目录
- [1. 引言](#1. 引言)
- [2. GPU流水线的基本构成](#2. GPU流水线的基本构成)
-
- [2.1 SIMT前端](#2.1 SIMT前端)
- [2.2 SIMD后端](#2.2 SIMD后端)
- [3. GPU流水线的工作原理](#3. GPU流水线的工作原理)
-
- [3.1 取指阶段](#3.1 取指阶段)
- [3.2 译码阶段](#3.2 译码阶段)
-
- [3.2.1 GPU流水线的数据冒险](#3.2.1 GPU流水线的数据冒险)
- [3.2.2 GPU流水线的结构冒险](#3.2.2 GPU流水线的结构冒险)
- [3.2.3 GPU流水线的控制冒险](#3.2.3 GPU流水线的控制冒险)
- [3.3 发射阶段](#3.3 发射阶段)
- [3.4 执行阶段](#3.4 执行阶段)
-
- [3.4.1 执行阶段的模块设计](#3.4.1 执行阶段的模块设计)
- [3.4.2 问题收集与处理](#3.4.2 问题收集与处理)
- [3.5 写回阶段](#3.5 写回阶段)
-
- [3.5.1 写回阶段的模块设计](#3.5.1 写回阶段的模块设计)
- [3.5.2 板块冲突](#3.5.2 板块冲突)
- [4. 参考文献 & 后记](#4. 参考文献 & 后记)
-
- [4.1 参考文件](#4.1 参考文件)
- [4.2 后记](#4.2 后记)
1. 引言
大概两年前,我曾分享过一篇 CPU 指令流水线的全面解析,和大家一起拆解了 CPU 通过流水线技术提升指令执行效率的底层逻辑(CPU流水线技术全面解读)。而近几年,AI 技术迅速崛起,其原因,除了各类创新神经网络架构的持续突破,高性能的 AI 计算平台更是成为了背后的有力支撑。GPU 作为 AI 并行计算的核心载体,其流水线的设计逻辑与运行机制,直接决定了 AI 模型的运算效率与落地能力,深入理解 GPU 流水线,也成为吃透 AI 模型底层运行原理的关键一环。
2. GPU流水线的基本构成
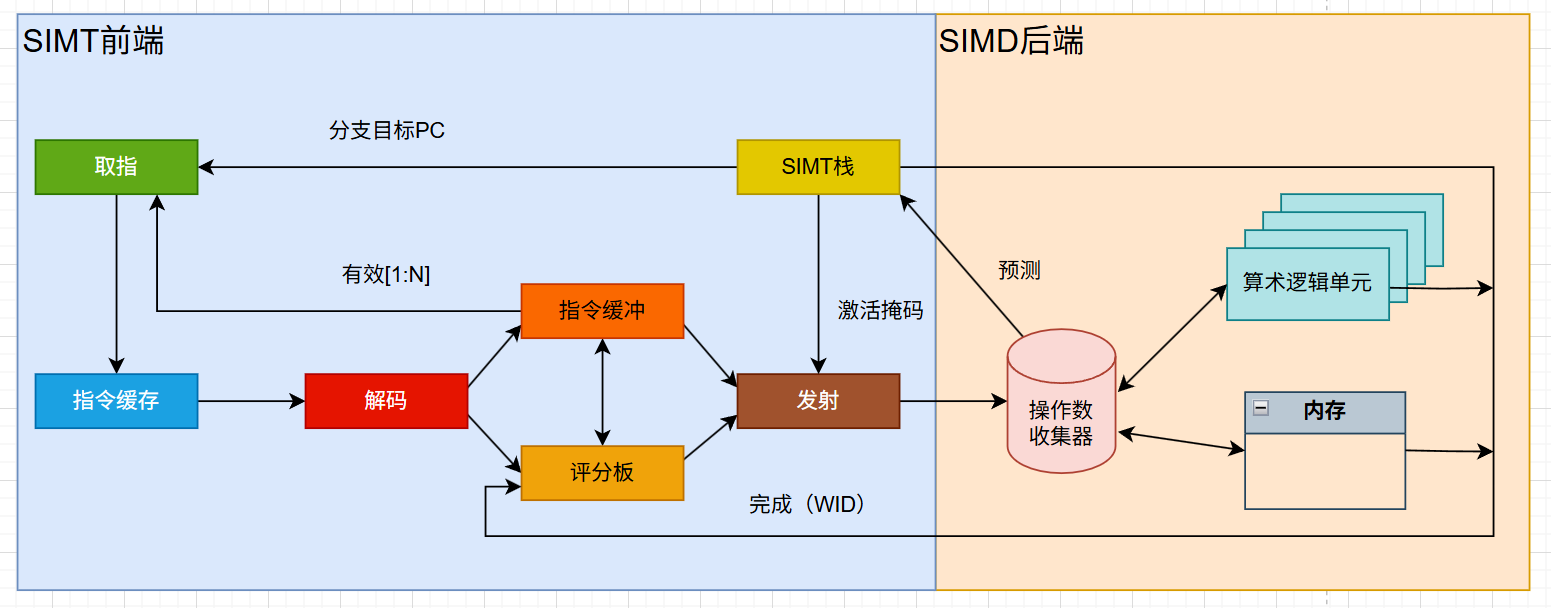
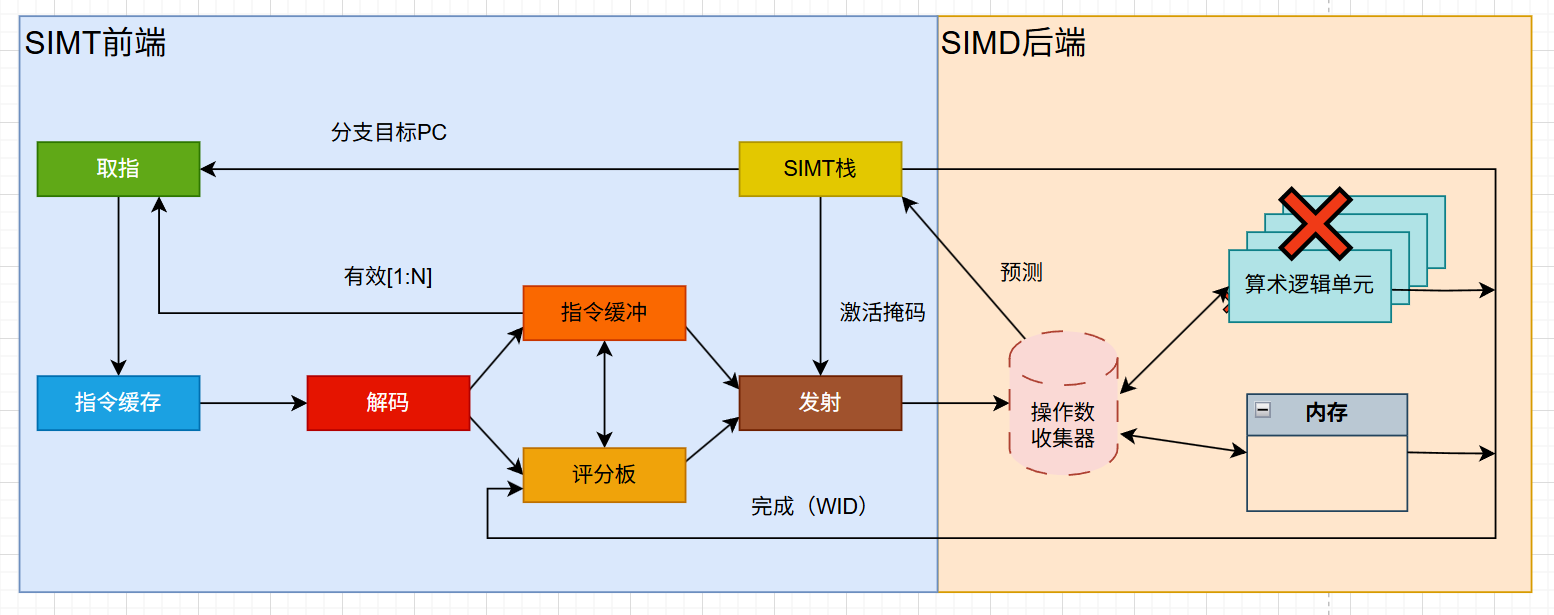
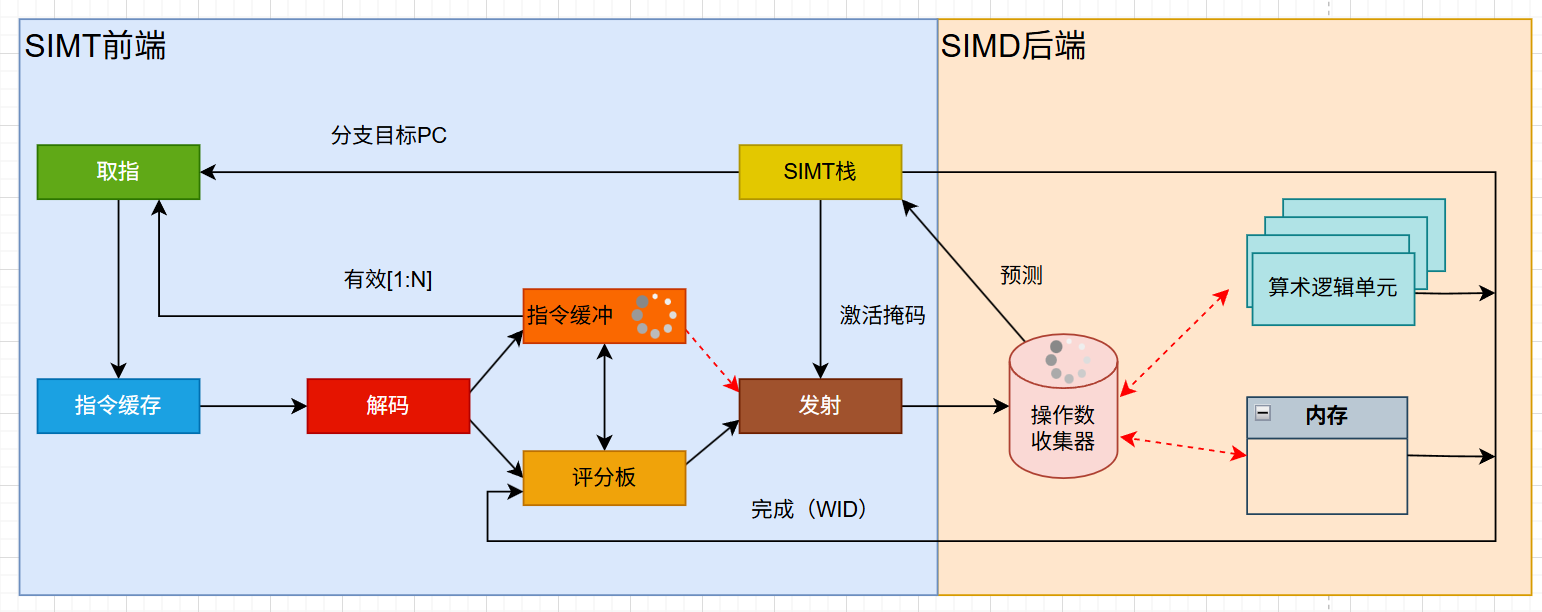
如图所示,GPU的指令流水线包含了一个SIMT(单指令多线程)前端和一个SIMD(单指令多数据)后端。具体包含了取指、译码、发射、执行、写回5个阶段(超流水线结构)。
2.1 SIMT前端
在流水线前端,每个线程都有自己的控制流。程序可能在某些线程上执行if分支,而在其他线程上执行else分支。但同一线程束,所有线程都会执行相同的指令,并根据需要进行masked。这种模式允许GPU以线程为中心的方式进行编程。
2.2 SIMD后端
线程传递到后端的执行阶段,各种计算单元就会对数据进行操作,流水线变得很像一个传统的SIMD。在这个阶段,一组线程(一个线程束)会执行相同的操作,但是会作用于不同的数据上。此时可看作纯粹的数据并行处理。
这种设计允许开发者以线程为中心进行编程,而硬件可以以数据为中心的方式优化执行,从而最大限度地提高吞吐量。
3. GPU流水线的工作原理
3.1 取指阶段
与CPU类似,为了提高取指的效率,GPU也有指令缓存。指令缓存是GPU的第一个调度部分。当指令被取出时,首选会判断这些指令是否已经在指令缓存中了。如果是,则指令会直接在本地取出并送入下一个阶段。
💥在取指之前,流水线如何知道自己到底需要取哪条指令呢?
GPU当然不知道下一个指令是什么?只能通过PC指针确定即将处理的指令地址(如果不是顺序结构,一般需要进行分支预测)。比如GPU要处理一个最常见的神经网络卷积 + BN + ReLU计算,当前指令缓存中的内容如下:
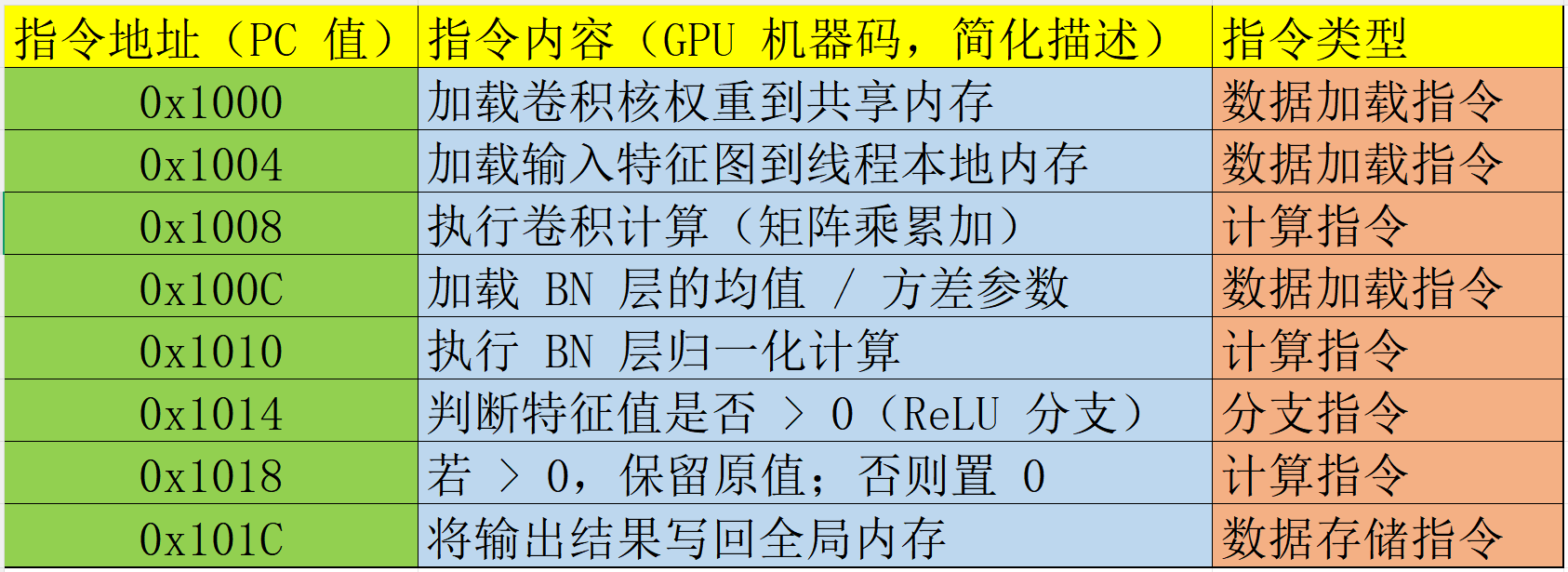
假设 GPU 第一次执行这段代码,指令缓存是空的:
拿着 0x1000 查缓存 → ❌ 未命中。
硬件会去 GPU 的 L2 缓存 / 显存里,读取包含 0x1000 的一整块指令(比如连续 8 条),填到指令缓存里。
下次再取 0x1000、0x1004 等地址时,就直接命中缓存命中✅️了。
如果遇到以下情况(时间局部性+空间局部性),指令缓存的优势将有可能进一步凸显(会受到缓存大小 以及缓存更新策略等因素影响,常见的更新策略是最近最久未使用):
- 循环结构
- 分支结构(if/else/switch)
- 反复调用的函数
取指后的指令被送入译码阶段,这时候,指令将被译码为可以由执行单元理解和执行的未操作。
当某些线程在线程束内选择了不同的执行路径时,线程束的执行可能会串行,也就是先执行一条路径,然后执行另一条路径,这种情况被成为线程分歧。
3.2 译码阶段
无论是CPU还是GPU,译码阶段的设计哲学都是一致的,都是为了将指令从一种形式转换为另一种形式。但也有些许不同。
-
CPU:作为通用处理器,可以运行各种应用程序和操作系统,指令集非常丰富,包括各种复杂的指令。译码阶段会涉及多种长度和复杂度的指令。
-
GPU:转为图形和大规模并行任务设计,指令集更为简洁。译码阶段更为简单和统一。
以英伟达平台为例,译码阶段在翻译SASS指令,而非PTX。
一旦指令被译码,通常会被保存在指令缓冲区中,等待被取出并执行。每个指令条目一般包含一条译码后的指令和两个标记位,一个有效位和一个就绪位。
- 🌍有效位:当前指令是否已经译码但尚未发送到执行单元的有效指令。如果为1,则指令有效,否则无效。
- 🌍就绪位:当前指令是否已经准备好被发送到执行单元。如果为1,则可以被发送,否则,还有一些前置条件或依赖性尚未被满足。
有效位和就绪位保存在流水线的什么地方呢?
有效位(Valid)和就绪位(Ready)是分开管理的,有效位 归指令缓冲管,就绪位 属于评分板。
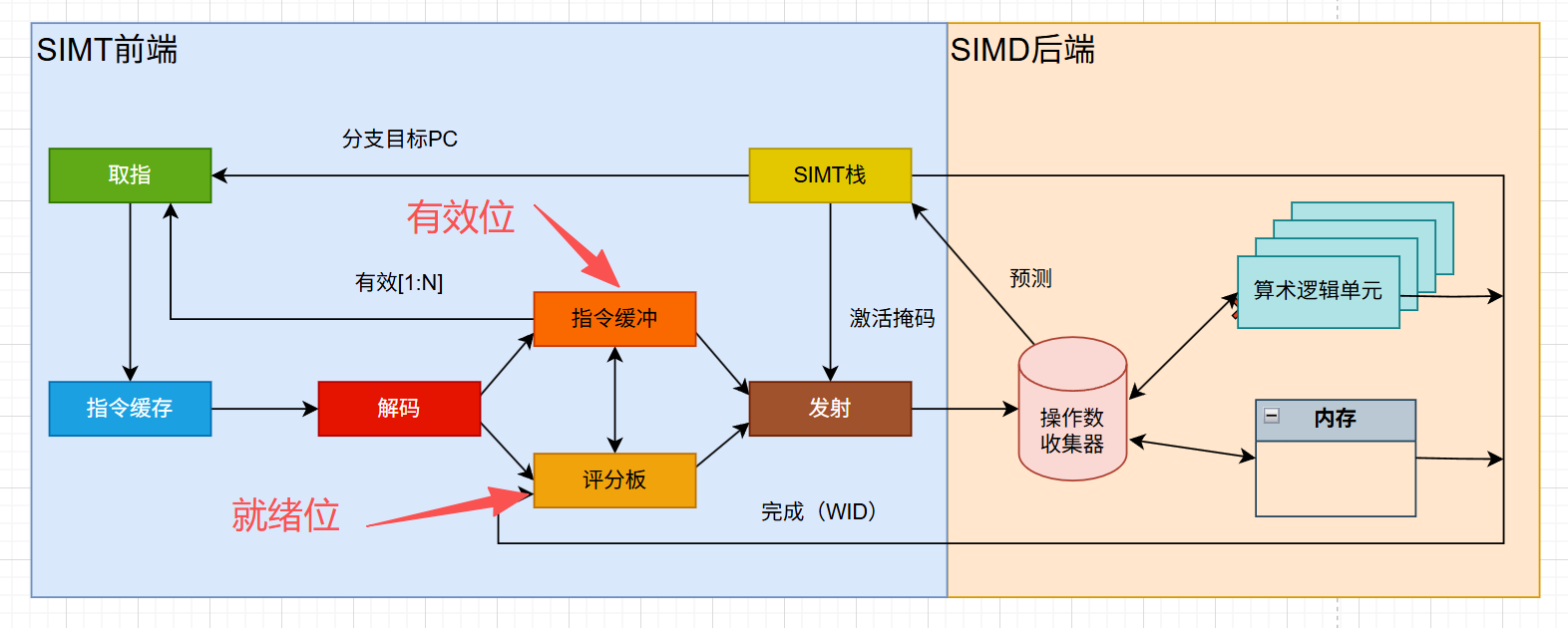
有效位很好理解,当前指令已经被顺利译码,且指令缓冲的相关单元是有东西的,不是空的。
就绪位取决于很多因素。最常见的因素是流水线冒险,包含了数据冒险,控制冒险和结构冒险(关于这3类冒险的详细解释,请参考我以前的帖子:CPU流水线技术全面解读)。也就是说,如果发生了流水线冒险,就绪位会置0,表示当前指令尚未准备好。
- 数据冒险:数据没等到 → 就绪失败
- 结构冒险:硬件抢不到 → 就绪失败
- 控制冒险:分支没确定 → 就绪失败
3.2.1 GPU流水线的数据冒险
🍉数据冒险的触发场景:指令需要的寄存器 / 数据还没写回,比如:
上一条指令的结果还在 ALU 里,没写到寄存器堆
Load 指令的数据还在从内存 / 缓存回来的路上
也就是说,操作数还没有准备好。操作数收集器在等数据(当前指令执行所需要的输入操作数),导致发射被卡住。
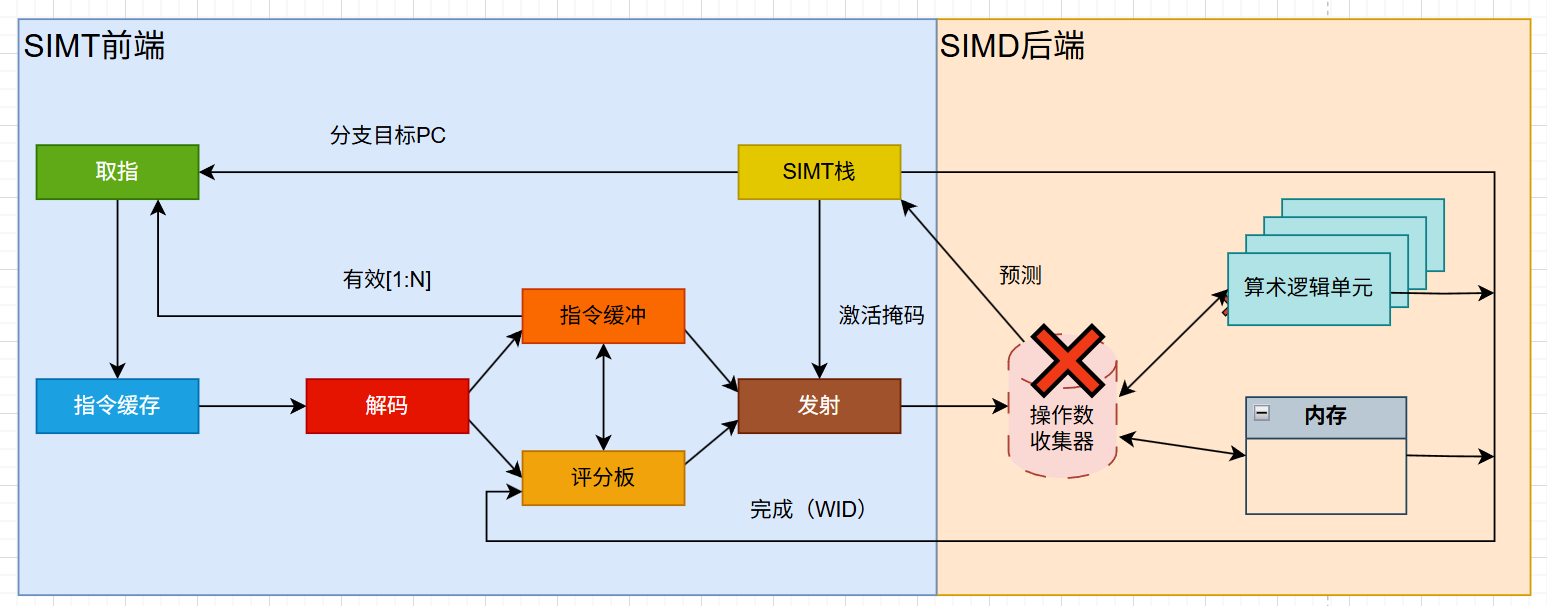
比如:
指令 1:FMA R0, R1, R2(在 ALU 里算)
指令 2:ADD R3, R0, R4(要用到 R0)
但此时,如果指令1的数据尚未写回到寄存器R0中,操作数收集器就会一直等数据,导致数据数据冒险。
🚩GPU的数据冒险与CPU还是有较大区别的,CPU的数据冒险往往发生在,本次计算算需要等到上次的计算结果。而GPU除了这种情况,还面临另外一种情况,即使不用等待上次的运算结果,数据也不能保证每次都按时保运到指定位置,因为GPU作为典型的并行计算平台,每次计算所需的数据远远大于CPU。
3.2.2 GPU流水线的结构冒险
🍉结构冒险的触发场景:硬件资源是有限的,但并行请求是无限的。当硬件资源访问冲突时,就会触发结构冒险。
在 GPU 里,"资源" 不只是 ALU,还包括:
🔰执行端口(ALU、Load/Store、Tensor Core 等)
🔰寄存器堆端口
🔰共享内存 bank
🔰缓存端口
🔰发射队列槽位
只要同一周期内,多个指令 / 线程束想抢同一种资源,就会触发结构冒险 → Ready=0,发射被阻塞。
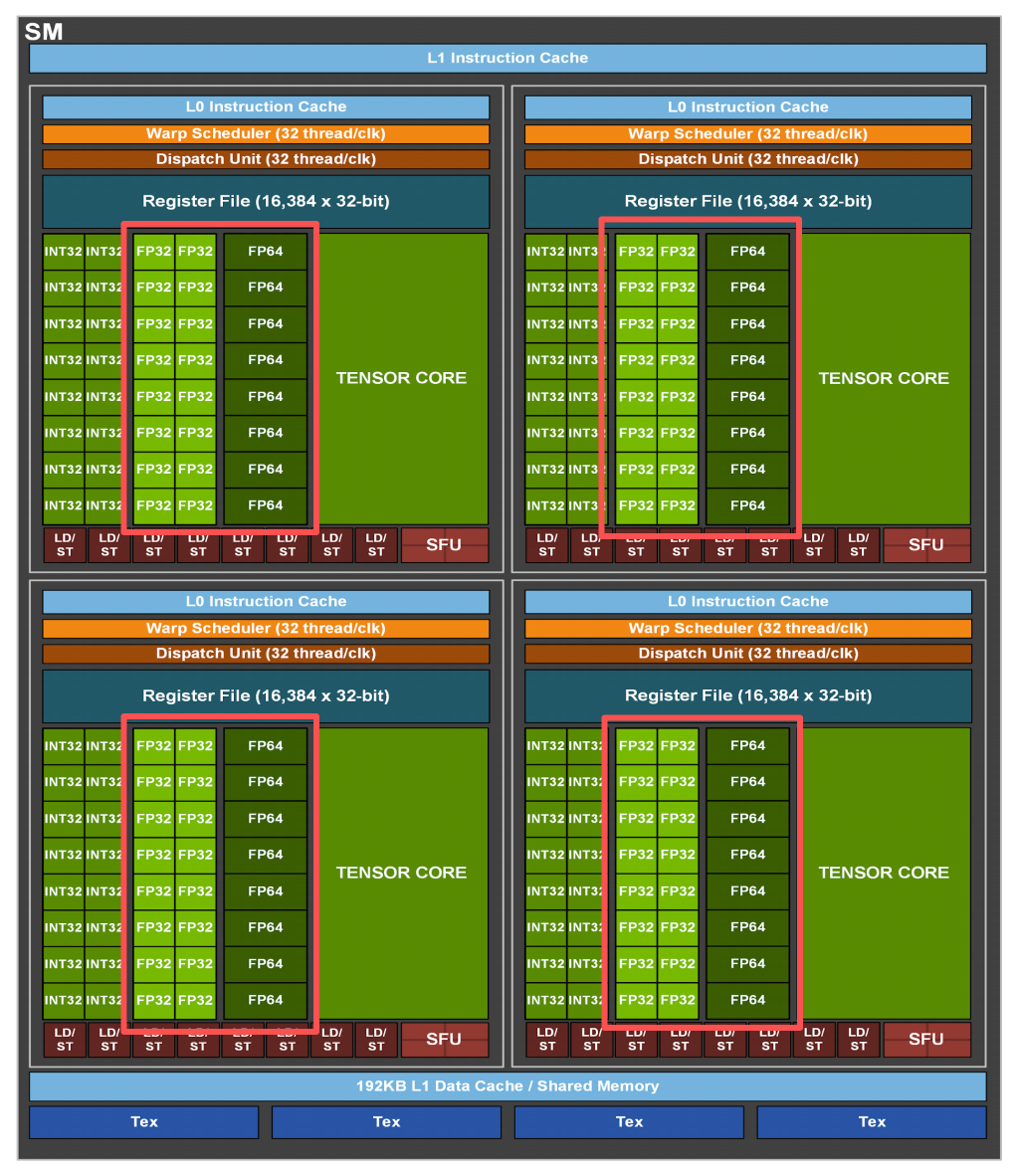
具体的触发场景有以下几种(英伟达安培架构为例):
-
执行单元竞争
场景:一个 SM 里只有 4 个 FP32 ALU,但同一周期有 8 条浮点指令要发射
结果:前 4 条能进 ALU,后 4 条必须等下一个周期 → 结构冒险
对应到图里:发射单元发现 ALU 全忙,指令只能留在指令缓冲里等
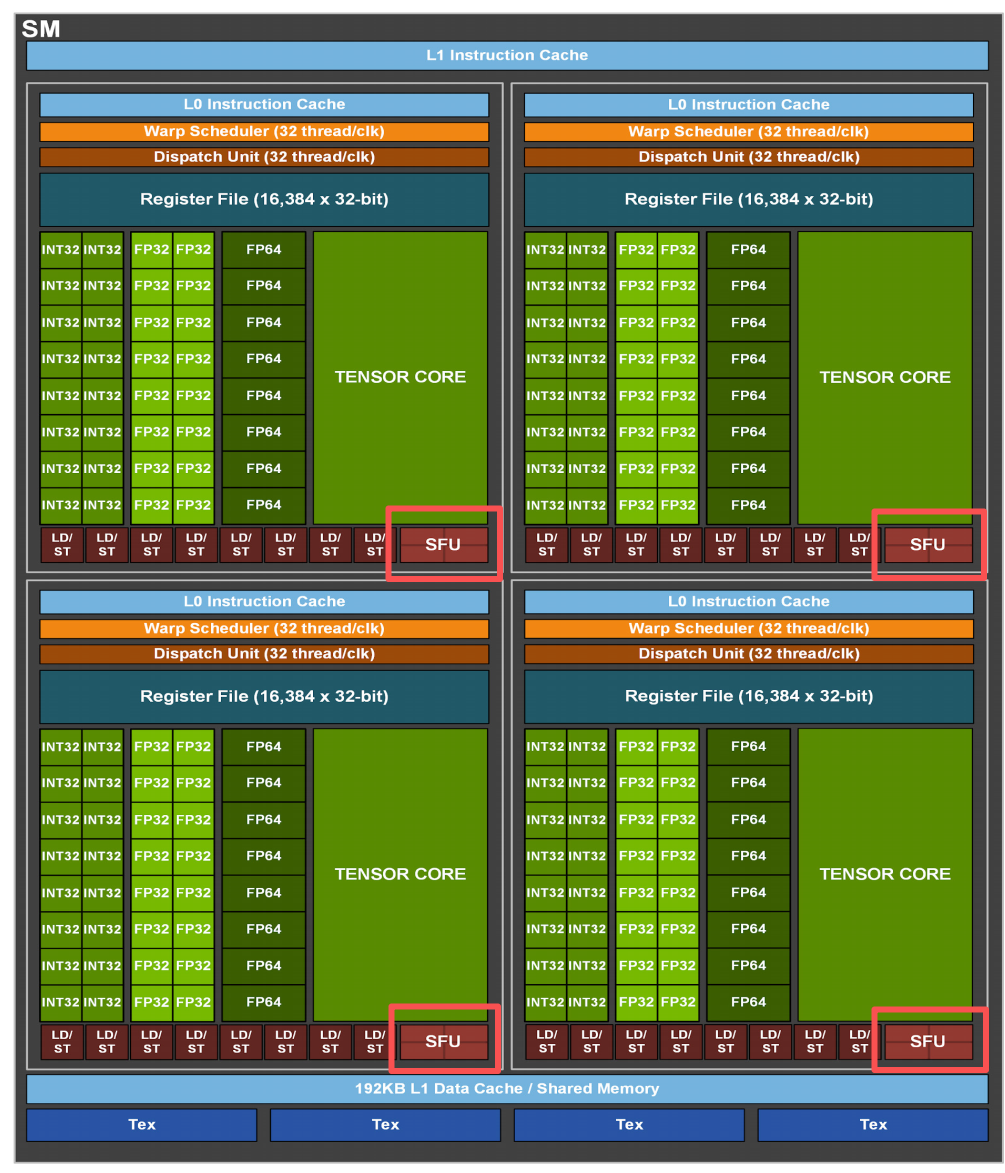
-
特殊功能单元竞争(SFU)
场景:多条指令同时需要用 Tensor Core / 除法单元 / 三角函数单元
结果:这类单元数量更少,竞争更激烈,阻塞更久
-
内存端口竞争
场景:大量 Load/Store 指令同时访问 L1 Cache / 共享内存
结果:内存端口被占满,后续访存指令必须排队 → 也算结构冒险
表现:操作数收集器等内存数据,但本质是内存硬件资源不够,不是数据没到
-
寄存器堆端口竞争
场景:一个周期内,多条指令同时读 / 写寄存器
结果:寄存器堆读 / 写端口数有限,超出就阻塞 → 结构冒险
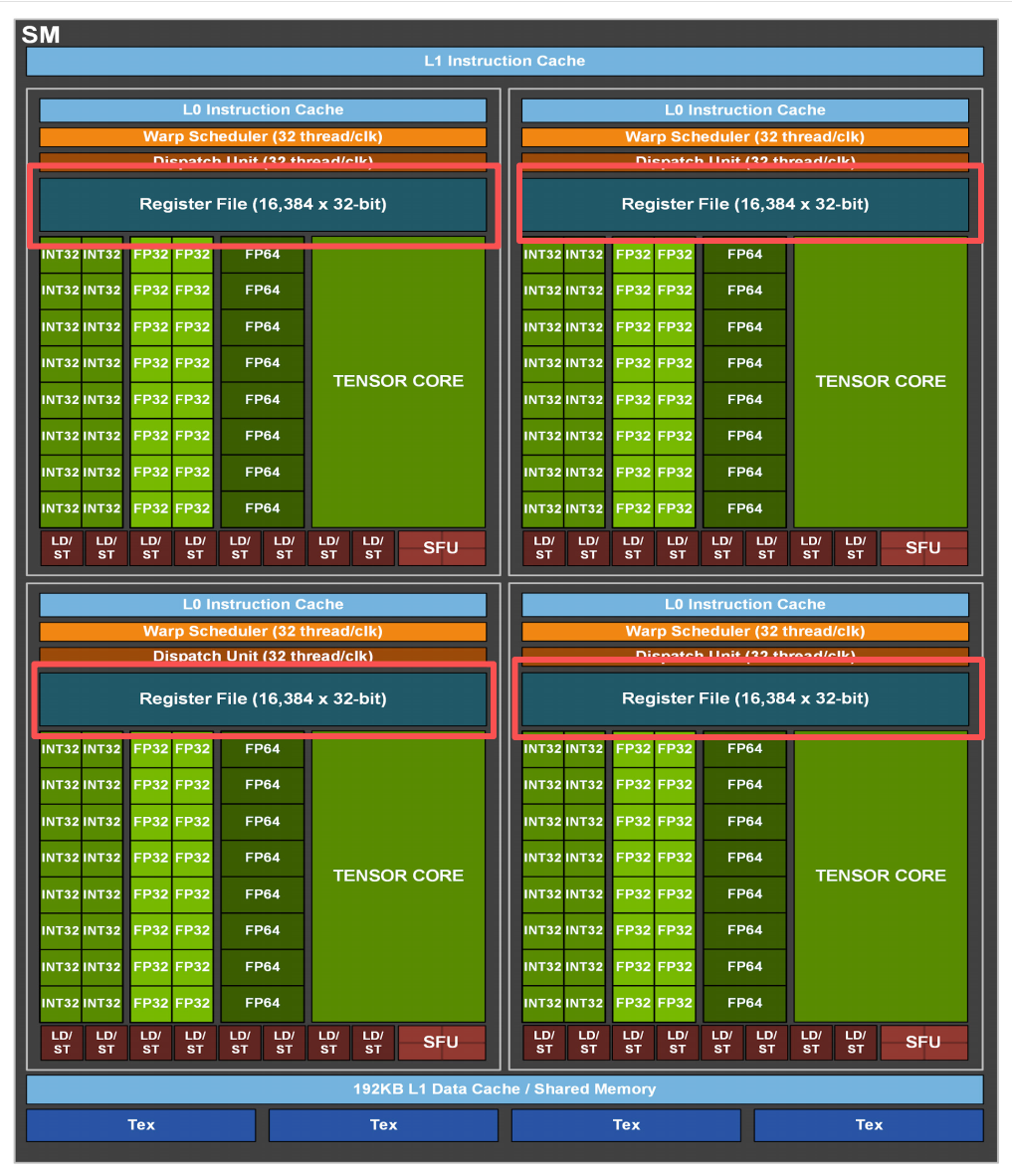
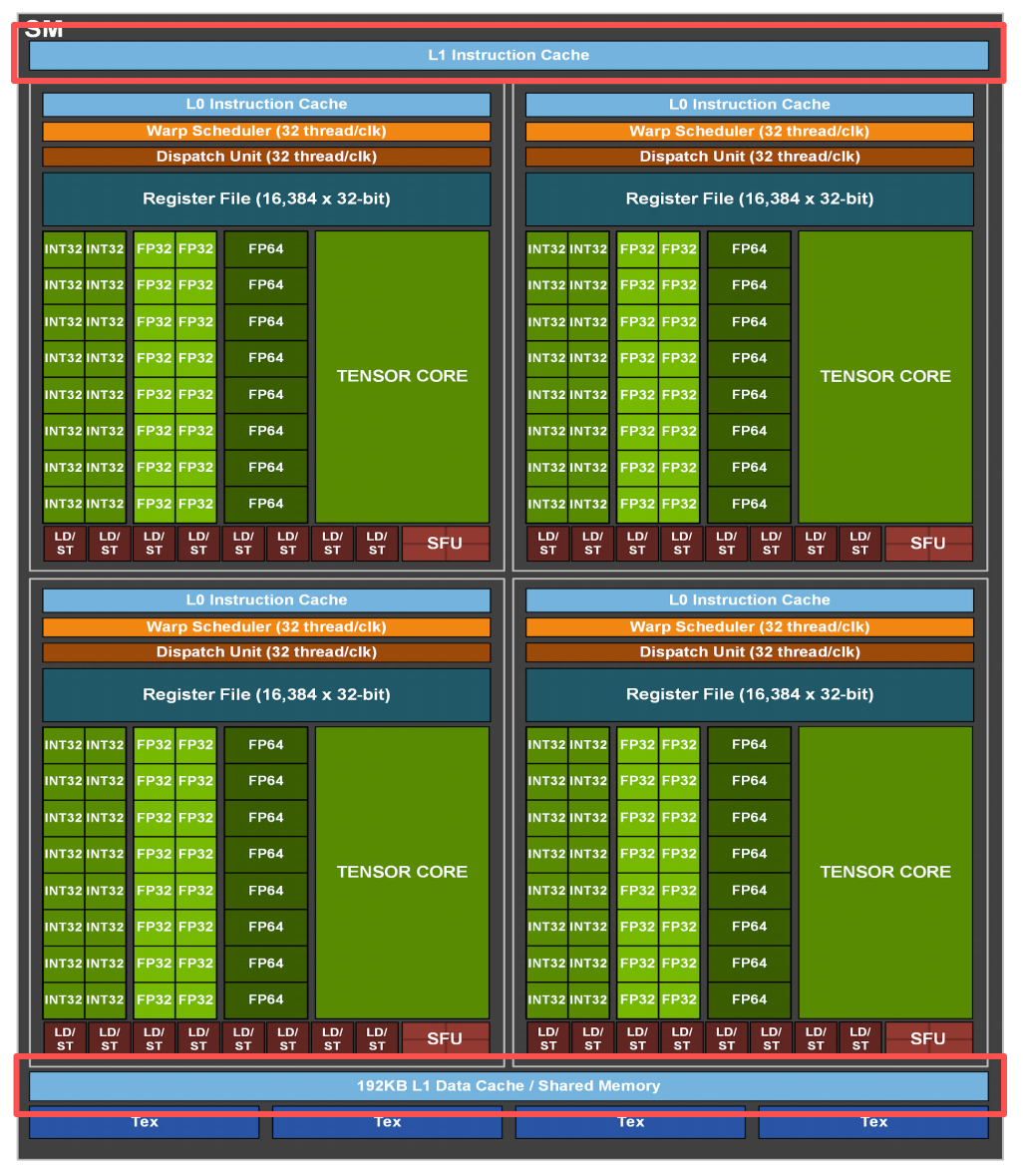
当然,从上面SM的硬件架构图上来看,显然还会有其他情况的结构冒险,比方说,张量核心(Tensor Core)、纹理缓存(Tex)等的资源抢占。
3.2.3 GPU流水线的控制冒险
🍉控制冒险发生在取指 (Fetch)阶段,源头是分支目标 PC (Branch Target PC)不确定。
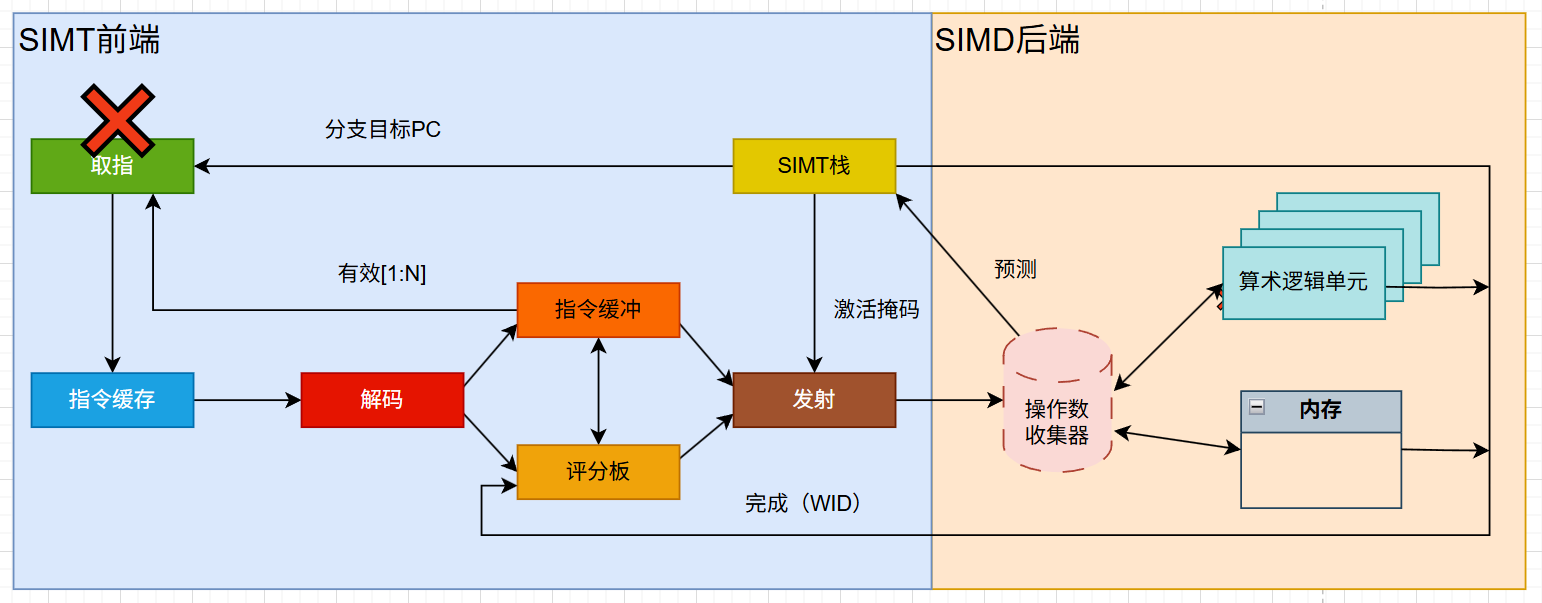
👉处理机制:
- CPU:在译码 / 执行阶段才算出地址,流水线排空,重填。
- GPU:指令送到 SIMT 栈,结合 激活掩码 (Active Mask) 判定分支走向。预测 (Prediction):硬件做分支预测(比如总是预测不跳转)。预测错误:取指单元 取到的是错误的指令(Valid=0 或废弃),整个流水线需要冲刷掉这部分错误指令。代价:切换到正确的分支目标 PC,重新取指。
🚩GPU 的控制冒险处理方式与 CPU 最大的不同在于:GPU 不依赖复杂的乱序执行来消除气泡,而是利用 SIMT 架构,通过「激活掩码 (Active Mask)」屏蔽掉分支预测错误的线程,让其他活跃的 Warp 继续填充流水线,从而以极高的并行度来 "隐藏" 控制冒险带来的延迟,而非消除延迟。
3.3 发射阶段
译码后的指令将会送往GPU庞大的执行单元。指令应该被送往什么单元,以及各单元目前是否能接收新的指令,以及指令是否存在相关关系(数据依赖),都是发射单元要考虑的。
可以发现,GPU的指令发射单元比CPU要复杂,CPU顶多是ALU,或者外加一个FPU,而GPU则不同,为了提升数据的并行性,存在多个,且多种数据处理单元,包括CUDA核,张量核,SFU等,发射阶段不仅仅要考虑发射什么指令,还要考虑往什么地方发。
指令的发射在GPU中更多地被称为调度过程,大致可以划分为以下几个环节。
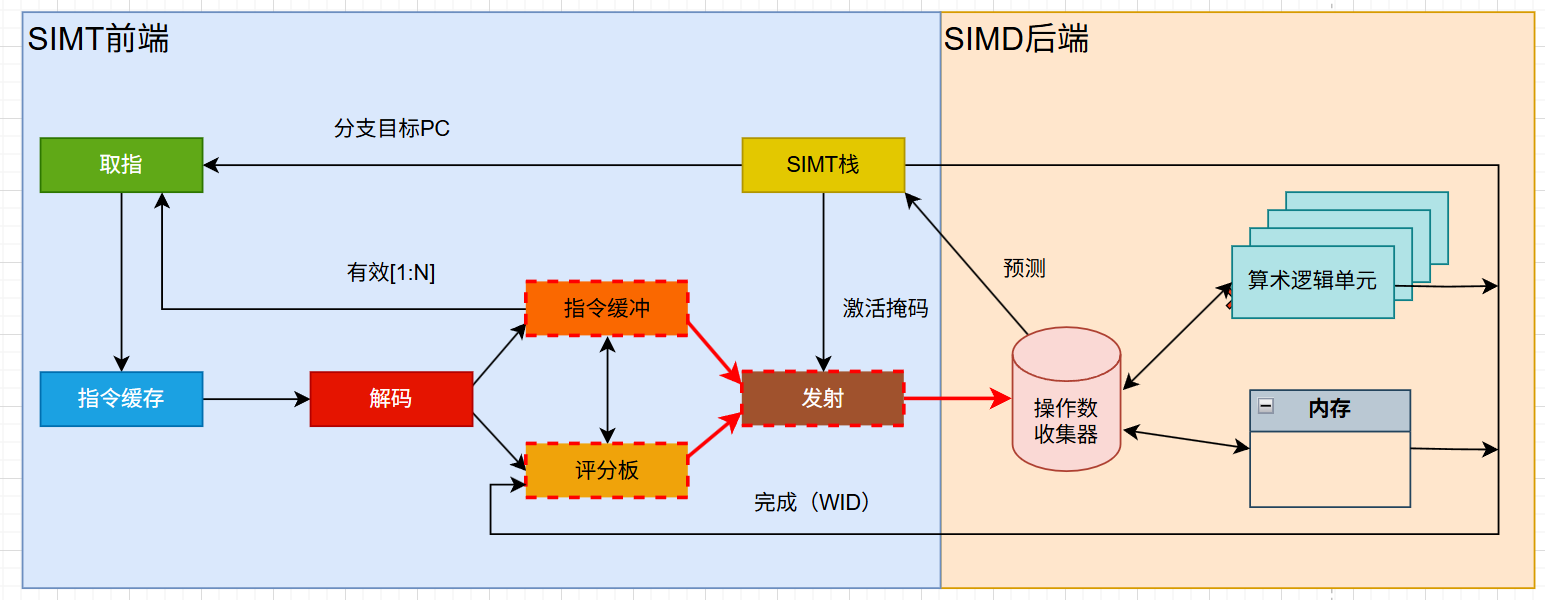
- 读取指令:调度单元从指令缓冲中读取指令。这些指令已经被译码并准备好发射。
- 检查依赖性:调度单元需要确保没有数据依赖性,即一条指令不依赖于另一条尚未完成的指令的结果。
- 检查资源可用性:检查必要的计算单元、寄存器或者其他需要用的资源是否可用。
- 分发指令:将指令发送的对用的物理单元。比方说将普通算术指令发送到CUDA核,将矩阵运算指令发送到张量核,将访存相关指令被发送到内存访问单元或者缓存系统等等。
- 选择线程或线程束:选择一个线程束执行指令,GPU中,一般有多个线程束可供选择。线程束的选择基于多种因素,如线程束优先级、资源需求或其在流水线中的位置。
检查依赖性,是为了规避数据冒险,而检查资源可用性,是为了规避结构冒险。
发射调度器是GPU的第二个调度部分,功能是从指令缓冲中选择一个线程束发射到后续流水线中。与取指调度器相互独立,调度方式是循环优先级策略(不同线程束)。发射调度器可以进行配置,每个时钟周期从同一个线程束中发射多条指令。
3.4 执行阶段
GPU流水线进入执行阶段后,运行流程如下:
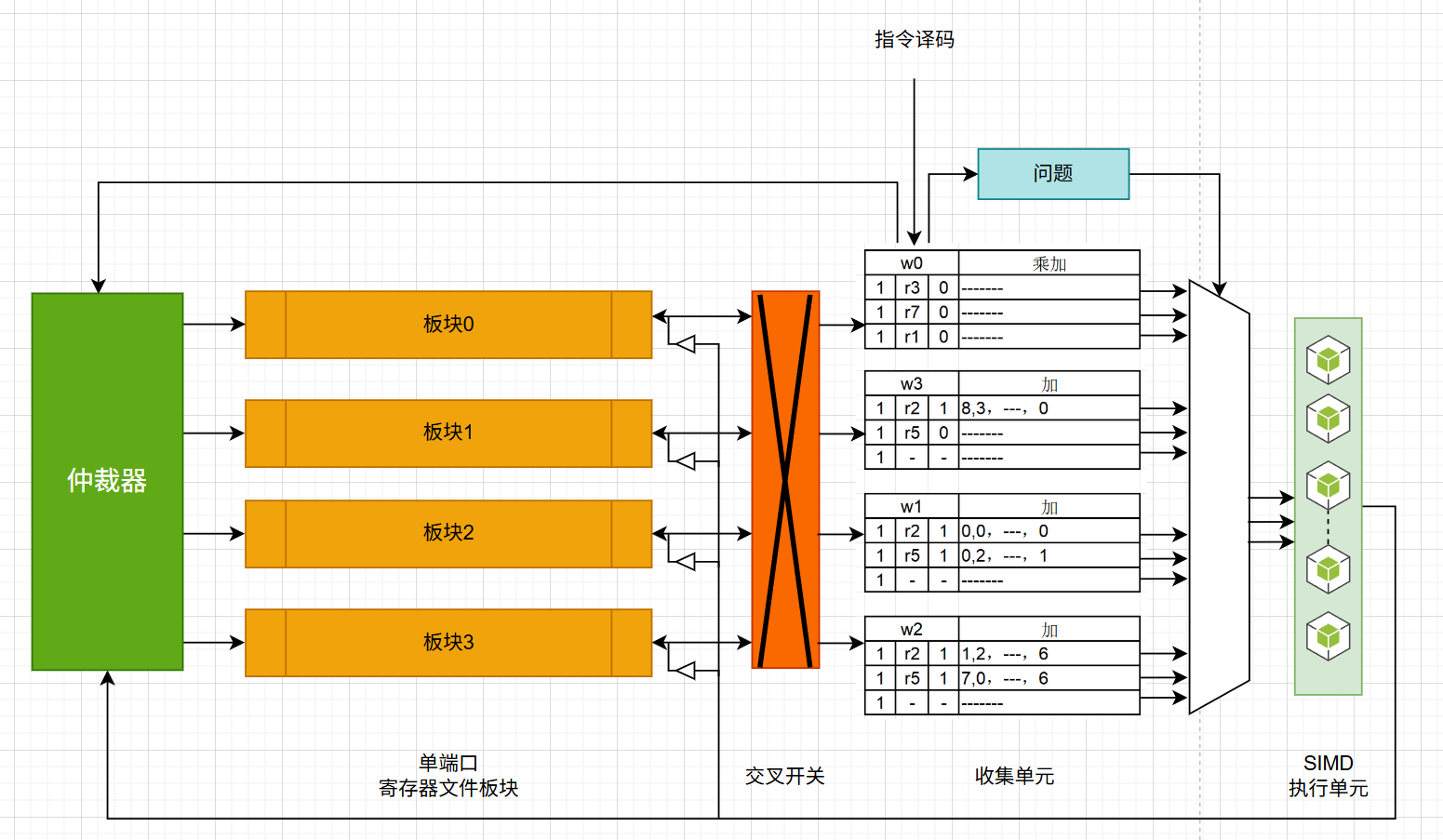
3.4.1 执行阶段的模块设计
- 仲裁器:仲裁器的主要作用是在多条可能的指令中选择一条执行(基于优先级,或者轮转等策略)。在GPU中,由于高度并行的特性,可能有多条指令或者线程束等待执行。
- 单端口寄存器文件板块 :用于存储线程的局部数据。单端口(Signle-Ported)的意思是,在任何时刻,每个板块只允许执行一个读操作或者一个写操作。这与多端口的寄存器不同,后者允许同时执行多个操作。
- 交叉开关:交叉开关提供了一个多对多的数据交换通道。在GPU上下文中,它可以使多个操作数收集单元从多个寄存器文件板块中读取数据。其可以在不产生冲突的情况下高效地处理多个并发请求。
- 收集单元 :负责从寄存器文件中收集所需的操作数。为每条指令提供一个缓冲区,用于存储所需的所有操作数。这确保了即使出现了板块冲突或者其他延迟,指令的执行也不会受阻。操作数收集这个过程涉及检查数据是否就绪、处理数据依赖及确保数据在需要时被取出和使用。为了提高性能,GPU可能采用多种技术,如乱序执行、寄存器重命名等,以确保在等待数据时可以执行其他指令。
- SIMD执行单元:这个前面已经提过很多次了,比方说什么CUDA核心,张量核心,SFU等。
🔑工作流程如下:
首先由仲裁器决定哪一条指令应该被执行。选定的指令由收集单元开始,从单端口寄存器文件板块中收集所需的操作数。这可能需要多个时钟周期,因为可能会遇到板块冲突。为了从多个寄存器文件板块向多个收集单元传输数据,采用了交叉开关。一旦收集单元收集了指令所需的所有操作数,该指令就会被发送给执行单元进行处理。
指令被译码了,那究竟被"翻译"成了什么呢?看很多的书籍,都会告诉我们,变成了微操作,那么微操作是个什么概念呢?
指令变成了三类东西:
- 微操作(决定执行什么)
- 寄存器地址(决定读哪里)
- 控制信号(决定硬件怎么走)
执行阶段看到的全是数据流动,但每一步数据流动,都被译码后的指令控制着。从这个角度说,"指令变成了微操作"这个说法并不严谨。
3.4.2 问题收集与处理
发现问题的主体:收集单元 + 评分板 + 地址生成单元
数据依赖问题 → 评分板(操作数未就绪)
板块冲突问题 → 收集单元(寄存器 Bank 端口竞争)
结构冒险问题 → 仲裁器 / 收集单元(执行单元端口被占满)
反馈路径:这些模块把"问题"信号,汇总到"问题"框,再由它反馈给仲裁器。
仲裁器的问题处理:
不会立刻 "重新仲裁",而是:
把这条指令留在指令缓冲 / 收集单元里阻塞,不发给执行单元
仲裁器转而去调度其他没有问题的就绪指令(比如别的 Warp)
等问题解决后(比如操作数就绪、Bank 空闲),这条指令才会被重新纳入调度候选
3.5 写回阶段
GPU流水线进入写回阶段后,运行流程如下:
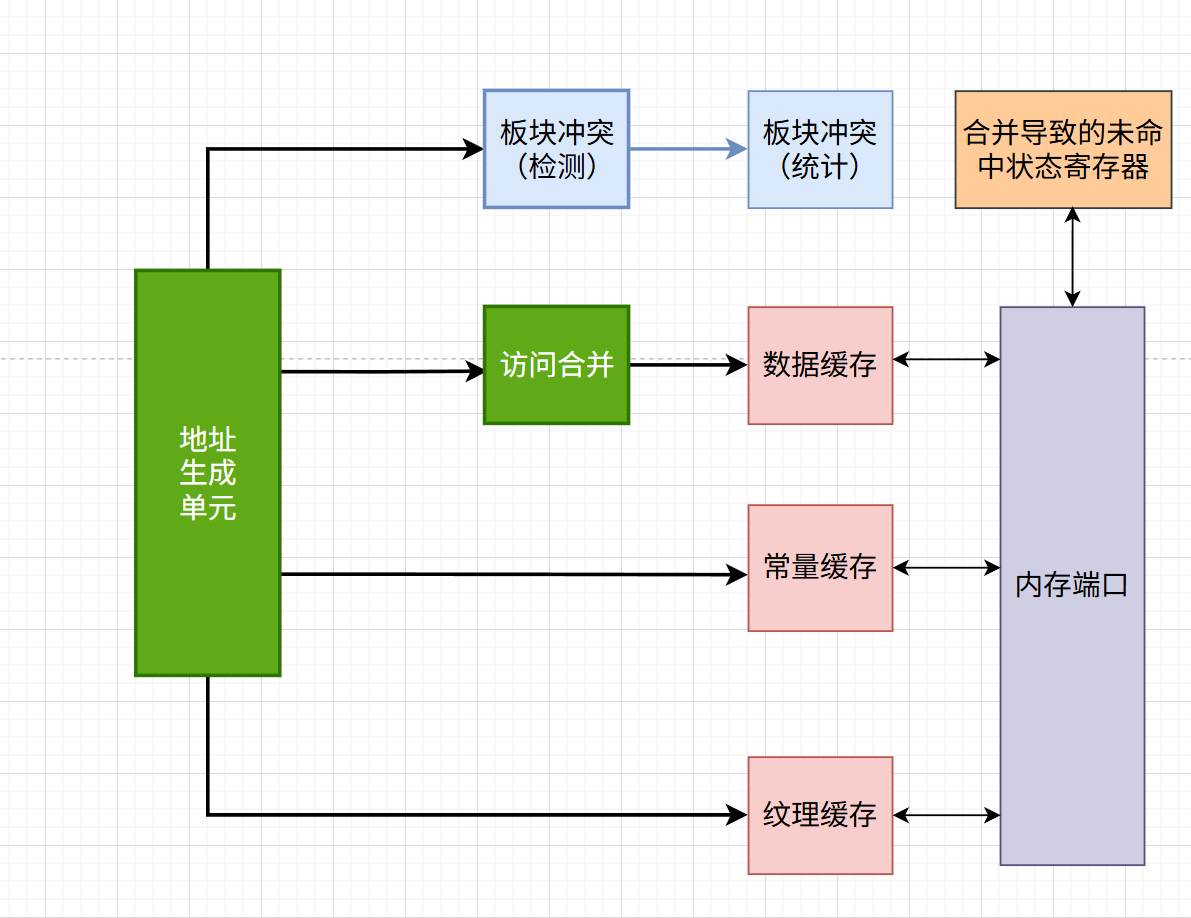
3.5.1 写回阶段的模块设计
地址生成单元(AGU)基于指令提供的基址、偏移量、索引等信息,计算出最终要访问的内存地址。地址生成单元生成的地址用于查找多级缓存。如果数据存在于某个缓存级别中,则直接从该缓存中读取数据,如果不存在,则需要进一步的寄存器访问。
地址生成单元可能会对生成的地址进行优化,以确保连续的存储器访问。这一过程称为地址合并,有助于提高存储器子系统的带宽利用率。
当多个线程尝试在同一时刻访问同一个存储板块的不同部分时,就会产生板块冲突。这可能会导致延迟。
缺失状态处理寄存器(MSHR: Miss Status Handling Register)是一个关键组件,用于跟踪和管理缓存不命中的状态。当请求的数据不在缓存中(缓存未命中)时,这些寄存器用于跟踪未完成的请求。有助于管理未解决的存储访问,从而增加带宽并降低访问延迟。它对于流水线的贡献在于保持处理器前进,即使在等待缓存缺失的数据返回时,由于MSHR的存在,GPU也可以继续执行其他指令或者处理其他缓存缺失。
3.5.2 板块冲突
板块冲突 = 多个请求同时抢同一个 Bank 的端口,就像多辆车同时挤上同一条车道,造成拥堵。
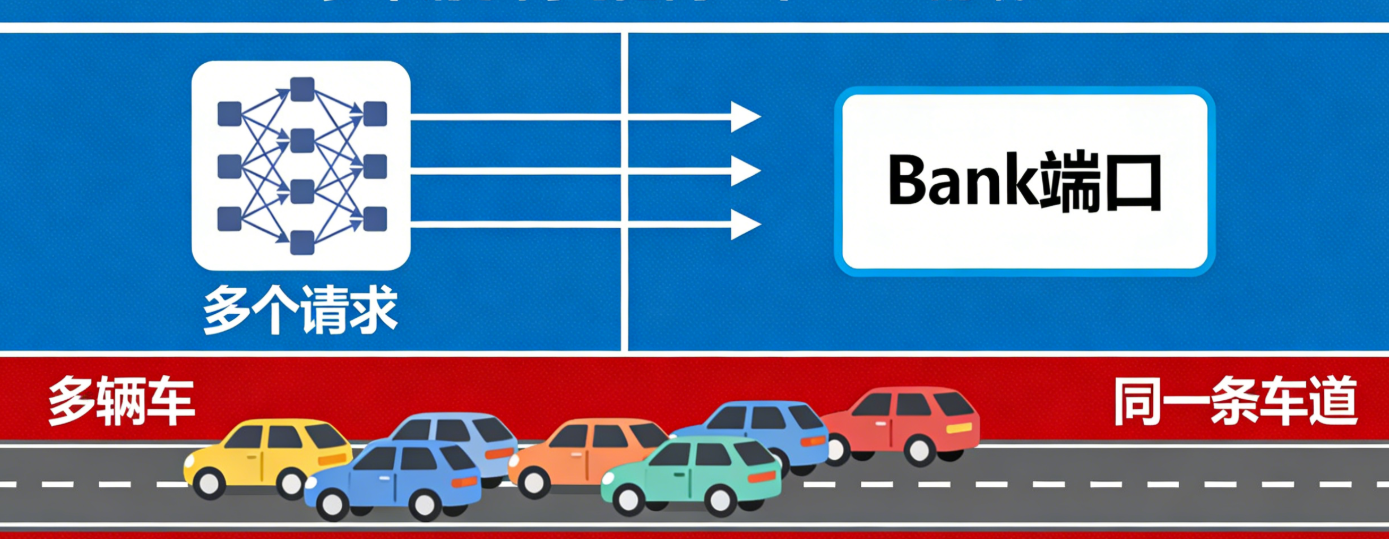
举个例子(寄存器文件场景):
线程束里有 32 个线程,同时要读寄存器 r3、r7、r1:
r3 映射到 板块 0
r7 映射到 板块 0
r1 映射到 板块 0
结果:3 个请求都要访问板块 0,但板块 0 只有 1 个读写端口 → 只能排队依次处理,这就是板块冲突。
后果:原本 1 周期能完成的访问,变成了 3 周期,性能直接下降。
4. 参考文献 & 后记
4.1 参考文件
- 《算力芯片------高性能CPU/GPU?NPU微架构分析》
- 《嵌入式C语言自我修养:从芯片、编译器到操作系统》
4.2 后记
本书从 SIMT 前端到 SIMD 后端,完整拆解了 GPU 流水线的取指、译码、发射、执行与写回全流程,既是对硬件架构的系统梳理,也是对底层逻辑的深度追问。译码阶段将指令拆解为微操作,评分板监测数据依赖,仲裁器与收集单元分别预判执行单元冲突与检测寄存器板块冲突,最终通过 "问题收集与处理" 模块汇总阻塞信号,实现指令的高效调度;写回阶段则聚焦地址生成与缓存访问。
这些细节不仅揭示了 GPU "延迟隐藏" 的设计思想 ------ 通过多 Warp 调度规避阻塞,更串联起指令流、数据流与控制流的协同逻辑。理解这些底层机制,既是读懂硬件并行精髓的关键,也是上层 CUDA 优化的根基。
限于篇幅,很多知识都没有来得及展开,比如评分板中除了保存指令的就绪位还有什么?乱序执行和寄存器重命名技术的实现细节是什么样的等等。将在后续篇幅中继续讲述,敬请关注!