大家好,我是锋哥。最近发布一条【AI大模型舆情分析】微博舆情分析可视化系统(pytorch2+基于BERT大模型训练微调+flask+pandas+echarts)高级实战。分上下节。
实战简介:
前面的2026版【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts+爬虫) 二次开发,前面课程舆情分析用得是snowNLP,我们现在改用基于BERT开源大模型微调,来实现舆情分析,提高舆情分析的准确率。重点讲解基本BERT大模型实现舆情分析,二分类问题。
视频教程和源码领取:
链接:https://pan.baidu.com/s/1_NzaNr0Wln6kv1rdiQnUTg
提取码:0000
微博舆情分析可视化系统 - 项目准备
基于python微博舆情分析可视化系统(flask+pandas+echarts) 项目源码本地运行下。
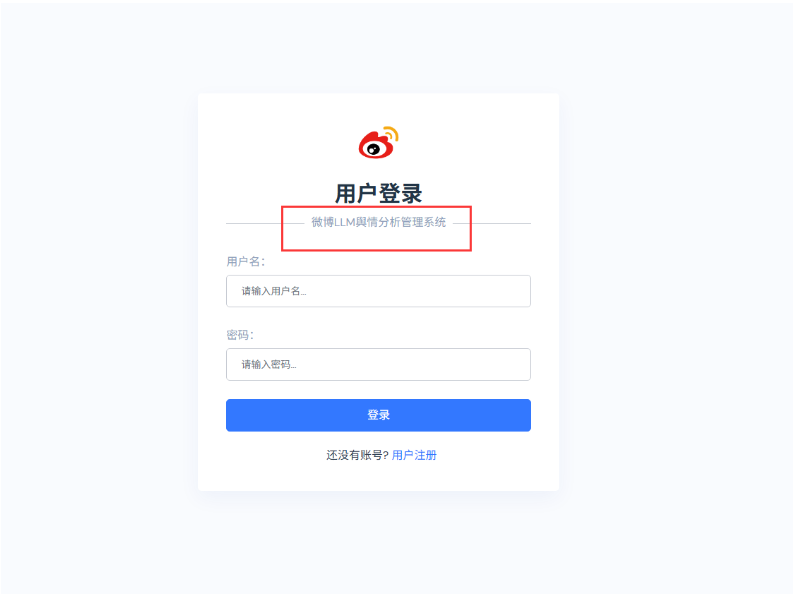
登录页面,我们改下小标题,加个LLM
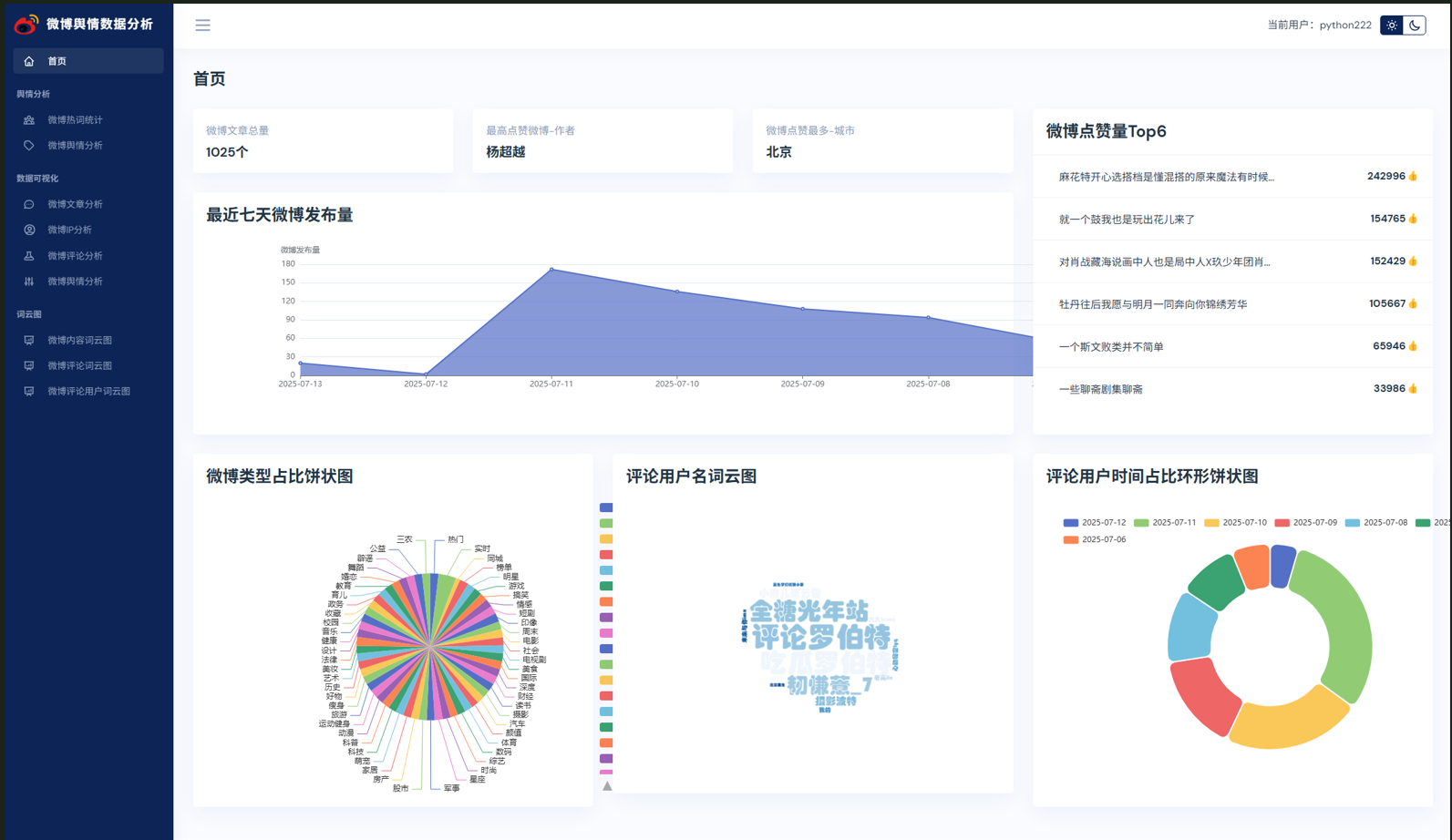
登录后,进入系统主页面:
BERT大模型实现舆情分析功能
大模型开发环境准备-PyTorch和transformers库
首先新建model目录,把Bert-base-chinese粘贴到model目录下。
我们大模型训练尽可能的基于GPU的,CUDA要安装下。
然后我们要安装Pytorch2和transformers库:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu126
pip install transformers -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com环境测试代码:
import torch
from transformers import pipeline
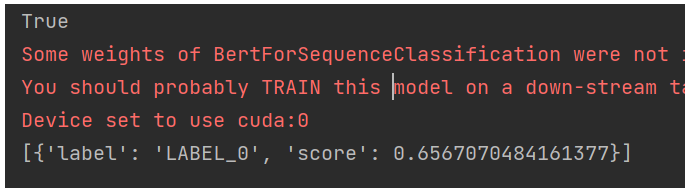
print(torch.cuda.is_available())
# 通过pipeline 加载模型
model = pipeline(task="text-classification", # 任务类型 二分类
model="Bert-base-chinese", # 模型名称
device=0 # 使用GPU
)
# 调用模型预测
result = model("小明是好学生")
print(result)运行结果:
BERT大模型情感分析功能封装(使用AutoModel自动模型方式)
新建llm目录,里面再新建weibo.py文件
代码实现:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 使用设备GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('../model/Bert-base-chinese')
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained('../model/Bert-base-chinese')
print(model)
# 情感分析
def data_classfication(data):
# 准备输入数据
input_ids = tokenizer.encode(
text=data, # 输入文本
return_tensors='pt', # 返回PyTorch张量
truncation=True, # 截断超过长度的输入文本
max_length=20, # 最长长度
padding="max_length" # 填充短的输入文本
).to(device)
# 评估模型
model.eval()
model.to(device)
# 模型预测
output = model(input_ids)
print(output)
# 获取预测结果
logits = output.logits
print(logits)
predication = torch.argmax(logits, dim=-1)
print(predication)
sentiment = predication.item() # 把张量转成数字
print(sentiment)
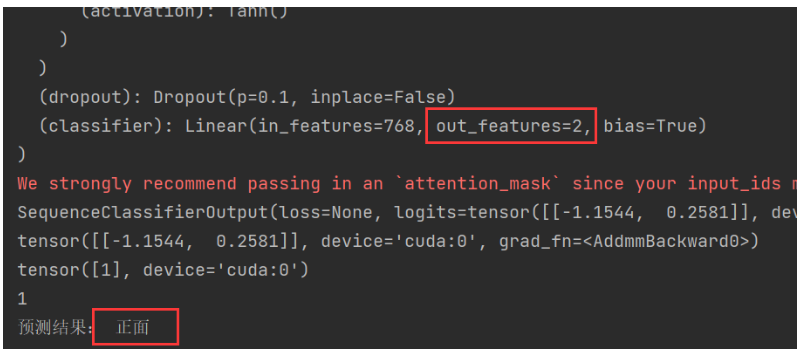
sentiment_label = "正面" if sentiment == 1 else "负面"
return sentiment_label
if __name__ == '__main__':
result = data_classfication("开心")
print("预测结果:", result)运行结果:
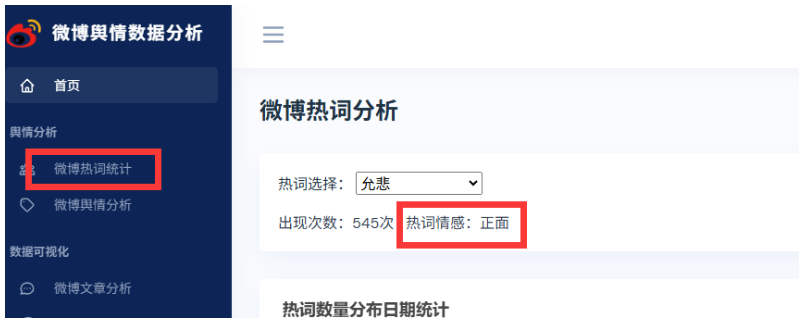
使用BERT大模型对微博热词进行情感分析
找到视图层业务逻辑代码:
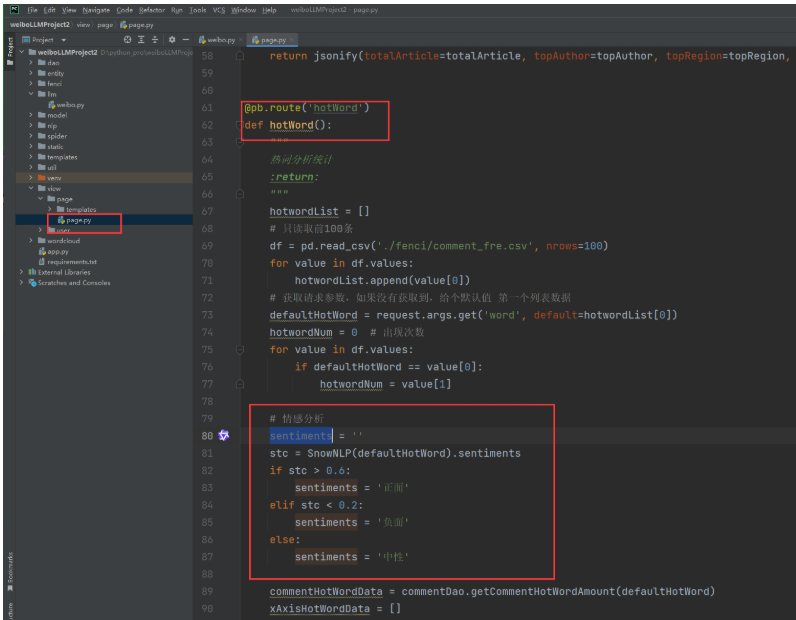
我们修改下:
# 改成使用大模型进行舆情分析
sentiments = data_classfication(defaultHotWord)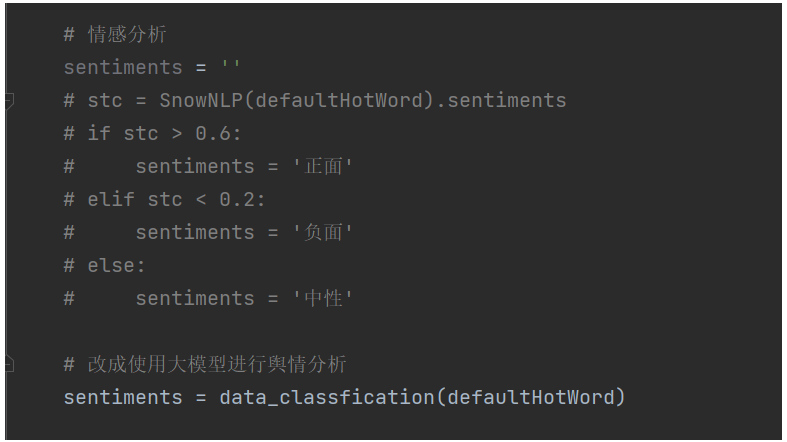
启动就直接报错了
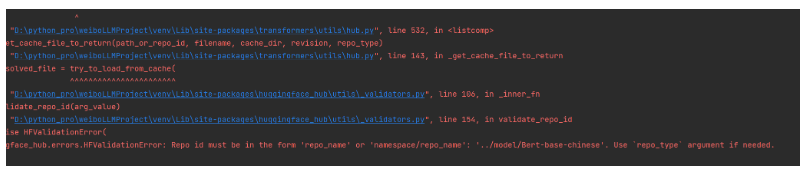
原因是加载模型用得是相对路径,我们调用封装方法的时候,相对路径又变了。所以我们企业级开发,一般不用相对路径,只用绝对路径,由于开发环境,测试环境,线上环境模型路径会变,所以我们一般都会把路径放到配置文件里面去,方便修改路径。
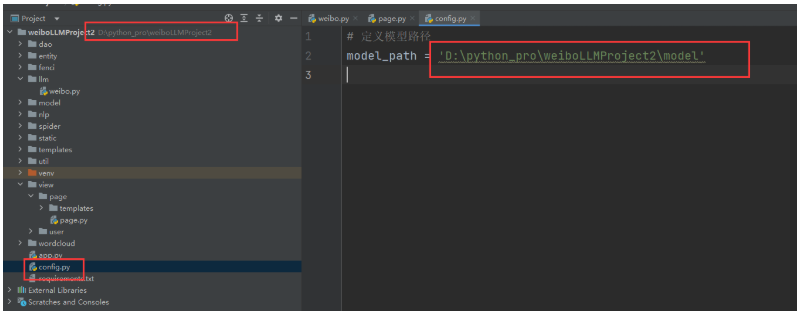
配置下模型路径:
# 定义模型路径
model_path = 'D:\python_pro\weiboLLMProject2\model'接下来,weibo.py里把相对路径,改成绝对路径,使用config.py里的model_path属性;
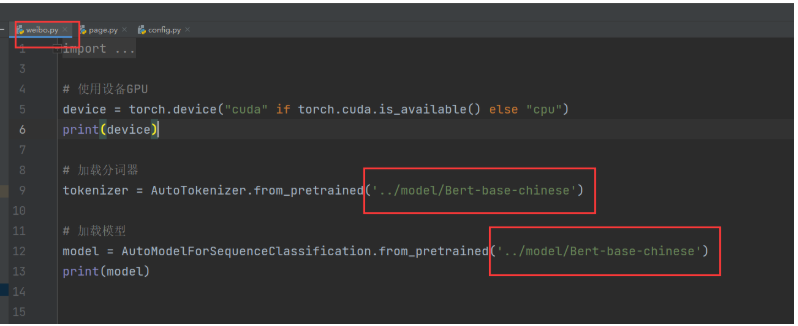
改成:
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(config.model_path + "/Bert-base-chinese")
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(config.model_path + "/Bert-base-chinese")
print(model)运行测试系统,可以了。不过情感分析的准确率很有限,等后面VIP课程,我们使用增量微调训练后的模型,准确率能上到90%以上。
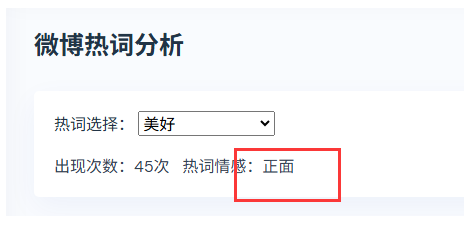
使用BERT大模型对微博文章内容进行情感分析
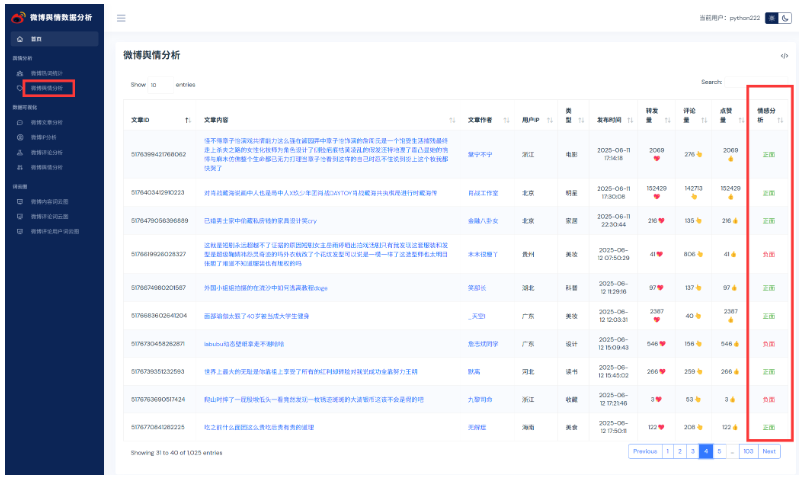
找到微博舆情分析后端视图业务逻辑代码:
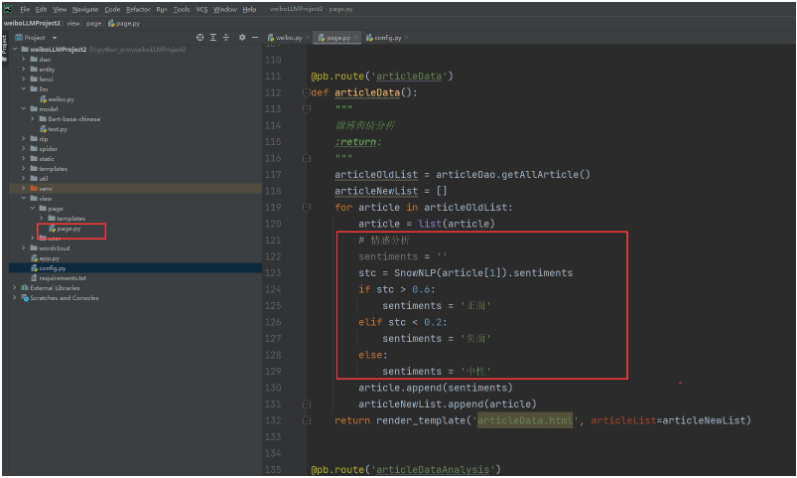
改成:
# 改成使用大模型进行舆情分析
sentiments = data_classfication(article[1])重启项目测试:
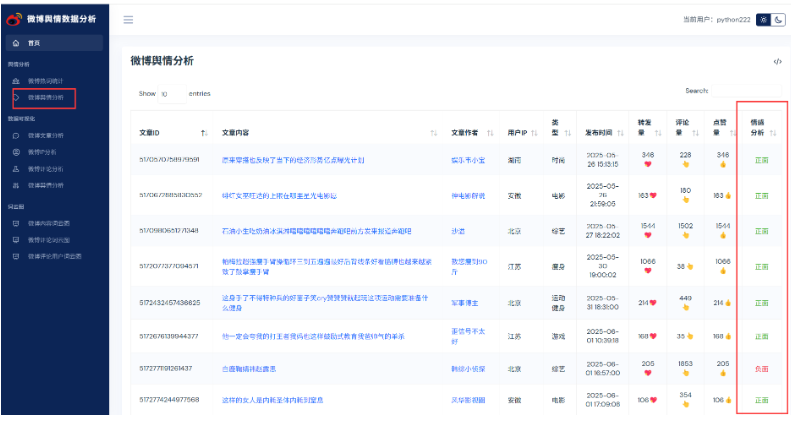
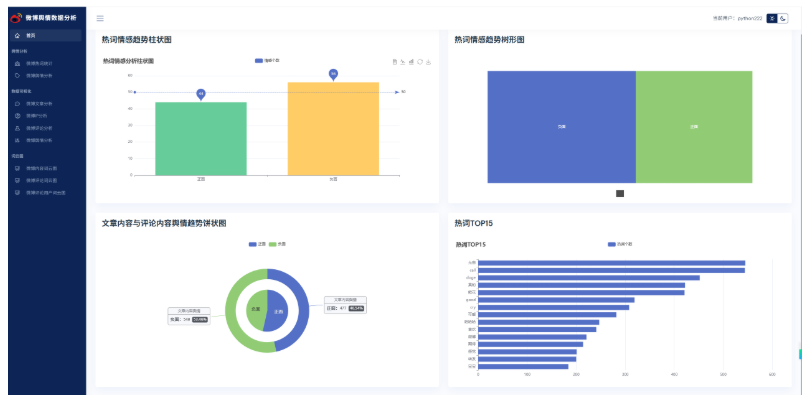
使用BERT大模型对微博舆情分析以及可视化操作
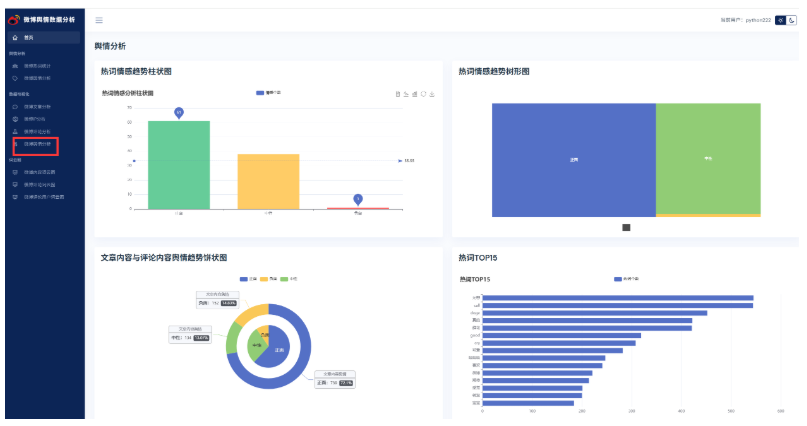
找到数据可视化微博舆情分析后端视图层业务逻辑代码,包括柱状图,树形图,饼状图。代码都需要修改;
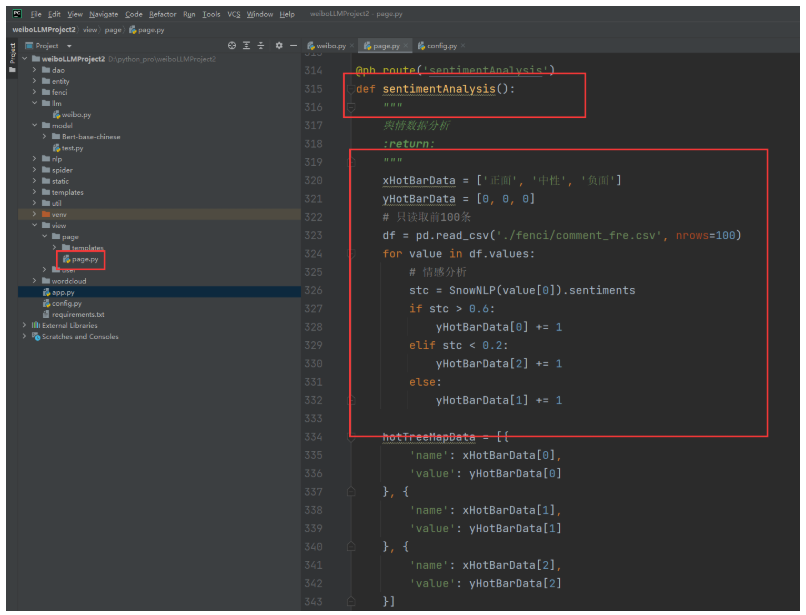
代码修改:
@pb.route('sentimentAnalysis')
def sentimentAnalysis():
"""
舆情数据分析
:return:
"""
xHotBarData = ['正面', '负面']
yHotBarData = [0, 0]
# 只读取前100条
df = pd.read_csv('./fenci/comment_fre.csv', nrows=100)
for value in df.values:
# 情感分析
# stc = SnowNLP(value[0]).sentiments
# if stc > 0.6:
# yHotBarData[0] += 1
# elif stc < 0.2:
# yHotBarData[2] += 1
# else:
# yHotBarData[1] += 1
# 使用大模型进行情感分析
sentiment_label = data_classfication(value[0])
if sentiment_label == '正面':
yHotBarData[0] += 1
else:
yHotBarData[1] += 1
hotTreeMapData = [{
'name': xHotBarData[0],
'value': yHotBarData[0]
}, {
'name': xHotBarData[1],
'value': yHotBarData[1]
}]
commentPieData = [{
'name': '正面',
'value': 0
}, {
'name': '负面',
'value': 0
}]
articlePieData = [{
'name': '正面',
'value': 0
}, {
'name': '负面',
'value': 0
}]
commentList = commentDao.getAllComment()
for comment in commentList:
# 情感分析
# stc = SnowNLP(comment[1]).sentiments
# if stc > 0.6:
# commentPieData[0]['value'] += 1
# elif stc < 0.2:
# commentPieData[2]['value'] += 1
# else:
# commentPieData[1]['value'] += 1
# 使用大模型进行情感分析
sentiment_label = data_classfication(comment[1])
if sentiment_label == '正面':
commentPieData[0]['value'] += 1
else:
commentPieData[1]['value'] += 1
articleList = articleDao.getAllArticle()
for article in articleList:
# 情感分析
# stc = SnowNLP(article[1]).sentiments
# if stc > 0.6:
# articlePieData[0]['value'] += 1
# elif stc < 0.2:
# articlePieData[2]['value'] += 1
# else:
# articlePieData[1]['value'] += 1
# 使用大模型进行情感分析
sentiment_label = data_classfication(article[1])
if sentiment_label == '正面':
articlePieData[0]['value'] += 1
else:
articlePieData[1]['value'] += 1
df2 = pd.read_csv('./fenci/comment_fre.csv', nrows=15)
xhotData15 = [x[0] for x in df2.values][::-1]
yhotData15 = [x[1] for x in df2.values][::-1]
return render_template('sentimentAnalysis.html',
xHotBarData=xHotBarData,
yHotBarData=yHotBarData,
hotTreeMapData=hotTreeMapData,
commentPieData=commentPieData,
articlePieData=articlePieData,
xhotData15=xhotData15,
yhotData15=yhotData15)重启项目测试: