MovieNet:一个用于电影理解的综合性数据集
摘要
近年来,视觉理解领域取得了显著进展。然而,如何理解具有艺术风格的故事性长视频(如电影)仍然面临挑战。本文中,我们介绍了MovieNet------一个用于电影理解的综合性数据集。MovieNet包含1100部电影,涵盖大量多模态数据(如预告片、图片、剧情描述等)。此外,该数据集还提供了多方面的人工标注,包括110万个带边界框和身份信息的角色实例、4.2万个场景边界、2500句对齐的描述语句、6.5万个地点和动作标签,以及9.2万个电影风格标签。据我们所知,MovieNet是目前规模最大、标注最丰富的综合性电影理解数据集。基于MovieNet,我们从不同角度建立了多个电影理解基准测试。在这些基准测试上进行的大量实验,充分展示了MovieNet的巨大价值,同时也揭示了现有方法在实现全面电影理解方面的差距。我们相信,这样一个综合性数据集将推动基于故事的长视频理解及相关领域的研究。MovieNet将依据相关规定公开发布,网址为https://movienet.github.io。
1 引言
\quad"你跳,我就跳,对吗?"当露丝放弃救生艇,向杰克呐喊时,我们都被《泰坦尼克号》这部电影讲述的凄美爱情故事深深打动。常言道:"电影令我们着迷、娱乐我们、教育我们并使我们愉悦。"电影中,角色在各种场景下面临不同境遇、展现多样行为,是现实世界的反映。它为我们呈现了诸多内容,如过往发生的故事、某个国家或地区的文化习俗、人类在不同情境下的反应与互动等。因此,理解电影,便是理解我们所处的世界。
\quad这一点不仅适用于人类,也适用于人工智能系统。考虑到电影的高度复杂性及其与现实世界的紧密关联,我们认为电影理解是展现高级机器智能的理想场景。此外,与网络图片16和短视频7相比,历史上数十万部电影蕴含丰富内容和多模态信息,是对数据需求巨大的深度模型的优质训练素材。
\quad基于上述洞察,本文构建了一个名为MovieNet的综合性电影理解数据集。如图1所示,MovieNet包含三个核心部分:数据、标注和基准测试。
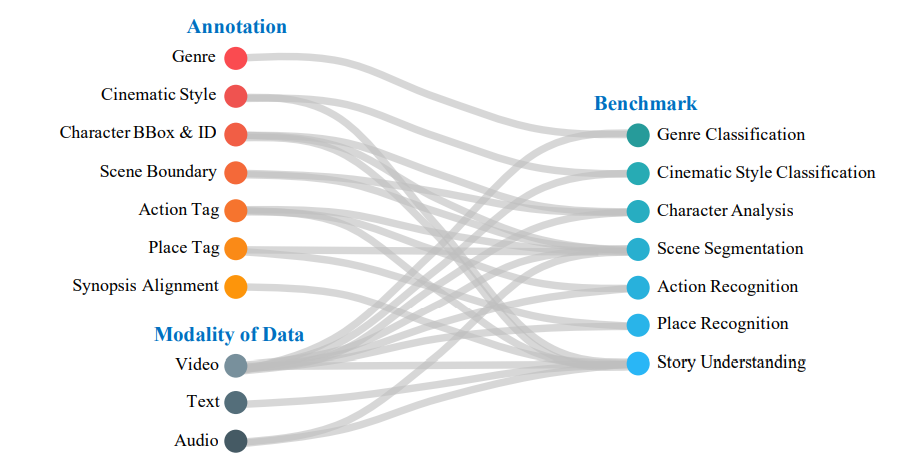
图1:MovieNet中的数据、标注、基准及其关系,共同构建了一个全面的数据集,用于对电影进行全面理解。
\quad首先,MovieNet包含大量多模态数据,包括电影、预告片、图片、字幕、剧本以及类型、演员阵容、导演、评分等元信息。该数据集共涵盖3000小时的视频、390万张图片、1000万句文本和700万条元信息。
\quad在标注方面,MovieNet包含海量标签,以支持电影理解的不同研究方向。我们认为,角色、地点等中层实体对高层故事理解至关重要,因此提供了多种语义元素的标注,包括角色边界框和身份、场景边界、动作/地点标签以及自然语言对齐描述。此外,电影作为一门拍摄艺术,其电影风格(如视角尺度、镜头运动、灯光等)对全面的视频分析也大有裨益。因此,我们对超过4.6万个镜头的视角尺度和镜头运动进行了标注。具体而言,MovieNet的标注包括:(1)110万个带边界框和身份信息的角色实例;(2)4万个场景边界;(3)6.5万个动作和地点标签;(4)1.2万句与电影片段对齐的描述语句;(5)9.2万个电影风格标签。
\quad基于MovieNet的数据和标注,我们开展了涵盖电影理解不同方面的研究课题,即类型分析、电影风格预测、角色分析、场景理解和电影片段检索。针对每个课题,我们建立了一个或多个具有挑战性的基准测试。随后进行了大量实验,以展示不同方法的性能。通过对实验结果的深入分析,我们还将揭示现有方法在全面电影理解方面的差距,以及综合性标注对全程视频分析的优势。
\quad据我们所知,MovieNet是首个用于电影理解的综合性数据集,包含大量多模态数据和多方面的高质量标注。我们希望它能推动视频编辑、以人为中心的场景理解、基于故事的视频分析等领域的研究。

图2:MovieNet是一个用于电影理解的综合数据集,包含来自不同模态的海量数据以及不同方面的高质量标注。此处我们展示了MovieNet中《泰坦尼克号》的部分数据(蓝色)和标注(绿色)。
2 相关数据集
现有研究
大多数电影理解数据集专注于电影的特定元素,如类型89,63、角色1,3,31,48,65,22,35、动作39,21,46,5,6、场景53,11,30,49,15,51和描述61。它们的规模通常较小,标注数量也有限。例如,22,65,3采用电视剧的多个剧集进行角色识别,39使用12部电影的片段进行动作识别,49仅基于3部电影开展场景分割研究。尽管这些数据集关注了电影理解的重要方面,但它们的规模不足以满足数据驱动的学习模式需求。此外,深度理解需要从中层元素过渡到高层故事,而现有每个数据集仅能支持单一任务,这给全面电影理解带来了困难。
MovieQA
MovieQA68包含为408部电影设计的1.5万个问题。其信息来源包括视频片段、剧情、字幕、剧本和描述性视频服务(DVS)。通过问答任务评估故事理解是一个不错的思路,但存在两个问题:(1)缺少角色身份等中层标注,难以开发有效的高层理解方法;(2)问题源自维基剧情,因此更偏向文本问答任务,而非基于故事的视频理解。一个有力的证据是,基于文本剧情的方法比基于"视频+字幕"的方法准确率高得多。
LSMDC
LSMDC57包含200部电影,附带为视障人士提供的电影语言描述(AD)。AD与大多数观众的自然描述差异较大,限制了基于该数据集训练的模型的适用性。此外,获取大量AD也存在困难。与先前的工作68,57不同,MovieNet提供了多种文本信息来源和中层实体的不同标注,是更适合基于故事的视频理解的数据源。
AVA
最近提出的AVA数据集28是一个动作识别数据集,包含430个15分钟的电影片段,标注了80种时空原子视觉动作。AVA数据集旨在促进原子视觉动作的识别任务。然而,就故事理解的目标而言,AVA数据集并不适用,原因如下:(1)数据集的标签以"站立""坐着"等为主,分布极不均衡;(2)从故事分析的角度来看,"站立""交谈""观看"等动作的信息量较少。因此,我们提出标注语义级别的动作,以同时支持动作识别和故事理解任务。
MovieGraphs
MovieGraphs71是最相关的数据集,它提供了51部电影片段中所描绘的社交场景的图结构标注,包括角色、互动、属性等。尽管两者都秉持多层标注的理念,但MovieNet在三个方面与MovieGraphs不同:(1)MovieNet不仅包含电影片段和标注,还涵盖图片、字幕、剧本、预告片等,能为各类研究课题提供更丰富的数据;(2)MovieNet支持并开展电影理解的多个方面研究,而MovieGraphs仅专注于场景识别;(3)MovieNet的规模远大于MovieGraphs。
表1:MovieNet与相关数据集的数据对比
| 数据集 | 电影数量 | 预告片 | 图片 | 元信息 | 剧本 | 剧情梗概 | 字幕 | 剧情 | AD |
|---|---|---|---|---|---|---|---|---|---|
| MovieQA68 | 408 | - | - | - | - | - | ✔️ | ✔️ | - |
| LSMDC57 | 200 | - | - | - | ✔️ | - | - | - | ✔️ |
| MovieGraphs71 | 51 | - | - | - | - | - | - | - | - |
| AVA28 | 430 | - | - | - | - | - | - | - | - |
| MovieNet | 1100 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | - |
3 探索MovieNet:数据与标注
MovieNet包含多种多模态数据和多方面的高质量标注,以支持电影理解研究。图2展示了MovieNet中《泰坦尼克号》的相关数据和标注。表1和表2对比了MovieNet与其他电影理解数据集,充分体现了MovieNet在质量、规模和丰富度上的巨大优势。
表2:MovieNet与相关数据集的标注对比
| 数据集 | 角色数量 | 场景数量 | 电影风格标签数 | 对齐语句数 | 动作/地点标签数 |
|---|---|---|---|---|---|
| MovieQA68 | - | - | - | 1.5万 | - |
| LSMDC57 | - | - | - | 12.8万 | - |
| MovieGraphs71 | 2.2万 | - | - | 2.1万 | 2.3万 |
| AVA28 | 11.6万 | - | - | - | 36万 |
| MovieNet | 110万 | 4.2万 | 9.2万 | 2.5万 | 6.5万 |
3.1 MovieNet中的数据
电影
我们精心挑选并购买了1100部电影的版权,选择标准如下:(1)彩色电影;(2)时长超过1小时;(3)涵盖多种类型、年份和国家/地区。
元信息
我们从互联网电影数据库(IMDb)和电影数据库(TMDb)获取了电影的元信息,包括标题、上映日期、国家/地区、类型、评分、时长、导演、演员阵容、故事情节等。以下简要介绍部分关键元素,详细内容请参见补充材料:(1)类型是电影最重要的属性之一,MovieNet中共有28种独特类型,总计80.5万个类型标签;(2)对于演员阵容,我们获取了演员的姓名、IMDb ID以及他们在电影中饰演的角色名称;(3)我们还提供了每部电影的IMDb ID、TMDb ID和豆瓣ID,研究人员可通过这些ID方便地从相关网站获取额外元信息。MovieNet中的元信息总数为37.5万条。需要注意的是,每种数据本身(即使没有电影视频)都能支持一些研究课题37,因此我们尽可能收集各类数据,这也是此处数据数量超过1100的原因,下文介绍的其他数据类型同理。
字幕
字幕通过两种方式获取:部分来自电影内嵌的字幕流;对于没有原始英文字幕的电影,我们从YIFY字幕网站爬取了字幕。所有字幕都经过人工检查,以确保与电影对齐。
预告片
我们根据IMDb和TMDb提供的链接,从YouTube下载了预告片。与先前通过电影标题在YouTube搜索预告片的工作10相比,这种方案更为优越,因为IMDb和TMDb中的预告片链接已由平台管理者和观众人工验证。我们共收集了属于3333部独特电影的6万个预告片。
剧本
剧本详细描述了角色的动作、表情和对话,是研究电影与语言关联课题的宝贵文本资源。我们从IMDb剧本数据库(IMSDb)和每日剧本网站(Daily Script)收集了约2000个剧本,并通过匹配对话与字幕,将剧本与电影进行对齐。
剧情梗概
剧情梗概是观众撰写的电影故事描述。我们从IMDb收集了1.1万个高质量剧情梗概,每篇均包含超过50个句子。剧情梗概也经过人工与电影对齐,具体细节将在3.2节介绍。
图片
我们从IMDb和TMDb收集了390万张电影相关图片,包括海报、静帧、宣传照、制作设计图、相关产品图、幕后照片和活动照片。
3.2 MovieNet中的标注
为提供支持电影理解不同研究课题的高质量数据集,我们在数据清理和人工标注方面付出了巨大努力,标注内容涵盖角色、场景、事件和电影风格等多个方面。由于篇幅限制,此处仅展示标注的内容和数量,详细信息请参见补充材料。
电影风格
电影风格(如视角尺度、镜头运动、灯光和色彩)是全面电影理解的重要方面,因为它影响着电影故事的呈现方式。在MovieNet中,我们选择了两种电影风格标签进行研究,即视角尺度和镜头运动。具体而言,视角尺度包括五个类别:远景、全景、中景、特写和极特写;镜头运动分为四个类别:静态镜头、摇移镜头、推镜头和拉镜头。这些类别的原始定义源自26,为方便研究,我们对其进行了简化。我们共标注了来自电影和预告片的4.7万个镜头,每个镜头都带有一个视角尺度标签和一个镜头运动标签。
角色边界框和身份
在电影这类以人为中心的视频中,人物扮演着重要角色。因此,检测和识别角色是电影理解的基础性工作。角色边界框和身份的标注过程包含四个步骤:(1)从不同电影中选择75.8万个关键帧进行边界框标注;(2)使用步骤1中的标注结果训练一个检测器;(3)利用训练好的检测器检测电影中的更多角色,并人工清理检测到的边界框;(4)人工标注所有角色的身份。为控制成本,我们仅保留IMDb演员名单中按 credits 排序的前10位演员,他们能涵盖大多数电影的主要角色。非主要演员阵容的角色标注为"其他"。最终,我们获得了3087个独特主要演员的110万个角色实例,以及36.4万个"其他"角色实例。
场景边界
从时间结构来看,电影包含两个层级------镜头和场景。镜头是电影的最小视觉单位,而场景是由语义相关的连续镜头组成的序列。捕捉电影的层级结构对电影理解至关重要。镜头边界检测问题已由62较好地解决,而场景边界检测(也称为场景分割)仍是一个开放问题。在MovieNet中,我们人工标注了场景边界,以支持场景分割研究,共得到4.2万个场景。
动作/地点标签
要理解场景中发生的事件,需要动作和地点标签。因此,我们首先根据场景边界将每部电影分割成片段,然后为每个片段人工标注地点和动作标签。对于地点标注,每个片段会被赋予多个地点标签(如{甲板、船舱});对于动作标注,我们首先检测包含角色和动作的子片段,然后为每个子片段分配多个动作标签。为保证标签的多样性和信息量,我们采取了以下措施:(1)鼓励标注人员创建新标签;(2)排除对故事理解信息量小的标签(如"站立""交谈")。最后,我们合并标签并筛选出出现频率不低于25次的80个动作和90个地点,作为最终标注。总计有4.2万个片段带有1.96万个地点标签和4.5万个动作标签。
描述对齐
由于事件比角色和场景更为复杂,用自然语言描述是表示事件的合适方式。先前的工作已实现将剧本46、描述性视频服务(DVS)57、书籍91或维基剧情66,67,68与电影对齐。然而,书籍与电影往往差异较大,难以良好对齐;DVS文本难以获取,限制了基于该类数据的数据集规模57;维基剧情通常是简短摘要,无法涵盖电影的所有重要事件。鉴于上述问题,我们选择剧情梗概作为MovieNet中的故事描述。电影片段与剧情梗概段落之间的关联由三名不同的标注人员通过"粗到细"的流程人工标注*。最终,我们获得了4208个高度一致的段落-片段对。*
4 应用MovieNet:基准测试与分析
凭借大量数据和综合性标注,MovieNet能够支持各类研究课题。本节中,我们将从类型、电影风格、角色、场景和故事五个方面对电影进行分析。针对每个课题,我们基于MovieNet建立一个或多个基准测试,并提供采用当前主流技术的基线模型和实验结果分析,以展示MovieNet在各类任务中的潜在影响。这些任务涵盖了全面电影理解的不同视角,但由于篇幅限制,此处仅作简要介绍,更多详细分析请参见补充材料,5节将介绍更多值得探索的有趣课题。
4.1 类型分析
类型是任何具有艺术元素的媒体的关键属性。电影类型分类已得到广泛研究89,63,10,但这些研究存在两个不足:(1)现有数据集规模较小;(2)所有研究都集中在图像或预告片分类,而忽略了一个更重要的问题------如何分析长视频的类型。
MovieNet提供了一个大规模的类型分析基准测试,包含1100部电影、6.8万个预告片和160万张图片。表3a对比了不同数据集,可见MovieNet的规模远大于先前的数据集。
表3:(a)MovieNet与其他类型分析基准测试的对比;(b)MovieNet中类型分类的部分基线模型结果
(a)
| 数据集 | 类型数量 | 电影数量 | 预告片数量 | 图片数量 |
|---|---|---|---|---|
| MGCD89 | 4 | - | - | 1.2万 |
| LMTD63 | 4 | - | - | 3.5万 |
| MScope10 | 13 | - | 5万 | 5万 |
| MovieNet | 21 | 1100 | 6.8万 | 160万 |
(b)
| 数据 | 模型 | 召回率@0.5 | 精确率@0.5 | 平均精度均值 |
|---|---|---|---|---|
| 图片 | VGG1664 | 27.32 | 66.28 | 32.12 |
| 图片 | ResNet5032 | 34.58 | 72.28 | 46.88 |
| 预告片 | TSN-r5074 | 17.95 | 78.31 | 43.70 |
| 预告片 | I3D-r509 | 16.54 | 69.58 | 35.79 |
| 预告片 | TRN-r5086 | 21.74 | 77.63 | 45.23 |
基于MovieNet,我们首先提供了基于图像和基于视频的类型分类基线模型,结果如表3b所示。将小数据集63,10中的类型分类结果与MovieNet中的结果对比发现,当数据集规模扩大时,模型性能大幅下降。新提出的MovieNet给现有方法带来了两个挑战:(1)MovieNet中的类型分类成为长尾识别问题,标签分布极不均衡(例如,"剧情片"的数量是"体育片"的40倍);(2)类型是依赖于角色动作、服装、面部表情甚至背景音乐的高层语义标签,而当前方法擅长视觉表征,面对需要考虑高层语义的问题时往往表现不佳。我们希望MovieNet能推动这些挑战性课题的研究。
另一个需要解决的新问题是如何分析电影的类型。由于电影时长极长,且并非所有片段都与类型相关,这一问题极具挑战性。遵循"从预告片学习并应用于电影"的思路36,我们采用基于预告片训练的视觉模型作为镜头级特征提取器,然后将特征输入时间模型以捕捉电影的时间结构,整体框架如图3a所示。通过这种方法,我们可以得到电影的类型响应曲线,具体而言,能够预测电影中哪些部分与特定类型的相关性更强。此外,该预测结果还可用于类型引导的预告片生成,如图3b所示。上述分析表明,MovieNet将推动这一具有挑战性和价值的研究课题的发展。
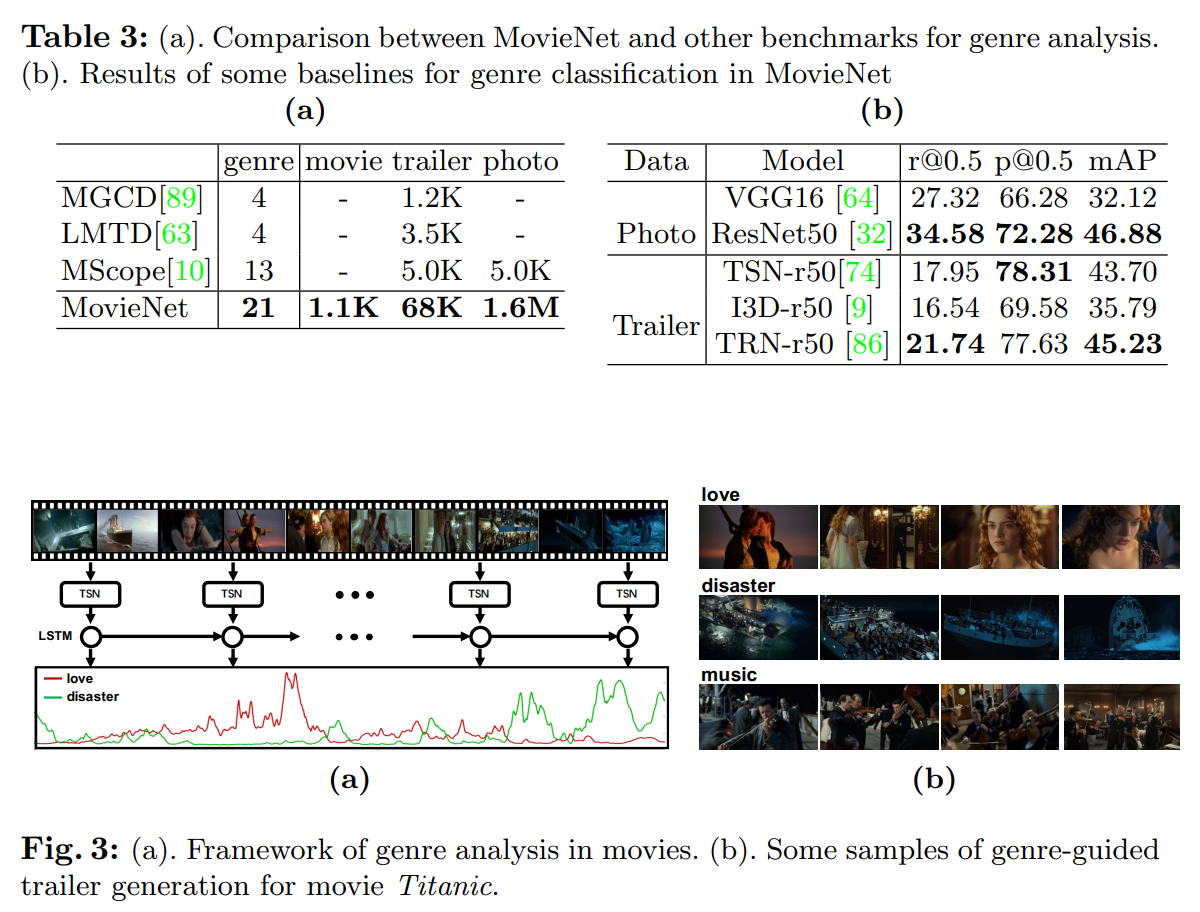
图3:(a). 电影体裁分析框架。b 电影《泰坦尼克号》的一些基于类型引导的预告片生成示例。
4.2 电影风格分析
如前所述,电影风格是从拍摄艺术的角度向观众呈现故事的方式。例如,推镜头通常用于吸引观众对特定对象的注意力。事实上,电影风格对视频理解和编辑都至关重要,但相关研究较少,也缺乏大规模数据集支持。
基于MovieNet中标注的电影风格标签,我们建立了电影风格预测基准测试,具体而言,是识别每个镜头的视角尺度和镜头运动。与现有数据集相比,MovieNet是首个同时涵盖视角尺度和镜头运动的数据集,且规模大得多,如表4a所示。我们应用了TSN74、I3D9等多种视频片段分类模型来解决这一问题,结果如表4b所示。由于视角尺度取决于镜头帧中主体的占比,检测主体对电影风格预测至关重要。此处,我们采用显著性检测方法17获取每个镜头的主体图,从而实现了更好的性能,如表4b所示。尽管利用主体为该任务指明了方向,但仍有很长的路要走。我们希望MovieNet能推动这一重要但被忽视的视频理解课题的发展。
表4:(a)MovieNet与其他电影风格预测基准测试的对比;(b)MovieNet中电影风格预测的部分基线模型结果
(a)
| 数据集 | 镜头数量 | 视角尺度类别数 | 镜头运动类别数 |
|---|---|---|---|
| Lie 20144 | 327 | 3 | ✔️ |
| Sports 200782 | 1364 | 8 | ✔️ |
| Context 201180 | 3206 | 4 | ✔️ |
| Taxon 200972 | 5054 | 7 | ✔️ |
| MovieNet | 46857 | 5 | ✔️ |
(b)
| 方法 | 视角尺度准确率 | 镜头运动准确率 |
|---|---|---|
| I3D9 | 76.79 | 78.45 |
| TSN74 | 84.08 | 70.46 |
| TSN+R³Net17 | 87.50 | 80.65 |
4.3 角色识别
现有研究71,75,45表明,电影是以人为中心的视频,角色在其中扮演着重要角色。因此,检测和识别角色对电影理解至关重要。尽管人物/角色识别并非新任务,但先前的研究要么基于其他数据源85,40,43,要么基于小规模基准测试31,3,65,导致其结果在电影角色识别方面缺乏说服力。
我们提出了两个电影角色分析基准测试:角色检测和角色识别。我们提供了来自3087个身份的110万个实例来支持这些基准测试。如表5所示,与一些流行的人物分析数据集相比,MovieNet包含更多的实例和身份。以下部分将分别对角色检测和角色识别进行分析。
表5:人物分析数据集对比
| 数据集 | 身份数量 | 实例数量 | 数据源 |
|---|---|---|---|
| COCO43 | - | 26.2万 | 网络图片 |
| CalTech19 | - | 35万 | 监控视频 |
| Market85 | 1501 | 3.2万 | 监控视频 |
| CUHK0340 | 1467 | 2.8万 | 监控视频 |
| AVA28 | - | 42.6万 | 电影 |
| CSM34 | 1218 | 12.7万 | 电影 |
| MovieNet | 3087 | 110万 | 电影 |

图4:不同数据源中的人员
角色检测
不同数据源的图像存在较大的领域差异,如图4所示。因此,在通用目标检测数据集(如COCO43)或行人数据集(如CalTech19)上训练的角色检测器,在检测电影角色时性能不够理想,这一结论得到了表6a中结果的支持。为获得更好的角色检测器,我们使用13,12中的工具包,在MovieNet上训练了多种流行模型55,42,8。结果表明,借助MovieNet中多样的角色实例,基于MovieNet训练的Cascade R-CNN模型能够实现极高的性能(平均精度均值达95.17%)。也就是说,利用大规模电影数据集和当前最先进的检测模型,角色检测问题可以得到较好的解决。这一高性能检测器将为电影角色分析研究提供支持。
角色识别
识别电影中的角色是一个更具挑战性的问题,从图4中多样的样本可以看出这一点。我们基于MovieNet进行了不同的实验,结果如表6b所示。从这些结果可以得出:(1)在行人重识别数据集上训练的模型由于领域差异,在角色识别中效果不佳;(2)聚合实例的不同视觉线索对电影角色识别至关重要;(3)当前最先进的模型平均精度均值可达75.95%,这表明该问题具有挑战性,需要进一步研究。
表6:(a)角色检测结果;(b)角色识别结果
(a)
| 训练数据 | 方法 | 平均精度均值 |
|---|---|---|
| COCO43 | Faster R-CNN | 81.50 |
| CalTech19 | Faster R-CNN | 5.67 |
| CSM34 | Faster R-CNN | 89.91 |
| MovieNet | Faster R-CNN | 92.13 |
| MovieNet | RetinaNet | 91.55 |
| MovieNet | Cascade R-CNN | 95.17 |
(b)
| 训练数据 | 线索 | 方法 | 平均精度均值 |
|---|---|---|---|
| Market85 | 身体 | r50-softmax | 4.62 |
| CUHK0340 | 身体 | r50-softmax | 5.33 |
| CSM34 | 身体 | r50-softmax | 26.21 |
| MovieNet | 身体 | r50-softmax | 32.81 |
| MovieNet | 身体+面部 | 两步法45 | 63.95 |
| MovieNet | 身体+面部 | PPCC34 | 75.95 |
4.4 场景分析
如前所述,场景是电影的基本语义单位。因此,分析电影中的场景至关重要。场景理解的关键问题可能在于场景边界的确定和场景内容的识别。如表7所示,MovieNet包含超过4.3万个场景边界和6.5万个动作/地点标签,是唯一能同时支持场景分割和场景标签标注的数据集。此外,MovieNet的规模也大于所有先前的工作。
表7:场景分析数据集对比
| 数据集 | 场景数量 | 动作标签数量 | 地点标签数量 |
|---|---|---|---|
| OVSD59 | 300 | - | - |
| BBC2 | 670 | - | - |
| Hollywood246 | 1.7万 | 1.2万 | - |
| MovieGraphs71 | - | 23.4万 | 7.6万 |
| AVA28 | - | 36万 | - |
| MovieNet | 4.2万 | 4.5万 | 1.96万 |
场景分割
我们首先测试了一些场景分割基线模型59,2。此外,我们还提出了一种基于双向LSTM27,52的序列模型,名为多语义LSTM(MS-LSTM),以研究多模态和多种语义元素(包括音频、角色、动作和场景)带来的增益。表9中的结果表明:(1)得益于大规模和高多样性,在MovieNet上训练的模型能够实现更好的性能;(2)多模态和多种语义元素对场景分割至关重要,显著提升了模型性能。
表9:场景分割结果
| 数据集 | 方法 | 平均精度(↑) | 交并比均值(↑) |
|---|---|---|---|
| OVSD59 | MS-LSTM | 0.313 | 0.387 |
| BBC2 | MS-LSTM | 0.334 | 0.379 |
| MovieNet | Grouping59 | 0.336 | 0.372 |
| MovieNet | Siamese2 | 0.358 | 0.396 |
| MovieNet | MS-LSTM | 0.465 | 0.462 |
动作/地点标签标注
为进一步理解电影中的故事,有必要对叙事关键元素(即地点和动作)进行分析。本节将介绍两个基准测试。首先,对于动作分析,任务是多标签动作识别,旨在识别给定视频片段中的所有人类动作或互动。我们在实验中实现了三种标准动作识别模型:TSN74、I3D9和基于83修改的SlowFast网络23,结果如表10所示。对于地点分析,我们提出了另一个多标签地点分类基准测试,采用I3D9和TSN74作为基线模型,结果如表10所示。从结果可以看出,由于不同实例的高度多样性,动作和地点标签标注是一个极具挑战性的问题。
表10:场景标签标注结果
| 标签类型 | 方法 | 平均精度均值 |
|---|---|---|
| 动作 | TSN74 | 14.17 |
| 动作 | I3D9 | 20.69 |
| 动作 | SlowFast23 | 23.52 |
| 地点 | I3D9 | 7.66 |
| 地点 | TSN74 | 8.33 |
4.5 故事理解
先前的视频理解研究广泛采用网络视频7,79作为数据源。与网络视频相比,电影最显著的特征是故事性。电影的创作目的是讲述故事,而用自然语言(如剧情梗概)描述是展现故事最直观的方式。基于上述观察,我们选择自然语言电影片段检索任务来分析电影中的故事。基于MovieNet中对齐的剧情梗概,我们建立了电影片段检索基准测试。具体而言,给定一段剧情梗概段落,我们旨在找到与该段落中故事内容最相关的电影片段。由于电影内容丰富且剧情梗概中的描述具有高层语义,这是一项极具挑战性的任务。表8对比了我们的基准测试数据集与其他相关数据集,可见与MovieQA68相比,我们的数据集在描述方面更复杂;与MovieGraphs71相比,我们的片段更长、包含的信息更多。
表8:电影故事理解数据集对比(1)每部电影的句子数;(2)每个片段的时长(秒)
| 数据集 | 每部电影句子数 | 每个片段时长(秒) |
|---|---|---|
| MovieQA68 | 35.2 | 202.7 |
| MovieGraphs71 | 408.8 | 44.3 |
| MovieNet | 83.4 | 428.0 |
一般来说,一个故事可以概括为"某人在某时某地做某事"。如图5所示,语言和视频所呈现的故事都可以表示为{角色、动作、地点}图序列。也就是说,理解故事需要:(1)识别叙事关键元素,即角色、动作、地点等;(2)分析电影和剧情梗概的时空结构。因此,我们的方法首先利用中层实体(如角色、场景)以及多模态(如字幕)来辅助检索,然后通过将中层实体构建为图结构,探索电影和剧情梗概的时空结构。详细内容请参见补充材料。
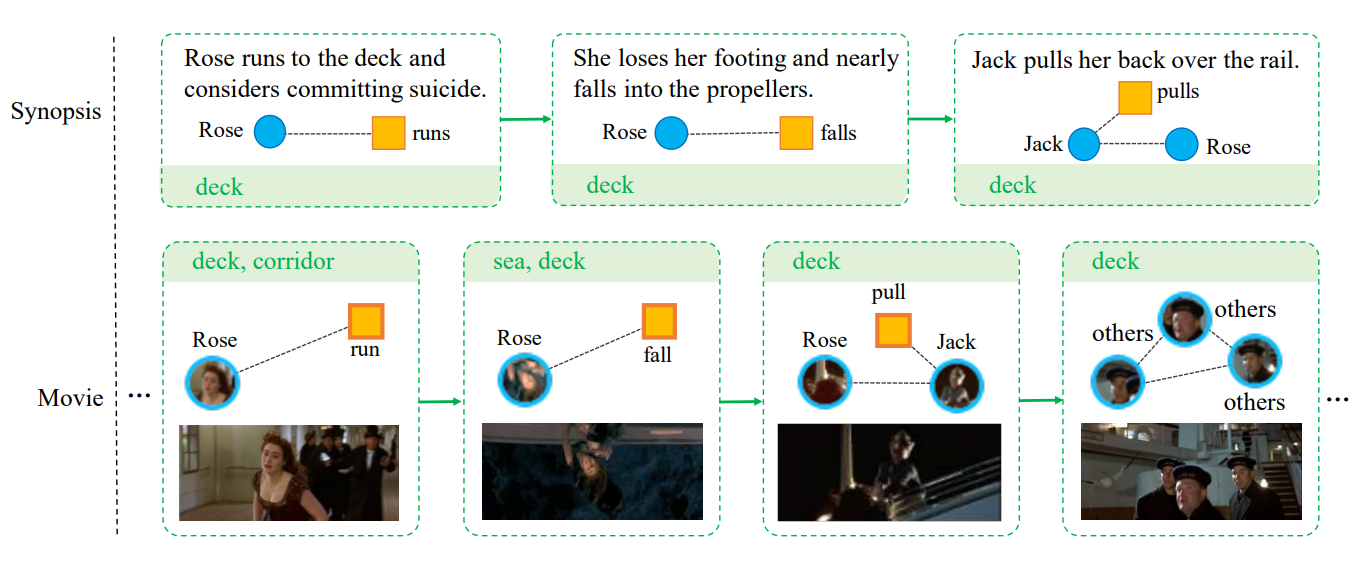
图5:MovieNet-MSR中的概要段落和电影片段示例。它展示了电影和概要中故事的空间-时间结构。我们还可以看到,人物、动作和地点是理解故事的关键要素。
利用中层实体和多模态
我们采用VSE25作为基线模型,该模型将视觉和语言特征嵌入到一个联合空间中。具体而言,段落特征通过对每个句子的Word2Vec47特征取平均得到,视觉特征通过对每个镜头的ResNet32外观特征取平均得到。我们添加了字幕特征来增强视觉特征,然后在框架中聚合了包括角色、动作和电影风格在内的不同语义元素。借助在MovieNet其他基准测试(如动作识别和角色检测)上训练的模型,我们能够获得动作特征和角色特征。此外,我们观察到不同电影风格下关注的元素有所不同。例如,在全景镜头中应更关注动作,而在特写镜头中应更关注角色和对话。基于这一观察,我们提出了一个电影风格引导的注意力模块,该模块预测镜头中每个元素(如动作、角色)的权重,用于增强视觉特征。实验结果如表11所示。实验表明,考虑电影的不同元素后,性能有了显著提升。这说明,一个包含支持中层实体分析的综合性标注的数据集,对电影理解至关重要。
探索电影和剧情梗概的时空图结构
简单添加不同的中层实体已能提升结果。此外,如图5所示,我们观察到电影和剧情梗概中的故事存在两个重要结构:(1)电影和剧情梗概的时间结构,即故事可以表示为按特定时间顺序排列的事件序列;(2)不同中层元素的空间关系(如角色共存及其互动)可以构建为图结构。我们采用77中的方法,将上述结构转化为两个图匹配问题,结果如表11所示。利用电影和剧情梗概中故事内部结构的图表示,检索性能可以进一步提升,这也表明具有挑战性的MovieNet将为基于故事的电影理解提供更好的数据源。
表11:电影片段检索结果(G表示全局外观特征,S表示字幕特征,A表示动作特征,P表示角色特征,C表示电影风格特征)
| 方法 | 召回率@1 | 召回率@5 | 召回率@10 | 中位排名 |
|---|---|---|---|---|
| 随机 | 0.11 | 0.54 | 1.09 | 460 |
| G | 3.16 | 11.43 | 18.72 | 66 |
| G+S | 3.37 | 13.17 | 22.74 | 56 |
| G+S+A | 5.22 | 13.28 | 20.35 | 52 |
| G+S+A+P | 18.50 | 43.96 | 55.50 | 7 |
| G+S+A+P+C | 18.72 | 44.94 | 56.37 | 7 |
| MovieSynAssociation77 | 21.98 | 51.03 | 63.00 | 5 |
5 讨论与未来工作
本文介绍了MovieNet,这是一个包含多方面标注的综合性数据集,用于支持全面的电影理解。
我们提出了多个涉及电影理解不同方面的具有挑战性的基准测试,即探索拍摄艺术、识别中层实体以及理解故事等高层语义。此外,电影片段检索的结果表明,根据电影的内部结构整合拍摄艺术和中层实体,对故事理解有很大帮助。这些都证明了综合性标注的有效性。
未来,我们的工作将从两个方面展开:(1)扩展标注:目前我们的数据集包含1100部电影,未来将进一步扩展数据集,纳入更多电影和标注;(2)探索更多方法和课题:为解决本文提出的具有挑战性的任务,我们将探索更有效的方法。此外,从视频编辑的角度来看,还有更多有意义和实用的课题可以利用MovieNet来解决,例如电影修复、预告片生成等。
补充材料
以下部分提供了MovieNet的详细信息,包括数据、标注、实验和工具包,内容组织如下:
(1)A节详细介绍了特定数据的内容以及数据的收集和清理方法:
- 元信息:给出元信息列表及其内容(见A.1节);
- 电影:提供电影的统计信息(见A.2节);
- 字幕:介绍字幕的收集和后处理流程(见A.3节);
- 预告片:说明预告片的选择和处理过程(见A.4节);
- 剧本:介绍剧本与电影的自动对齐方法(见A.5节);
- 剧情梗概:介绍剧情梗概的统计信息(见A.6节);
- 图片:展示图片的统计信息和部分示例(见A.7节)。
(2)B节通过描述标注界面和流程,详细展示了MovieNet的标注工作:
- 角色边界框和身份:介绍利用半自动化算法收集图像和标注图像的分步流程(见B.1节);
- 电影风格:呈现电影风格的分析结果,介绍电影风格标注的流程和界面(见B.2节);
- 场景边界:展示如何通过优化的标注流程有效标注场景边界(见B.3节);
- 动作和地点标签:描述为电影片段联合标注动作和地点标签的流程,展示相关流程和界面(见B.4节);
- 剧情梗概对齐:介绍一种高效的"粗到细"标注流程,用于将剧情梗概段落与电影片段对齐(见B.5节);
- 预告片-电影对齐:介绍一种自动方法,将预告片中的镜头与原电影对齐,该标注有助于预告片生成等任务(见B.6节)。
(3)C节在MovieNet上建立了多个基准测试,并在每个基准测试上进行了实验,详细介绍了每个基准测试的实验实现细节:
- 类型分类:类型分类是基于MovieNet类型分类基准测试的多标签分类任务(详见C.1节);
- 电影风格分析:在MovieNet电影风格预测基准测试中,包含两个分类任务,即视角尺度分类和镜头运动分类(见C.2节的实现细节);
- 角色检测:介绍MovieNet角色检测基准测试中的检测任务、模型和实现细节(见C.3节);
- 角色识别:进一步介绍MovieNet角色识别的具有挑战性的基准测试设置(详见C.4节);
- 场景分割:场景分割任务是通过场景切割电影的边界检测任务,将介绍特征提取、基线模型和评估协议的细节(见C.5节);
- 动作识别:呈现MovieNet上的多标签动作分类任务,包括基线模型和实验结果的细节(见C.6节);
- 地点识别:同样呈现MovieNet上的多标签地点分类任务(见C.7节);
- 故事理解:为实现故事理解,我们利用MovieNet片段检索基准测试,探索MovieNet不同方面的综合分析潜力,实验设置和结果见C.8节。
(4)为管理所有数据并支持所有基准测试,我们构建了一个代码库,包含便捷的处理工具。除了基准测试的代码外,我们还将发布该工具包,其功能见D节。
A MovieNet中的数据
MovieNet包含多种多模态数据和多方面的高质量标注,用于支持电影理解。以下详细介绍这些数据,表A1对比了MovieNet与其他相关数据集的数据情况。
A.1 元信息
MovieNet包含37.5万部电影的元信息。需要注意的是,元信息的数量远大于提供视频资源的电影数量(即1100部),因为我们认为元信息本身可以支持多种任务。此外,这1100部精选电影的元信息均包含在该元信息集中。图A1展示了《泰坦尼克号》的元信息示例,以下详细介绍元信息中的各个项目。
- IMDb ID:IMDb网站上电影的ID,通常以"tt"开头,后跟7或8位数字(例如《泰坦尼克号》的IMDb ID为"tt0120338")。通过该ID可以轻松从IMDb获取电影的相关信息(例如《泰坦尼克号》的主页为"https://www.imdb.com/title/tt0120338/")。在MovieNet中,IMDb ID也被用作电影的ID。
- TMDb ID:TMDb网站上电影的ID。我们发现TMDb中的部分内容质量高于IMDb(例如,TMDb提供不同版本的预告片和更高分辨率的海报),因此将其作为IMDb的补充。TMDb为用户提供了信息搜索API,借助MovieNet中提供的TMDb ID,用户可以根据需要轻松获取更多信息。
- 豆瓣ID:豆瓣电影网站上电影的ID。我们发现对于一些亚洲电影(如中国和日本电影),IMDb和TMDb上的信息较少,因此转向中国电影网站------豆瓣电影,以获取更多亚洲电影的信息。MovieNet中部分电影提供了豆瓣ID,方便用户使用。
- 版本:对于有多个版本的电影(如普通版、导演剪辑版),我们提供每个版本的时长和描述,帮助研究人员将标注与自己的资源对齐。
- 标题:电影的标题,遵循IMDb的格式(例如《Titanic (1997)》)。
- 类型:基于叙事元素或观众情感反应的分类(如喜剧、剧情片)。MovieNet中的电影共有28种独特类型,图A2展示了类型的分布情况。
- 上映日期:电影的公映日期,图A3展示了每年上映的电影数量,从中可以看出电影数量逐年递增。
- 国家/地区:电影的制作国家/地区,图A4展示了MovieNet中电影所属的前40个国家/地区。
- IMDb评分:用户在IMDb上对电影的评分,图A5展示了不同评分的分布情况。
- 导演:包含导演的姓名和ID。
- 编剧:包含编剧的姓名和ID。
- 演员阵容:电影中的演员列表,每个演员条目包含演员姓名、ID以及在电影中饰演的角色名称。
- 概述:电影的简要介绍,通常涵盖电影的背景和主要角色。
- 故事情节:电影的剧情摘要,比概述更长、细节更丰富。
- 维基剧情:来自维基百科的电影剧情摘要,通常比概述和故事情节更长。

图A1:电影《泰坦尼克号》的元数据示例。
表A1:MovieNet与相关数据集的数据对比
| 数据集 | 电影数量 | 预告片数量 | 图片数量 | 元信息数量 | 类型标签数量 | 剧本数量 | 剧情梗概数量 | 字幕数量 | 剧情数量 | AD数量 |
|---|---|---|---|---|---|---|---|---|---|---|
| MovieScope10 | - | 5027 | 5027 | 5027 | 1.3万 | - | - | - | 5027 | - |
| MovieQA68 | 408 | - | - | - | - | - | - | 408 | 408 | - |
| LSMDC57 | 200 | - | - | - | - | 50 | - | - | - | 186 |
| MovieGraphs71 | 51 | - | - | - | - | - | - | - | - | - |
| AVA28 | 430 | - | - | - | - | - | - | - | - | - |
| MovieNet | 1100 | 6万 | 390万 | 37.5万 | 80.5万 | 986 | 3.1万 | 5388 | 4.6万 | - |
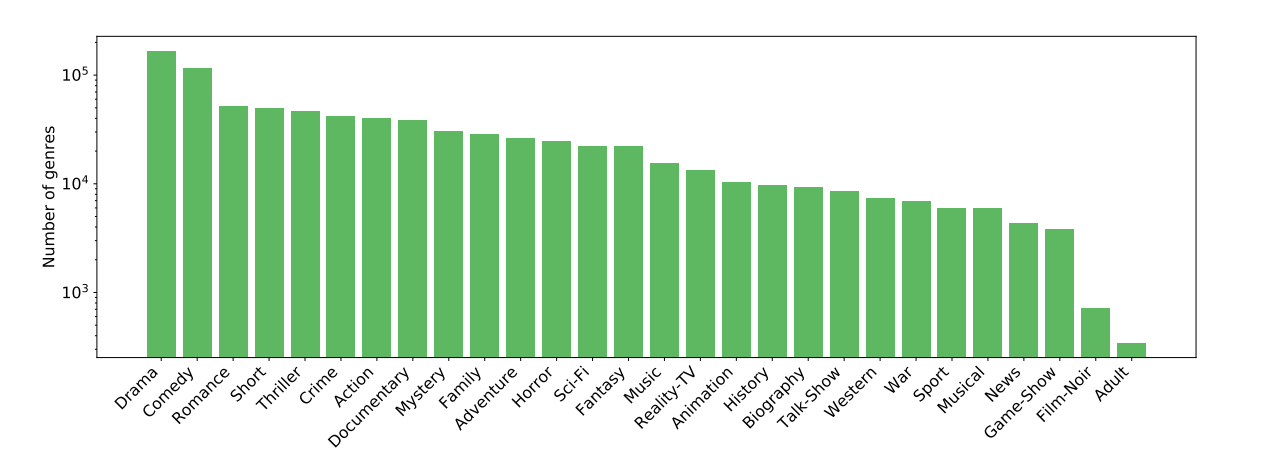
图A2:元数据中的流派统计。该图显示了每个流派类别的流派数量(y轴为对数刻度)
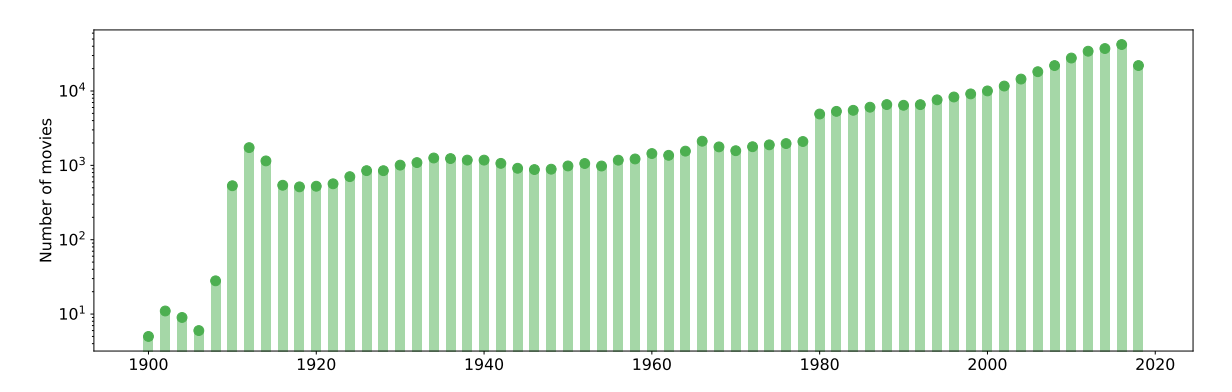
图A3:元数据中电影上映日期的分布。该图显示了每年电影的数量(y轴为对数刻度)。请注意,电影数量通常随时间推移而增加。
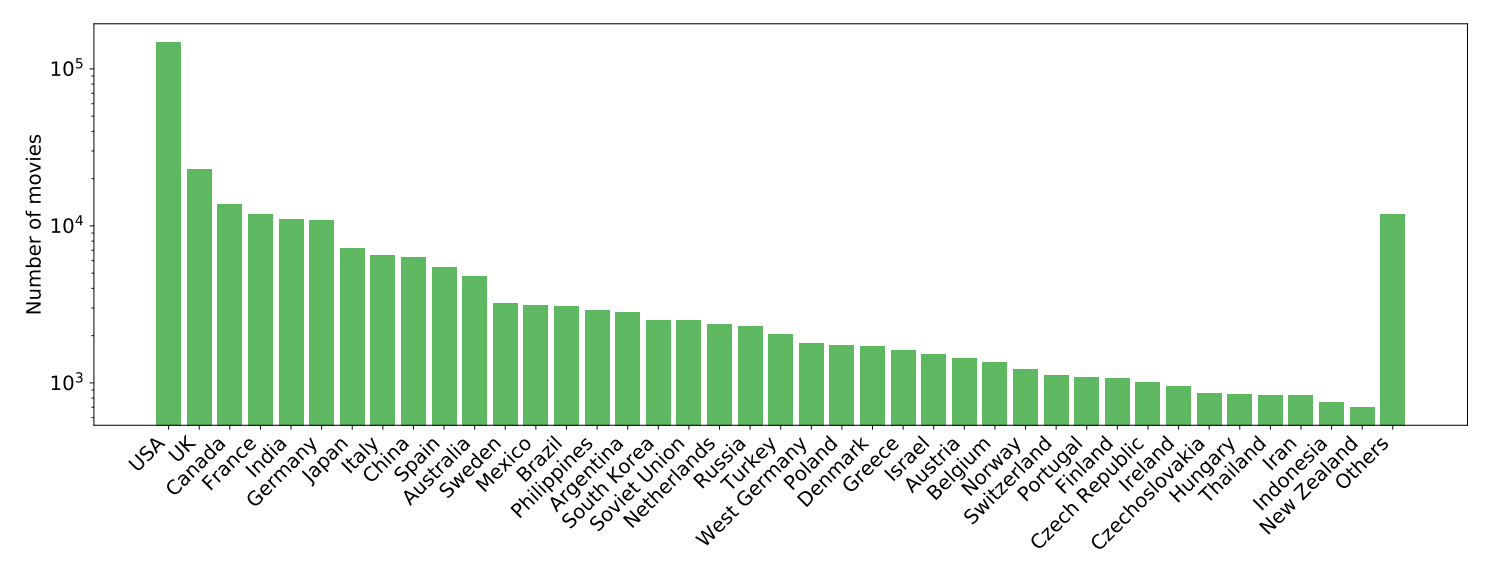
图A4:元数据中电影所属的国家。此处我们展示了前40个国家,左侧为"其他"。电影数量(y轴)采用对数刻度。
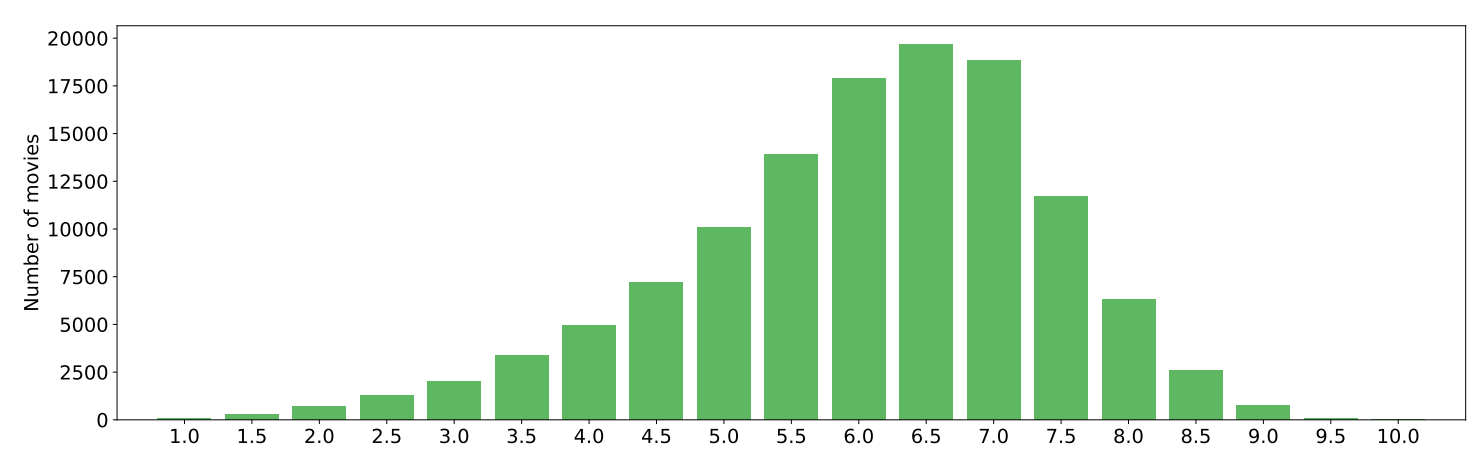
图A5:MovieNet元数据中的评分分布。
A.2 电影
如论文中所述,MovieNet包含1100部电影。图A6展示了这1100部电影的部分统计信息,包括时长和镜头数量的分布。如A.1节所述,除了这1100部电影外,我们还尽可能提供了其他电影的元信息,下文介绍的预告片、图片等其他数据类型也是如此,不再单独说明。
论文中提到,我们选择的电影涵盖了不同的年份、国家/地区和类型,图A7展示了这些数据的分布情况,可以看出电影在年份、国家/地区和类型方面具有多样性。
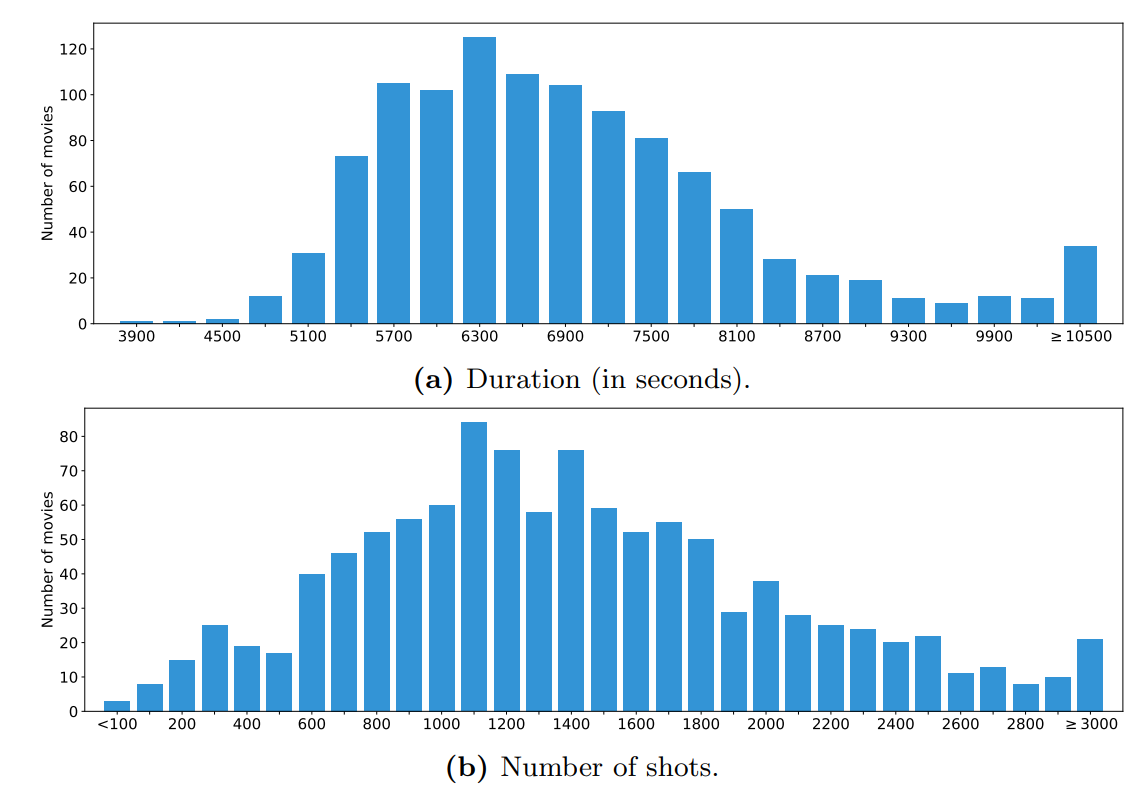
图A6:MovieNet中1000部电影的镜头时长和数量分布。
特征表示
对于当前的深度学习框架和计算能力而言,处理长视频并非易事。为方便研究,我们提出了多种电影的特征表示方法:
- 基于镜头的视觉特征:对于大多数任务(如类型分类),基于镜头的表示是一种高效的表示方式。镜头是一段连续拍摄的帧序列,可视为电影的最小视觉单位。因此,我们在MovieNet中采用基于镜头的电影表示。具体而言,我们首先使用镜头检测工具62将每部电影分割成镜头,然后采样三个关键帧,并使用在ImageNet上预训练的模型提取视觉特征。
- 音频特征:对于每个镜头,我们还截取该镜头内的音频波形,然后提取音频特征14,作为视觉特征的补充。
- 基于帧的特征:对于动作识别等需要考虑运动信息的任务,我们还提供基于帧的特征。
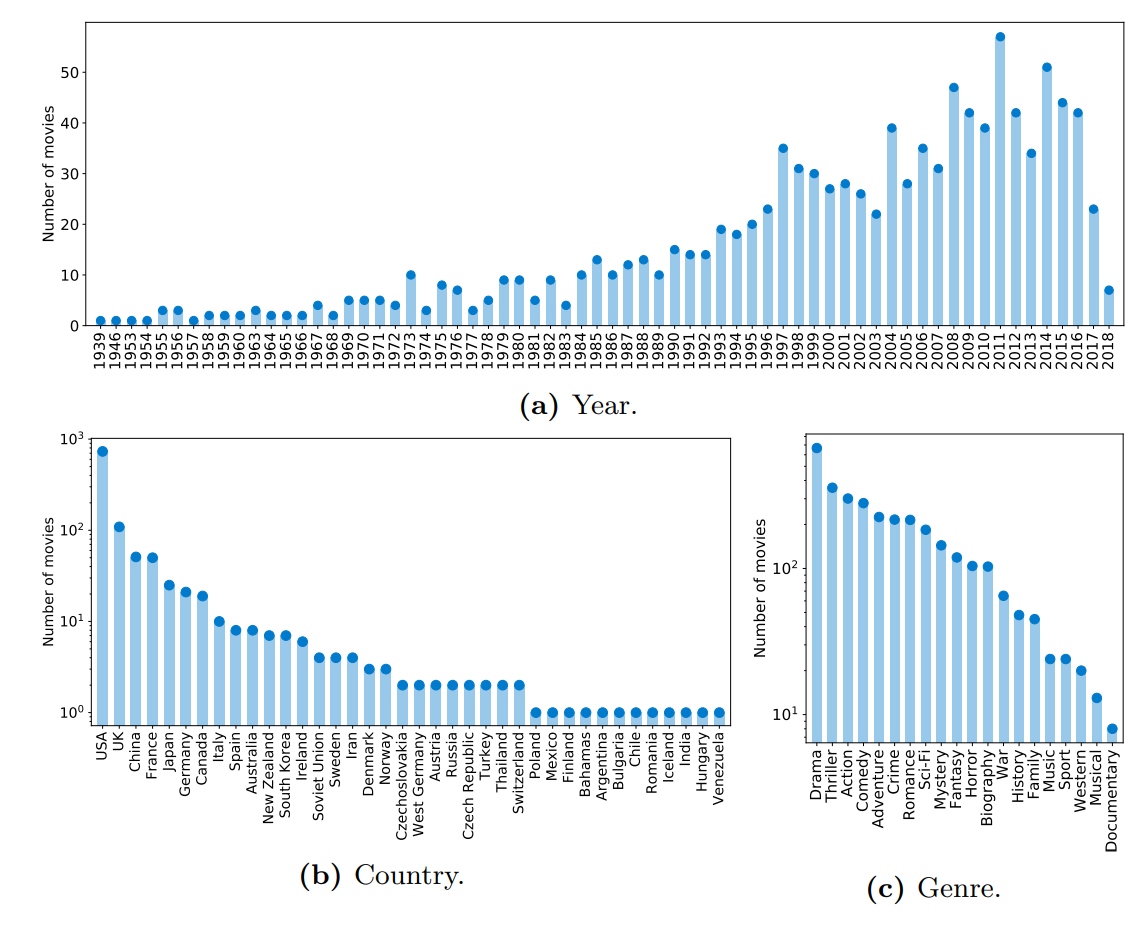
图A7:MovieNet中1100部电影的发行年份、国家和类型分布(国家和类型的y轴采用对数刻度)。
A.3 字幕
MovieNet中的每部电影都配有与电影对齐的英文字幕。由于一部电影通常有多个版本(如导演剪辑版、加长版),下载的字幕往往与视频不对齐。为确保每个字幕都与视频源对齐,在人工检查之前,我们采取了以下措施:(1)对于从原始视频中提取或从互联网上下载的字幕,首先确保字幕完整且为英文版本(通过正则表达式验证);(2)清理字幕,去除HTML标签等噪声;(3)利用现成工具7将音频转换为文本,并将文本与字幕匹配,得到时间偏移量;(4)过滤掉时间偏移量超过特定阈值的字幕,并重新下载。之后,我们人工检查仍然存在问题的字幕,并重复上述步骤。
具体而言,步骤(4)中的阈值设置为60秒,基于以下观察:(1)大多数对齐的字幕时间偏移量在1秒以内;(2)一些特殊情况(如长时间无对话的场景)会导致工具生成几秒的时间偏移量,但通常不超过60秒;(3)与原电影不匹配的字幕通常属于其他版本或来自其他电影,此时时间偏移量会大于60秒。
之后,我们让标注人员人工检查自动对齐后的字幕是否仍然存在错位情况。结果表明,自动对齐效果良好,仅有少数字幕仍存在问题。
A.4 预告片
MovieNet包含来自3333部独特电影的6万个预告片。图A8展示了预告片的统计信息,包括时长和镜头数量的分布。
除了来自电影的精彩片段(我们称之为内容镜头)外,预告片通常还包含一些额外的镜头,用于展示导演姓名、上映日期等重要信息(我们称之为信息镜头)。信息镜头与其他镜头差异较大,包含的视觉内容较少。对于大多数涉及预告片的任务,我们通常只关注内容镜头,因此有必要区分信息镜头和内容镜头。我们开发了一种简单的方法来解决这一问题:
对于一个镜头,首先使用场景文本检测器69检测每个帧上的文本,然后生成每个帧的二值图(文本边界框覆盖的区域设为1,其他区域设为0),接着对一个镜头的所有二值图取平均,得到热力图,再对热力图取平均,得到一个总分s,用于表示镜头中检测到的文本量。在MovieNet中,总分s高于阈值α且平均对比度低于阈值β的镜头被视为信息镜头。这里考虑对比度是因为观察到信息镜头通常具有简单的背景。
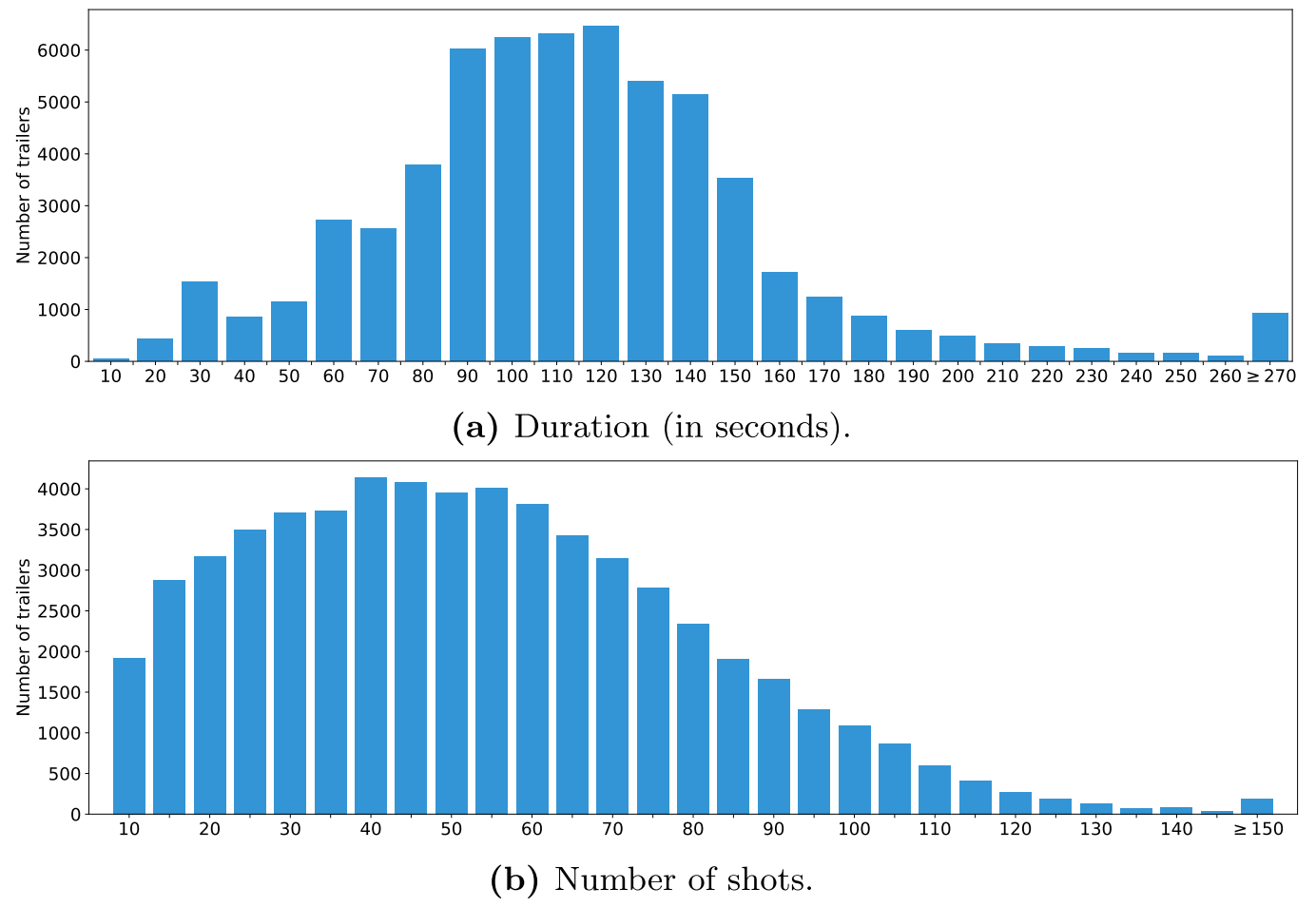
图 A8:MovieNet 中预告片的时长和镜头数分布
A.5 剧本
MovieNet提供了对齐的剧本,以下介绍剧本对齐的细节。如论文中所述,我们通过自动匹配对话与字幕,将电影剧本与电影对齐,具体流程如下:
电影剧本是电影制作人员撰写的作品,叙述了故事情节和对话,对电影摘要等任务非常有用。为获取这些任务的数据,需要将剧本与电影时间线对齐。
在预处理阶段,我们开发了一种基于正则表达式匹配的剧本解析算法,将剧本格式化为场景单元列表,其中每个场景单元表示特定事件的故事情节片段和对话片段的组合,示例如图A9所示。为将每个故事情节片段与电影时间线对齐,我们首先将对话片段与字幕关联起来。具体而言,我们将剧本-时间线对齐问题转化为对话-字幕对齐的优化问题,这一思路源于对话是字幕大纲的观察。
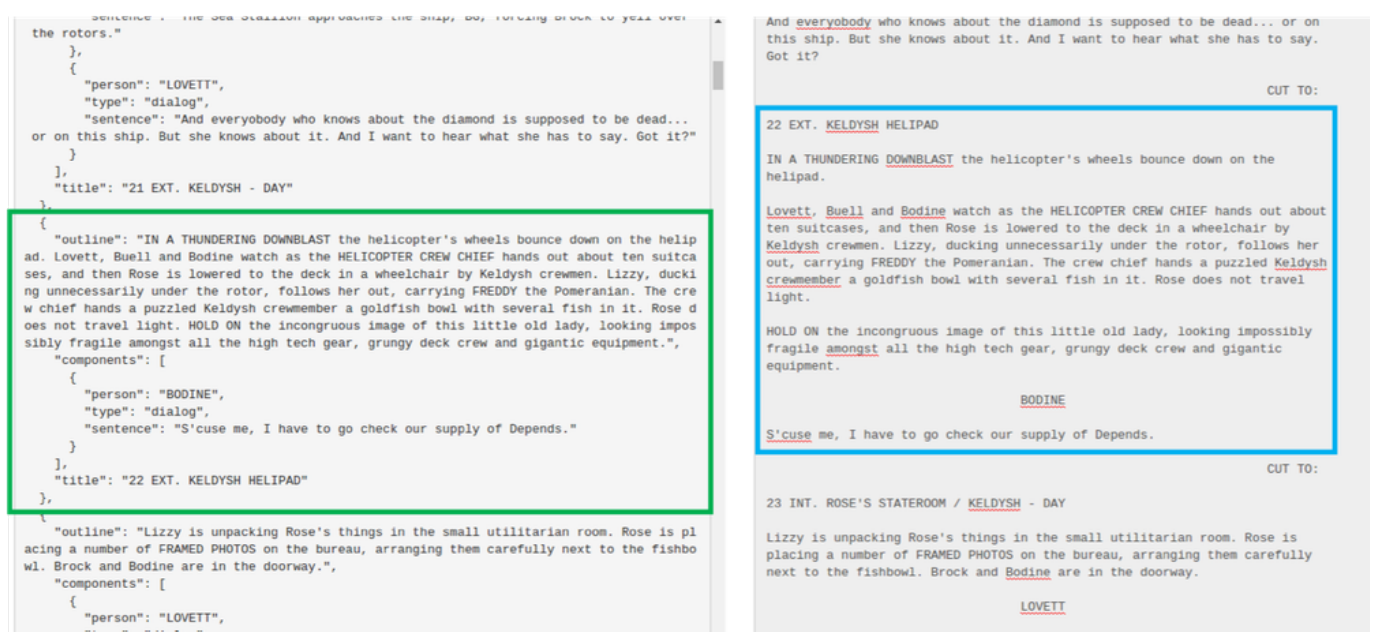
图 A9:这里展示了一个解析后的剧本示例。左侧块显示了格式化后的剧本片段,右侧块显示了对应的原始剧本片段,来自《泰坦尼克号》。
设digidig_idigi表示第i个场景单元中的对话片段,subjsub_jsubj表示第jjj个字幕句子。我们使用TF-IDF50提取对话片段和字幕句子的文本特征,设fi=TF−IDF(digi)f_i=TF-IDF(dig_i)fi=TF−IDF(digi)表示第i个对话片段的TF-IDF特征向量,gj=TF−IDF(subj)g_j=TF-IDF(sub_j)gj=TF−IDF(subj)表示第j个字幕句子的TF-IDF特征向量。对于所有M个对话片段和N个字幕句子,相似度矩阵S定义为:
si,j=S(i,j)=fiTgj∣fi∣∣gj∣\]\[s_{i,j}=S(i,j)=\\frac{f_{i}\^{T}g_{j}}{\\vert f_i \\vert \\vert g_j \\vert}\]\[si,j=S(i,j)=∣fi∣∣gj∣fiTgj
对于第jjj个字幕句子,我们假设其匹配的对话片段索iji_jij应小于第j+1j+1j+1个字幕句子匹配的对话片段索ij+1i_{j+1}ij+1。考虑到这一假设,我们将对话-字幕对齐问题转化为以下优化问题:
maxij∑j=0N−1sij,js.t.0≤ij−1≤ij≤ij+1≤M−1\]\[ \\begin{array}{ll} \\underset{i_j}{max} \& \\sum_{j=0}\^{N-1} s_{i_j,j} \\\\ s.t. \& 0 \\leq i_{j-1} \\leq i_j \\leq i_{j+1} \\leq M-1 \\end{array} \]\[ijmaxs.t.∑j=0N−1sij,j0≤ij−1≤ij≤ij+1≤M−1
该问题可以通过动态规划算法有效解决。设L(p,q)表示将S替换为其子矩阵S0,...,p,0,...,q后上述优化问题的最优值,则有以下等式成立:
L(i,j)=max{L(i,j−1),L(i−1,j)+si,j}\]\[L(i,j)=\\max\\{L(i,j-1),L(i-1,j)+s_{i,j}\\}\]\[L(i,j)=max{L(i,j−1),L(i−1,j)+si,j}
可以看出,原问题的最优值为L(M-1,N-1)。为得到最优解,我们应用算法1所示的动态规划算法。一旦获得对话片段与字幕句子之间的关联,就可以直接将字幕句子的时间戳分配给与该对话片段来自同一场景单元的剧本片段。图A10展示了剧本对齐的定性结果,表明我们的算法无需人工干预,就能建立故事情节与时间线之间的关联。
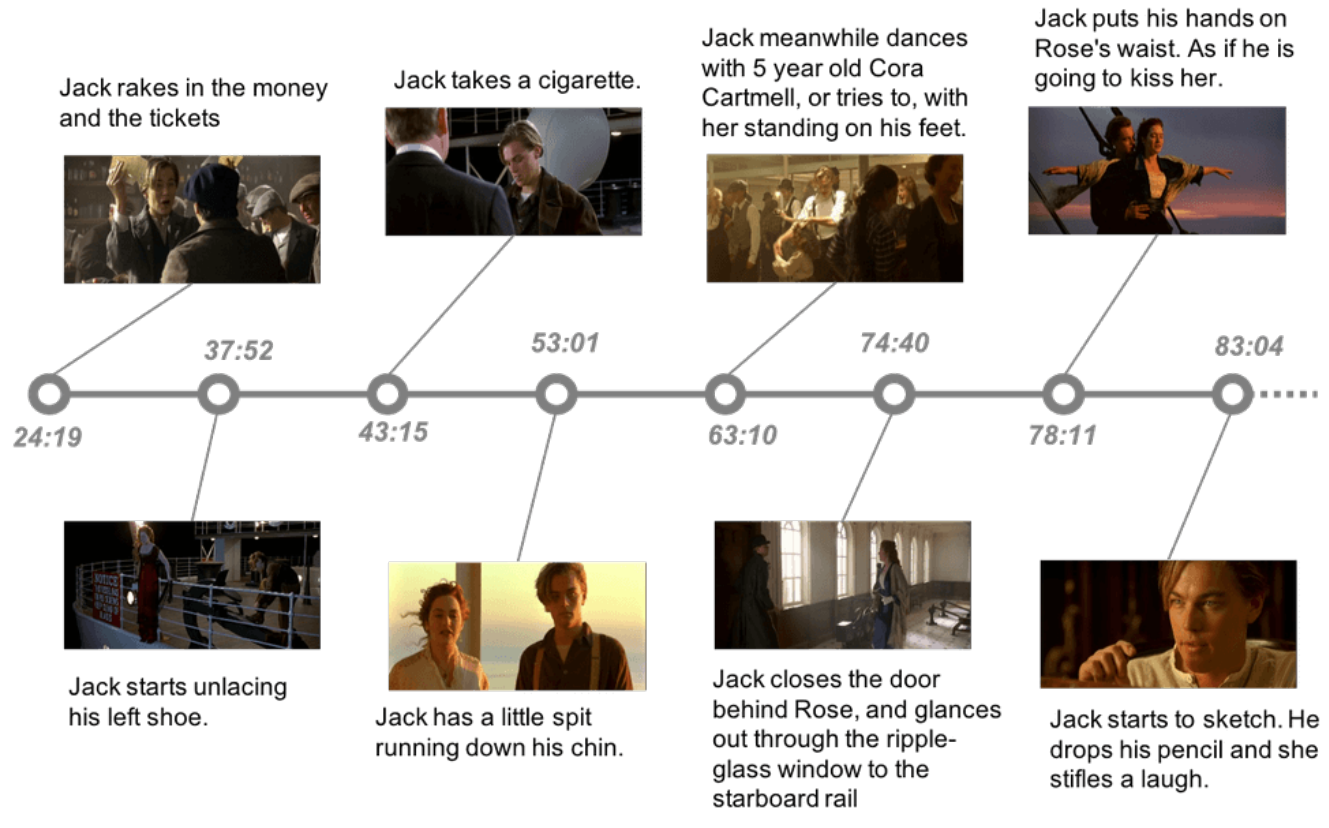
图 A10:剧本对齐的定性结果。该示例来自电影《泰坦尼克号》。每个带有时间戳的节点都与一个匹配的故事情节片段和一张快照图片相关联。
!
算法1 剧本对齐
输入 :S ∈ R^M×N
输出:R
- 初始化inds为M×N矩阵,val为M×N矩阵;
- 对于列col从0到N-1:
a. 对于行row从0到M-1:
i. a = valrow, col-1 + Srow, col(col=0时valrow, col-1设为0);
ii. b = valrow-1, col(row=0时valrow-1, col设为0);
iii. 如果a > b:- indsrow, col = row;
- valrow, col = a;
iv. 否则: - indsrow, col = indsrow-1, col;
- valrow, col = b;
- 初始化index = M-1;
- 对于列col从N-1到0:
a. Rcol = index;
b. index = indsindex, col; - 返回R。
A.6 剧情梗概
表A2展示了剧情梗概的部分统计信息,图A11展示了剧情梗概语料库的词云。与维基剧情相比,剧情梗概是质量更高的文本资源,包含更丰富的内容和更长的描述。
表A2:维基剧情与剧情梗概的统计信息对比
| 类型 | 每部电影句子数 | 每个句子单词数 | 每部电影单词数 |
|---|---|---|---|
| 维基剧情 | 26.2 | 23.6 | 618.6 |
| 剧情梗概 | 98.4 | 20.4 | 2004.7 |

图 A11:MovieNet 中剧情概要语料库的词云。
A.7 图片
如论文中所述,MovieNet包含来自7种类型的390万张电影图片。图A12展示了每种类型图片的占比,图A13展示了部分图片示例。
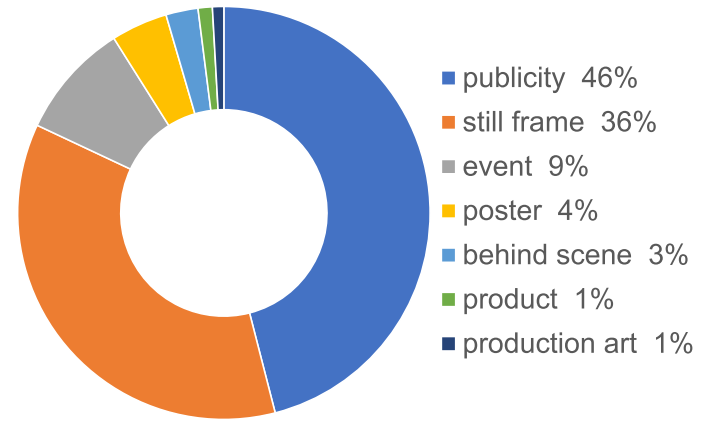
图A12:MovieNet中不同照片类型的百分比。

图A13:MovieNet中不同类型照片的样本。
B MovieNet中的标注
为实现高质量标注,我们在设计流程和标注界面方面付出了巨大努力,以下详细介绍相关内容。
B.1 角色边界框和身份
流程和界面
角色边界框和身份的标注遵循六个步骤:(1)首先从提供的电影中随机选择75.8万个关键帧(关键帧通过每个镜头平均采样三个帧获得),然后让标注人员标注这些帧中角色的边界框,共得到130万个角色边界框;(2)利用这130万个角色边界框训练一个角色检测器,具体而言,该检测器是带有特征金字塔41的Cascade R-CNN8,以ResNet-10132为骨干网络,检测精度可达95%;(3)由于一个镜头内不同帧中的角色身份通常是重复的,因此我们从每个镜头中仅选择一个帧进行角色身份标注。我们将训练好的检测器应用于用于身份标注的关键帧,由于检测器性能良好,此步骤仅需人工清理假阳性边界框,最终得到110万个角色实例;(4)标注电影中的角色身份是一项具有挑战性的任务,因为角色的视觉外观差异很大。为降低成本,我们开发了一个半自动化系统用于身份标注的第一步。首先从IMDb或TMDb获取每个演员的肖像(部分示例如图B1所示);(5)然后使用在MS1M29上训练的人脸模型提取人脸特征,使用在PIPA84上训练的模型提取身体特征。通过计算肖像与电影中角色实例的特征相似度,为每个演员排序候选列表,然后让标注人员判断每个候选是否为该演员。此外,每次标注后候选列表会更新,类似于主动学习,标注界面如图B2所示。我们发现该半自动化系统能大幅降低标注成本;(6)由于半自动化系统可能引入一些偏差和噪声,我们进一步设计了清理步骤。在此步骤中,按时间顺序展示帧,并显示第一步的标注结果,标注人员可以利用时间上下文清理标注结果。

图 B1:以肖像为中心的MovieNet人物注释示例。
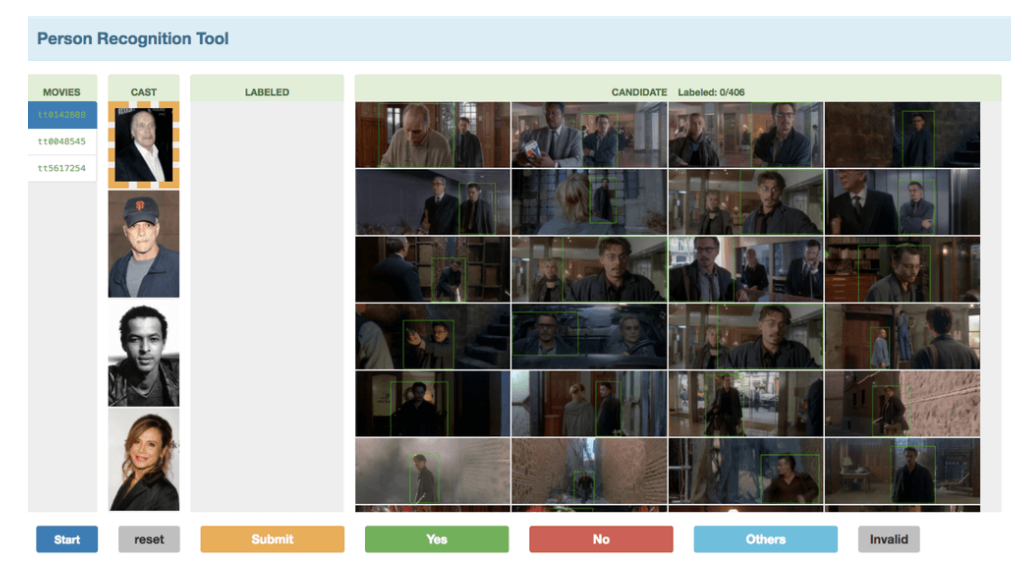
图 B2:角色身份注释界面(阶段 1)。从左到右,分别为:(1)电影列表,(2)所选电影的演员列表,通过演员的肖像显示,(3)已标注的样本,标记为所选演员,这将有助于标注更难的样本,(4)所选演员的候选人列表,由我们的算法生成,考虑了面部特征和身体特征。注释者可以标注正样本(点击"是")或负样本(点击"否")。经过几轮迭代,当他们熟悉电影中的所有演员时,可以通过点击"其他"来标注属于演员名单中的角色。
统计信息和样本
图B5展示了角色标注的部分统计信息,包括边界框的尺寸分布和实例数量分布。从统计信息可以看出,角色实例的数量呈长尾分布。然而,莱昂纳多·迪卡普里奥等著名演员的角色实例数量远多于其他演员。图B1也展示了部分样本,可以看出MovieNet包含大规模且多样化的角色,这将有助于角色分析研究。
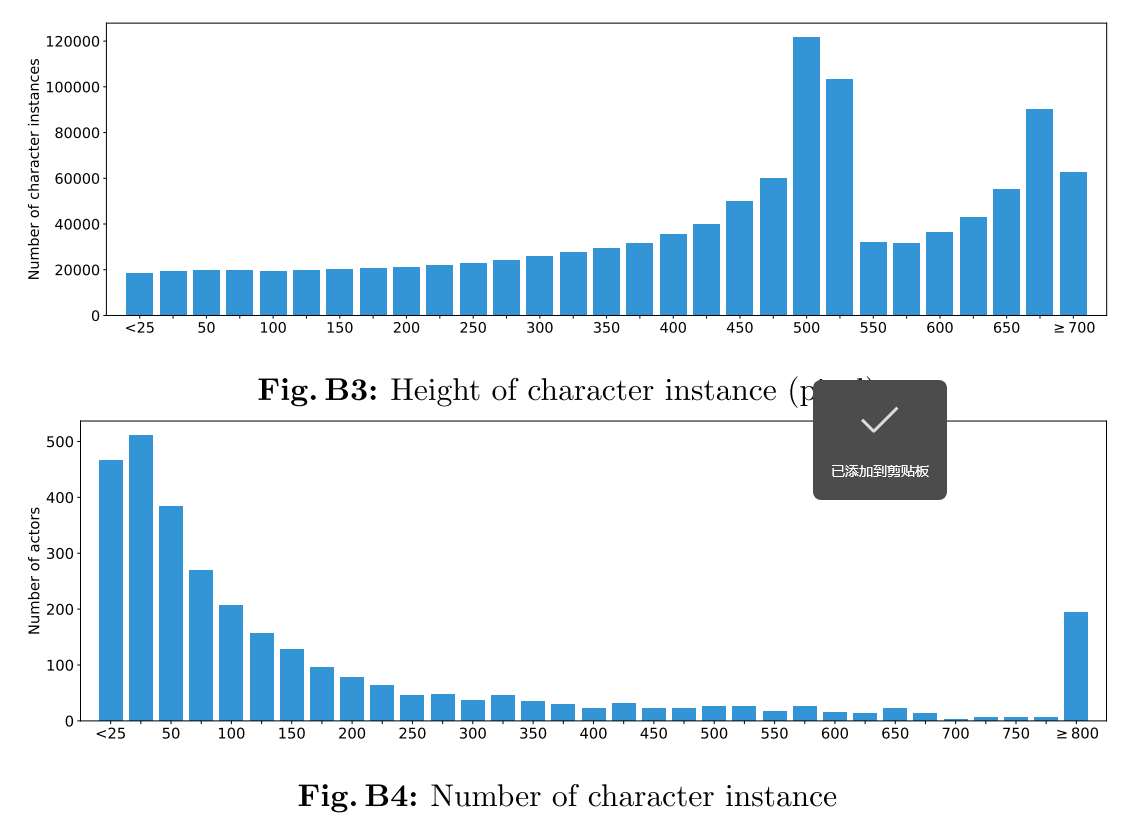
图 B5:角色边界框和身份注释的统计数据,包括角色实例的高度和角色实例的数量。
B.2 电影风格
我们标注了镜头中两种常用的电影风格标签26:视角尺度描述了镜头帧中主体的占比,镜头运动描述了摄像机的运动或镜头的变化。
视角尺度
视角尺度分为5类(如图B6所示):(1)极特写镜头:仅展示主体的极小部分(如人的眼睛或嘴巴);(2)特写镜头:聚焦于主体的相对较小部分(如人的面部或手部);(3)中景镜头:包含主体的一部分(如人的膝盖或腰部以上);(4)全景镜头:包含完整的主体;(5)远景镜头:从远距离拍摄,主体在帧中非常小。

图 B6:《碟中谍》中的镜头电影风格(画面比例类型)示例。从 (a) 到 (e),分别是极近景、特写镜头、中景镜头、全景镜头和远景镜头。

图 B7:《碟中谍》中的镜头电影风格(运动类型)示例。从 (a) 到 (d),分别是静态镜头、平移和俯仰镜头、远离镜头和拉近镜头。
镜头运动
镜头运动分为4类(如图B7所示):(1)静态镜头:摄像机固定,主体可自由移动;(2)摇移镜头:摄像机移动或旋转;(3)拉镜头:摄像机拉远;(4)推镜头:摄像机拉近。
 (注:原文图表链接此处以示例替代,实际翻译时需保留原图表引用格式)
(注:原文图表链接此处以示例替代,实际翻译时需保留原图表引用格式)
标注类别
与26中的定义相比,我们简化了电影风格类别,以降低标注成本,但确保简化后的类别足以满足大多数应用场景。例如,灯光等其他电影风格也是重要方面,但灯光的标准难以制定,目前我们正与电影专家合作开展相关工作。
标注流程
为确保标注质量,我们采取了以下措施:(1)不要求标注人员同时从电影或预告片中切割镜头并标注标签,而是使用现成方法62从电影和预告片中切割镜头,考虑到镜头检测问题已得到较好解决,这将减轻标注人员的负担;(2)所有标注人员都先接受电影专业人员的培训,通过专业测试后才能进行标注。他们使用我们的基于网络的标注工具(如图B8所示),每个任务标注三次,以确保高标注一致性。
(注:原文图表链接此处以示例替代,实际翻译时需保留原图表引用格式)
样本
我们在《碟中谍》这部电影中展示了每种视角尺度类别的五个样本(如图B6所示):极特写镜头揭示角色或物体的详细信息;特写镜头展示角色的面部和情绪;中景镜头呈现角色参与的活动;远景镜头展示角色或物体的场景设置;全景镜头展示电影的景观环境。此外,还展示了不同运动类型镜头的四个示例(如图B7所示)。
B.3 场景边界
标注流程
为提高标注效率和标签质量,我们提出了以下标注策略:如果要求标注人员逐帧浏览电影,工作量将非常庞大。在本研究中,我们采用基于镜头的方法,基于镜头是某个场景的一部分这一观察。因此,我们将场景视为连续的镜头序列,场景边界可从镜头边界中选择。此外,镜头检测作为一项任务已得到较好解决。具体而言,对于每部电影,首先使用现成方法62将其分割成镜头,这种基于镜头的方法极大地简化并加快了标注过程。
标注界面
我们还开发了基于网络的标注工具(如图B9所示),方便人工标注人员判断两个连续镜头之间是否存在场景转换。在网络用户界面上,标注人员可以观看位于中心的两个镜头,以及分别位于左侧和右侧的这两个镜头的前序帧和后序帧。观看两个镜头后,标注人员需要判断它们是否属于不同的场景,前序帧和后序帧也能提供有用的上下文信息。
(注:原文图表链接此处以示例替代,实际翻译时需保留原图表引用格式)
标注质量
一部电影通常包含1000到2000个镜头,标注人员标注整部电影大约需要1小时,这可能导致注意力难以集中。为缓解这一问题,我们将每部电影分割成3到5个片段(带有重叠部分),每个片段包含约500到700个镜头,标注一个片段仅需约15分钟。我们发现,标注人员标注片段时比标注整部电影更容易集中注意力。所有标注人员在开始标注任务前,都接受了培训,学习如何使用标注工具以及如何处理各种模糊情况。我们要求标注人员在每两个镜头之间做出谨慎判断,如果标注人员对某些情况不确定,可以选择"不确定"并跳过。标注过程分为两轮:第一轮,将电影的每个片段分配给三名独立的标注人员,以检查一致性;第二轮,将标注不一致的结果(即三名标注人员的意见不统一)重新分配给两名额外的标注人员,此时每个片段将获得五个标注结果。
样本
图B10展示了两个场景边界的示例。场景分割具有挑战性,因为仅依靠视觉线索不足以识别场景边界。例如,在第一部电影《航班》的第84到89场景,以及第二部电影《大梦想家》的第123到124场景中,大多数帧看起来非常相似,需要角色、动作、音频等额外的语义信息才能做出正确预测。不同场景的分割难度不同,也存在一些简单情况(例如第122和123场景之间的边界,由于视觉变化明显,容易识别)。
(注:原文图表链接此处以示例替代,实际翻译时需保留原图表引用格式)
B.4 动作和地点标签
本节介绍MovieNet中动作和地点标签的标注流程。我们开发了一个界面,用于联合标注动作和地点标签,以下详细介绍相关流程和界面。
标注流程
我们根据场景边界将每部电影分割成片段,每个场景视频时长约2分钟。我们为每个片段人工标注地点和动作标签:对于地点标注,每个片段会被赋予多个地点标签(如甲板、船舱),涵盖该视频中出现的所有地点;对于动作标注,要求标注人员首先检测包含人物和动作的子片段(标注覆盖连续人类动作的边界),然后为每个子片段分配多个动作标签,描述其中的动作
B.5 剧情简介对齐
为了支持电影片段检索任务,我们手动将电影片段与剧情概要段落关联。在本节中,我们将介绍电影-剧情概要对齐的以下细节,包括注释界面和工作流程。
注释工作流程。在从 IMDb 收集剧情概要后,我们进一步筛选出高质量的概要,即那些包含超过 50 个句子的概要,进行注释。然后,我们开发了一个粗到精的程序,有效地将每个段落与其对应的片段对齐。(1)在粗略阶段,每部电影被划分为 N 个片段,每个片段持续几分钟。这里我们设置 N = 64。对于每个剧情概要段落,我们要求注释者选择 K 个连续的片段,涵盖整个剧情概要段落的内容。(2)在精细阶段,注释者需要细化边界,使得结果片段与剧情概要段落更好地对齐。
为了确保注释质量,我们做了以下努力:(1)来自同一部电影的剧情概要段落将分配给同一位注释者。为了确保他们熟悉电影,我们向注释者提供了电影的详细概述,包括角色列表、剧情、评论等。(2)每个剧情概要段落会分配给 3 位注释者。然后,我们只保留那些一致性较高的注释,即那些在所有 3 次注释中具有高时间交并比(IoU)的注释。最终,获得了 4208 对段落-片段配对。
注释界面。电影-剧情概要对齐是通过粗到精的方式收集的,如图 B16 所示。我们开发了一个在线界面来进行这两个阶段的工作。粗略阶段的界面如图 B17 所示。在开始注释每部电影时,注释者需要浏览该电影的概述,概述可以在菜单栏中的"MOVIE INFO"和"SYN PREVIEW"中查看。然后,注释者选择一段连续的 N 个片段,涵盖文本面板中显示的对应剧情概要描述。在收到注释后,后端服务器会将这些连续片段合并为一个完整的片段进入精细阶段。如图 B18 所示,在精细阶段,注释者调整结果片段的时间边界。我们允许注释者在当前播放位置设置时间戳作为开始或结束时间戳。为了便于精细调整,用户可以通过最小步长 0.1 秒前进或后退来控制视频播放器。