一、项目需求分析
大家好!今天我们来实战一个加盟品牌信息爬虫 项目 目标网站是1637加盟网(www.1637.com),这是一个提供各种品牌加盟信息的平台 通过这个项目,你将掌握如何:
爬取目标:
-
多页面翻页爬取(1-10页数据)
-
结构化信息提取(品牌名称、分类、公司、发布时间等8个字段)
-
复杂文本处理(使用正则表达式提取特定信息)
-
数据分页保存(每页保存为独立的Excel文件)
技术要点:
-
XPath选择器使用技巧
-
正则表达式匹配提取
-
反爬虫策略应对
-
数据存储与组织
二、网页分析与目标确认
首先我们需要分析目标网站的页面结构,确定要爬取哪些信息
2.1 网站页面结构分析
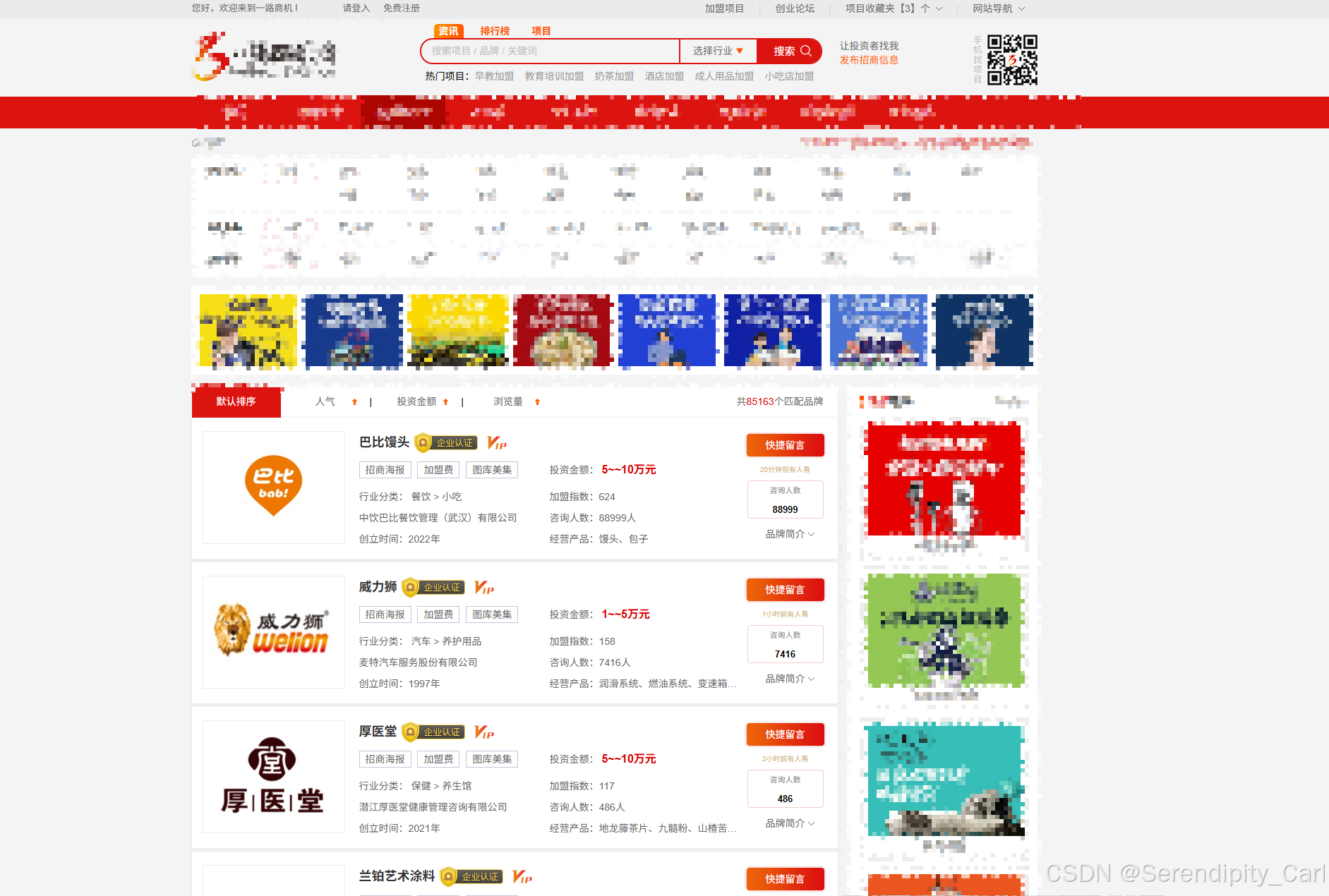
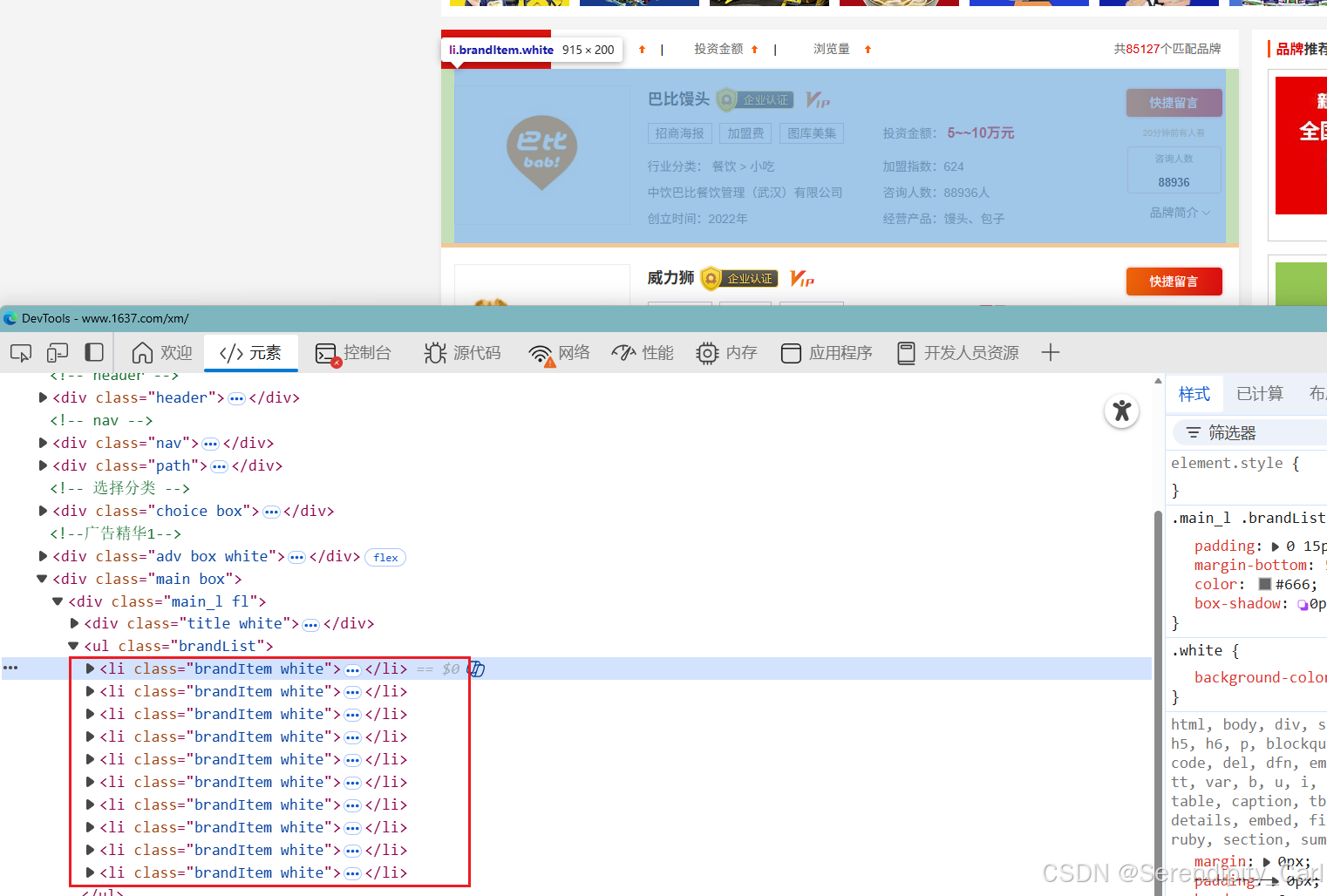
通过浏览器开发者工具(F12)分析,我们发现:
-
每个品牌信息都在
<li class="brandItem white">标签中 -
品牌名称在
//dl[@class="dl2 fl"]/h4/a/text()路径下 -
详细信息需要从
//dd[@class="fr"]中提取
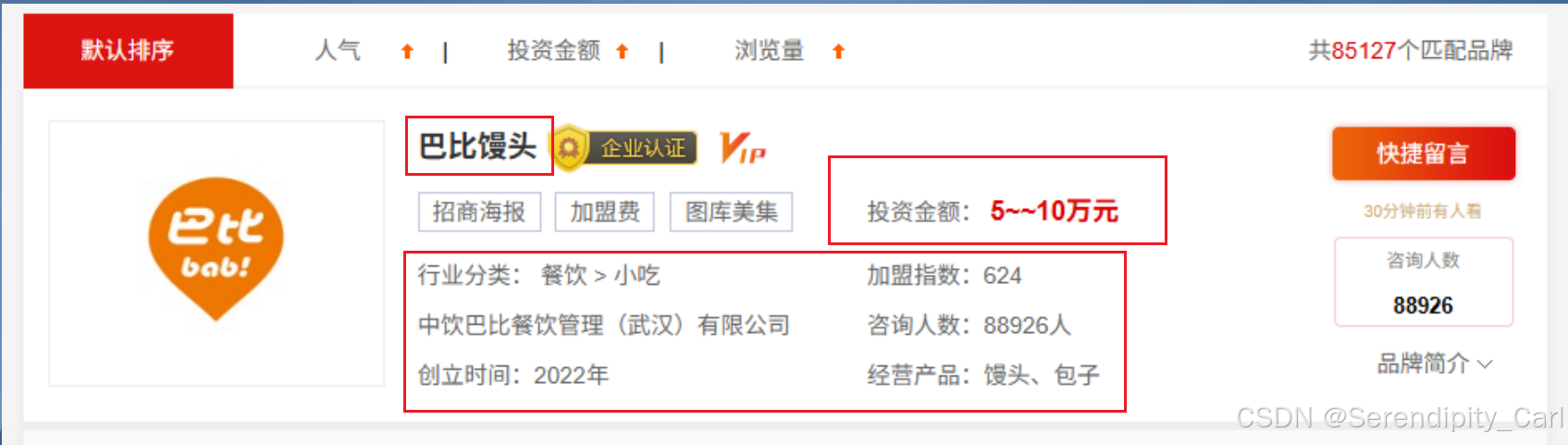
2.2 确定要爬取的数据字段
我们需要提取以下8个关键信息:
三、爬虫代码实战
OK,分析完页面结构后,我们开始写代码。我会一步一步带你完成这个爬虫
3.1 环境准备与导入库
python
import os.path
import re
import pandas as pd
import requests
from lxml import etree库说明:
-
os.path:用于检查文件夹是否存在,创建保存目录 -
re:正则表达式,用于提取复杂文本信息 -
pandas:数据处理,保存为Excel格式 -
requests:发送HTTP请求,获取网页内容 -
lxml:解析HTML,使用XPath提取数据
3.2 创建保存目录
在开始爬取前,我们先创建一个文件夹来保存数据:
python
# 检查'project'文件夹是否存在,如果不存在就创建
if not os.path.exists('project'):
os.makedirs('project')
print("✅ 保存目录创建成功:project/")这样做的目的是把爬取的数据统一放在一个文件夹里,方便管理
3.3 分析请求头(反爬虫策略)
网站一般会有反爬虫机制,我们需要模拟浏览器发送请求 查看浏览器Network面板,复制完整的请求头
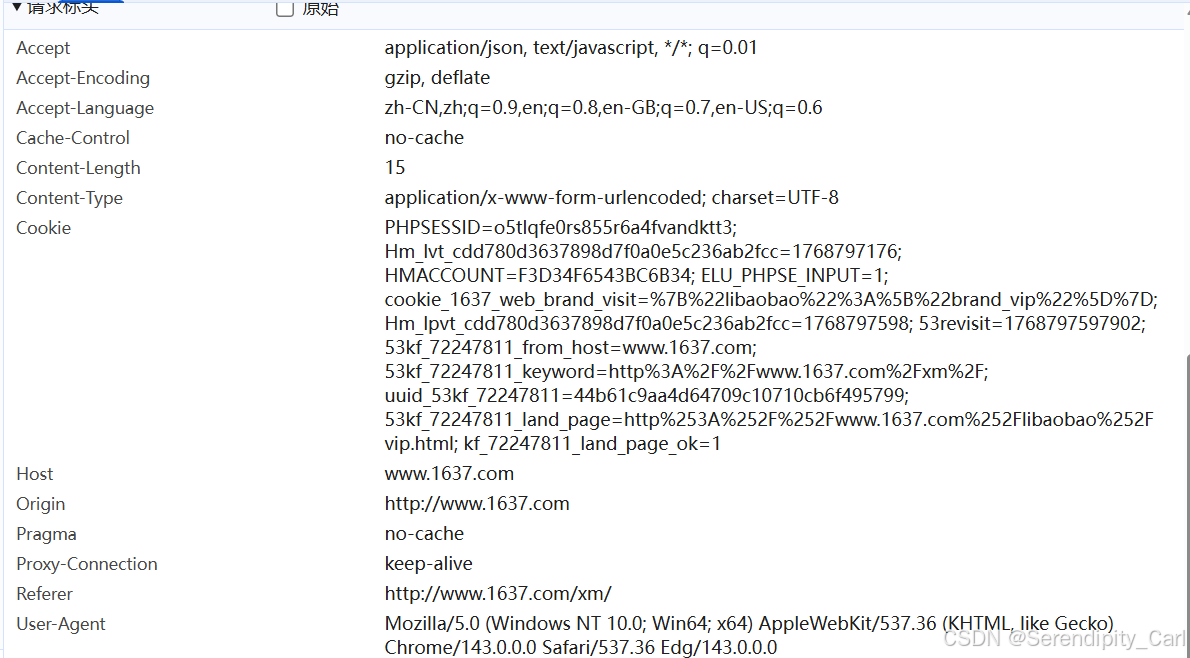
python
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding": "gzip, deflate",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "PHPSESSID=o5tlqfe0rs855r6a4fvandktt3; Hm_lvt_cdd780d3637898d7f0a0e5c236ab2fcc=1768797176; HMACCOUNT=F3D34F6543BC6B34; ELU_PHPSE_INPUT=1; Hm_lpvt_cdd780d3637898d7f0a0e5c236ab2fcc=1768797193",
"host": "www.1637.com",
"pragma": "no-cache",
"proxy-connection": "keep-alive",
"referer": "http://www.1637.com/",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}关键字段说明:
-
User-Agent:告诉服务器我们使用的是Chrome浏览器 -
Referer:表示请求来自哪个页面,有些网站会检查这个 -
Cookie:维持登录状态,有些数据需要登录才能访问 -
Accept-Encoding:告诉服务器我们可以接受压缩的数据,节省流量
3.4 主爬取循环(多页爬取)
我们要爬取第1页到第10页的数据,观察URL规律
第1页:http://www.1637.com/xm/p1.html
第2页:http://www.1637.com/xm/p2.html
第3页:http://www.1637.com/xm/p3.html
...
第10页:http://www.1637.com/xm/p10.html
可以看出,页码就在URL的 p{page}.html 部分 我们使用for循环来实现
python
for page in range(1, 11): # range(1, 11) 生成 1-10 的数字
# 构建每一页的URL
url = f'http://www.1637.com/xm/p{page}.html'
print(f"🚀 开始爬取第 {page} 页:{url}")
# 发送GET请求,带上我们准备好的请求头
resp = requests.get(url, headers=headers)
# 检查请求是否成功(状态码200表示成功)
if resp.status_code == 200:
print(f"✅ 第 {page} 页请求成功")
else:
print(f"❌ 第 {page} 页请求失败,状态码:{resp.status_code}")
continue # 跳过这一页,继续下一页3.5 解析网页内容(XPath使用)
获取到网页HTML后,我们需要用lxml来解析它
python
# 将响应文本转换为lxml可以解析的格式
html = etree.HTML(resp.text)
# 使用XPath找到所有品牌信息的li标签
lis = html.xpath('.//li[@class="brandItem white"]')
print(f"📊 第 {page} 页找到 {len(lis)} 个品牌")XPath语法说明:
-
.//li[@class="brandItem white"]:查找所有class属性为"brandItem white"的li标签 -
//表示从任意位置开始查找 -
[@class="brandItem white"]是属性条件
3.6 提取单个品牌信息
现在我们进入最核心的部分------从每个li标签中提取我们需要的数据:
python
# 创建一个空列表,用于保存本页的所有品牌数据
data = []
# 遍历每个li标签(每个品牌)
for li in lis:
# 1. 提取品牌名称
name = ''.join(li.xpath('.//dl[@class="dl2 fl"]/h4/a/text()'))
# 2. 提取品牌分类(可能有多个分类,用|连接)
category = '|'.join(li.xpath('.//a[@target="_self"]//text()'))
# 3. 提取所属公司
company = ''.join(li.xpath('.//dt[@class="fl"]/p[3]/a/span/text()'))
# 4. 提取发布时间
publish_time = ''.join(li.xpath('.//dt[@class="fl"]/p[4]/span/text()'))XPath技巧说明:
-
''.join(...):将提取的文本列表合并成一个字符串 -
'|'.join(...):用竖线连接多个分类,方便后续分析 -
//text():获取元素下的所有文本,包括子元素的文本
3.7 使用正则表达式提取详细信息
这里有个难点:投资金额、加盟指数等信息都在一个复杂的文本块中,我们需要用正则表达式来提取:
python
# 5. 获取详细信息文本块
info_text = li.xpath('string(.//dd[@class="fr"])')
# 清理文本:去掉换行符和多余空格
info_text = info_text.replace('\n', '').replace(' ', '')
# 使用正则表达式提取关键信息
pattern = r'投资金额:(?P<price>.*?)加盟指数:(?P<join_number>.*?)咨询人数:(?P<pople>.*?)经营产品:(?P<product>.*?)'
obj = re.compile(pattern)
# 查找所有匹配项
matches = obj.finditer(info_text)
# 遍历匹配结果(实际上每个品牌只有一个匹配)
for match in matches:
invest_price = match.group('price')
join_number = match.group('join_number')
pople = match.group('pople')
product = match.group('product')正则表达式详细解释:
python
r'投资金额:(?P<price>.*?)加盟指数:(?P<join_number>.*?)咨询人数:(?P<pople>.*?)经营产品:(?P<product>.*)'
(?P<price>.*?):命名捕获组,匹配"投资金额:"后面到"加盟指数:"之前的所有内容
.*?:非贪婪匹配,匹配任意字符,尽可能少匹配
这样我们可以一次性提取出4个字段的信息3.8 组织数据并保存
提取完所有信息后,我们把它组织成字典格式,方便后续保存
python
# 创建数据字典
brand_data = {
'name': name,
'category': category,
'company': company,
'publish_time': publish_time,
'invest_price': invest_price,
'join_number': join_number,
'pople': pople,
'product': product
}
# 添加到数据列表
data.append(brand_data)
# 将本页数据保存为Excel文件
df = pd.DataFrame(data)
output_file = f'project/page_{page}.xlsx'
df.to_excel(output_file, index=False)
print(f"💾 第 {page} 页数据已保存:{output_file},共 {len(data)} 条记录")保存策略说明:
-
每页保存为一个独立的Excel文件
-
文件名格式:
page_1.xlsx、page_2.xlsx... -
不保存索引列(
index=False) -
统一保存在
project文件夹中 -
保存至 csv 以及mysql 如下
python
import csv
csv_writer = csv.DictWriter(open(f'project/p_{page}.csv', 'w', encoding='utf-8-sig', newline=''), fieldnames=[
'name',
'category',
'company',
'publish_time',
'invest_price',
'join_number',
'pople',
'product',
])
csv_writer.writeheader()
csv_writer.writerow(dit)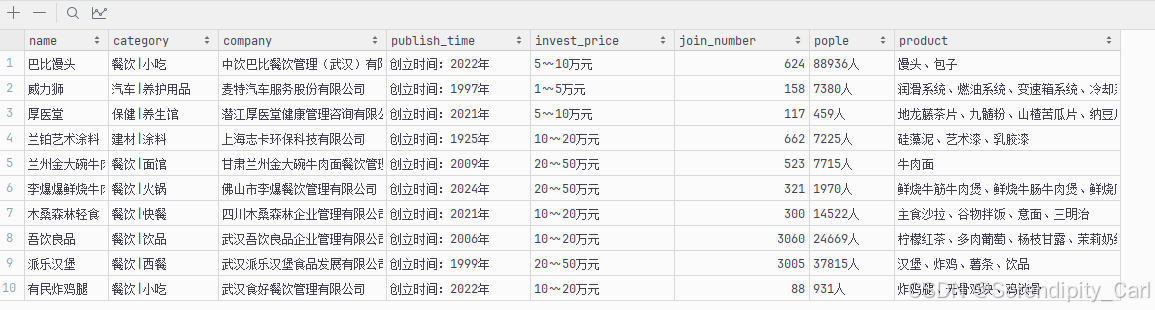
数据库:
python
connection = pymysql.connect(
user='root',
password="",
host='localhost',
database='spider',
)
cursor = connection.cursor()
sql = 'insert into project values (%s,%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql, tuple(dit.values()))
connection.commit()
cursor.close()
connection.close()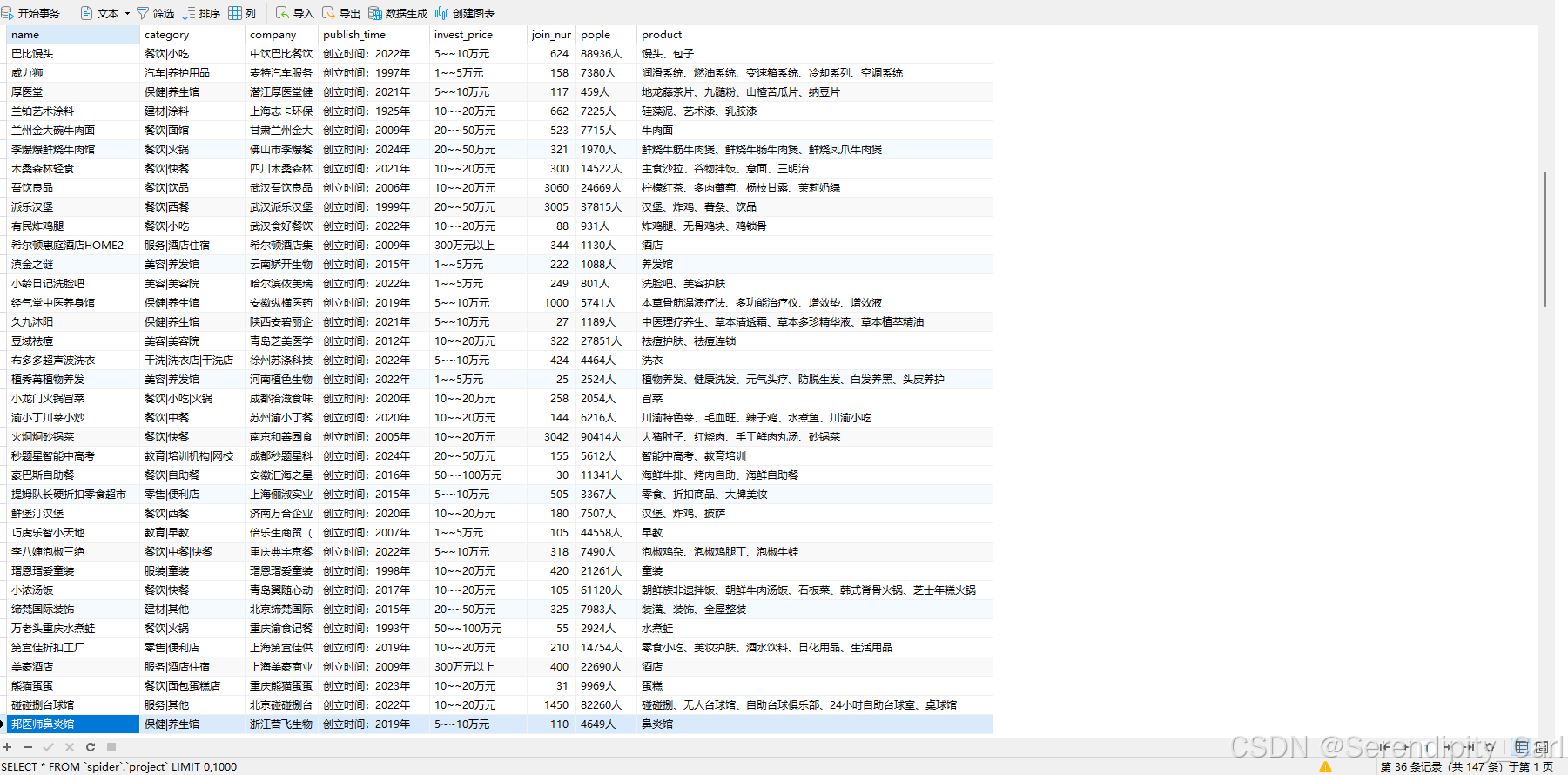
四、完整代码整合
下面是完整的爬虫代码,你可以直接复制运行:
python
import os.path
import re
import pandas as pd
import requests
from lxml import etree
# 1. 创建保存目录
if not os.path.exists('project'):
os.makedirs('project')
# 2. 请求头设置(模拟浏览器)
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding": "gzip, deflate",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "PHPSESSID=o5tlqfe0rs855r6a4fvandktt3; Hm_lvt_cdd780d3637898d7f0a0e5c236ab2fcc=1768797176; HMACCOUNT=F3D34F6543BC6B34; ELU_PHPSE_INPUT=1; Hm_lpvt_cdd780d3637898d7f0a0e5c236ab2fcc=1768797193",
"host": "www.1637.com",
"pragma": "no-cache",
"proxy-connection": "keep-alive",
"referer": "http://www.1637.com/",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
# 3. 主爬取循环(1-10页)
for page in range(1, 11):
# 构建URL
url = f'http://www.1637.com/xm/p{page}.html'
print(f"\n{'='*50}")
print(f"🚀 开始爬取第 {page} 页:{url}")
# 发送请求
resp = requests.get(url, headers=headers)
# 检查响应状态
if resp.status_code != 200:
print(f"❌ 请求失败,状态码:{resp.status_code}")
continue
# 解析HTML
html = etree.HTML(resp.text)
# 查找所有品牌项目
lis = html.xpath('.//li[@class="brandItem white"]')
print(f"📊 找到 {len(lis)} 个品牌")
# 数据存储列表
data = []
# 4. 提取每个品牌的信息
for li in lis:
# 提取基础信息
name = ''.join(li.xpath('.//dl[@class="dl2 fl"]/h4/a/text()'))
category = '|'.join(li.xpath('.//a[@target="_self"]//text()'))
company = ''.join(li.xpath('.//dt[@class="fl"]/p[3]/a/span/text()'))
publish_time = ''.join(li.xpath('.//dt[@class="fl"]/p[4]/span/text()'))
# 提取详细信息(使用正则表达式)
info = li.xpath('string(.//dd[@class="fr"])')
info = info.replace('\n', '').replace(' ', '')
# 正则匹配
pattern = r'投资金额:(?P<price>.*?)加盟指数:(?P<join_number>.*?)咨询人数:(?P<pople>.*?)经营产品:(?P<product>.*)'
obj = re.compile(pattern)
matches = obj.finditer(info)
for match in matches:
# 组织数据字典
brand_dict = {
'name': name,
'category': category,
'company': company,
'publish_time': publish_time,
'invest_price': match.group('price'),
'join_number': match.group('join_number'),
'pople': match.group('pople'),
'product': match.group('product')
}
data.append(brand_dict)
# 5. 保存为Excel
if data: # 只有当有数据时才保存
df = pd.DataFrame(data)
filename = f'project/page_{page}.xlsx'
df.to_excel(filename, index=False)
print(f"💾 数据已保存:{filename},共 {len(data)} 条记录")
else:
print(f"⚠️ 第 {page} 页没有提取到数据")
print("\n" + "="*50)
print("✅ 所有页面爬取完成!")
print(f"📁 数据保存在 'project' 文件夹中")五、运行结果展示
运行上面的代码,你会看到如下输出:
==================================================
🚀 开始爬取第 1 页:http://www.1637.com/xm/p1.html
📊 找到 20 个品牌
💾 数据已保存:project/page_1.xlsx,共 20 条记录
==================================================
🚀 开始爬取第 2 页:http://www.1637.com/xm/p2.html
📊 找到 20 个品牌
💾 数据已保存:project/page_2.xlsx,共 20 条记录
...(中间省略)...
==================================================
🚀 开始爬取第 10 页:http://www.1637.com/xm/p10.html
📊 找到 20 个品牌
💾 数据已保存:project/page_10.xlsx,共 20 条记录
==================================================
✅ 所有页面爬取完成!
📁 数据保存在 'project' 文件夹中
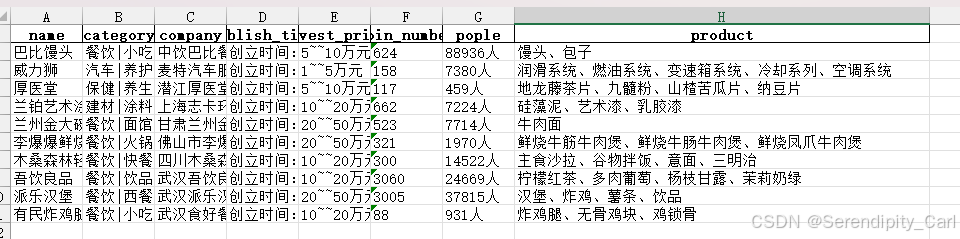
打开其中一个Excel文件,你会看到这样的数据结构:
六.数据清洗
6.1 环境准备与数据加载
python
import re
import numpy as np
import pandas as pd
# 设置Pandas显示选项,便于查看完整数据
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.width', 1000) # 设置显示宽度为1000字符
# 加载原始数据
df = pd.read_excel('./project/page_all.xlsx')
print(f"数据形状: {df.shape}")
print(f"数据预览:\n{df.head()}")6.2 缺失值处理
虽然本次数据中所有字段都没有缺失值,但在实际项目中,缺失值处理是数据清洗的重要步骤:
python
# 检查各字段缺失情况
missing_info = df.isna().sum()
print("缺失值统计:")
print(missing_info)
# 缺失值处理策略:
# 1. 数值字段:用均值、中位数填充或删除
# 2. 分类字段:用众数填充或创建"未知"类别
# 3. 文本字段:填充为空字符串或删除6.3 发布时间处理
原始发布时间字段格式不一,需要提取数字部分并转换为标准时间格式
python
def deal_publish_time(p_str):
"""
处理发布时间,提取数字部分
参数:
p_str: 原始发布时间字符串
返回:
提取的数字字符串或NaN
"""
if pd.isna(p_str):
return np.nan # 如果是缺失值,返回NaN
# 使用正则表达式提取所有数字
result = re.findall(r'\d+', str(p_str))
if result:
return result[0] # 返回第一个匹配的数字串
else:
return np.nan # 如果没有找到数字,返回NaN
# 应用处理函数
df['publish_time'] = df['publish_time'].apply(deal_publish_time)
print("发布时间处理示例:")
print(df['publish_time'].head())6.4 投资价格处理
投资价格字段包含范围值(如"5-10万")和单个数值,需要统一处理:
python
def deal_invest_price(i_str):
"""
处理投资价格,支持范围值(取平均值)和单个数值
参数:
i_str: 原始投资价格字符串
返回:
处理后的数值或NaN
"""
if pd.isna(i_str):
return np.nan
# 处理范围值(使用~~分隔)
if '~~' in i_str:
# 提取两个数值
result = re.findall(r'(\d+)~~(\d+)', str(i_str))
if result:
# 计算平均值
return (int(result[0][0]) + int(result[0][1])) / 2
else:
# 提取单个数值
result = re.findall(r'(\d+)', str(i_str))
if result:
return result[0]
return np.nan # 如果都不匹配,返回NaN
# 应用处理函数
df['invest_price'] = df['invest_price'].apply(deal_invest_price)
print("投资价格处理示例:")
print(df['invest_price'].head())6.5 人数字段处理
人数字段可能包含非数字字符,需要提取纯数字部分:
python
def deal_people(p_str):
"""
处理人数字段,提取数字部分
参数:
p_str: 原始人数字符串
返回:
提取的数字字符串或NaN
"""
if pd.isna(p_str):
return np.nan
# 提取所有数字
res = re.findall(r'(\d+)', str(p_str))
if res:
return res[0] # 返回第一个匹配的数字
else:
return np.nan
# 应用处理函数
df['pople'] = df['pople'].apply(deal_people)
print("人数处理示例:")
print(df['pople'].head())6.6 数据类型转换与特征提取
python
# 数据类型转换
df['pople'] = df['pople'].astype(int) # 转换为整数
df['invest_price'] = df['invest_price'].astype(float) # 转换为浮点数
# 转换发布时间为datetime格式
# format='mixed'允许Pandas自动推断格式,errors='coerce'将错误值转为NaT
df['publish_time'] = pd.to_datetime(df['publish_time'], format='mixed', errors='coerce')
# 提取时间特征
df['year'] = df['publish_time'].dt.year # 年份
df['month'] = df['publish_time'].dt.month # 月份
print("时间特征提取示例:")
print(df[['publish_time', 'year', 'month']].head())6.7 保存清洗后的数据
python
# 保存清洗后的数据,不保存索引列
df.to_excel('./project/cleaned_page_all.xlsx', index=False)
print("清洗后的数据已保存到: ./project/cleaned_page_all.xlsx")
print(f"最终数据形状: {df.shape}")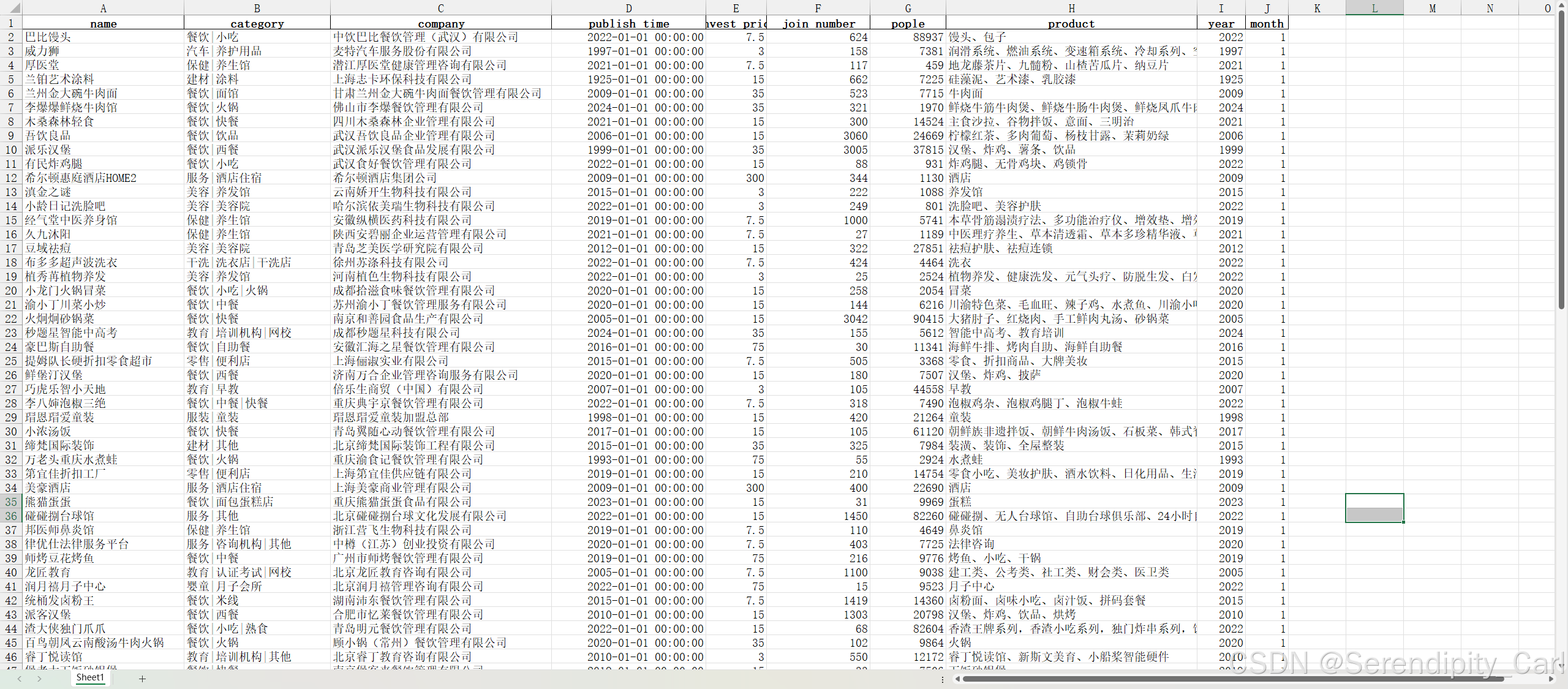
七.数据可视化
7.1 环境准备
python
import re
from collections import Counter
import jieba
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
import warnings
# 忽略警告信息
warnings.filterwarnings('ignore')
# 设置Pandas显示选项
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
# 加载清洗后的数据
df = pd.read_excel('./project/cleaned_page_all.xlsx')
print(f"可视化数据形状: {df.shape}")7.2 行业类别分布分析
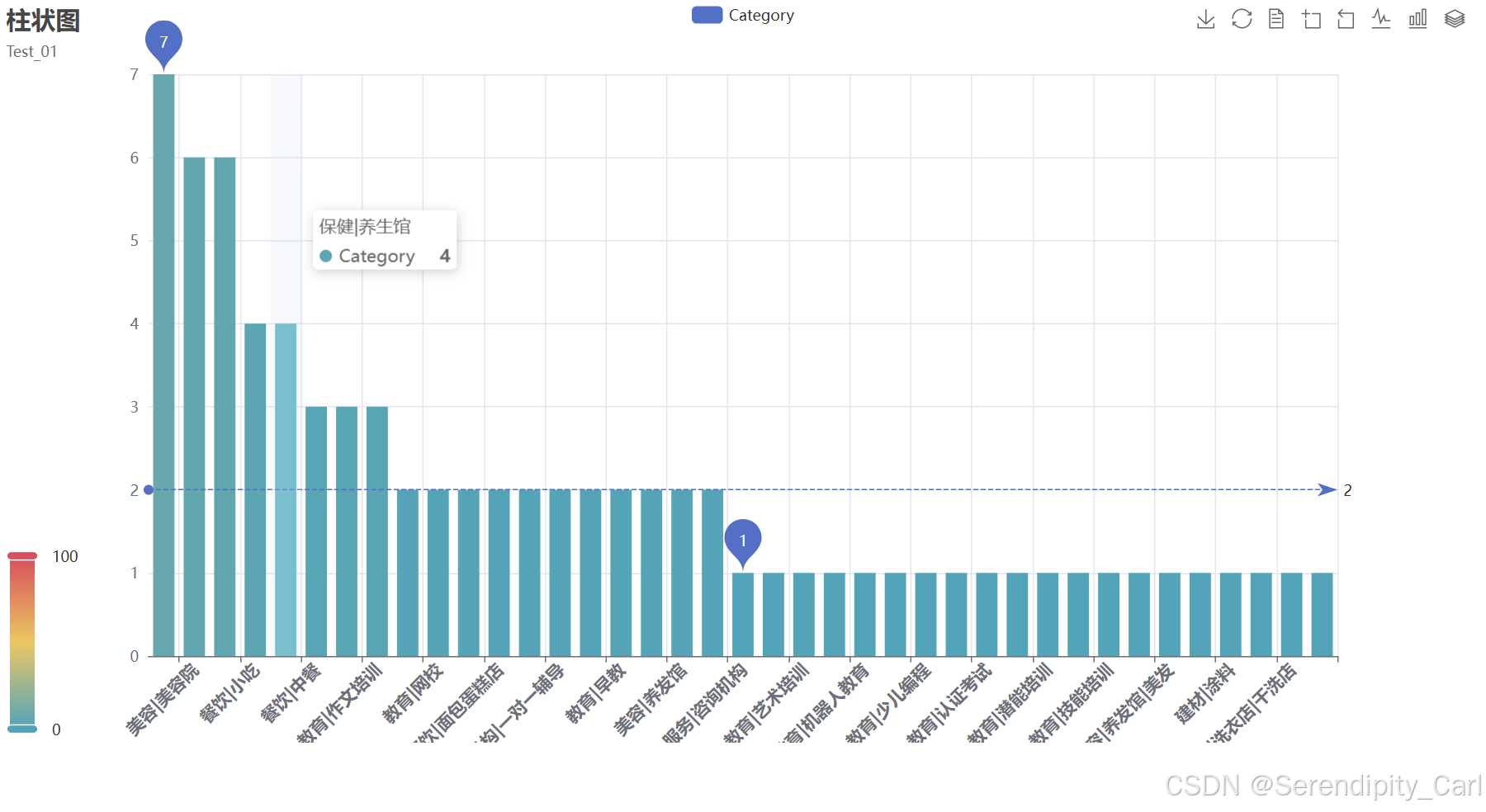
分析项目在不同行业类别中的分布情况,识别热门行业:
python
# 统计各行业类别的项目数量
cate_level = df['category'].value_counts()
print("行业类别分布Top10:")
print(cate_level.head(10))
# 创建柱状图
bar = (
Bar()
.add_xaxis(cate_level.index.tolist()) # X轴:行业类别
.add_yaxis('Category', cate_level.values.tolist(), # Y轴:项目数量
label_opts=opts.LabelOpts(is_show=False), # 不显示柱顶标签
category_gap='30%') # 柱间距30%
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=True), # 显示图例
visualmap_opts=opts.VisualMapOpts(is_show=True), # 显示视觉映射
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside'), # 内置缩放
toolbox_opts=opts.ToolboxOpts(is_show=True), # 显示工具箱
xaxis_opts=opts.AxisOpts(type_='category', boundary_gap=True), # X轴配置
tooltip_opts=opts.TooltipOpts(is_show=True, trigger='axis', axis_pointer_type='shadow'), # 提示框
yaxis_opts=opts.AxisOpts(type_='value', boundary_gap=True), # Y轴配置
title_opts=opts.TitleOpts(
title='行业类别分布柱状图',
subtitle='项目数量分布情况',
title_textstyle_opts=opts.TextStyleOpts(font_weight='bold', font_size=20)
)
)
.set_series_opts(
# 标记最大值和最小值
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_='max'), opts.MarkPointItem(type_='min')]
),
# 标记平均值线
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_='average')]
)
)
)
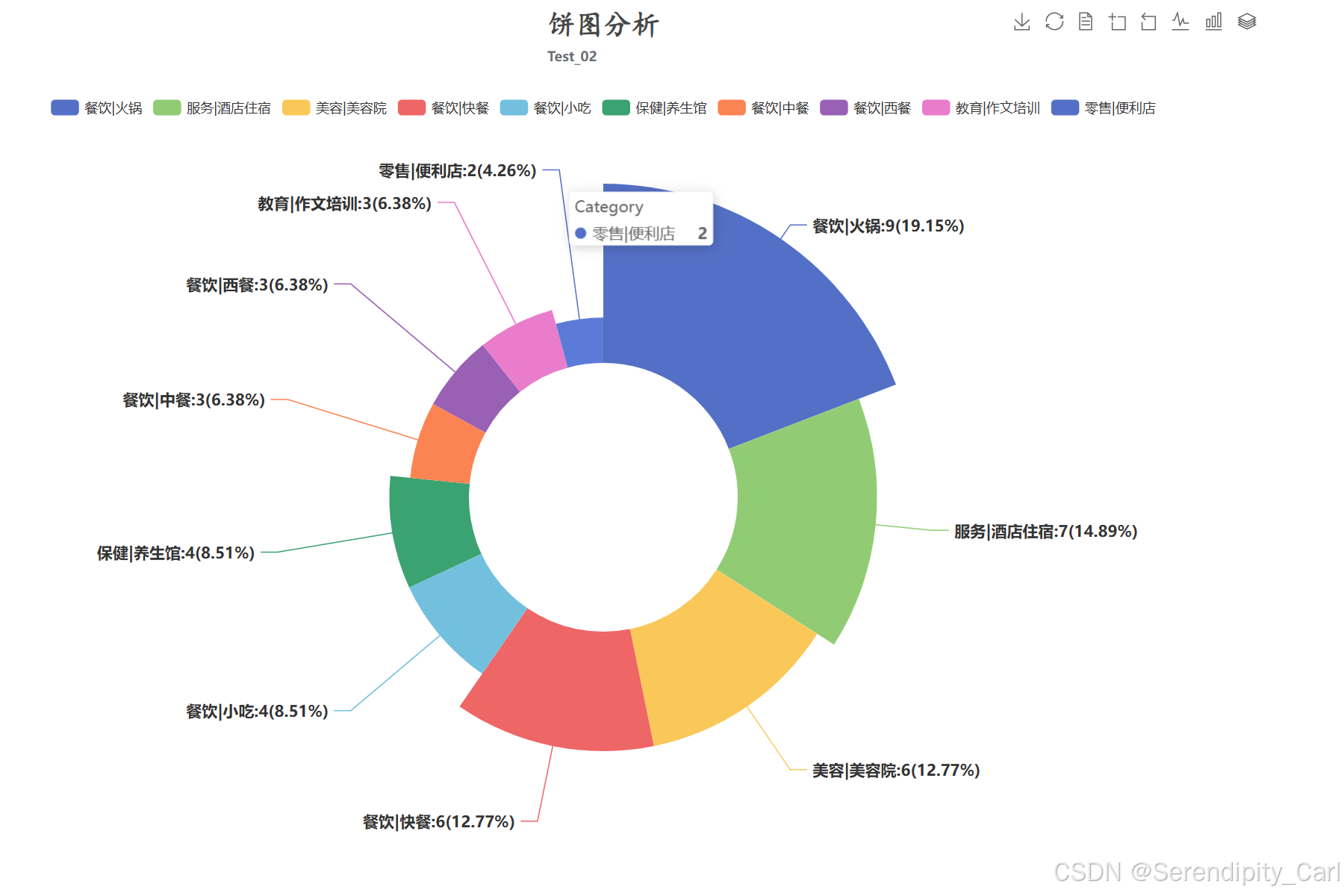
7.3 行业类别饼图分析
python
# 准备饼图数据(取前10个类别)
data = [(i, j) for i, j in zip(cate_level.index.tolist(), cate_level.values.tolist())][:10]
pie = (
Pie(init_opts=opts.InitOpts(
width='1200px',
height='800px',
page_title='饼图',
renderer='svg',
theme='white'
))
.add('Category',
data_pair=data, # 数据对
center=['50%', '55%'], # 饼图中心位置
radius=['30%', '70%'], # 内外半径
rosetype='radius', # 玫瑰图类型
label_opts=opts.LabelOpts(
is_show=True,
font_weight='bold',
font_size=14,
formatter='{b}:{c}({d}%)' # 显示格式:类别:数量(百分比)
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='行业类别分布饼图',
subtitle='Top10类别占比',
title_textstyle_opts=opts.TextStyleOpts(
font_weight='bold',
font_family='楷体',
font_size=25
),
pos_top='top',
pos_left='center'
),
legend_opts=opts.LegendOpts(is_show=True, pos_top='10%'), # 图例
toolbox_opts=opts.ToolboxOpts(is_show=True), # 工具箱
)
)
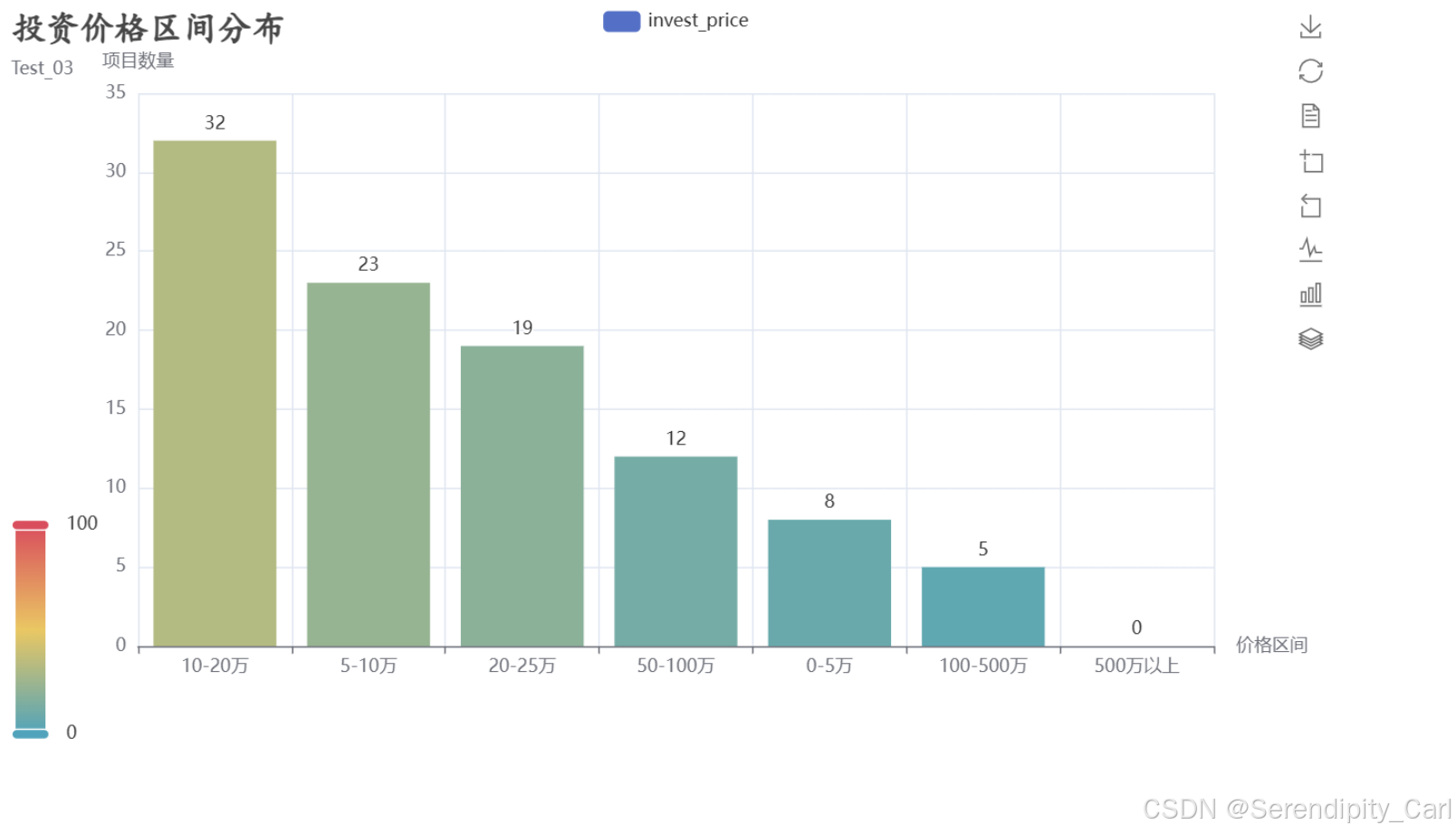
7.4 投资价格分析
分析投资价格的分布情况,了解项目投资规模:
python
# 创建投资价格区间
# 使用pd.cut将连续的投资价格离散化为区间
df['invest_level'] = pd.cut(
df['invest_price'],
bins=[0, 5, 10, 20, 50, 100, 500, 1000], # 区间边界
labels=['0-5万', '5-10万', '10-20万', '20-50万', '50-100万', '100-500万', '500万以上'] # 区间标签
)
# 统计各价格区间的项目数量
invest_Level = df['invest_level'].value_counts()
print("投资价格区间分布:")
print(invest_Level)
# 创建投资价格区间分布柱状图
bar_1 = (
Bar()
.add_xaxis(invest_Level.index.tolist()) # X轴:价格区间
.add_yaxis('invest_price', invest_Level.values.tolist(), # Y轴:项目数量
label_opts=opts.LabelOpts(is_show=True, position='top')) # 显示顶部标签
.set_global_opts(
title_opts=opts.TitleOpts(
title='投资价格区间分布',
subtitle='不同投资规模的项目数量',
title_textstyle_opts=opts.TextStyleOpts(
font_weight='bold',
font_family='楷体',
font_size=23
)
),
toolbox_opts=opts.ToolboxOpts(
is_show=True,
orient='vertical', # 垂直排列
pos_left='860px' # 位置
),
xaxis_opts=opts.AxisOpts(name='价格区间'), # X轴名称
yaxis_opts=opts.AxisOpts(name='项目数量'), # Y轴名称
visualmap_opts=opts.VisualMapOpts(is_show=True), # 视觉映射
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside') # 内置缩放
)
)
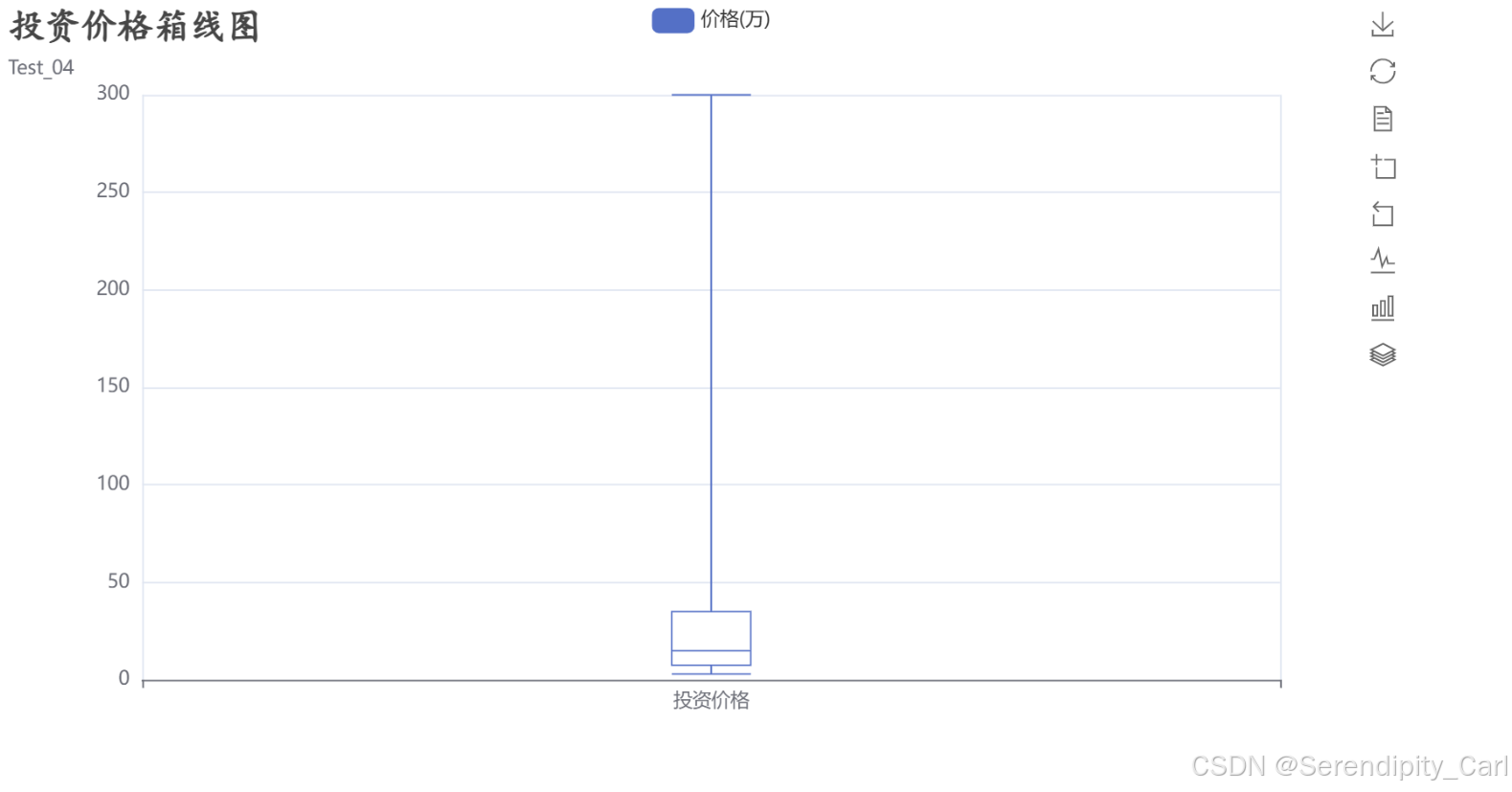
# 创建投资价格箱线图(显示分布特征)
box = (
Boxplot()
.add_xaxis(['投资价格']) # X轴:单一类别
.add_yaxis('价格(万)',
Boxplot.prepare_data([df['invest_price'].tolist()]) # 准备箱线图数据
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='投资价格箱线图',
subtitle='价格分布特征(最小值、下四分位、中位数、上四分位、最大值)',
title_textstyle_opts=opts.TextStyleOpts(
font_weight='bold',
font_family='楷体',
font_size=23
)
),
toolbox_opts=opts.ToolboxOpts(
is_show=True,
orient='vertical',
pos_left='860px'
)
)
)
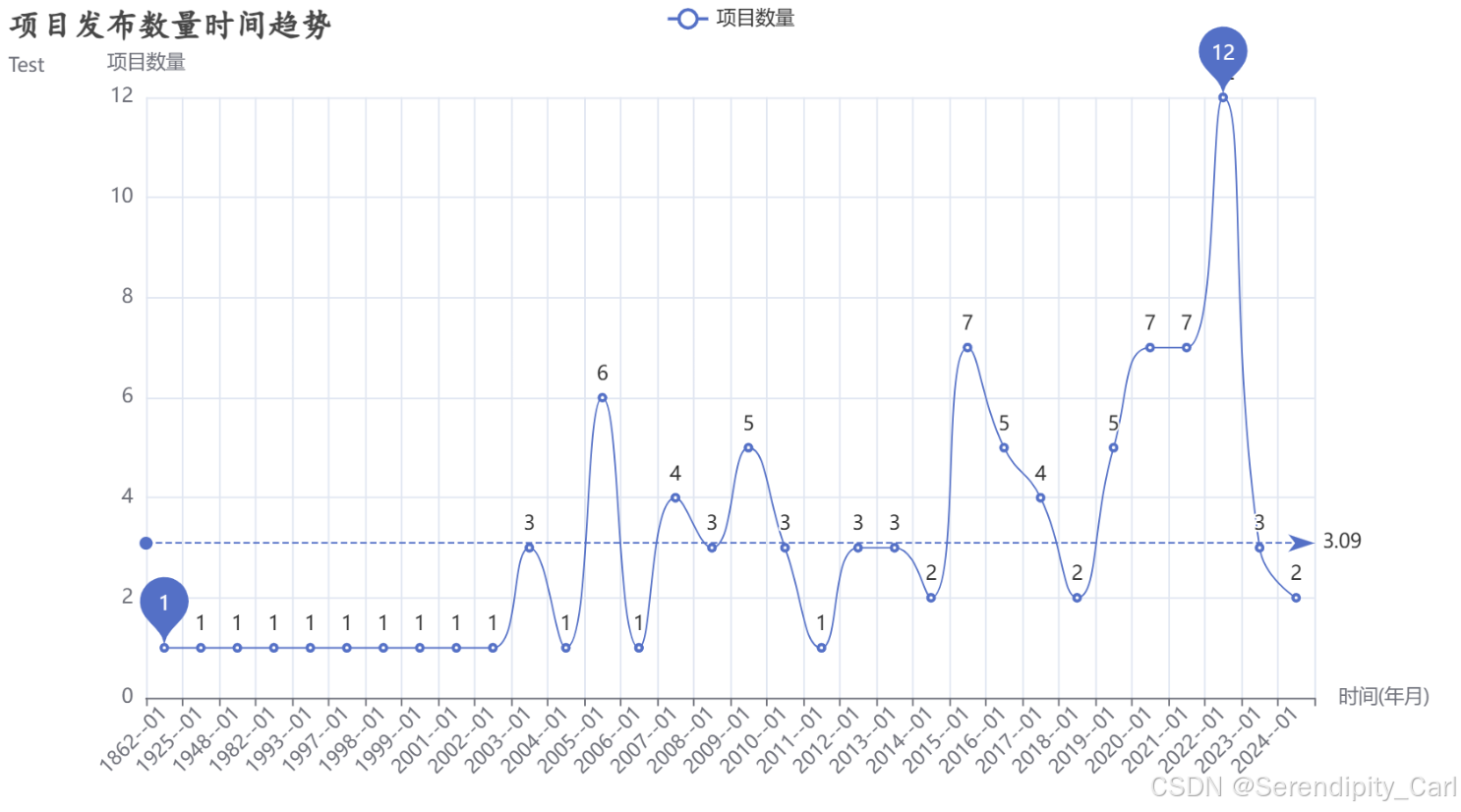
7.5 项目发布趋势分析
分析项目发布的时间趋势,识别市场活跃度变化:
python
# 按年份和月份统计项目发布数量
project_number = df.groupby(['year', 'month'])['name'].count().reset_index(name='number')
# 等同于:project_number = df.groupby(['year', 'month'], as_index=False)['name'].count()
# 创建年月格式的日期列
project_number['date'] = project_number.apply(
lambda x: f"{x['year']}--{x['month']:02d}", # 格式:2023--01
axis=1 # 按行操作
)
print("项目发布数量时间序列(部分):")
print(project_number.head())
# 创建时间趋势折线图
line = (
Line()
.add_xaxis(project_number['date'].tolist()) # X轴:年月
.add_yaxis('项目数量',
project_number['number'].tolist(), # Y轴:项目数量
is_smooth=True) # 平滑曲线
.set_global_opts(
title_opts=opts.TitleOpts(
title='项目发布数量时间趋势',
subtitle='按月统计',
title_textstyle_opts=opts.TextStyleOpts(
font_size=20,
font_family='楷体',
font_weight='bold'
)
),
xaxis_opts=opts.AxisOpts(
name='时间(年月)',
axislabel_opts=opts.LabelOpts(rotate=45) # 标签旋转45度
),
yaxis_opts=opts.AxisOpts(name='项目数量'), # Y轴名称
tooltip_opts=opts.TooltipOpts(
is_show=True,
trigger='axis', # 触发方式
axis_pointer_type='cross' # 十字准星指示器
)
)
.set_series_opts(
# 标记平均值线
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_='average', name='平均值')]
),
# 标记最大值和最小值点
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_='max', name='最大值'),
opts.MarkPointItem(type_='min', name='最小值')
]
)
)
)
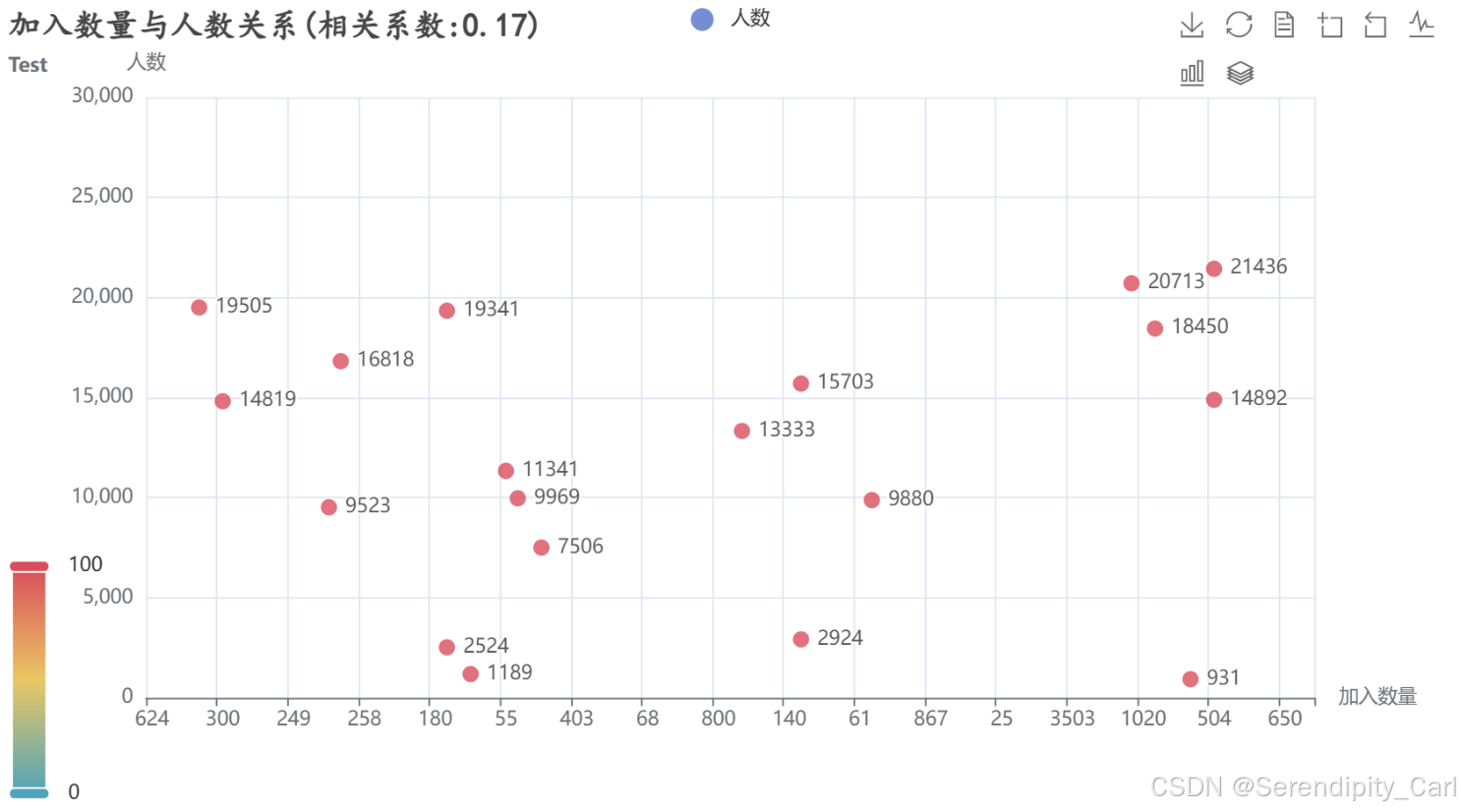
7.6 加入数量与人数关系分析
分析项目参与度指标的相关性:
python
# 重命名列以增加可读性
df.rename(columns={'pople': 'people'}, inplace=True)
# 计算相关系数
cor = df['join_number'].corr(df['people'])
print(f"加入数量与人数的相关系数: {cor:.2f}")
# 创建散点图
scatter = (
Scatter()
.add_xaxis(df['join_number'].tolist()) # X轴:加入数量
.add_yaxis('人数', df['people'].tolist()) # Y轴:人数
.set_global_opts(
title_opts=opts.TitleOpts(
title=f'加入数量与人数关系(相关系数:{cor:.2f})',
subtitle='相关性分析',
title_textstyle_opts=opts.TextStyleOpts(
font_weight='bold',
font_size=20,
font_family='楷体'
)
),
xaxis_opts=opts.AxisOpts(name='加入数量'), # X轴名称
yaxis_opts=opts.AxisOpts(name='人数', max_=30000), # Y轴名称和最大值
visualmap_opts=opts.VisualMapOpts(is_show=True), # 视觉映射
toolbox_opts=opts.ToolboxOpts(is_show=True), # 工具箱
)
)
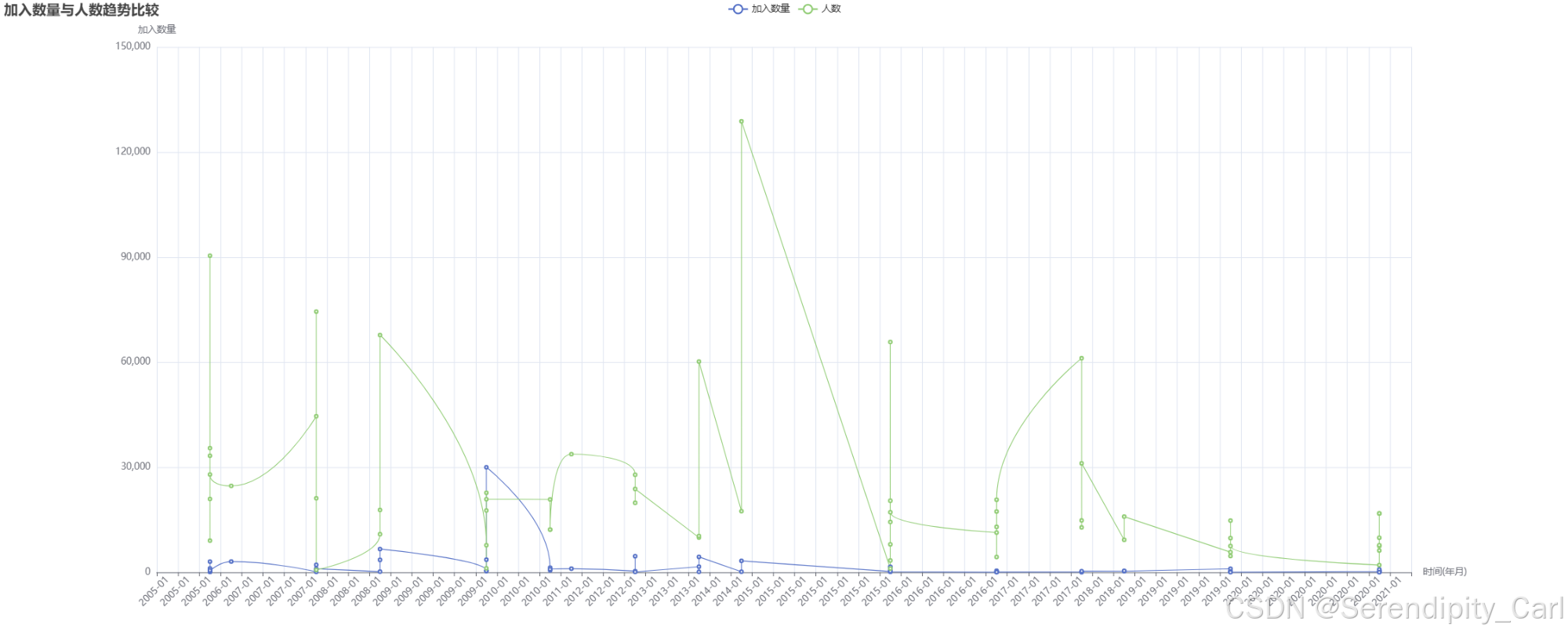
# 创建双Y轴折线图(时间序列比较)
sorted_data = df.sort_values(['year', 'month']) # 按时间排序
line_2 = (
Line(init_opts=opts.InitOpts(
width='2000px',
height='800px',
renderer='canvas',
theme='white'
))
.add_xaxis(sorted_data.apply(
lambda x: f"{x['year']}-{x['month']:02d}",
axis=1
).tolist()) # X轴:年月
.add_yaxis('加入数量',
sorted_data['join_number'].tolist(), # 第一个Y轴:加入数量
is_smooth=True,
label_opts=opts.LabelOpts(is_show=False)) # 不显示标签
.add_yaxis('人数',
sorted_data['people'].tolist(), # 第二个Y轴:人数
is_smooth=True,
label_opts=opts.LabelOpts(is_show=False)) # 不显示标签
.set_global_opts(
title_opts=opts.TitleOpts(title='加入数量与人数趋势比较'), # 标题
xaxis_opts=opts.AxisOpts(
name='时间(年月)',
axislabel_opts=opts.LabelOpts(rotate=45) # 标签旋转
),
yaxis_opts=opts.AxisOpts(name='加入数量', position='left'), # 左侧Y轴
tooltip_opts=opts.TooltipOpts(is_show=True), # 提示框
datazoom_opts=opts.DataZoomOpts(is_show=True, type_='inside'), # 内置缩放
visualmap_opts=opts.VisualMapOpts(is_show=True) # 视觉映射
)
)
7.7 产品信息词云分析
分析产品描述中的关键词,了解技术热点:
python
def clean_product(product):
"""
清洗产品信息,去除特殊字符和多余空格
参数:
product: 原始产品信息字符串
返回:
清洗后的字符串
"""
# 去除非中文、英文、数字、空格的字符
product = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', '', str(product))
# 去除所有空白字符(包括空格、制表符、换行符等)
product = re.sub(r'\s+', '', product).strip()
return product
# 应用清洗函数
df['product'] = df['product'].apply(clean_product)
# 合并所有产品信息
all_product = ''.join(df['product'].tolist())
# 使用jieba进行中文分词
words = jieba.lcut(all_product)
# 定义停用词列表(过滤无意义词汇)
stopwords = ['的', '了', '和', '是', '在', '我', '有', '就', '不', '人', '都', '一',
'一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着',
'没有', '看', '好', '自己', '这', '系统', '系列', '产品']
# 过滤停用词和单字词
words = [word for word in words if word not in stopwords and len(word) > 1]
# 统计词频
word_counts = Counter(words)
top_100_words = word_counts.most_common(100)
print("产品信息高频词汇Top10:")
for word, count in top_100_words[:10]:
print(f"{word}: {count}次")
# 创建词云图
word_cloud = (
WordCloud()
.add('',
top_100_words, # 词频数据
word_size_range=[10, 80], # 词大小范围
shape='star', # 词云形状
textstyle_opts=opts.TextStyleOpts(font_family='楷体'), # 字体
pos_left='left', # 位置
pos_top='middle')
.set_global_opts(
title_opts=opts.TitleOpts(
title='产品信息词云图',
subtitle='高频关键词可视化',
title_textstyle_opts=opts.TextStyleOpts(
font_family='楷体',
font_size=20,
font_weight='bold'
)
),
)
)
# 按行业类别分析产品关键词
category_product = df.groupby('category')['product'].apply(lambda x: ''.join(x)).reset_index()
print("\n各行业类别产品关键词Top10:")
for idx, row in category_product.iterrows():
print(f"\n{row['category']}:")
# 提取该分类的高频词汇
category_words = jieba.lcut(row['product'])
category_words = [word for word in category_words if word not in stopwords and len(word) > 1]
category_word_counts = Counter(category_words)
top_10 = category_word_counts.most_common(10)
for word, count in top_10:
print(f" {word}: {count}")
7.8 创建综合仪表盘
将所有可视化图表整合到一个交互式仪表盘中:
python
# 创建可拖拽布局的仪表盘
page = Page(
layout=Page.DraggablePageLayout, # 可拖拽布局
page_title='项目数据分析Dashboard' # 页面标题
)
# 添加所有图表到仪表盘
page.add(
bar, # 行业类别柱状图
pie, # 行业类别饼图
bar_1, # 投资价格区间分布
box, # 投资价格箱线图
line, # 项目发布趋势
scatter, # 加入数量与人数散点图
line_2, # 双Y轴趋势比较
word_cloud, # 产品信息词云
)
# 渲染为HTML文件
page.render('project_analysis_dashboard.html')
print("综合仪表盘已保存为: project_analysis_dashboard.html")
print("请用浏览器打开查看交互式图表")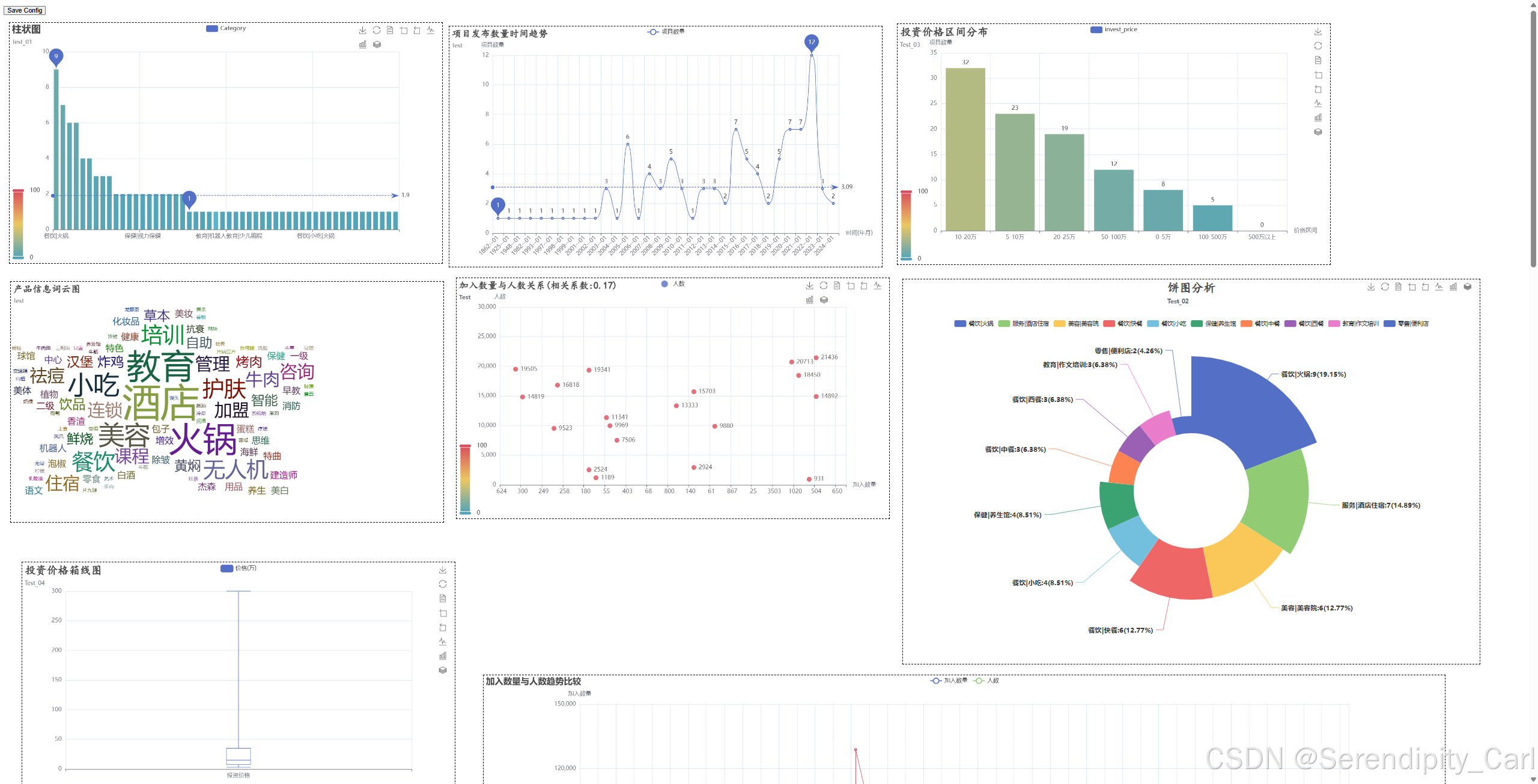
你的点赞和关注是我更新的最大动力!
如果本教程对你有帮助:
-
👍 点赞支持一下
-
💬 评论告诉我你还想学什么爬虫项目
-
🔔 关注我获取更多爬虫和数据挖掘教程
-
⭐ 收藏本文,方便以后查阅
我们一起进步! 🚀