哈希表
- 哈希表
- 哈希冲突
- 扩容和负载因子
- 两数之和
- [49. 字母异位词分组](#49. 字母异位词分组)
- [128. 最长连续序列](#128. 最长连续序列)
- <unordered_map>和<unordered_set>
哈希表
哈希表可以理解为一个加强版的数组。
数组可以通过索引在
O(1) 的时间复杂度内查找到对应元素,索引是一个非负整数。
哈希表是类似的,可以通过 key 在
O(1) 的时间复杂度内查找到这个 key 对应的 value。key 的类型可以是数字、字符串等多种类型。
怎么做的?特别简单,哈希表的底层实现就是一个数组(我们不妨称之为 table)。它先把这个 key 通过一个哈希函数(我们不妨称之为 hash)转化成数组里面的索引,然后增删查改操作和数组基本相同:
c
// 哈希表伪码逻辑
class MyHashMap {
private:
vector<void*> table;
public:
// 增/改,复杂度 O(1)
void put(auto key, auto value) {
int index = hash(key);
table[index] = value;
}
// 查,复杂度 O(1)
auto get(auto key) {
int index = hash(key);
return table[index];
}
// 删,复杂度 O(1)
void remove(auto key) {
int index = hash(key);
table[index] = nullptr;
}
private:
// 哈希函数,把 key 转化成 table 中的合法索引
// 时间复杂度必须是 O(1),才能保证上述方法的复杂度都是 O(1)
int hash(auto key) {
// ...
}
};哈希冲突
上面给出了 hash 函数的实现,那么你肯定也会想到,如果两个不同的 key 通过哈希函数得到了相同的索引,怎么办呢?这种情况就叫做「哈希冲突」。
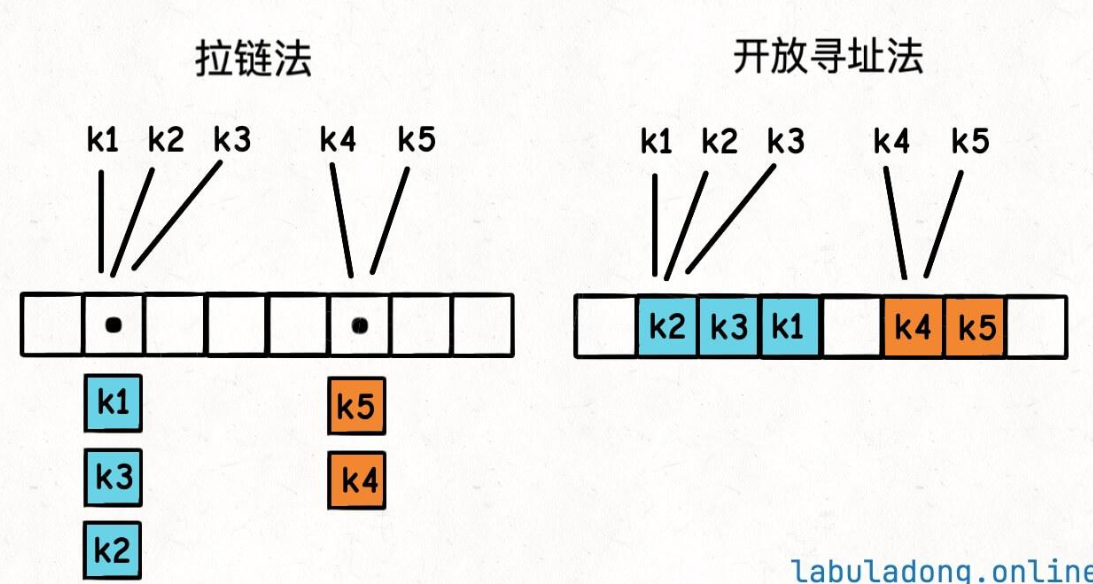
扩容和负载因子
1、哈希函数设计的不好,导致 key 的哈希值分布不均匀,很多 key 映射到了同一个索引上。
2、哈希表里面已经装了太多的 key-value 对了,这种情况下即使哈希函数再完美,也没办法避免哈希冲突。
对于第一个问题没什么好说的,开发编程语言标准库的大佬们已经帮你设计好了哈希函数,你只要调用就行了。
对于第二个问题是我们可以控制的,即避免哈希表装太满,这就引出了「负载因子」的概念。
两数之和
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hashtable;
for (int i = 0; i < nums.size(); ++i) {
int complement = target - nums[i];
if (hashtable.find(complement) != hashtable.end()) {
// 如果找到了,返回它的下标和当前下标
return {hashtable[complement], i};
}
hashtable[ums[i]]n = i;
}
return {}; // 题目保证有解,这就只是为了语法正确
}
};49. 字母异位词分组
第一个for循环先把元素按照排序的方式归类好例如 eat tae都归类为aet
注意先复制一份,这样不会修改原数组
在push进哈希表中达到这个效果mp = { "aet": "eat", "tea" }
然后剔除标签(it.second)即可
重点讲一下mpkey.push_back(s);,首先在map中查找key查不查的到都返回一个vector的引用
因为哈希表的value类型是vector< string > 然后利用vector的push_back插入s
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>> mp;
for(const string& s:strs){
string key = s;
sort(key.begin(),key.end());
mp[key].push_back(s);
}
vector<vector<string>> res;
for(auto& it : mp){
res.push_back(move(it.second));
}
return res;
}
};128. 最长连续序列
和上文不一样使用单独用于查找的unordered_set
先把数据都插入进去
然后遍历一下,如果这个数字的前一位没查到,就可以证明他可以当车头
记录此刻的头部和长度
如果能查到后一位
本身和长度就都加一(车头和后一节车厢连起来了)
这一列车厢全都连接完毕后,记录一下此刻的最大长度
cpp
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> num_set;
for(int& num:nums){
num_set.insert(num);
}
int maxlongnum = 0;
for(int num:num_set){
if(!num_set.count(num-1)){
int cur = num;
int cur_long = 1;
while(num_set.count(cur+1)){
cur += 1;
cur_long += 1;
}
maxlongnum = max(maxlongnum,cur_long);
}
}
return maxlongnum;
}
};<unordered_map>和<unordered_set>
<unordered_set>
. std::unordered_set (哈希集合)
- 定义:只存 Key,不存 Value。
- 特性:去重(Key 唯一)、无序。
- 用途:黑名单检测、去重、快速查找是否存在。
| 操作 | 代码示例 | 返回值解释 (重点) | 补充 |
|---|---|---|---|
| 插入 | st.insert(key) | 返回 pair<iterator, bool>。 | 1. first: 指向元素的迭代器。2. second: true 表示插入成功(原集合无此数),false 表示失败(已存在)。 |
| 查找 | st.find(key) | 返回 iterator。 | 如果找到,指向该元素;如果没找到,返回 st.end()。 |
| 计数 | st.count(key) | 返回 size_t (整数)。 | 因去重,只能返回 1 (存在) 或 0 (不存在)。 |
| 删除 | st.erase(key) | 返回 size_t。 | 成功删除返回 1,没删掉(本来就不在)返回 0。 |
cpp
#include <iostream>
#include <unordered_set>
using namespace std;
void testSet() {
unordered_set<int> st;
// 1. 插入并检查返回值
auto res = st.insert(10);
if (res.second) cout << "10 插入成功" << endl;
st.insert(10); // 再次插入,静默失败,不会报错
// 2. 查找
if (st.find(20) == st.end()) {
cout << "20 不在集合里" << endl;
}
}std::unordered_map (哈希映射)
- 定义:存储 Key-Value 对(键值对)。
- 特性:Key 唯一,Value 可以重复。通过 Key 找 Value。
- 用途:字典、缓存、计数器(统计词频)。
| 操作 | 代码示例 | 返回值解释 (重点) | 补充 |
|---|---|---|---|
| 下标访问 | mpkey | 返回 Value 的引用。 | ⚠️ 副作用:如果 Key 不存在,会自动插入一个默认值(0 或空串),然后返回这个新值的引用。 |
| 插入 | mp.insert({k, v}) | 返回 pair<iterator, bool>。 | 逻辑同 set,如果 Key 已存在,不会更新 Value,而是保持原样并返回 false。 |
| 查找 | mp.find(key) | 返回 iterator。 | it->first 是 Key,it->second 是 Value。没找到返回 mp.end()。 |
| 安全访问 | mp.at(key) | 返回 Value 的引用。 | 如果 Key 不存在,抛出 std::out_of_range 异常。 |
cpp
#include <iostream>
#include <unordered_map>
using namespace std;
void testMap() {
unordered_map<string, int> mp;
// 1. 下标法(最常用,但这行代码其实包含了 查找+插入)
mp["apple"] = 5;
// 2. 累加(引用引用的好处)
mp["apple"]++; // apple 变成 6
// 3. insert 的坑:不会覆盖!
mp.insert({"apple", 100});
cout << mp["apple"] << endl; // 输出还是 6,不是 100!
// 4. 正确的查找方式
if (mp.find("banana") == mp.end()) {
cout << "没有香蕉" << endl;
}
}面试->底层原理
当你声明一个 unordered_map 时,内存里到底发生了什么?
- 桶数组 (Buckets)
STL 内部维护了一个指针数组(通常称为 Buckets)。数组的每个位置存储一个指针,指向一个节点。 - 哈希函数 (Hash Function)
当你执行 mp"abc" = 1:
计算 "abc" 的哈希值(比如得到 999999)。
计算下标:index = hash_value % bucket_count(假设数组长 10,则 index = 9)。
去访问数组的第 9 号位置。 - 冲突解决 (Linked List)
如果第 9 号位置已经有数据了(比如 "xyz" 也在第 9 号),由于 C++ 采用拉链法:
它会遍历第 9 号位置挂着的链表。
检查 Key 是否相同。
如果 Key 相同,更新 Value。
如果 Key 不同,将新节点挂在链表的末尾(或头部,视实现而定)。 - 重哈希 (Rehashing)
如果数据越来越多,链表会越来越长,查询就会退化成 O ( N ) O(N) O(N)。
为了避免这种情况,有一个指标叫 Load Factor (负载因子),默认为 1.0。
当 元素数量 > 桶数量 * 1.0 时,哈希表会自动扩容。
扩容过程: 创建一个更大的数组(通常是 2 倍),把旧表里的所有元素重新计算哈希值,放入新表。这是一个耗时操作。
其他类型的哈希表 (Variant)
C++ STL 还提供了允许 Key 重复的哈希表。
- std::unordered_multiset
区别:允许插入重复的 Key。
用途:如果你只是一堆数据往里扔,想知道每个数出现了几次,但又不想用 Map 存 {num, count},可以直接扔进这里面。
API 差异:count(key) 会返回真实的个数(可能大于 1)。erase(key) 会删除所有等于该 Key 的元素。 - std::unordered_multimap
区别:一个 Key 可以对应多个 Value。
场景:比如建立"作者 -> 书籍"的索引,一个作者可以写多本书。
结构:{ "曹雪芹": "红楼梦" }, { "曹雪芹": "石头记" } 可以共存。