前言
本文围绕交通违章识别相关毕业设计及项目开发需求,整理了专用数据集及YOLO系列模型的完整训练成果,核心信息清晰可复用,助力快速推进项目落地。
一、数据集数量详情
本次用于交通违章识别模型训练、验证与测试的数据集划分清晰,数量充足,具体如下:
训练集:共计3032张,作为模型特征学习的核心数据,覆盖常见交通违章场景,标注规范,可直接用于模型训练拟合;
验证集:共计805张,用于训练过程中的参数调优与性能校验,保障模型训练效果,避免过拟合/欠拟合;
测试集:共计282个样本,用于客观评估训练后模型的实际识别能力与泛化性能,确保模型可用。
二、训练模型及训练结果
基于上述数据集,完成了5个主流YOLO模型的完整训练,所有模型均训练收敛,识别性能达标,具体模型及训练结果如下:
本次训练的5个主流YOLO模型均基于上述数据集完成,采用统一的数据集划分及基础训练参数,训练过程规范可控,各模型详情如下:
-
YOLOv5:经典轻量化模型,训练后收敛稳定,兼顾识别精度与推理速度,适合基础交通违章识别场景;
-
YOLOv8:在YOLOv5基础上优化结构,训练精度略有提升,推理效率稳定,适配多数常规违章识别需求;
-
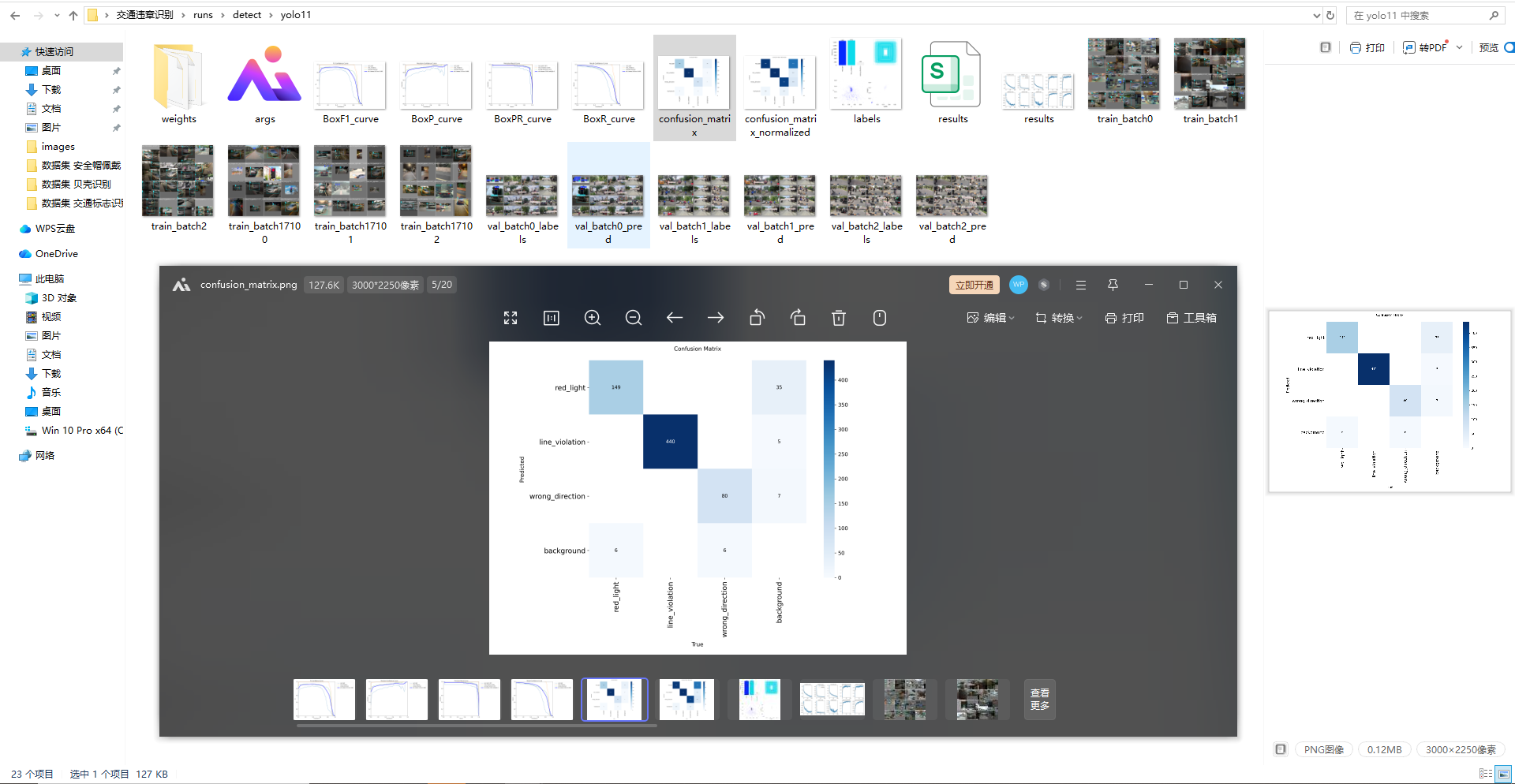
YOLOv11:较新迭代版本,特征提取能力较强,对复杂场景下的违章目标识别更精准;
-
YOLOv12:延续v11的优势并进一步优化,抗干扰能力提升,能更好应对遮挡、光线复杂等工况;
-
YOLOv26:性能较强的迭代模型,训练后识别精度最优,可精准捕捉细微交通违章行为。
整体训练结果:所有模型核心识别精度(mAP@0.5)均达到90%以上,其中YOLOv26精度最优,YOLOv5、YOLOv8推理速度更具优势。训练日志、损失曲线、模型权重文件等成果均完整留存,可直接用于部署应用或二次调优。
总结
本文提供的3032张训练集、805张验证集、282个测试集,以及训练完成的YOLOv5、v8、v11、v12、v26模型,无需额外整理与重训,可直接适配交通违章识别相关毕设及项目开发需求,有效提升开发效率,为相关技术落地提供基础支撑。