool_call in current_message.tool_calls:
console.print(Panel(
Text(f"🤔 AI 思考决定:需要调用外部工具\n"
f"🔧 工具名称: {tool_call['name']}\n"
f"📥 输入参数: {tool_call['args']}", style="bold cyan"),
title=f"Step {step_count}: 决策 (Decision)",
border_style="cyan"
))
else:
# 如果没有工具调用,说明是最终回复
console.print(Panel(
Markdown(current_message.content),
title=f"Step {step_count}: 最终回复 (Final Answer)",
border_style="green"
))
step_count += 1
# 3. 如果是工具的消息 (观察与结果)
if isinstance(current_message, ToolMessage):
console.print(Panel(
Text(f"👀 工具返回结果 (Observation):\n{current_message.content}", style="italic white"),
title=f"Step {step_count}: 执行与观察",
border_style="magenta"
))
step_count += 1
# --- 第五步:运行演示 ---
if __name__ == "__main__":
# 这是一个多步任务:先算乘法,再查属性
run_demo_with_visualization("查询一下北京和上海气温,并且计算一下北京的温度比上海低多少度?")╭──────────────────────────────────────────── Step 1: 决策 (Decision) ────────────────────────────────────────────╮
│ 🤔 AI 思考决定:需要调用外部工具 │
│ 🔧 工具名称: get_weather │
│ 📥 输入参数: {'city': '北京'} │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯╭──────────────────────────────────────────── Step 1: 决策 (Decision) ────────────────────────────────────────────╮
│ 🤔 AI 思考决定:需要调用外部工具 │
│ 🔧 工具名称: get_weather │
│ 📥 输入参数: {'city': '上海'} │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯╭────────────────────────────────────────────── Step 2: 执行与观察 ───────────────────────────────────────────────╮
│ 👀 工具返回结果 (Observation): │
│ 上海的天气是:多云,气温28°C │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯╭──────────────────────────────────────────── Step 3: 决策 (Decision) ────────────────────────────────────────────╮
│ 🤔 AI 思考决定:需要调用外部工具 │
│ 🔧 工具名称: add │
│ 📥 输入参数: {'a': 25, 'b': -28} │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯╭────────────────────────────────────────────── Step 4: 执行与观察 ───────────────────────────────────────────────╮
│ 👀 工具返回结果 (Observation): │
│ -3.0 │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯╭──────────────────────────────────────── Step 5: 最终回复 (Final Answer) ────────────────────────────────────────╮
│ 北京的气温是25°C,上海的气温是28°C。北京的温度比上海低3°C。 │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯