LangGraph学习笔记(二)---核心组件与工作流人机交互
文章目录
一、LangGraph
1.定义
LangGraph 是一个用于构建有状态的多参与者应用程序的库,利用 LLM 创建代理和多代理工作流。
2.核心优势
① 循环性:允许定义涉及循环的流程,适用于代理架构,区别于基于 DAG 的解决方案。
② 可控性:作为底层框架,提供对应用程序流和状态的细粒度控制。
③ 持久性:内置持久性支持,便于实现人机协作和记忆特性。
3.技术灵感来源
- Pregel 和 Apache Beam(底层设计灵感)
- NetworkX(公共接口设计)
4.开发与平台
① 开发者:LangChain Inc(LangChain 的创建者)
② 使用方式:可独立于 LangChain 使用
③ 平台组成:
- LangGraph 服务器(API)
- LangGraph SDK(API 客户端)
- LangGraph CLI(命令行工具)
- LangGraph Studio(UI/调试器)
④ 平台性质 :
商业解决方案,用于将代理部署到生产环境,构建于开源框架之上。
官方文档地址:https://langchain-ai.github.io/langgraph/
中文文档地址:https://www.aidoczh.com/langgraph/
5.主要特性
-
循环和分支:在您的应用程序中实现循环和条件。
-
持久性:在图中的每一步自动保存状态。在任何时刻暂停和恢复图的执行,以支持错误恢复、人机协作工作流、时间旅行等。
-
人机协作:中断图的执行以批准或编辑代理计划的下一个动作。
-
流式支持:在每个节点产生输出时进行流式传输(包括令牌流式传输)。
-
与 LangChain 的集成:LangGraph 与 LangChain 和 LangSmith 无缝集成(但不需要它们)。
6.LangGraph平台及解决的问题
① LangGraph平台定义
LangGraph 平台是一个商业解决方案,用于将代理应用程序部署到生产环境,构建于开源的 LangGraph 框架之上。
② 平台解决的问题(针对复杂部署)
-
流式支持:提供多种流式模式,优化以应对不同的应用需求。
-
后台运行:支持在后台异步运行代理。
-
支持长时间运行的代理:具备处理长时间运行任务的基础设施。
-
双重文本处理:处理用户在代理回复前收到两条消息的情况。
-
处理突发性:通过任务队列确保在高负载下请求依然能被稳定处理,避免丢失。
二、核心组件
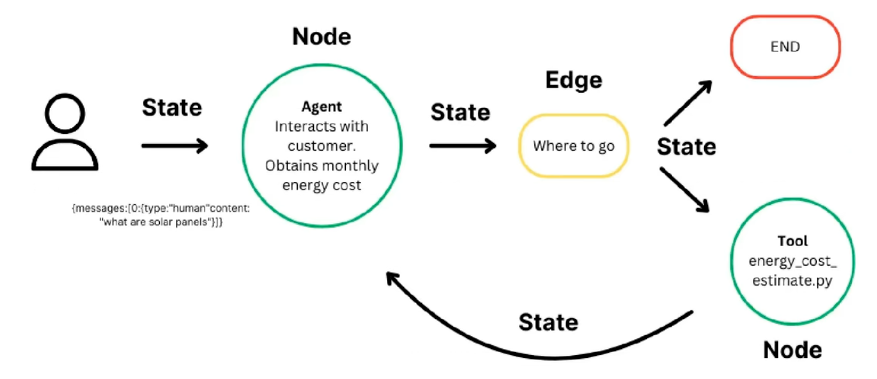
1.状态(State)
-
表示应用程序的当前快照的共享数据结构。
-
通常是 TypedDict 或 Pydantic BaseModel,也可以是任何 Python 类型。
2.节点(Nodes)
-
编码代理逻辑的 Python 函数。
-
接收当前状态作为输入,执行计算,并返回更新后的状态。
-
可以包含 LLM 调用或纯 Python 代码。
3.边(Edges)
-
根据当前状态决定下一步执行哪个节点的 Python 函数。
-
可以是条件分支,也可以是固定转换。
三、执行
1. 核心执行机制
LangGraph 使用 消息传递 机制定义程序执行流程,受 Google 的 Pregel 系统 启发,按 超级步骤 离散化执行。
2.执行流程
① 节点在接收到新消息(状态)时变为 活动状态。
② 活动节点执行其函数并更新状态,然后通过边向其他节点发送消息。
③ 接收节点在消息到达后激活,继续执行。
3.超级步骤
- 定义:图节点上的一次迭代。
超级步骤可以被认为是图节点上的单个迭代。并行运行的节点属于同一个超级步骤,而顺序运行的节点则属于不同的超级步骤。在图执行开始时,所有节点都处于 inactive 状态。当节点在任何传入边(或 "通道")上收到新消息(状态)时,它将变为 active 状态。然后,活动节点运行其函数并响应更新。在每个超级步骤结束时,没有传入消息的节点通过将其标记为 inactive 来投票 halt。当所有节点都处于 inactive 状态且没有消息在传输中时,图执行终止。
四、使用的主要图类
1.StateGraph
python
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
class MyState(TypedDict):
...
graph = StateGraph(MyState)- 核心说明:StateGraph 类是使用的主要图类。它由用户定义的 状态 对象参数化。
基类:图 - 图的特性:一个图,其节点通过读取和写入共享状态进行通信。每个节点的签名是 State -> Partial。
- Reducer 函数:每个状态键可以选择性地使用一个 reducer 函数进行注释,该函数将用于聚合从多个节点接收到的该键的值。reducer 函数的签名是 (Value, Value) -> Value。
① 参数
state_schema(类型:任何,默认值:None)
- 定义状态的模式类,用于规范图中共享状态的结构与类型。
- config_schema(可选 类型:\[任何],默认值:None)
- 定义配置的模式类。使用此方法可在您的 API 中公开可配置参数,方便外部对图的运行参数进行调整。
示例
python
# 示例:state_graph.py
# 从langgraph.graph模块导入START和StateGraph
from langgraph.graph import START, StateGraph
# 定义一个节点函数my_node,接收状态和配置,返回新的状态
def my_node(state, config):
return {"x": state["x"] + 1, "y": state["y"] + 2}
# 创建一个状态图构建器builder,使用字典类型作为状态类型
builder = StateGraph(dict)
# 向构建器中添加节点my_node,节点名称将自动设置为'my_node'
builder.add_node(my_node) # node name will be 'my_node'
# 添加一条边,从START到'my_node'节点
builder.add_edge(START, "my_node")
# 编译状态图,生成可执行的图
graph = builder.compile()
# 调用编译后的图,传入初始状态{"x": 1, "y": 2}
print(graph.invoke({"x": 1, "y": 2}))2.编译图
- 编译的定义:编译是一个非常简单的步骤。它对图的结构进行一些基本检查(例如检查是否有孤立的节点等)。它也是你可以指定运行时参数的地方,例如检查点和断点。
- 编译的必要性:你必须在使用图之前编译它,只需调用 .compile 方法即可完成编译。
- 构建图的完整流程:要构建你的图,你首先定义状态,然后添加节点和边,最后进行编译。
python
# 你必须在使用图之前编译它。
graph = graph_builder.compile(...)3.State(状态)
定义图时,你做的第一件事是定义图的 状态。状态 包含图的模式以及归约器函数,它们指定如何将更新应用于状态。状态 的模式将是图中所有 节点 和 边 的输入模式,可以是 TypedDict 或者 Pydantic 模型。所有 节点 将发出对 状态 的更新,这些更新然后使用指定的 归约器 函数进行应用。
1.Schema(模式)
指定图模式的主要文档化方法是使用 TypedDict。但是,我们也支持使用 Pydantic BaseModel 作为你的图状态,以添加默认值和其他数据验证。
默认情况下,图将具有相同的输入和输出模式。如果你想更改这一点,你也可以直接指定显式输入和输出模式。当你有许多键,其中一些是显式用于输入,而另一些是用于输出时,这很有用。查看此笔记本,了解如何使用。
默认情况下,图中的所有节点都将共享相同的状态。这意味着它们将读取和写入相同的状态通道。可以在图中创建节点写入私有状态通道,用于内部节点通信 ------ 查看此笔记本,了解如何执行此操作。
2.Reduces(归约器)
归约器是理解节点更新如何应用于状态的关键。
状态中的每个键都有其自己的独立归约器函数。如果未显式指定归约器函数,则假设对该键的所有更新都应该覆盖它。存在几种不同类型的归约器,从默认类型的归约器开始。
示例:
python
# 示例:default_reducer.py
from typing import TypedDict, List, Dict, Any
class State(TypedDict):
foo: int
bar: List[str]
def update_state(current_state: State, updates: Dict[str, Any]) -> State:
# 创建一个新的状态字典
new_state = current_state.copy()
# 更新状态字典中的值
new_state.update(updates)
return new_state
# 初始状态
state: State = {"foo": 1, "bar": ["hi"]}
# 第一个节点返回的更新
node1_update = {"foo": 2}
state = update_state(state, node1_update)
print(state) # 输出: {'foo': 2, 'bar': ['hi']}
# 第二个节点返回的更新
node2_update = {"bar": ["bye"]}
state = update_state(state, node2_update)
print(state) # 输出: {'foo': 2, 'bar': ['bye']}在此示例中,没有为任何键指定归约器函数。假设图的输入是 {"foo": 1, "bar": "hi"}。然后,假设第一个节点返回 {"foo": 2}。这被视为对状态的更新。请注意,节点不需要返回整个状态模式 ------ 只需更新即可。应用此更新后,状态则变为 {"foo": 2, "bar": "hi"}。如果第二个节点返回 {"bar": "bye"},则状态则变为 {"foo": 2, "bar": "bye"}。
4.Nodes(节点)
在 LangGraph 中,节点通常是 Python 函数(同步或 async),其中第一个位置参数是状态,(可选地),第二个位置参数是 "配置",包含可选的可配置参数(例如 thread_id)。
类似于 NetworkX,您可以使用 add_node 方法将这些节点添加到图形中。
python
# 示例:node_case.py
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START
from langgraph.graph import END
# 初始化 StateGraph,状态类型为字典
graph = StateGraph(dict)
# 定义节点
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
def my_other_node(state: dict):
return state
# 将节点添加到图中
graph.add_node("my_node", my_node)
graph.add_node("other_node", my_other_node)
# 连接节点以确保它们是可达的
graph.add_edge(START, "my_node")
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", END)
# 编译图
print(graph.compile())在幕后,函数被转换为RunnableLambda,它为您的函数添加了批处理和异步支持,以及本地跟踪和调试。
如果您在没有指定名称的情况下将节点添加到图形中,它将被赋予一个默认名称,该名称等同于函数名称。
python
graph.add_node(my_node)
# You can then create edges to/from this node by referencing it as `my_node`1.START节点
START 节点是一个特殊节点,它代表将用户输入发送到图形的节点。引用此节点的主要目的是确定哪些节点应该首先被调用。
python
from langgraph.graph import START
graph.add_edge(START, "my_node")
graph.add_edge("my_node", "other_node")2.END节点
END 节点是一个特殊节点,它代表一个终端节点。当您想要指定哪些边在完成操作后没有动作时,会引用此节点。
python
from langgraph.graph import END
graph.add_edge("other_node", END)5.Edges(边)
边定义了逻辑如何路由以及图形如何决定停止。这是您的代理如何工作以及不同节点如何相互通信的重要部分。有一些关键类型的边:
- 普通边:直接从一个节点到下一个节点。
- 条件边:调用一个函数来确定下一个要转到的节点。
- 入口点:用户输入到达时首先调用的节点。
- 条件入口点:调用一个函数来确定用户输入到达时首先调用的节点。
一个节点可以有多个输出边。如果一个节点有多个输出边,则所有这些目标节点将在下一个超级步骤中并行执行。
1.普通边
如果您总是想从节点 A 到节点 B,您可以直接使用 add_edge 方法。
python
# 示例:edges_case.py
graph.add_edge("node_a", "node_b")2.条件边
如果您想选择性地路由到一个或多个边(或选择性地终止),您可以使用 add_conditional_edges 方法。
此方法接受节点的名称和一个 "路由函数",该函数将在该节点执行后被调用。
python
graph.add_conditional_edges("node_a", routing_function)类似于节点,routing_function 接受图形的当前 state 并返回一个值。
默认情况下,返回值 routing_function 用作要将状态发送到下一个节点的节点名称(或节点列表)。
所有这些节点将在下一个超级步骤中并行运行。
您可以选择提供一个字典,该字典将 routing_function 的输出映射到下一个节点的名称。
python
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"})3.入口点
入口点是图形启动时运行的第一个节点。您可以从虚拟的 START 节点使用 add_edge 方法到要执行的第一个节点,以指定进入图形的位置。
python
from langgraph.graph import START
graph.add_edge(START, "my_node")4.条件入口点
条件入口点允许您根据自定义逻辑从不同的节点开始。您可以从虚拟的 START 节点使用 add_conditional_edges 来实现这一点。
python
from langgraph.graph import START
graph.add_conditional_edges(START, routing_function)您可以选择提供一个字典,该字典将 routing_function 的输出映射到下一个节点的名称。
python
graph.add_conditional_edges(START, routing_my, {True: "my_node", False: "other_node"})五、Human-in-the-loop(人机交互)
人机交互(或称 "在循环中")工作流将人类输入整合到自动化过程中,在关键阶段允许决策、验证或修正。这在基于 LLM 的应用中尤其有用,因为基础模型可能会产生偶尔的不准确性。在合规、决策或内容生成等低误差容忍场景中,人类的参与通过允许审查、修正或覆盖模型输出来确保可靠性。
使用案例
基于 LLM 应用中的人机交互工作流的关键使用案例包括:
- 🔍 审查工具调用:人类可以在工具执行之前审查、编辑或批准 LLM 请求的工具调用。
- ✅ 验证 LLM 输出:人类可以审查、编辑或批准 LLM 生成的内容。
- 💡 提供上下文:使 LLM 能够明确请求人类输入以进行澄清或提供额外细节,或支持多轮对话。
1.interrupt
interrupt函数 在 LangGraph 中通过在特定节点暂停图形、向人类展示信息以及使用他们的输入恢复图形,从而启用人工干预工作流。该函数对于批准、编辑或收集额外输入等任务非常有用。interrupt函数 与Command对象结合使用,以人类提供的输入恢复图形。
python
from langgraph.types import interrupt
def human_node(state: State):
value = interrupt(
# 任何可序列化为 JSON 的值,供人类查看。
# 例如,一个问题、一段文本或状态中的一组键
{
"text_to_revise": state["some_text"]
}
)
# 使用人类的输入更新状态或根据输入调整图形。
return {
"some_text": value
}
graph = graph_builder.compile(
checkpointer=checkpointer # `interrupt` 工作所需
)
# 运行图形直到遇到中断
thread_config = {"configurable": {"thread_id": "some_id"}}
graph.invoke(some_input, config=thread_config)
# 用人类的输入恢复图形
graph.invoke(Command(resume=value_from_human), config=thread_config)2.Warning
中断非常强大且易于使用。然而,尽管它们在开发者体验上可能类似于 Python 的 input() 函数,但重要的是要注意,它们不会自动从中断点恢复执行。相反,它们会重新运行使用中断的整个节点。因此,中断通常最好放置在节点的开头或一个专用的节点中。请阅读「从中断恢复」部分以获取更多细节。
要求
要在图形中使用 interrupt,您需要:
- 指定一个检查点,以在每一步后保存图形状态。
- 在适当位置调用 interrupt()。有关示例,请参见「设计模式」部分。
- 使用线程 ID 运行图形,直到触发 interrupt。
- 使用 invoke / ainvoke / stream / astream 恢复执行(见 Command 原语)。
3.设计模式
您通常可以采取三种不同的 "行动" 来实现人工干预工作流:
-
批准或拒绝:在关键步骤之前暂停图形,例如 API 调用,以审查和批准该操作。如果拒绝该操作,您可以阻止图形执行该步骤,并可能采取替代行动。此模式通常涉及根据人类的输入 "路由" 图形。
-
编辑图形状态:暂停图形以审查和编辑图形状态。这对于纠正错误或使用额外信息更新状态非常有用。此模式通常涉及使用人类的输入 "更新" 状态。
-
获取输入:在图形的特定步骤明确请求人类输入。这对于收集额外信息或上下文以帮助代理的决策过程或支持 "多轮对话" 非常有用。
链接:https://aidoczh.com/langgraph/concepts/human_in_the_loop/
总结
记得关注么么叽