目录
[- 真实过程:](#- 真实过程:)
[1.4、CHS & LBA 地址](#1.4、CHS & LBA 地址)
[- CHS转成LBA:](#- CHS转成LBA:)
[- LBA转成CHS:](#- LBA转成CHS:)
[2.1、引入 "分块" 概念](#2.1、引入 “分块” 概念)
[2.2、引入 "分区" 概念](#2.2、引入 “分区” 概念)
[2.3、引入 "inode" 概念](#2.3、引入 “inode” 概念)
前面我们介绍了对文件的 IO 操作,我们知道文件存储在磁盘,当我们打开一个文件,文件就会被加载到内存。那么文件是怎么在磁盘上被存储和管理的呢?
一、理解磁盘
磁盘属于硬件,容量大,价格便宜。
1.1、物理结构

光盘大家肯定都不陌生,为什么能用它来看电影,就是因为光盘如图的这一面存储了数据。
磁盘与之类似,但磁盘的两个面都可以存储数据。物理结构如下图所示,

💥那为什么磁盘能够存储数据?
所有的数据都会被编码成0和1二进制的形式存储在磁盘中,我们看着磁盘好像是光滑的,但其实磁盘上面有非常多的凸起,我们可以把这些小凸起看成一个个的小磁针。
而磁铁有南北极(两态),正好可以用来表示0和1两种状态,北极朝上的是 0,南极朝上的是 1。
所以,在磁盘上存储数据就是用磁头改变磁盘上一定区域内磁性物质的磁化方向(0/1)。

磁盘的空间结构,实际上是三个盘片,即六个盘面。
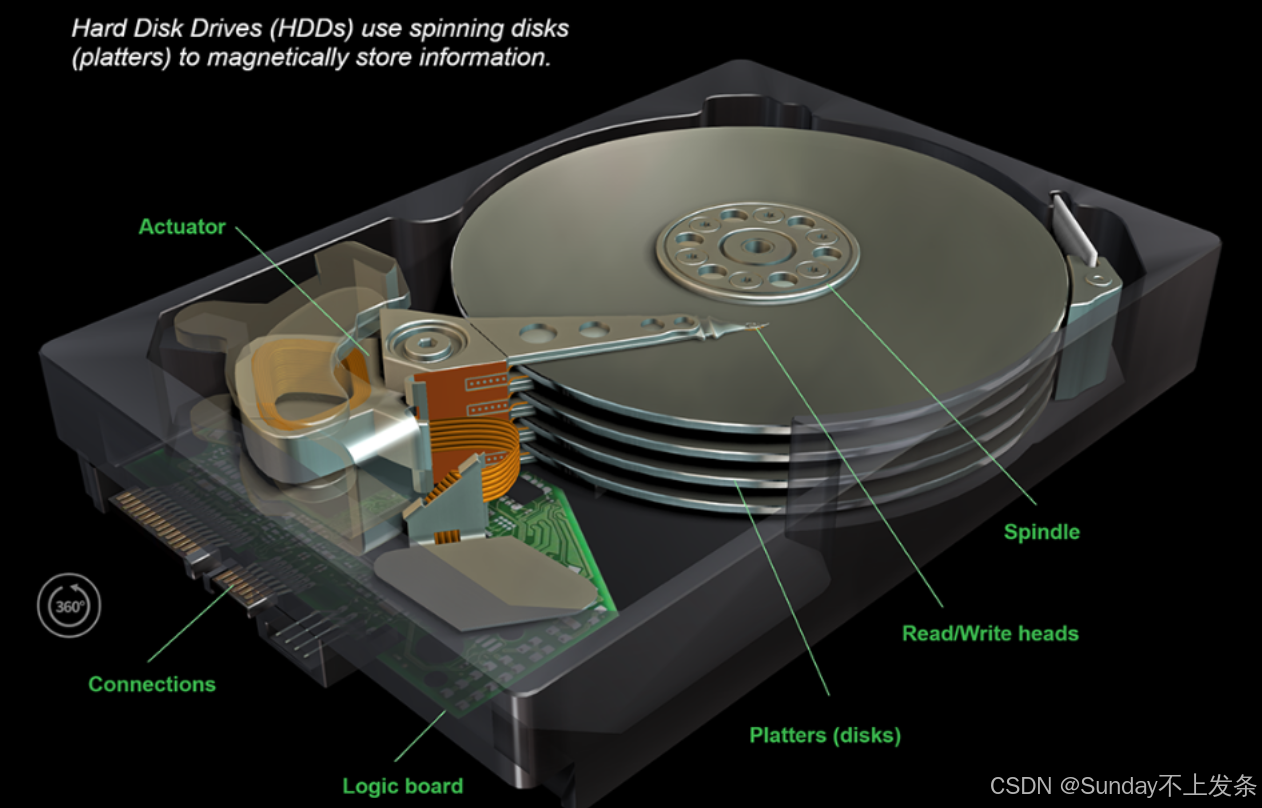
1.2、存储结构
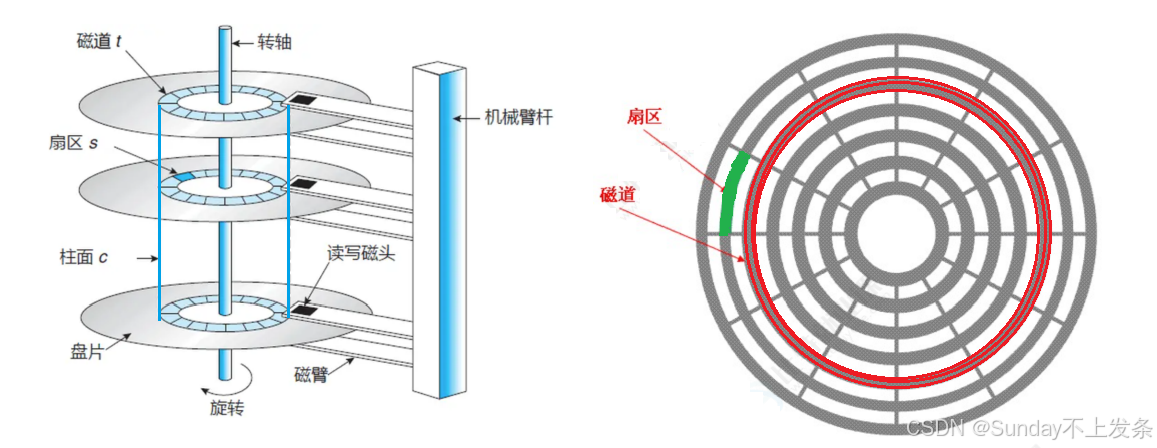
扇区:是磁盘存储数据的基本单位,512字节(0.5KB),块设备。
💦 那么问题就来了:既然扇区是存储数据的基本单位,那么我们将数据存储到指定的扇区就需要定位扇区的位置,怎么定位呢?
磁盘是空间结构,定位空间的一个位置,我们知道需要三个坐标(参数)即可。
**• 柱面号:**确定磁头要访问哪一个柱面(cylinder),即确定在哪个磁道;
**• 磁头号:**定位磁头(header),即确定在哪个盘面;
**• 扇区号:**确定是哪个扇区(sector)。
以上这种寻址方式就是CHS地址定位法。
文件 = 内容+属性 都是数据,无非就是占据那几个扇区的问题!然后定位几个扇区进行存储就好了。
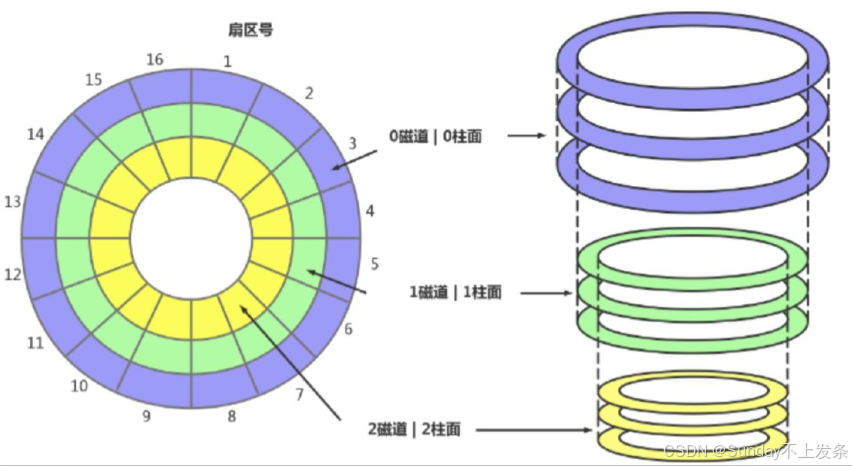
💥我们知道一个扇区是512个字节,那么磁盘容量是多大呢?
磁盘容量 = 磁头数 * 磁道数 * 每磁道扇区数 * 每扇区字节数
一个细节:传动臂上的磁头是共进退的。
1.3、逻辑结构

如上为磁带,将其拉直就是线性结构,那我们可不可以将磁盘抽象为这种结构来理解呢?
我们可以将磁盘的磁道想象成一卷磁带,如果将其剪短拉直,不就是线性结构嘛,每个扇区相当于数组的一个单元。

这样每一个扇区,就有了一个线性地址(其实就是数组下标),这种地址叫做 LBA。
- 真实过程:
前面我们提到一个细节:传动臂上的磁头是共进退的 。所以,六个磁头所指的磁道半径相同,即此时磁头所指的磁道构成上面提到的 柱面。
所以,磁盘物理上分了很多面,但是在我们看来,逻辑上,磁盘整体是由"柱面"卷起来的。
所以,磁盘的真实情况是:
**• 磁道:**某一盘面的某一个磁道展开(一维数组):

**• 柱面:**整个磁盘所有盘面的同一个磁道,即柱面展开:
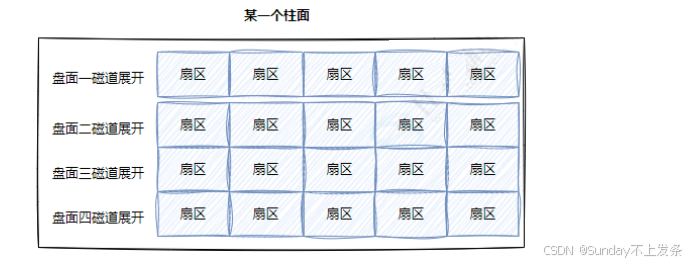
而所有磁道上的扇区数相同,这不就是二维数组嘛!!!
• 整个磁盘:
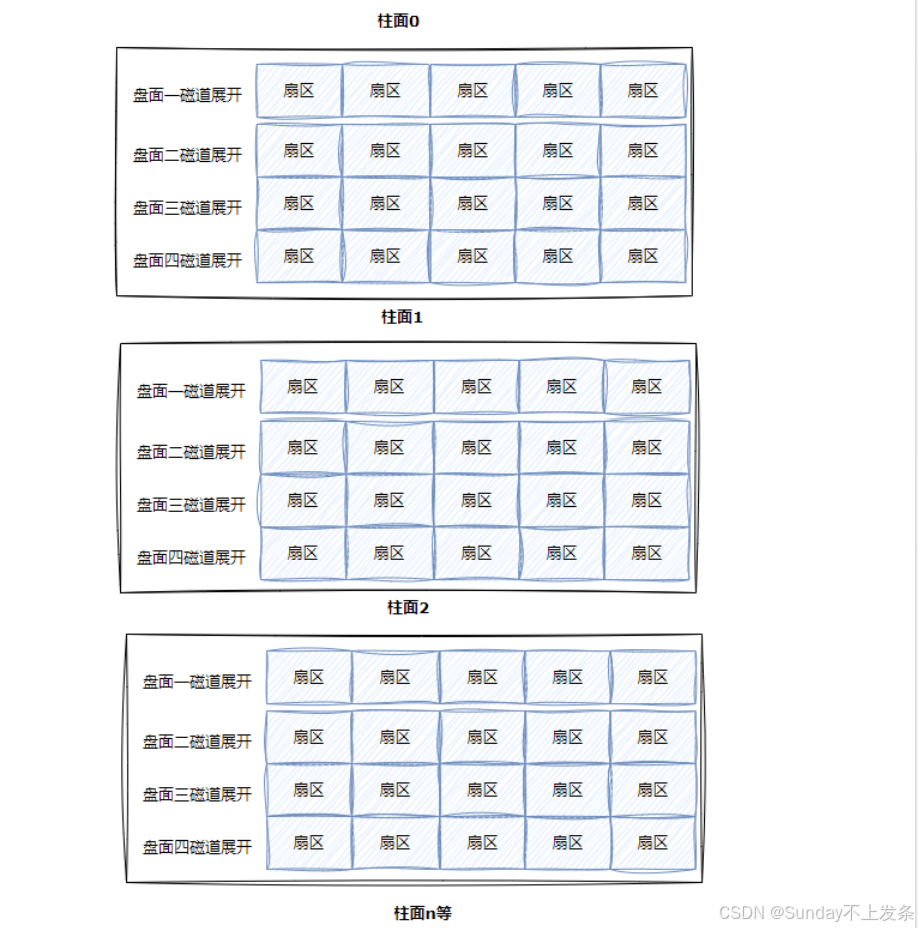
所有,寻址一个扇区:先找到哪一个柱面(Cylinder) ,再确定柱面内哪一个磁道(其实就是磁头位置, Head),最后确定扇区(Sector),所以就有了CHS。
如果我们将所有的二维数组拆开,拼接为一维数组:

每个扇区都对应有一个数组下标,即LBA地址。所以操作系统只需要一个LBA地址就能找到指定的扇区。但由于磁盘真实结构,所以就需要将LBA地址转化为CHS地址。
那么怎么将LBA地址转化为CHS地址呢?
1.4、CHS & LBA 地址
- CHS转成LBA:
LBA = 柱面号 * 每柱面扇区数 + 磁头号 * 每磁道扇区数 + 扇区号 - 1
- LBA转成CHS:
柱面号 = LBA / 单个柱面扇区数;
磁头号 = LBA % (柱面号 * 每柱面扇区数) / 单个磁道扇区数;
扇区号 = LBA % 单个磁道扇区数 + 1。
谁完成的:硬盘自身的固件(Firmware),这是最底层、最核心的转换主体,磁盘出厂时固件已固化 CHS/LBA 映射规则,接收 LBA 地址后自动完成硬件级转换;
二、文件系统
2.1、引入 "分块" 概念
磁盘的最小存储单位是扇区,但实际操作系统在向磁盘读写数据时并不会以扇区为单位进行,这样效率太低,所以操作系统会连续读取多个扇区,即一个块。
磁盘会先被进行分区(下面讲),然后每个区按照块为单位进行分块。一个"块"的大小是由格式化的时候确定的,并且不可 以更改,最常见的是4KB ,即连续八个扇区组成一个 "块 "。"块"是文件存取的最小单位。
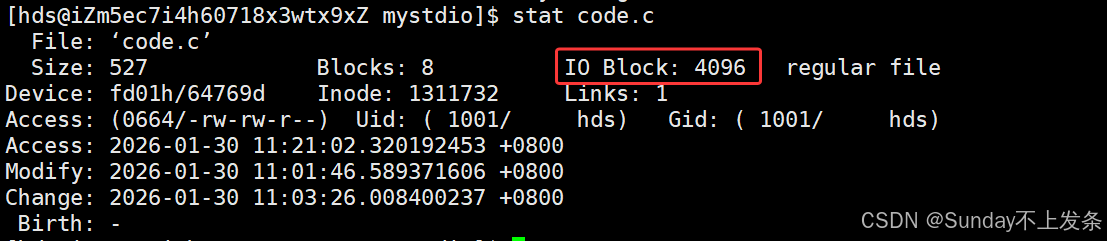
注意:
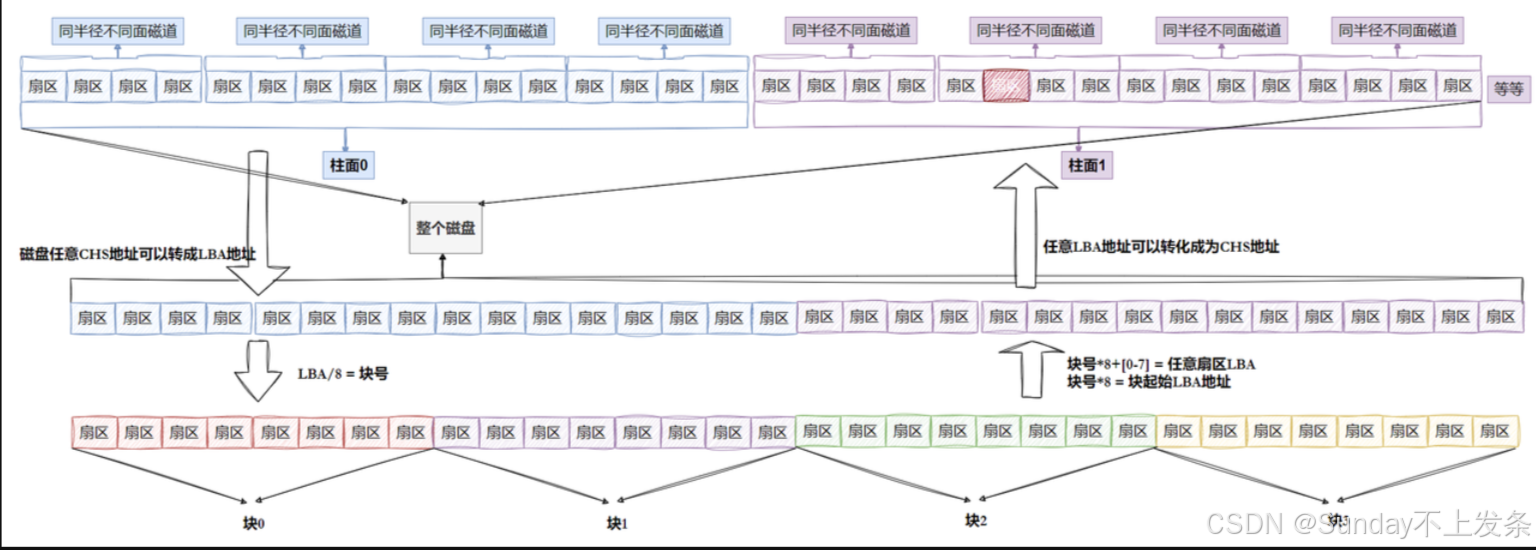
- 磁盘就是一个三维数组,我们把它看待成为一个"一维数组",数组下标就是LBA,每个元素都是扇区
- 每个扇区都有LBA,那么8个扇区一个块,每一个块的地址我们也能算出来。
- 块号 = LBA / 8
- LAB=块号*8 + n. (n是块内第几个扇区)
2.2、引入 "分区" 概念
为了提高管理效率,隔离数据,减少碎片空间,将磁盘又进行了分区。我们建立的C,D,E盘其实就是对磁盘进行了分区。怎么分区呢?
分区的最小单位是柱面,其本质就是设置每个区的起 始柱面和结束柱面号码。
📌 注意:
• 柱面大小一致,扇区个位一致,那么其实只要知道每个分区的起始和结束柱面号,知道每 一个柱面多少个扇区,那么该分区多大,就清楚了。

2.3、引入 "inode" 概念
文件 = 属性 + 数据,通过ls -l就可以查看文件的相关数据:
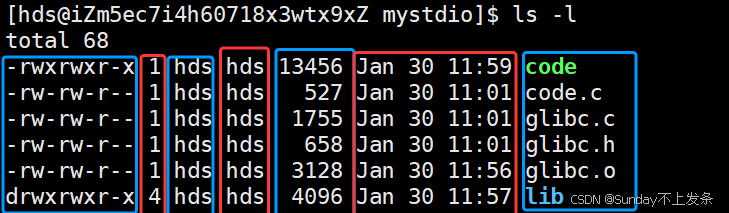
ls -l 每一行的 7 列依次是:
模式(权限) 、硬链接数(引用计数) 、所有者 、所属组 、大小 、最后修改时间 、文件名想要查看更详细的信息就需要用:stat 文件名
💦文件的属性数据和内容数据实际上是分开存储的,那么属性数据是存储在什么地方的呢?
这种储存文件 元信息的区域就叫做inode,中文译名为"索引节点"。
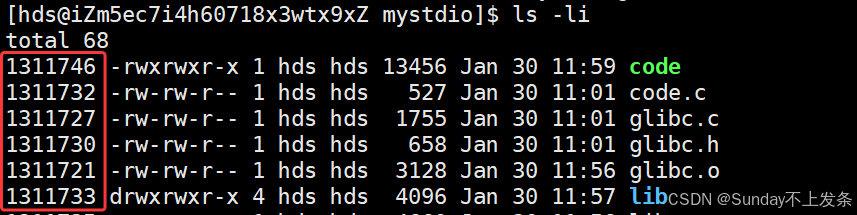
bashls -li圈出来的就是每个文件对应的 inode 号,里面存储的就是文件的属性数据。
📌++注意:++• Linux下文件的存储是属性和内容分离存储的
• Linux下,保存文件属性的集合叫做inode,一个文件,一个inode,inode内有一个唯一 的标识符,叫做inode号。
💥inode 实际就是一个结构体,那文件属性都有哪些呢?
bash
/*
* 磁盘上索引节点(inode)的结构定义
*/
struct ext2_inode {
__le16 i_mode; /* 文件模式(类型+权限) */
__le16 i_uid; /* 文件所有者UID的低16位 */
__le32 i_size; /* 文件大小(字节) */
__le32 i_atime; /* 最后访问时间 */
__le32 i_ctime; /* 节点创建/属性修改时间 */
__le32 i_mtime; /* 文件内容最后修改时间 */
__le32 i_dtime; /* 文件删除时间 */
__le16 i_gid; /* 文件所属组GID的低16位 */
__le16 i_links_count; /* 硬链接数 */
__le32 i_blocks; /* 文件占用的块数 */
__le32 i_flags; /* 文件标志 */
union {
struct {
__le32 l_i_reserved1; /* 保留字段 */
} linux1;
struct {
__le32 h_i_translator; /* 翻译器(Hurd系统使用) */
} hurd1;
struct {
__le32 m_i_reserved1; /* 保留字段(Masix系统使用) */
} masix1;
} osd1; /* 操作系统相关字段1 */
__le32 i_block[EXT2_N_BLOCKS]; /* 数据块指针数组 */
__le32 i_generation; /* 文件版本号(用于NFS) */
__le32 i_file_acl; /* 文件访问控制列表(ACL) */
__le32 i_dir_acl; /* 目录访问控制列表(ACL) */
__le32 i_faddr; /* 碎片地址 */
union {
struct {
__u8 l_i_frag; /* 碎片编号 */
__u8 l_i_fsize; /* 碎片大小 */
__u16 i_pad1; /* 填充字段 */
__le16 l_i_uid_high; /* 以下2个字段 */
__le16 l_i_gid_high; /* 原为reserved2[0](高16位UID/GID) */
__u32 l_i_reserved2; /* 保留字段 */
} linux2;
struct {
__u8 h_i_frag; /* 碎片编号(Hurd系统使用) */
__u8 h_i_fsize; /* 碎片大小(Hurd系统使用) */
__le16 h_i_mode_high; /* 模式高16位(Hurd系统使用) */
__le16 h_i_uid_high; /* UID高16位(Hurd系统使用) */
__le16 h_i_gid_high; /* GID高16位(Hurd系统使用) */
__le32 h_i_author; /* 作者ID(Hurd系统使用) */
} hurd2;
struct {
__u8 m_i_frag; /* 碎片编号(Masix系统使用) */
__u8 m_i_fsize; /* 碎片大小(Masix系统使用) */
__u16 m_pad1; /* 填充字段(Masix系统使用) */
__u32 m_i_reserved2[2]; /* 保留字段(Masix系统使用) */
} masix2;
} osd2; /* 操作系统相关字段2 */
};
/*
* 数据块相关常量定义
*/
#define EXT2_NDIR_BLOCKS 12 // 直接块数量
#define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS // 一级间接块指针索引
#define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) // 二级间接块指针索引
#define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) // 三级间接块指针索引
#define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1) // 块指针总数(12+1+1+1=15)
// 备注:EXT2_N_BLOCKS = 15📌 再次注意:
• 文件名属性并未纳入到inode数据结构内部
• inode的大小一般是128字节或者256,我们后面统一128字节
• 任何文件的内容大小可以不同,但是属性大小一定是相同的
到目前为止,以及结合之前的讲解,相信大家已经对文件在磁盘的储存有了更加深入的理解。
但还有很多问题等待解答:
怎么找到未被占用的"块"?"块"是怎么被管理的?
存储文件属性数据的 inode 被存储在哪里?
这些确实都是文件系统进行管理的!!!
下期我们就以Ext2文件系统进行详细的讲解。
