文章目录
- 每日一句正能量
- [第6章 Kafka分布式发布订阅消息系统](#第6章 Kafka分布式发布订阅消息系统)
- 章节概要
- [6.3 Kafka 集群部署与测试](#6.3 Kafka 集群部署与测试)
-
- [6.3.1 安装Kafka](#6.3.1 安装Kafka)
- [6.3.2 启动Kafka服务](#6.3.2 启动Kafka服务)

每日一句正能量
也许生活中偶有黯淡无光的时刻,但别忘了还有未实现的梦想,努力朝着自己的目标一点点前进。幸福就是每一个微小目标的达成。这些温暖明亮的小目标,一定也有你的。认真做好眼下的每一件事,去遇见因为努力而变得更美好的自己。
第6章 Kafka分布式发布订阅消息系统
章节概要
Kafka是一个高吞吐量的分布式发布订阅消息系统,它在实时计算系统中有着非常强大的功能。通常情况下,我们使用Kafka构建系统或应用程序之间的数据管道,用来转换或响应实时数据,使数据能够及时的进行业务计算,得出相应结果。本章将针对Kafka工作原理、Kafka集群部署以及Kafka的基本操作进行详细讲解。
6.3 Kafka 集群部署与测试
6.3.1 安装Kafka
Kafka集群部署依赖于Java环境和Zookeeper服务,在本书第二章搭建Spark HA小节,我们已经完成了上述环境和Zookeeper集群的配置。下面通过4个步骤讲解Kafka集群的安装流程。
- 下载、解压安装包
Kafka集群安装很简单,访问Kafka 官方网站http://kafka.apache.org/downloads.html下载安装包,由于后续章节会与Spark框架整合使用,因此在选择Kafka的版本时要与Scala版本保持一致, 本书选择当前最新稳定版本kafka_2.11-2.0.0.tgz 。
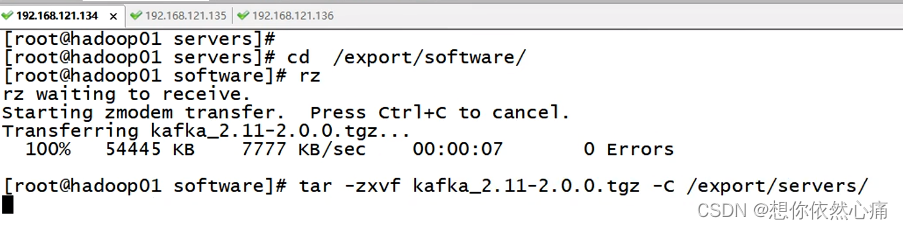
下载完成后,将安装包上传至hadoop01节点中的/export/software目录下,使用以下命令解压安装包:
shell
tar -zxvf kafka_2.11-2.0.0.tgz -C /export/servers/结果如下图所示:
- 修改配置文件。
进入Kafka文件夹下的/export/servers/kafka_2.11-2.0.0/config目录,修改server.properties配置文件(vi server.properties),修改后的内容如文件6-1所示。
文件6-1 server.properties
shell
#broker的全局唯一编号, 不能重复
broker.id=0
#用来监听链接的端口,producer或consumer将在此端 ]建立连接
por t=9092
#处理网络请求的线程数量
num. network.threads=3
#用来处理磁盘I0的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/export/data/kafka/
#topic在当前broker.上的分片个数
num.partitions=2
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=1
#滚动生成新的segment文件的最大时间
log.roll.hours=1
#日志文件中每个segment的大小,默认为1G
loa.seament.bvtes=1073741824
#周期性检查文件大小的时间
log.retention.check.interval.ms=30000
#日志清理是否打开
log.cleaner.enable=true
#broker需要使用zoakeeper保存meta数据
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
#zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000
#partionbuffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000
#消息缓冲的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000
#删除topic(是否允许删除)
delete.topic.enable=true
#设置本机IP
host.name=hadoop01关于文件中的核心参数介绍如下:
- broker.id:
集群中每个节点的唯一-且永久的名称, 该值必须大于等于0,在本案例中,主机名为hadoop01、hadoop02、hadoop03的节点中, 该参数值依次设置为0、1、 2。 - log.dirs:
指定运行日志存放的地址,可以指定多个目录,并以逗号分隔。 - zookeeper.connect:
指定Zookeeper集群中的IP与端口号。 - delete.topic.enable:
是否允许删除Topic,如果设置False, 表示允许删除。 - host.name:
设置本机IP地址。若设置错误,则客户端会抛出Producer connection to localhost:9092 unsuccessful的异常信息。
- 添加环境变量
为了操作方便,可以在/etc/profile文件中添加Kafka环境变量, 配置参数如下。
shell
export KAFKA_HOME=/export/servers/kafa_2.11-2.0.0
export PATH=$PATH:$KAFKA_HOME/bin- 分发文件
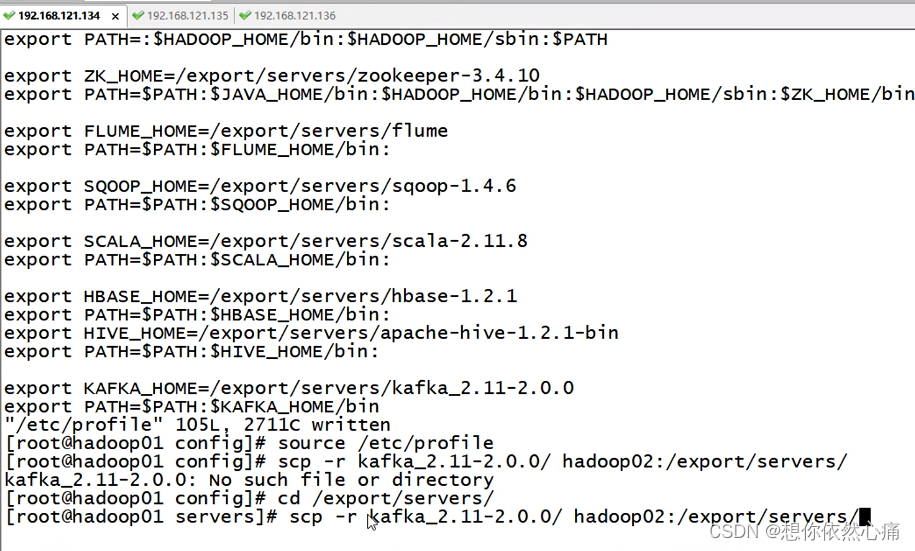
修改配置文件后,将Kafka本地安装目录/export/servers/kafka_ _2.11-2.0.0以及 环境变量配置文件/etc/profile分发至hadoop02、hadoop03机器, 命令如下(下面路径为相对路径,所以要先回到/export/servers目录下)。
shell
scp -r kafka_2.11-2.0.0/ hadoop02:/export/servers/
scp -r kafka_2.11-2.0.0/ hadoop03:/export/servers/
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile分发完成后,并根据当前节点的情况修改"broker.id"和"host.name*参数,随后还需要使用"source /etc/profile"使环境变量生效。至此,Kafka集群配置完毕。结果如下图所示:

将hadoop02上的/export/servers/kafka_2.11-2.0.0/config/ server.properties配置中的参数修改:
shell
broker.id =1
host.name=hadoop02将hadoop03上的/export/servers/kafka_2.11-2.0.0/config/ server.properties配置中的参数修改:
shell
broker.id =2
host.name=hadoop03结果如下图所示:



6.3.2 启动Kafka服务
- 启动Zookeeper服务
Kafka服务启动前,需要先启动Zookeeper集群服务(在hadoop集群下)。在三台节点上依次输入"zkServer.sh start"启动Zookeeper服务,也可以通过一键启动脚本启动Zookeeper集群服务, Zookeeper服务启动后的效果如图所示。
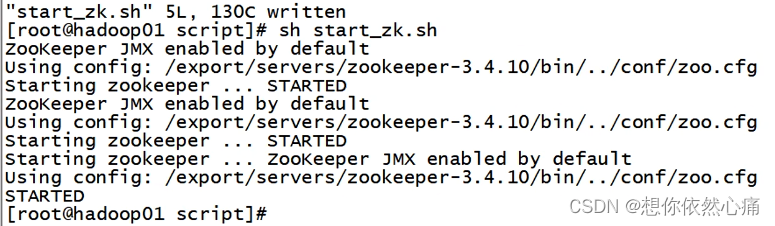
我们可以写一个一键启动脚本start_zk.sh来完成一键启动Zookeeper集群服务。具体命令如下:
shell
#!/bin/sh
for host in hadoop01 hadoop02 hadoop03
do
ssh root@$host "/export/servers/zookeeper-3.4.10/bin/zkServer.sh start"
done-
启动Kafka服务
Zookeeper服务启动成功后,进入到Kafka的/export/servers/kafka_2.11-2.0.0目录下bin/kafka-server start.sh脚本启动Kafka服务了,命令如下。bin/kafka-server-start.sh config/server.properties
结果如下图所示:

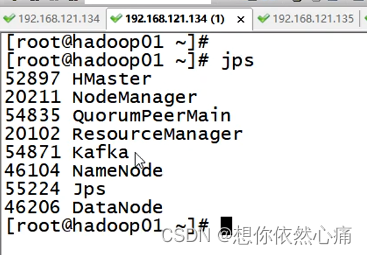
上述命令执行成功后,如果控制台输出的消息中无异常信息,并且光标始终处于闪烁状态,即表示Kafka服务启动成功,如图所示。

克隆一个会话用jps查看进程:
转载自:https://blog.csdn.net/u014727709/article/details/144041398
欢迎 👍点赞✍评论⭐收藏,欢迎指正