一、结构化输出 - Structured
1. 概念介绍
这里的结构化输出主要是指大模型可以输出符合要求的JSON数据,JSON数据的正确分两方面来看:
- JSON格式正确。比如
{"count":1}正确,而{"count":1不正确。 - JSON的字段语义正确。比如定义了count字段为数值,那么
{"count":1}正确,而{"count":"一"}不正确。
Langchain(python)提供了- Pydantic、 TypedDict、 JSON Schema 三种方式来定义结构,常用的是Pydantic.
但是早期模型其实不支持JSON格式化输出(API层不提供支持),所以早期的Langchain是通过注入指令/提示词 + 正则提取的方式实现。
到2026年了,很多主流模型都是支持格式化输出了,几乎成了一种标准能力。
2. 返回对象(词典)
🌰例子:我想要了解某个电影的信息,并期望以结构化的数据返回。
python
from app.config import settings
from langchain_openai import ChatOpenAI
from langchain.messages import HumanMessage, AIMessage, SystemMessage
from pydantic import BaseModel, Field
model = ChatOpenAI(
model=settings.glm_model,
base_url=settings.siliconflow_base_url,
api_key=settings.siliconflow_api_key,
temperature=0.9,
max_tokens=3000,
timeout=60,
verbosity=True
)
class Movie(BaseModel):
"""电影的相关信息"""
title: str = Field(..., description="电影名称")
year: int = Field(..., description="电影上映时间")
director: str = Field(..., description="电影的导演")
rating: float = Field(..., description="电影的豆瓣评分")
model_with_structure = model.with_structured_output(Movie)
response = model_with_structure.invoke("介绍下电影《罗小黑战记2》")
print(type(response)) <class '__main__.Movie'>
print(response) # title='电影《罗小黑战记2》的最新情况' year=2024 director='不思凡 / MTJJ (疑似联合执导)' rating=5.0可以看出,我的提示词里面并没有要求LLM如何提取信息,但是返回结果却是按照我给的pydantic模型定义提取了信息,,最终返回一个Pydantic对象。(P.S. 这里的代码,langchain可没有去做增强我们的提示词的事哦,而是把结构化输出的任务交给了LLM provider)
现在主流LLM都支持结构化输出,看看openAI的文档,这些LLM provider内部会做工程化,完成结构化输出这个能力,并提供API。
LLM provider内部工程化,会使用提示词要求大模型按"格式"输出。此外,一方面对大模型加掩码控制一些不合法的输出,另一方面对输出的结果进行校验(如果不满足pydantic的校验,则反馈错误给大模型重试)
最终提取的信息准确度,取决于提示词和LLM的能力。这里如果把提示词换成介绍下电影《罗小黑战记2》,获取title、year、director、rating信息 效果会更好点。
在代码顶部加上下面代码,打印所有的调用日志信息
python
from langchain_core.globals import set_debug
# 开启全局详细模式
set_debug(True)另外,我还做了下实验:下面是我用deepseek v3.2 作为LLM, 跑上面代码,打印的中间信息,可以看出LLM返回了一个序列化的JSON数据(title重复了,说明deepseek v3.2在结构化输出这方面能力还是较差)
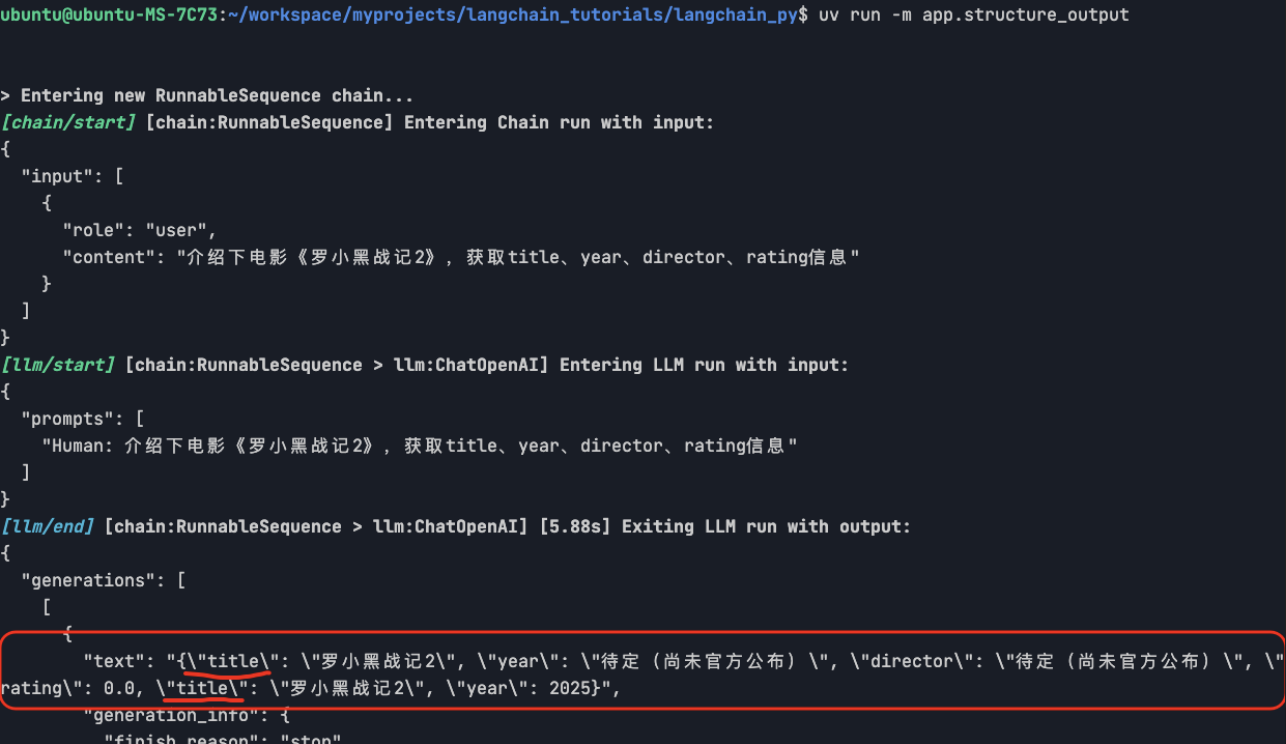
3. 返回列表结构
🌰例子:我希望LLM对我的需求拆分成任务列表。
python
from langchain.agents import create_agent
from app.config import settings
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field, RootModel
from langchain_core.globals import set_debug
# 开启全局详细模式
set_debug(True)
model = ChatOpenAI(
model=settings.glm_model,
base_url=settings.siliconflow_base_url,
api_key=settings.siliconflow_api_key,
temperature=0.9,
max_tokens=3000,
timeout=60,
)
class DevProcessList(RootModel[list[str]]):
"""按顺序的软件开发流程字符串列表"""
def test_structure_list():
model_with_structure = model.with_structured_output(DevProcessList)
response = model_with_structure.invoke(
[{"role": "user", "content": "软件开发的流程是?请给我一个有顺序的字符串列表"}],
)
print(type(response)) # <class '__main__.DevProcessList'>
print(response.model_dump()) # ['需求分析', '系统设计', '编码实现', '软件测试', '部署发布', '运维维护']你可以看出model.with_structured_output这种方式,LLM是严格返回列表(序列化的json)
!\[Pasted image 20260125131309.png]
还有种方式,很多教程都有提到------PydanticOutputParser,核心代码如下:
python
from langchain_core.output_parsers import PydanticOutputParser
model_with_structure = model | PydanticOutputParser(pydantic_object=DevProcessList)
response = model_with_structure.invoke(
[{"role": "user", "content": "软件开发的流程是?请给我一个有顺序的字符串列表"}],
)
print(type(response)) # <class '__main__.DevProcessList'>
print(response.model_dump()) # ['需求分析', '系统设计', '编码实现', '软件测试', '部署发布', '运维维护']LLM的实际输出如下,并不是一个序列化的JSON。
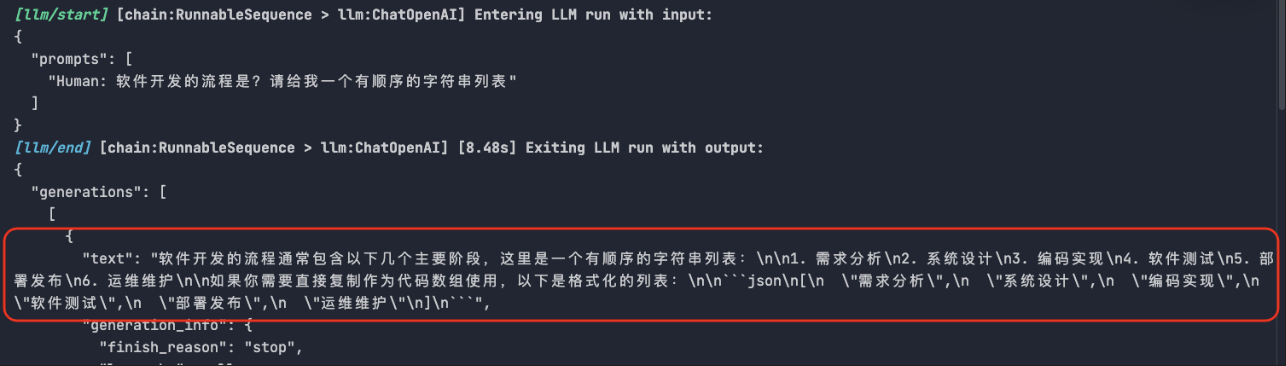
但是langchain还是能正确给我们返回 一个 列表。 原因在于PydanticOutputParser解析器,解析器会在用户提示词注入格式化指令(也是提示词),然后对结构进行正则匹配拿到列表/pydantic对象。
而model.with_structured_output则是通过LLM provider提供的API参数,明确获取结构化数据(几乎100%可靠)
langchain_core 提供了4种结构化输出的解析器CommaSeparatedListOutputParser、StructuredOutputParser、
JsonOutputParser、PydanticOutputParser 。
这些解析器都依赖langchain的指令注入和正则匹配,可靠性一般,生产环境更推荐model.with_structured_output。
P.S 关于列表生成,更推荐使用PydanticOutputParser ,而不是CommaSeparatedListOutputParser,因为CommaSeparatedListOutputParser是langchain根据逗号进行分割和去空格的方式,准确性会存在问题,比如下面:
-
LLM的返回:
"text": "以下是标准软件开发流程(SDLC)的字符串列表:\n\n1. 需求分析\n2. 系统设计\n3. 开发实施\n4. 软件测试\n5. 部署上线\n6. 运维与迭代"
-
langchain解析后返回:
python
['以下是标准软件开发流程(SDLC)的字符串列表:', '1. 需求分析', '2. 系统设计', '3. 开发实施', '4. 软件测试', '5. 部署上线', '6. 运维与迭代']4. agent的结构化输出策略
在 LangChain(尤其是在较新版本的 create_agent 或 LangGraph 架构中)中,ToolStrategy 和 ProviderStrategy 是实现**结构化输出(Structured Output)**的两种核心策略。
简单来说,它们的区别在于"是利用模型原生的结构化能力,还是通过'欺骗'模型调用工具来间接实现结构化"。
create_agent的参数response_format 支持下面4个类型值:
ProviderStrategy使用提供者原生的结构化输出ToolStrategy使用工具调用以获得结构化输出type模式类型 - 根据模型能力自动选择最佳策略None无格式化要求(默认)
代码示例:
python
from pydantic import BaseModel, Field
from langchain.agents import create_agent
class ContactInfo(BaseModel):
"""Contact information for a person."""
name: str = Field(description="The name of the person")
email: str = Field(description="The email address of the person")
phone: str = Field(description="The phone number of the person")
# 自动选择策略(推荐):
agent = create_agent(model, tools, response_format=ContactInfo)
# 使用模型原生提供的,前提是模型API支持
agent = create_agent(model, tools, response_format=ProviderStrategy(ContactInfo))
# 强制使用 ToolStrategy:
from langchain.agents.structured_output import ToolStrategy
agent = create_agent(model, tools, response_format=ToolStrategy(ContactInfo))ToolStrategy vs. ProviderStrategy 的区别
| 维度 | ToolStrategy (工具策略) | ProviderStrategy (厂商原生策略) |
|---|---|---|
| 实现机制 | 模拟工具调用:将你需要的输出 Schema 包装成一个"虚构工具",让模型去调用它。 | 原生 API 支持:直接利用模型厂商提供的结构化输出功能(如 OpenAI 的 JSON Mode 或 Strict Mode)。 |
| 兼容性 | 极高:只要模型支持工具调用(Function Calling),就能使用。 | 有限:仅支持提供原生结构化接口的厂商(如 OpenAI, Anthropic, Google)。 |
| 可靠性 | 中等:依赖模型对工具参数的遵循能力。 | 最高:厂商在模型底层和 API 层做了强校验,输出更稳定。 |
| 使用场景 | 模型不支持原生结构化输出,或需要高度通用的代码实现时。 | 追求最高成功率和严谨的 Schema 校验时。 |
| 默认行为 | 在模型不支持原生结构化时作为备选方案(Fallback)。 | LangChain 在识别到支持的模型时会默认优先选择。 |
选择建议
- 什么时候用 ProviderStrategy?
只要你的模型支持(如 GPT-4o, Claude 3.5 Sonnet),永远优先使用 ProviderStrategy。它在底层有更强的约束,能够减少模型胡言乱语(Hallucination)或格式错误的概率。 - 什么时候用 ToolStrategy?
当你使用的模型较旧、或是某些国产/开源模型仅支持 Function Calling 但没有专门的 JSON Schema 模式时,使用ToolStrategy是实现结构化数据提取的唯一可靠途径。
大多数情况下,建议直接传入type(pydantic对象),让Langchain自己选择策略。
二、工具调用 - Tools
1. 工具调用的演变
主流 LLM 实现工具调用的方式经历了三个阶段,这决定了它们对结构化输出的依赖程度:
第一阶段:纯 Prompt 时代的"软约束"
- 做法 :在 Prompt 里写:"如果你想查天气,请输出 JSON 格式:
{"action": "weather", "city": "xxx"}"。 - 现状:这是早期的做法(如 GPT-3 时代)。
- 问题 :模型经常"掉链子",生成的格式不对,这就往往需要正则来提取函数名和参数。此时,工具调用非常依赖模型的自觉性,解析错误率高。
第二阶段:模型微调的"半强约束"(主流现状)
- 做法:OpenAI (GPT-3.5/4)、Anthropic (Claude 3/3.5)、Google (Gemini) 对模型进行了专门的工具调用微调。
- 现状 :模型看到
tools参数时,会进入一种"工具模式"。 - 依赖关系 :虽然模型努力输出结构化 JSON,但由于没有底层的硬性限制,它仍然可能偶尔输出错误的 JSON 结构。
第三阶段:语法级别(Grammar)的"硬约束"(即 Structured Outputs)
- 做法 :这是 OpenAI 在 2024 年 8 月推出的功能(
strict: true)。 - 原理:在模型生成 Token 的每一瞬间,系统会根据 JSON Schema 过滤掉所有不符合语法的 Token。
- 现状 :这是工具调用的终极形态 。此时,工具调用与结构化输出完全合为一体。如果定义了 Schema,模型物理上不可能输出格式错误的 JSON。
2. Function Calling
OpenAI最早提出Function Calling 的概念和功能。Function Calling 就是一种Tools Calling (在Langchain中所有LLM provider的 "工具使用",包括Function Calling 都被抽象为Tools Calling)。
Function Calling 的流程(5 个步骤):
- 定义函数:你在调用 API 时,提供一份"说明书"(JSON Schema),告诉模型你有几个函数、它们的作用是什么、需要什么参数。
- 模型判断:用户提问(如"帮我查下明天的北京天气")。模型发现这匹配了你定义的函数,于是返回一个特殊的"函数调用请求" JSON。
- 程序执行 :你的后端代码解析这个 JSON,实际运行对应的函数(如去访问气象局 API),并拿到结果。
- 结果反馈:你将函数的运行结果(如"北京明天多云转晴,20度")发回给模型。
- 自然回复:模型根据这个真实数据,组织语言给用户一个自然的最终回答。
关键特性
- 并行调用 (Parallel Function Calling):模型可以一次性决定调用多个函数。例如,问"北京和伦敦天气如何?",模型会一次性输出两个函数调用指令。
- 强制/自动模式 (tool_choice):你可以强制模型必须调用某个工具,或者让它根据对话自行判断是否需要。
- 结构化输出 (Structured Outputs):OpenAI 的最新版本保证了输出的参数百分之百符合你定义的格式要求,极大地提高了生产环境的稳定性。
3. Function Calling vs. MCP的区别
先说总结:MCP是依赖Function Calling 的能力,是对Function Calling (简称FC) 能力的拓展。FC是一种基础能力,而MCP是一种架构协议(这意味这个更好拓展,有利于系统级别开发)。
MCP 包含了3部分
- MCP Host:AI 软件(如 Claude Desktop)。
- MCP Client:协议层,负责协调。
- MCP Server:数据源或工具的提供者(如 Google Drive 插件、数据库查询器)。
在FC中,需要定义函数...调用函数,这些都是在定义流程,并确保LLM能完成这一流程。
而MCP,则是明确分工了。MCP Server负责定义工具/函数;MCP Client负责把这些工具/函数 暴露给LLM并识别LLM的结果调用工具;
这个MCP Server从 「主应用」中抽离出来,可以被多个「应用」复用------只要「应用」实现了MCP Client。
因此,MCP还定义了 MCP Client和 MCP Server之间的通信协议。
4. Langchain 的 Tools设计
工具定义和使用
基础使用
这里我先假设一个场景------电影分析 :
用户希望能准确获取一些《罗小黑》电影的分析,具体来说,希望分析出为什么有人喜欢,有人吐槽。那么就需要真实的影评数据。
首先我们定义一个函数(模拟能从数据库获取 影评 数据)
python
from langchain.tools import tool
@tool
def get_reviews(positive: bool) -> list[str]:
"""
获取罗小黑电影评论列表
Args:
positive: 是否获取正面评论, True 表示获取正面评论, False 表示获取负面评论
Returns:
评论列表
"""
positive_reviews = [
"原来两三岁的小孩也可以不扯女孩裙子啊;原来不整屎尿屁也可以做出让全场大笑的效果啊;原来女角色也可以不穿超短裙高开叉高跟鞋啊;原来男师父女徒弟也可以不暧昧纯师徒情啊;原来一个动画片里正派之间也可以有不同的价值观啊;原来不喊口号不献祭亲朋好友父老乡亲也能表达反战的思想啊。罗小黑你还是太超前了。",
"瑕不掩瑜。非常好的一点是,一点儿爹味都没有,不judge任何人(妖精),没有任何人(妖精)需要被打败或悔过。这在中国的大型说教重灾区---------国漫中已是十分可贵。",
""无限虽然爱装逼,但是他没有跟鹿野搞花千骨,此乃一胜;没有跟罗小黑搞黑猫和他的蓝发师尊,此乃二胜;没有和哪吒搞男同,此乃三胜"",
"我宣布鹿野是我唯一的姐!太帅了!!!工装裤配T恤,低马尾,非传统女性角色,太帅了5555555希望越来越强,早日拳打无限脚踢各大长老!!! 以及,真是好多场经费爆炸的打斗啊",
]
negative_reviews = [
"呃...片方到底懂不懂自己的IP魅力在哪啊!搞什么武器、战争的宏大场面啊,又搞不明白,妥妥露怯!整个剧情就是,稀碎...",
]
return positive_reviews if positive else negative_reviews使用 @tool 装饰器。默认情况下,函数名就是暴露给LLM的名称,函数的 docstring(函数文档字符串) 会成为工具的描述,帮助模型理解何时使用它。
你也可以自定义,比如:
python
@tool("get_movie_reviews", description="获取罗小黑电影评论列表")
def get_reviews(positive: bool) -> list[str]:
"""..."""
...这里我通过 docstring 来进行了参数说明,对于复杂的参数类型描述,你也可以使用pydantic来声明参数,然后类似下面这样使用
python
from pydantic import BaseModel, Field
class ReviewsInput(BaseModel):
"""查询影评的输入参数"""
include_forecast: bool = Field(
default=False,
description="是否获取正面评论, True 表示获取正面评论, False 表示获取负面评论"
)
@tool("get_movie_reviews", args_schema=ReviewsInput)
def get_reviews(positive: bool) -> list[str]:
"""获取罗小黑电影评论列表"""
...测试 是否能正常调用Tool,代码如下,可以看出LLM识别出我们的意图,然后响应说"你可以发起函数调用"
python
def test_tool_calling():
"""
测试工具调用
"""
# reviews = get_reviews.invoke({"positive": True})
# print(reviews) # 输出reviews列表: ["原来两三岁...",...]
model_with_tools = model.bind_tools([get_reviews])
response = model_with_tools.invoke("请分析罗小黑电影的负面评论原因?") # 返回 AIMessage
for tool_call in response.tool_calls:
# 查看函数调用
print(f"Tool: {tool_call['name']}")
print(f"Args: {tool_call['args']}")
# Tool: get_reviews
# Args: {'positive': False}模型输出的结果如图:
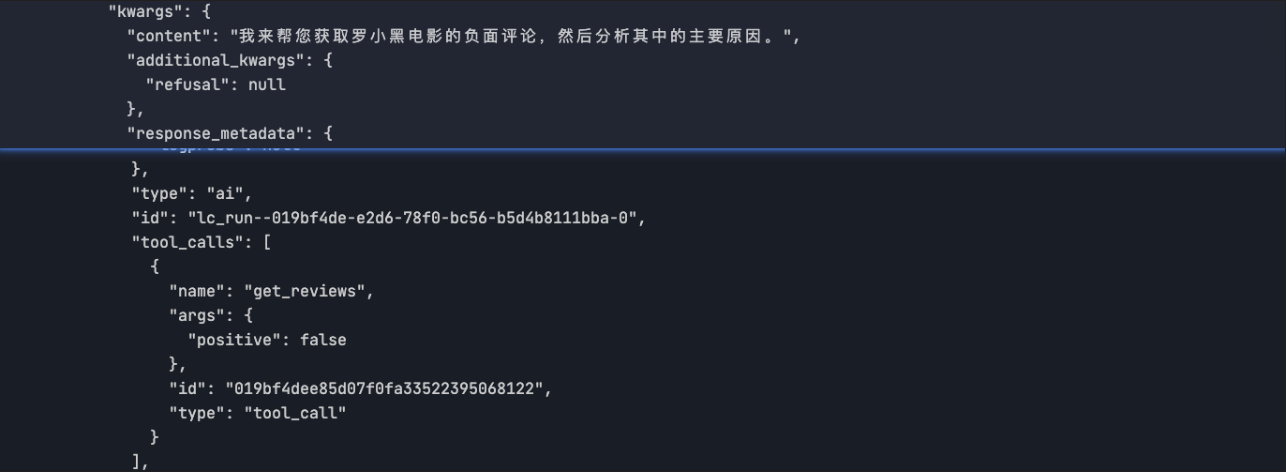
tool_calls数组有内容说明是成功调用了工具,希望我们提供影评数据。下面就带上影评数据进行第二请求。
python
def test_tool_calling_2():
"""
测试工具调用2
"""
model_with_tools = model.bind_tools([get_reviews])
prompt = "请分析罗小黑电影的正面评论原因?"
response = model_with_tools.invoke(prompt) # AIMessage
tool_messages: list[ToolMessage] = []
for tool_call in response.tool_calls:
print(f"Tool: {tool_call['name']}")
print(f"Args: {tool_call['args']}")
reviews = get_reviews.invoke(tool_call["args"])
tool_messages.append(
ToolMessage(
content=json.dumps(reviews, ensure_ascii=False),
tool_call_id=tool_call["id"],
)
)
final_response = model_with_tools.invoke([HumanMessage(content=prompt), response, *tool_messages])
print(final_response.content)
'''输出:
## 🎬 正面评论原因分析
### 1. **儿童教育价值出色**
...
'''这里用ToolMessage 来封装这些影评数据,然后和历史记录一起发送给LLM。
每个由工具返回的
ToolMessage都包含一个与原始工具调用匹配的tool_call_id,这有助于模型将结果与请求关联起来。
下面贴出两次请求的提示词,你可以看到Langchain帮我做了那些事。
json
{
"prompts": [
"Human: 请分析罗小黑电影的正面评论原因?"
]
}
json
{
"prompts": [
"Human: 请分析罗小黑电影的正面评论原因?\nAI: 我来帮您获取罗小黑电影的正面评论,然后分析其中的正面评价原因。[{'name': 'get_reviews', 'args': {'positive': True}, 'id': '019bf500873b7d3b26cbb49ba71c4984', 'type': 'tool_call'}]\nTool: [\"原来两三岁的小孩也可以不扯女孩裙子啊;原来不整屎尿屁也可以做出让全场大笑的效果啊;原来女角色也可以不穿超短裙高开叉高跟鞋啊;原来男师父女徒弟也可以不暧昧纯师徒情啊;原来一个动画片里正派之间也可以有不同的价值观啊;原来不喊口号不献祭亲朋好友父老乡亲也能表达反战的思想啊。罗小黑你还是太超前了。\", \"瑕不掩瑜。非常好的一点是,一点儿爹味都没有,不judge任何人(妖精),没有任何人(妖精)需要被打败或悔过。这在中国的大型说教重灾区---------国漫中已是十分可贵。\", \""无限虽然爱装逼,但是他没有跟鹿野搞花千骨,此乃一胜;没有跟罗小黑搞黑猫和他的蓝发师尊,此乃二胜;没有和哪吒搞男同,此乃三胜"\", \"我宣布鹿野是我唯一的姐!太帅了!!!工装裤配T恤,低马尾,非传统女性角色,太帅了5555555希望越来越强,早日拳打无限脚踢各大长老!!! 以及,真是好多场经费爆炸的打斗啊\"]"
]
}P.S. invoke会将Message列表 序列化成字符串,其中ToolMessage就是:
Tool: [工具调用返回的消息]强制工具使用
默认情况下,模型会根据用户的输入自由选择使用哪个绑定工具。但是,你可能希望强制选择一个工具,确保模型使用特定的工具或给定列表中的任何工具:
python
model_with_tools = model.bind_tools([tool_1], tool_choice="tool_1")并行工具调用
许多模型在适当的情况下支持并行调用多个工具。这使模型能够同时从不同来源收集信息。
你留意到了吗?前面的tool_calls字段是一个数组,意味着可以调用多个工具。那么我们试一试下面的提问(只是把问题改了,看下结果):
"请分析罗小黑电影的正面评论原因和负面评论原因?"现在问题同时包含"正面原因分析"和"负面原因分析",LLM会调用两次工具 分别查询出正面评论和负面评论吗?
结论:会。
回答结果如下:
基于获取的评论数据,我来为您分析罗小黑电影的正面和负面评论原因:
## 正面评论的主要原因:
...
## 负面评论的主要原因:
...流工具调用
这里直接贴出官方的例子吧~
python
for chunk in model_with_tools.stream(
"What's the weather in Boston and Tokyo?"
):
# Tool call chunks arrive progressively
for tool_chunk in chunk.tool_call_chunks:
if name := tool_chunk.get("name"):
print(f"Tool: {name}")
if id_ := tool_chunk.get("id"):
print(f"ID: {id_}")
if args := tool_chunk.get("args"):
print(f"Args: {args}")
# Output:
# Tool: get_weather
# ID: call_SvMlU1TVIZugrFLckFE2ceRE
# Args: {"lo
# Args: catio
# Args: n": "B
# Args: osto
# Args: n"}
# Tool: get_weather
# ID: call_QMZdy6qInx13oWKE7KhuhOLR
# Args: {"lo
# Args: catio
# Args: n": "T
# Args: okyo
# Args: "}访问上下文
试想一下,如果下面的get_reviews想要访问一些其他信息,这些信息又不应该暴露给LLM使用,那么如何处理呢?Langchain给出了答案:ToolRuntime。
python;
@tool
def get_reviews(positive: bool) -> list[str]:
"""
"""
pass其实很简单,就是给你定义的工具函数传入一个ToolRuntime的参数(句柄),这个句柄可以获取上下文信息。
python
@dataclass
class Context:
user_id: str
@tool
def get_reviews_with_runtime(
positive: bool,
runtime: ToolRuntime[Context] # ToolRuntime 对模型不可见, 最终的实际tool 函数的参数不会包含runtime
) -> list[str]:
"""
获取罗小黑电影评论列表
Args:
positive: 是否获取正面评论, True 表示获取正面评论, False 表示获取负面评论
Returns:
评论列表
"""
print("1.查看对话的状态")
print(runtime.state["messages"])
# [HumanMessage(content='请分析罗小黑电影的正面评论原因?'), IMessage(content='我来帮您获取罗小黑电影的正面评论并分析其中的原因。'), ...]
print("2.借助user_id,可以查询user的个人信息")
user_id = runtime.context.user_id
print(f"user_id: {user_id}")
# user_id: user123
print("3.在长任务中,使用stream_writer反馈进度,通常配合langgraph使用")
writer = runtime.stream_writer
writer({"status": "starting", "message": f"正在处理查询"})
writer({"status": "progress", "message": f"完成50%"})
#...运行agent,调用工具,查看上下文信息打印。
python
def test_tool_runtime():
agent = create_agent(
model,
tools=[get_reviews_with_runtime],
context_schema=Context,
)
result = agent.invoke(
{"messages": [{"role": "user", "content": "请分析罗小黑电影的正面评论原因?"}]},
context=Context(user_id="user123")
)附录
代码 - 传送门
本章节对应的代码: