适用对象:Spring Boot / Spring Cloud 微服务研发与架构团队
目标:用 Sentinel 建立可落地的"限流/熔断/降级/热点/系统保护/规则工程化/集群治理/K8s部署"全链路体系。
目录
第一部分:架构与核心思想
Sentinel 设计哲学与流量治理模型
为什么 Sentinel 比 Hystrix 更适合现代微服务
第二部分:Spring Boot 整合 Sentinel 全流程
环境搭建与版本选型
Sentinel Dashboard 全面使用指南
第三部分:流量控制(限流)
QPS / 线程数 / 链路限流完整实战
@SentinelResource 标准用法与致命坑
第四部分:熔断与降级
异常比例 / RT / 慢调用熔断
多级降级设计模型
第五部分:热点参数与系统自适应保护
热点参数限流真实案例
系统规则如何防止整机雪崩
第六部分:统一异常体系
统一限流响应与企业标准返回模型
第七部分:规则工程化
Nacos 规则持久化完整方案
JSON 标准模板
第八部分:微服务熔断体系
Feign + Sentinel 服务间熔断
Gateway + Sentinel 三层流量防护
第九部分:高并发与集群治理
集群流控设计
大流量架构模式
第十部分:Kubernetes 部署
Sentinel 在 K8s 中的部署与端口模型
第十一部分:生产规范
资源命名规范
规则配置标准
事故复盘与踩坑总结
第十二部分:终极总结
Sentinel 企业级落地方法论
第一部分:架构与核心思想
1. Sentinel 设计哲学与流量治理模型
1.1 Sentinel 核心理念:以"流量"为中心的稳定性工程
Sentinel 的出发点不是"异常处理",而是把系统看作一个需要被治理的 流量系统:
入口流量
(用户请求 / RPC 调用 / MQ 消费)
内部资源
(接口、方法、远程调用、DB/Redis、线程池)
系统容量
(CPU/Load/RT/线程/队列)
治理策略
(限流、熔断降级、热点保护、系统自适应)
Sentinel 提供的能力包含:限流、并发隔离(信号量)、熔断降级、热点参数、系统规则、自适应保护等。
(官方项目与文档入口可参考 sentinelguard.io 与 alibaba/Sentinel 仓库)
1.2 资源模型(Resource)与规则模型(Rule)
Sentinel 的一切治理,都围绕 资源(resource) 展开。资源可以是:
HTTP API:GET:/orders/{id}
方法:OrderService#detail
RPC:rpc:orderService.detail
外部依赖:redis:get, db:selectOrder
治理规则则是"绑定资源"的策略集合:
FlowRule:流控(QPS/线程/匀速排队)
DegradeRule:熔断降级(异常比例/异常数/慢调用RT)
ParamFlowRule:热点参数
SystemRule:系统自适应保护
AuthorityRule:黑白名单(可选)
1.3 典型流量治理链路(建议用"全链路资源化")
用 Mermaid 表示"请求 → 资源 → 规则 → 结果"的链路:
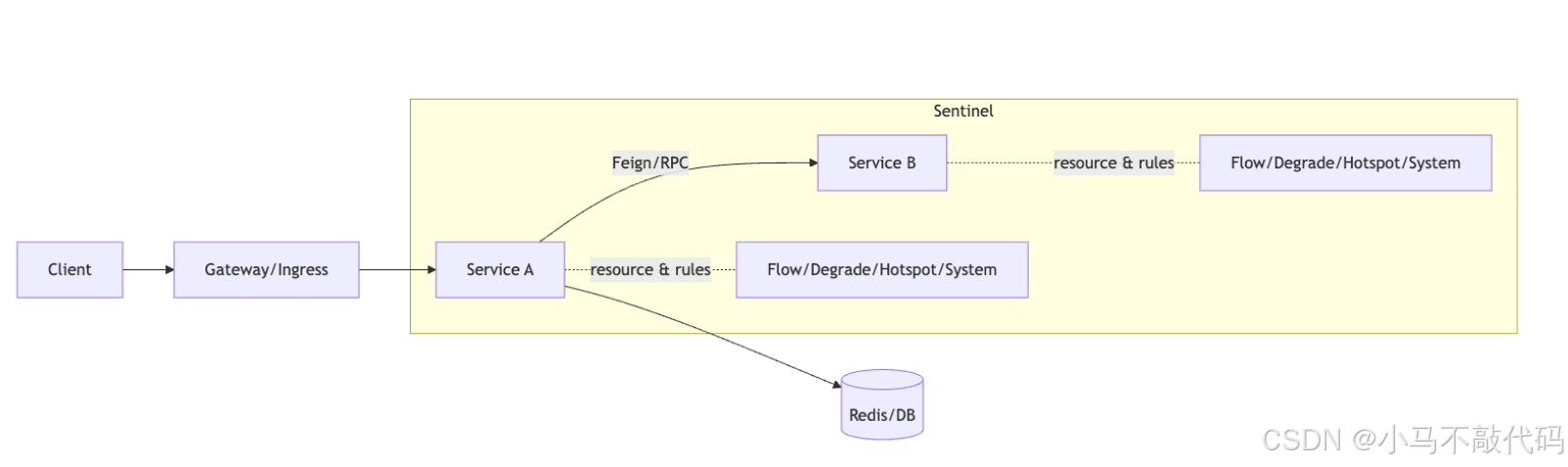
2. 为什么 Sentinel 比 Hystrix 更适合现代微服务
2.1 Hystrix 的时代背景与局限
Hystrix 以"线程池隔离 + 熔断"著称,但它的局限在于:
维护状态:Netflix 已停止对 Hystrix 的活跃维护(生态迁移明显)
以"熔断"为中心,对限流/热点/系统自适应支持不完整
动态规则与可视化治理不足(需要大量自研)
2.2 Sentinel 的优势(面向"治理平台化")
Sentinel 更适合现代微服务的关键点:
规则驱动:治理策略可动态下发与持久化(Nacos/文件/Push)
多维防护:限流、熔断、热点、系统保护一体化
可观测性:Dashboard 统一查看资源、规则、实时指标(Dashboard 可从官方 release 获取) (Dashboard 获取方式见官方文档说明)(sentinelguard.io)
与 Spring Cloud Alibaba 深度整合(OpenFeign、RestTemplate 等适配指南)(Spring Cloud Alibaba)
结论:Hystrix 更像"库";Sentinel 更像"治理体系的底座"。
第二部分:Spring Boot 整合 Sentinel 全流程
3. 环境搭建与版本选型
3.1 版本选型原则(强烈建议按"发布列车"对齐)
生产选型的第一原则:Spring Boot / Spring Cloud / Spring Cloud Alibaba(SCA)必须按兼容矩阵匹配。
官方说明(SCA 2023.x 分支示例)给出了适配表:
Spring Cloud Alibaba 2023.0.1.0 对应 Spring Cloud 2023.0.1 / Spring Boot 3.2.4(示例)(Spring Cloud Alibaba) SCA 仓库也给出各分支对应的 Spring Cloud & Spring Boot 范围(例如 2023.x 对应 Spring Cloud 2023 & Boot 3.2.x,2025.0.x 对应 Spring Cloud 2025.0.x & Boot 3.5.x 等)(GitHub)
✅ 落地建议
先定 Spring Boot 版本(公司基线)
再选 Spring Cloud 发布列车
最后选匹配的 SCA 版本(再引入 Sentinel Starter)
3.2 Maven 依赖(示例:BOM 管理 + Sentinel Starter)
以下为结构示例,请把版本替换为你选定的发布列车版本(按上面兼容表)。
java
<dependencyManagement>
<dependencies>
<!-- Spring Cloud BOM -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Spring Cloud Alibaba BOM -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${sca.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!-- 可选:Nacos 规则持久化会用到 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
</dependencies>3.3 application.yaml 最小配置
java
spring:
application:
name: order-service
cloud:
sentinel:
transport:
dashboard: sentinel-dashboard:8080
# 客户端与 Dashboard 通信的端口(默认 8719,冲突需改)
port: 8719
eager: true # 推荐:启动即初始化,避免首次请求抖动4. Sentinel Dashboard 全面使用指南
4.1 Dashboard 获取与启动
Dashboard 可从官方 release 获取 jar,或源码构建(官方文档明确说明从 release 下载与 mvn 打包)(sentinelguard.io)
启动示例(常用参数):
java
java -jar sentinel-dashboard.jar \
--server.port=8080 \
--sentinel.dashboard.auth.username=admin \
--sentinel.dashboard.auth.password=admin4.2 Dashboard 核心模块怎么用(按"生产工作流"理解)
机器列表:实例是否在线、心跳是否正常、端口是否可达
簇点链路:资源拓扑与调用链(定位限流/熔断点的核心入口)
实时监控:QPS、RT、异常、Block 数等
规则管理:流控/降级/热点/系统规则配置与推送(生产建议走持久化)
4.3 接入常见故障排查(Checklist)
实例不显示:
检查 spring.cloud.sentinel.transport.dashboard 是否可达
检查客户端 transport.port 是否被占用(默认 8719)
只有第一次请求才出现:
开启 eager: true 或保证启动后有一次健康探测请求
规则推送后不生效:
检查资源名是否一致(最常见:你配的资源名 ≠ 实际统计的资源名)
第三部分:流量控制(限流)
5. QPS / 线程数 / 链路限流完整实战
5.1 三种限流的适用场景
QPS 限流(最常用):保护接口吞吐;适用于突发流量
线程数/并发限流(隔离):保护下游慢资源(DB/三方接口)避免线程耗尽
链路限流:同一资源被不同入口调用时,可按入口精细化治理(防止"后台任务拖垮前台接口")
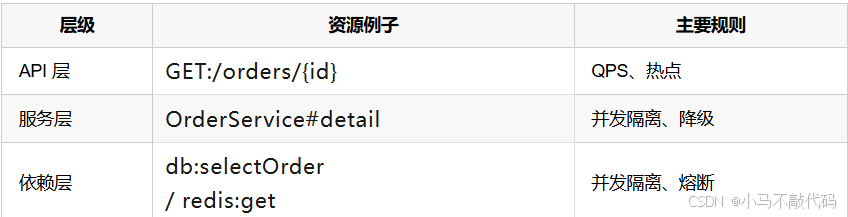
5.2 资源粒度建议(企业实践)
建议把资源分为三层并分别治理:
5.3 QPS 限流(Controller 示例)
java
@RestController
@RequestMapping("/orders")
public class OrderController {
@GetMapping("/{id}")
@SentinelResource(
value = "GET:/orders/{id}",
blockHandler = "block",
blockHandlerClass = OrderBlockHandlers.class
)
public OrderDTO detail(@PathVariable Long id) {
return new OrderDTO(id, "OK");
}
}
public class OrderBlockHandlers {
public static OrderDTO block(Long id, com.alibaba.csp.sentinel.slots.block.BlockException ex) {
// 这里返回"统一标准返回模型"的简化示例,完整见第11章
throw new BizException("TOO_MANY_REQUESTS", "请求过多,请稍后再试");
}
}5.4 并发(线程数)限流(保护慢资源)
适用于:DB 慢查询、第三方接口慢、下游不稳定。
策略要点:
QPS 不高但 RT 高 → 线程堆积 → 线程数限流更有效
线程数限流本质是"并发闸门",优先保护线程池
5.5 链路限流(按入口治理)
目标:同一资源 OrderService#detail 可能被:
前台接口调用(必须保)
定时任务调用(可降级)
批处理调用(可限流)
链路限流需要你明确入口(建议:入口统一资源化,并保持命名规范,见第19章)。
6. @SentinelResource 标准用法与致命坑
6.1 标准三件套:value / blockHandler / fallback
blockHandler:只处理限流/系统保护/热点的 BlockException
fallback:处理业务异常/运行时异常(不包含 block)
exceptionsToIgnore:白名单异常,不触发 fallback(慎用)
java
@SentinelResource(
value = "OrderService#detail",
blockHandler = "block",
fallback = "fallback"
)
public OrderDTO detail(Long id) { ... }
public OrderDTO block(Long id, BlockException ex) { ... }
public OrderDTO fallback(Long id, Throwable t) { ... }6.2 致命坑清单(生产高频)
方法签名不匹配:blockHandler/fallback 参数与返回值必须严格匹配
blockHandler 写成 fallback:导致限流时走 500(而不是业务可控降级)
资源名随意拼:Dashboard 配置了规则但资源名对不上 → "规则形同虚设"
把限流当重试:限流发生后应快速失败 + 引导客户端退避,不应服务端内部疯狂重试
未统一异常返回:不同接口返回风格不一致,前端/调用方难以治理(第11章解决)
第四部分:熔断与降级
7. 异常比例 / RT / 慢调用熔断
7.1 熔断的本质:切断"故障放大链路"
常见故障放大:
下游抖动 → RT 增大 → 线程堆积 → CPU 飙升 → 整体雪崩
熔断目标:
在"可控阈值"内主动降级,保证核心链路可用
7.2 三类常用熔断策略(选型建议)
异常比例:下游错误率高(5xx、超时)→ 快速熔断
异常数:错误量绝对值高(突发)→ 适合低QPS但偶发尖刺
慢调用 RT:RT 超阈值达到比例 → 适合"慢病型"故障(最常见)
实操建议
先用慢调用 RT 兜底(保护线程与整体吞吐)
再叠加异常比例(保护下游失败风暴)
7.3 降级(fallback)与熔断(degrade rule)配合
熔断触发后:请求会被快速拒绝(减少资源消耗)
降级兜底:返回可接受的"替代结果"(缓存、默认值、提示页)
8. 多级降级设计模型
8.1 典型多级降级:核心链路优先
按"业务价值"把能力分层:
L0:核心(必须成功)→ 强保护(更高优先级资源、更严格限流、更保守熔断)
L1:重要(可降级)→ 返回缓存/简化数据
L2:非核心(可关闭)→ 直接返回"系统繁忙"
8.2 多级降级落地模板(建议)
接口级 fallback:兜住用户体验
依赖级隔离/熔断:兜住线程与资源
网关级限流/熔断:兜住系统入口
第五部分:热点参数与系统自适应保护
9. 热点参数限流真实案例
9.1 场景:某个商品/热点 ID 把系统打穿
典型特征:
总 QPS 不高,但某个 productId=爆款 占比极高
DB/缓存击穿,局部资源被打穿
热点规则:
以参数维度治理(对"爆款 ID"单独限流)
9.2 落地方法(建议)
资源:GET:/products/{id}
参数:id
策略:
默认阈值:100 QPS
热点阈值:对 TopN 热点 ID 限制 10 QPS
工程建议:热点限流必须配合"本地缓存/布隆过滤/互斥锁/单飞"防止缓存击穿。
10. 系统规则如何防止整机雪崩
系统保护是"最后一道闸门",按机器全局视角触发:
CPU 使用率
Load1
平均 RT
线程数/入口 QPS(不同实现版本略有差异)
目标:当机器快扛不住时,全局限流保护进程存活(比 OOM/FullGC 强)。
第六部分:统一异常体系
11. 统一限流响应与企业标准返回模型
11.1 企业级返回模型(统一码 + 统一语义 + 可观测字段)
建议字段:
java
code:稳定错误码(如RATE_LIMITED/CIRCUIT_OPEN)
message:用户可读提示
traceId:链路追踪
timestamp
details:可选(仅内部/灰度返回)
{
"code": "RATE_LIMITED",
"message": "请求过多,请稍后再试",
"traceId": "b3f2d2...",
"timestamp": 1737168000000
}11.2 Web 层统一 Block 处理(推荐)
做法:实现统一的 BlockExceptionHandler(网关/Servlet 环境方式略不同),把所有 Block 统一返回为上面的标准模型。
原则:
不要在业务代码里到处 try-catch BlockException
统一在框架层拦截(ControllerAdvice / Filter / Gateway Handler)
第七部分:规则工程化
12. Nacos 规则持久化完整方案
12.1 为什么必须持久化
Dashboard 直接推规则的问题:
重启丢失
多环境不隔离
灰度/回滚难
规则变更不可审计
工程化目标:
规则作为配置资产:可版本化、可审计、可灰度
12.2 推荐架构:Nacos 作为单一真相源(SoT)
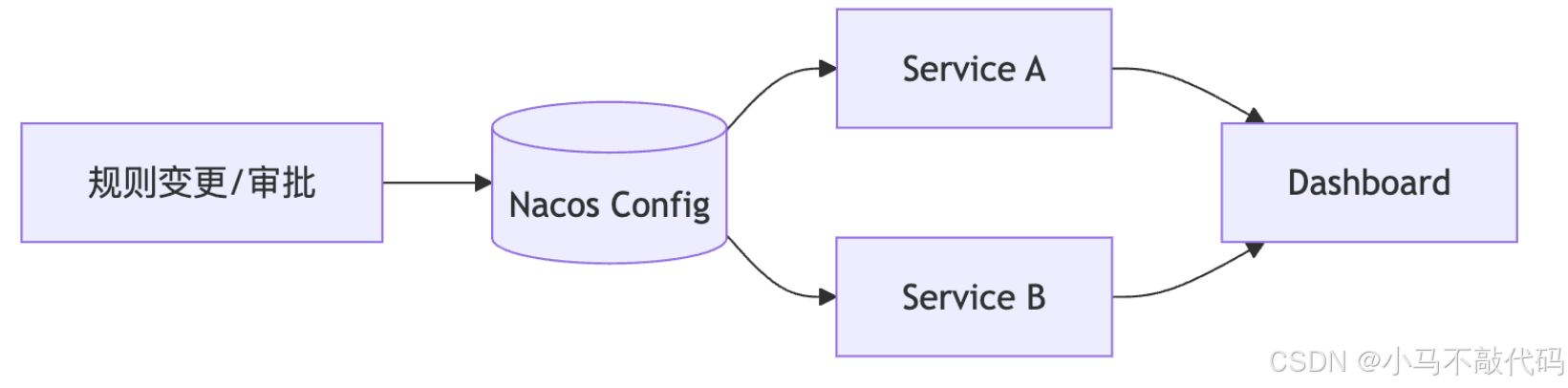
Spring Cloud Alibaba 与 Nacos/Sentinel 的整合属于常见实践路径(SCA 是 Sentinel 在 Spring 体系的主流整合方式之一)(Spring Cloud Alibaba)
12.3 Nacos DataSource 配置示例(概念模板)
java
spring:
cloud:
sentinel:
datasource:
flow:
nacos:
server-addr: nacos:8848
dataId: order-service-flow-rules
groupId: SENTINEL_RULES
rule-type: flow建议:按"应用名 + 规则类型 + 环境"拆分 dataId,例如: order-service.flow.prod.json / order-service.degrade.prod.json
13. JSON 标准模板
注意:不同 Sentinel/SCA 版本字段可能有细微差异;JSON 模板应以你项目依赖版本的 Rule 类为准(建议在代码里维护同款 POJO + 校验)。
13.1 FlowRule(流控)模板(示例)
java
[
{
"resource": "GET:/orders/{id}",
"limitApp": "default",
"grade": 1,
"count": 200,
"strategy": 0,
"controlBehavior": 0
}
]字段建议(工程约定):
resource:资源名(必须与统计资源一致)
grade:QPS/线程(枚举)
count:阈值
strategy:直接/关联/链路
controlBehavior:快速失败/匀速排队/预热
13.2 DegradeRule(熔断降级)模板(示例)
java
[
{
"resource": "rpc:inventory#deduct",
"grade": 0,
"count": 0.2,
"timeWindow": 10,
"minRequestAmount": 50,
"statIntervalMs": 10000
}
]13.3 ParamFlowRule(热点参数)模板(示例)
java
[
{
"resource": "GET:/products/{id}",
"paramIdx": 0,
"count": 50,
"grade": 1
}
]13.4 SystemRule(系统规则)模板(示例)
java
[
{
"avgRt": 200,
"maxThread": 300
}
]第八部分:微服务熔断体系
14. Feign + Sentinel 服务间熔断
14.1 目标:把"服务间调用"纳入同一治理体系
Feign 调用:天然是"资源"
下游抖动:应在调用侧快速降级,避免把压力传回上游
SCA 对 OpenFeign 等组件有适配说明(作为工程整合依据)(Spring Cloud Alibaba)
14.2 典型落地:FeignFallbackFactory(保留异常原因)
java
@FeignClient(name = "inventory-service", fallbackFactory = InventoryFallbackFactory.class)
public interface InventoryClient {
@PostMapping("/inventory/deduct")
DeductResult deduct(@RequestBody DeductReq req);
}
@Component
class InventoryFallbackFactory implements FallbackFactory<InventoryClient> {
@Override
public InventoryClient create(Throwable cause) {
return req -> DeductResult.fail("INVENTORY_DEGRADED", "库存服务繁忙");
}
}建议:fallback 返回必须"可观测"(带 code、traceId、降级原因),并与第11章统一模型一致。
15. Gateway + Sentinel 三层流量防护
15.1 三层模型(入口→服务→依赖)
第1层:Gateway(入口限流/黑白名单/基础熔断)
第2层:Service(业务资源限流/熔断/热点)
第3层:Dependency(DB/Redis/第三方隔离)
15.2 网关层规则建议
按路由维度(routeId / api group)限流
对"登录/下单/支付"设置更严格的保护
对"非核心接口"设置更激进的降级
第九部分:高并发与集群治理
16. 集群流控设计
16.1 为什么需要集群流控
单机限流解决不了:
多实例下阈值不一致(例如 10 台实例每台 200 QPS,总体变 2000 QPS)
热点流量被负载均衡打散后仍可能冲击下游
集群流控目标:把阈值从"实例维度"提升到"集群维度"。
16.2 架构:Token Server + Cluster Client
Token Server:统一发放令牌
Client:向 Token Server 申请令牌,超限即拒绝
生产建议:
Token Server 做高可用(至少 2 副本)
失败策略要明确:Token Server 不可用时,是"放行"还是"拒绝"(看业务风险)
17. 大流量架构模式
17.1 常见大流量组合拳
入口削峰:网关限流 + 排队 + 熔断
缓存体系:本地缓存 + 分布式缓存 + 防击穿
异步化:MQ 解耦(下单、日志、通知)
降级策略:多级数据(实时→近实时→缓存→默认值)
读写分离与分片:热点 key 拆分
17.2 Sentinel 在其中的位置
Sentinel 不是替代缓存/MQ/分库分表,而是提供:
可控的"保护闸门"
规则驱动的"动态治理"
第十部分:Kubernetes 部署
18. Sentinel 在 K8s 中的部署与端口模型
18.1 端口模型(必须讲清楚)
Dashboard HTTP 端口:例如 8080
客户端与 Dashboard 通信端口(transport.port):默认 8719(冲突需改)
Dashboard 下载与启动方式见官方文档说明(release jar / 源码构建)(sentinelguard.io)
18.2 K8s 部署建议(生产)
Dashboard:
Deployment + Service(ClusterIP)
Ingress 暴露给内网(建议加认证/白名单)
业务服务:
通过环境变量注入 dashboard 地址
配置 transport.port 避免 sidecar/多容器端口冲突
示例(概念):
java
env:
- name: SPRING_CLOUD_SENTINEL_TRANSPORT_DASHBOARD
value: "sentinel-dashboard:8080"
- name: SPRING_CLOUD_SENTINEL_TRANSPORT_PORT
value: "8719"Helm Chart 也有社区实现(适合作为参考,但生产仍建议走公司统一 Chart 规范)。(artifacthub.io)
第十一部分:生产规范
19. 资源命名规范
19.1 命名目标
稳定(改代码不轻易改资源名)
可读(看规则就知道保护什么)
可聚合(按域/系统/接口分组)
19.2 推荐命名格式(可直接落地)
HTTP API:METHOD:/path
GET:/orders/{id}
方法:Class#method
OrderService#detail
RPC:rpc:service#method
rpc:inventory#deduct
依赖:db:xxx / redis:xxx
db:selectOrder
强制规则:资源名是"治理资产",必须进入代码评审与变更流程。
20. 规则配置标准
20.1 规则生命周期(企业必备)
需求提出 → 影响评估 → 灰度 → 观测 → 全量 → 回滚预案
每条规则必须有:
目标资源
阈值依据(容量评估/压测结果)
生效范围(环境、集群、实例)
负责人
过期时间(避免历史规则堆积)
20.2 阈值设置"最小可行"原则
不要一上来就非常复杂
先做入口保护(QPS)+ 慢调用熔断
再逐步下沉到依赖层隔离与热点
21. 事故复盘与踩坑总结
21.1 复盘模板(强烈建议固定化)
事故时间线
影响面(QPS、错误率、RT、用户量)
根因(下游/配置/容量/发布)
Sentinel 规则是否生效(资源名是否对上?阈值是否合理?)
纠正与预防(规则工程化、压测基线、容量评估)
21.2 高频踩坑(再次强调)
资源名不一致 → 规则失效
把限流当重试 → 进一步打爆下游
未统一异常返回 → 调用方无法正确降级
规则不持久化 → 重启即丢、环境互串
第十二部分:终极总结
22. Sentinel 企业级落地方法论
22.1 一句话方法论
用 资源化 定义治理边界,用 规则工程化 管控变更,用 三层防护 扛住不确定性。
22.2 落地路线图(建议按阶段推进)
阶段1:单体/单服务防护
API 资源化 + QPS 限流 + 慢调用熔断 + 统一返回
阶段2:微服务链路治理
Feign 调用资源化 + 下游隔离/熔断 + 多级降级
阶段3:规则工程化
Nacos 持久化 + 灰度发布 + 审计回滚
阶段4:集群与云原生
集群流控 + K8s 部署规范 + 全链路可观测闭环
附录 A:快速自检清单(上线前)
兼容矩阵对齐(Boot/Cloud/SCA)(Spring Cloud Alibaba)
Dashboard 可访问、实例可见、指标正常(sentinelguard.io)
资源命名规范统一
统一 Block/异常返回已接入
核心链路已做:入口限流 + 慢调用熔断 + 依赖隔离
规则已走持久化与灰度流程