视频讲解:https://www.bilibili.com/video/BV1bd6sBpEvT/?vd_source=5ba34935b7845cd15c65ef62c64ba82f
代码仓库:https://github.com/LitchiCheng/mujoco-learning
在前面分享过《MuJoCo 机械臂 PPO 强化学习逆向运动学(IK)》,在工作空间内,如果没有障碍物,那么任何一组解都是可以下发给机械臂进行控制并到目标点。
但实际若存在人机交互或是动态变化的环境,工作空间内进入任何物体都会影响关节的执行动作,进而造成目标点无法到达的实际结果。那么解决避障、绕张的规划变得尤为重要。
传统的路径规划的方式前面也介绍过《Mujoco 机械臂 OMPL 进行 RRT 关节空间路径规划避障、绕障》,那么在强化学习中我们如何让模型网络学习到该特性,"掌握"绕障、避障的技巧呢?
首先对于observation要进行设计,希望在奖励和实际中找到障碍物和是否碰撞以及目标点的关系,则观测空间如下:
self.obs_size = 7 + 3 + 3 + 1
self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(self.obs_size,), dtype=np.float32)
def _get_observation(self) -> np.ndarray:
joint_pos = self.data.qpos[:7].copy().astype(np.float32)
return np.concatenate([joint_pos, self.goal_position, self.obstacle_position + np.random.normal(0, 0.001, size=3), np.array([self.obstacle_size], dtype=np.float32)])对于奖励如何设计,从几个角度,
-
目标点是有精度要求
-
不想碰障碍物
-
机械臂不要超过关节限位
-
机械臂抖动不要太厉害
-
时间不要太长
def _calc_reward(self, joint_angles: np.ndarray, action: np.ndarray) -> tuple[np.ndarray, float]:
now_ee_pos = self.data.body(self.end_effector_id).xpos.copy()
dist_to_goal = np.linalg.norm(now_ee_pos - self.goal_position)# 非线性距离奖励 if dist_to_goal < self.goal_arrival_threshold: distance_reward = 20.0*(1.0+(1.0-(dist_to_goal / self.goal_arrival_threshold))) elif dist_to_goal < 2*self.goal_arrival_threshold: distance_reward = 10.0*(1.0+(1.0-(dist_to_goal / 2*self.goal_arrival_threshold))) elif dist_to_goal < 3*self.goal_arrival_threshold: distance_reward = 5.0*(1.0+(1.0-(dist_to_goal / 3*self.goal_arrival_threshold))) else: distance_reward = 1.0 / (1.0 + dist_to_goal) # 平滑惩罚 smooth_penalty = 0.001 * np.linalg.norm(action - self.last_action) # 碰撞惩罚 contact_reward = 10.0 * self.data.ncon # 关节角度限制惩罚 joint_penalty = 0.0 for i in range(7): min_angle, max_angle = self.model.jnt_range[:7][i] if joint_angles[i] < min_angle: joint_penalty += 0.5 * (min_angle - joint_angles[i]) elif joint_angles[i] > max_angle: joint_penalty += 0.5 * (joint_angles[i] - max_angle) time_penalty = 0.001 * (time.time() - self.start_t) total_reward = (distance_reward - contact_reward - smooth_penalty - joint_penalty - time_penalty) self.last_action = action.copy() return total_reward, dist_to_goal, self.data.ncon > 0
网络采用 PPO,对称网络,策略网络和价值网络,超参数需要实际调整,环境中障碍物为随机改变位置,目标点也随机,完整的训练代码如下,训练将TRAIN_MODE改True,测试改False即可
import numpy as np
import mujoco
import gym
from gym import spaces
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
from stable_baselines3.common.vec_env import SubprocVecEnv
import torch.nn as nn
import warnings
import torch
import mujoco.viewer
import time
from typing import Optional
from scipy.spatial.transform import Rotation as R
# 忽略stable-baselines3的冗余UserWarning
warnings.filterwarnings("ignore", category=UserWarning, module="stable_baselines3.common.on_policy_algorithm")
import os
def write_flag_file(flag_filename="rl_visu_flag"):
flag_path = os.path.join("/tmp", flag_filename)
try:
with open(flag_path, "w") as f:
f.write("This is a flag file")
return True
except Exception as e:
return False
def check_flag_file(flag_filename="rl_visu_flag"):
flag_path = os.path.join("/tmp", flag_filename)
return os.path.exists(flag_path)
def delete_flag_file(flag_filename="rl_visu_flag"):
flag_path = os.path.join("/tmp", flag_filename)
if not os.path.exists(flag_path):
return True
try:
os.remove(flag_path)
return True
except Exception as e:
return False
class PandaObstacleEnv(gym.Env):
def __init__(self, visualize: bool = False):
super(PandaObstacleEnv, self).__init__()
if not check_flag_file():
write_flag_file()
self.visualize = visualize
else:
self.visualize = False
self.handle = None
self.model = mujoco.MjModel.from_xml_path('./model/franka_emika_panda/scene_pos_with_obstacles.xml')
self.data = mujoco.MjData(self.model)
# for i in range(self.model.ngeom):
# if self.model.geom_group[i] == 3:
# self.model.geom_conaffinity[i] = 0
if self.visualize:
self.handle = mujoco.viewer.launch_passive(self.model, self.data)
self.handle.cam.distance = 3.0
self.handle.cam.azimuth = 0.0
self.handle.cam.elevation = -30.0
self.handle.cam.lookat = np.array([0.2, 0.0, 0.4])
self.np_random = np.random.default_rng(None)
self.end_effector_id = mujoco.mj_name2id(self.model, mujoco.mjtObj.mjOBJ_BODY, 'ee_center_body')
self.home_joint_pos = np.array(self.model.key_qpos[0][:7], dtype=np.float32)
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(7,), dtype=np.float32)
# 7轴关节角度、目标位置、障碍物位置和球体直径
self.obs_size = 7 + 3 + 3 + 1
self.observation_space = spaces.Box(low=-np.inf, high=np.inf, shape=(self.obs_size,), dtype=np.float32)
# self.goal_position = np.array([0.4, 0.3, 0.4], dtype=np.float32)
self.goal_position = np.array([0.4, -0.3, 0.4], dtype=np.float32)
self.goal_arrival_threshold = 0.005
self.goal_visu_size = 0.02
self.goal_visu_rgba = [0.1, 0.3, 0.3, 0.8]
# 在xml中增加障碍物,worldbody 中添加如下
# <geom name="obstacle_0"
# type="sphere"
# size="0.060"
# pos="0.300 0.200 0.500"
# contype="1"
# conaffinity="1"
# mass="0.0"
# rgba="0.300 0.300 0.300 0.800"
# />
# 并在init函数中初始化障碍物的位置和大小
for i in range(self.model.ngeom):
name = mujoco.mj_id2name(self.model, mujoco.mjtObj.mjOBJ_GEOM, i)
if name == "obstacle_0":
self.obstacle_id_1 = i
self.obstacle_position = np.array(self.model.geom_pos[self.obstacle_id_1], dtype=np.float32)
self.obstacle_size = self.model.geom_size[self.obstacle_id_1][0]
self.last_action = self.home_joint_pos
def _render_scene(self) -> None:
if not self.visualize or self.handle is None:
return
self.handle.user_scn.ngeom = 0
total_geoms = 1
self.handle.user_scn.ngeom = total_geoms
mujoco.mjv_initGeom(
self.handle.user_scn.geoms[0],
mujoco.mjtGeom.mjGEOM_SPHERE,
size=[self.goal_visu_size, 0.0, 0.0],
pos=self.goal_position,
mat=np.eye(3).flatten(),
rgba=np.array(self.goal_visu_rgba, dtype=np.float32)
)
def reset(self, seed: Optional[int] = None, options: Optional[dict] = None) -> tuple[np.ndarray, dict]:
super().reset(seed=seed)
if seed is not None:
self.np_random = np.random.default_rng(seed)
# 重置关节到home位姿
mujoco.mj_resetData(self.model, self.data)
self.data.qpos[:7] = self.home_joint_pos
self.data.qpos[7:] = [0.04,0.04]
mujoco.mj_forward(self.model, self.data)
self.goal_position = np.array([self.goal_position[0], self.np_random.uniform(-0.3, 0.3), self.goal_position[2]], dtype=np.float32)
self.obstacle_position = np.array([self.obstacle_position[0], self.np_random.uniform(-0.3, 0.3), self.obstacle_position[2]], dtype=np.float32)
self.model.geom_pos[self.obstacle_id_1] = self.obstacle_position
mujoco.mj_step(self.model, self.data)
if self.visualize:
self._render_scene()
obs = self._get_observation()
self.start_t = time.time()
return obs, {}
def _get_observation(self) -> np.ndarray:
joint_pos = self.data.qpos[:7].copy().astype(np.float32)
return np.concatenate([joint_pos, self.goal_position, self.obstacle_position + np.random.normal(0, 0.001, size=3), np.array([self.obstacle_size], dtype=np.float32)])
def _calc_reward(self, joint_angles: np.ndarray, action: np.ndarray) -> tuple[np.ndarray, float]:
now_ee_pos = self.data.body(self.end_effector_id).xpos.copy()
dist_to_goal = np.linalg.norm(now_ee_pos - self.goal_position)
# 非线性距离奖励
if dist_to_goal < self.goal_arrival_threshold:
distance_reward = 20.0*(1.0+(1.0-(dist_to_goal / self.goal_arrival_threshold)))
elif dist_to_goal < 2*self.goal_arrival_threshold:
distance_reward = 10.0*(1.0+(1.0-(dist_to_goal / 2*self.goal_arrival_threshold)))
elif dist_to_goal < 3*self.goal_arrival_threshold:
distance_reward = 5.0*(1.0+(1.0-(dist_to_goal / 3*self.goal_arrival_threshold)))
else:
distance_reward = 1.0 / (1.0 + dist_to_goal)
# 平滑惩罚
smooth_penalty = 0.001 * np.linalg.norm(action - self.last_action)
# 碰撞惩罚
contact_reward = 10.0 * self.data.ncon
# 关节角度限制惩罚
joint_penalty = 0.0
for i in range(7):
min_angle, max_angle = self.model.jnt_range[:7][i]
if joint_angles[i] < min_angle:
joint_penalty += 0.5 * (min_angle - joint_angles[i])
elif joint_angles[i] > max_angle:
joint_penalty += 0.5 * (joint_angles[i] - max_angle)
time_penalty = 0.001 * (time.time() - self.start_t)
total_reward = (distance_reward
- contact_reward
- smooth_penalty
- joint_penalty
- time_penalty)
self.last_action = action.copy()
return total_reward, dist_to_goal, self.data.ncon > 0
def step(self, action: np.ndarray) -> tuple[np.ndarray, np.float32, bool, bool, dict]:
joint_ranges = self.model.jnt_range[:7]
scaled_action = np.zeros(7, dtype=np.float32)
for i in range(7):
scaled_action[i] = joint_ranges[i][0] + (action[i] + 1) * 0.5 * (joint_ranges[i][1] - joint_ranges[i][0])
self.data.ctrl[:7] = scaled_action
self.data.qpos[7:] = [0.04,0.04]
mujoco.mj_step(self.model, self.data)
reward, dist_to_goal, collision = self._calc_reward(self.data.qpos[:7], action)
terminated = False
if collision:
# print("collision happened, ", self.data.ncon)
# info = {}
# for i in range(self.data.ncon):
# contact = self.data.contact[i]
# # 获取几何体对应的body_id
# body1_id = self.model.geom_bodyid[contact.geom1]
# body2_id = self.model.geom_bodyid[contact.geom2]
# # 通过mj_id2name转换body_id为名称
# body1_name = mujoco.mj_id2name(self.model, mujoco.mjtObj.mjOBJ_BODY, body1_id)
# body2_name = mujoco.mj_id2name(self.model, mujoco.mjtObj.mjOBJ_BODY, body2_id)
# info["pair"+str(i)] = {}
# info["pair"+str(i)]["geom1"] = contact.geom1
# info["pair"+str(i)]["geom2"] = contact.geom2
# info["pair"+str(i)]["pos"] = contact.pos.copy()
# info["pair"+str(i)]["body1_name"] = body1_name
# info["pair"+str(i)]["body2_name"] = body2_name
# print(info)
reward -= 10.0
terminated = True
if dist_to_goal < self.goal_arrival_threshold:
terminated = True
print(f"[成功] 距离目标: {dist_to_goal:.3f}, 奖励: {reward:.3f}")
# else:
# print(f"[失败] 距离目标: {dist_to_goal:.3f}, 奖励: {reward:.3f}")
if not terminated:
if time.time() - self.start_t > 20.0:
reward -= 10.0
print(f"[超时] 时间过长,奖励减半")
terminated = True
if self.visualize and self.handle is not None:
self.handle.sync()
time.sleep(0.01)
obs = self._get_observation()
info = {
'is_success': not collision and terminated and (dist_to_goal < self.goal_arrival_threshold),
'distance_to_goal': dist_to_goal,
'collision': collision
}
return obs, reward.astype(np.float32), terminated, False, info
def seed(self, seed: Optional[int] = None) -> list[Optional[int]]:
self.np_random = np.random.default_rng(seed)
return [seed]
def close(self) -> None:
if self.visualize and self.handle is not None:
self.handle.close()
self.handle = None
def train_ppo(
n_envs: int = 24,
total_timesteps: int = 80_000_000, # 本次训练的新增步数
model_save_path: str = "panda_ppo_reach_target",
visualize: bool = False,
resume_from: Optional[str] = None
) -> None:
ENV_KWARGS = {'visualize': visualize}
env = make_vec_env(
env_id=lambda: PandaObstacleEnv(** ENV_KWARGS),
n_envs=n_envs,
seed=42,
vec_env_cls=SubprocVecEnv,
vec_env_kwargs={"start_method": "fork"}
)
if resume_from is not None:
model = PPO.load(resume_from, env=env) # 加载时需传入当前环境
else:
# POLICY_KWARGS = dict(
# activation_fn=nn.ReLU,
# net_arch=[dict(pi=[256, 128], vf=[256, 128])]
# )
POLICY_KWARGS = dict(
activation_fn=nn.LeakyReLU,
net_arch=[
dict(
pi=[512, 256, 128],
vf=[512, 256, 128]
)
]
)
model = PPO(
policy="MlpPolicy",
env=env,
policy_kwargs=POLICY_KWARGS,
verbose=1,
n_steps=2048,
batch_size=2048,
n_epochs=10,
gamma=0.99,
# ent_coef=0.02, # 增加熵系数,保留后期探索以提升泛化性
ent_coef = 0.001,
clip_range=0.15, # 限制策略更新幅度
max_grad_norm=0.5, # 梯度裁剪防止爆炸
learning_rate=lambda f: 1e-4 * (1 - f), # 学习率线性衰减(初始1e-4,后期逐步降低)
device="cuda" if torch.cuda.is_available() else "cpu",
tensorboard_log="./tensorboard/panda_obstacle_avoidance/"
)
print(f"并行环境数: {n_envs}, 本次训练新增步数: {total_timesteps}")
model.learn(
total_timesteps=total_timesteps,
progress_bar=True
)
model.save(model_save_path)
env.close()
print(f"模型已保存至: {model_save_path}")
def test_ppo(
model_path: str = "panda_obstacle_avoidance",
total_episodes: int = 5,
) -> None:
env = PandaObstacleEnv(visualize=True)
model = PPO.load(model_path, env=env)
success_count = 0
print(f"测试轮数: {total_episodes}")
for ep in range(total_episodes):
obs, _ = env.reset()
done = False
episode_reward = 0.0
while not done:
obs = env._get_observation()
# print(f"观察: {obs}")
action, _states = model.predict(obs, deterministic=True)
# action += np.random.normal(0, 0.002, size=7) # 加入噪声
obs, reward, terminated, truncated, info = env.step(action)
# print(f"动作: {action}, 奖励: {reward}, 终止: {terminated}, 截断: {truncated}, 信息: {info}")
episode_reward += reward
done = terminated or truncated
if info['is_success']:
success_count += 1
print(f"轮次 {ep+1:2d} | 总奖励: {episode_reward:6.2f} | 结果: {'成功' if info['is_success'] else '碰撞/失败'}")
success_rate = (success_count / total_episodes) * 100
print(f"总成功率: {success_rate:.1f}%")
env.close()
if __name__ == "__main__":
TRAIN_MODE = True # 设为True开启训练模式
if TRAIN_MODE:
import os
os.system("rm -rf /home/dar/mujoco-bin/mujoco-learning/tensorboard*")
delete_flag_file()
MODEL_PATH = "assets/model/rl_obstacle_avoidance_checkpoint/panda_obstacle_avoidance_v3"
RESUME_MODEL_PATH = "assets/model/rl_obstacle_avoidance_checkpoint/panda_obstacle_avoidance_v2"
if TRAIN_MODE:
train_ppo(
n_envs=64,
total_timesteps=60_000_000,
model_save_path=MODEL_PATH,
visualize=True,
# resume_from=RESUME_MODEL_PATH
resume_from=None
)
else:
test_ppo(
model_path=MODEL_PATH,
total_episodes=100,
)
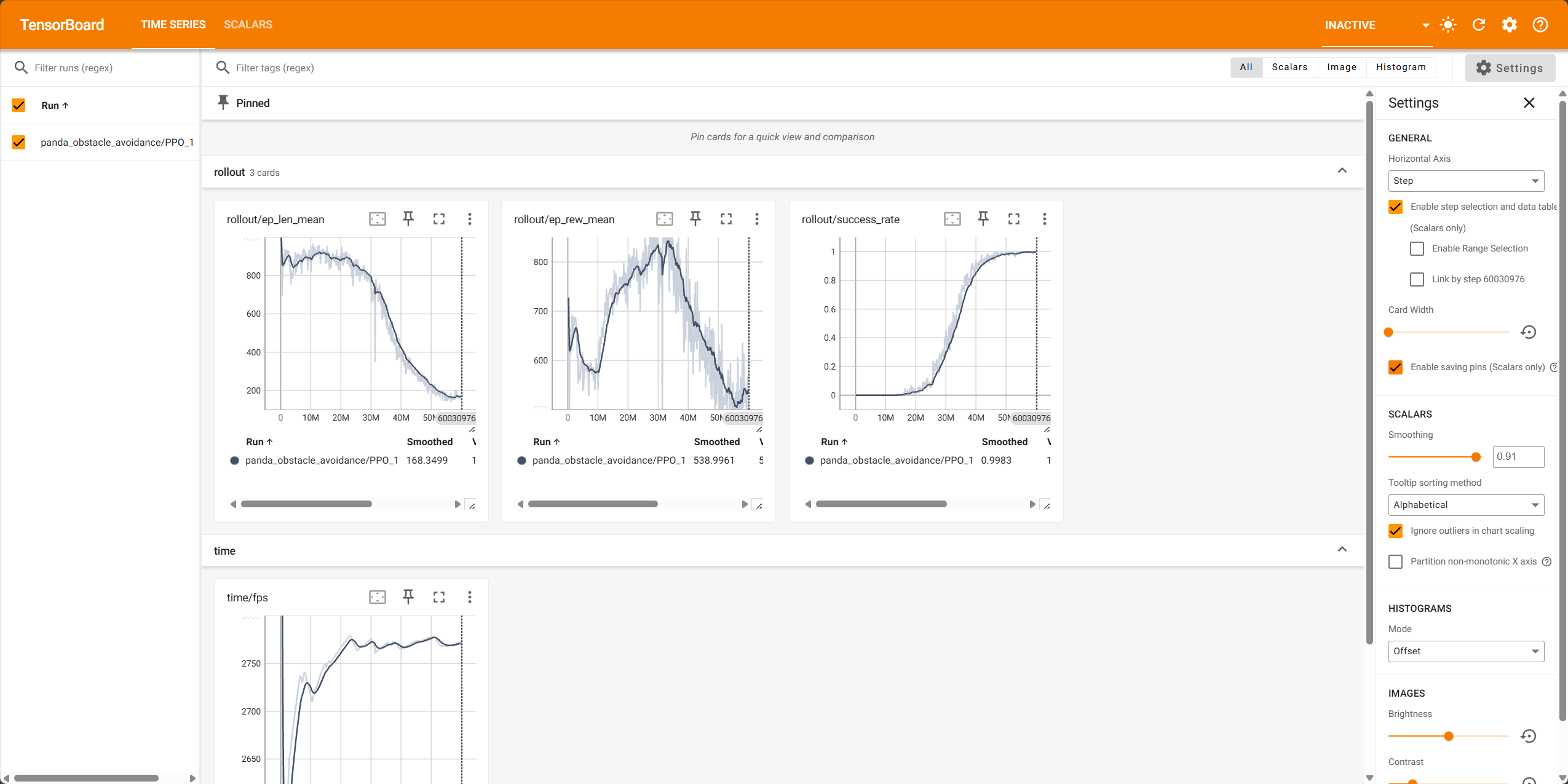
os.system("date")使用Tensorboard观察训练数据,可以看到接近训练结束时成功率接近100%