标题一次,非Qwen3-VL-0.6B官方。最近手里有一台昇腾910B的服务器,顺便摸索下国产芯片的训练都有哪些坑,笔者时隔一年对Reyes《【多模态&LLM】Reyes:一个从0到1开始训练的多模态大模型(技术报告)》进行了改造,原本的Reyes由8B的参数构成(InternViT-300M-448px-V2_5+Qwen2.5-7B-Instruct),随着端侧模型的发展与手里资源的限制,最终笔者将Reyes参数量设置成0.6B,训练了一个轻量化的多模态模型,最终在MMMU-benchmark取得了38.7的得分。
模型架构
得益于开源社区优秀的开源模型(qwenvl、smolvlm等)在模型、代码、训练等提供的思路,Reyes-0.6B整体结构遵循经典的Vit+两层MLP+LLM架构:
- vit视觉编码器:SigLIP2-Base-Patch16-512
- LLM:qwen3-0.6B
优化trick
原生分辨率支持
在上个版本Reyes-8B中,主要采用了动态分辨率对图像进行预处理,包括归一化、缩放、裁剪、根据宽高比动态处理等操作。

在《多模态大模型中不同分辨率策略研究与原生分辨率的有效性评估》和现有多个VLMs(如qwenvl、keye-vl等)中都使用了原生分辨率。
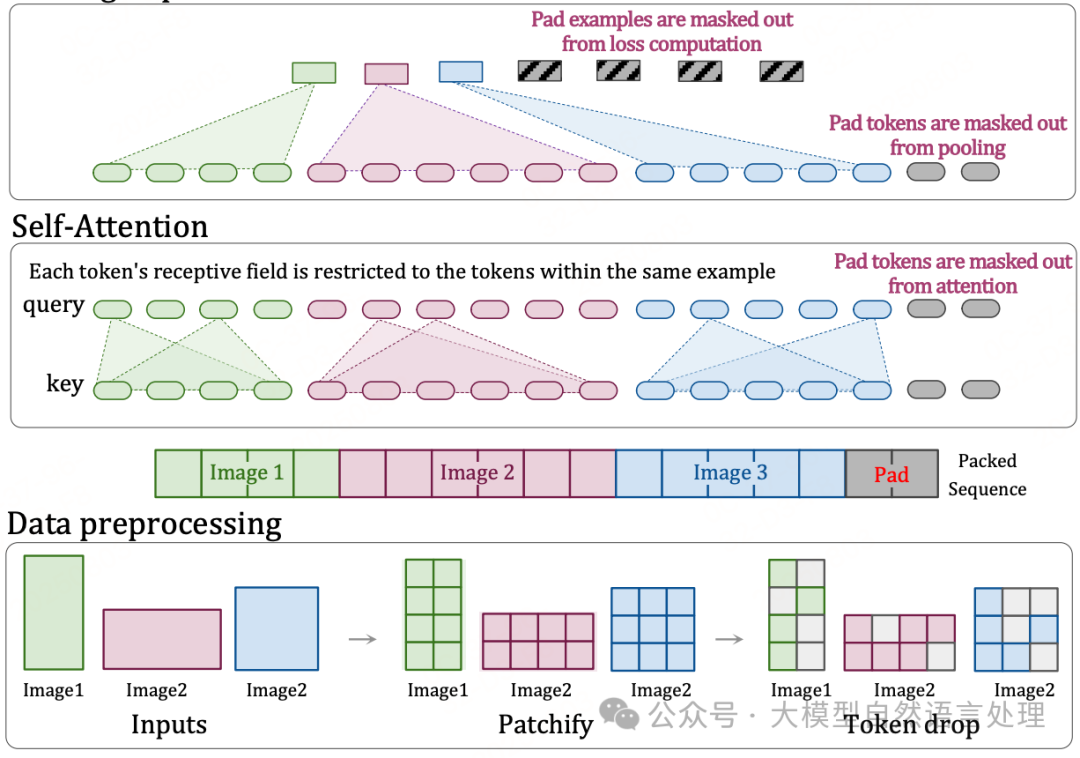
因此本次Reyes-0.6B模型也增加了原生分辨率的支持,通过适配集成 2D Rotary Position Embeddings(2D-RoPE)和双三次插值适配位置嵌入实现。
像素洗牌(Pixel Shuffle)支持
在《开源的轻量化VLM-SmolVLM模型架构、数据策略及其衍生物PDF解析模型SmolDocling》提到,像素洗牌通过重新排列编码图像,以增加通道深度为代价换取空间分辨率。这减少了视觉标记数量,同时保持信息密度。
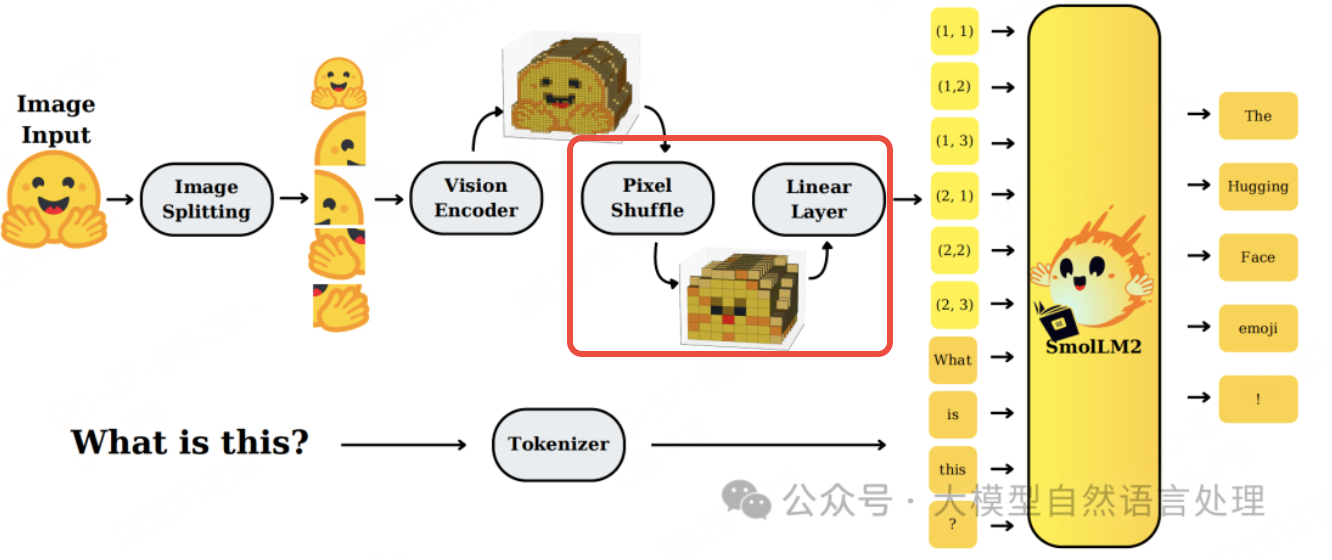

训练
训练数据得益于开源社区的快速发展,如FineVision、《多模态视觉语言模型:Molmo2训练数据、训练配方》提到的若干优质的数据集,结合一些筛选和净化手段。
训练整体分预训练和SFT两阶段:
- 预训练:训练模型的对齐能力,由VQA+OCR+caption数据构成。1024x1024低分辨率训练。
- SFT:训练模型的多模态理解能力,由纯文本+VQA的混合数据进行训练,2048x2048高分辨率训练。
推理代码
import torch
from transformers import AutoModel, AutoTokenizer, CLIPImageProcessor
model_dir = "模型权重"
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
image_processor = CLIPImageProcessor.from_pretrained(model_dir, trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "描述一下这张图片。"},
{
"type": "image_url",
"image_url": {
"url": "test.png"
},
}
],
},
]
res = model.chat(messages, tokenizer, image_processor, max_new_tokens=1024, do_sample=True, temperature=0.6)
print(res)一些case
VQA:

- prompt:描述一下这张图片。
- 输出:这张图片展示了一只威尔士柯基犬,它正坐在一条灰色的石板路上。狗狗的毛色主要是棕色和白色相间的,面部和胸部有明显的白色部分。它的耳朵竖立,眼睛半闭,嘴巴微微张开,露出一点粉色的舌头,看起来非常开心和活泼。背景中可以看到一些树木和草地,表明这只狗可能在一个公园或类似的户外环境中。整体上,这张照片给人一种轻松愉快的感觉,体现了狗狗的活力和亲近人心的一面。
OCR:

- prompt:识别图片中的文字,输出markdown格式。
- 输出:

尾注:本次仅记录训练Reyes-0.6B的过程和一些trick的验证。