最近我刷到 PageIndex 的文章,说实话,真的让人眼前一亮。
官方对它的介绍是把它叫做"无向量 RAG"。

它最核心的魅力就在于:彻底抛弃了那种笨重的向量数据库,让 AI 像人类专家一样,先看目录、再翻细节,靠迭代式的推理去检索信息。
这一思路的提出,为受限于传统 RAG 应用瓶颈的开发者,带来了全新的解决方向与思路。
为什么说传统 RAG 越来越让人头秃?
以前我们做 RAG,流程大概是这样,把文档切成碎块、转成向量、存进数据库,然后靠语义相似度去做召回,最后把找回内容给到大模型来回复。
但这套方法在处理复杂长文档时,有一些明显问题:
- "长得像"不代表"真的对":向量搜索只看语义接近,但用户的提问往往是表达"意图",而文档里是"内容",两者可能根本对不上号。
- 硬生生切断了逻辑:为了塞进模型,我们不得不把文档暴力切成 512 或 1000 词的小块(Hard Chunking),这刀砍下去,很可能把关键上下文切断了。
- 不理解"跨页参考":如果文档里写一句"详情请看附录 G",传统的向量检索直接就抓瞎了,因为它没法像人一样顺着线索去翻页。
灵感来源:Claude Code 是怎么玩的?
PageIndex 的诞生其实深受 Claude Code 的启发。
Claude Code 在写代码时展现了一种极其简洁却高效的思路。
它根本不用向量数据库,而是给 AI 一套简单的工具(比如 grep 或 glob)和一份精简的文件清单(llms.txt)。
AI 会自己根据任务去思考:"我要修这个 Bug,应该先看哪个文件?",然后自己去搜索、打开并阅读。
这种智能体式检索(Agentic Retrieval )把检索的主动权还给了模型,让模型从一个被动的"信息消费者 "变成了主动的"搜索者"。
PageIndex 如何让 AI 从被动搜索转向主动推理?
既然代码可以这么搞,那复杂的 PDF、财报和技术手册能不能也这么搞?PageIndex 应运而生。
1. 给 AI 一张"地图" (Tree-structured Index)
PageIndex 不再切碎文档,而是把文档变成一棵层级树 。这个索引直接放在模型的上下文窗口(Context Window)里,就像给 AI 发了一份带摘要的详细目录。
PageIndex 树索引示例(JSON 格式):
json
{
"node_id": "0006",
"title": "金融稳定性",
"summary": "联邦储备系统关于风险监控的概述...",
"sub_nodes": [
{
"node_id": "0007",
"title": "监控金融脆弱性",
"summary": "美联储如何通过四个领域监控风险..."
},
...
]
}2. 像人一样"读"文档
有了这张地图,AI 的检索过程就变成了动态推理:
- 扫一眼目录:看看哪一章可能藏着答案。
- 选定章节:锁定具体节点。
- 提取内容:只读那一页或那一节。
- 判断内容是否足够 :如果不够,回第一步接着找;够了就直接写答案。
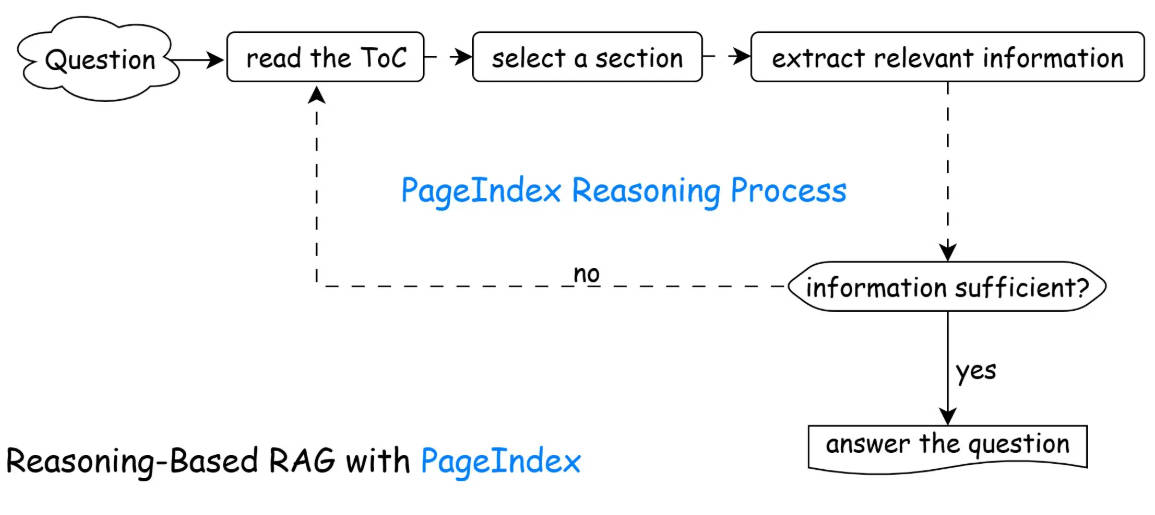
凭什么它能替代传统 RAG?
在 FinanceBench(金融问答基准测试)中,PageIndex 跑出了 98.7% 的准确率,这数据确实挺震撼的。它的优势非常明显:
| 维度 | 传统向量 RAG | PageIndex 方案 |
|---|---|---|
| 核心逻辑 | 语义相似度搜索 | 基于结构的推理检索 |
| 基础设施 | 复杂(向量库、嵌入流水线) | 轻量(JSON 树索引) |
| 可解释性 | 差(不知道为啥搜出这块) | 强(能看到 AI 翻阅的路径) |
| 跨轮对话 | 很难整合聊天历史 | 天然支持(模型记得刚才看了哪) |
什么时候该考虑用它?
如果你手里的文档是长格式、有明确结构 的(比如几百页的财报、法律合同、技术手册),而且你希望 AI 的回答能溯源、精准、不胡说八道,那 PageIndex 绝对是神器。
它把检索从一种"外部的基础设施工程"变回了"模型内部的推理逻辑"。
说白了,就是别再让 AI 像没头苍蝇一样乱搜了,给它一张地图,让它自己去读吧!
个人思考
虽然上面看到 PageIndex 给 RAG 提供了新思路,在某些场景也很不错,但可能也会有几个问题。
它更适合结构化长文档、要精准溯源的场景,可碰到无目录、无排版的非结构化内容,就很难建树状索引,实用性会大打折扣,不如传统 RAG 灵活。
另外,想控制推理成本和响应速度,就要减少无效迭代。可它靠多次主动检索,本身就耗算力,长篇文档下响应通常比传统 RAG 慢,还很吃模型推理能力,逻辑弱一点就会找错、漏信息。
从我个人角度来看,PageIndex 可能暂时没法完全替代传统 RAG,用的时候可能需要匹配好场景、做好预处理,同时权衡好速度和成本。