文章目录
- [一、图片补全(Image Inpainting)含义、用途及过程示意图](#一、图片补全(Image Inpainting)含义、用途及过程示意图)
-
- [1. 图片补全的含义](#1. 图片补全的含义)
- [2. 图片补全的核心用途](#2. 图片补全的核心用途)
- [3. 图片补全过程示意图(文字+结构示意)](#3. 图片补全过程示意图(文字+结构示意))
- 二、算法技术路线
-
- [1.Context Encoder(2016)](#1.Context Encoder(2016))
-
- 1)、核心架构:编码器-解码器(Encoder-Decoder)主结构、核心架构:编码器-解码器(Encoder-Decoder)主结构)
- 2)、核心目标:联合损失函数(重建损失 + 对抗损失)、核心目标:联合损失函数(重建损失 + 对抗损失))
- 3)、核心设计:通道丢弃式上下文学习、核心设计:通道丢弃式上下文学习)
- 4)、核心定位:上下文感知的端到端补全、核心定位:上下文感知的端到端补全)
- 5)、代码解析、代码解析)
一、图片补全(Image Inpainting)含义、用途及过程示意图
1. 图片补全的含义
图片补全,也常称图像修复/图像填充 ,是计算机视觉与图像处理领域的核心任务之一,指针对图像中存在缺失、破损、遮挡或人为指定的空白区域,利用图像自身的有效信息或外部先验知识,自动生成视觉上合理、语义上连贯的内容,将缺失区域补全,使修复后的图像整体自然无违和感的技术。
缺失区域可分为两类:
- 结构性缺失:如照片划痕、污渍、文字遮挡、物体破损等,区域边界有明确的纹理/结构延续性;
- 语义性缺失:如主动移除图像中的物体后留下的大面积空白,需要补全符合场景逻辑的内容(如移除人物后补全背景草地、建筑)。
2. 图片补全的核心用途
图片补全的应用覆盖工业修复、内容创作、视觉预处理、隐私保护等多个场景,核心用途如下:
- 老旧/破损图像修复
修复老照片的划痕、褪色、折痕、霉斑,修复扫描文档的污渍/缺角,还原历史影像和文档的完整性,是数字档案修复的关键技术。 - 内容编辑与创作
移除图像中多余的物体(如路人、广告牌、水印),补全被遮挡的主体;影视后期中补全绿幕/穿帮区域,艺术创作中生成缺失的图像局部,提升内容美观度与完整性。 - 视觉任务预处理
为目标检测、图像分割、人脸识别等下游任务预处理数据,去除图像中的噪声遮挡、补全传感器采集时的缺失像素(如医学影像、遥感图像的坏点/坏行),提升模型训练与推理的精度。 - 隐私与安全处理
主动遮挡敏感信息(如人脸、车牌、个人信息)后,自然补全遮挡区域,避免生硬的黑块/白块,兼顾隐私保护与图像视觉合理性。 - 特殊图像领域应用
医学影像中补全MRI/CT的扫描缺失区域,辅助医生诊断;遥感图像中修复云层遮挡、传感器故障导致的缺失数据,用于地理监测与分析。
3. 图片补全过程示意图(文字+结构示意)
图片补全的通用流程分为输入与区域标注→特征提取→内容生成→融合优化→输出修复图像五步,以下是结构化示意图(文字版,可直接转化为可视化流程图):
输入原始图像
标注缺失区域Mask
特征提取:提取有效区域的纹理/结构/语义特征
内容生成:基于特征生成缺失区域的填充内容
融合优化:边界平滑+纹理一致性+语义合理性调整
输出完整修复图像
各步骤细节示意:
- 输入与Mask标注:左侧为带缺失区域的原始图像(如中间有黑色空白块),右侧为二值化Mask图(缺失区域为1,有效区域为0);
- 特征提取:通过传统算法(如纹理合成)或深度学习(如CNN、Transformer)提取有效区域的局部纹理、边缘结构、全局语义信息;
- 内容生成:传统方法基于邻域纹理匹配填充,深度学习方法通过编码器-解码器生成符合场景的内容;
- 融合优化:对填充区域与原始区域的边界做高斯平滑、泊松融合,消除拼接痕迹,调整色彩/亮度一致性;
- 输出结果:缺失区域被自然补全,图像整体视觉连贯。
二、算法技术路线
1.Context Encoder(2016)
Context Encoder是由Pathak等人在2016年提出的基于深度学习的图像补全经典算法 ,是首个将无监督表示学习 与图像补全 结合的端到端模型,核心思想围绕上下文感知的编码-解码生成 与对抗性约束展开,具体分为四大核心要点:
1)、核心架构:编码器-解码器(Encoder-Decoder)主结构
Context Encoder采用全卷积的编码器-解码器架构 ,摒弃全连接层,保留图像的空间结构信息,实现从局部上下文到缺失区域的端到端生成:
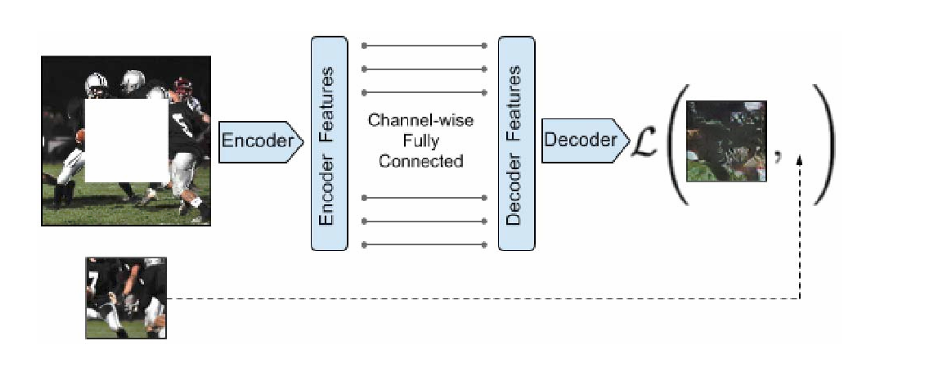
图 :上下文编码器。将上下文图像送入编码器以提取特征,这些特征通过 3.1节所述的按通道全连接层与解码器相连,随后解码器生成图像中的缺失区域。
- 编码器(Encoder)
输入为带缺失区域的图像 ,通过多层卷积+池化(或步幅卷积)逐步压缩空间维度,提取全局上下文特征 (包括图像的语义信息、结构布局、纹理规律),将原始图像映射为低维、高语义的特征向量,核心是捕捉缺失区域周边的有效上下文信息,为生成提供先验。 - 解码器(Decoder)
输入为编码器输出的全局特征,通过多层反卷积(转置卷积)逐步上采样,恢复图像的空间分辨率,直接生成缺失区域的像素内容,将高维语义特征还原为与原始图像尺寸匹配的填充区域,实现从特征到像素的映射。
2)、核心目标:联合损失函数(重建损失 + 对抗损失)
Context Encoder的创新点在于结合像素级重建约束与对抗性语义约束,既保证填充内容的像素准确性,又保证视觉合理性,避免传统方法的模糊、纹理重复问题:
- 重建损失(L2 Loss/MSE Loss)
计算解码器生成的填充内容与真实缺失区域标签的均方误差,约束生成内容在像素级上贴近真实值,保证基础的结构与纹理准确性,是模型的基础优化目标。 - 对抗损失(Adversarial Loss)
引入判别器(Discriminator) 构成生成对抗网络(GAN)分支:判别器负责区分"模型生成的填充区域"和"真实图像的对应区域",编码器-解码器作为生成器,试图欺骗判别器。通过对抗训练,让生成内容在语义、视觉风格上符合真实图像的分布,解决单纯重建损失导致的填充内容模糊、缺乏细节的问题。
3)、核心设计:通道丢弃式上下文学习
Context Encoder采用随机通道丢弃(Channel-wise Dropout) 或固定区域掩码 的方式模拟缺失区域,在无监督场景下(无需人工标注缺失区域的真实标签),让模型自主学习从周边上下文推断缺失内容的能力:
- 训练时,随机遮挡图像的局部区域(如中心正方形、随机矩形),模型仅通过未遮挡区域的上下文信息生成遮挡内容;
- 这种无监督训练方式让模型学习到通用的图像上下文规律,而非拟合特定缺失区域,泛化性更强。
4)、核心定位:上下文感知的端到端补全
Context Encoder的核心突破是摆脱传统图像补全对局部纹理匹配的依赖 ,从全局上下文语义出发生成内容:
- 传统方法(如PatchMatch)仅基于邻域小范围纹理合成,难以处理大面积、语义复杂的缺失区域;
- Context Encoder通过编码器提取全局语义,解码器结合对抗约束生成符合场景逻辑的内容,既能补全简单纹理区域,也能处理需要语义理解的复杂场景(如补全人物背景的建筑、自然景观),为后续基于GAN/Transformer的图像补全模型奠定了基础。
总结:Context Encoder的本质是以编码器-解码器为骨架,以重建损失保证像素精度、对抗损失保证视觉真实,通过无监督上下文学习实现端到端的图像缺失区域补全,是深度学习图像补全领域的里程碑式算法。
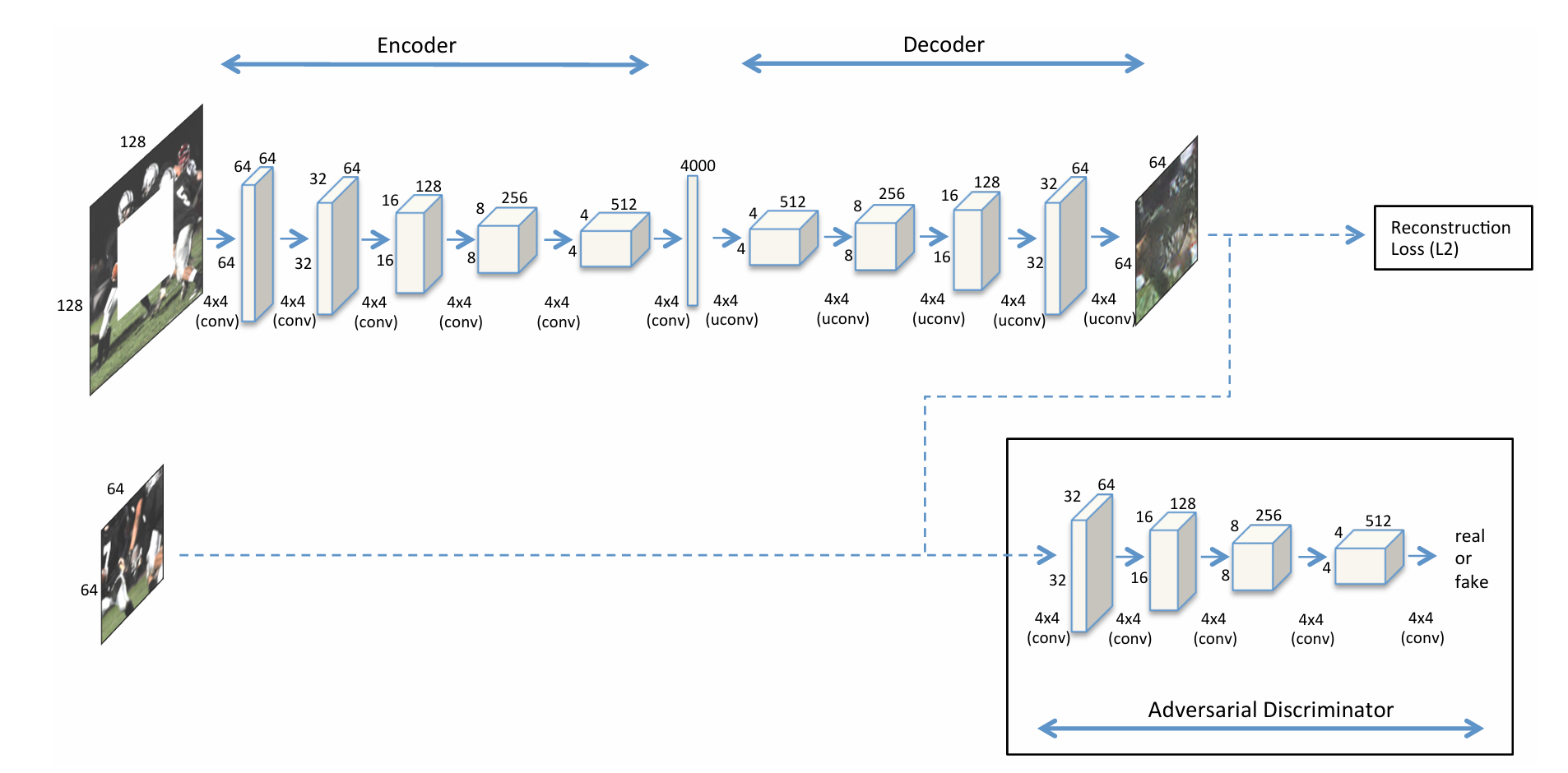
图a:带对抗损失的语义补全上下文编码器架构
核心目标 :实现语义图像补全(semantic inpainting) ,针对图像中缺失的中心区域(演示为64×64的"center region dropout"),生成视觉真实、语义连贯的补全内容。训练时联合优化重建损失(L2 Loss)和对抗损失(Adversarial Loss),兼顾像素精度与生成真实感。
1. 编码器(Encoder):提取全局上下文特征
- 输入:带64×64中心缺失区域的128×128图像(RGB通道数为3)。
- 结构 :5层卷积层(Conv2d),逐步下采样并增加通道数,压缩空间维度的同时提取多尺度纹理与语义特征:
- 第1层:128×128×3 → 4×4卷积(步幅2,填充1)→ 输出64×64×64(尺寸减半,通道数64)。
- 第2层:64×64×64 → 4×4卷积(步幅2,填充1)→ 输出32×32×64。
- 第3层:32×32×64 → 4×4卷积(步幅2,填充1)→ 输出16×16×128(通道数翻倍至128)。
- 第4层:16×16×128 → 4×4卷积(步幅2,填充1)→ 输出8×8×256(通道数翻倍至256)。
- 第5层:8×8×256 → 4×4卷积(步幅2,填充1)→ 输出4×4×512(通道数翻倍至512)。
- 输出:4×4×4000的瓶颈特征图(压缩全局上下文信息,为解码器提供生成依据)。
2. 解码器(Decoder):生成缺失区域内容
- 输入:编码器输出的4×4×4000瓶颈特征。
- 结构 :5层转置卷积层(ConvTranspose2d,标注为"uconv"),逐步上采样并减少通道数,将低维特征还原为高分辨率图像:
- 第1层:4×4×4000 → 4×4转置卷积(步幅1,填充0)→ 输出4×4×512(通道数降至512)。
- 第2层:4×4×512 → 4×4转置卷积(步幅2,填充1)→ 输出8×8×256(尺寸翻倍,通道数减半)。
- 第3层:8×8×256 → 4×4转置卷积(步幅2,填充1)→ 输出16×16×128。
- 第4层:16×16×128 → 4×4转置卷积(步幅2,填充1)→ 输出32×32×64。
- 第5层:32×32×64 → 4×4转置卷积(步幅2,填充1)→ 输出64×64×64(生成与缺失区域尺寸匹配的补全内容)。
- 输出:64×64的补全区域,填充回原始图像后得到完整的128×128图像。
3. 对抗判别器(Adversarial Discriminator):判别补全区域真实性
- 输入:生成的64×64补全区域(或真实图像的对应区域)。
- 结构 :4层卷积层(Conv2d),下采样提取判别特征,最终输出"真实(real)"或"生成(fake)"的概率:
- 第1层:64×64×3 → 4×4卷积(步幅2,填充1)→ 输出32×32×64。
- 第2层:32×32×64 → 4×4卷积(步幅2,填充1)→ 输出16×16×128。
- 第3层:16×16×128 → 4×4卷积(步幅2,填充1)→ 输出8×8×256。
- 第4层:8×8×256 → 4×4卷积(步幅2,填充1)→ 输出4×4×512。
- 第5层:4×4×512 → 4×4卷积(步幅1,填充0)→ 输出1×1×1(Sigmoid激活后输出概率)。
- 作用:通过对抗训练迫使生成器生成更逼真的补全区域,解决单纯重建损失导致的模糊问题。
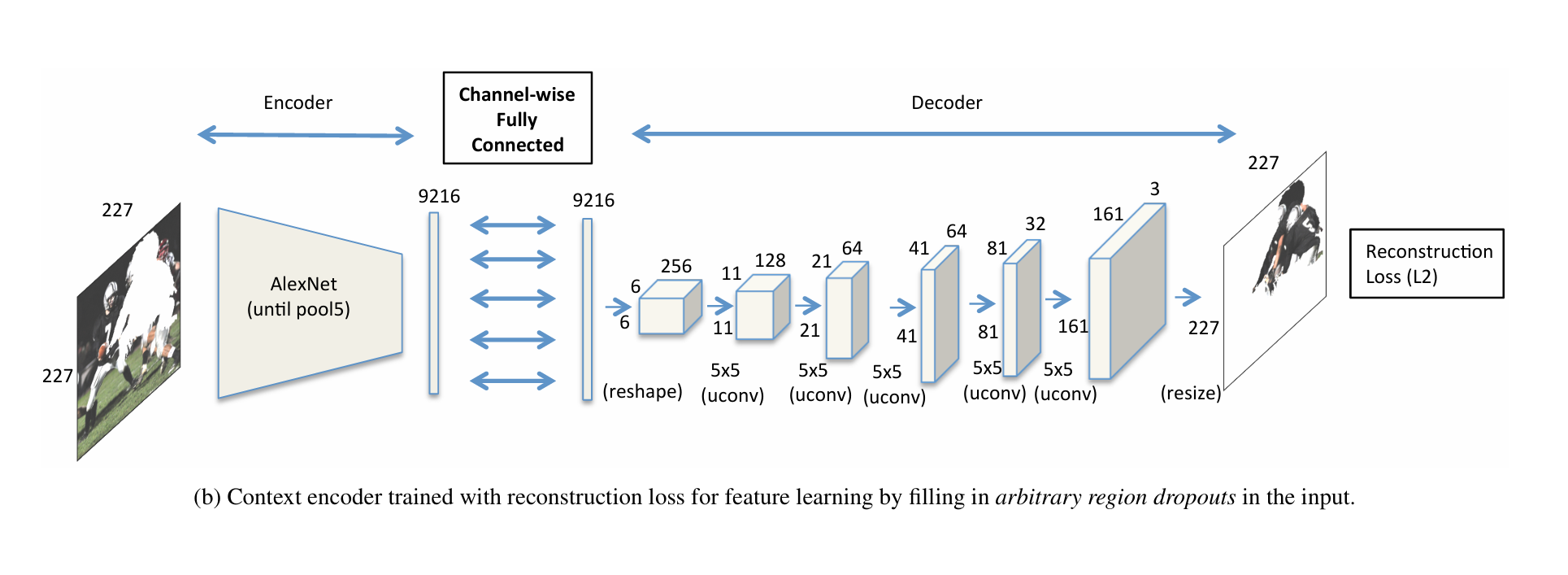
图b:用于特征学习的上下文编码器架构(仅重建损失)
核心目标 :通过填充输入图像中任意缺失区域(arbitrary region dropouts),进行无监督特征学习(unsupervised feature learning),仅用重建损失优化,不依赖对抗约束。
1. 编码器(Encoder):基于AlexNet的特征提取
- 输入:227×227的图像(AlexNet标准输入尺寸),含任意缺失区域。
- 结构 :复用AlexNet的前5层卷积+池化(until pool5) ,提取高维语义特征:
- 经AlexNet的conv1→pool1→conv2→pool2→conv3→conv4→conv5→pool5后,输出为6×6×256的特征图(空间尺寸6×6,通道数256)。
- 展平后得到9216维向量(6×6×256=9216),作为编码器最终输出。
2. 按通道全连接层(Channel-wise Fully Connected)
- 作用:连接编码器与解码器的特征通道,保持通道维度一致(输入输出均为9216维),实现通道级特征映射,避免全连接层破坏空间结构。
- 输入:编码器输出的9216维向量。
- 输出:9216维向量,直接传递给解码器。
3. 解码器(Decoder):生成完整图像
- 输入 :按通道全连接层输出的9216维向量,先reshape为6×6×256(恢复空间结构)。
- 结构 :6层转置卷积层(ConvTranspose2d,标注为"uconv"),逐步上采样至原始输入尺寸227×227:
- 第1层:6×6×256 → 5×5转置卷积(步幅1,填充2)→ 输出11×11×128(尺寸放大,通道数减半)。
- 第2层:11×11×128 → 5×5转置卷积(步幅2,填充2)→ 输出21×21×64。
- 第3层:21×21×64 → 5×5转置卷积(步幅2,填充2)→ 输出41×41×64。
- 第4层:41×41×64 → 5×5转置卷积(步幅2,填充2)→ 输出81×81×32。
- 第5层:81×81×32 → 5×5转置卷积(步幅2,填充2)→ 输出161×161×16。
- 第6层:161×161×16 → 5×5转置卷积(步幅1,填充2)+ 尺寸调整(resize)→ 输出227×227×3(与输入尺寸、通道数一致)。
- 输出:227×227的补全图像,填充了输入中的任意缺失区域。
4. 损失函数
- 仅重建损失(L2):计算生成图像与原始图像的像素均方误差,迫使编码器学习通用的图像上下文特征,用于无监督预训练或特征表示学习。
5)、代码解析
模型代码:
github链接
python
# 导入PyTorch核心库,用于张量计算和自动求导
import torch
# 导入PyTorch神经网络层模块,包含卷积、激活、归一化等所有基础层
import torch.nn as nn
# 定义生成器网络 _netG,继承nn.Module(PyTorch所有网络的基类)
# 功能:实现Context Encoder的编码器-瓶颈层-解码器架构,输入带缺失的128×128图像,生成补全的64×64区域
class _netG(nn.Module):
def __init__(self, opt):
# 调用父类nn.Module的初始化方法,固定写法
super(_netG, self).__init__()
# 记录GPU数量,用于后续多GPU并行训练
self.ngpu = opt.ngpu
# 构建生成器的主网络:Sequential是按顺序执行的层容器,按编码器→瓶颈层→解码器组织
self.main = nn.Sequential(
# --------------------------- 编码器(Encoder):下采样提取上下文特征 ---------------------------
# 输入尺寸:(nc) x 128 x 128 | nc:图像通道数(RGB=3,灰度图=1)
# 卷积层:核4×4,步幅2,填充1,无偏置 | 作用:下采样(尺寸减半),通道数提升至nef
# 无偏置原因:后续接BatchNorm,BatchNorm的β会替代偏置的作用,减少计算量
nn.Conv2d(opt.nc, opt.nef, 4, 2, 1, bias=False),
# LeakyReLU激活:斜率0.2,inplace=True(原地操作,节省内存)
# 编码器全程用LeakyReLU,解决负区间梯度消失问题,适配下采样的特征提取
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(nef) x 64 x 64 | nef:生成器编码器的基础通道数(如64)
# 第二层卷积:通道数保持nef,下采样至32×32
nn.Conv2d(opt.nef, opt.nef, 4, 2, 1, bias=False),
# 批量归一化:加速训练,防止梯度消失,稳定特征分布
nn.BatchNorm2d(opt.nef),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(nef) x 32 x 32
# 第三层卷积:通道数翻倍至nef*2,下采样至16×16
nn.Conv2d(opt.nef, opt.nef*2, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.nef*2),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(nef*2) x 16 x 16
# 第四层卷积:通道数翻倍至nef*4,下采样至8×8
nn.Conv2d(opt.nef*2, opt.nef*4, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.nef*4),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(nef*4) x 8 x 8
# 第五层卷积:通道数翻倍至nef*8,下采样至4×4(编码器下采样极限)
nn.Conv2d(opt.nef*4, opt.nef*8, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.nef*8),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(nef*8) x 4 x 4
# --------------------------- 瓶颈层(Bottleneck):全局上下文特征压缩 ---------------------------
# Context Encoder的核心:将4×4特征压缩为1×1的瓶颈特征,捕捉全局上下文信息
# 卷积层:核4×4,步幅1,填充0,无偏置 | 4×4输入刚好输出1×1,通道数转为nBottleneck
nn.Conv2d(opt.nef*8, opt.nBottleneck, 4, bias=False),
nn.BatchNorm2d(opt.nBottleneck),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(nBottleneck) x 1 x 1 | nBottleneck:瓶颈层通道数(如1024),存储全局上下文特征
# --------------------------- 解码器(Decoder):上采样生成补全区域 ---------------------------
# 转置卷积(ConvTranspose2d):与卷积相反,实现上采样(尺寸放大),核心用于生成像素
# 第一层转置卷积:从1×1瓶颈特征上采样至4×4,通道数转为ngf*8
# 核4×4,步幅1,填充0,无偏置 | 1×1输入刚好输出4×4
nn.ConvTranspose2d(opt.nBottleneck, opt.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(opt.ngf * 8),
# 解码器全程用ReLU激活:保证生成特征的非负性,提升生成的多样性
nn.ReLU(True),
# 输出尺寸:(ngf*8) x 4 x 4 | ngf:生成器解码器的基础通道数(如64)
# 第二层转置卷积:上采样至8×8,通道数减半至ngf*4
# 核4×4,步幅2,填充1 | 通用上采样公式:输出尺寸=(输入-1)*步幅 + 核 - 2*填充
nn.ConvTranspose2d(opt.ngf * 8, opt.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ngf * 4),
nn.ReLU(True),
# 输出尺寸:(ngf*4) x 8 x 8
# 第三层转置卷积:上采样至16×16,通道数减半至ngf*2
nn.ConvTranspose2d(opt.ngf * 4, opt.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ngf * 2),
nn.ReLU(True),
# 输出尺寸:(ngf*2) x 16 x 16
# 第四层转置卷积:上采样至32×32,通道数减半至ngf
nn.ConvTranspose2d(opt.ngf * 2, opt.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ngf),
nn.ReLU(True),
# 输出尺寸:(ngf) x 32 x 32
# 最后一层转置卷积:上采样至64×64,通道数还原为nc(与输入图像通道一致)
nn.ConvTranspose2d(opt.ngf, opt.nc, 4, 2, 1, bias=False),
# Tanh激活:将像素值映射到[-1, 1],符合GAN的图像归一化标准(训练前图像会归一化到[-1,1])
nn.Tanh()
# 最终输出尺寸:(nc) x 64 x 64 → 补全后的64×64局部区域
)
# 前向传播方法:定义网络的张量计算流程,PyTorch自动求导的基础
def forward(self, input):
# 判断是否满足多GPU并行条件:输入是CUDA张量 且 GPU数量>1
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
# 多GPU并行计算:将main网络分发到多个GPU,输入数据拆分计算后合并
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
# 单GPU/CPU:直接执行main序列的层计算
output = self.main(input)
# 返回生成的64×64补全区域
return output
# 定义局部判别器网络 _netlocalD,继承nn.Module
# 功能:Context Encoder的**局部判别器**(区别于全局判别器),仅判别生成器输出的64×64补全区域是否为真实图像
# 输出[0,1]的概率值:0=生成的假区域,1=真实的图像区域
class _netlocalD(nn.Module):
def __init__(self, opt):
super(_netlocalD, self).__init__()
# 记录GPU数量,用于多GPU并行
self.ngpu = opt.ngpu
# 构建判别器主网络:纯卷积下采样结构(DCGAN风格),无全连接层,保留空间特征
self.main = nn.Sequential(
# 输入尺寸:(nc) x 64 x 64 → 生成器输出的补全区域
nn.Conv2d(opt.nc, opt.ndf, 4, 2, 1, bias=False),
# 判别器全程用LeakyReLU(0.2):防止梯度消失,提升判别器的稳定性
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(ndf) x 32 x 32 | ndf:判别器的基础通道数(如64)
# 第二层卷积:通道翻倍至ndf*2,下采样至16×16
nn.Conv2d(opt.ndf, opt.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(ndf*2) x 16 x 16
# 第三层卷积:通道翻倍至ndf*4,下采样至8×8
nn.Conv2d(opt.ndf * 2, opt.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(ndf*4) x 8 x 8
# 第四层卷积:通道翻倍至ndf*8,下采样至4×4
nn.Conv2d(opt.ndf * 4, opt.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(opt.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出尺寸:(ndf*8) x 4 x 4
# 最后一层卷积:通道数转为1(单通道输出概率),4×4→1×1
# 核4×4,步幅1,填充0,无偏置 | 4×4输入刚好输出1×1
nn.Conv2d(opt.ndf * 8, 1, 4, 1, 0, bias=False),
# Sigmoid激活:将输出映射到[0,1],表示输入区域为"真实图像"的概率
nn.Sigmoid()
)
# 前向传播方法
def forward(self, input):
# 多GPU并行判断与计算,同生成器逻辑
if isinstance(input.data, torch.cuda.FloatTensor) and self.ngpu > 1:
output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
else:
output = self.main(input)
# 将输出的1×1张量展平为(batch_size, 1)的形状,方便后续计算对抗损失(如BCELoss)
# -1表示自动匹配批次大小,适配任意批量的输入
return output.view(-1, 1)主函数训练代码
python
# 从python2兼容python3的print函数,旧版PyTorch常用兼容写法
from __future__ import print_function
# 导入命令行参数解析库,用于灵活设置训练超参数
import argparse
# 导入系统库,用于文件夹创建、路径操作
import os
# 导入随机数库,用于设置随机种子保证实验可复现
import random
# 导入PyTorch核心库
import torch
import torch.nn as nn
# 导入PyTorch多GPU并行训练模块
import torch.nn.parallel
# 导入PyTorch CUDA加速相关模块,用于提升训练效率
import torch.backends.cudnn as cudnn
# 导入PyTorch优化器模块(Adam/SGD等)
import torch.optim as optim
# 导入PyTorch数据加载器
import torch.utils.data
# 导入PyTorch内置的数据集(ImageFolder/LSUN/CIFAR10等)
import torchvision.datasets as dset
# 导入PyTorch图像预处理模块(缩放、裁剪、归一化等)
import torchvision.transforms as transforms
# 导入PyTorch图像保存工具,用于保存训练过程中的补全结果
import torchvision.utils as vutils
# 导入PyTorch旧版的变量封装类(新版已整合到Tensor,无需单独使用)
from torch.autograd import Variable
# 从自定义model.py中导入生成器_netG、局部判别器_netlocalD
from model import _netlocalD,_netG
# 导入自定义工具库(代码中未实际调用,为预留扩展)
import utils
# ========================== 第一步:命令行参数解析 ==========================
# 创建参数解析器对象
parser = argparse.ArgumentParser()
# 数据集类型:streetview(街景,默认) | cifar10 | lsun | imagenet | folder | lfw
parser.add_argument('--dataset', default='streetview', help='cifar10 | lsun | imagenet | folder | lfw ')
# 数据集根路径
parser.add_argument('--dataroot', default='dataset/train', help='path to dataset')
# 数据加载的工作线程数,多线程加速数据读取
parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
# 批次大小(batch size),默认64
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
# 输入图像尺寸(高/宽),默认128×128(Context Encoder论文标准)
parser.add_argument('--imageSize', type=int, default=128, help='the height / width of the input image to network')
# 以下为GAN通用超参数(本代码中nz未实际使用,为GAN框架预留)
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--ngf', type=int, default=64, help='生成器解码器基础通道数')
parser.add_argument('--ndf', type=int, default=64, help='判别器基础通道数')
parser.add_argument('--nc', type=int, default=3, help='图像通道数,RGB=3,灰度图=1')
# 训练轮数(epoch),默认25
parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
# 学习率,默认0.0002(DCGAN经典学习率)
parser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')
# Adam优化器的beta1参数,默认0.5(DCGAN经典值,加速训练收敛)
parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
# 是否使用CUDA加速(GPU训练),加--cuda参数则启用
parser.add_argument('--cuda', action='store_true', help='enables cuda')
# 使用的GPU数量,默认1
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
# 生成器预训练模型路径,用于断点续训,默认空
parser.add_argument('--netG', default='', help="path to netG (to continue training)")
# 判别器预训练模型路径,用于断点续训,默认空
parser.add_argument('--netD', default='', help="path to netD (to continue training)")
# 输出结果根路径,默认当前目录
parser.add_argument('--outf', default='.', help='folder to output images and model checkpoints')
# 手动设置随机种子,保证实验可复现,默认随机
parser.add_argument('--manualSeed', type=int, help='manual seed')
# ========================== Context Encoder 专属超参数 ==========================
# 生成器编码器瓶颈层通道数,默认4000(论文标准)
parser.add_argument('--nBottleneck', type=int,default=4000,help='of dim for bottleneck of encoder')
# 补全区域的重叠边缘宽度,默认4,用于边缘加权L2损失,让补全边缘更平滑
parser.add_argument('--overlapPred',type=int,default=4,help='overlapping edges')
# 生成器编码器基础通道数,默认64
parser.add_argument('--nef',type=int,default=64,help='of encoder filters in first conv layer')
# L2重建损失的权重,默认0.998,对抗损失权重为1-0.998=0.002
parser.add_argument('--wtl2',type=float,default=0.998,help='0 means do not use else use with this weight')
# 判别器损失权重(预留参数,代码中实际用1-wtl2)
parser.add_argument('--wtlD',type=float,default=0.001,help='0 means do not use else use with this weight')
# 解析所有命令行参数,保存到opt对象中
opt = parser.parse_args()
# 打印所有超参数,方便查看训练配置
print(opt)
# ========================== 第二步:创建训练结果保存文件夹 ==========================
# 分别创建:裁剪后的带掩码图像、真实图像、补全后的重建图像、模型权重的保存目录
try:
os.makedirs("result/train/cropped") # 带中心掩码的输入图像
os.makedirs("result/train/real") # 原始真实图像
os.makedirs("result/train/recon") # 模型补全后的重建图像
os.makedirs("model") # 模型权重文件
# 若文件夹已存在,捕获OSError异常,不报错
except OSError:
pass
# ========================== 第三步:设置随机种子,保证实验可复现 ==========================
# 若未手动设置随机种子,则随机生成1-10000的整数作为种子
if opt.manualSeed is None:
opt.manualSeed = random.randint(1, 10000)
print("Random Seed: ", opt.manualSeed)
# 设置python内置随机数种子
random.seed(opt.manualSeed)
# 设置PyTorch CPU随机数种子
torch.manual_seed(opt.manualSeed)
# 若使用CUDA,设置所有GPU的随机数种子
if opt.cuda:
torch.cuda.manual_seed_all(opt.manualSeed)
# 启用cudnn的benchmark模式,针对固定尺寸的图像输入,加速卷积运算(训练阶段推荐开启)
cudnn.benchmark = True
# 警告:若检测到CUDA设备但未加--cuda参数,提示用户使用GPU训练
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
# ========================== 第四步:加载数据集并做预处理 ==========================
# 根据不同的数据集类型,创建对应的数据集对象,统一预处理流程:
# 1. 缩放至imageSize×imageSize 2. 中心裁剪 3. 转为Tensor 4. 归一化到[-1,1](GAN经典归一化)
# 注:新版PyTorch中transforms.Scale已更名为transforms.Resize
if opt.dataset in ['imagenet', 'folder', 'lfw']:
# 文件夹数据集(按文件夹分类,通用格式)
dataset = dset.ImageFolder(root=opt.dataroot,
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
# 归一化:mean=(0.5,0.5,0.5), std=(0.5,0.5,0.5) → 像素值从[0,1]→[-1,1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
elif opt.dataset == 'lsun':
# LSUN场景数据集(仅加载卧室训练集)
dataset = dset.LSUN(db_path=opt.dataroot, classes=['bedroom_train'],
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
elif opt.dataset == 'cifar10':
# CIFAR10小数据集(自动下载)
dataset = dset.CIFAR10(root=opt.dataroot, download=True,
transform=transforms.Compose([
transforms.Scale(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
)
elif opt.dataset == 'streetview':
# 街景数据集(默认,Context Encoder论文主要实验数据集)
transform = transforms.Compose([transforms.Scale(opt.imageSize),
transforms.CenterCrop(opt.imageSize),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset = dset.ImageFolder(root=opt.dataroot, transform=transform )
# 断言:确保数据集加载成功,若失败则直接报错
assert dataset
# 创建数据加载器(dataloader),实现批量读取、随机打乱、多线程加速
dataloader = torch.utils.data.DataLoader(dataset, batch_size=opt.batchSize,
shuffle=True, # 训练阶段随机打乱数据,避免过拟合
num_workers=int(opt.workers)) # 数据加载线程数
# ========================== 第五步:定义常量,简化后续代码 ==========================
ngpu = int(opt.ngpu)
nz = int(opt.nz)
ngf = int(opt.ngf)
ndf = int(opt.ndf)
nc = 3 # 固定RGB图像通道数
nef = int(opt.nef)
nBottleneck = int(opt.nBottleneck)
wtl2 = float(opt.wtl2) # L2重建损失权重
overlapL2Weight = 10 # 重叠边缘的L2损失加权系数,让边缘补全更平滑
# ========================== 第六步:定义权重初始化函数 ==========================
# 采用DCGAN的权重初始化策略,保证模型训练初期的稳定性
# 对卷积层、批归一化层进行初始化,其他层无需处理
def weights_init(m):
# 获取当前层的类名
classname = m.__class__.__name__
# 若为卷积层(Conv2d/ConvTranspose2d)
if classname.find('Conv') != -1:
# 权重初始化为正态分布:均值0,标准差0.02
m.weight.data.normal_(0.0, 0.02)
# 若为批归一化层(BatchNorm2d)
elif classname.find('BatchNorm') != -1:
# 权重初始化为正态分布:均值1,标准差0.02
m.weight.data.normal_(1.0, 0.02)
# 偏置初始化为0
m.bias.data.fill_(0)
# ========================== 第七步:初始化模型,支持断点续训 ==========================
resume_epoch=0 # 断点续训的起始轮数,默认从0开始
# 初始化生成器_netG,传入超参数opt
netG = _netG(opt)
# 对生成器应用自定义权重初始化
netG.apply(weights_init)
# 若指定了预训练生成器路径,加载权重并获取续训起始轮数
if opt.netG != '':
# 加载模型(兼容CPU/GPU),map_location用于将GPU模型加载到CPU
netG_ckpt = torch.load(opt.netG,map_location=lambda storage, location: storage)
netG.load_state_dict(netG_ckpt['state_dict']) # 加载模型权重
resume_epoch = netG_ckpt['epoch'] # 获取上次训练的最后一轮数
# 打印生成器网络结构,方便查看
print(netG)
# 初始化局部判别器_netlocalD,传入超参数opt
netD = _netlocalD(opt)
# 对判别器应用自定义权重初始化
netD.apply(weights_init)
# 若指定了预训练判别器路径,加载权重并更新续训起始轮数
if opt.netD != '':
netD_ckpt = torch.load(opt.netD,map_location=lambda storage, location: storage)
netD.load_state_dict(netD_ckpt['state_dict'])
resume_epoch = netD_ckpt['epoch']
# 打印判别器网络结构,方便查看
print(netD)
# ========================== 第八步:定义损失函数和张量 ==========================
# 判别器的损失函数:二分类交叉熵损失(BCELoss),用于区分真实/生成的中心区域
criterion = nn.BCELoss()
# 生成器的L2重建损失:均方误差损失(MSELoss),用于保证像素级补全精度
criterionMSE = nn.MSELoss()
# 定义张量,用于存储数据(提前定义可节省内存,避免每次迭代重新创建)
input_real = torch.FloatTensor(opt.batchSize, 3, opt.imageSize, opt.imageSize) # 原始真实图像
input_cropped = torch.FloatTensor(opt.batchSize, 3, opt.imageSize, opt.imageSize) # 带中心掩码的输入图像
label = torch.FloatTensor(opt.batchSize) # 判别器的标签(1=真实,0=生成)
real_label = 1 # 真实样本的标签
fake_label = 0 # 生成样本的标签
# 存储原始图像的中心区域(128×128→64×64),作为L2重建损失的真实标签
real_center = torch.FloatTensor(opt.batchSize, 3, opt.imageSize//2, opt.imageSize//2)
# 若使用CUDA,将模型、损失函数、张量全部移至GPU
if opt.cuda:
netD.cuda()
netG.cuda()
criterion.cuda()
criterionMSE.cuda()
input_real, input_cropped,label = input_real.cuda(),input_cropped.cuda(), label.cuda()
real_center = real_center.cuda()
# 将张量封装为Variable(旧版PyTorch用于自动求导,新版Tensor已集成autograd,可删除)
input_real = Variable(input_real)
input_cropped = Variable(input_cropped)
label = Variable(label)
real_center = Variable(real_center)
# ========================== 第九步:定义优化器 ==========================
# 判别器优化器:Adam优化器,学习率opt.lr,beta1=opt.beta1,beta2=0.999(固定)
optimizerD = optim.Adam(netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
# 生成器优化器:与判别器相同,分开定义保证参数独立更新
optimizerG = optim.Adam(netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
# ========================== 第十步:核心训练循环(GAN交替训练) ==========================
# 从断点续训的轮数开始,训练至opt.niter轮
for epoch in range(resume_epoch,opt.niter):
# 遍历dataloader,i为迭代步数,data为当前批次的(图像,标签)
for i, data in enumerate(dataloader, 0):
# 读取当前批次的真实图像(data[0]),忽略分类标签(data[1])
real_cpu, _ = data
# 提取真实图像的**中心64×64区域**(Context Encoder的补全目标)
# 128×128的图像,从32像素开始取64像素(32+64=96),即中心区域
real_center_cpu = real_cpu[:,:,int(opt.imageSize/4):int(opt.imageSize/4)+int(opt.imageSize/2),
int(opt.imageSize/4):int(opt.imageSize/4)+int(opt.imageSize/2)]
# 获取当前批次的实际大小(最后一批可能小于opt.batchSize)
batch_size = real_cpu.size(0)
# 将真实图像数据复制到预定义的张量中
input_real.data.resize_(real_cpu.size()).copy_(real_cpu)
# 初始化带掩码的输入图像为真实图像(后续修改中心区域为掩码)
input_cropped.data.resize_(real_cpu.size()).copy_(real_cpu)
# 将真实中心区域复制到预定义的张量中
real_center.data.resize_(real_center_cpu.size()).copy_(real_center_cpu)
# ========================== 生成带中心掩码的输入图像(关键步骤) ==========================
# 对input_cropped的**中心区域(排除重叠边缘)**填充掩码值,模拟图像缺失
# 掩码值为:2*117/255-1、2*104/255-1、2*123/255-1 → 对应ImageNet数据集的RGB均值归一化后的值
# 排除overlapPred=4的边缘,是为了保留边缘上下文信息,让模型更好的补全
input_cropped.data[:,0,int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred),
int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred)] = 2*117.0/255.0 - 1.0
input_cropped.data[:,1,int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred),
int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred)] = 2*104.0/255.0 - 1.0
input_cropped.data[:,2,int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred),
int(opt.imageSize/4+opt.overlapPred):int(opt.imageSize/4+opt.imageSize/2-opt.overlapPred)] = 2*123.0/255.0 - 1.0
# ========================== 第一阶段:训练判别器netD ==========================
# 判别器训练目标:最大化 log(D(real)) + log(1-D(fake))
netD.zero_grad() # 清空判别器的梯度(PyTorch梯度累加,必须手动清空)
# 设置标签为真实标签1,尺寸适配当前批次
label.data.resize_(batch_size).fill_(real_label)
# 判别器对**真实中心区域**进行判别
output = netD(real_center)
# 计算真实样本的损失:BCELoss(判别输出, 真实标签)
errD_real = criterion(output, label)
# 反向传播:计算梯度
errD_real.backward()
# 记录真实样本的判别均值(越接近1,判别器性能越好)
D_x = output.data.mean()
# 判别器对**生成的中心区域**进行判别
# 生成器根据带掩码的输入,生成补全的中心区域(fake)
fake = netG(input_cropped)
# 设置标签为生成标签0
label.data.fill_(fake_label)
# 对生成样本进行判别,使用detach()阻止梯度传递到生成器(仅训练判别器)
output = netD(fake.detach())
# 计算生成样本的损失
errD_fake = criterion(output, label)
# 反向传播:计算梯度
errD_fake.backward()
# 记录生成样本的判别均值(越接近0,判别器性能越好)
D_G_z1 = output.data.mean()
# 判别器总损失 = 真实样本损失 + 生成样本损失
errD = errD_real + errD_fake
# 优化器更新判别器的参数
optimizerD.step()
# ========================== 第二阶段:训练生成器netG ==========================
# 生成器训练目标:最大化 log(D(G(input_cropped))) + 最小化L2(生成区域, 真实中心区域)
netG.zero_grad() # 清空生成器的梯度
# 生成器希望判别器将生成样本判定为真实,因此标签设为1
label.data.fill_(real_label)
# 判别器对生成样本的重新判别(此时计算梯度会传递到生成器)
output = netD(fake)
# 计算生成器的对抗损失:BCELoss(判别输出, 真实标签)
errG_D = criterion(output, label)
# ========================== 计算加权L2重建损失(Context Encoder核心) ==========================
# 构建L2损失的加权矩阵:边缘区域权重高(10*wtl2),中心区域权重低(wtl2)
# 目的:让模型重点保证补全区域与原始图像的**边缘衔接平滑**,避免拼接痕迹
wtl2Matrix = real_center.clone() # 复制真实中心区域的形状
wtl2Matrix.data.fill_(wtl2*overlapL2Weight) # 初始所有区域权重为wtl2*10
# 中心区域的权重设为原始wtl2(降低中心区域的加权,重点优化边缘)
wtl2Matrix.data[:,:,int(opt.overlapPred):int(opt.imageSize/2 - opt.overlapPred),
int(opt.overlapPred):int(opt.imageSize/2 - opt.overlapPred)] = wtl2
# 计算生成区域与真实区域的平方误差
errG_l2 = (fake-real_center).pow(2)
# 应用加权矩阵,对边缘区域的误差进行加权
errG_l2 = errG_l2 * wtl2Matrix
# 计算加权后的L2损失均值
errG_l2 = errG_l2.mean()
# 生成器总损失:对抗损失*(1-wtl2) + L2重建损失*wtl2
# 权重平衡:wtl2=0.998时,重点优化L2重建(像素精度),轻微优化对抗(视觉真实)
errG = (1-wtl2) * errG_D + wtl2 * errG_l2
# 反向传播:计算生成器的梯度
errG.backward()
# 记录生成样本的判别均值(越接近1,生成器性能越好)
D_G_z2 = output.data.mean()
# 优化器更新生成器的参数
optimizerG.step()
# ========================== 打印训练日志 ==========================
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f / %.4f l_D(x): %.4f l_D(G(z)): %.4f'
% (epoch, opt.niter, i, len(dataloader),
errD.data[0], errG_D.data[0],errG_l2.data[0], D_x,D_G_z1, ))
# ========================== 保存训练结果(每100步) ==========================
if i % 100 == 0:
# 保存原始真实图像
vutils.save_image(real_cpu,
'result/train/real/real_samples_epoch_%03d.png' % (epoch))
# 保存带中心掩码的输入图像
vutils.save_image(input_cropped.data,
'result/train/cropped/cropped_samples_epoch_%03d.png' % (epoch))
# 生成重建图像:将生成的中心区域填充回带掩码的输入图像
recon_image = input_cropped.clone()
recon_image.data[:,:,int(opt.imageSize/4):int(opt.imageSize/4+opt.imageSize/2),
int(opt.imageSize/4):int(opt.imageSize/4+opt.imageSize/2)] = fake.data
# 保存补全后的重建图像
vutils.save_image(recon_image.data,
'result/train/recon/recon_center_samples_epoch_%03d.png' % (epoch))
# ========================== 保存模型权重(每轮结束) ==========================
# 保存生成器:以字典形式保存(轮数+模型权重),方便断点续训
torch.save({'epoch':epoch+1,
'state_dict':netG.state_dict()},
'model/netG_streetview.pth' )
# 保存判别器
torch.save({'epoch':epoch+1,
'state_dict':netD.state_dict()},
'model/netlocalD.pth' )